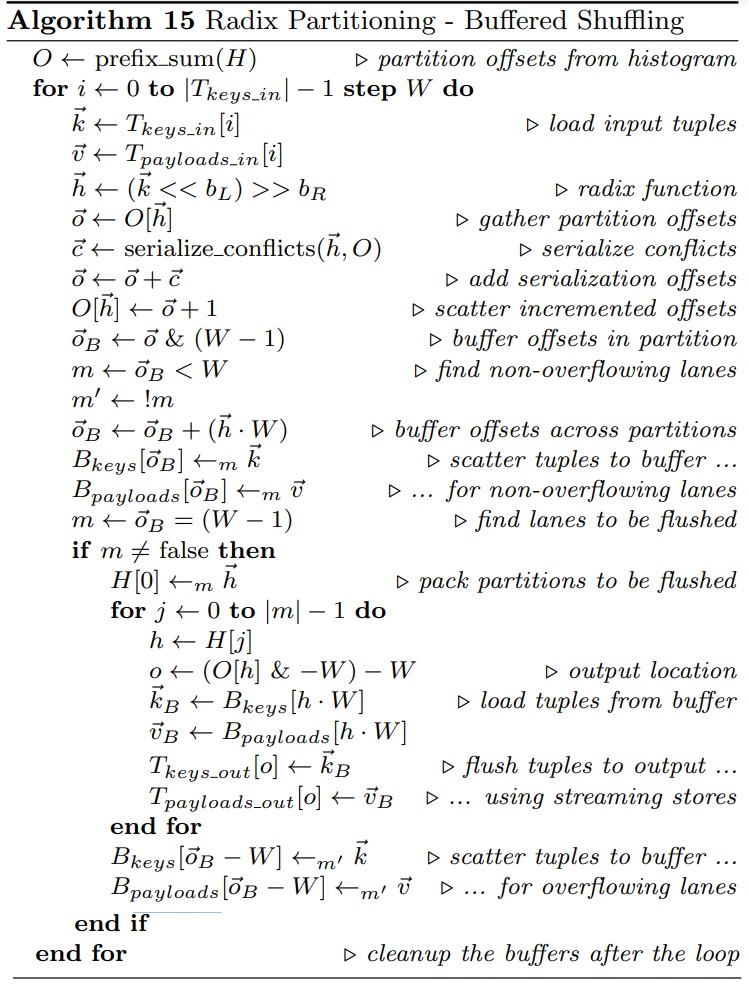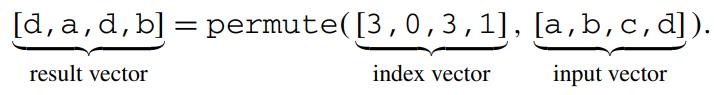2023年2月1日
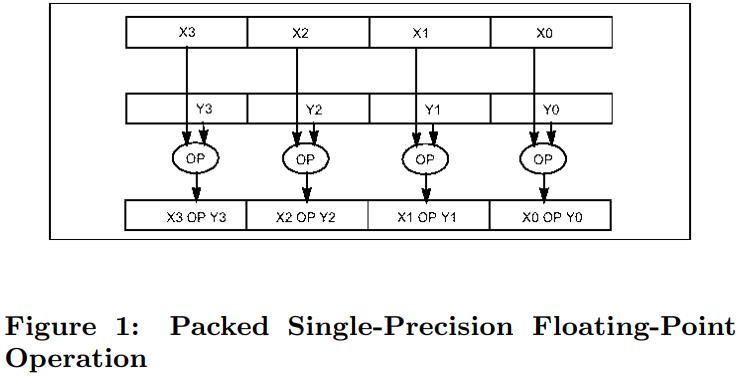
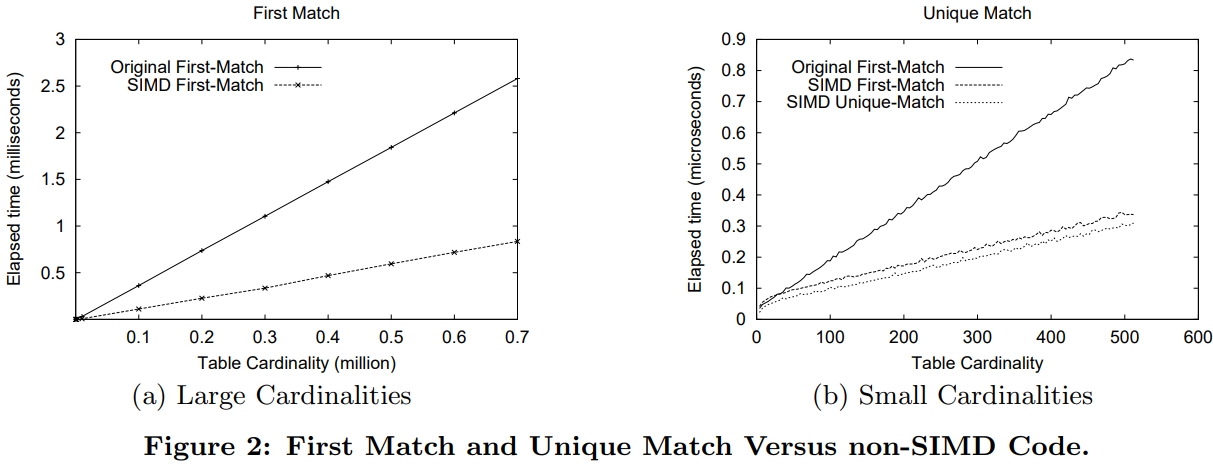
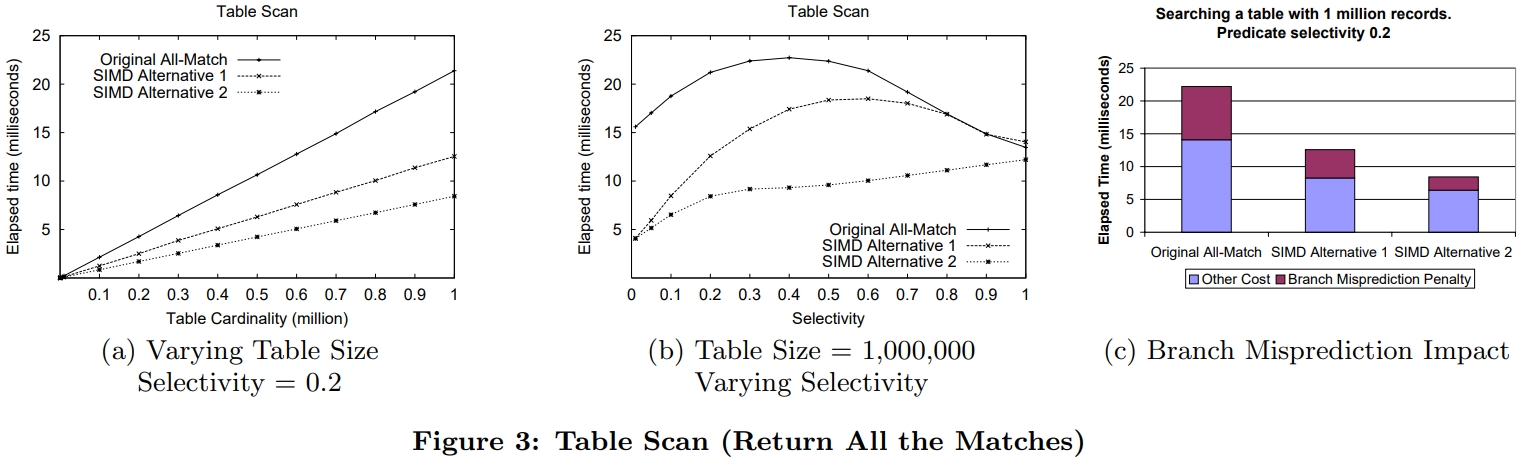
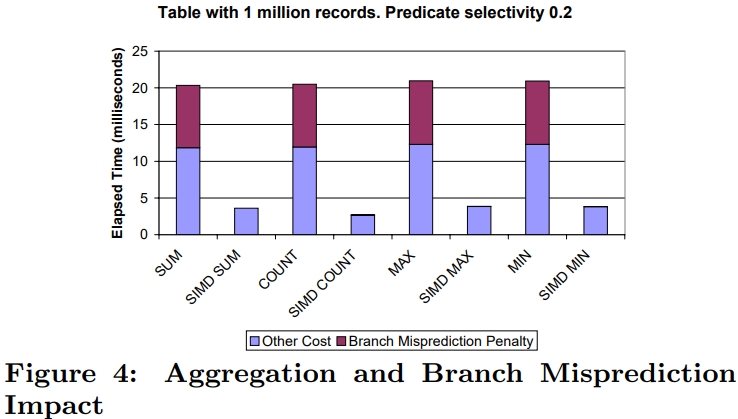
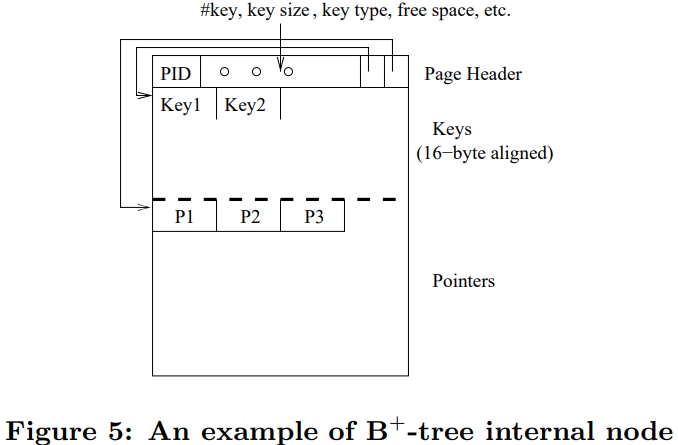
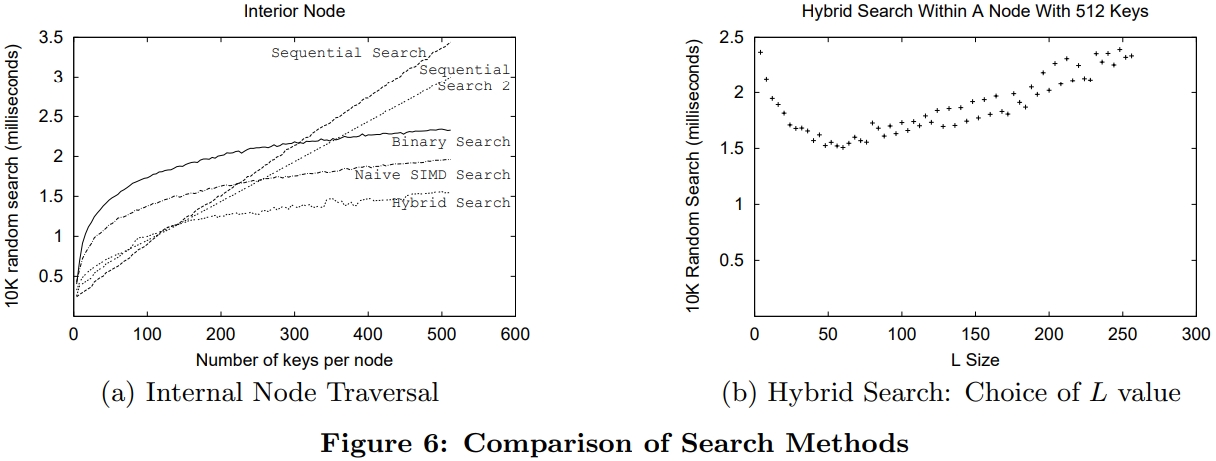
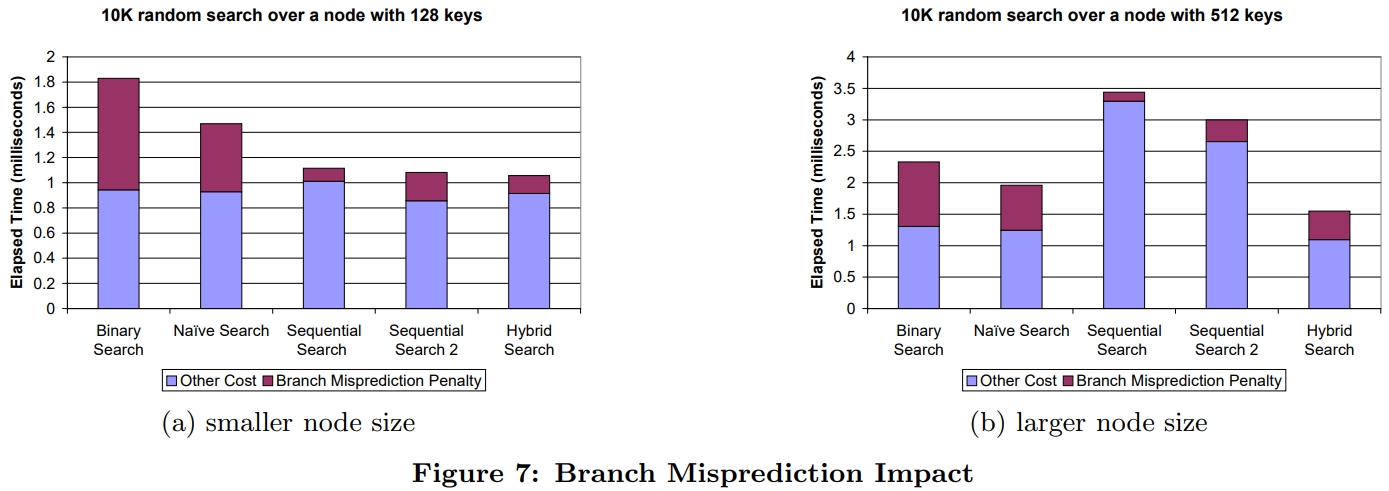
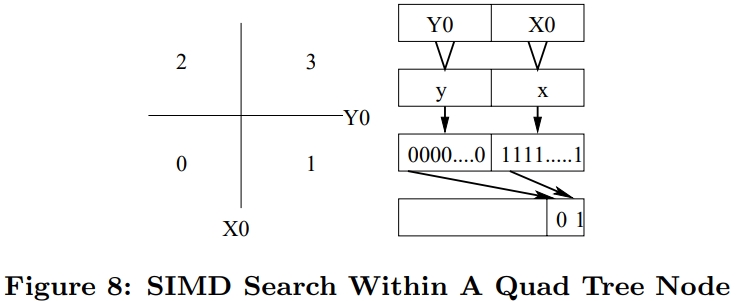
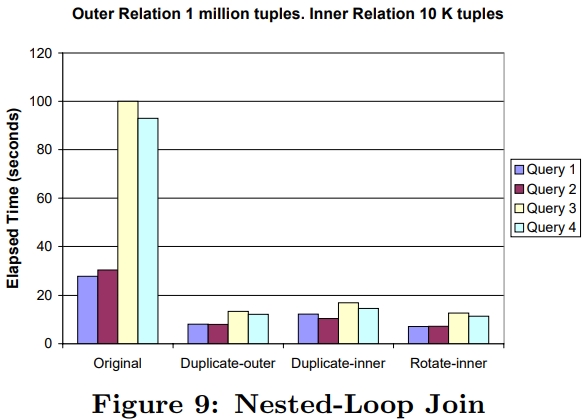
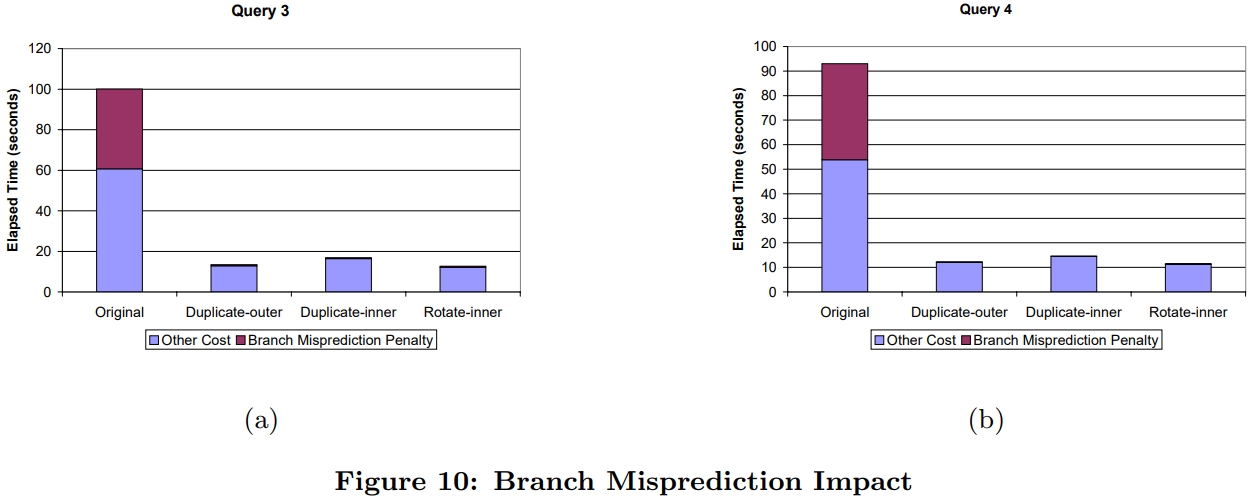
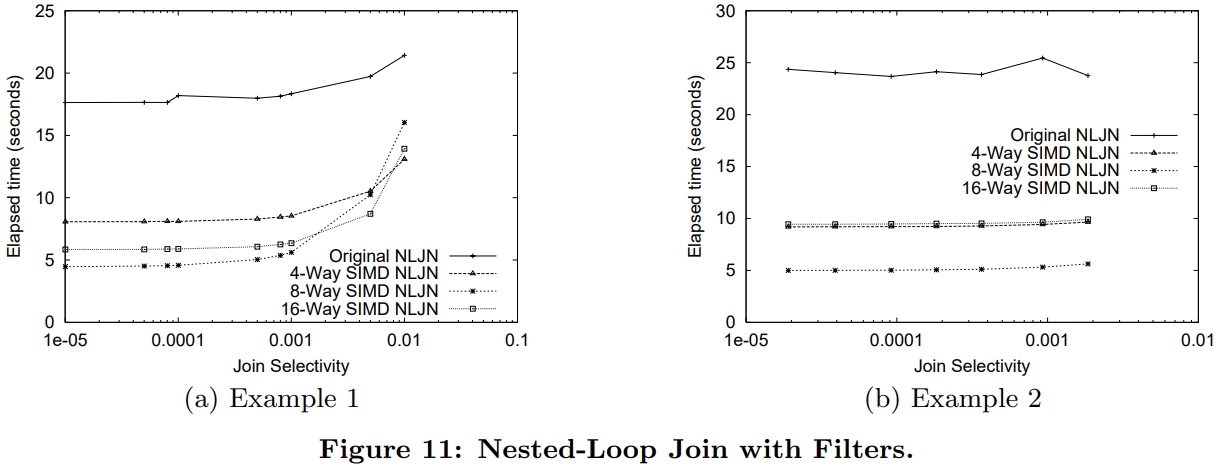
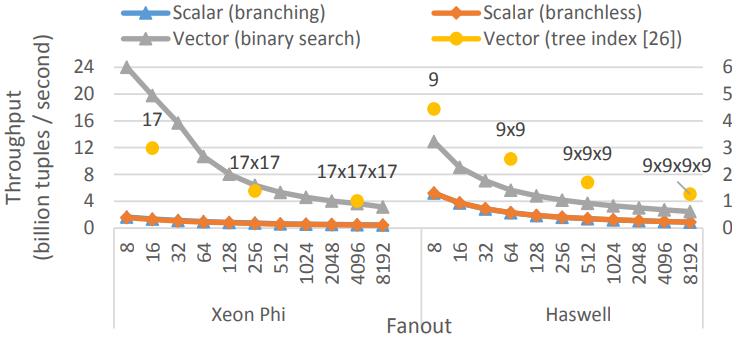
介绍了SIMD指令一些基本概念,并行流水线,以及分支预测失败带来的影响;论文中提到了使用SIMD指令的方式,以及不同平台产生的差异;之后用伪代码的方式描述几个数据库常用操作;scan操作详细对比了标量版和SIMD版的区别,以及如何消除分支的方式,还有返回选中的一个元素、多个元素的标量、SIMD方式;聚合的实现方式SIMD有提供相关的操作 SIMD_min、SIMD_max即可,对于索引部分主要是介绍树结构索引,详细讨论了中间节点、叶子节点的实现方式;在有序元素上使用二分效率是非常高的,但也会有分支预测失败问题,论文中给出了混合二分+顺序扫描方式;最后是join处理方式,这里只列出了nested-loop join的SIMD实现,Duplicate-outer、Duplicate-inner、Rotate-inner
阅读全文
2023年1月27日
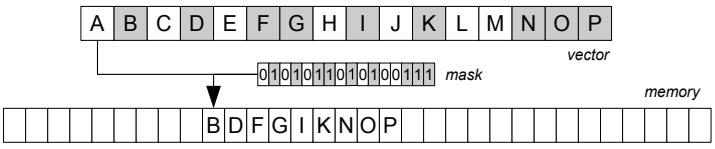
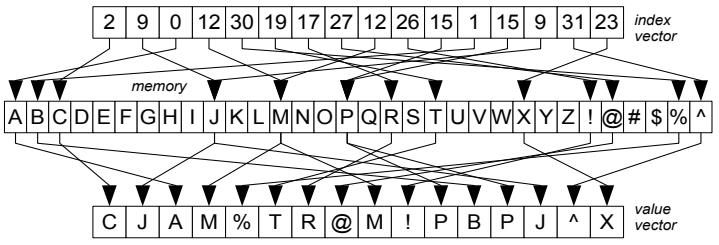
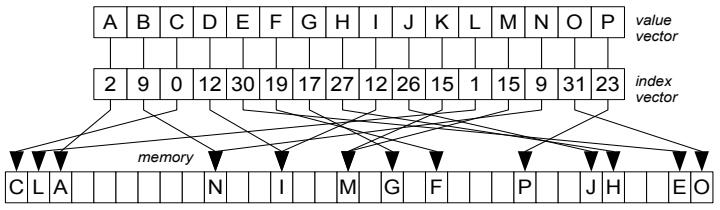
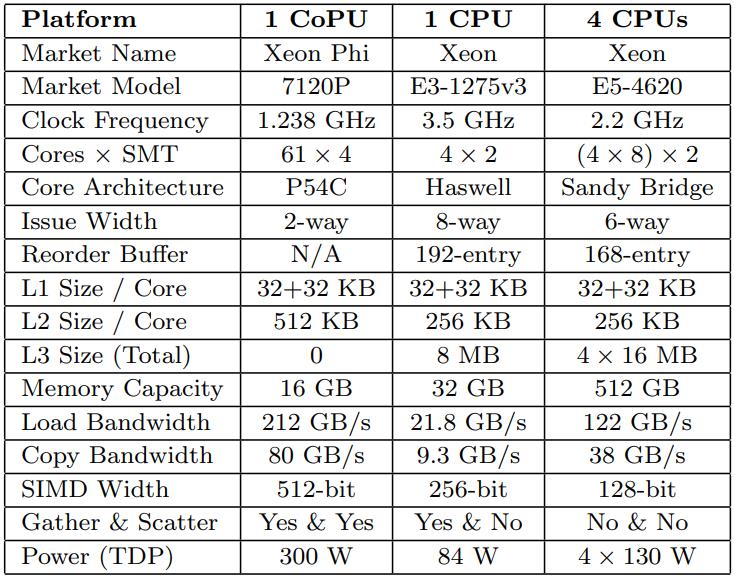
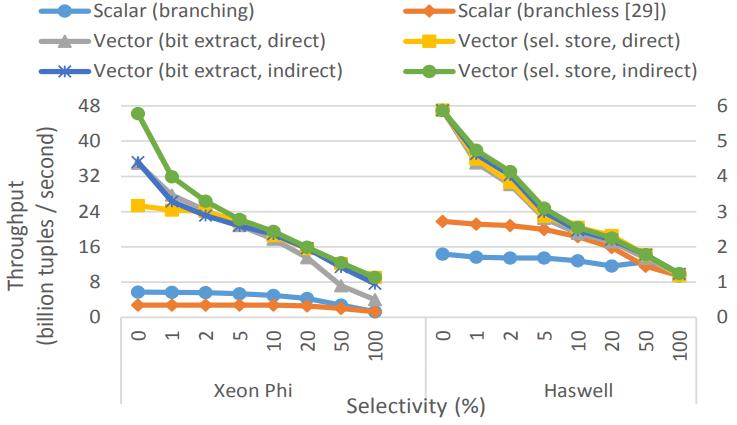
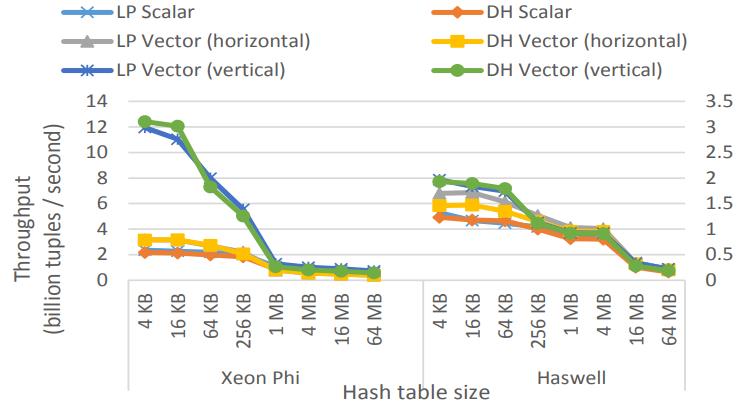
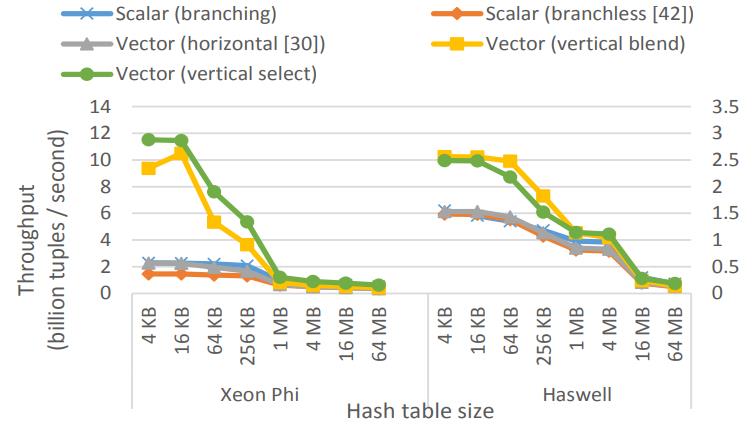
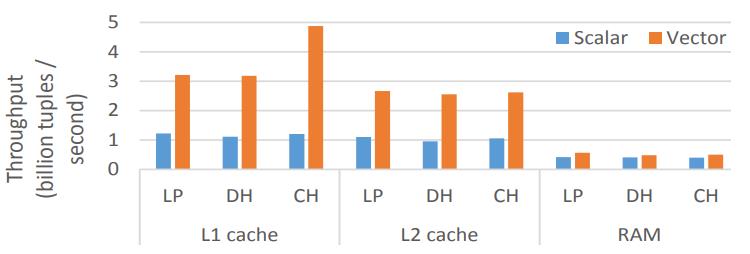
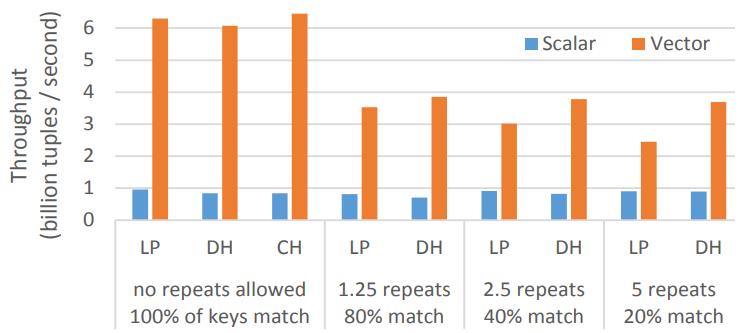
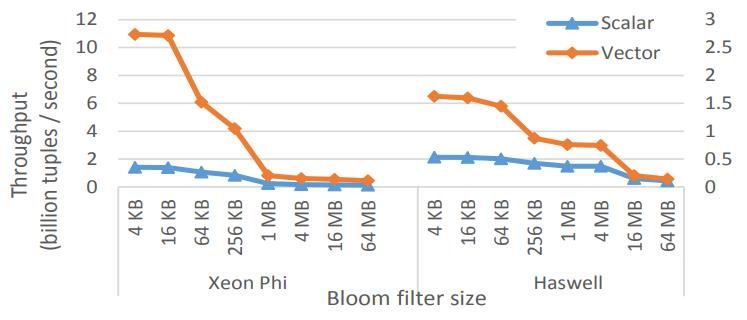
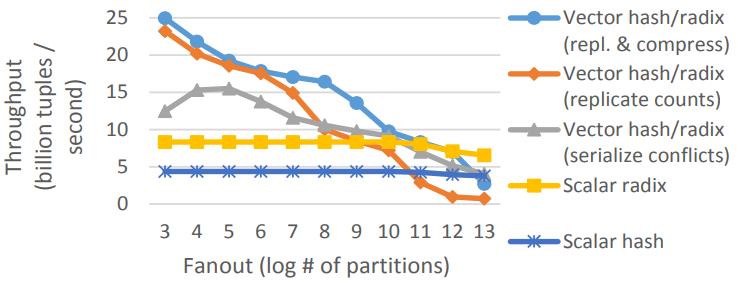
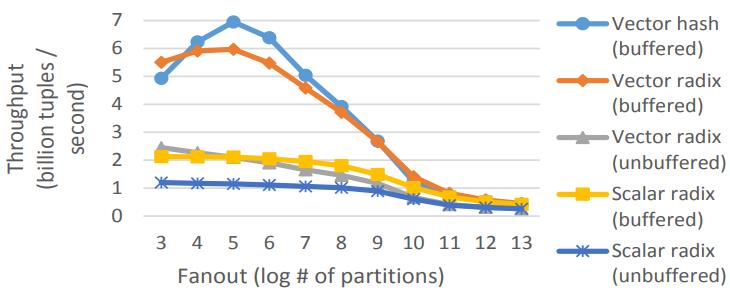
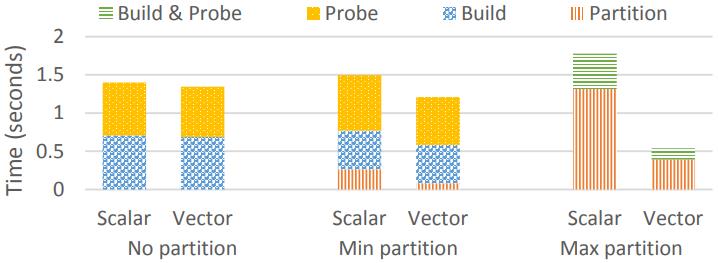
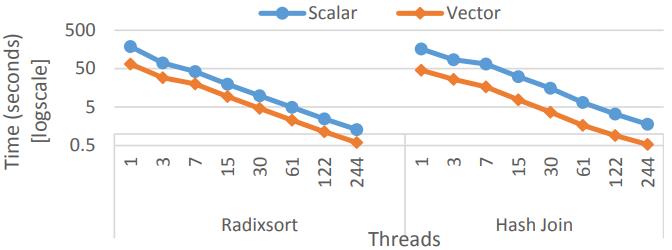
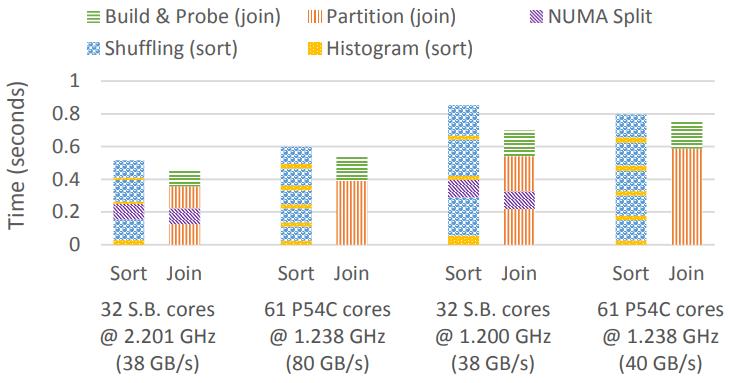
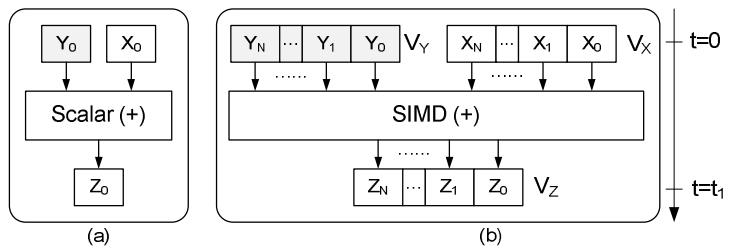
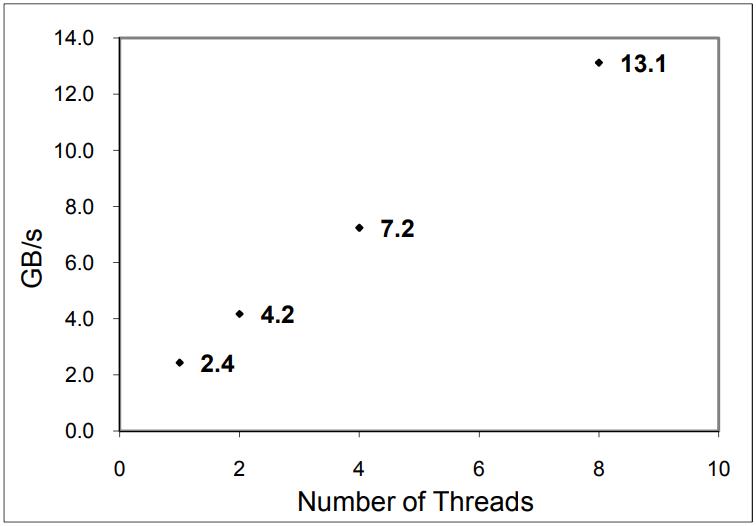
这是Oracle联合哥伦比亚大学做的研究,论文中讨重点讨论了数据并行化(线程、指令、数据),也就是SIMD实现;论文中给出了一些基本的SIMD操作,如selective sotre/load、gather、scatter,在论文发表的时候,这几个操作主流CPU不是全支持,只能通过一些模拟操作来支持,如permutation等;通过定义这四个最基本的操作,再往上就可以定义数据库查询中比较重要的操作了,如:scan、hash-table(horizontal、vertical、build、线性探测、double hash、cuckoo hash)、bloom filter、分区(radix、hash、range);通过hash、分区等操作,又可以定义出排序、join等更复杂的操作,相当于是层层搭积木;测试结果SIMD会有大幅度性能提升,但也受到cache size的影响
阅读全文
2023年1月19日
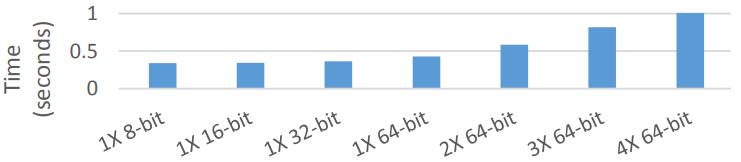
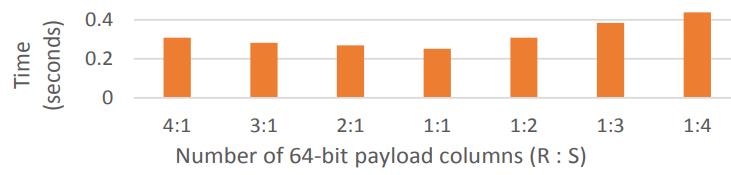
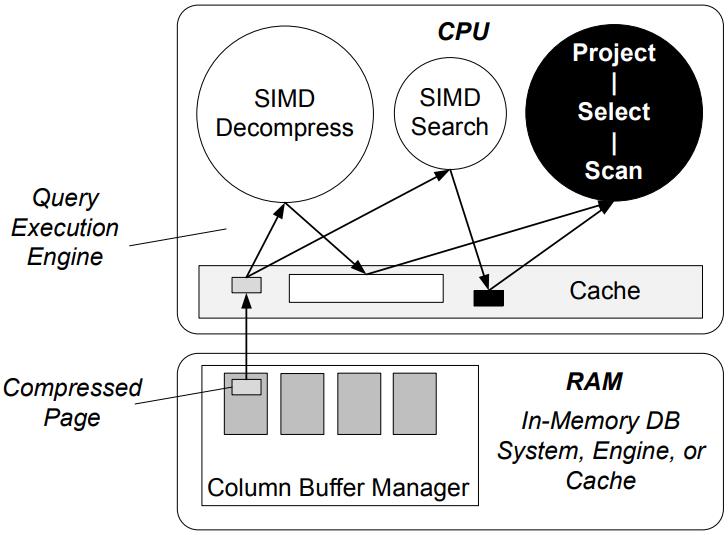
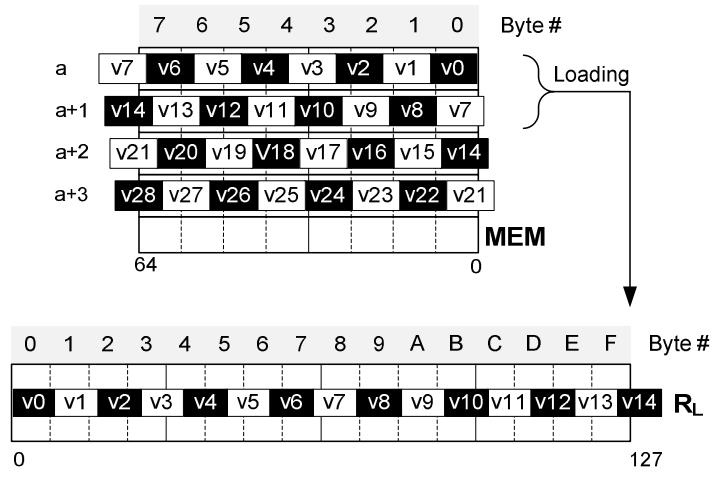
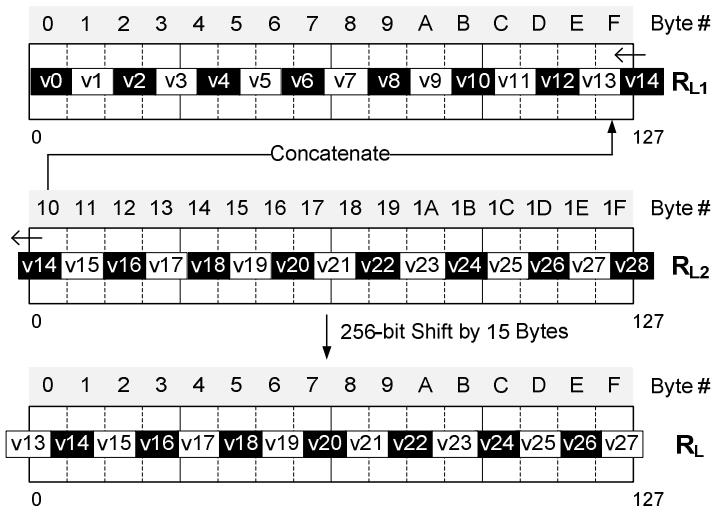
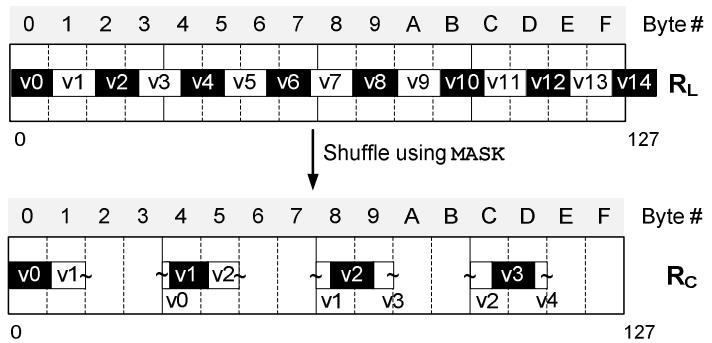
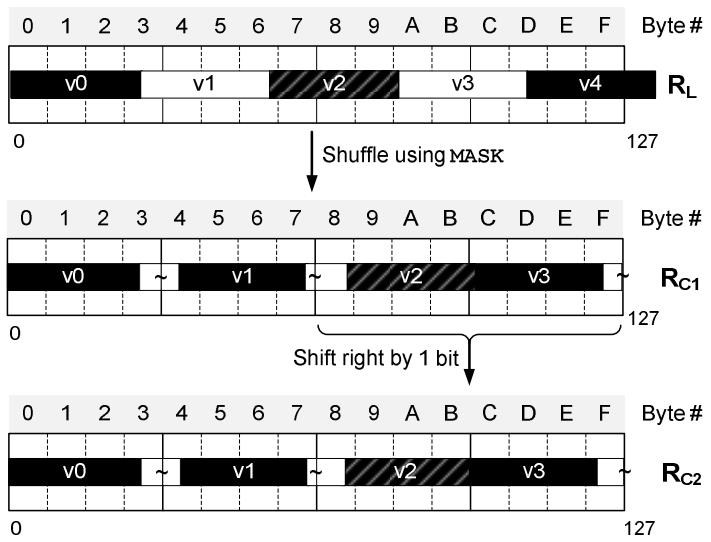
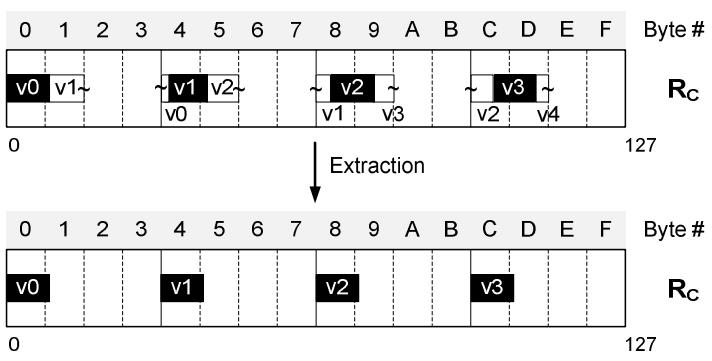
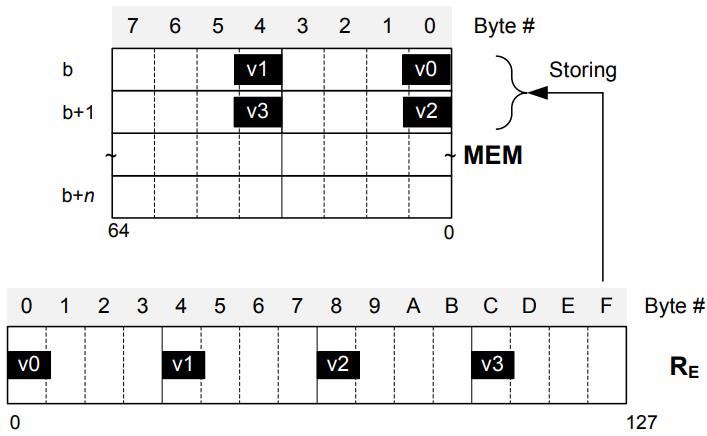
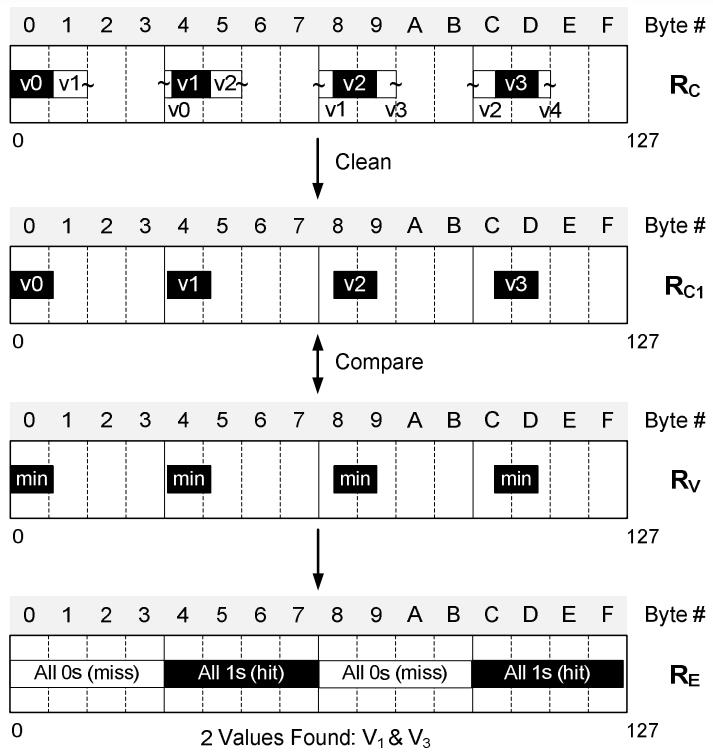
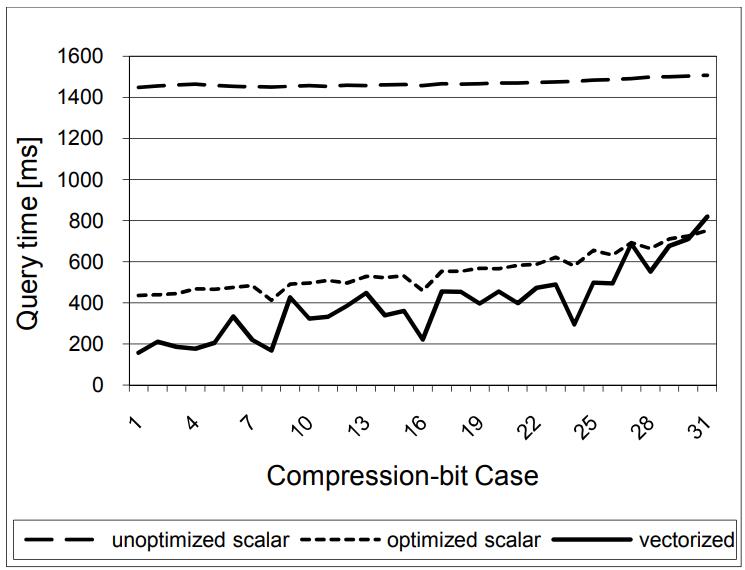
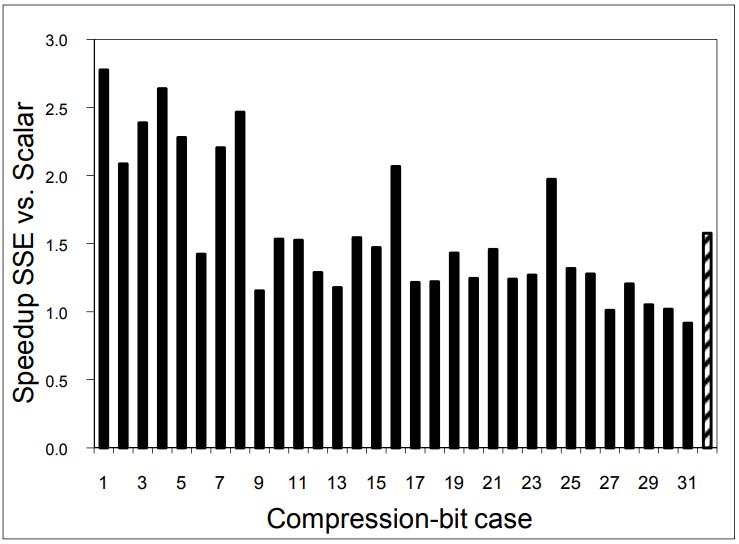
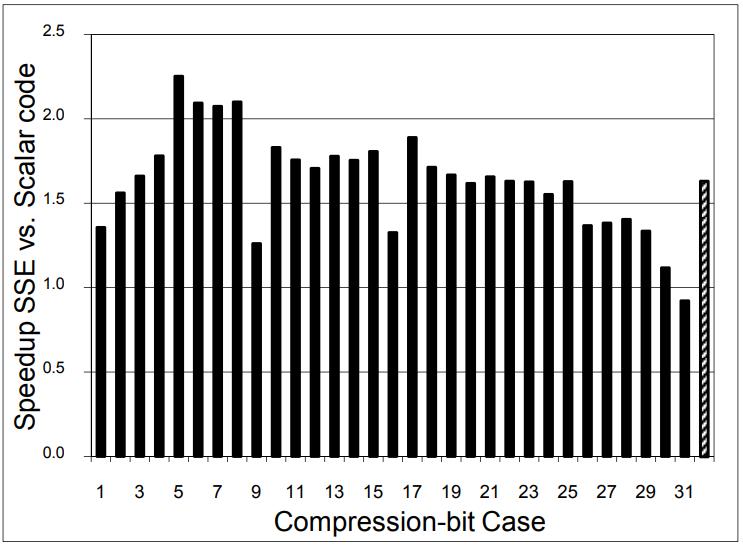
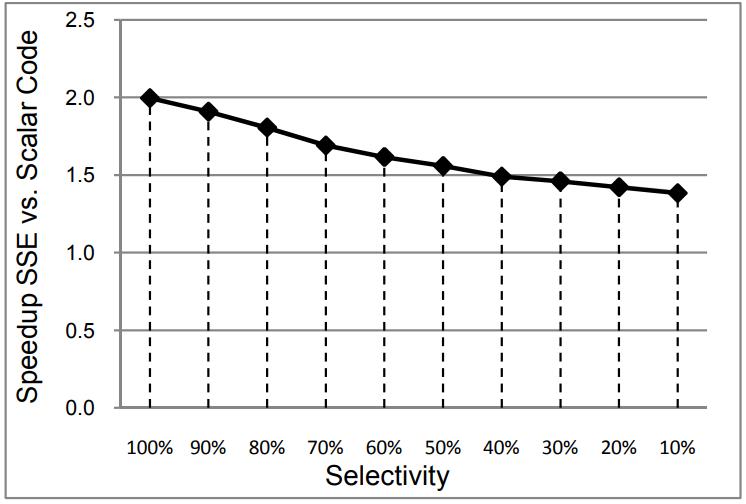
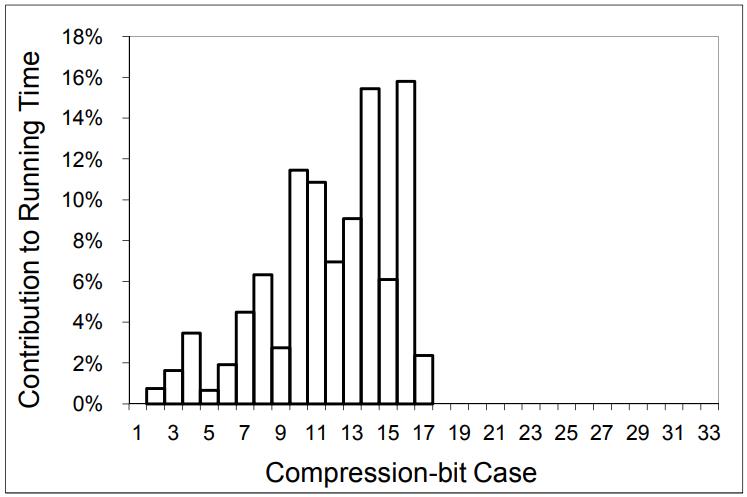
现代数据库由I/O瓶颈转向了CPU瓶颈,利用多核能力加速全表扫描,但是向量化的能力没能充分发挥。使用向量化包括:内嵌汇编、硬件厂商提供的跨平台库函数、编译器指示符、编译器自动优化,每种都是可用性和可控性之间的权衡。论文中引入了两项优化:使用SIMD方式在寄存器中解压 轻量压缩数据(使用concatenate、shift、shuffle、mark等指令完成);使用SIMD完成等值和范围查找(使用掩码指令,将4个元素加载到寄存器中,再通过min、max比较范围,最后生成索引数组向量位),通过测试结果都有大幅度提升,并且优化实现可以适用各种数据库
阅读全文
2023年1月17日
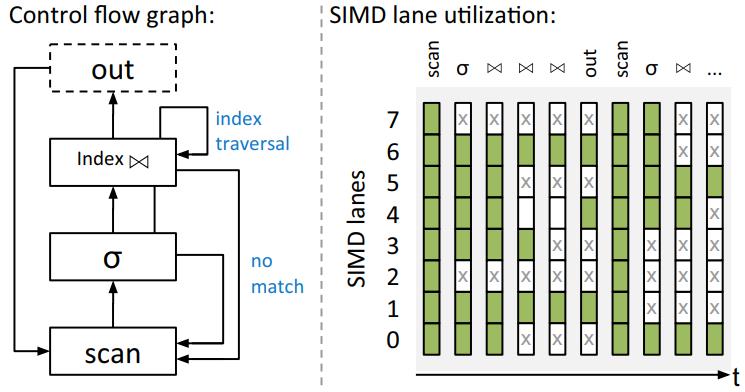
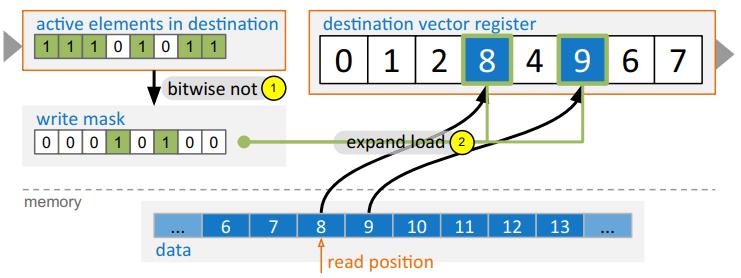
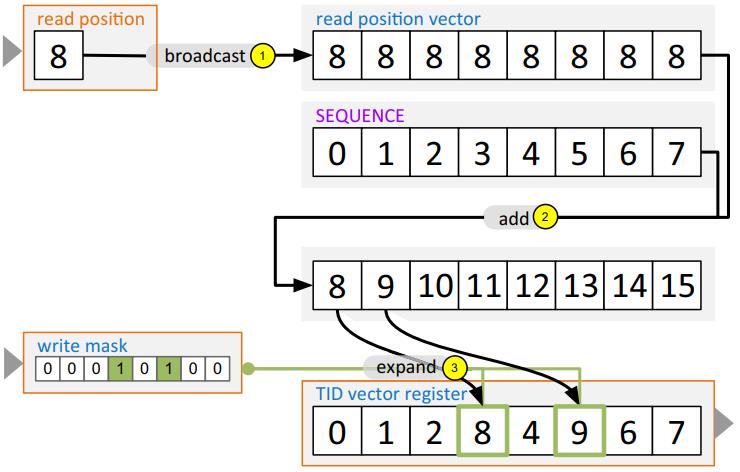
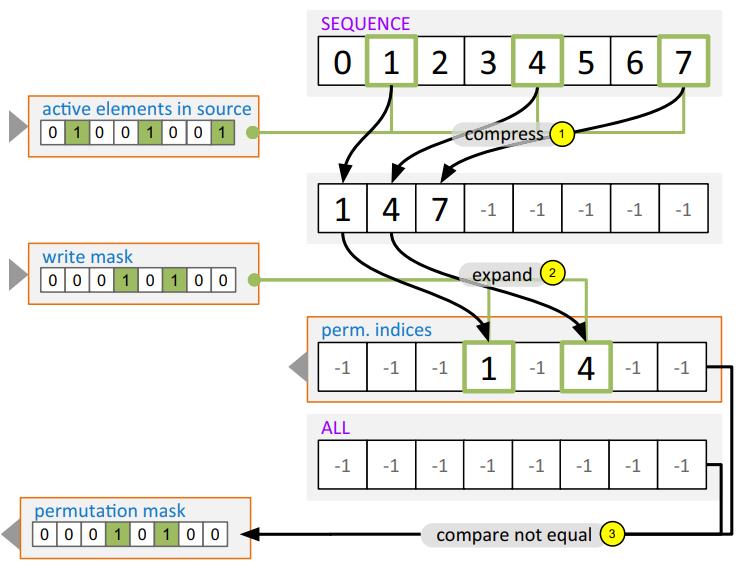
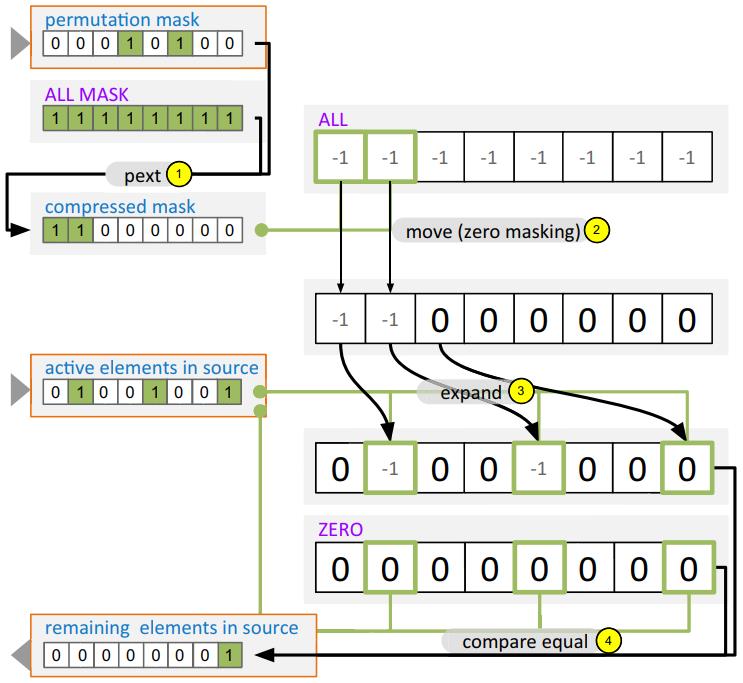
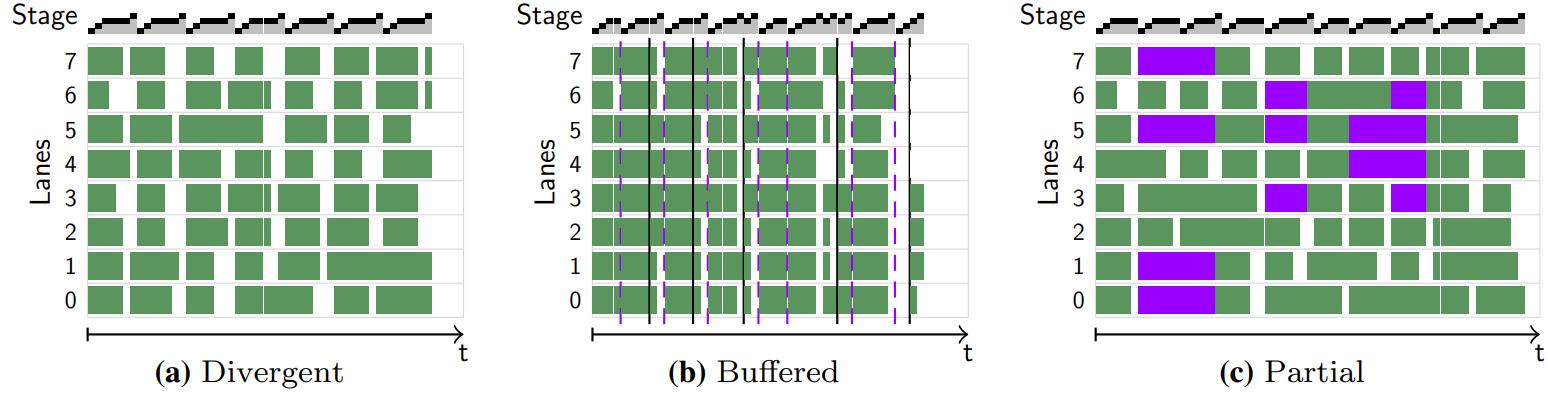
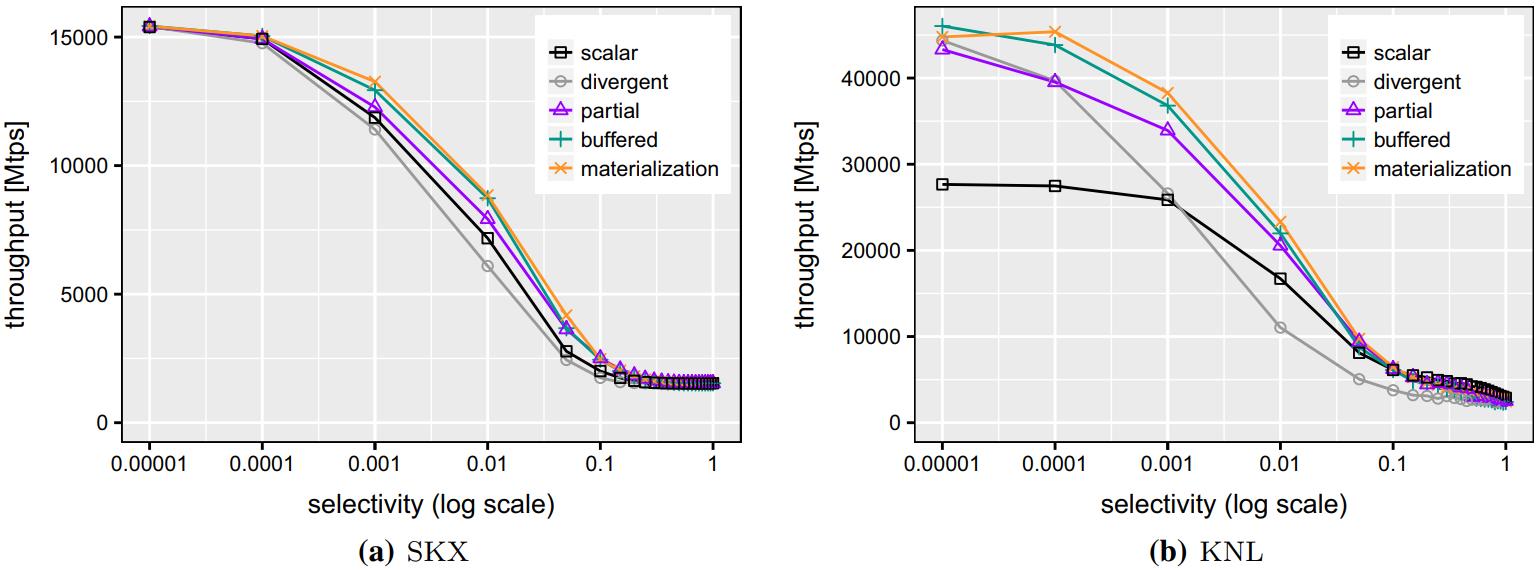
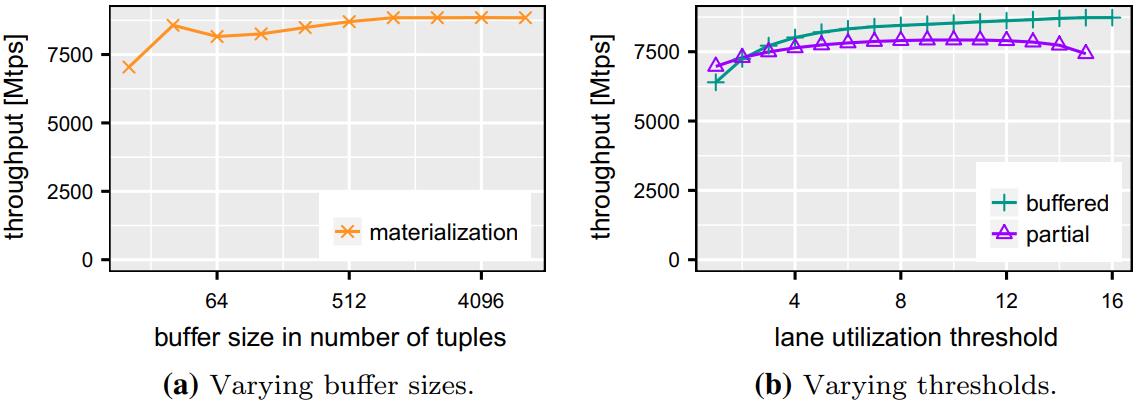
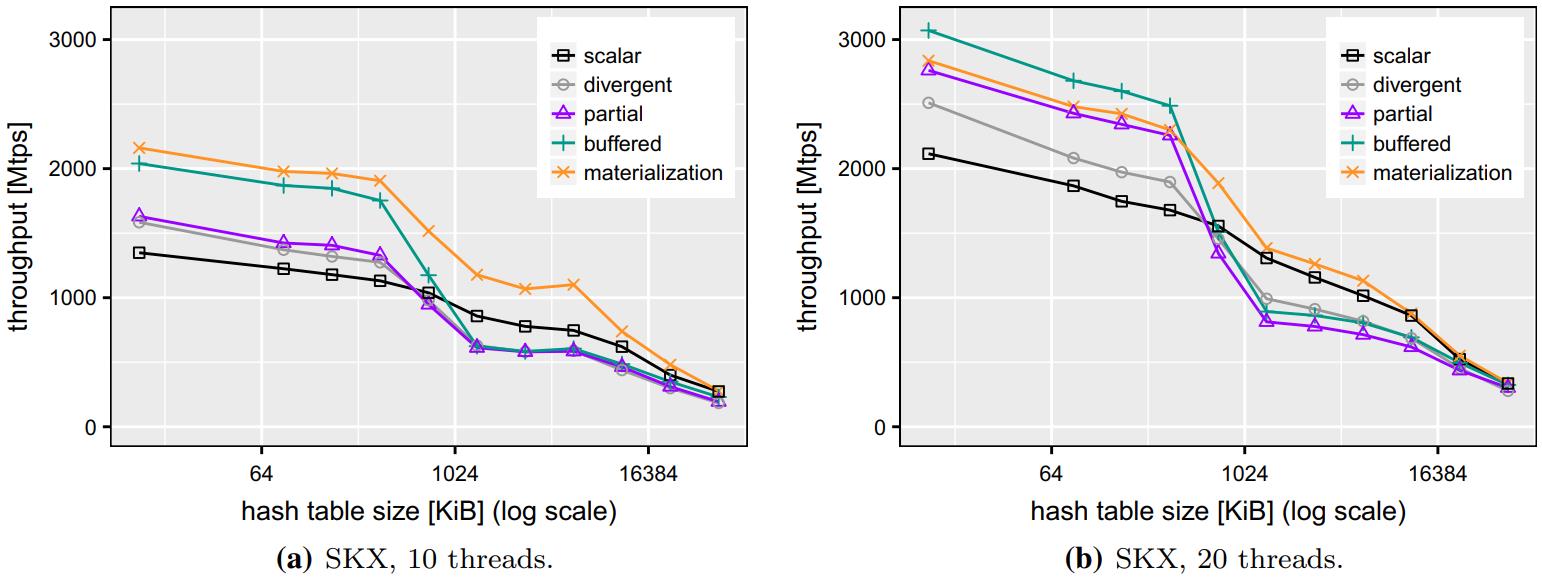
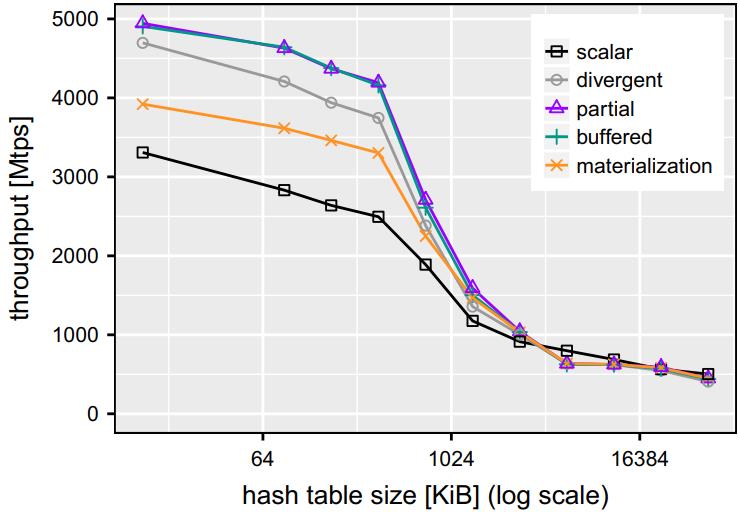
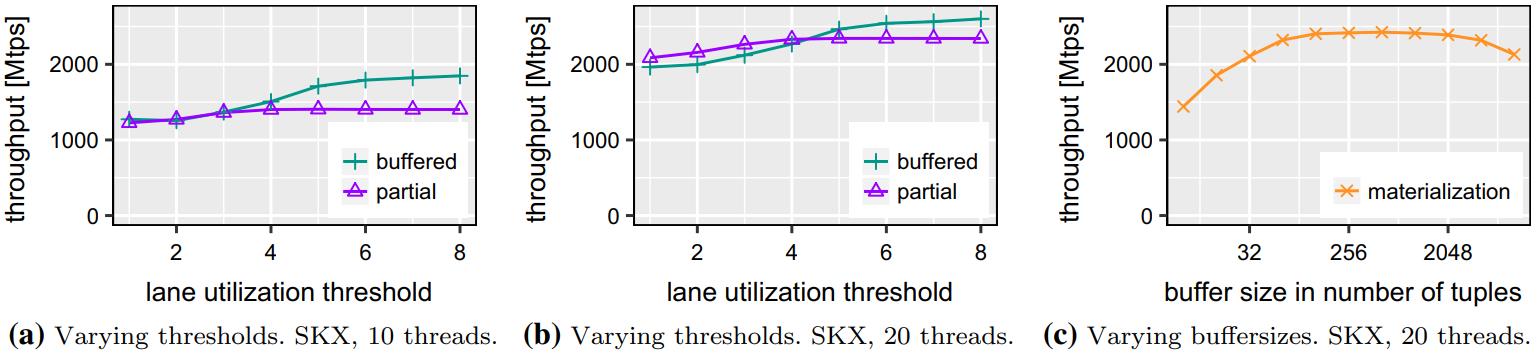
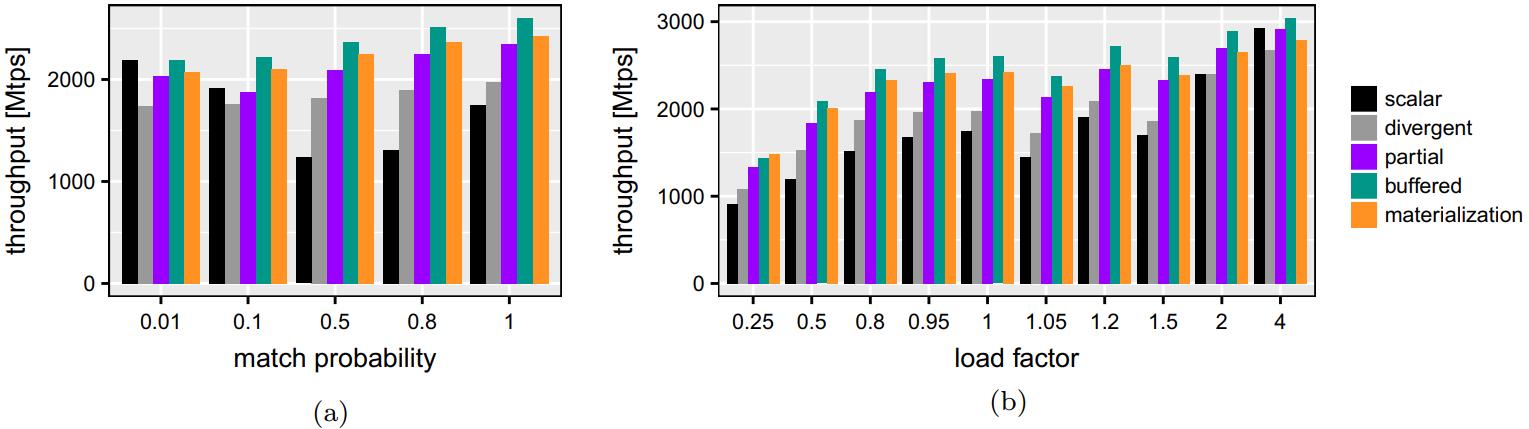
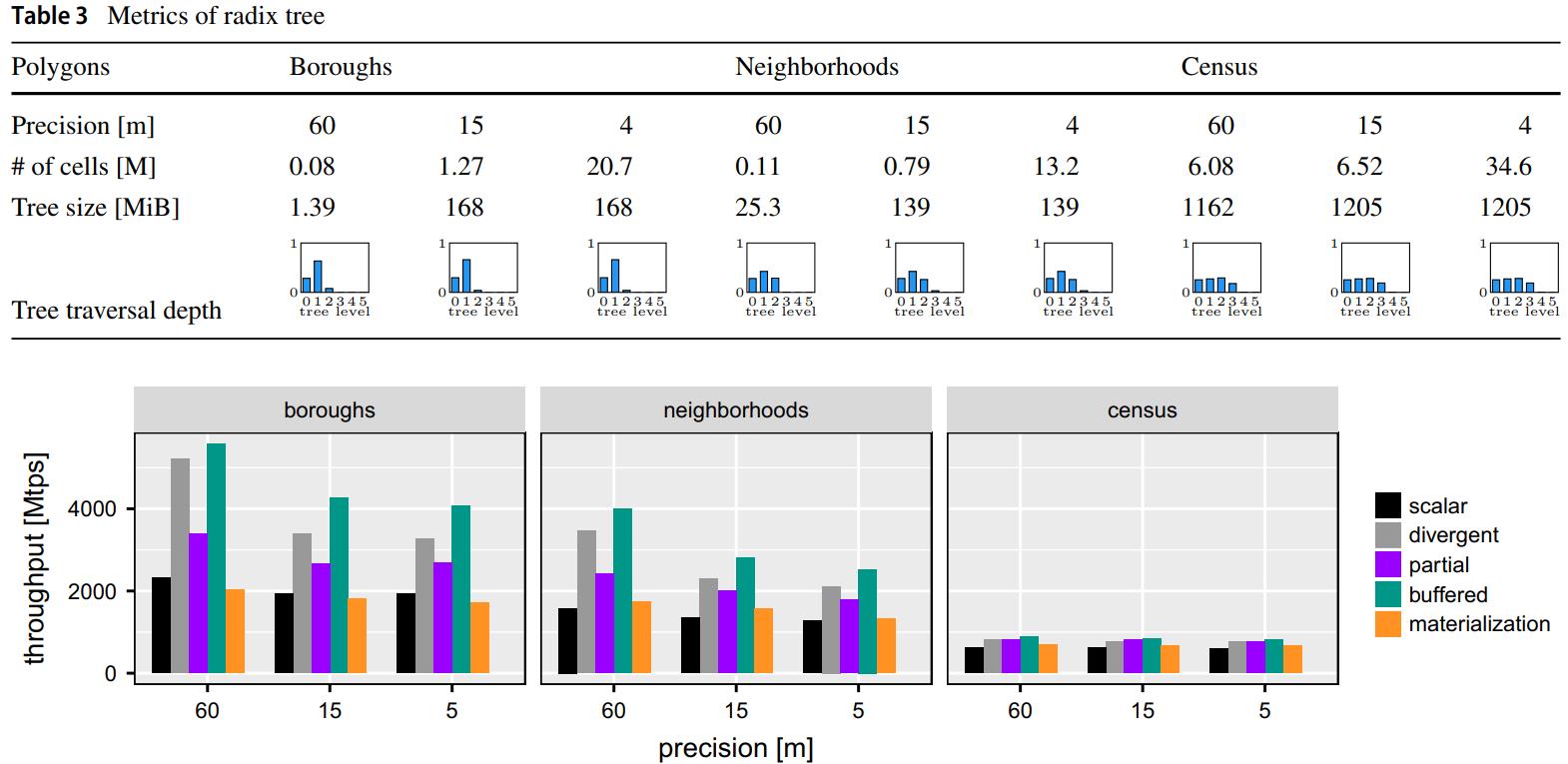
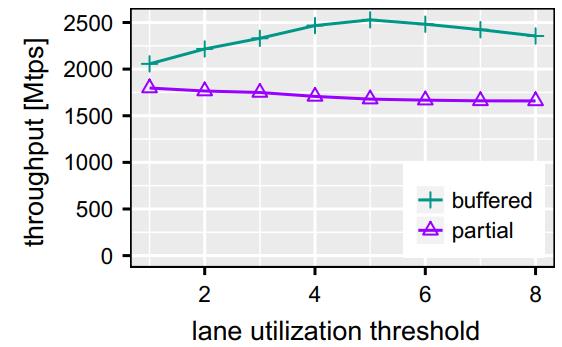
现代数据库很多都采用了向量化执行,也就是利用 SIMD 指令,SIMD指令在碰到分支时,会出现部分元素不满足条件,导致不活跃影响利用率吞吐量下降,论文中利用了 AVX512指令集的:mark指令、permute指令、compress、expand,来实现重填充算法和策略;包括:全消费策略(需增加寄存器,主要利用buffer),以及部分消费策略(增加新寄存器,利用mark),在能放入cache的场景中,这两种算法表现的都不错,是scalar的两倍,但对于复杂场景,以及cache放不下的场景则表现退化,另外如何设置 阈值也是一个开放问题
阅读全文