2023年2月8日
CPU and Cache Efficient Management of Memory-Resident Databases
阅读全文
2023年2月5日
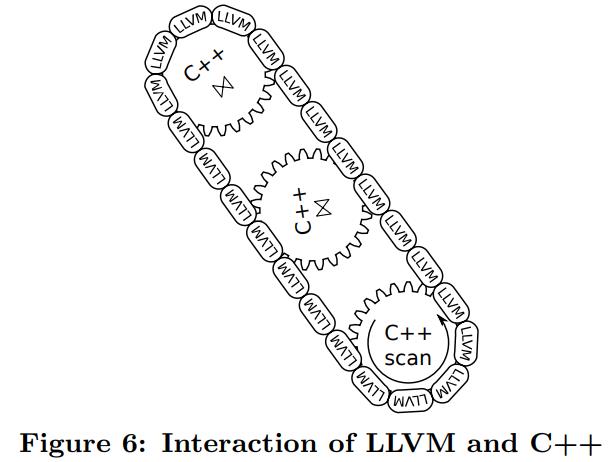
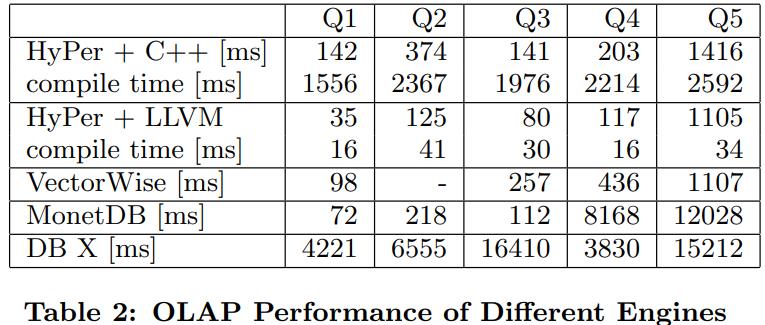
这是HyPer的一篇论文(HyPer是由德国莫尼黑大学主导的OLAP、OLTP混合型主内存数据库),介绍了code-gen的具体实现,最初HyPer的code-gen是生成了C++代码,然后使用gcc编译;但编译时间很长,再加上优化时间就更长了,甚至比查询执行时间还长;于是HyPer做了优化,改用LLVM,将code-gen的核心代码转为了LLVM的IR,这个IR是调用LLVM的API生成的,不是手写的所以相对容易一些,对于一些简单的操作是生成了LLVM,于是复杂的操作,如scan、join、sort需要将LLVM和C++混合执行,LLVM可以直接调用C++,所以不存在性能损失;通过最后执行来看,LLVM的code-gen从编译、优化时间,SQL执行时间,都比其他系统有很大提升
阅读全文
2023年2月4日
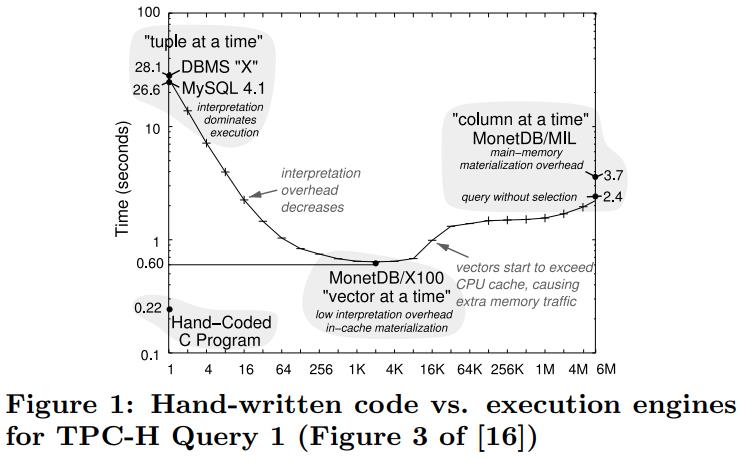
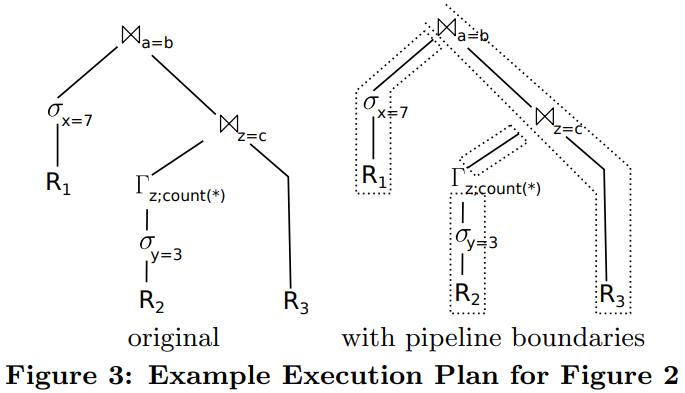
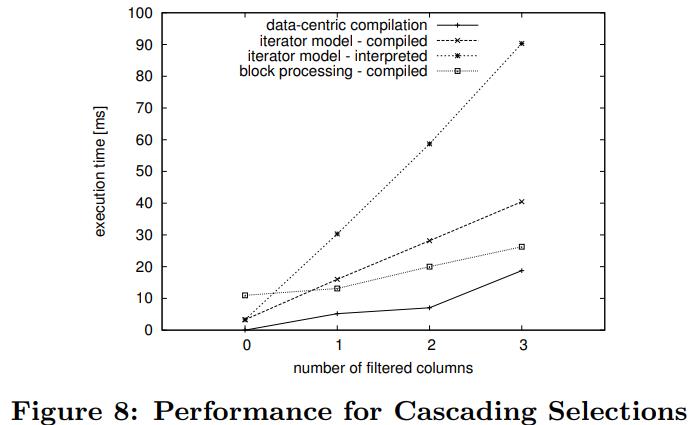
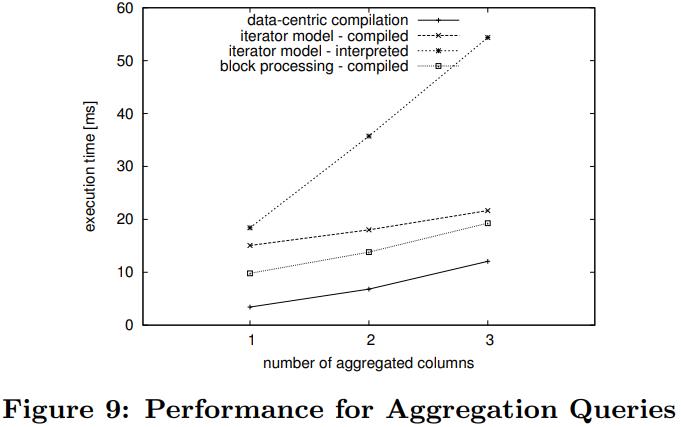
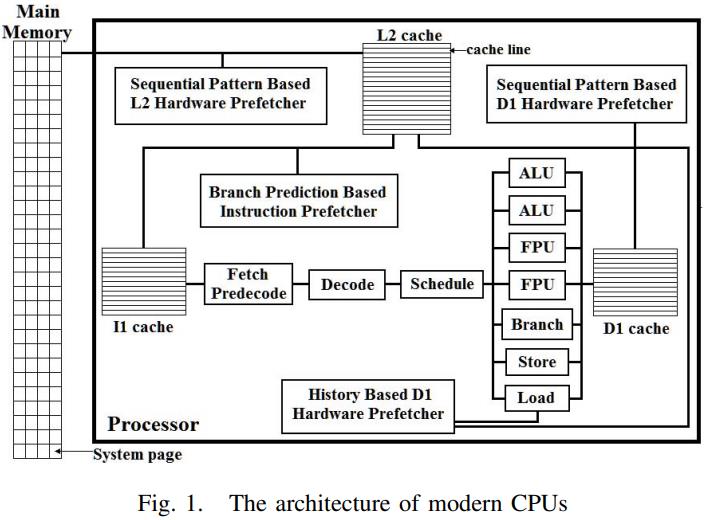
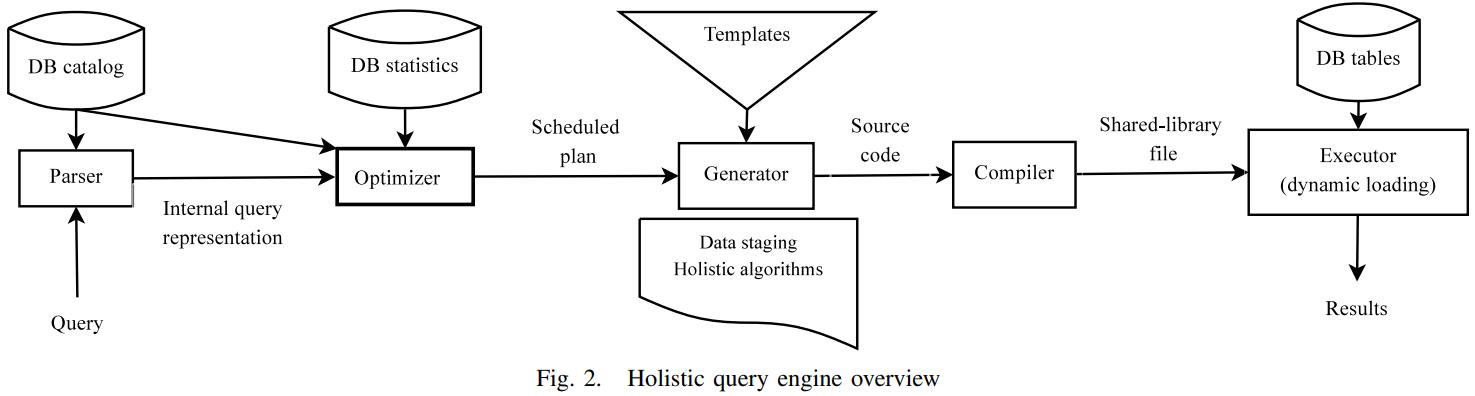
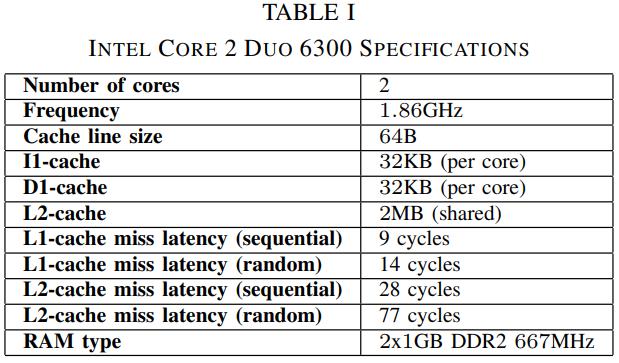
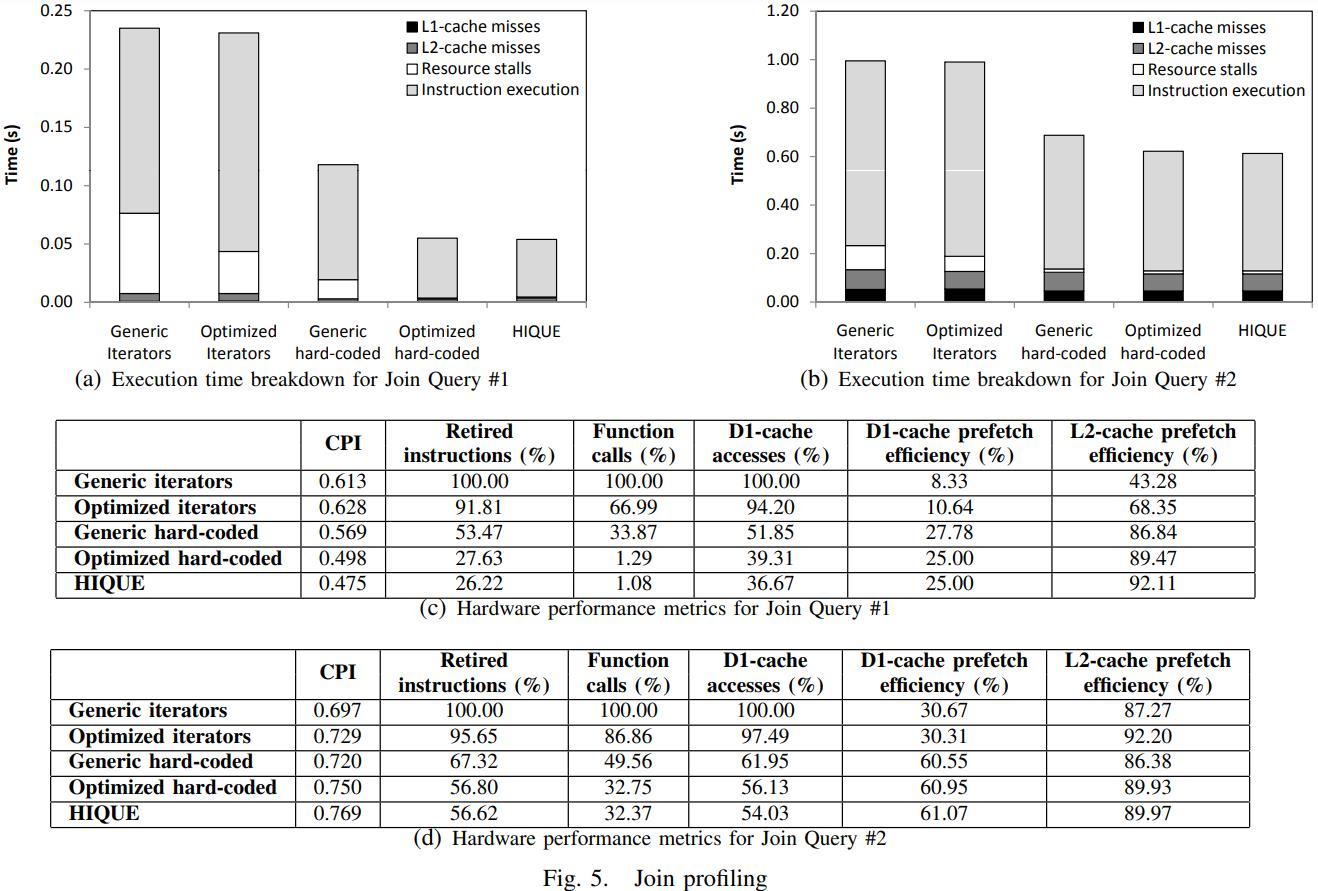
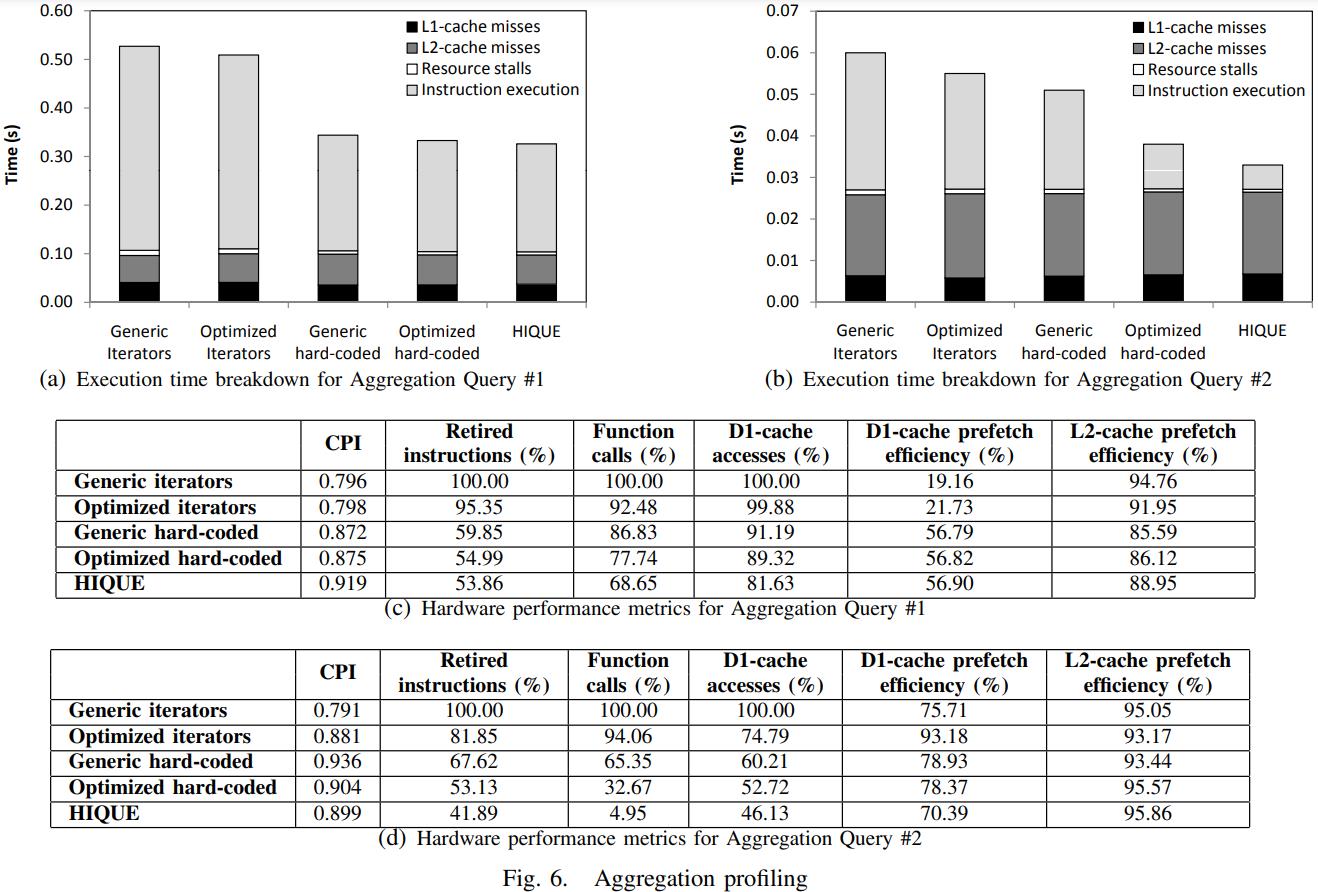
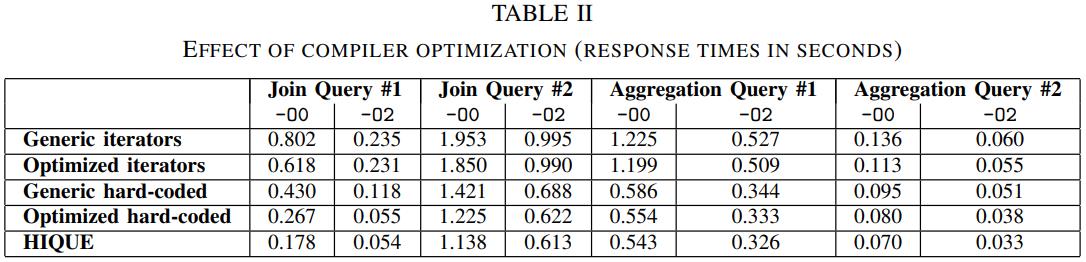
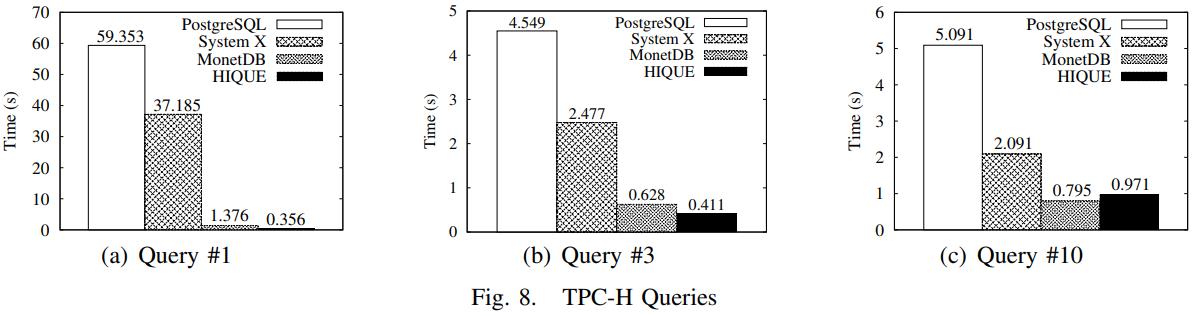
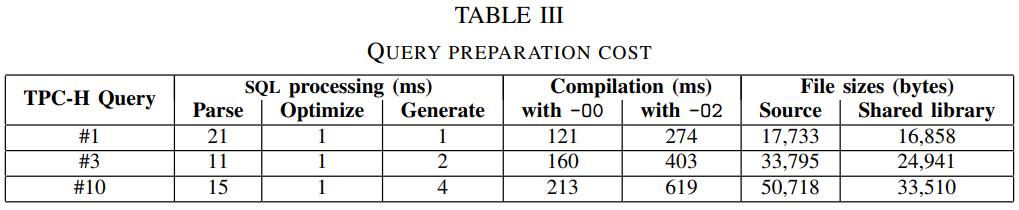
英国爱丁堡大学的一篇论文,从传统系统到现代系统的变化一个重要点是:内存增大很多,以前的I/O瓶颈对于现在来说不那么重要了,反而是CPU和内存瓶颈;而之前的火山模型对于CPU利用率来说很不好,大量的虚函数调用,多层级的函数调用增加了cache miss,也会产生更多的指令,不利于并行化和cache局部性;这篇论文提出了一个代码模板,通过识别不同的查询计划算子,来对应的生成不同的代码(对应一个大函数),不同函数之间通过物化来连接,之后通过编译器GCC来编译这段C代码,还可以对代码最O2级别优化(但会增加运行期执行时间)来达到更好的效果,论文对比了join、sort、聚合,虽然使用的是NSM存储模型,但是执行效果来看跟MonetDB的DSM差不多了;代码生成的缺点是对于小查询会有额外的开销(编译、优化、link时间)
阅读全文