2023年1月13日
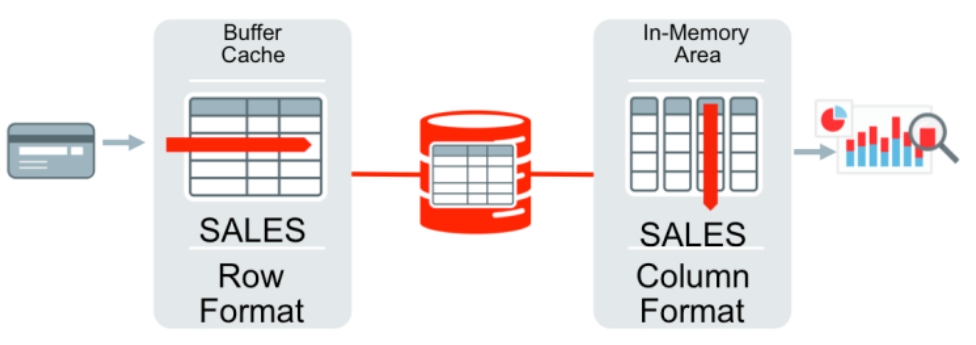
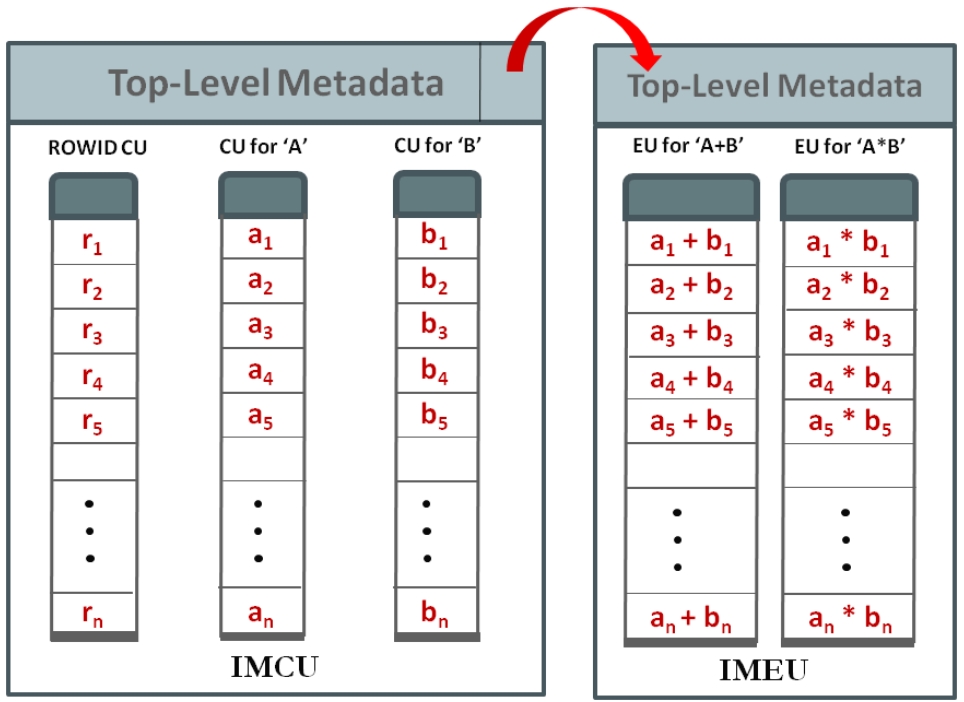
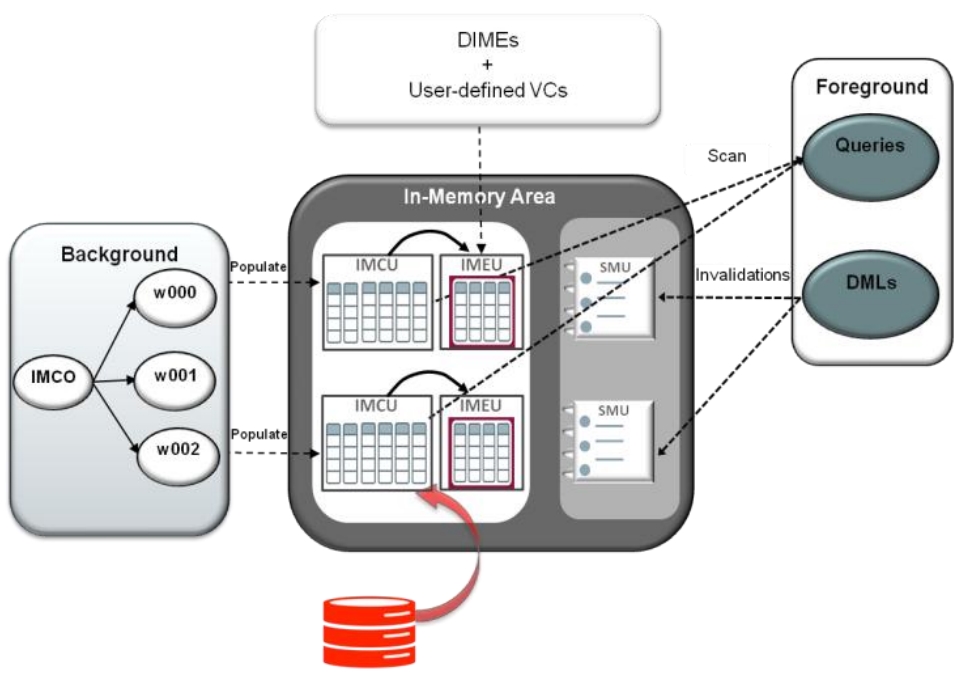
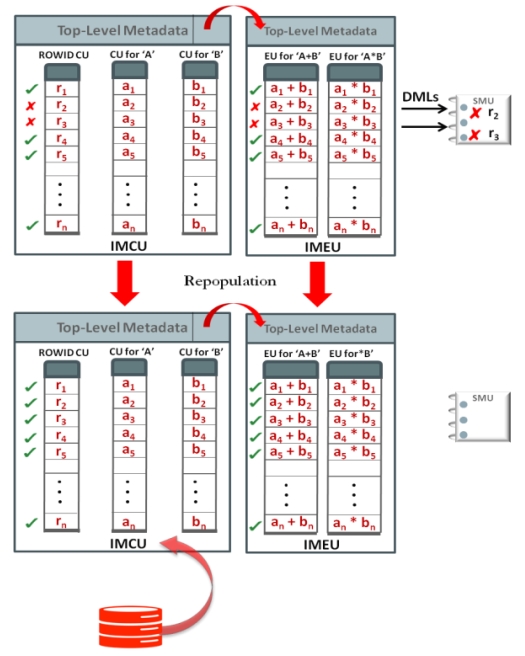
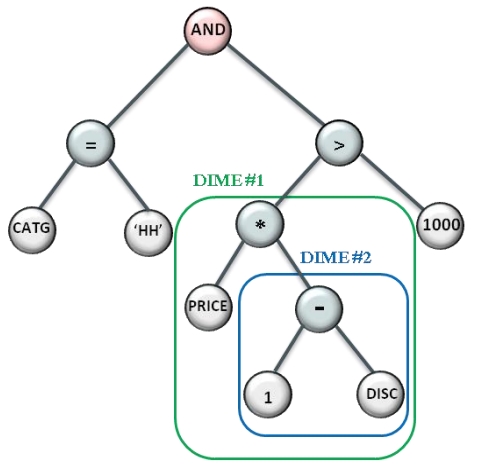
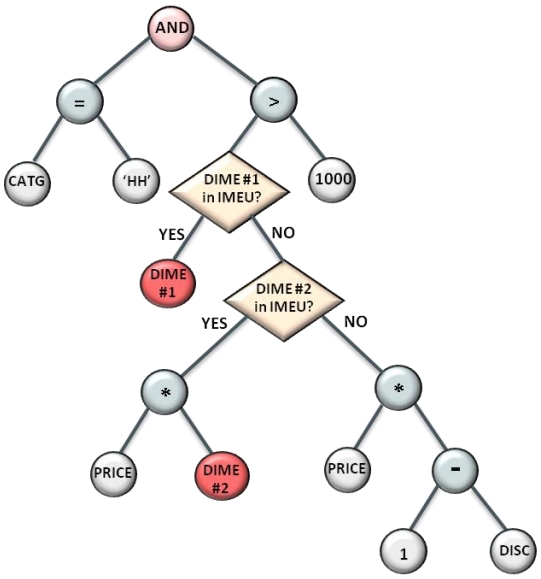
Oracle12推出了混合行/列的存储格式,磁盘(buffer pool)中按列存储,内存中按列存储加速OLAP场景;而表达式求值在很多场景下是黑盒,不易监控、也占用资源,Oracle捕获了频繁使用的表达式,将表达式物化到内存中,然后在查询计划中,根据代价来改变查询计划,将原始的查询计划的子树,替换为内存中的物化表达式,在OLAP场景中大幅度提升性能,在混合OLTP场景中也非常有效
阅读全文
2023年1月7日
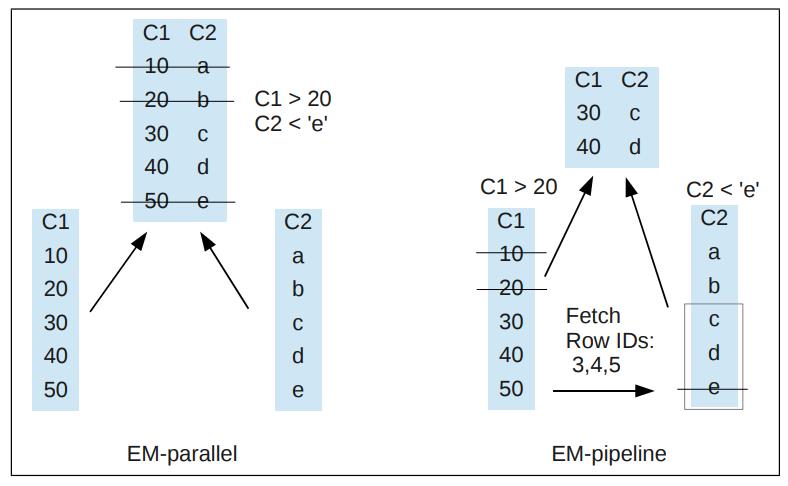
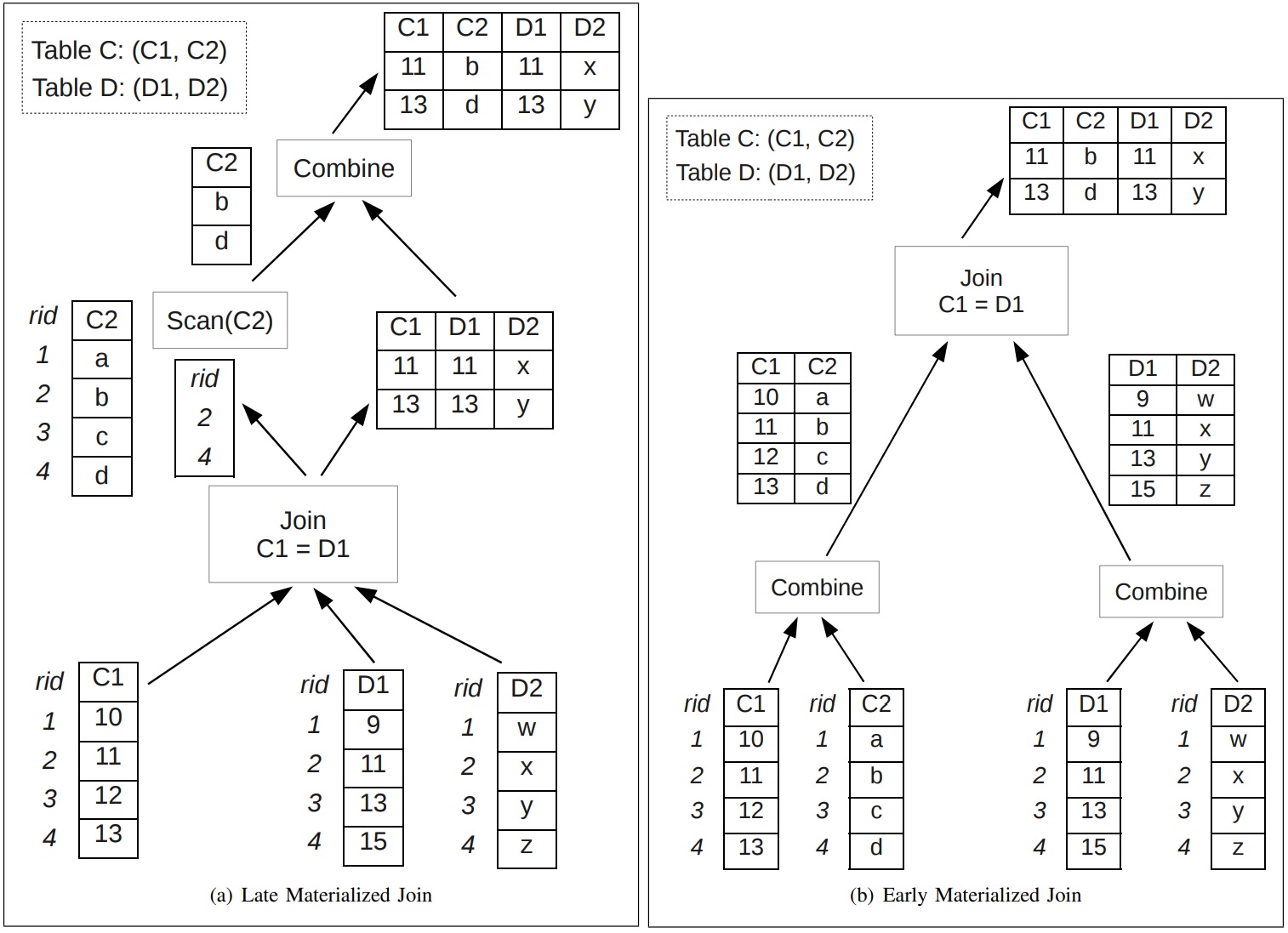
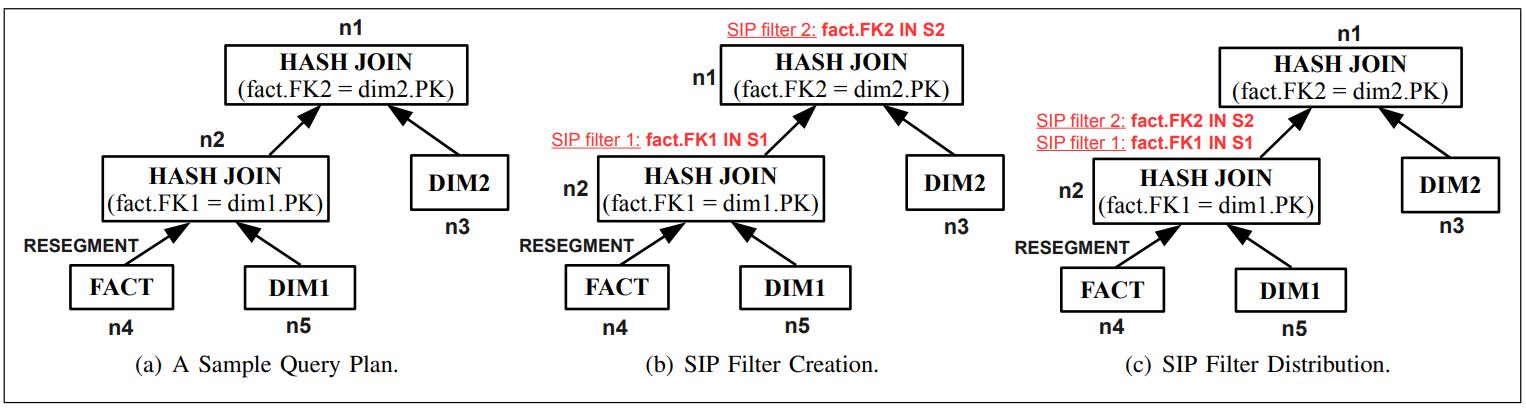
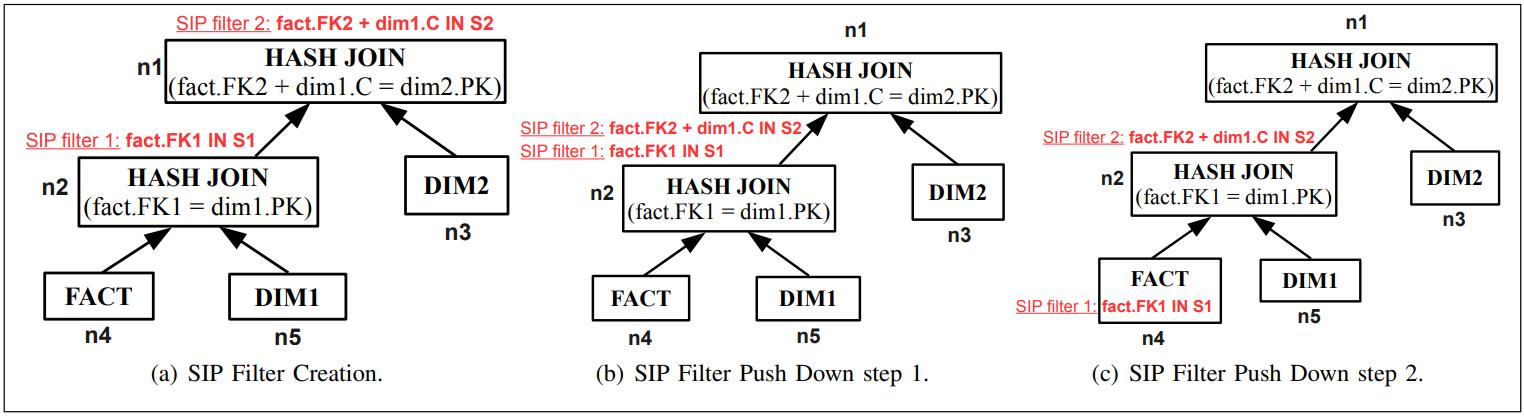
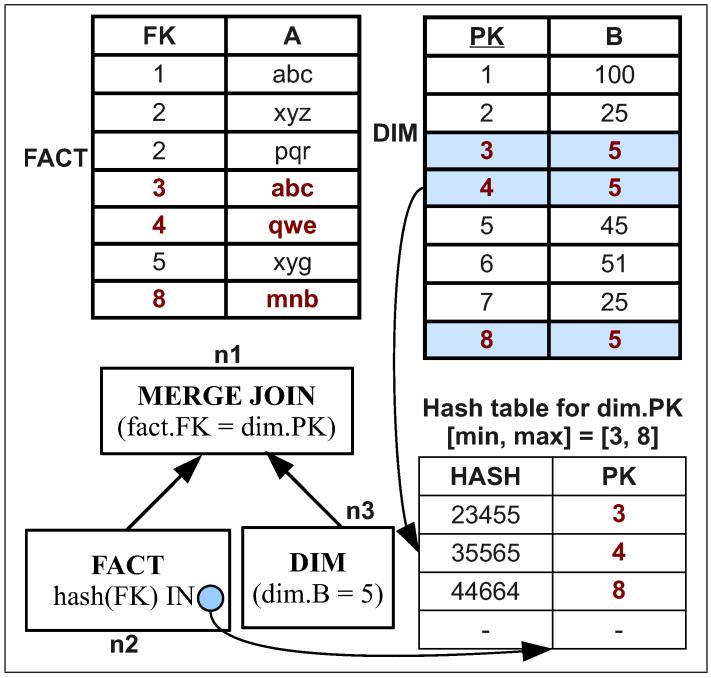
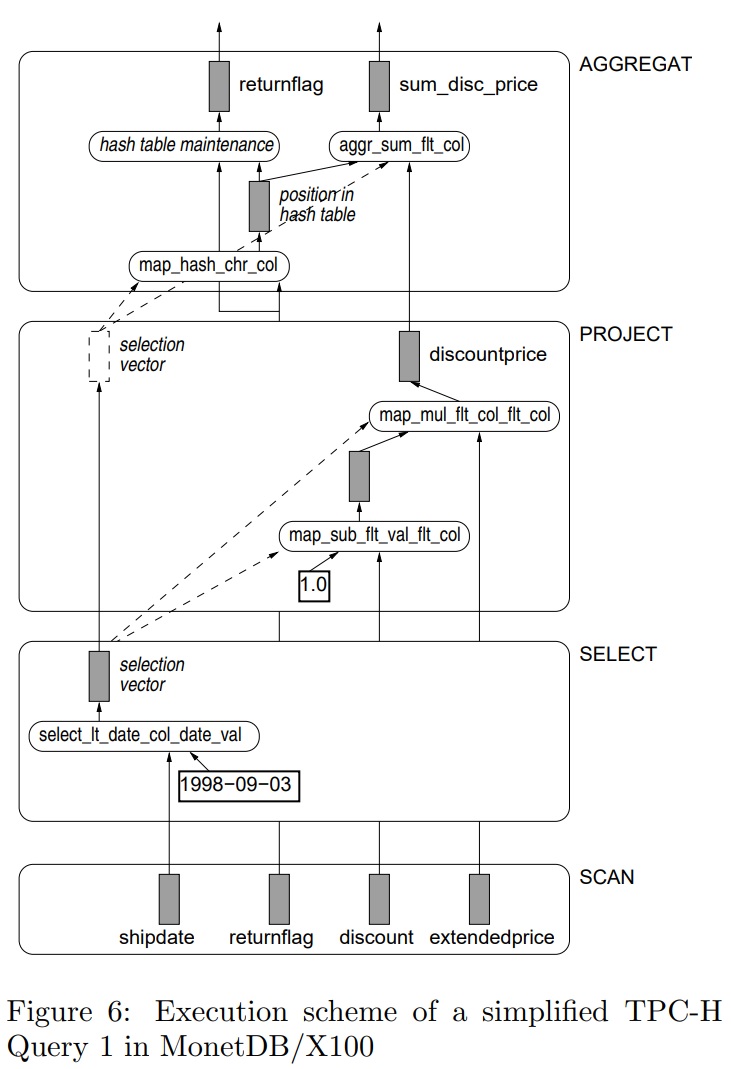
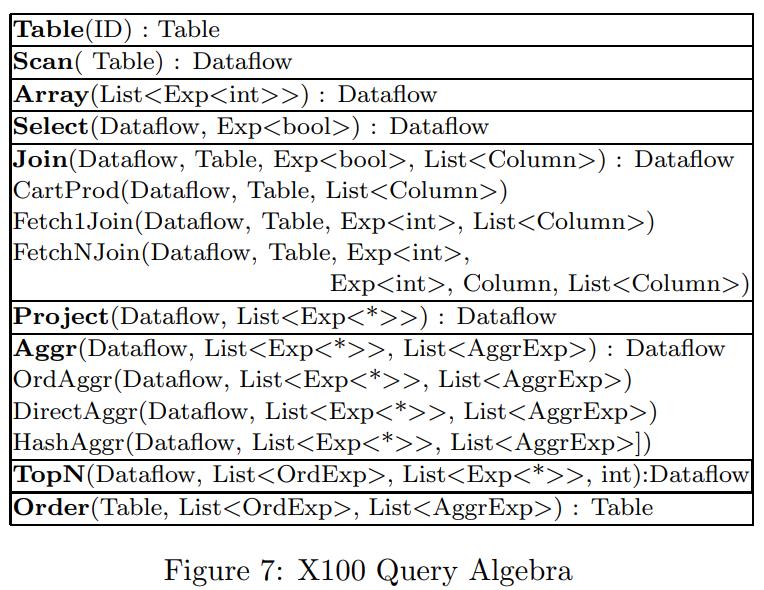
列存数据库会通过物化的方式来重建tuple,包括早期物化EM、延迟物化LM,延迟物化的性能更好,但实现更难,当出现join溢出时会出现,此时会退回到早期物化;论文在早期物化基础上增加了:边信息传递SIP技术,并给出了实现细节,如何创建SIP,如何做push down;使用EM+SIP技术,比原始的EM性能大幅度提升,并且在很多场景下比延迟物化LM性能更好
阅读全文
2023年1月5日
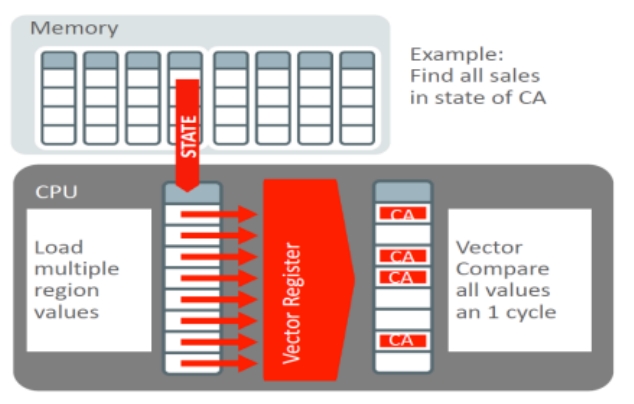
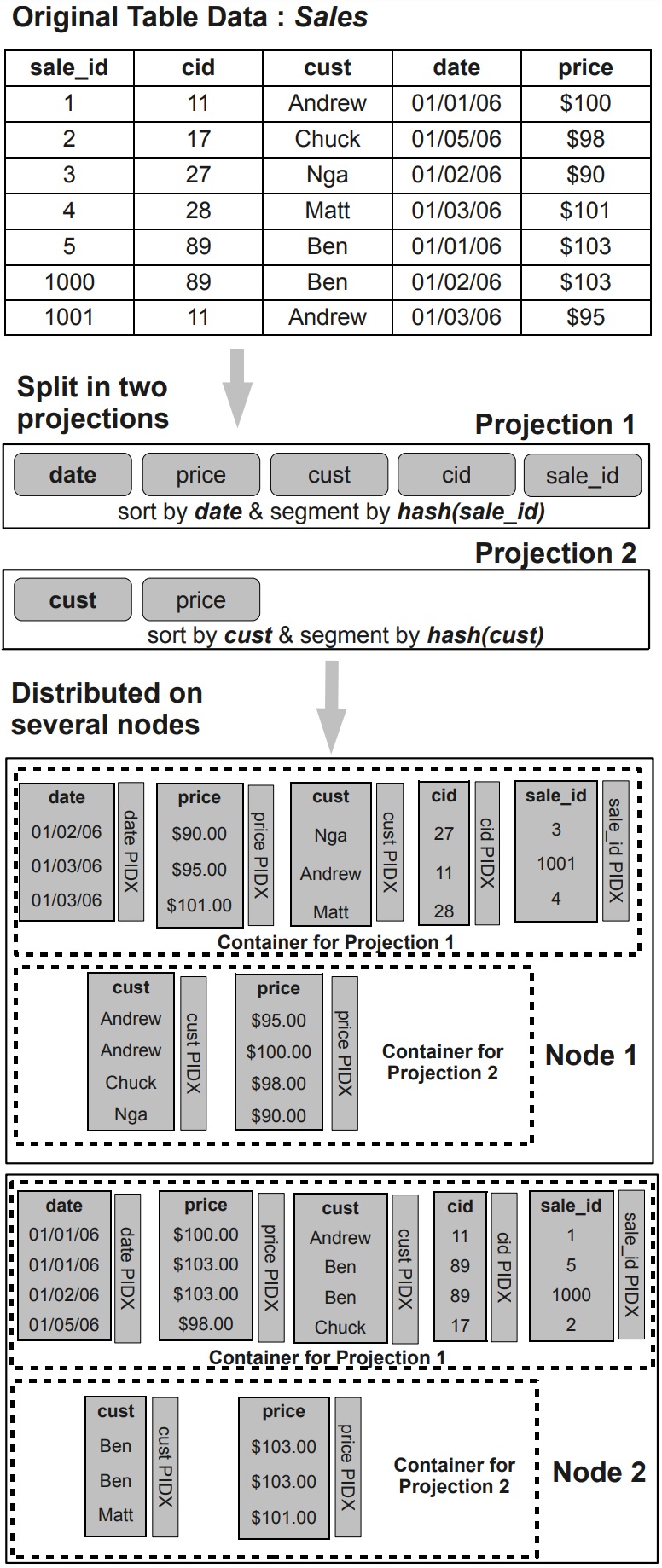
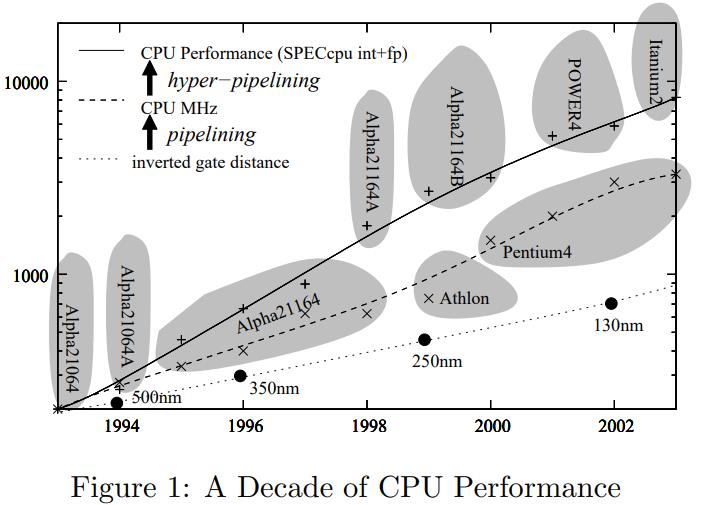
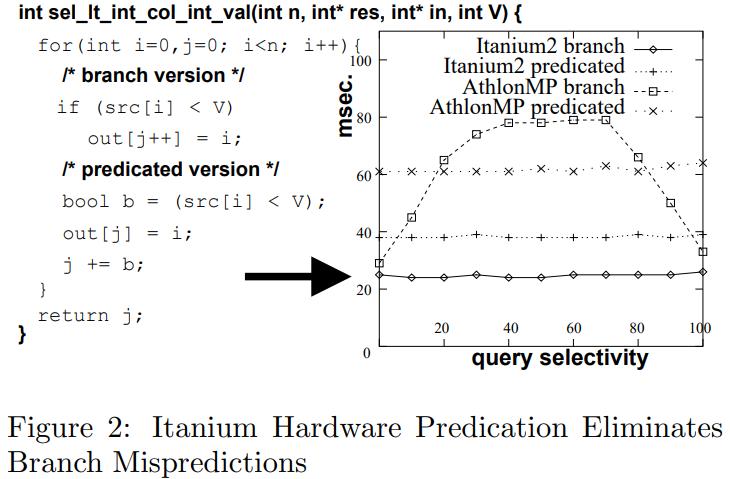
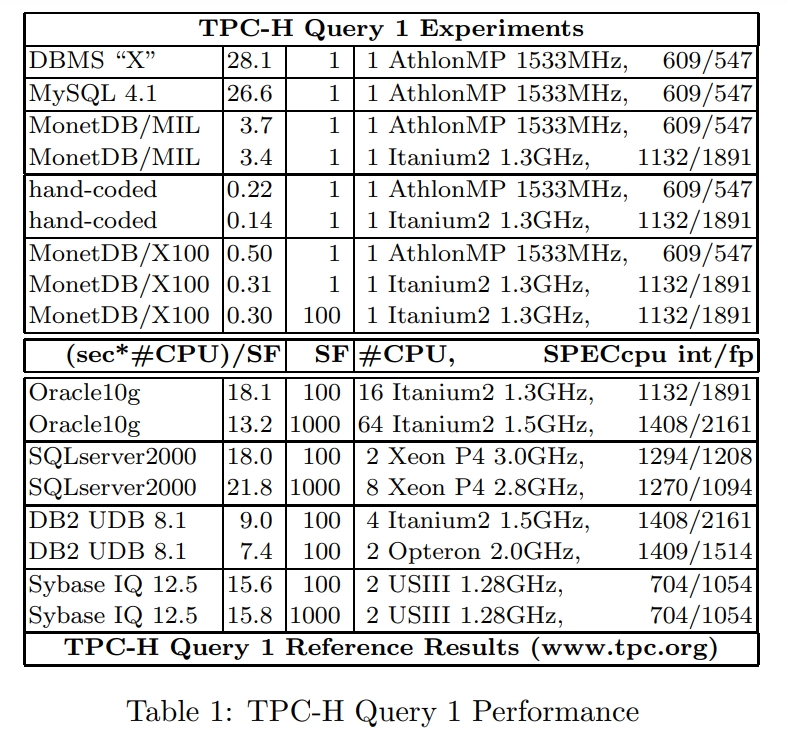
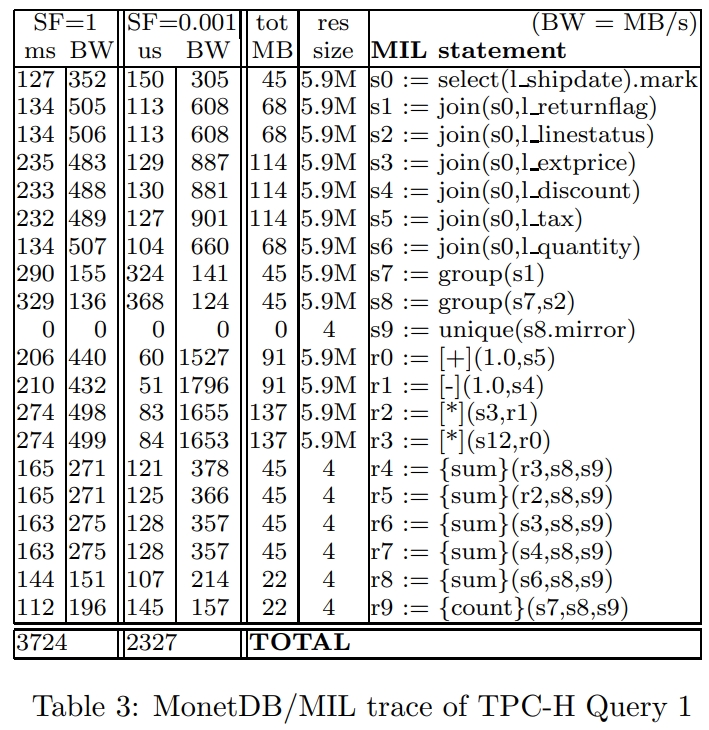
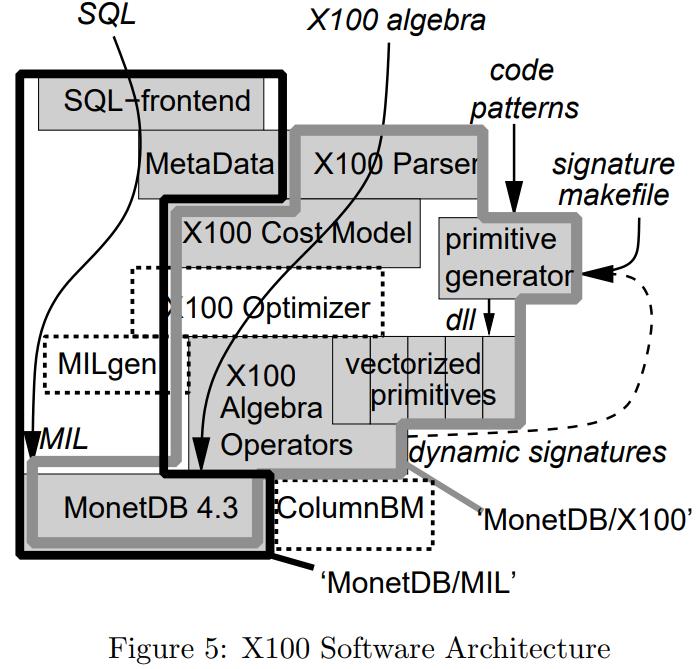
2005年的一篇论文,通过分析MySQL、MonetDB发现这两种没有达到硬件上的预期效果,MySQL是因为经典的火山模型导致编译器没法利用循环流水线,出现大量CPU等待;而MonetDB避免了上述情况但使用了物化,又导致大量的内存带宽拷贝;这篇论文结合了这两者的特点,选择了向量化的执行方式,并配合了合适的cache size,使得执行效率大幅度提升
阅读全文
2023年1月3日
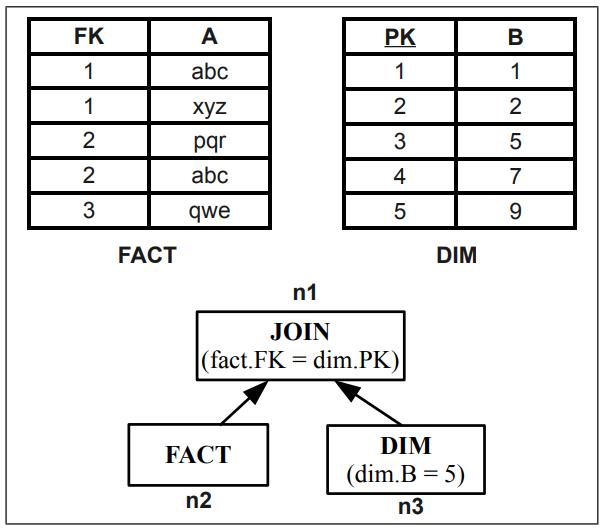
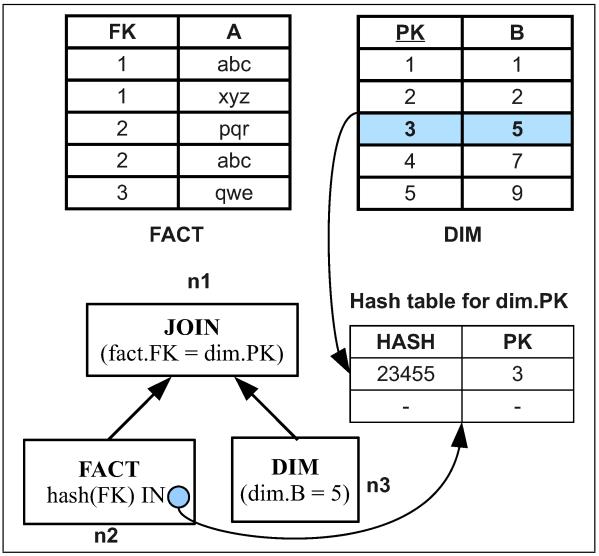
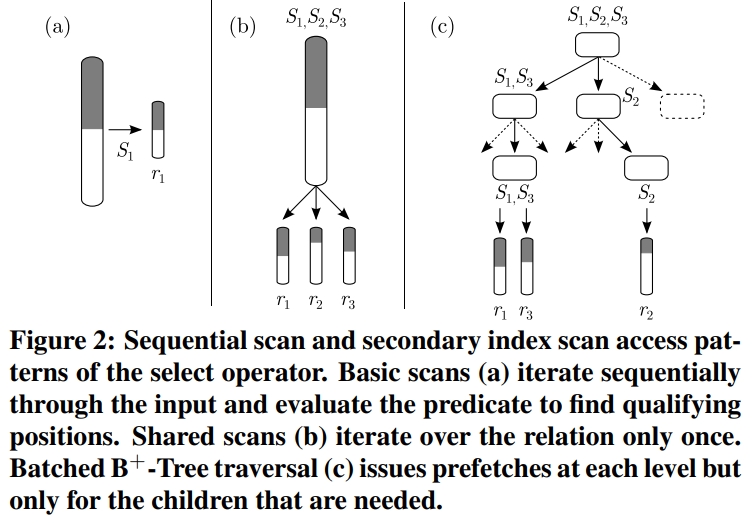
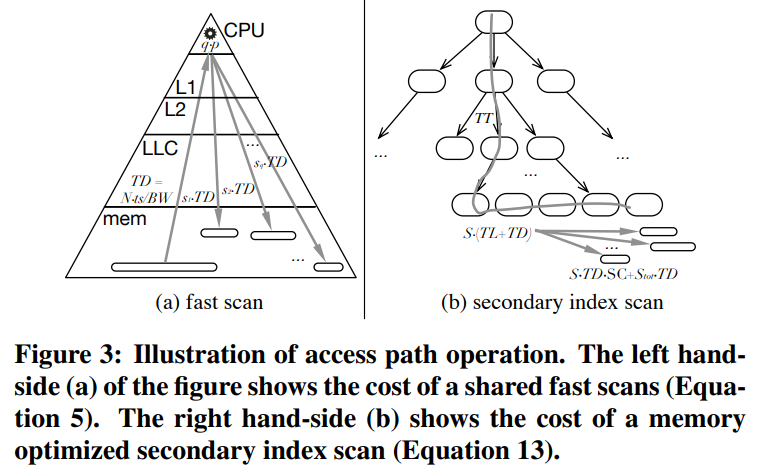
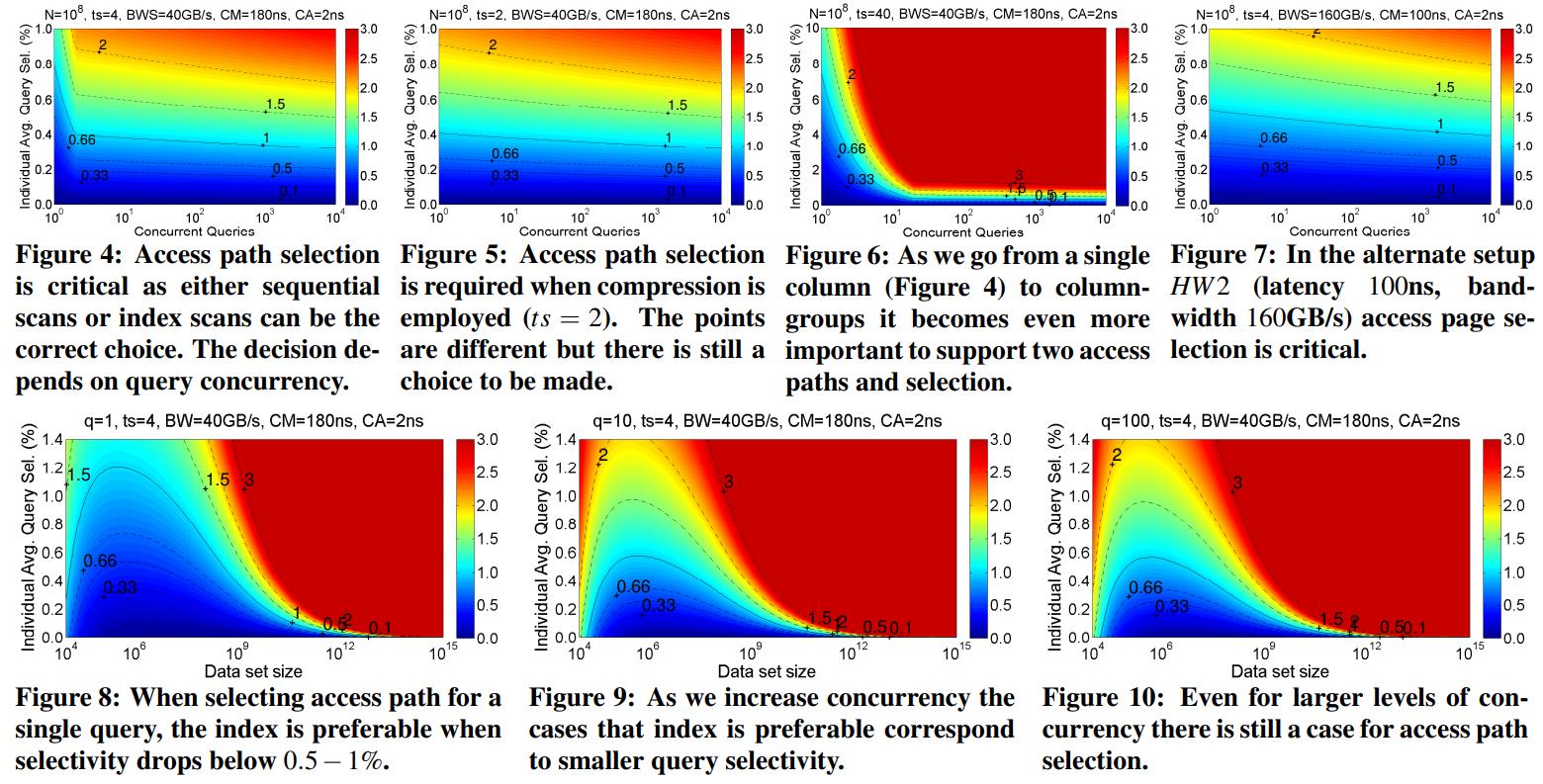
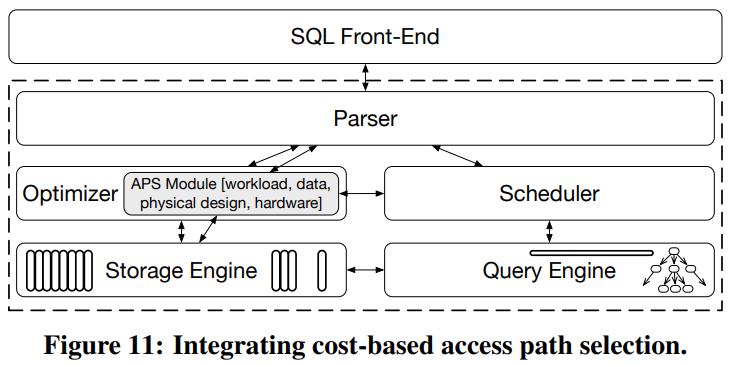
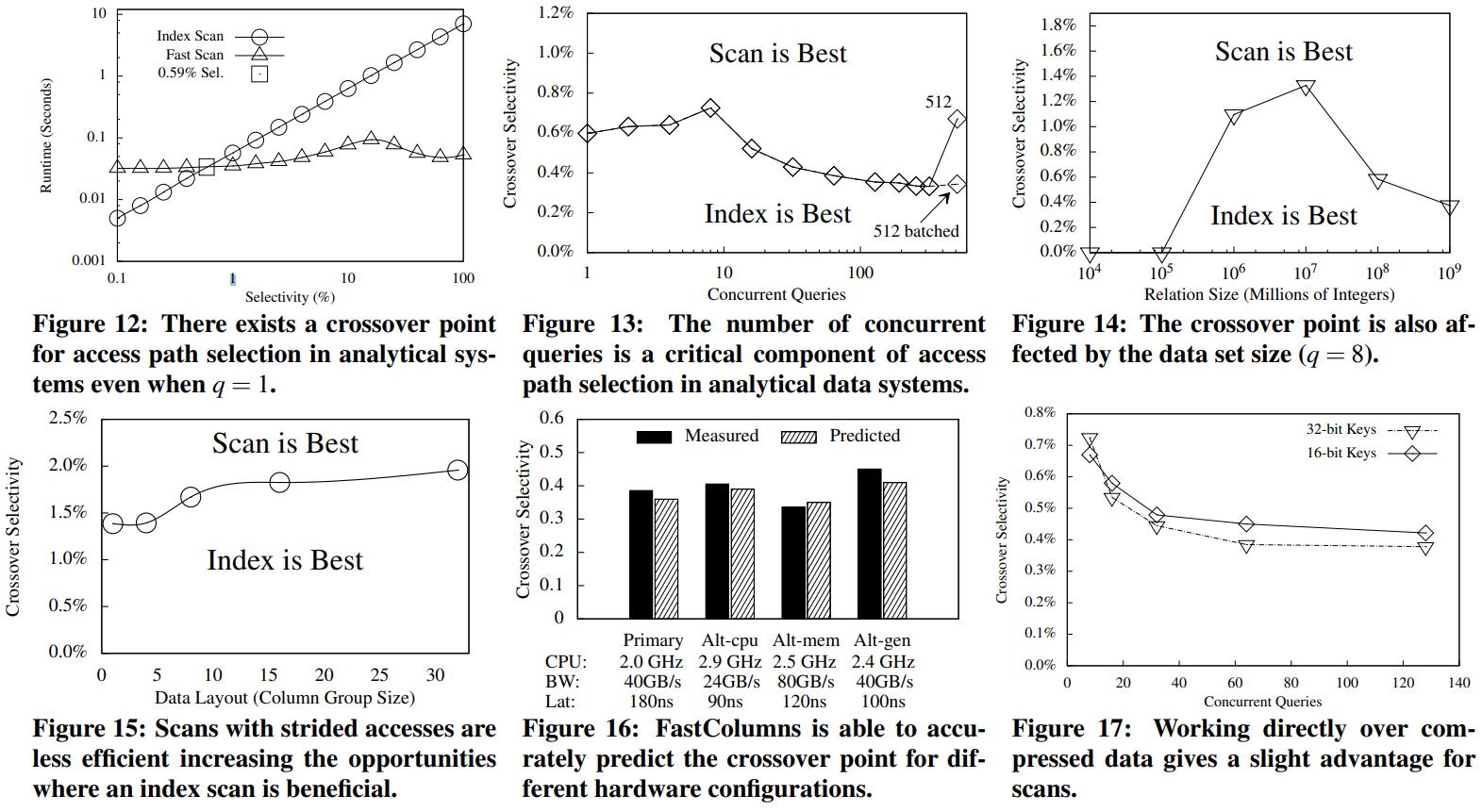
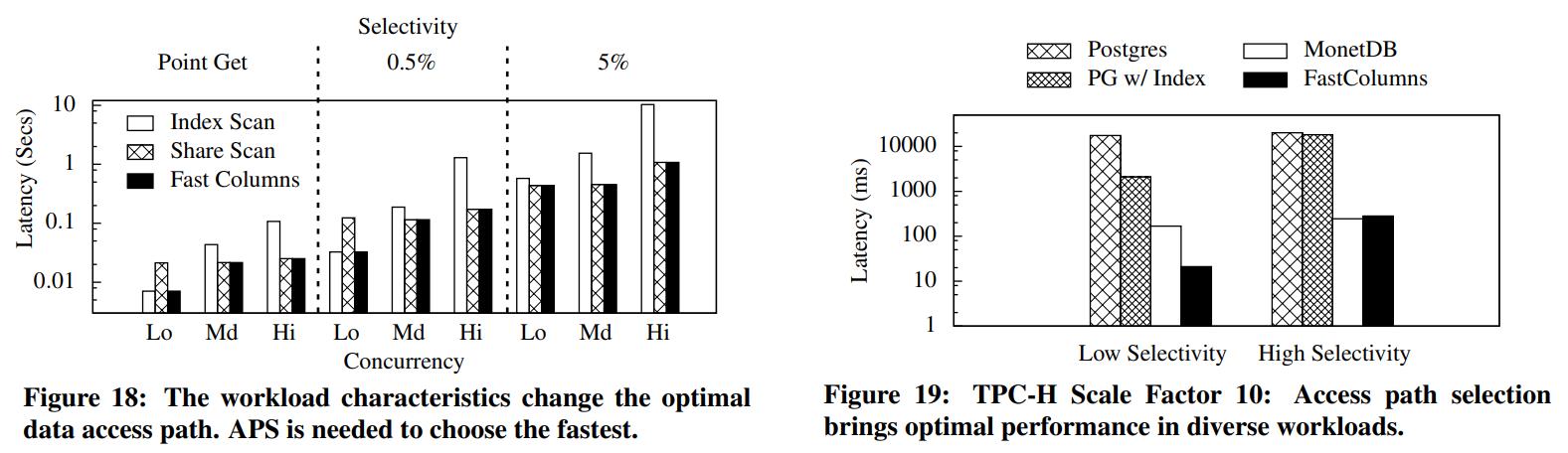
CMU Query Execution & Processing课程的一篇论文,现代分析系统中scan越来越重要,但二级索引依然有用,通过对比硬件参数、数据布局、压缩、并发等综合情况考虑之下,来选择:scan执行 或者index执行;通过性能评估发现,调节scan或者index并不是一个固定的值,而是根据不同的参数以及硬件情况,会动态变化的
阅读全文