2025年8月29日
把Spark和Flink在计算模型和运维方式上的差异放到一起看,重点包括:
- 先看 Spark 处理流 与 Flink 处理批 的天然短板,理解为什么 Spark 更偏微批、Flink 更偏实时,而不是简单说谁“全能”
- 重点拆 Shuffle、checkpoint、反压、内存模型、代码生成 这些底层机制,解释两者性能差异为什么会落到 I/O、CPU 和延迟上
- 再把 spark-submit、Thrift Server、Spark Operator、Livy 与 flink run、Flink Kubernetes Operator、REST API、SQL Client、Application Mode 摆在一起比较
- 最后落到实用选择:如果目标是 批处理吞吐、流式低延迟、K8s 原生部署、CI/CD 自动化、SQL 接入,Spark 和 Flink 分别更适合什么场景
阅读全文
2025年4月13日
把 OpenLDAP 最常见的学习入口整理到一起,重点包括:
- 先从 OpenLDAP 的主要模块 入手,理解
slapd、lloadd、协议库以及周边工程分别负责什么
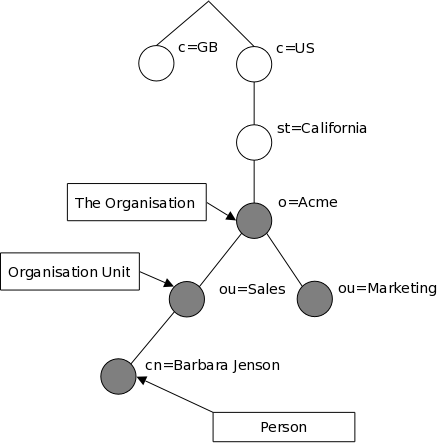
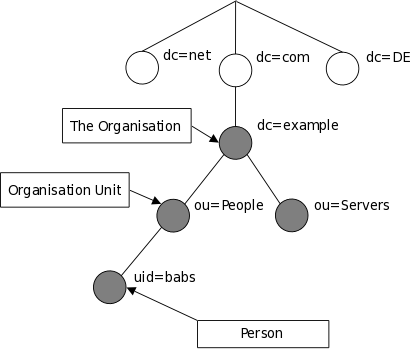
- 再结合 目录树结构 和 按 DNS 分层的组织方式,建立对 LDAP 数据组织模型的直觉
- 命令部分集中整理 ldapadd、ldapmodify、ldapdelete、ldapsearch、ldappasswd、ldapwhoami 等常用工具,方便日常查询和维护
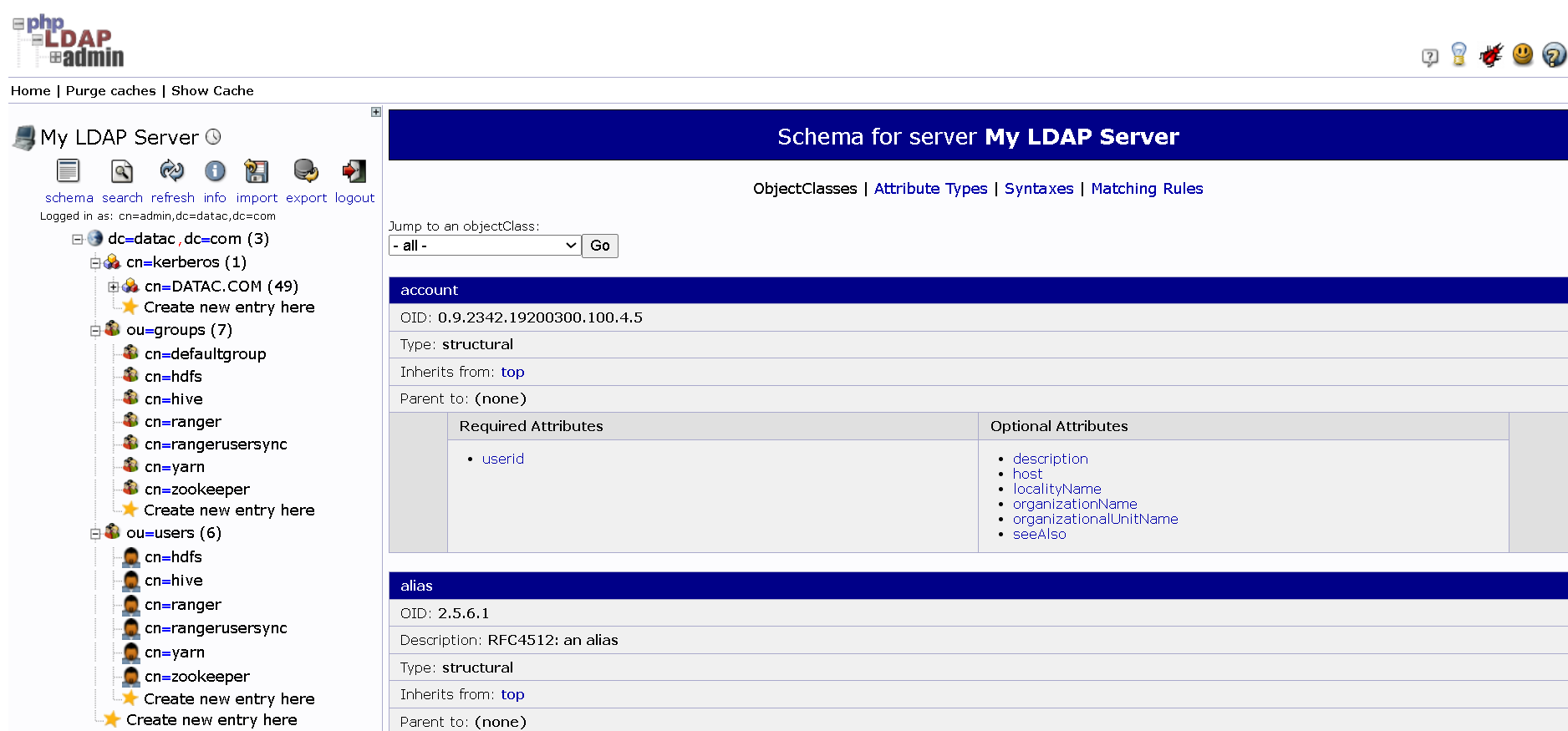
- 后面补上 配置文件、Web 控制台和官方文档入口,让这篇既能做入门笔记,也能当成后续排障和查配置时的索引
阅读全文
2024年10月23日
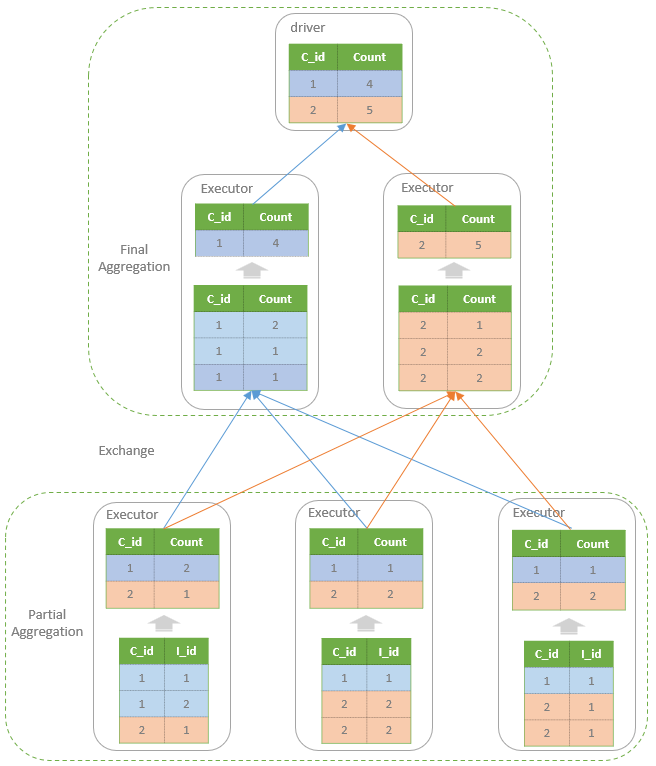
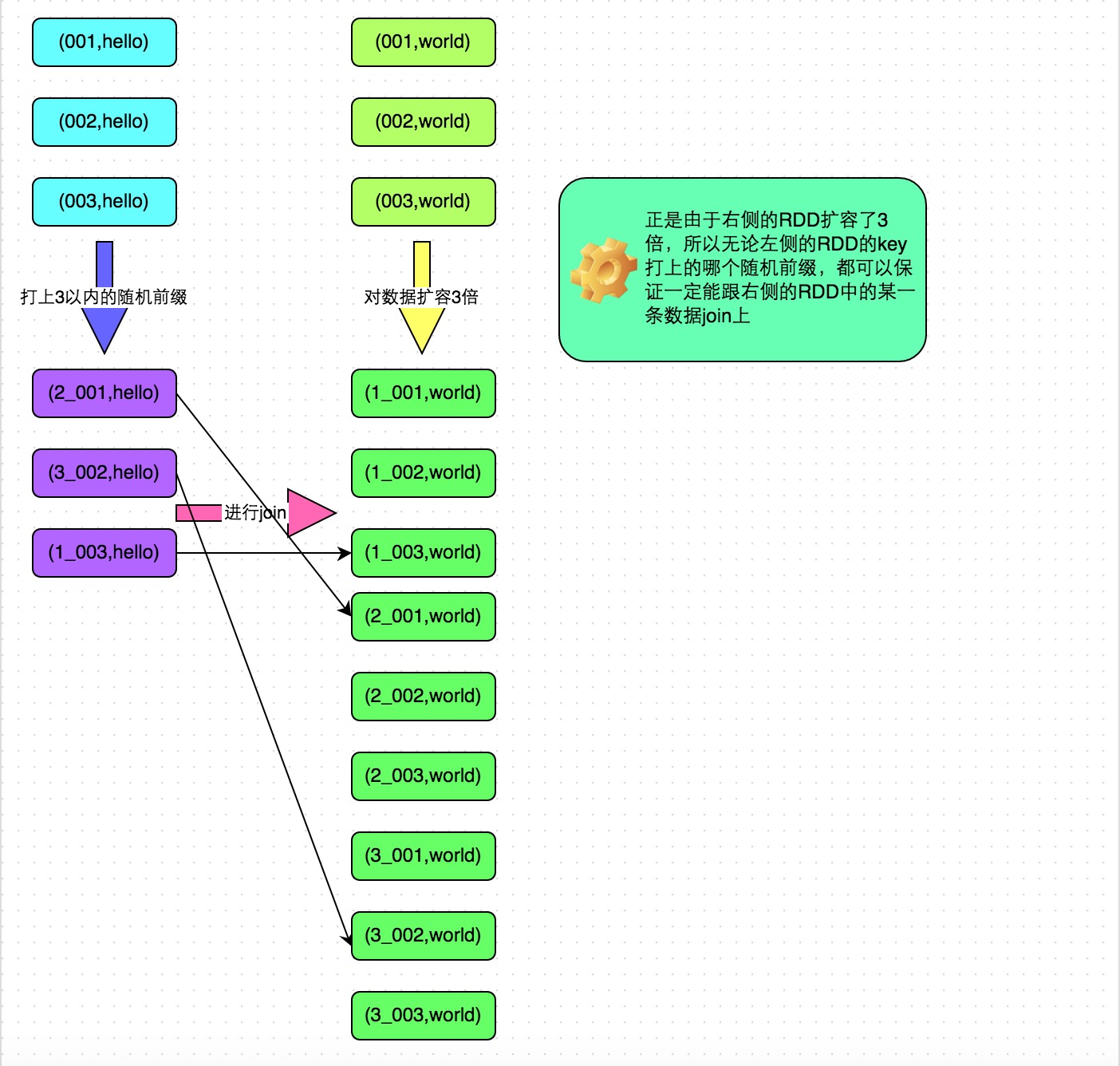
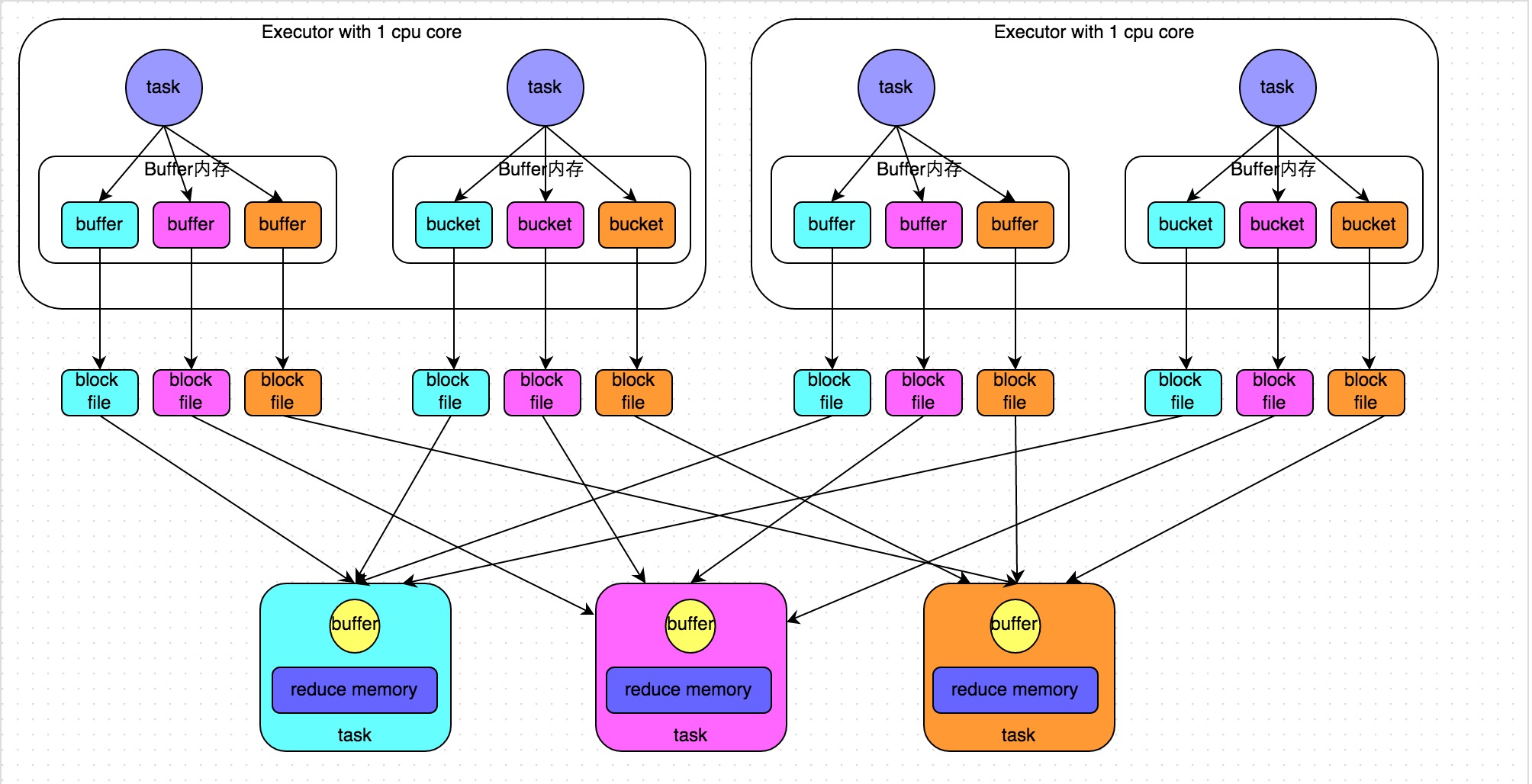
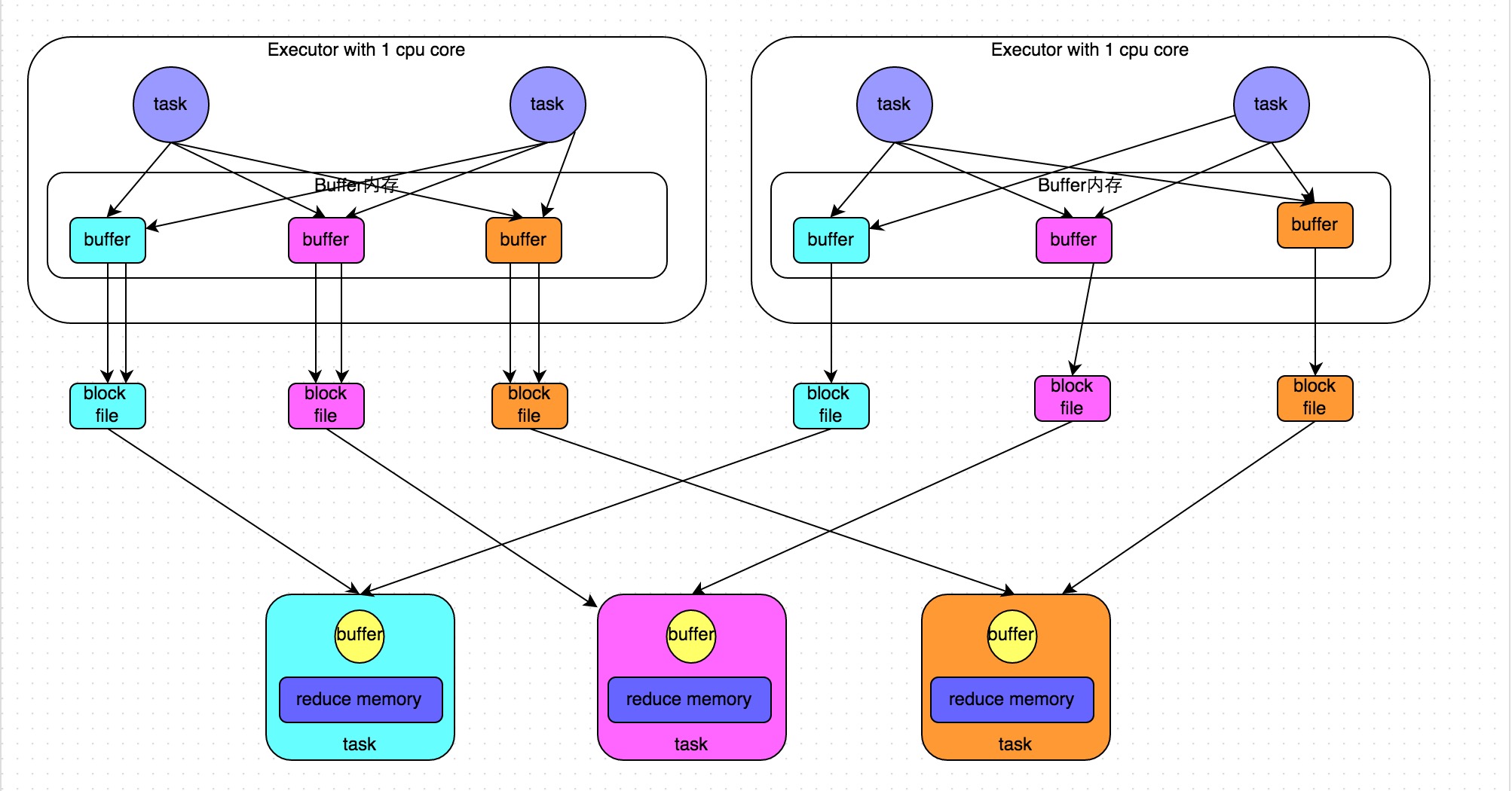
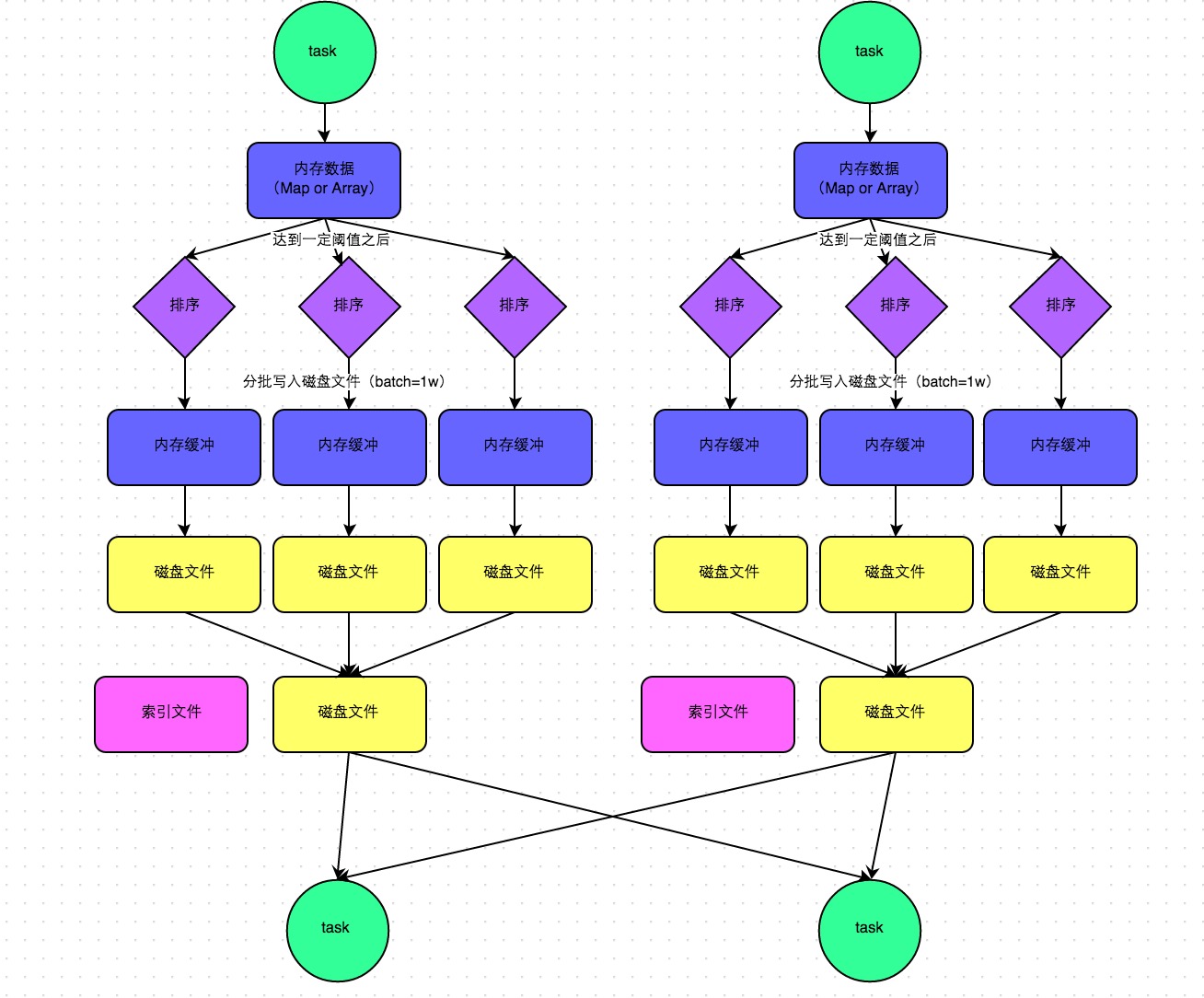
web-ui观察 executor指标:失败,shuffle,cache,CPU,内存,RDD数量,GC;stage关注 DAG,也是shuffle等数据,还有 Event Timeline。shuffle优化方式:增加并行度,group by变成局部聚合+全局聚合;转为 BHJ,大表 join 大表的 外表加盐,内表复制N份,再去盐gourp原始id,最后聚合;shuffle原理,HashShuffleManager(废除),SortShuffleManager。 with 缓存优化,查询下推,自动倾斜join优化,LIMIT大数量优化,bucked join,4表join转为2个2个join增加并行度。RSS,向量化, AQE
阅读全文
2024年10月22日
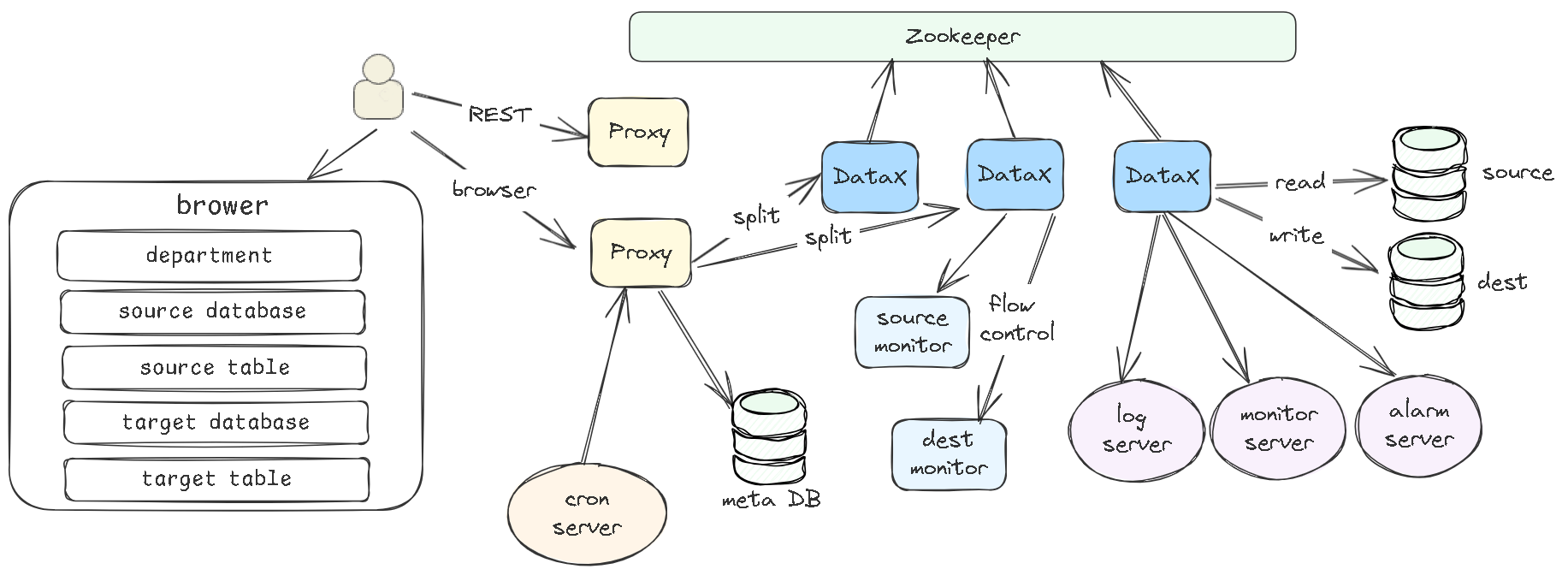
DataX:读写插件,Job任务拆分,Task和Task Group,transform(filter,substr,replace,可自定义),流控,脏数据,数据库冥等写入,ETL架构。Canal:Server(服务端-客户端模式,嵌入式模式),多个instance,包括:eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)、eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)、eventStore (数据存储)、metaManager (增量订阅&消费信息管理器)
阅读全文
2024年10月18日
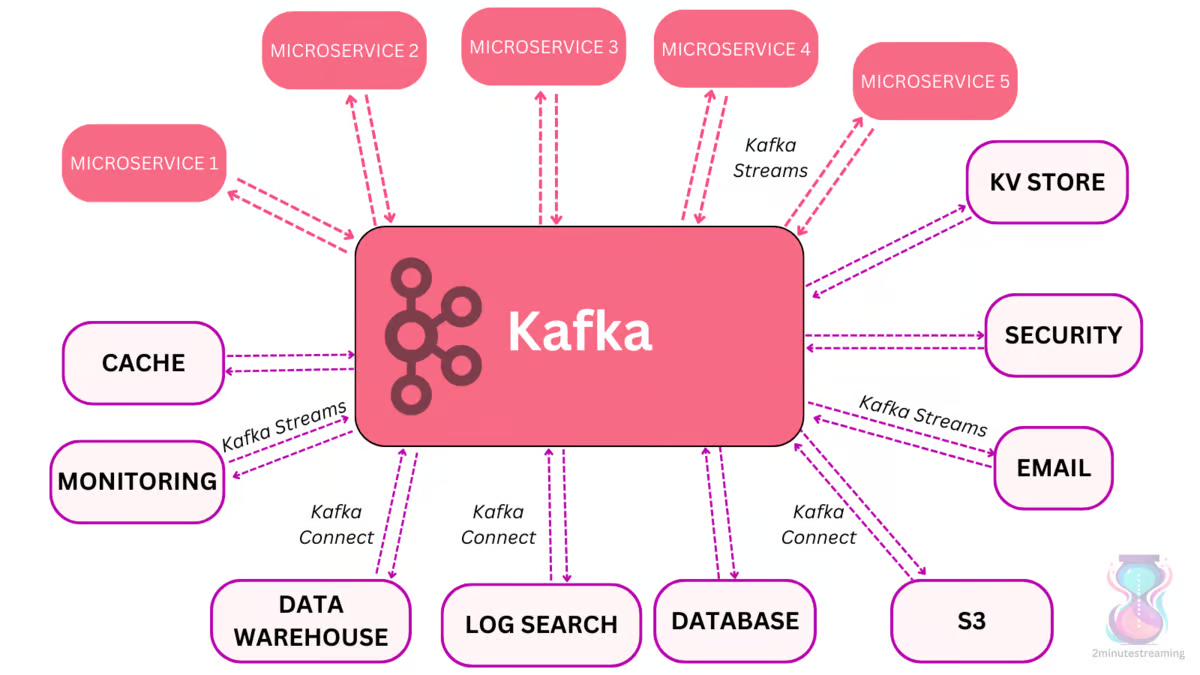
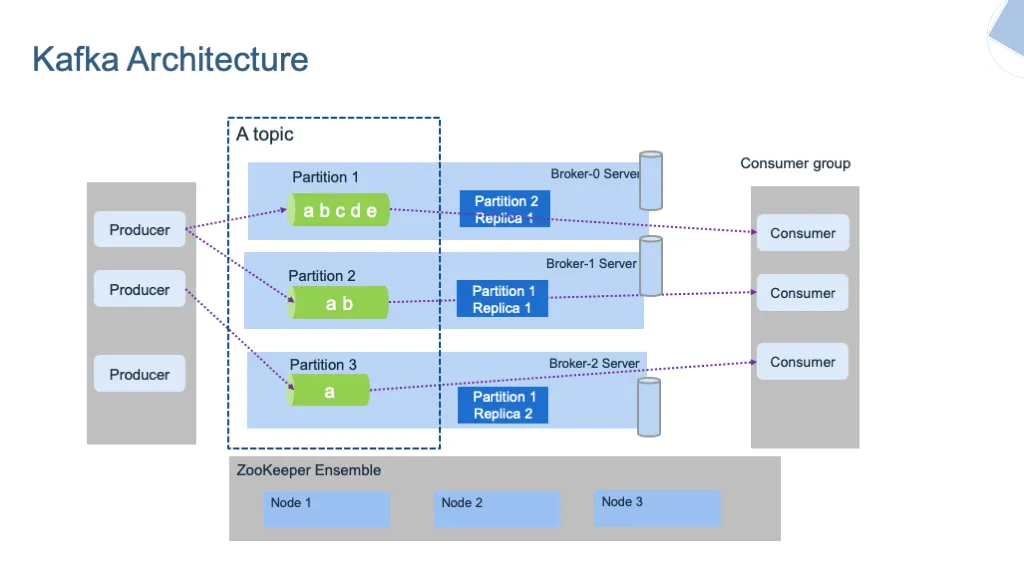
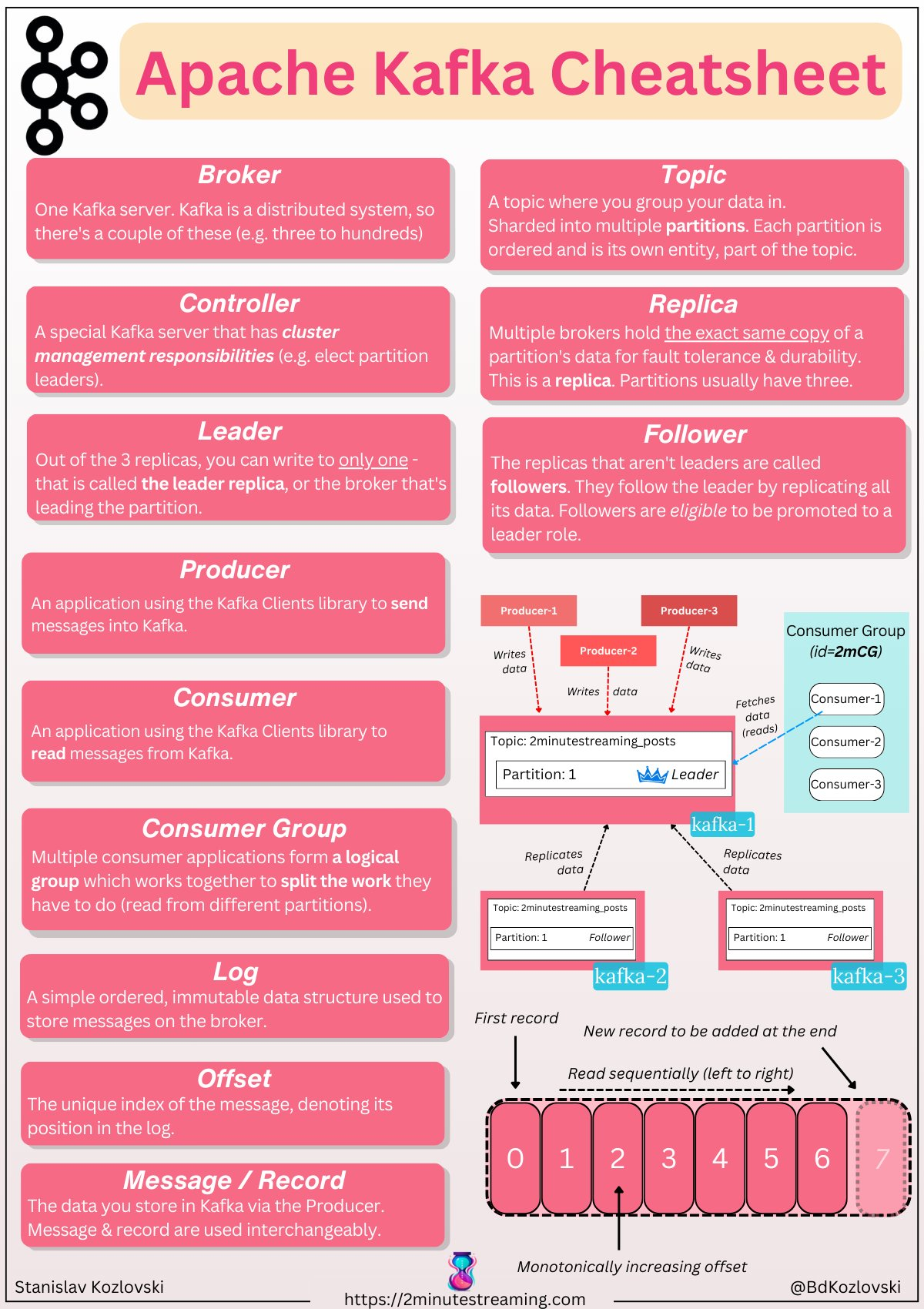
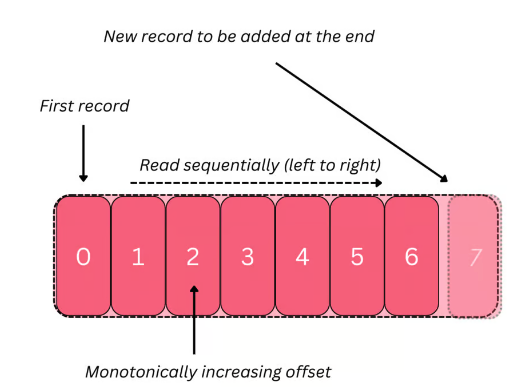
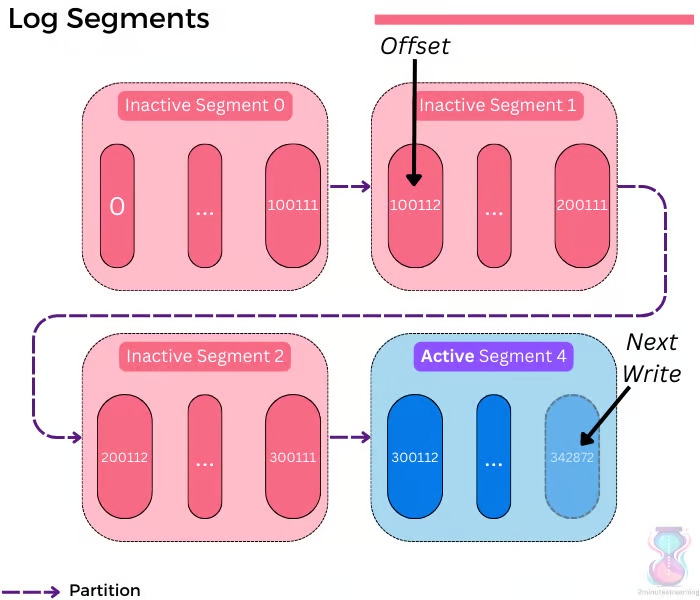
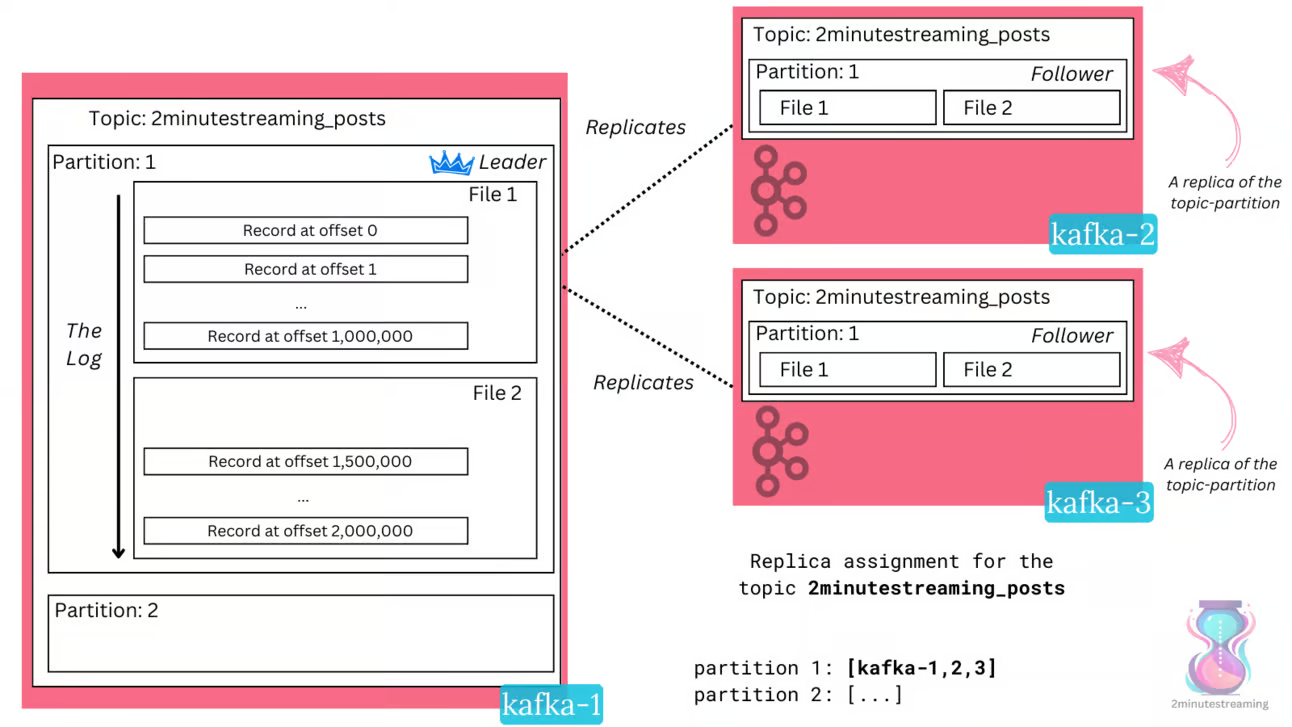
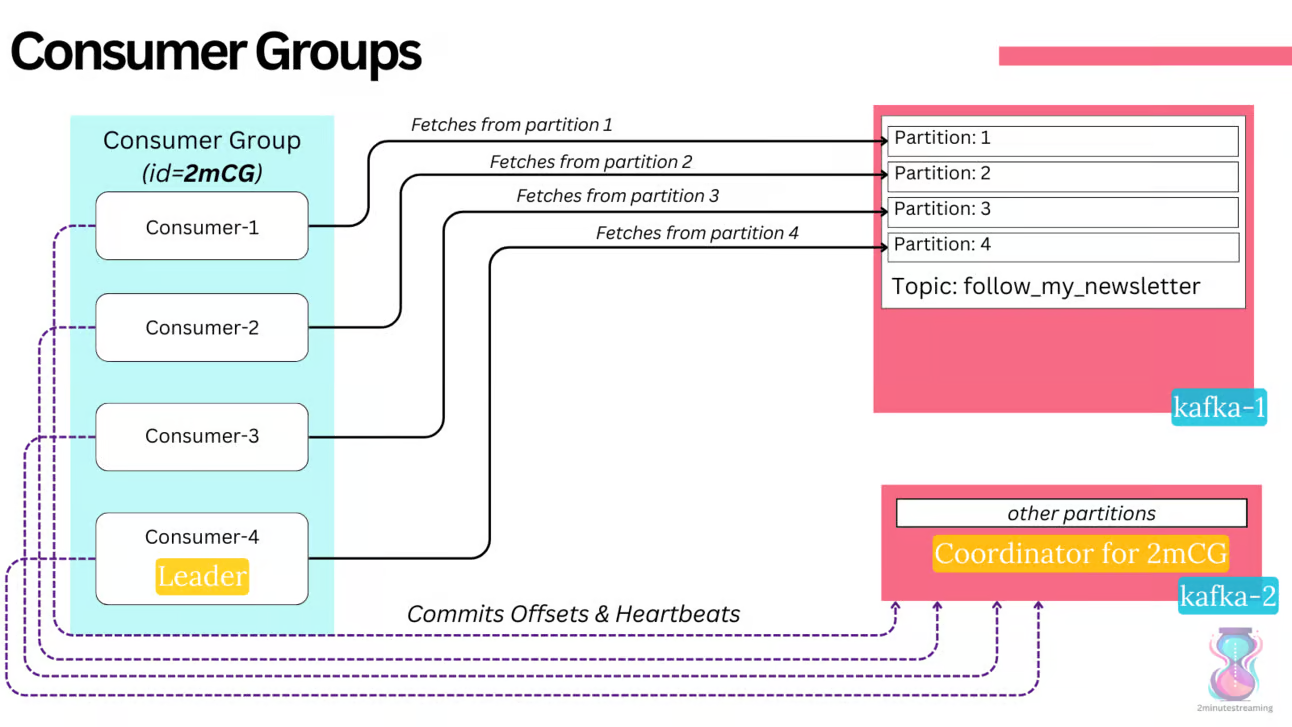
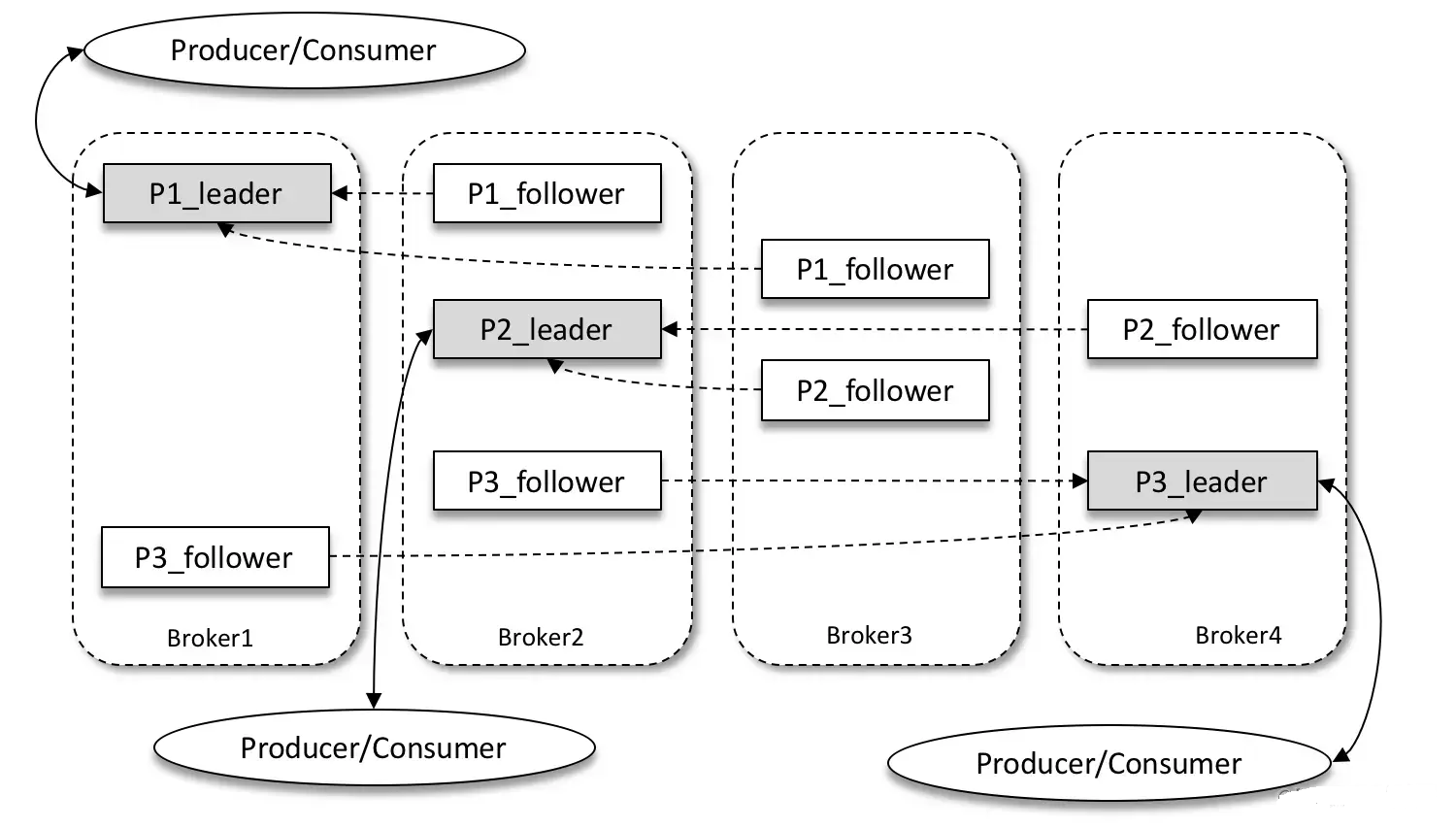
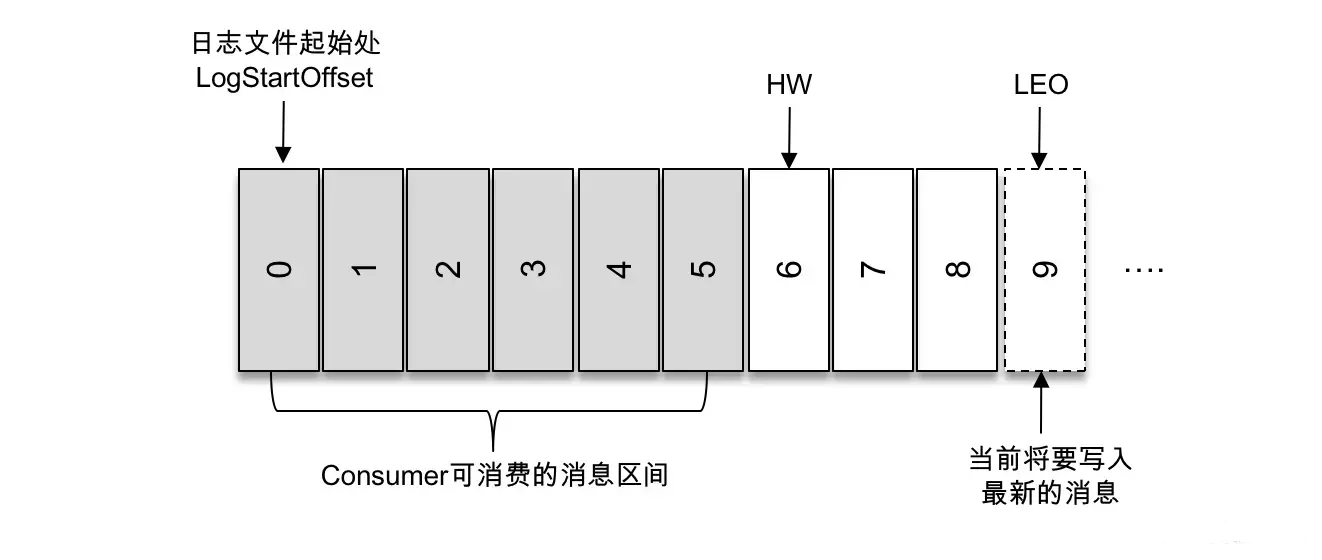
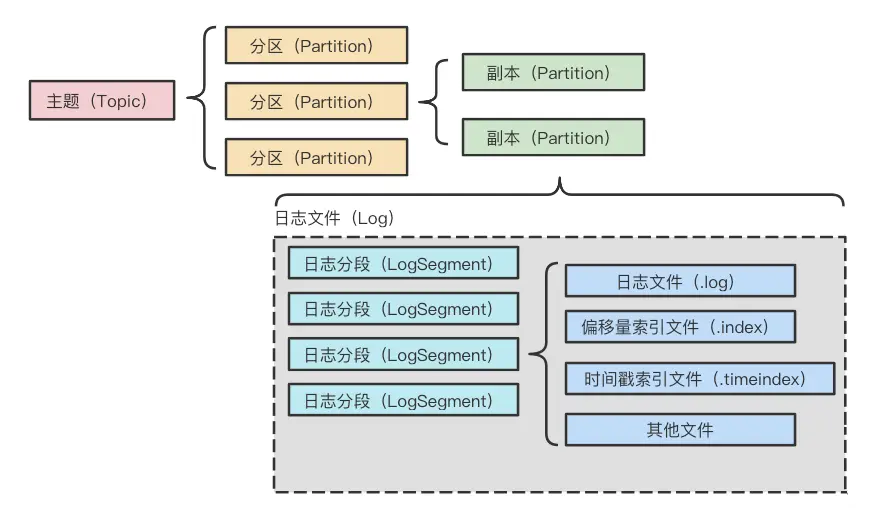
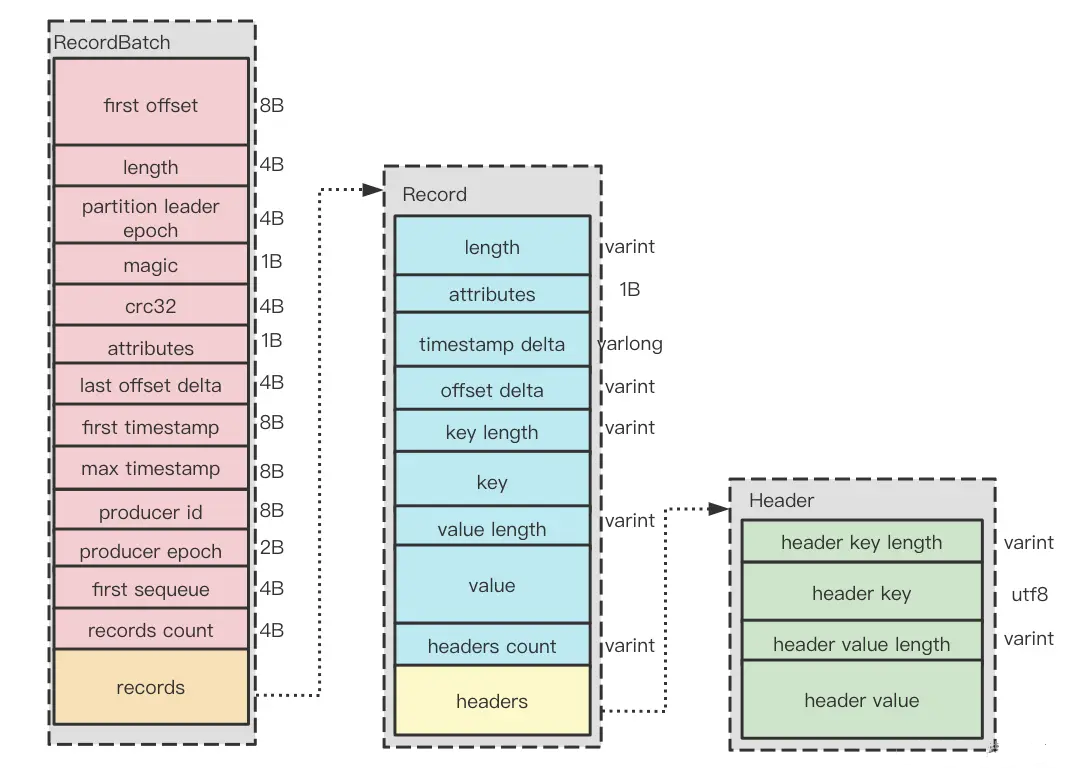
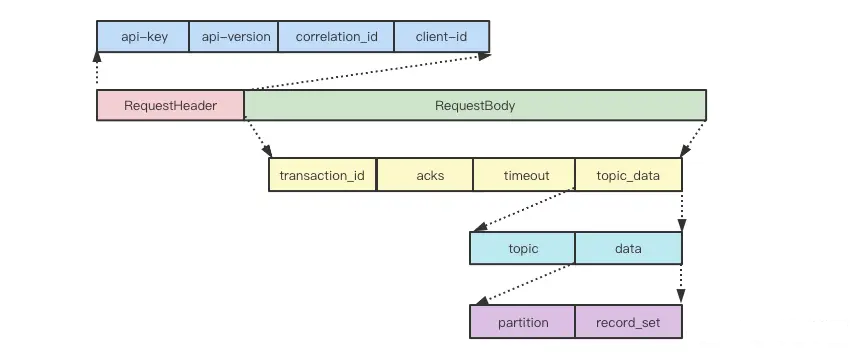
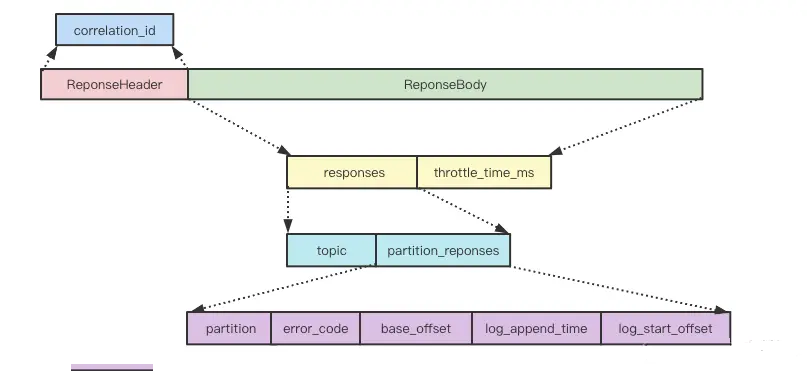
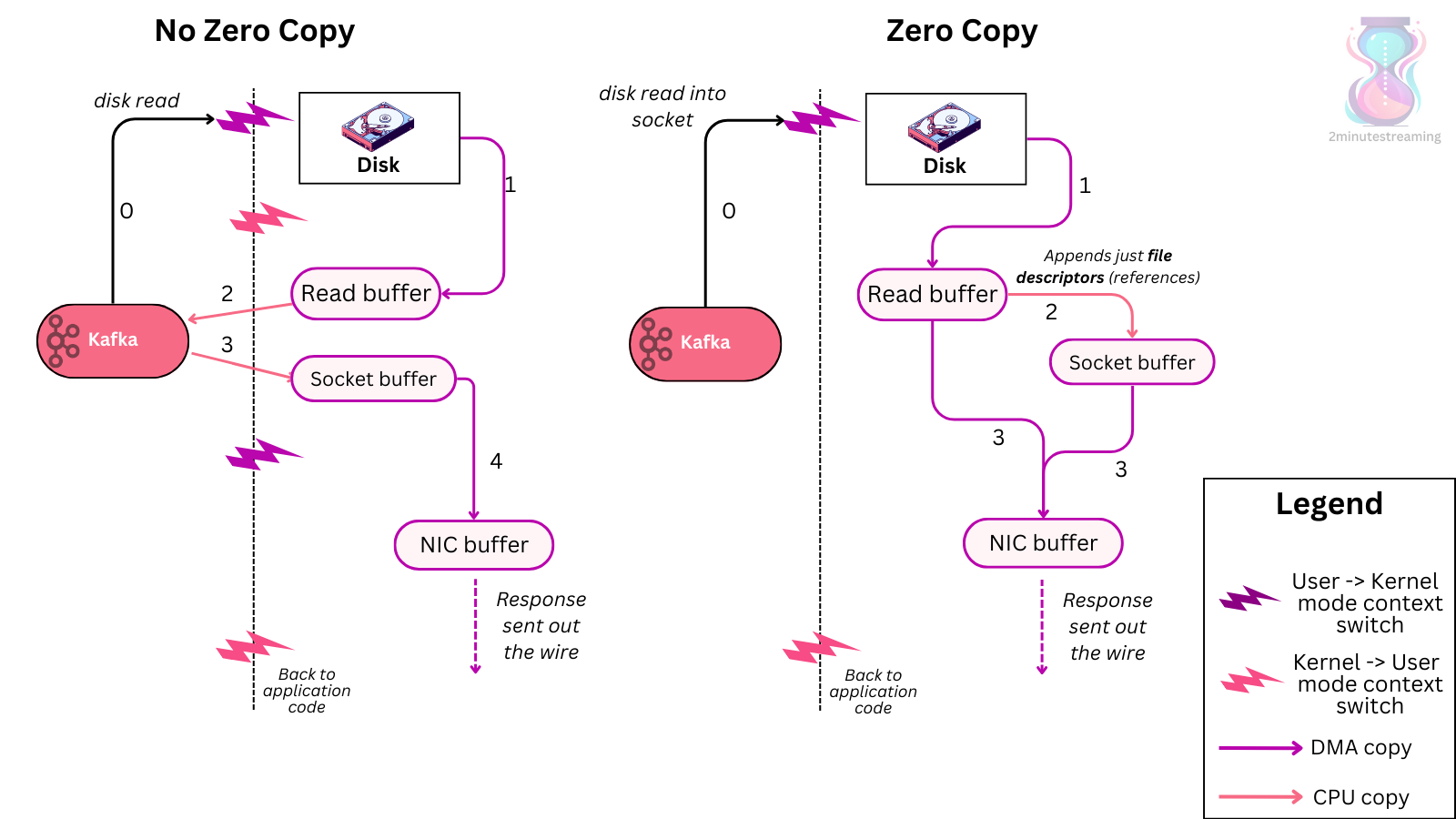
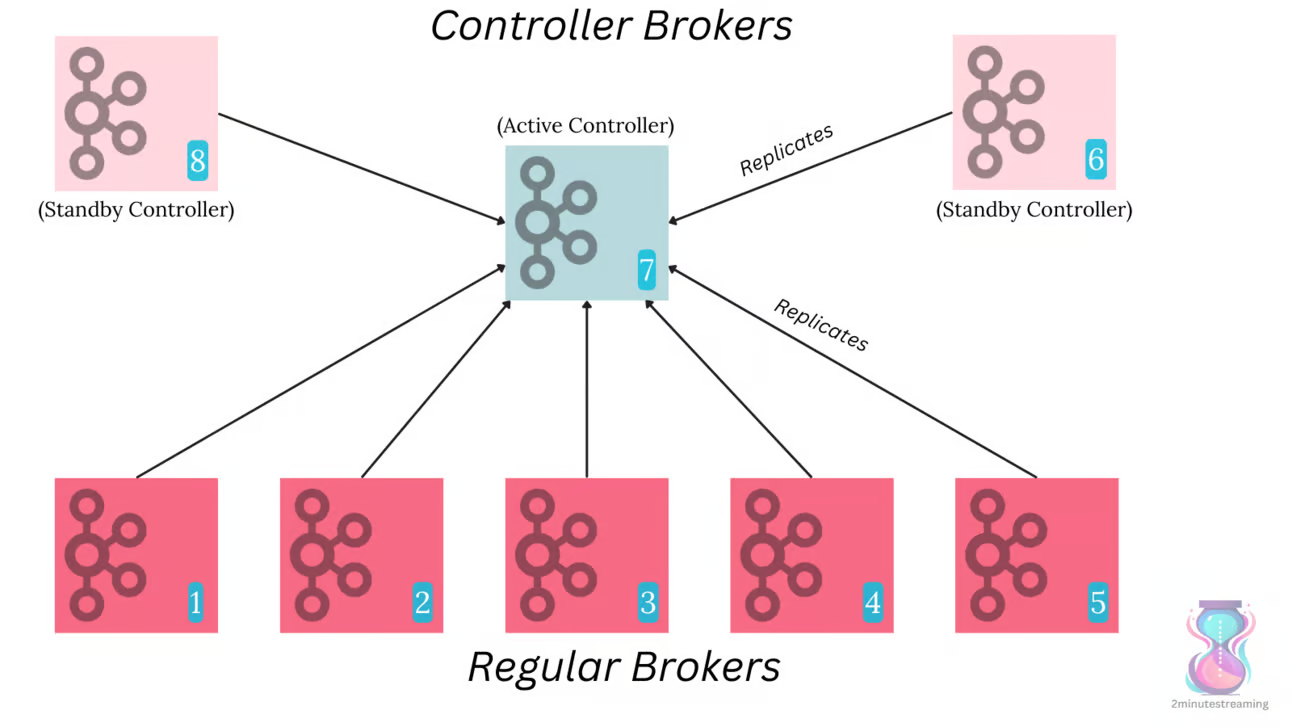
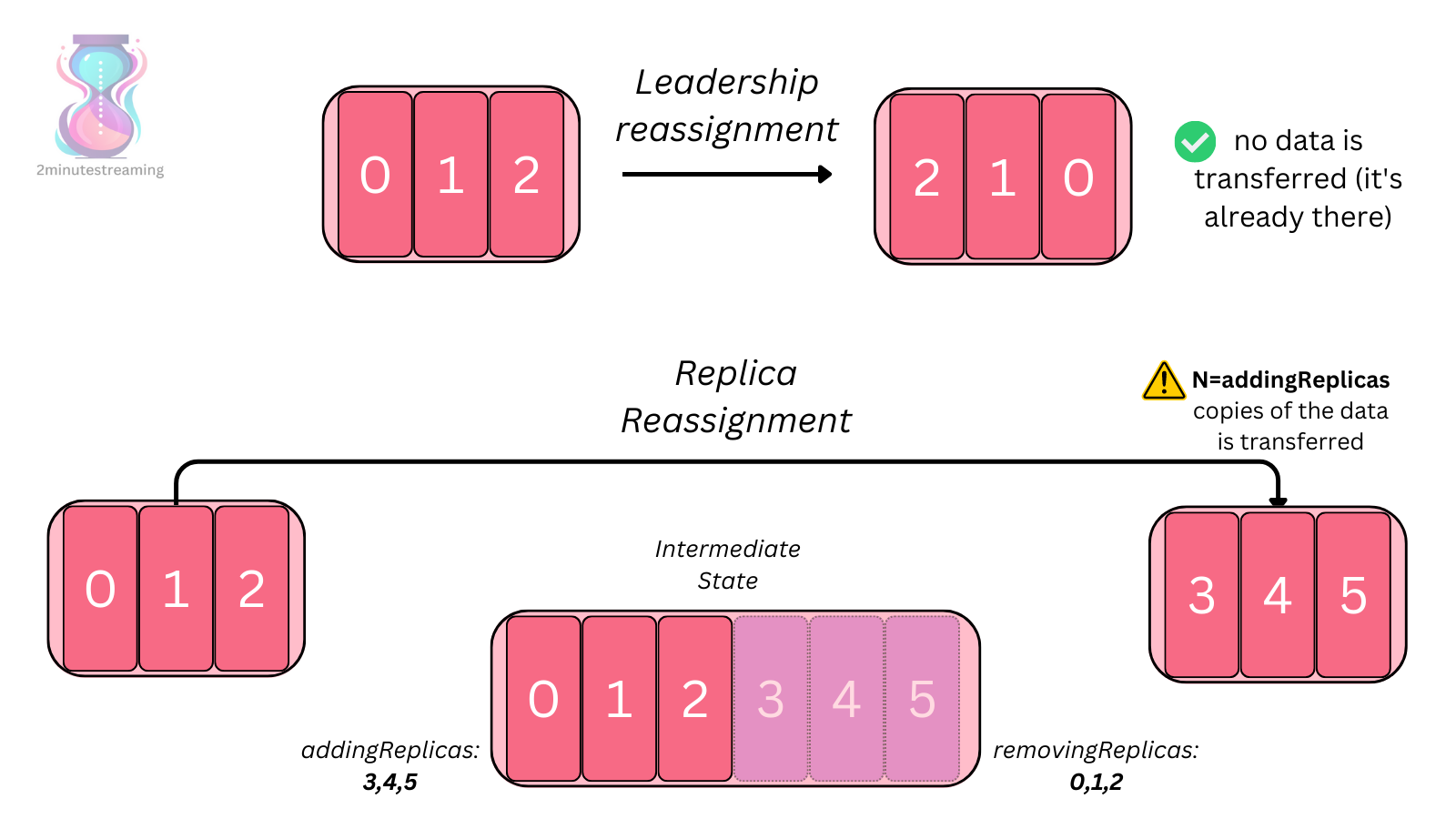
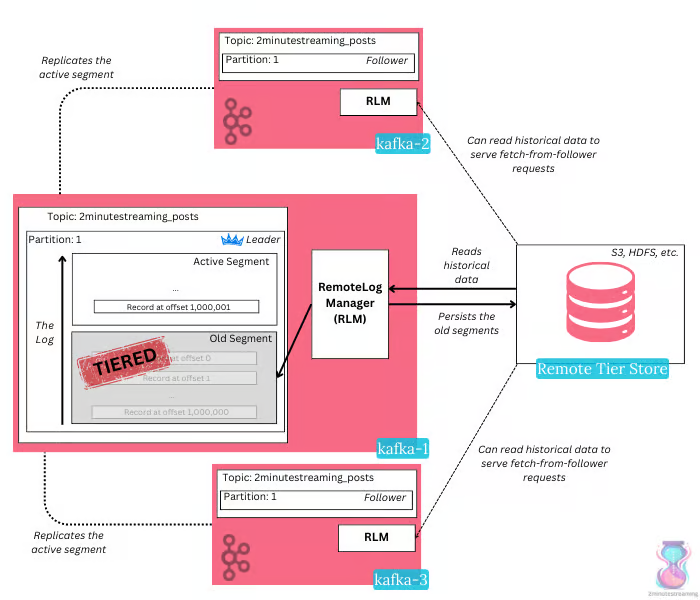
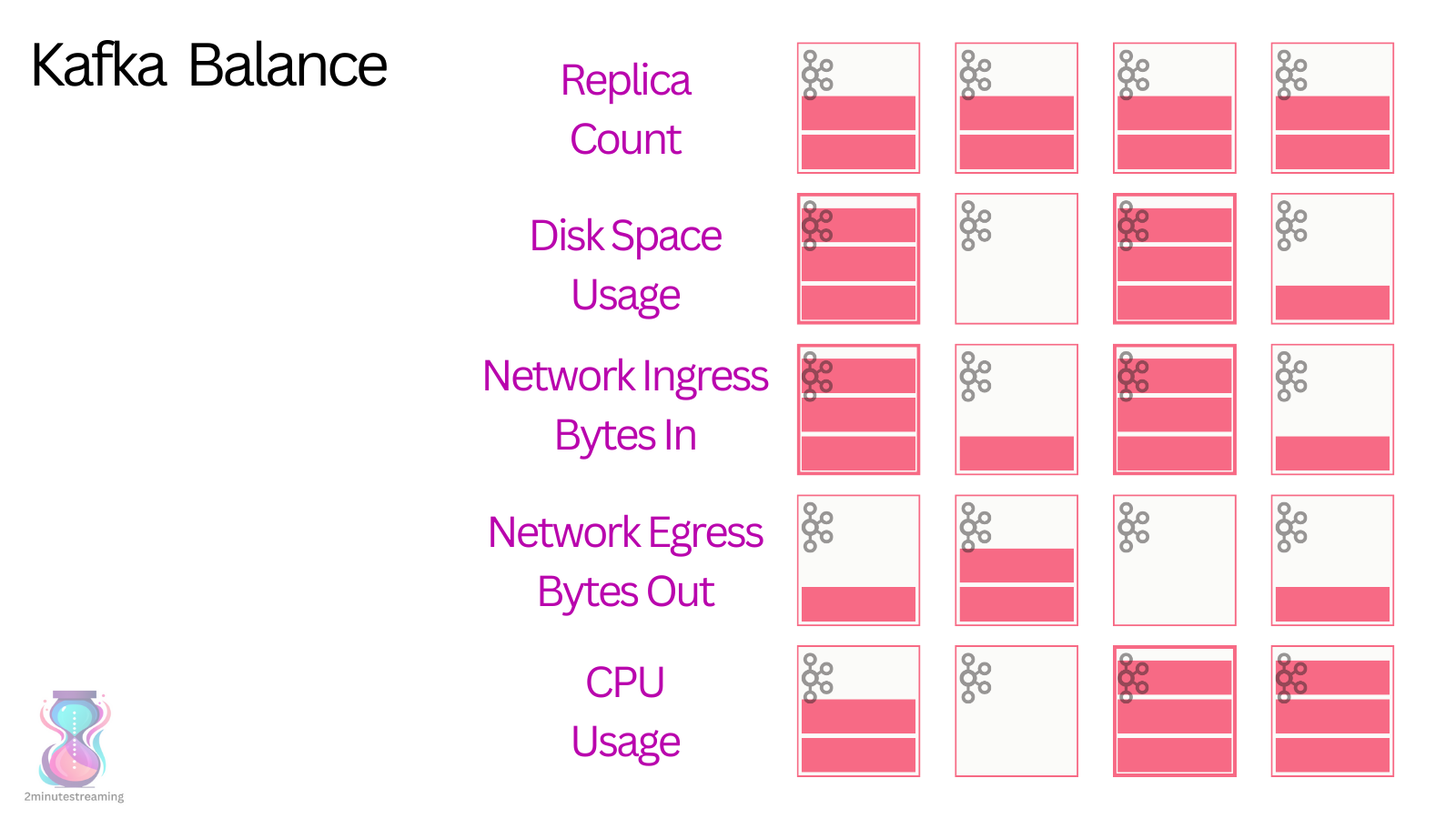
producer, broker, consumer,consumer group消费对应的partition数据,partition 包括多个 log segment,当一个达到阈值后,变成read only,再生成一个新的;每次都是head或者tail读,以及append写,速度很快,另外用了page cache会将数据写先到缓存再刷新;每个分区都有一个leader,副本只用于备份不做读写处理;副本如果能跟上leader就会放到 ISR集合中,ISR集合中最小的读确认offset 就是高水位,低水位是下次写的offset;producer 用 ack=0、1、all来表示副本节点是否接受了消息;ZK 后面迁移到了 Z-Raft 了,还有分层存储;kafka balance 是 NP问题,kafka connect,kafka streams;未来发展:完全基于云的kafka,用C++重写的kafka,数据存储在S3上的 statefulness 的kafka
阅读全文
2024年10月3日
大数据平台上云的问题:集群管控方式变了,YARN调度系统变了;安全性问题、DDos、数据治理问题;成本问题,计费策略;存储迁移,HDFS -> S3 语义的变化;多云高可用方案;混合云方案;适配其他业务线
阅读全文
2024年10月2日
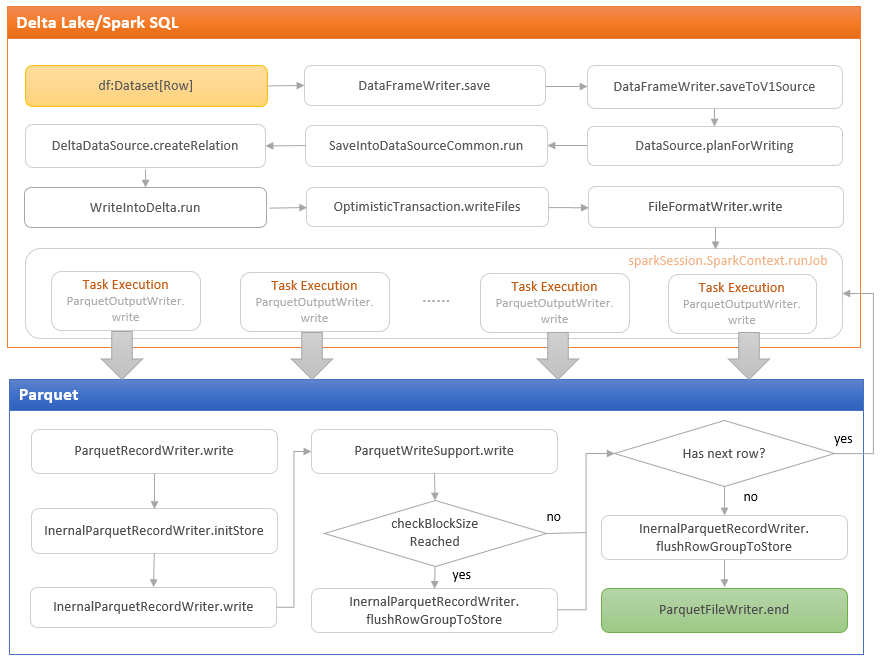
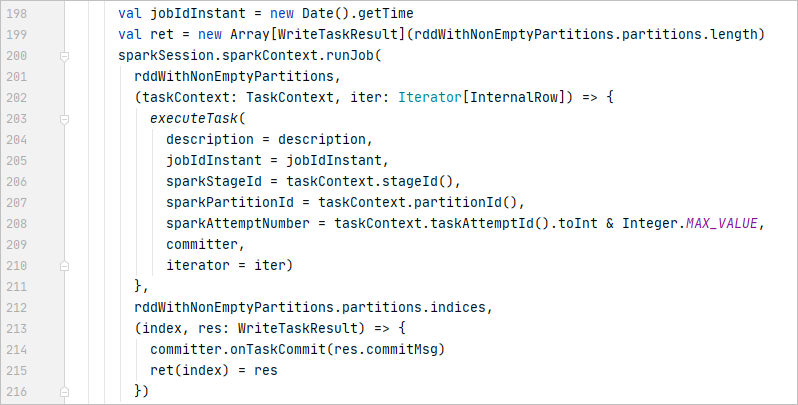
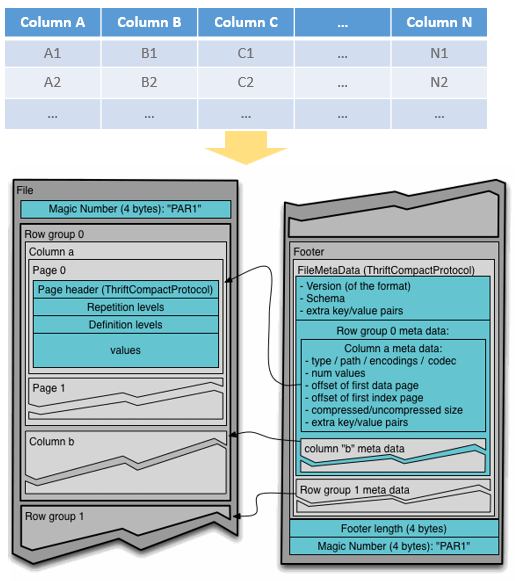
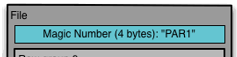
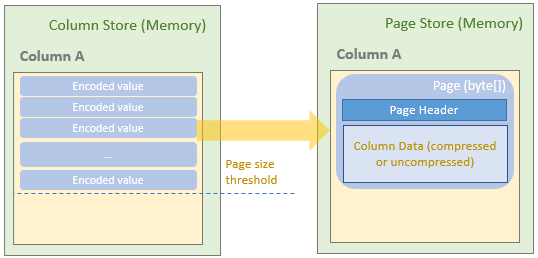
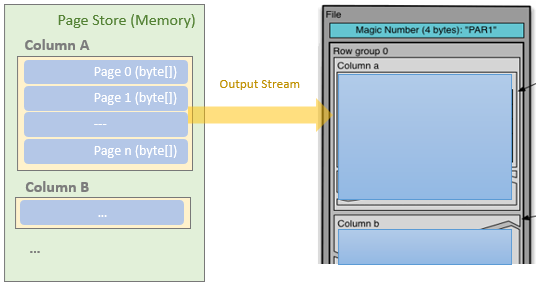
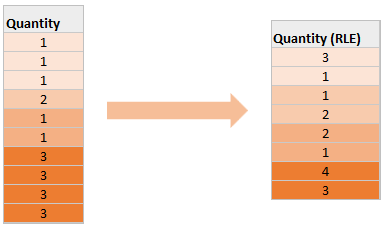
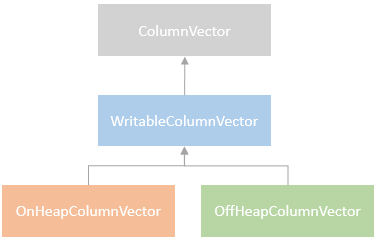
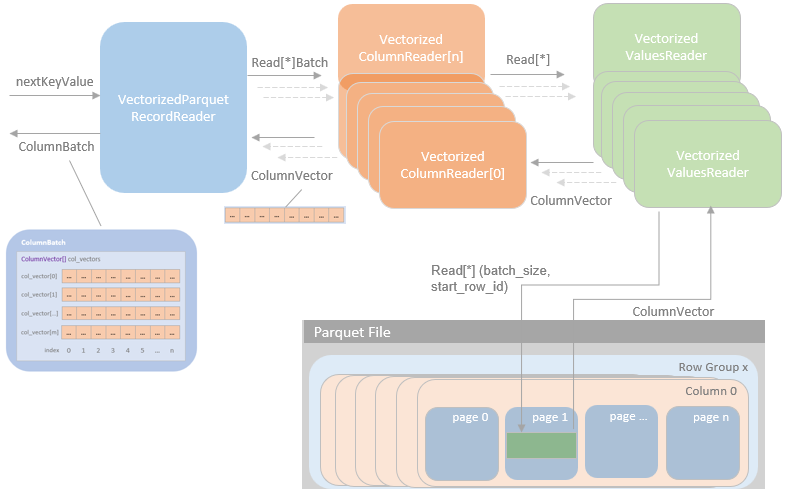
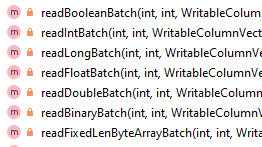
Spark执行Delta的过程,通过自定义的format格式,到DataFrameWriter.saveToV1Source,在是到DeltaDataSource#createRealation,写入做优化事务处理,再用FileFormatWriter创建多个Task并行写入,之后就是到Parquet内部执行阶段。Parquet包含Row Groups,往下是Column Chunk,再往下是Page,文件尾部包含Footer和一些元数据信息。Spark是按行写入的,一次写一行,每行写对应的 column。Parquet编码包括Dictionary Encoding、Run Length Encoding (RLE)、Delta Encoding。读取的主要类是VectorizedParquetRecordReader执行一批读取,调用VectorizedColumnReaders(对应每个column),再调用VectorizedValuesReader(读取一个column中的一段数据),返回由上层应用消费 。
阅读全文
2024年9月9日
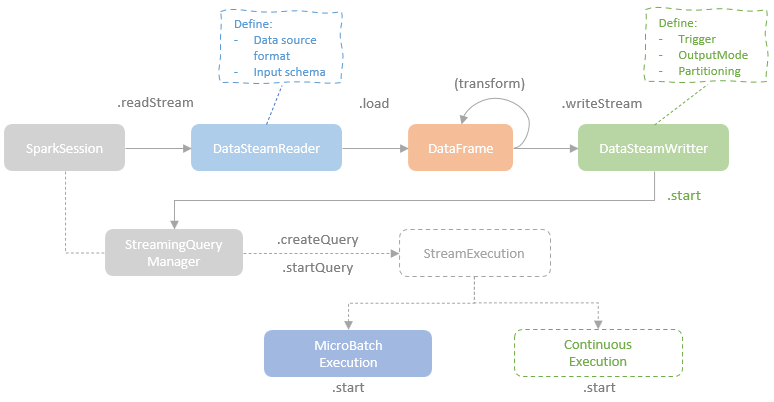
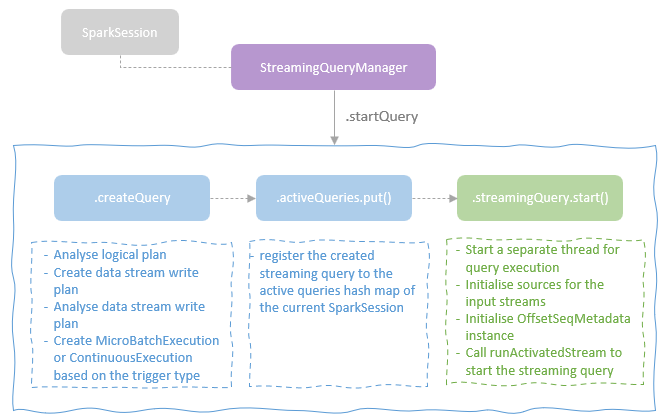
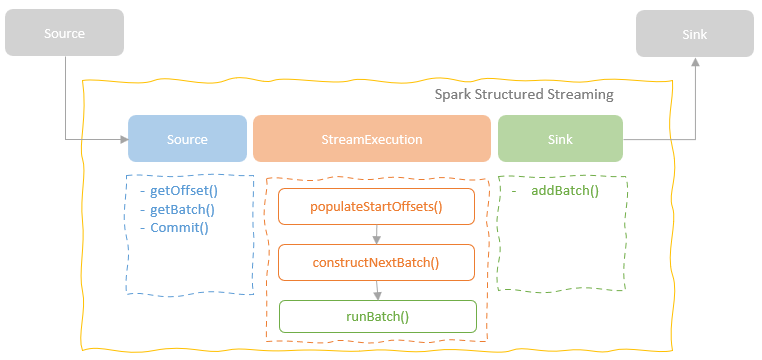
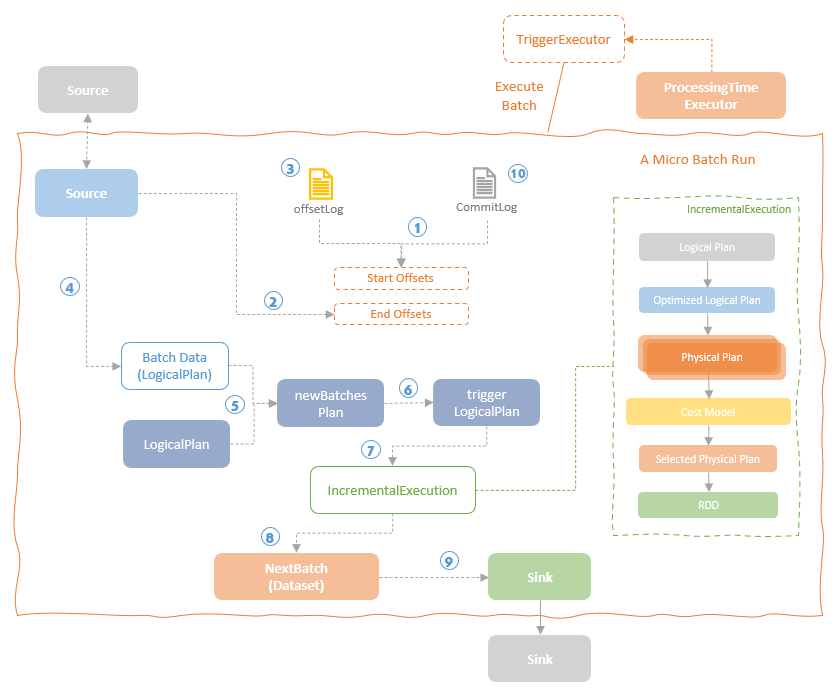
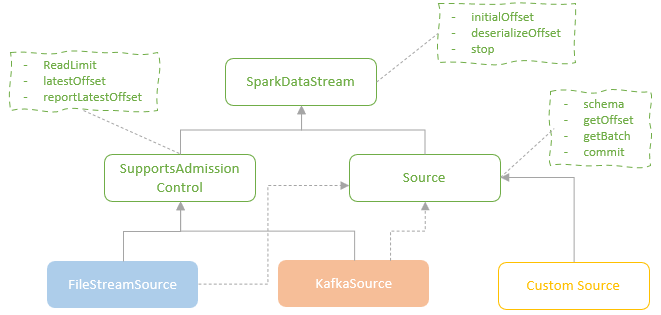
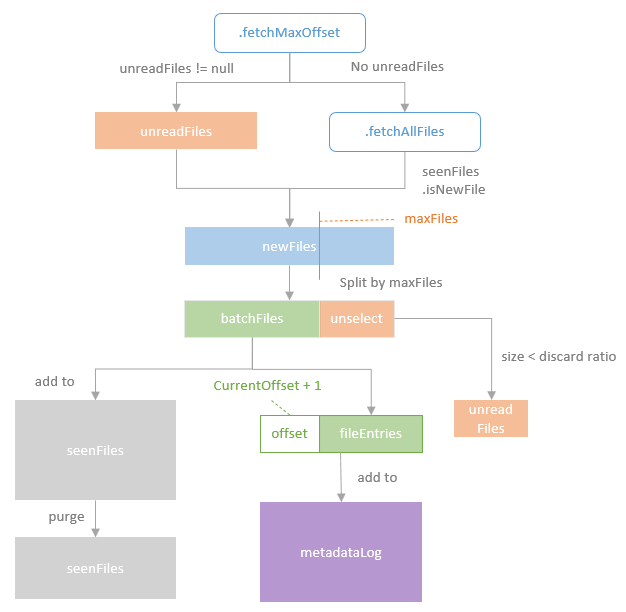
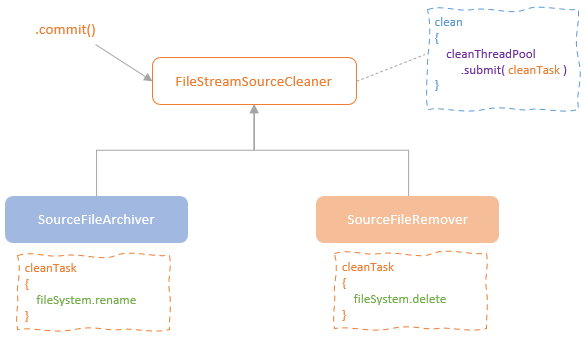
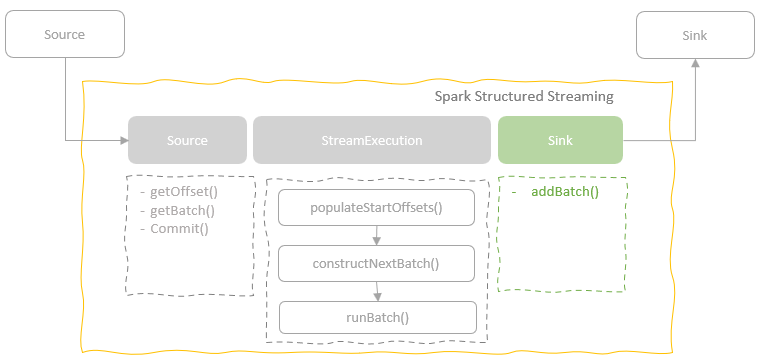
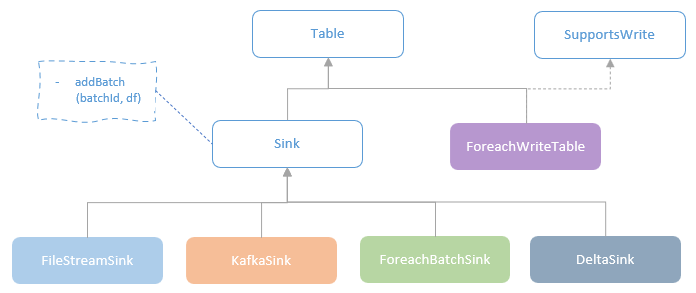
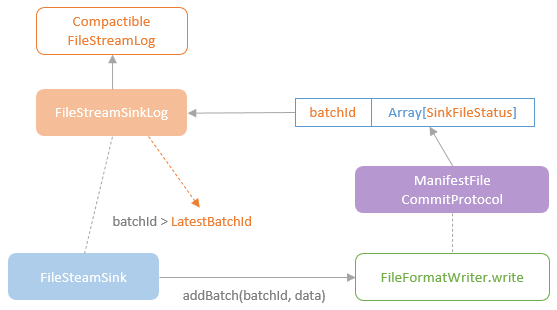
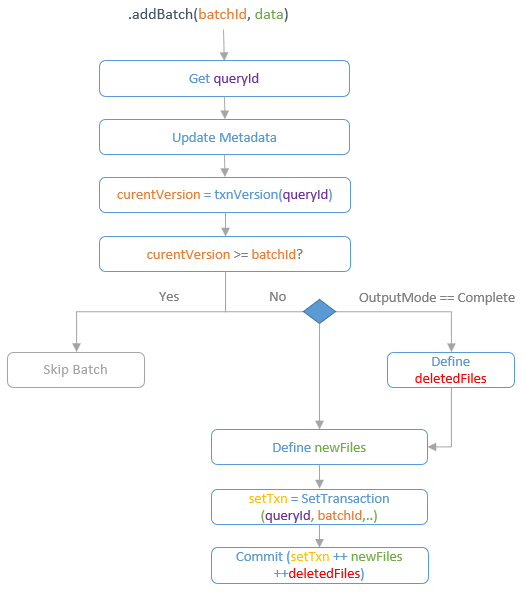
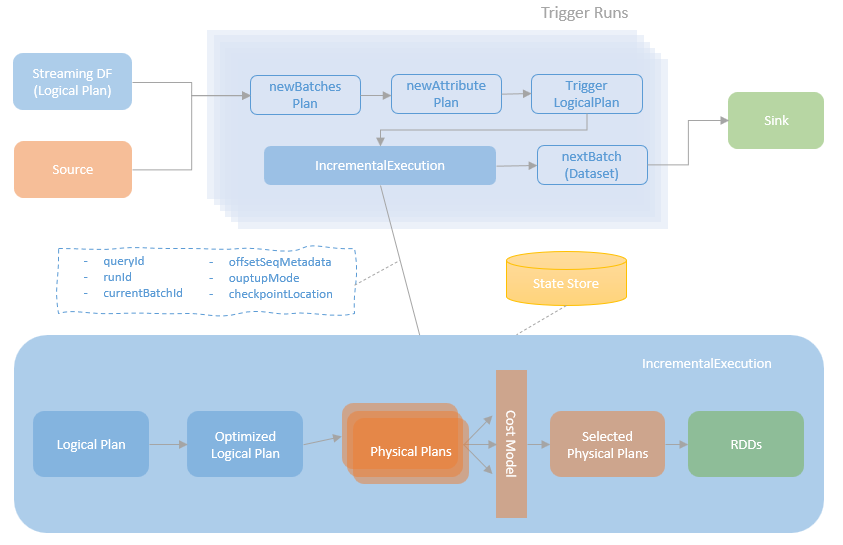
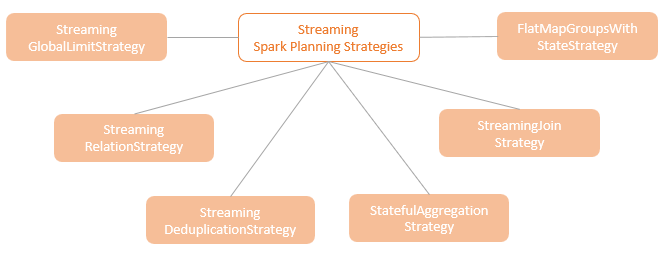
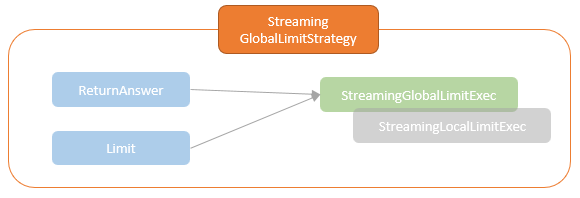
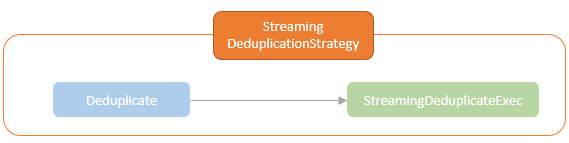
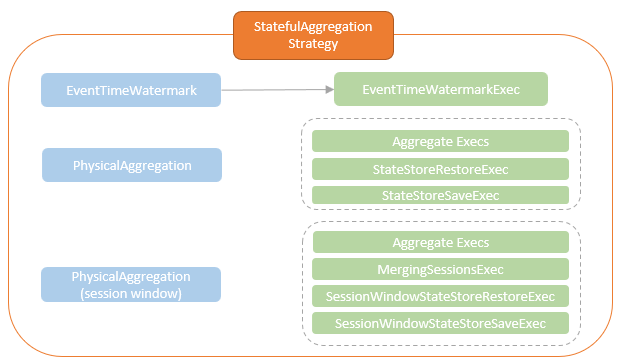
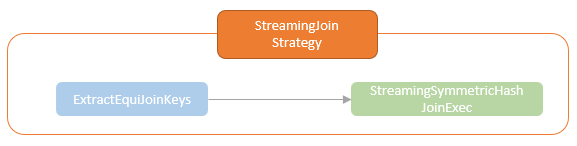
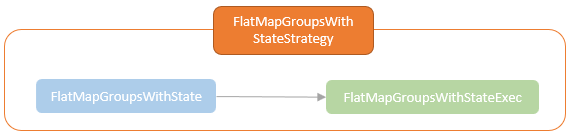
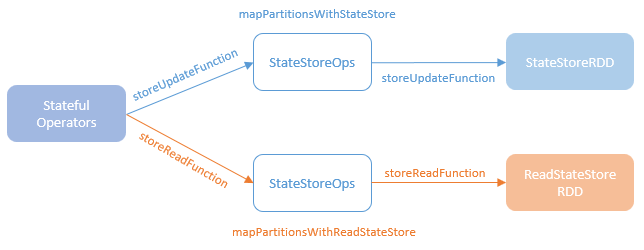
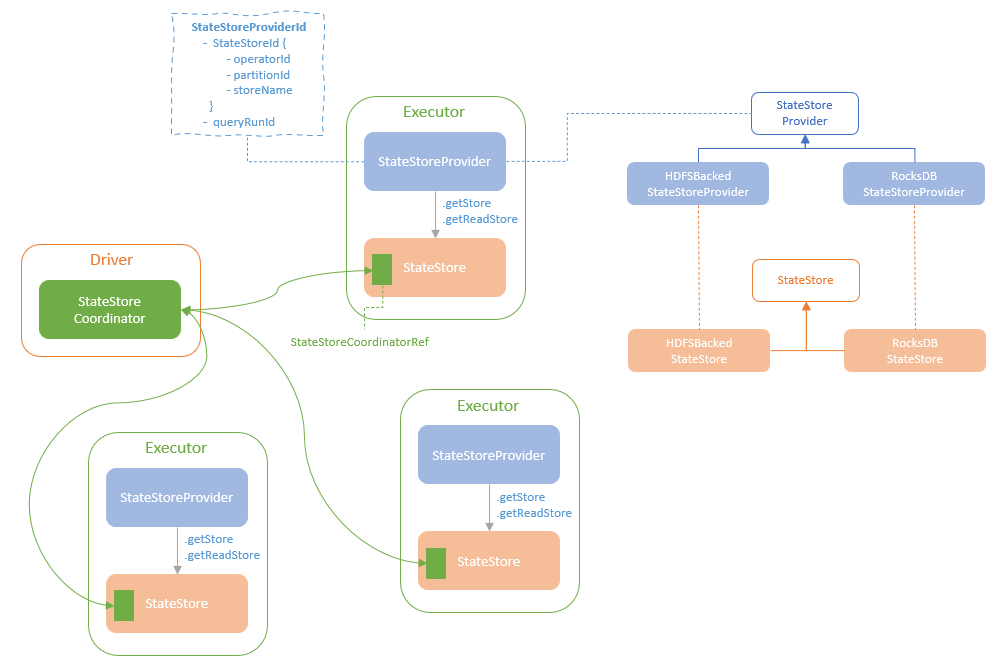
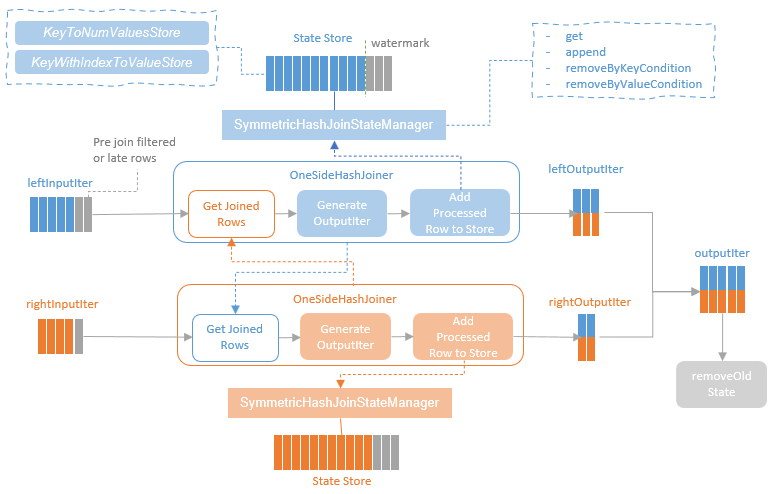
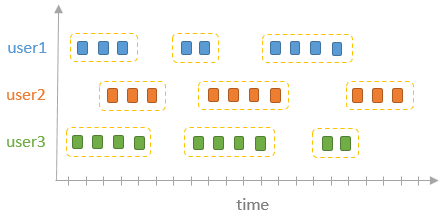
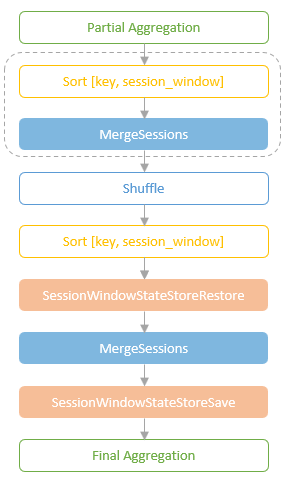
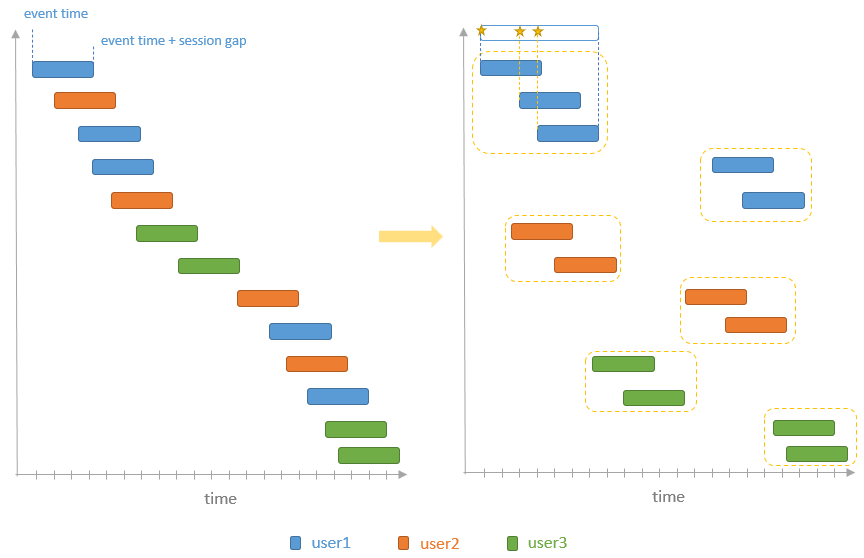
spark streaming的基本原理,包括MicroBatchExecution,ContinuousExecution,通过IncrementalExecution + 状态实现micro-batch 并复用了spark 的所有查询逻辑;Source接口支持 getOffset,commit,可以自定义各种扩展实现;Sink包括:FileStreamSink、KafkaSink、DeltaSink、、ForeachBatchSink,ForeachWriteTable;Stateful将信息存如StateStoreRDD,保存到 HDFSBackedStateStoreProvider、RocksDBStateStoreProvider 中;Stream-Stream Join使用了StreamingSymmetricHashJoin,需要保证状态;Session Window同样也是通过插入一些流相关的算子 + 状态保存实现的
阅读全文
2024年9月1日
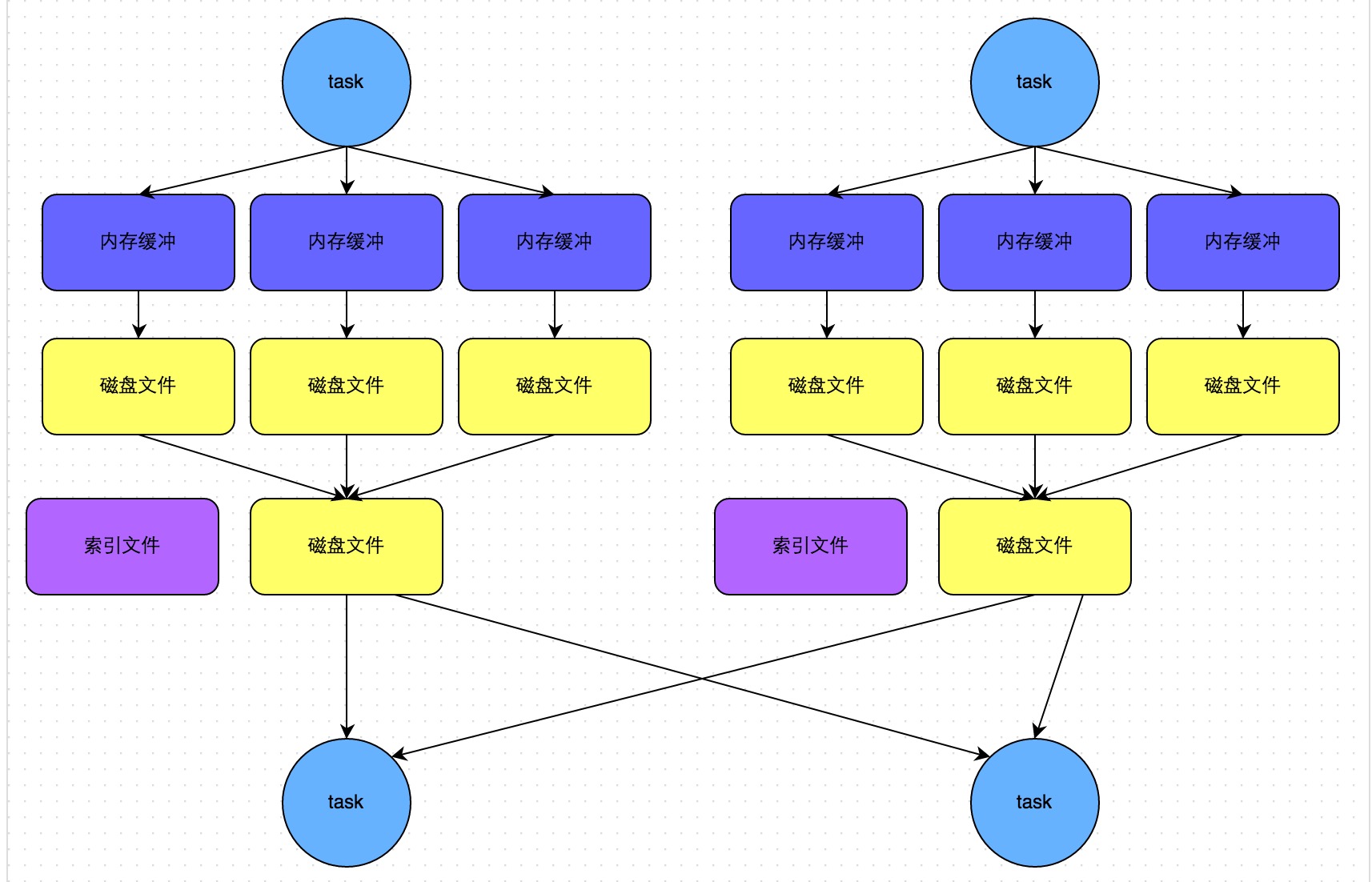
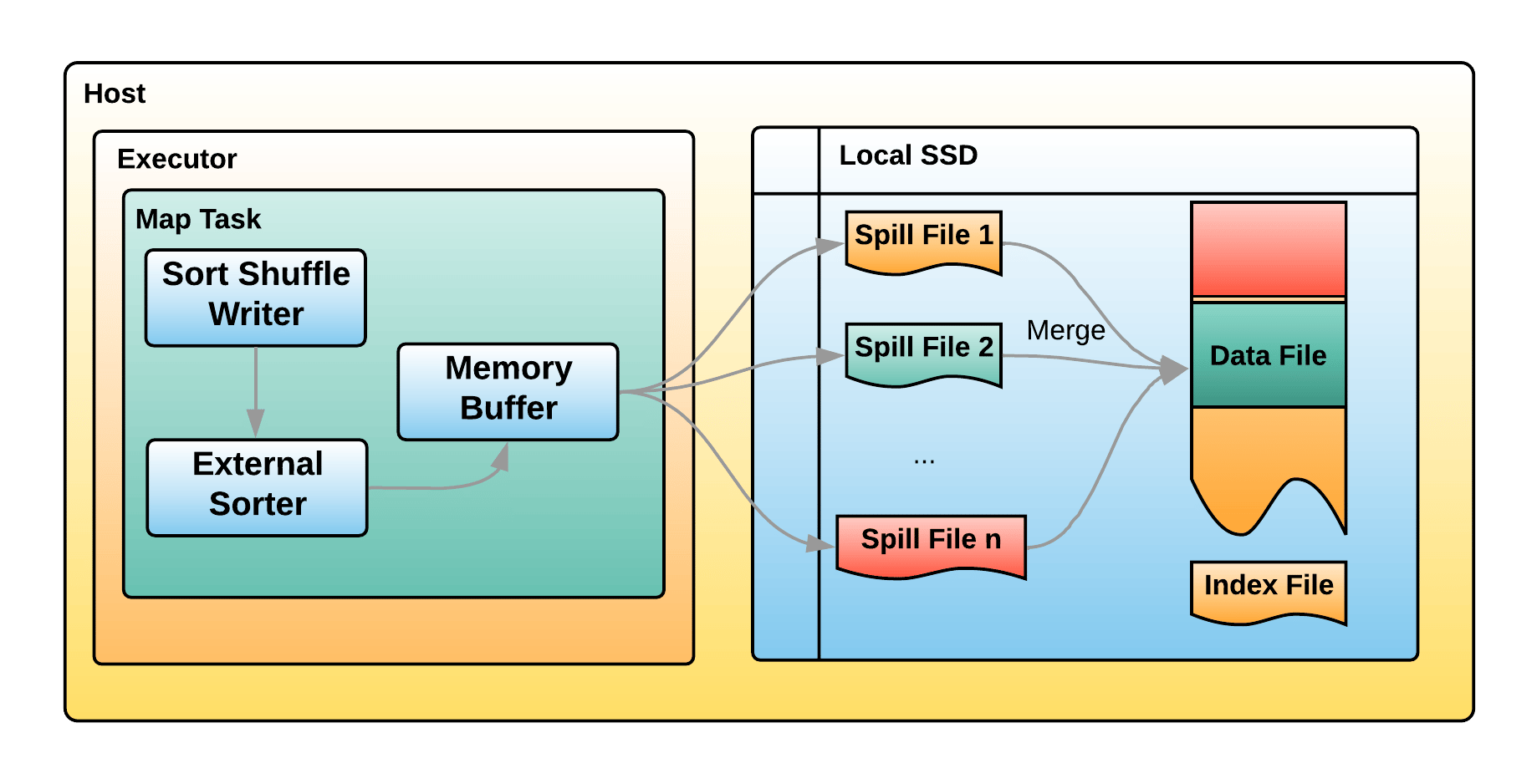
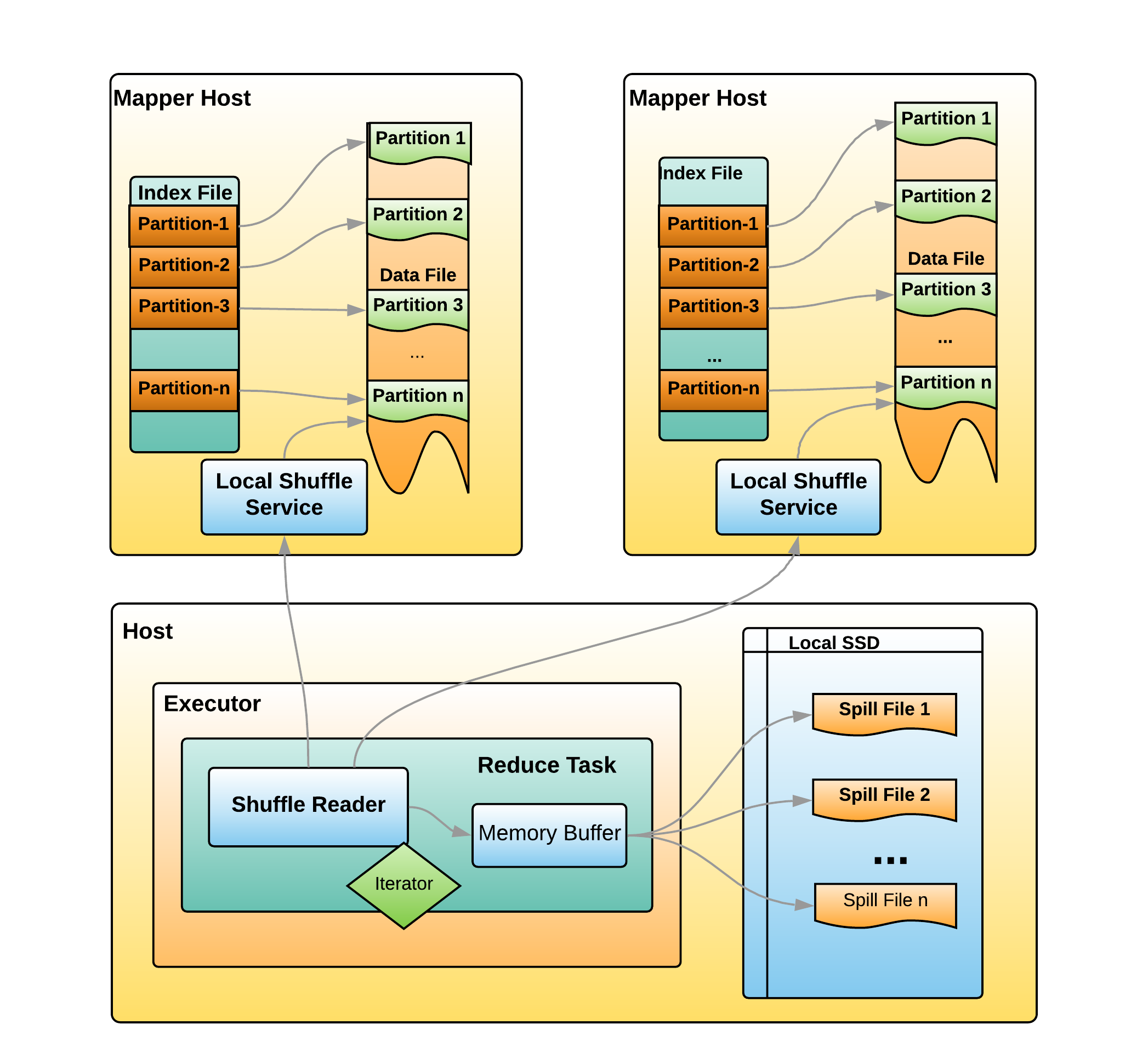
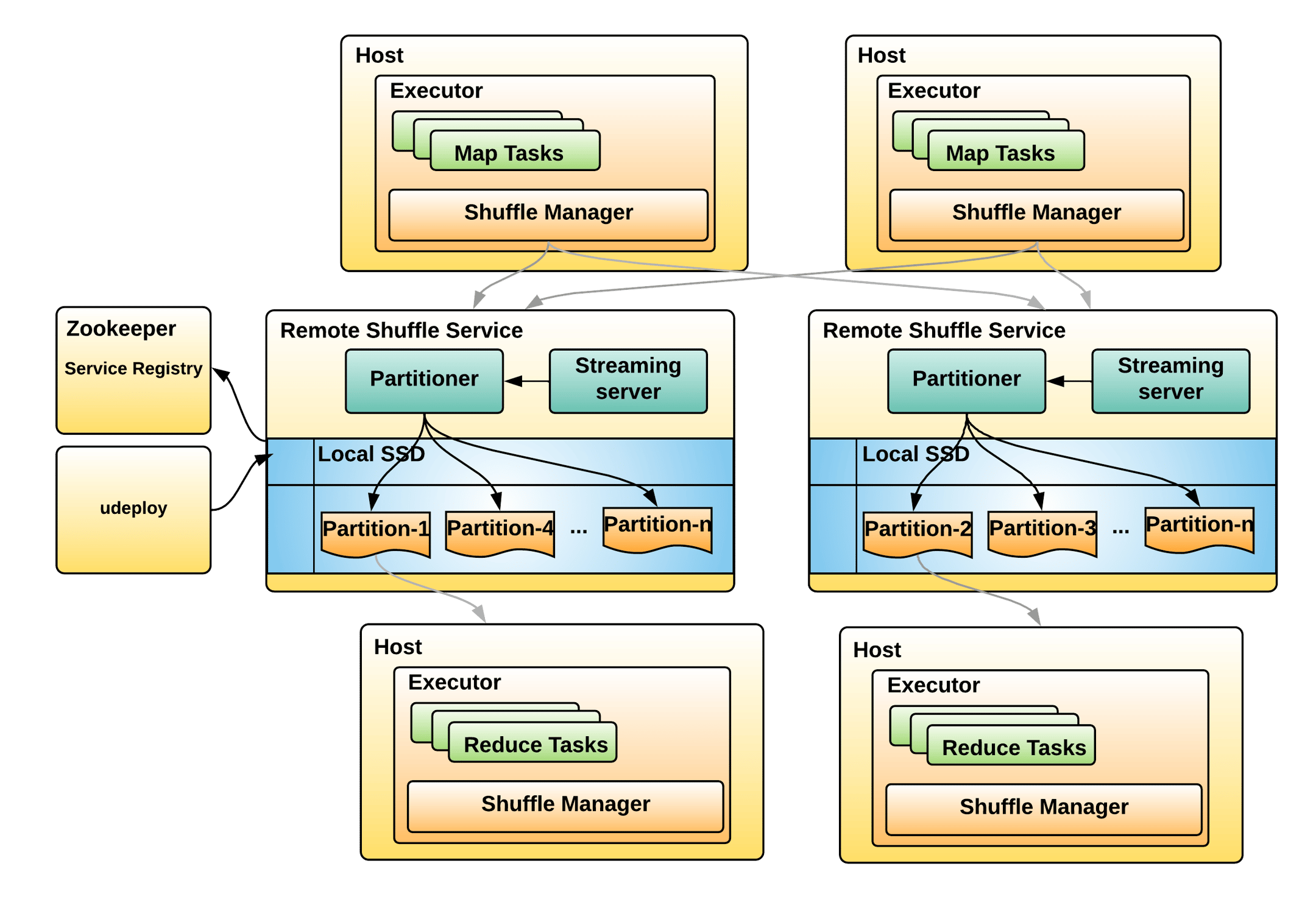
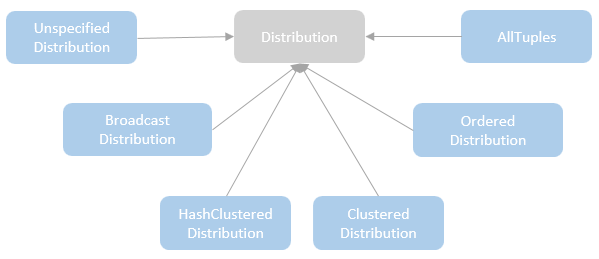
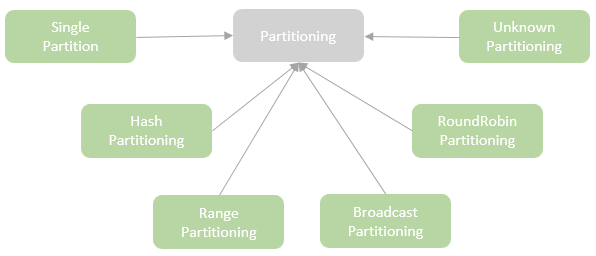
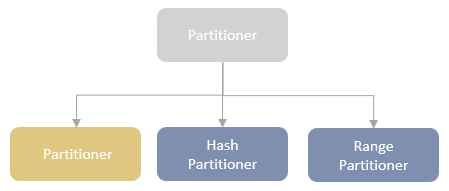
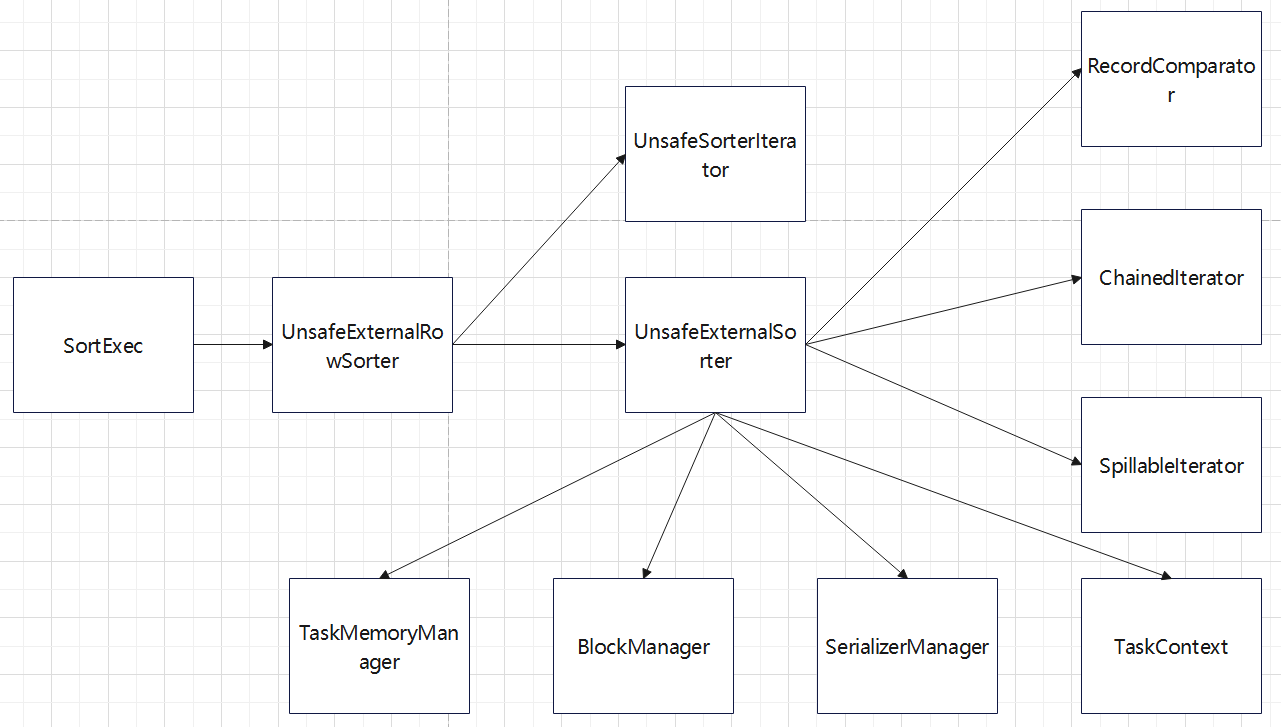
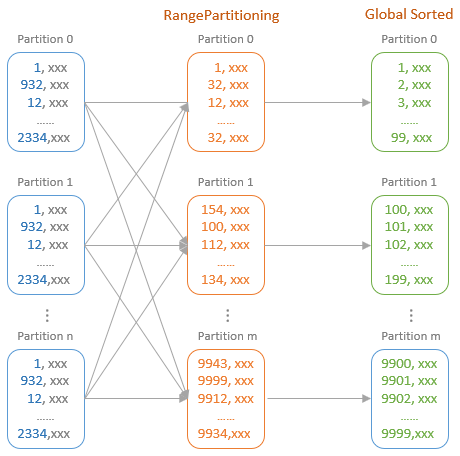
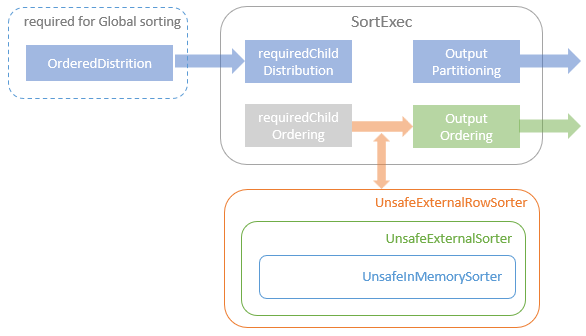
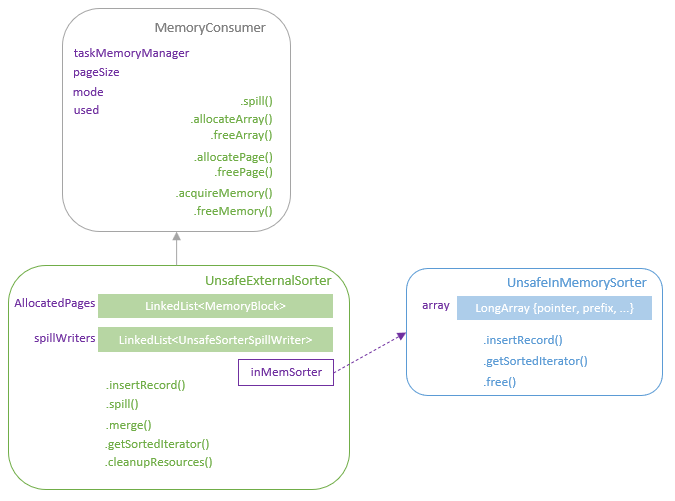
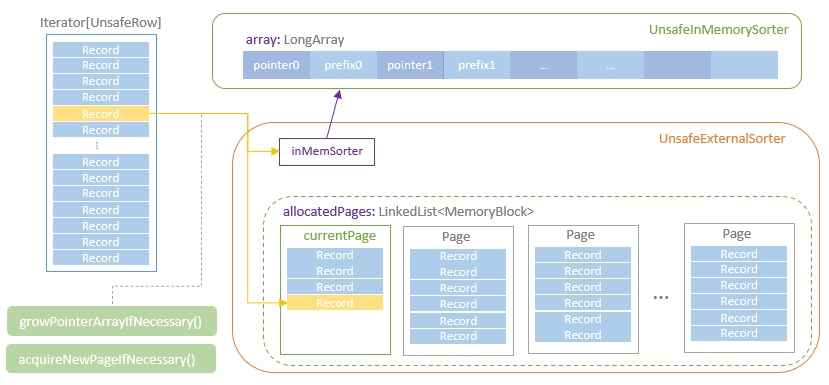
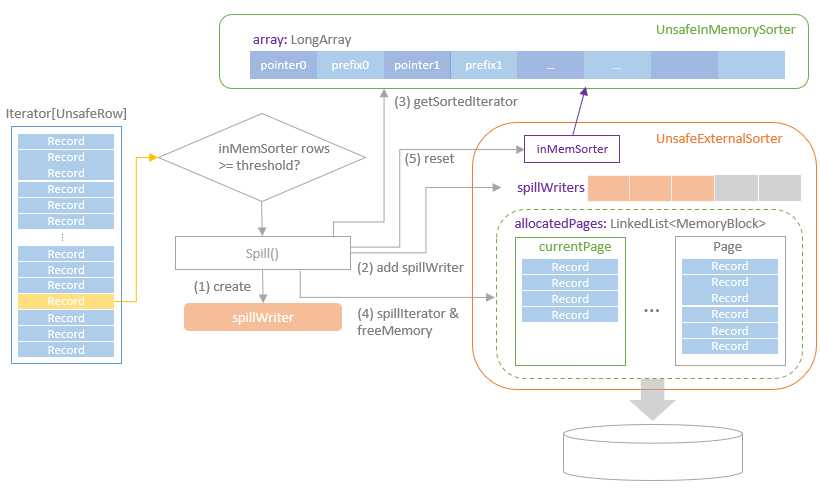
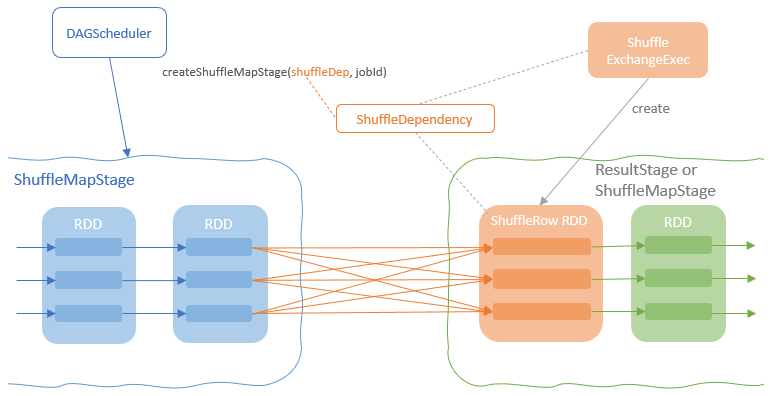
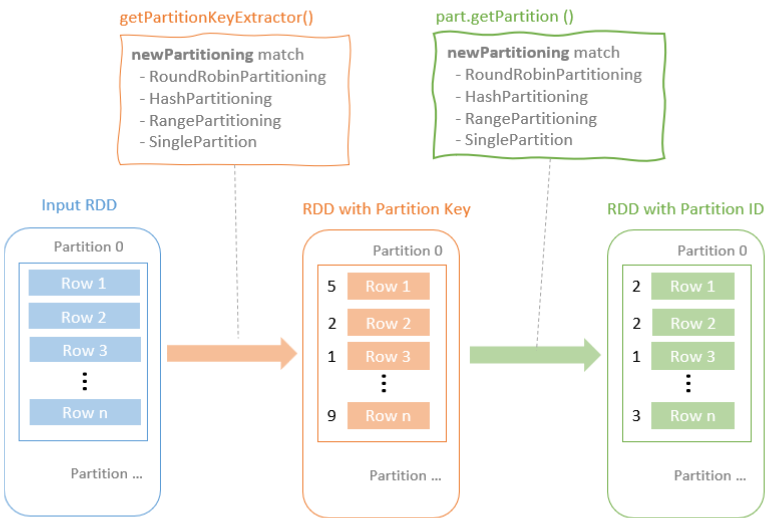
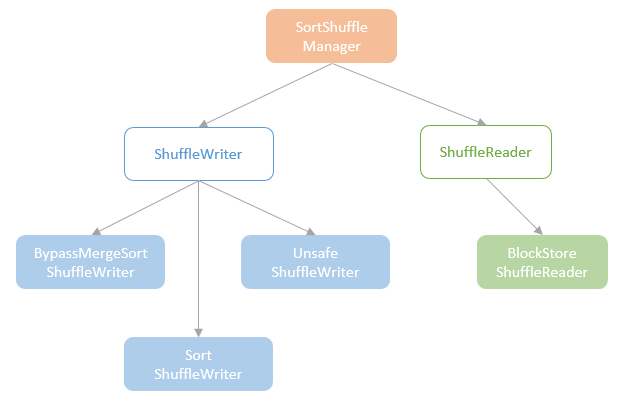
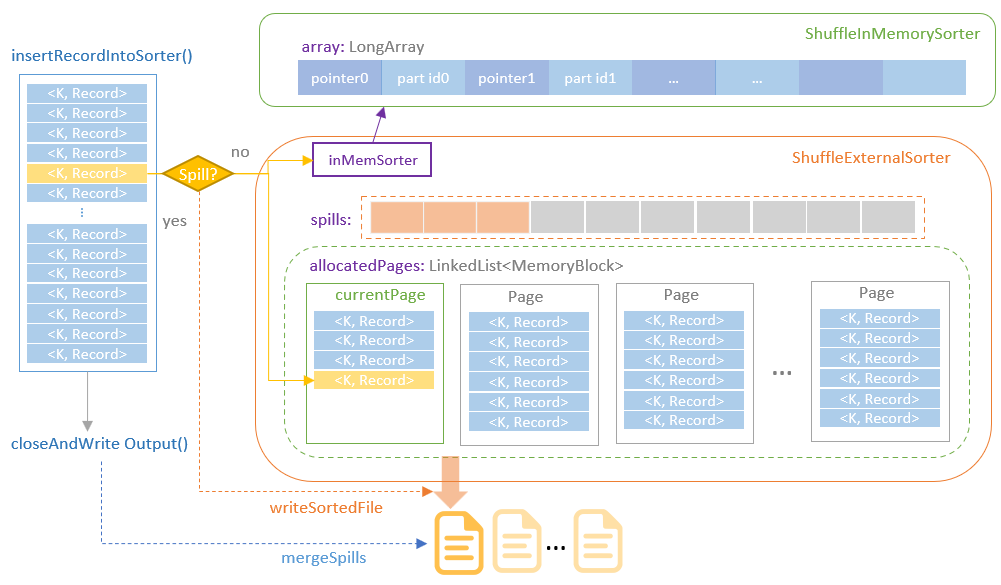
Distribution及相关类,Partitioning类,Partitioner类,排序的物理算子,UnsafeExternalSorter 和UnsafeInMemorySorter,spill和归并排序;shuffle操作,ShuffleDependency,ShuffleRowRDD,map端的ShuffleMapTasks,reduce端 ShuffleDependency 从shuffle manager 那里读取数据,拿到MapStauts 状态;ShuffleManager 包含了ShuffleWriter,ShuffleReader;BypassMergeSortShuffleWriter 、UnsafeShuffleWriter、SortShuffleWriter、、BlockStoreShuffleReader
阅读全文
2024年4月7日
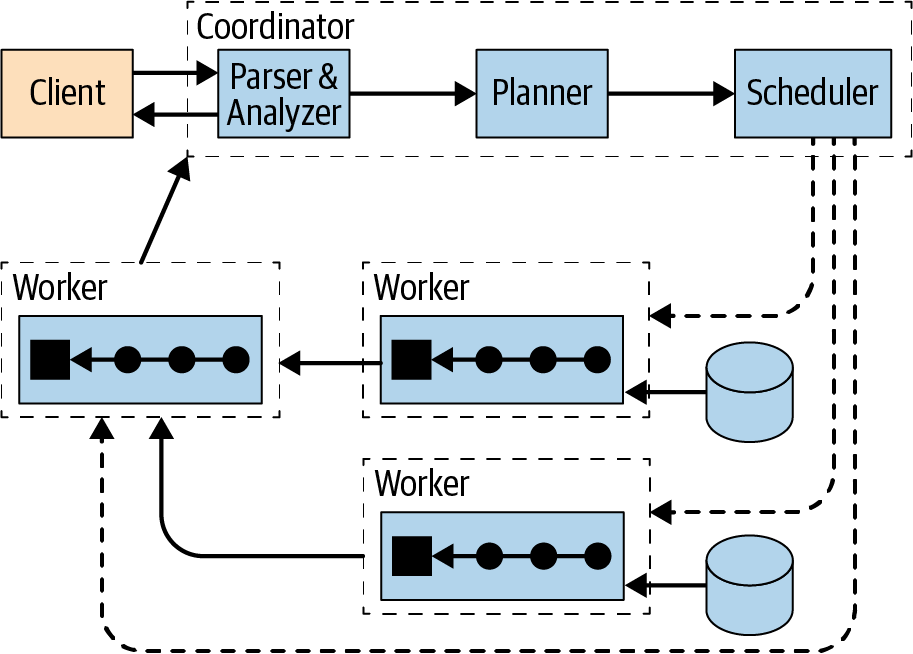
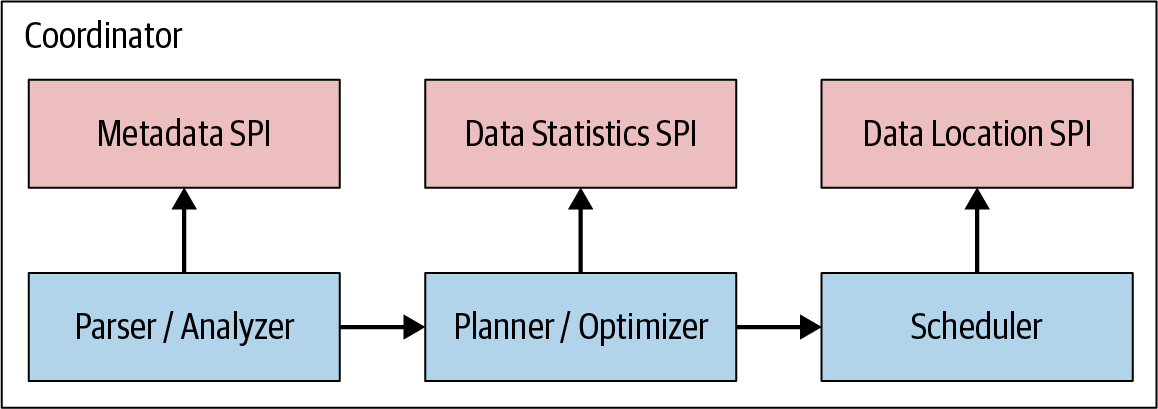
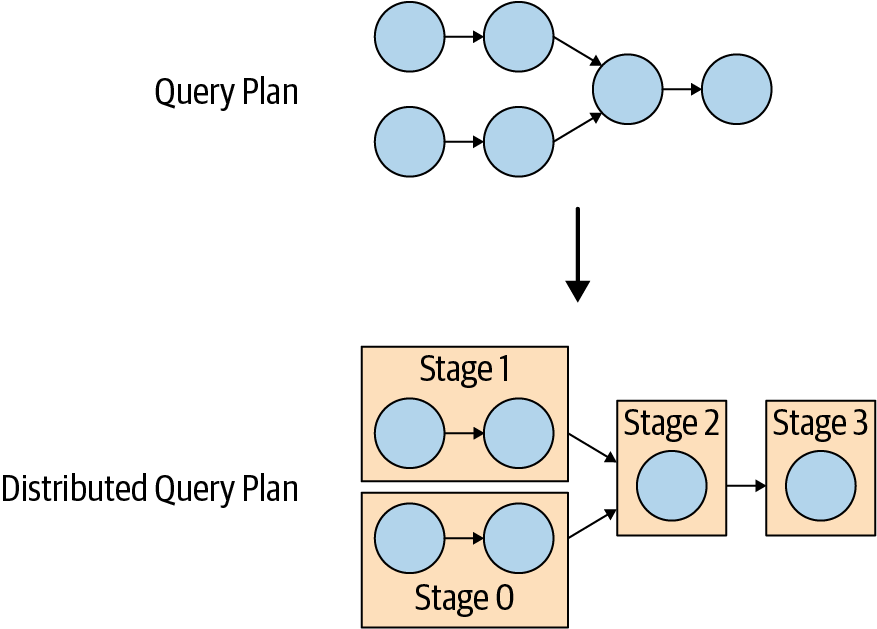
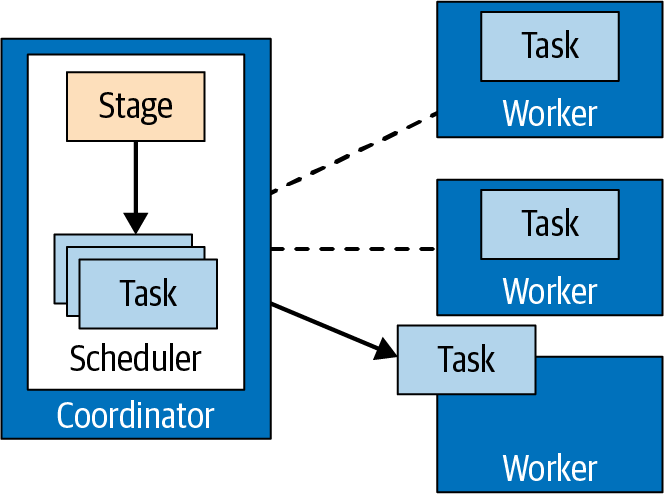
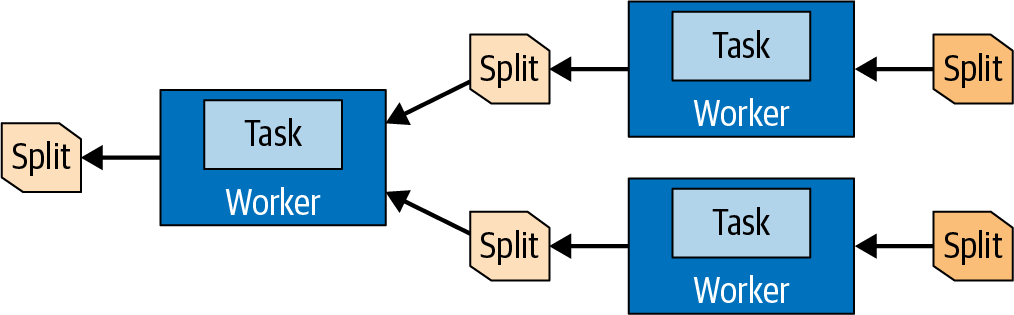
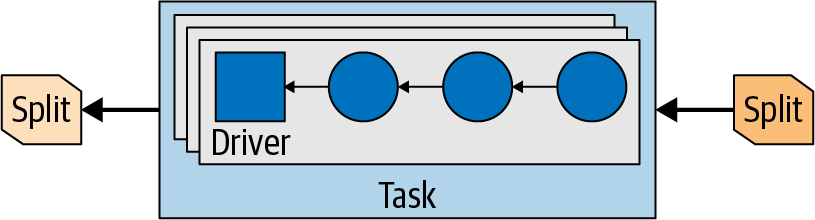
三种角色:discovery、coordinate、worker;连接器的设计:Metadata SPI、Data Statistics SPI、Data Location SPI、Data Stream SPI;查询计划,物理计划和调度,Stage,split,page,driver;Dynamic filtering,Spill to disk,Table statistics,JOIN 策略,CBO,join order,Join pushdown
阅读全文