背景
本文主要介绍程序的汇编执行逻辑,通过一段段的c程序,经过gcc编译,再用objdump反汇编,来观察每段代码具体到机器级别是怎么执行的。
你会发现汇编语言执行的逻辑跟高级语言差别还是很大的,汇编语言执行的对象是寄存器和内存。
下图是x86架构下的通用寄存器,也就是这些寄存器即可以作为加法的参数,也可以用于位运算。
但因为早期寄存器的数量比较少,所有对不同寄存器的使用就有要求,比如rax一般用于保存函数的返回值。
这里的rax是64位寄存器、eax是32位寄存器、ax是16位寄存器、al是8位寄存器。
 上图中的参数1、参数2是用来做函数调用时,传递参数的。一般规定
上图中的参数1、参数2是用来做函数调用时,传递参数的。一般规定rdi保存参数1、rsi保存参数2。
由于寄存器的数量有限,不可能无限制使用,比如在函数调用时,如果调用栈很长,那么寄存器就不够用了,这时候就需要将寄存器中的值保存起来,保存到内存中。
有些寄存器规定是函数的调用者保存的,有些寄存器规定是被调用者保存的。
当然,你也可以不遵守这个规定,程序可以执行,但是库函数、第三方库都是遵守这个规定的,你要是不遵守这个规定,胡乱使用寄存器,到时候可能会出现一些离奇的问题,那样排查起来都会很麻烦。
介绍常用的汇编指令
以及 GDB的一些调试参数
gcc编译命令,-g 是加上调试信息,如果用gdb调试的话就比较有用了。
1
|
gcc -g -o hello hello.c
|
反汇编命令,将二进制程序显示成汇编代码。
这里的汇编格式是AT&T格式的汇编,跟Intel格式的汇编显示起来有些不一样。
比如:
1
|
mov %rax, %rax # 将寄存器rax的值拷贝到rbx
|
对于Intel汇编显示的类似这样,跟AT&T格式是相反的:
1
|
mo rbx, rax # 将寄存器rax的值拷贝到rbx
|
一些比较常用的指令:
mov: 数据传送指令,把A->B,mov有很多变种,针对的是不同字节的,比如拷贝单字节、双字节、四字节等push和pop:这两个是操作栈的,将数据放入栈中,以及从栈中弹出,在函数调用的使用会经常用到inc、dec:分别是+1,-1neg、not:取负,取补add、sub、imul、idiv:分别是 加、减、乘、除xor、or、and:分别是异或、或、与shl、sar、shr:分别是左移、算术右移、逻辑右移
再来说说lea指令,像mov是把一个内存/寄存器的内容拷贝到另一处,而lea拷贝的是地址,等价的c代码如下:
1
2
|
int a = 10;
int *x = &a;
|
*x = &a等价于lea a的地址,x。
本篇文章将会通过各种简短的c程序来观察反汇编后的运行逻辑,由于gcc编译时没有做优化,所以有些反汇编看起来是在做无用功,比如将寄存器的内容拷贝到内存中,又将内存中的值拷贝回寄存器。
没有优化的好处是能方便的看出c代码和汇编代码的一一对应关系。
本文主要介绍的运行逻辑包括如下部分,通过将下面这些程序片段反汇编,来一一观察程序的底层运行原理:
- 函数执行原理
- 函数调用时的栈分配
- 函数调用和返回原理
- 指向函数的指针
- 函数调用时传递多个参数
- 循环跳转原理
- if-else逻辑
- do-while逻辑
- while逻辑
- for循环
- switch
- 数组和结构体原理
- 浮点数的计算原理
函数调用
栈分配
假设一段c程序,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
|
#include<stdio.h>
int fun(int a, int b) {
int c = 10;
return a + b + c;
}
int main() {
int res = fun(1, 2);
printf("res->%d\n",res);
return 1;
}
|
程序很简单,main函数调用fun函数,main传递了两个参数a和b。
在fun函数内,计算a + b + 10并返回。
最后回到main函数内,将结果打印。
编译代码,再反汇编后(删减了部分)
第一列是地址,第二列是机器编码,第三列是汇编代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
000000000040052d <fun>:
40052d: 55 push %rbp
40052e: 48 89 e5 mov %rsp,%rbp
400531: 89 7d ec mov %edi,-0x14(%rbp)
400534: 89 75 e8 mov %esi,-0x18(%rbp)
400537: c7 45 fc 0a 00 00 00 movl $0xa,-0x4(%rbp)
40053e: 8b 45 e8 mov -0x18(%rbp),%eax
400541: 8b 55 ec mov -0x14(%rbp),%edx
400544: 01 c2 add %eax,%edx
400546: 8b 45 fc mov -0x4(%rbp),%eax
400549: 01 d0 add %edx,%eax
40054b: 5d pop %rbp
40054c: c3 retq
000000000040054d <main>:
40054d: 55 push %rbp
40054e: 48 89 e5 mov %rsp,%rbp
400551: 48 83 ec 10 sub $0x10,%rsp
400555: be 02 00 00 00 mov $0x2,%esi
40055a: bf 01 00 00 00 mov $0x1,%edi
40055f: e8 c9 ff ff ff callq 40052d <fun>
400564: 89 45 fc mov %eax,-0x4(%rbp)
400567: 8b 45 fc mov -0x4(%rbp),%eax
40056a: 89 c6 mov %eax,%esi
40056c: bf 20 06 40 00 mov $0x400620,%edi
400571: b8 00 00 00 00 mov $0x0,%eax
400576: e8 95 fe ff ff callq 400410 <printf@plt>
40057b: b8 01 00 00 00 mov $0x1,%eax
400580: c9 leaveq
400581: c3 retq
400582: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
400589: 00 00 00
40058c: 0f 1f 40 00 nopl 0x0(%rax)
|
现在,我们从汇编的角度分析下,main函数时如何调用fun函数,并拿到返回结果的。
在main函数和fun函数开头结尾,都有这么一段:
1
2
3
4
5
|
push %rbp
mov $rsp, $rbp
...
...
pop %rbp
|
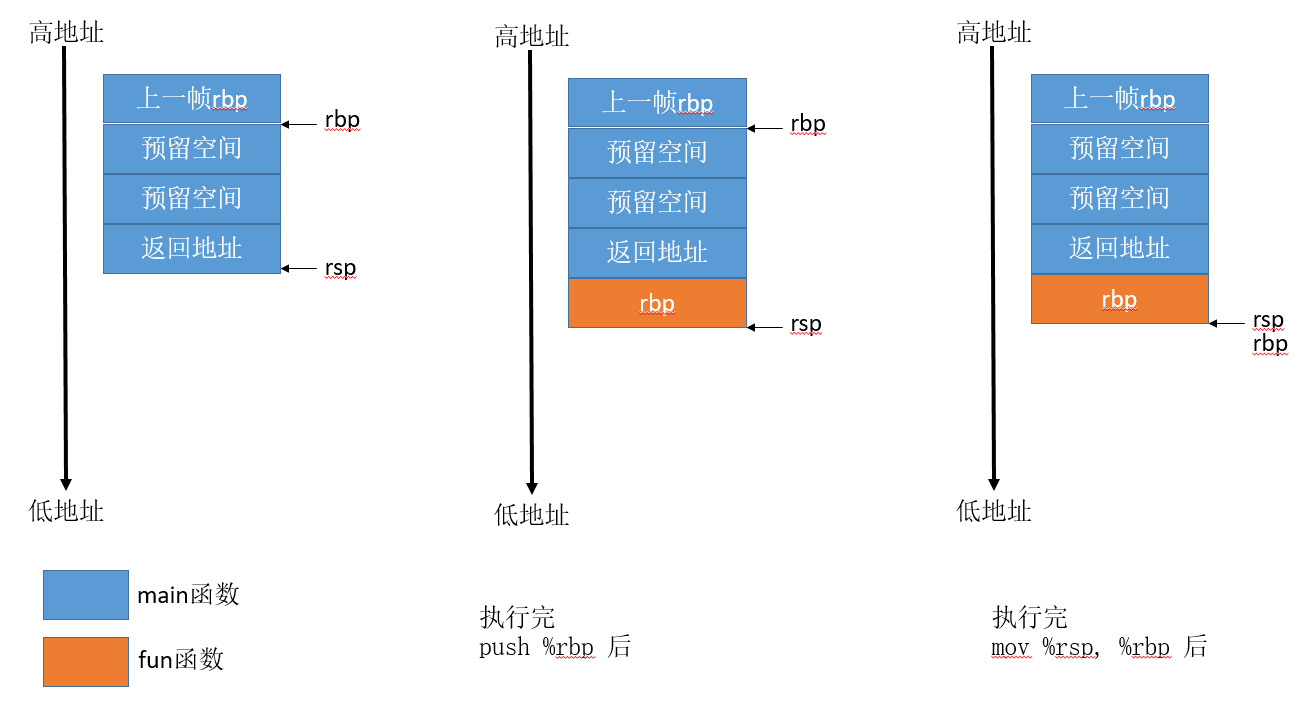
从汇编角度看,每个函数都有一个栈帧,而rsp和rbp是指向栈帧的寄存器。
rbp指向栈尾,rsp指向栈顶。
上图中蓝色表示main函数的栈帧,橙色部分表示fun函数的栈帧。
在准备执行push %rbp这句之前,栈帧的布局如上图最左边的结构。
当执行完push %rbp这句后,会把rbp的值保存起来,这是使用者约定,x86架构下的函数调用方和被调用方都有责任保存指定的寄存器。
同时rsp会减少8个字节,也就是从高地址往低地址方向走,执行完后的结果如上图中间部分。
之后,再执行mov $rsp, $rbp,这是将rsp的值赋给rbp,执行完后的结果如上图的右边部分。
函数开头结尾的那几句也可以写成这样:
1
2
3
4
5
6
|
sub $8, %rsp #rsp - 8,栈增长8个字节(栈往下增长)
mov %rbp, (%rsp) #将rbp保存到rsp的地址中
...
...
mov (%rsp), %rbp #将rsp地址中的值拷贝到rbp中(还原)
add $8, %rsp #将rsp + 8,栈缩小8个字节(往上缩小)
|
后面就是fun函数内部的具体逻辑了,在fun函数内部,可能又会使用栈,或者继续调用其他函数,那么rsp会继续增长(往低地址方向增长),而rbp是保持不变的。
等fun执行完了,会再执行pop %rbp,这句是将栈中的内容弹出来,放到rbp中。
栈中的内容是什么呢,就是上图橙色的部分,也就是将之前保存的rbp值会还原。
再来看看fun函数内部做的事情:
1
2
3
4
5
6
7
8
|
mov %edi,-0x14(%rbp)
mov %esi,-0x18(%rbp)
movl $0xa,-0x4(%rbp)
mov -0x18(%rbp),%eax
mov -0x14(%rbp),%edx
add %eax,%edx
mov -0x4(%rbp),%eax
add %edx,%eax
|
edi和esi对应第一、第二个参数,x86对于函数间传递参数是有要求的,在不超过6个参数的情况下,从参数 1 到 参数 6需要分别使用下面寄存器:
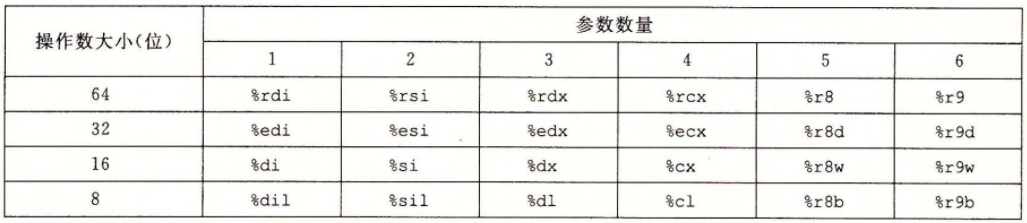
mov %edi,-0x14(%rbp)
mov %esi,-0x18(%rbp)
这两句的是把参数1、参数2的值放到栈中。
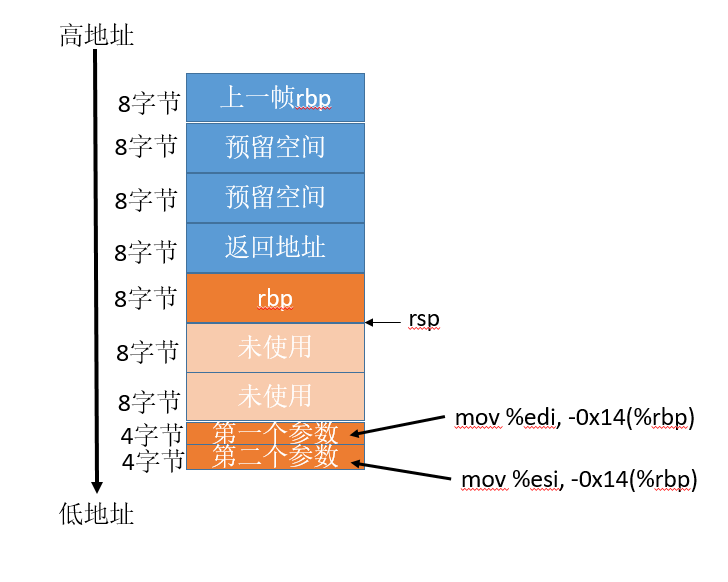 如上图,
如上图,-0x14(%rbp)相当于对rbp的地址减20字节记作x,mov操作则把第一个参数放到x地址中。
-x18(%rbp)相当于把rbp的地址减24字节记作y,mov操作则把第二个参数放到y地址中。
这两个地址实际上还没有开辟,因为他们比rsp都要小。
下面是fun后面的内容,直接看注释就行了。
1
2
3
4
5
6
|
movl $0xa,-0x4(%rbp) #把常数10放到rbp地址-10中
mov -0x18(%rbp),%eax #刚才存入的y地址内容放入eax
mov -0x14(%rbp),%edx #刚才存入的y地址内容放入edx
add %eax,%edx #相当于参数 a + b,存入edx
mov -0x4(%rbp),%eax #把10放入eax
add %edx,%eax #edx(计算过的a+b) + 10
|
结果保存在eax中,最后执行retq返回。
根据规定返回的值应当保存在eax中,所以main再取eax就可以拿到返回值了。
函数调用
回到main函数中,这回说下这几句(省略了机器编码):
1
2
3
4
5
6
7
8
9
10
11
|
00000000004005cf <fun>:
4005cf: push %rbp
。。。
4005ee: retq
4005f3: sub $0x10,%rsp
4005f7: mov $0x2,%esi
4005fc: mov $0x1,%edi
400601: callq 4005cf <fun>
400606: mov %eax,-0x4(%rbp)
|
sub $0x10,%rsp是扩大栈空间,但最后这个预留的空间其实没有被用到。
然后把2放到esi,1放到edi中。
后面一句很关键,call 4005cf <fun>,call指令是用来调用一个函数的。
这句是调用fun函数,4005cf就是fun函数第一条指令的地址。
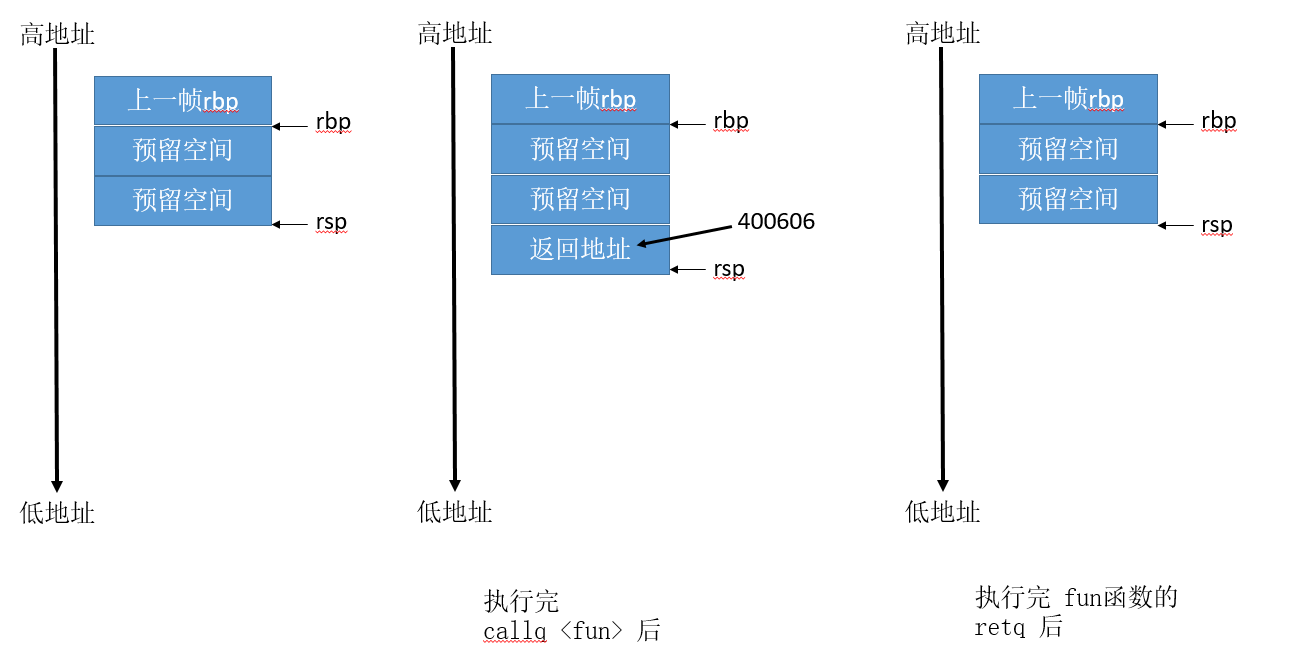 在执行
在执行call指令前,栈的布局如上图左边结构;等执行完call之后后,会将main函数接着call之后的下一条指令地址放入栈中。
下一条指令地址就是400606,同时还会修改rsp。
这时rip会指向fun函数的入口地址,这样下一条指令执行的就是fun函数中的逻辑了。
等fun函数执行完后会执行retq指令。
这时会将栈中的返回地址弹出来存入rip,于是下一条指令的就会接着从main函数调用之后继续执行。当然rsp的值也会跟着修改。
函数的执行也可以通过下面指令来模拟:
1
2
3
4
5
|
push %rip #将下一条待执行的地址保存起来
jmp <fun> #跳转到 fun 函数入口
。。。
pop %rip #将mian的下一条待执行的地址取出
jmp %rip #跳转到下一条指定继续执行
|
指向函数的指针
程序如下:
1
2
3
4
5
6
7
8
9
10
11
12
|
#include <stdio.h>
int fun(int x, int *p) {
return x + *p;
}
int foo() {
int (*fp)(int, int*);
fp = fun;
int y = 1;
int res = fp(3, &y);
printf("res -> %d\n",res);
}
|
反编译后的结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
000000000040052d <fun>:
40052d: push %rbp
40052e: mov %rsp,%rbp
400531: mov %edi,-0x4(%rbp)
400534: mov %rsi,-0x10(%rbp)
400538: mov -0x10(%rbp),%rax
40053c: mov (%rax),%edx
40053e: mov -0x4(%rbp),%eax
400541: add %edx,%eax
400543: pop %rbp
400544: retq
0000000000400545 <foo>:
400545: push %rbp
400546: mov %rsp,%rbp
400549: sub $0x10,%rsp
40054d: movq $0x40052d,-0x8(%rbp)
400554: 00
400555: movl $0x1,-0x10(%rbp)
40055c: lea -0x10(%rbp),%rdx
400560: mov -0x8(%rbp),%rax
400564: mov %rdx,%rsi
400567: mov $0x3,%edi
40056c: callq *%rax
40056e: mov %eax,-0xc(%rbp)
400571: mov -0xc(%rbp),%eax
400574: mov %eax,%esi
400576: mov $0x400630,%edi
40057b: mov $0x0,%eax
400580: callq 400410 <printf@plt>
400585: leaveq
400586: retq
|
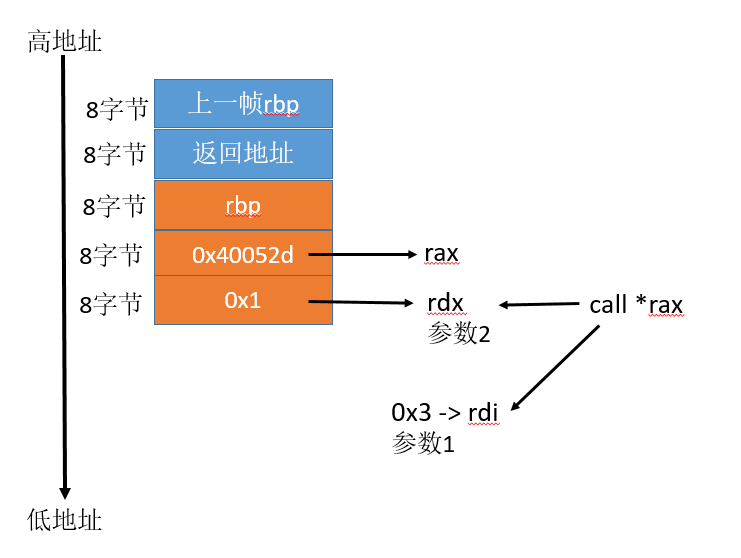
下面来分析下foo函数中的内容:
- 首先栈往下增长 16个字节
movq $0x40052d,-0x8(%rbp) 这句,是将fun的地址放到(%rbp-8)的位置movl $0x1,-0x10(%rbp),再将 1 放到(%rbp-16)的位置lea -0x10(%rbp),%rdx,把(%rbp-16)的地址赋给rdx,这句相当于指针,也就是&ymov -0x8(%rbp),%rax,把fun的地址赋给raxmov %rdx,%rsi和move %$0x3,%edi是在调用fun之前准备的参数,也就是参数二、参数一callq *%rax,注意rax前面有一个星号,这里先拿到了rax的值,也就是fun函数的地址,再调用这个函数
栈的布局,和寄存器内容如下:
传递多个参数
如果被调用的函数参数超过6个,就需要用栈中的内存来传递参数。
调用者将将参数1 - 参数6保存到对应的寄存器,再将参数7 - 参数n 放到栈中。
之后被调用的函数,可以通过寄存器获取到参数1 - 参数6,通过获取栈内存拿到 参数7 - 参数n。
超过6个参数传递的例子,代码如下:
1
2
3
4
5
6
7
8
9
10
11
|
#include<stdio.h>
int foo_2(int a, int b, int c, int d, int e, int f, int i, int j, int k) {
return a + b + c + d + e + f + i + j + k;
}
int foo_1() {
int res = foo_2(1, 2, 3, 4, 5, 6, 7, 8, 9);
printf("f -> %d\n",res);
}
|
反汇编后的结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
000000000040052d <foo_2>:
40052d: push %rbp
40052e: mov %rsp,%rbp
400531: mov %edi,-0x4(%rbp)
400534: mov %esi,-0x8(%rbp)
400537: mov %edx,-0xc(%rbp)
40053a: mov %ecx,-0x10(%rbp)
40053d: mov %r8d,-0x14(%rbp)
400541: mov %r9d,-0x18(%rbp)
400545: mov -0x8(%rbp),%eax
400548: mov -0x4(%rbp),%edx
40054b: add %eax,%edx
40054d: mov -0xc(%rbp),%eax
400550: add %eax,%edx
400552: mov -0x10(%rbp),%eax
400555: add %eax,%edx
400557: mov -0x14(%rbp),%eax
40055a: add %eax,%edx
40055c: mov -0x18(%rbp),%eax
40055f: add %eax,%edx
400561: mov 0x10(%rbp),%eax
400564: add %eax,%edx
400566: mov 0x18(%rbp),%eax
400569: add %eax,%edx
40056b: mov 0x20(%rbp),%eax
40056e: add %edx,%eax
400570: pop %rbp
400571: retq
0000000000400572 <foo_1>:
400572: push %rbp
400573: mov %rsp,%rbp
400576: sub $0x30,%rsp
40057a: movl $0x9,0x10(%rsp)
400581: 00
400582: movl $0x8,0x8(%rsp)
400589: 00
40058a: movl $0x7,(%rsp)
400591: mov $0x6,%r9d
400597: mov $0x5,%r8d
40059d: mov $0x4,%ecx
4005a2: mov $0x3,%edx
4005a7: mov $0x2,%esi
4005ac: mov $0x1,%edi
4005b1: callq 40052d <foo_2>
4005b6: mov %eax,-0x4(%rbp)
4005b9: mov -0x4(%rbp),%eax
4005bc: mov %eax,%esi
4005be: mov $0x4006c0,%edi
4005c3: mov $0x0,%eax
4005c8: callq 400410 <printf@plt>
4005cd: leaveq
4005ce: retq
|
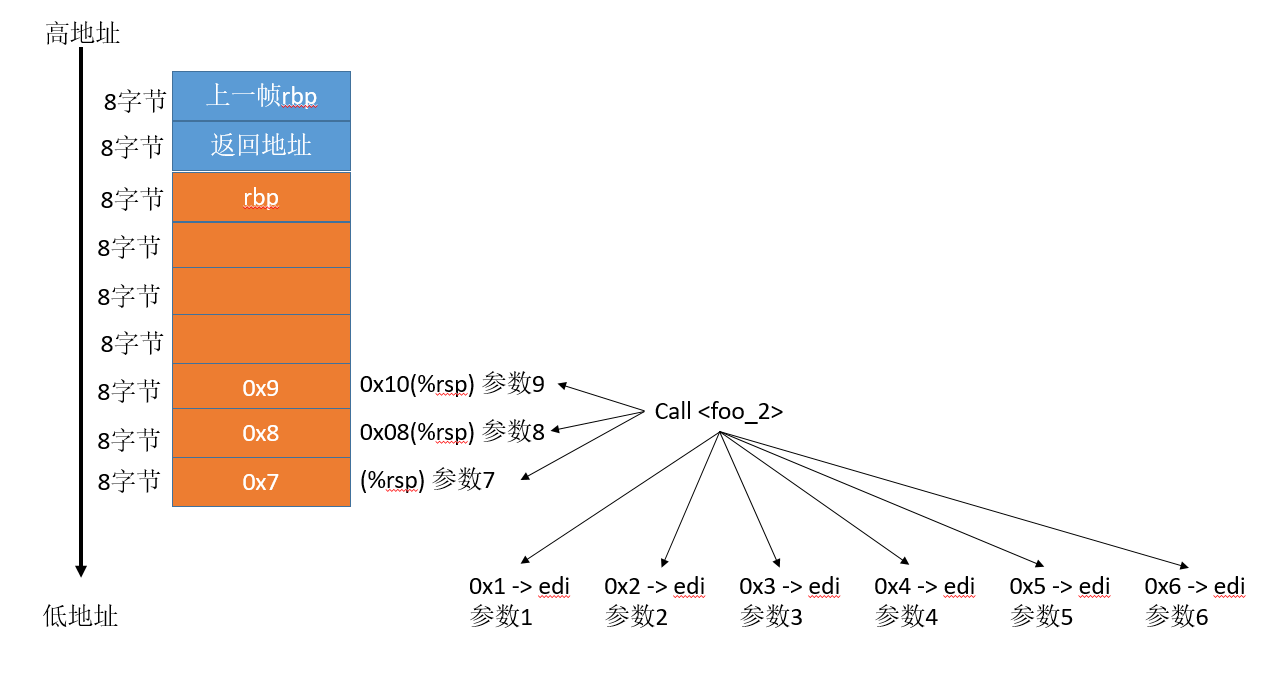
foo_1函数在调用foo_2之前,栈的布局和寄存器内容如下:
 由此可见,当参数超过了
由此可见,当参数超过了6个之后,就需要使用栈上的内存来传递参数了。
上图中,将参数7(地址(%rsp))、参数8(地址0x08(%rsp))、参数9(地址0x10(%rsp))保存在了栈中,分别对应
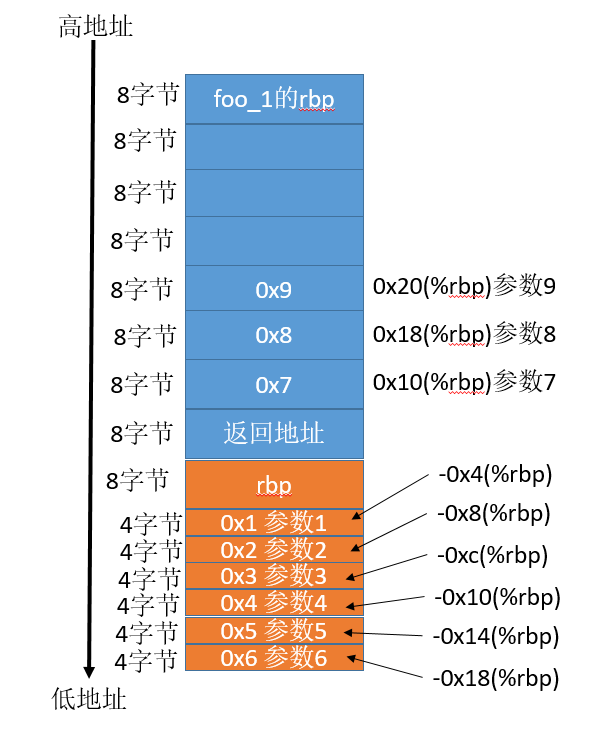
再来看下foo_2的栈和寄存器,下面蓝色部分是foo_1的栈,橙色部分是foo_2的栈
 在
在foo_2中,首先将参数1 – 参数6保存在了栈中,当然这其实没必要,参数都放到寄存器中了,直接用寄存器中的值就可以了,不需要来回倒塌,主要是gcc编译时没做优化。
参数7 - 参数8 保存在了foo_1的栈空间里,所以用0x10(%rbp)来获取参数7。
因为栈的地址是由高向低增长的,rbp加上一个值就是往上查找,减去一个值就是往下查找。
循环和跳转
跳转相关的指令
程序是如何实现跳转的呢?
关键在于cmp和test两个指令。
cmp用来做比较(减法操作)操作,cmp 1, rax
如果rax为0,就设置零标志位为1,之后跳转指令jz判断会判断eflag寄存器的零标志位是否为1,如果是则跳转到指定的地址处。
1
2
|
cmp 1, rax # rax - 1
jz 0x12345 # 如果为0,则跳转到0x12345处
|
而test用的是与操作:
test %rax, %rbx # rax & rbx
je 0x123456 # 如果相等则跳转到 0x12345处
上面说的的eflags是一个特殊的寄存器,当执行了test或cmp之,eflags的某些位会变化,比如有进位、或者溢出、结果为0等等。
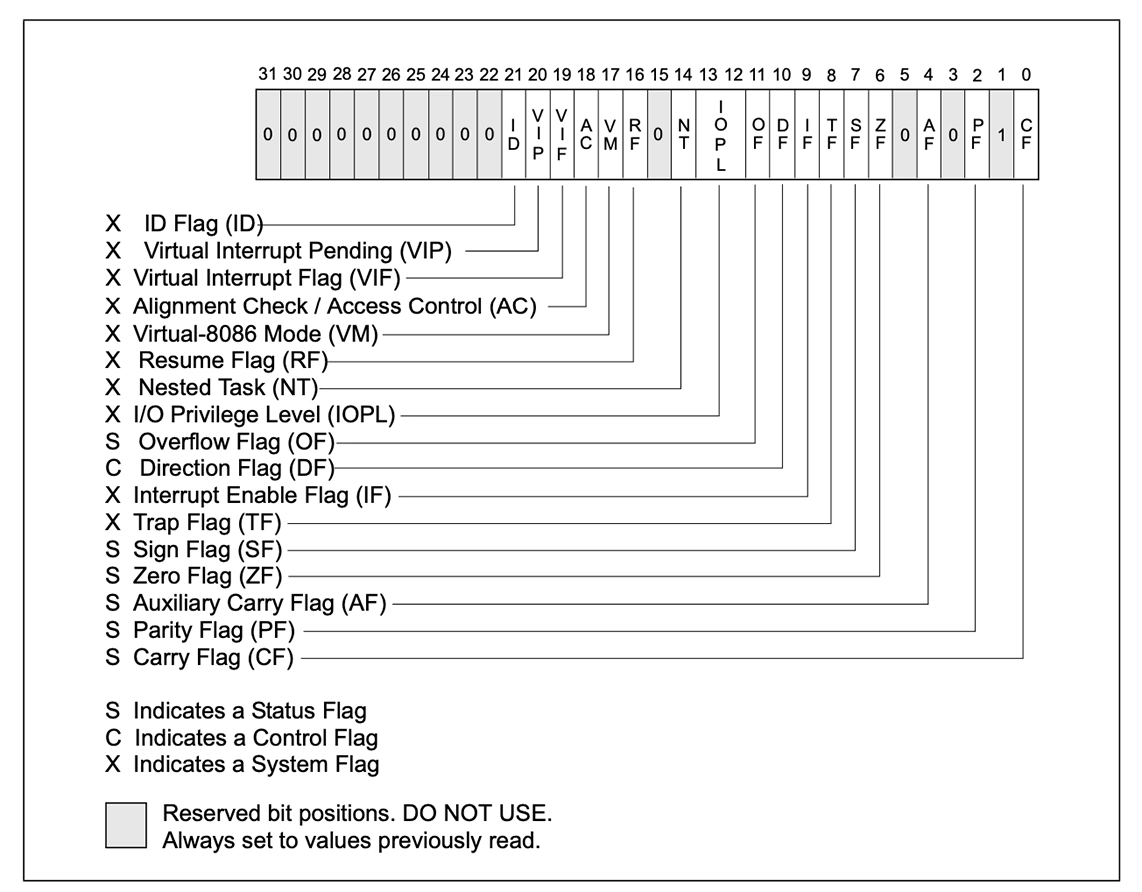
- OF(Overflow Flag)溢出标志,溢出时为1,否则置0.标明一个溢出了的计算,如:结构和目标不匹配。
- SF(Sign Flag)符号标志,结果为负时置1,否则置0。
- ZF(Zero Flag)零标志,运算结果为0时置1,否则置0。
- CF(Carry Flag)进位标志,进位时置1,否则置0.注意:Carry标志中存放计算后最右的位。
- AF(Auxiliary carry Flag)辅助进位标志,记录运算时第3位(半个字节)产生的进位置。
有进位时1,否则置0。
- PF(Parity Flag)奇偶标志.结果操作数中1的个数为偶数时置1,否则置0。
控制标志位:
- DF(Direction Flag)方向标志,在串处理指令中控制信息的方向。
- IF(Interrupt Flag)中断标志。
- TF(Trap Flag)陷井标志。
相关的跳转指令:
| 指令 |
含义 |
| je或jz |
如果相等则跳转(等于0) |
| jne或jnz |
如果不等则跳转(不等于0) |
| js |
如果为负则跳转 |
| jns |
如果不为负则跳转 |
| jg或jnle |
如果大于,且是有符号数则跳转 |
| jge或jnl |
如果大于等于,且是有符号数则跳转 |
| jl或jnge |
如果小于,且是有符号数则跳转 |
| jle或jng |
如果小于等于,且是有符号数则跳转 |
if判断
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
int loop_if(int i) {
int res = 0;
if(1 == i) {
res = 1;
}
else if(2 == i) {
res = 2;
}
else {
res = 10;
}
return res;
}
|
jmp跳转后面跟的是loop_if的起始地址+迁移量组成的标签,比如:jne 4005de <loop_if+0x1d>,jne后面跟的就是跳转到哪条地址,尖括号中对应的是loop_if起始地址的偏移量,这里跳转的是4005de。
对应的就是这句:4005de: cmpl $0x2,-0x14(%rbp),我在这句后面加了注释, # 后面跟的就是标签 <loop_if+0x1d>。
反汇编的结果如下(省略了机器编码):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
00000000004005c1 <loop_if>:
4005c1: push %rbp
4005c2: mov %rsp,%rbp
4005c5: mov %edi,-0x14(%rbp)
4005c8: movl $0x0,-0x4(%rbp)
4005cf: cmpl $0x1,-0x14(%rbp)
4005d3: jne 4005de <loop_if+0x1d>
4005d5: movl $0x1,-0x4(%rbp)
4005dc: jmp 4005f4 <loop_if+0x33>
4005de: cmpl $0x2,-0x14(%rbp) #<loop_if+0x1d>
4005e2: jne 4005ed <loop_if+0x2c>
4005e4: movl $0x2,-0x4(%rbp)
4005eb: jmp 4005f4 <loop_if+0x33>
4005ed: movl $0xa,-0x4(%rbp) #<loop_if+0x2c>
4005f4: mov -0x4(%rbp),%eax #<loop_if+0x33>
4005f7: pop %rbp
4005f8: retq
|
汇编代码的跳转逻辑如下:

do-while
代码如下:
1
2
3
4
5
6
7
8
9
|
int loop_1() {
int a = 1;
int res = 0;
do {
res = a * 10;
a++;
} while(a < 10);
return res;
}
|
等价的goto版本如下,一上来先执行loop标签里面的代码,然后执行if判断,如果满足条件则goto到loop标签处,继续执行。后面的汇编代码其实就是翻译这个goto版本。
1
2
3
4
5
6
7
8
9
10
11
|
int loop_1() {
int a = 1;
int res = 0;
loop:
res = a * 10;
a++;
if(a < 10) {
goto loop;
}
return res;
}
|
反汇编后的结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
000000000040052d <loop_1>:
40052d: push %rbp
40052e: mov %rsp,%rbp
400531: movl $0x1,-0x4(%rbp) # a = 1
400538: movl $0x0,-0x8(%rbp) # res = 0
40053f: mov -0x4(%rbp),%edx # res -> %edx
400542: mov %edx,%eax
400544: shl $0x2,%eax # 逻辑左移,等于eax * 2
400547: add %edx,%eax # eax + 1
400549: add %eax,%eax # eax * 2,这三条指令类似 ((eax*4)+1)*2
40054b: mov %eax,-0x8(%rbp) # eax -> res
40054e: addl $0x1,-0x4(%rbp) # a++
400552: cmpl $0x9,-0x4(%rbp) # a和9比较
400556: jle 40053f <loop_1+0x12> # 若小于跳转到 40053f
400558: mov -0x8(%rbp),%eax # 保存结果->eax,待返回用
40055b: pop %rbp
40055c: retq
|
while循环
代码如下:
1
2
3
4
5
6
7
8
9
|
int loop_2() {
int a = 1;
int res = 0;
while(a < 10) {
res = a * 10;
a++;
}
return res;
}
|
等价的goto版本,一上来先goto到test标签,执行if判断,如果满足跳转到loop标签处继续执行,不满足则往下执行,相当于跳出了while循环,汇编代码就是翻译了这段等价的goto代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
int loop_2() {
int a = 1;
int res = 0;
goto test:
loop:
res = a * 10;
a++;
test:
if(a < 10) {
goto loop;
}
return res;
}
|
反汇编后的结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
000000000040055d <loop_2>:
40055d: push %rbp
40055e: mov %rsp,%rbp
400561: movl $0x1,-0x4(%rbp) # a = 1
400568: movl $0x0,-0x8(%rbp) # res = 0
40056f: jmp 400584 <loop_2+0x27> #跳转到 400584
400571: mov -0x4(%rbp),%edx # res -> edx
400574: mov %edx,%eax # exd -> eax
400576: shl $0x2,%eax # 逻辑左移,等于eax * 2
400579: add %edx,%eax # eax + 1
40057b: add %eax,%eax # eax * 2,这三条指令类似 ((eax*4)+1)*2
40057d: mov %eax,-0x8(%rbp) # eax -> res
400580: addl $0x1,-0x4(%rbp) # a++
400584: cmpl $0x9,-0x4(%rbp) # a和9比较
400588: jle 400571 <loop_2+0x14> # 若小于跳转到 400571
40058a: mov -0x8(%rbp),%eax # 保存结果->eax,待返回用
40058d: pop %rbp
40058e: retq
|
for循环
代码如下:
1
2
3
4
5
6
7
|
int loop_3() {
int res = 0;
for(int a = 1; a < 10; ++a) {
res = a * 10;
}
return res;
}
|
等价的goto版本,跟while的goto版本有些类似,一上来先判断下是否满足条件,不满足的话就不会执行这个循环了,循环主体和a++都放在了loop块内,在loop块内还有一个判断,如果满足条件则跳转到loop继续执行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
int loop_3() {
int a = 1;
int res = 0;
if(n >= 10) {
goto done
}
loop:
res = a * 10;
a++;
if(a < 10) {
goto loop;
}
done:
return res;
}
|
反汇编结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
000000000040058f <loop_3>:
40058f: push %rbp
400590: mov %rsp,%rbp
400593: movl $0x0,-0x4(%rbp) # 0 -> res
40059a: movl $0x1,-0x8(%rbp) # 1 -> a
4005a1: jmp 4005b6 <loop_3+0x27> # 强制跳转,准备比较
4005a3: mov -0x8(%rbp),%edx # a(1) -> edx
4005a6: mov %edx,%eax # edx -> eax
4005a8: shl $0x2,%eax # 逻辑左移,等于eax * 2
4005ab: add %edx,%eax # eax + 1
4005ad: add %eax,%eax # eax * 2,这三条指令类似 ((eax*4)+1)*2
4005af: mov %eax,-0x4(%rbp) # eax -> res
4005b2: addl $0x1,-0x8(%rbp) # a++
4005b6: cmpl $0x9,-0x8(%rbp) #9和a比较
4005ba: jle 4005a3 <loop_3+0x14> # 若小于则跳转
4005bc: mov -0x4(%rbp),%eax # 否则将结果->eax,待返回使用
4005bf: pop %rbp
4005c0: retq
|
switch语句
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
int loop_switch(int i ) {
int res = 0;
switch(i) {
case 1:
res = 1;
break;
case 2:
res = 2;
break;
case 3:
res = 3;
break;
case 4:
res = 4;
break;
case 5:
res = 5;
break;
default:
res = 10;
break;
}
return res;
}
|
switch语句是用跳转表实现的,根据传入参数值,然后去跳转表中查找匹配的地址,之后直接做一个跳转,这样的好处是省去了大量的比较了,即便条件分支很多,也不会对性能有影响,加上了跳转表后的逻辑如下,后面汇编代码就是根据这个逻辑翻译的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
static void *jmp[6] = {&&case_1,
&&case_2,
&&case_3,
&&case_4,
&&case_5,
&&case_default};
if(i > 6) {
goto *jmp[6]
}
case_1:
res = 1;
goto done;
case_2:
res = 2;
goto done;
case_3:
res = 3;
goto done;
case _4:
res = 4;
goto done;
case_5:
res = 5;
goto done;
case_default:
res = 10;
done:
res -> %rax
|
反汇编结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
00000000004006e6 <loop_switch>:
4006e6: push %rbp
4006e7: mov %rsp,%rbp
4006ea: mov %edi,-0x14(%rbp) # 保存参数i
4006ed: movl $0x0,-0x4(%rbp) # res <- 0
4006f4: cmpl $0x5,-0x14(%rbp) # 比较i和5
4006f8: ja 400734 <loop_switch+0x4e> # 若大于5,则执行defualt分支
4006fa: mov -0x14(%rbp),%eax # i -> eax
4006fd: mov 0x4008f0(,%rax,8),%rax # 跳转表
400704: 00
400705: jmpq *%rax # 执行跳转表
400707: movl $0x1,-0x4(%rbp) # res <- 1
40070e: jmp 40073c <loop_switch+0x56> # 跳转到switch结束后的位置
400710: movl $0x2,-0x4(%rbp) # res < - 2
400717: jmp 40073c <loop_switch+0x56> # 跳转到switch结束后的位置
400719: movl $0x3,-0x4(%rbp) # res <- 3
400720: jmp 40073c <loop_switch+0x56> # 跳转到switch结束后的位置
400722: movl $0x4,-0x4(%rbp) # res <- 4
400729: jmp 40073c <loop_switch+0x56> # 跳转到switch结束后的位置
40072b: movl $0x5,-0x4(%rbp) # res <- 5
400732: jmp 40073c <loop_switch+0x56> # 跳转到switch结束后的位置
400734: movl $0xa,-0x4(%rbp) # res <- 10
40073b: nop
40073c: mov -0x4(%rbp),%eax # switch结束后的位置, res->%rax,待函数返回使用
40073f: pop %rbp
400740: retq
|
switch执行的跳转逻辑如下图:

组合和结构体
这里展示了数组、结构体对应的汇编代码,从下面的反汇编代码能看到,汇编里面并没有数组、结构体这些东西,对于汇编来说,只有读写内存、读写寄存器而已。
数组
代码如下:
1
2
3
4
|
void arr_1() {
int n[5] = {1,2,3,4,5};
n[3] = 99;
}
|
反汇编后的结果如下:
1
2
3
4
5
6
7
8
9
10
11
|
000000000040057d <arr_1>:
40057d: push %rbp
40057e: mov %rsp,%rbp
400581: movl $0x1,-0x20(%rbp)
400588: movl $0x2,-0x1c(%rbp)
40058f: movl $0x3,-0x18(%rbp)
400596: movl $0x4,-0x14(%rbp)
40059d: movl $0x5,-0x10(%rbp)
4005a4: movl $0x63,-0x14(%rbp)
4005ab: pop %rbp
4005ac: retq
|
上面汇编操作对应如下图:
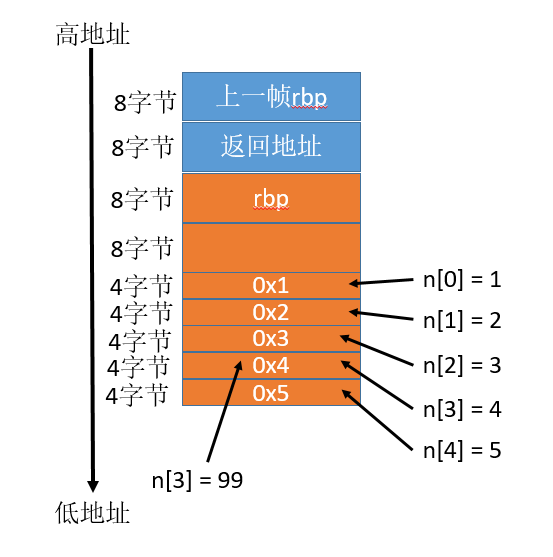 从汇编角度看,其实是没有数组这个东西的,因为操作的都是内存。所以对于同样一个内存地址,可以写4字节,也可以写8字节,甚至超过数组范围写数据也是可以的,汇编也没有越界、类型不匹配这种检查。
从汇编角度看,其实是没有数组这个东西的,因为操作的都是内存。所以对于同样一个内存地址,可以写4字节,也可以写8字节,甚至超过数组范围写数据也是可以的,汇编也没有越界、类型不匹配这种检查。
结构体
代码如下:
1
2
3
4
5
6
7
8
9
10
11
|
struct person {
int a;
char b;
char *c;
} p;
void arr_2() {
struct person t;
t.a = 10;
t.b = 'a';
t.c = "abcde";
}
|
反汇编结果如下:
1
2
3
4
5
6
7
8
9
|
00000000004005ad <arr_2>:
4005ad: push %rbp
4005ae: mov %rsp,%rbp
4005b1: movl $0xa,-0x10(%rbp) # t.a = 10
4005b8: movb $0x61,-0xc(%rbp) # t.b = 'a'
4005bc: movq $0x4008c0,-0x8(%rbp) # t.c = "abcde"
4005c3: 00
4005c4: pop %rbp
4005c5: retq
|
从反汇编的结果看,结构体的逻辑很简单,就是往栈中赋几个值。而且从汇编的角度也体现不出来结构体,对于汇编来说就是普通的mov指令而已。
联合体
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
union student {
int a;
short b;
long c;
char *d;
};
void arr_3() {
union student s;
s.a = 1;
s.b = 2;
s.c = 3;
s.d = "abcdefg";
}
|
反汇编结果如下:
1
2
3
4
5
6
7
8
9
10
11
|
00000000004005c6 <arr_3>:
4005c6: push %rbp
4005c7: mov %rsp,%rbp
4005ca: movl $0x1,-0x10(%rbp) # s.a = 1
4005d1: movw $0x2,-0x10(%rbp) # s.b = 2
4005d7: movq $0x3,-0x10(%rbp) # s.c = 3
4005de: 00
4005df: movq $0x4008c6,-0x10(%rbp) # s.d = "abcdefg"
4005e6: 00
4005e7: pop %rbp
4005e8: retq
|
联合体跟结构体差不多,从汇编角度看,都是普通的mov操作,也就是对于汇编来说,没有什么对象、结构体,都是往内存地址中赋值。
当然联合体和结构体还是有些不同,结构体给变量赋值的时候,是往不同的内存地址赋值;而联合体赋值的时候,每个变量的内存起始位置都是一样的。
赋值的地址都是-0x10(%rbp),所以联合体的大小,是由长度最长的那个变量决定的。
动态申请内存
代码如下:
1
2
3
4
|
void arr_1(int a) {
char *m = malloc( 200 * sizeof(char) );
printf("malloc -> %x\n",m);
}
|
反汇编结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
000000000040057d <arr_1>:
40057d: push %rbp
40057e: mov %rsp,%rbp
400581: sub $0x20,%rsp # 栈增长32个字节
400585: mov %edi,-0x14(%rbp) # 保存edi(参数a)
400588: mov $0xc8,%edi # 将200赋给edi
40058d: callq 400480 <malloc@plt> # 调用malloc函数
400592: mov %rax,-0x8(%rbp) # 动态创建的内存 -> *m
400596: mov -0x8(%rbp),%rax # *m -> rax
40059a: mov %rax,%rsi # rax -> rsi(参数2)
40059d: mov $0x400860,%edi # 字符串地址->edi(参数1)
4005a2: mov $0x0,%eax # 0 -> rax
4005a7: callq 400450 <printf@plt> # 调用printf函数
4005ac: leaveq
4005ad: retq
|
从汇编结果看,动态申请的内存,是调用了malloc申请一块内存,然后返回内存地址,它的生命周期不受栈的控制,即便arr_1函数销毁了,新申请的内存仍然在,这里由于没有手动调用free,在函数返回后,这段内存就没法被访问了,导致了内存泄露。
从使用上来看,动态申请内存只是调用一个函数而已,跟普通的指针引用、函数返回没什么区别。只是这段空间不在栈上了,使用就要更小心了。
浮点数
浮点数的计算,用的是另外一套寄存器,一共16个通用浮点寄存器。浮点数和整数之间的转换也有对应的指令,另外还有操作浮点数的运算操作指令。
16个通用浮点寄存器如下:

浮点数相关的指令,复制相关指令:
vmovss、vmossd: 传送单精度数、双精度数vmovaps、vmovapd: 传送对齐的封装好的单精度数、双精度数
浮点数转整数相关指令:
vcvttss2si、vcvttsd2si: 用截断的方式把单精度数转为整数、用截断的方式把双精度数转为整数vcvttss2siq、vcvttsd2siq: 用截断的方式把单精度数转为四字节整数、用截断的方式把双精度数转为四字节整数
整数转浮点数相关指令:
vcvtsi2ss、vcvtsi2sd: 把整数转换成单精度数、双精度数vcvtsi2ssq、vcvtsi2sdq: 把四字节整数转换成单精度数、双精度数
浮点数的运算操作指令:
vaddss、vaddsd: 浮点数加法,单精度和双精度vsubss、vsubsd: 浮点数减法,单精度和双精度vmulss、vmulsd: 浮点数乘法,单精度和双精度vdivss、vdivsd: 浮点数除法,单精度和双的精度vmaxss、vmaxsd: 浮点数最大值,单精度和双精度,D <- max(s2,s1)vminss、vminsd: 浮点数最小值,单精度和双精度sqrtss、sqrtsd: 浮点数平方根,单精度和双精度
浮点数的位运算指令:
vxorps: 位级异或,单精度vorpd: 位级异或,双精度vandps: 位级与,单精度vandpd: 位级与,双精度
比较操作:
ucomiss: 比较单精度ucomisd: 比较双精度
vunpcklps指令:%xmm0, %xmm0, %xmm0
用来交叉放置来自两个 XMM 寄存器的值,把它们存储到第三个寄存器中。(如果一个源寄存器的内容为字 [ s1, s2, s3, s4 ],另一个源寄存器为 [ d1, d2, d3, d4 ],那么目的寄存器的值会是 [ s1, d1, s0, d0 ]。
下面来看一个具体的例子,一段c程序操作浮点数:
1
2
3
4
5
6
7
|
float foo_1(int a, int b, float c, float d, double e) {
int x = (int)c;
int y = (int)d;
long z = (long)e;
float res = (float)(x + y + z);
return res;
}
|
反汇编结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
00000000004004ed <foo_1>:
4004ed: push %rbp
4004ee: mov %rsp,%rbp
4004f1: mov %edi,-0x24(%rbp) # 保存参数1
4004f4: mov %esi,-0x28(%rbp) # 保存参数2
4004f7: movss %xmm0,-0x2c(%rbp) # 保存参数3
4004fc: movss %xmm1,-0x30(%rbp) # 保存参数4
400501: movsd %xmm2,-0x38(%rbp) # 保存参数5
400506: movss -0x2c(%rbp),%xmm0
40050b: cvttss2si %xmm0,%eax # int x = (int)c
40050f: mov %eax,-0x4(%rbp) # 保存x的值到内存中
400512: movss -0x30(%rbp),%xmm0
400517: cvttss2si %xmm0,%eax # int y = (int)d
40051b: mov %eax,-0x8(%rbp) # 保存y的值到内存中
40051e: movsd -0x38(%rbp),%xmm0
400523: cvttsd2si %xmm0,%rax # long z = (long)e
400528: mov %rax,-0x10(%rbp) # 保存z的值到内存中
40052c: mov -0x8(%rbp),%eax # y -> eax
40052f: mov -0x4(%rbp),%edx # x -> edx
400532: add %edx,%eax # x+y -> eax
400534: movslq %eax,%rdx
400537: mov -0x10(%rbp),%rax # z -> rax
40053b: add %rdx,%rax # x+y+z->rax
40053e: cvtsi2ss %rax,%xmm0 # (x+y+z) -> float
400543: movss %xmm0,-0x14(%rbp) # 后面几句将xmm0 -> rax,待函数返回使用
400548: mov -0x14(%rbp),%eax
40054b: mov %eax,-0x3c(%rbp)
40054e: movss -0x3c(%rbp),%xmm0
400553: pop %rbp
400554: retq
|
首先将 5 个参数保存至内存中,内存栈地址如下:
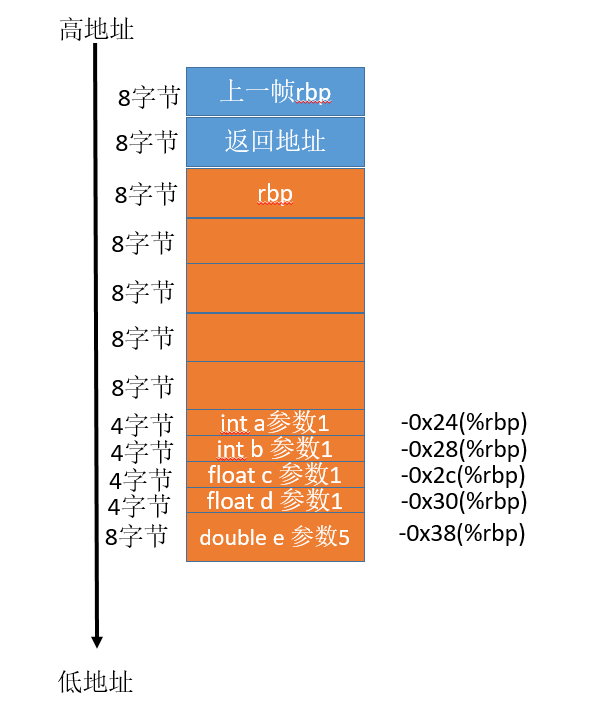
下面看下几个强制转换语句
1
2
3
|
int x = (int)c;
int y = (int)d;
long z = (long)e;
|
分析下对应的指令:
cvttss2si %xmm0,%eax,等价于int x = (int)cmov %eax,-0x4(%rbp),保存x的值到内存中movss -0x30(%rbp),%xmm0,把内存中的float d拷贝到xmm0cvttss2si %xmm0,%eax,等价于int y = (int)d mov %eax,-0x8(%rbp),保存y的值到内存中movsd -0x38(%rbp),%xmm0,把内存中double e拷贝到xmm0cvttsd2si %xmm0,%rax,等价于long z = (long)emov %rax,-0x10(%rbp),保存z的值到内存中
后面的操作是执行float res = (float)(x + y + z)这句,并将结果保存到xmm0寄存器,待函数返回使用。
mov -0x8(%rbp),%eax,y -> eaxmov -0x4(%rbp),%edx,x -> edxadd %edx,%eax,x+y -> eaxmovslq %eax,%rdx, eax -> rdxmov -0x10(%rbp),%rax,z -> raxadd %rdx,%rax,x+y+z->raxcvtsi2ss %rax,%xmm0,(x+y+z) -> floatmovss %xmm0,-0x14(%rbp),后面几句将xmm0 -> rax,待函数返回使用mov -0x14(%rbp),%eaxmov %eax,-0x3c(%rbp)movss -0x3c(%rbp),%xmm0,拷贝至xmm0
参考