分布式数据库课程中的论文
基础部分
总结
- 分布式数据库特性:写多读少、低延迟、海量并发、海量存储、高可靠性、关系型数据库
- 分布式数据库内部演化视角
- 客户端组件 + 单体数据库,sharding-jdbc
- 代理中间件 + 单体数据库,mycat
- 单元化架构 + 单体数据库
- 一致性模型
- 分布式系统,探讨当系统内一份逻辑数据存在多个物理副本时,对其读写操作会产生什么影响,CAP理论
- 数据库领域,于事务相关,进一步细化到ACID四方面
- 数据一致性
- 状态一致性 state consistency,数据所处的客观、实际状态所体现的一致性
- 操作一致性 operation consistency,外部用户通过协议约定的操作,能够读取到的数据一致性
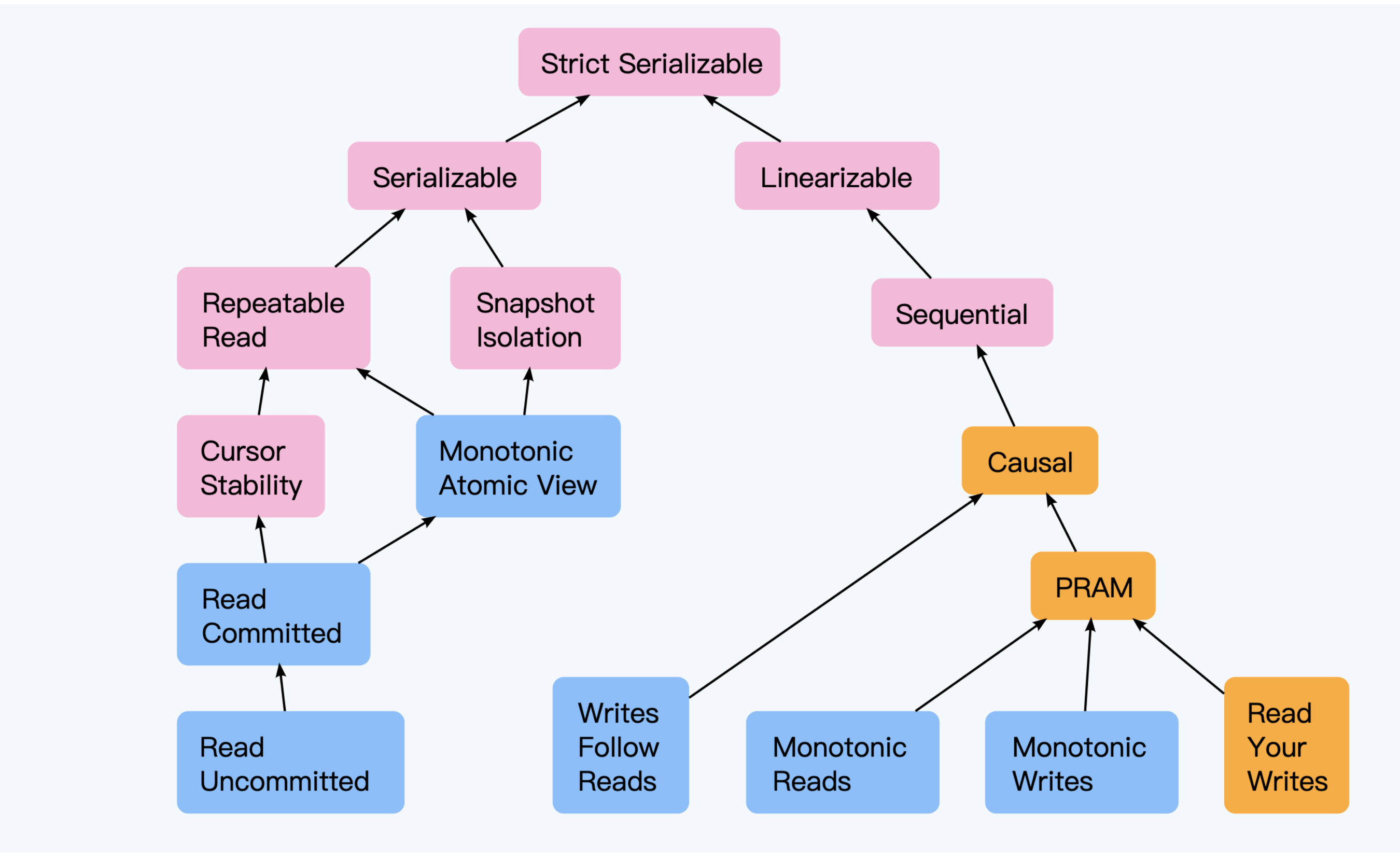
- 强一致性
- 弱一致性,最终一致性
- 写后读一致性,读自己写一致性
- 单调读一致性
- 前缀一致性,因果关系
- 线性一致性 linearizability,全局时钟
- 因果一致性,逻辑时钟
- 排序:线性一致性 > 顺序一致性 > 因果一致性 > {写后读一致性、单调一致性、前缀一致性}
- 其他:
- 有限旧一致性
- 会话一致性
- 单调写一致性
- 读和写一致性
- 事务一致性
- WAL
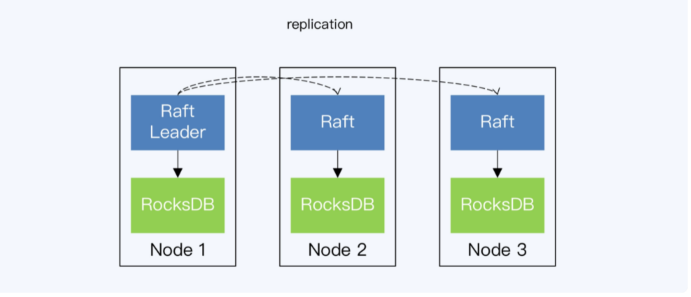
- 主从复制、基于paxos/raft的共识算法日志数据
- SQL-92定义的四种隔离级别没有考虑到快照问题,少了一些情况
- 幻读和写倾斜
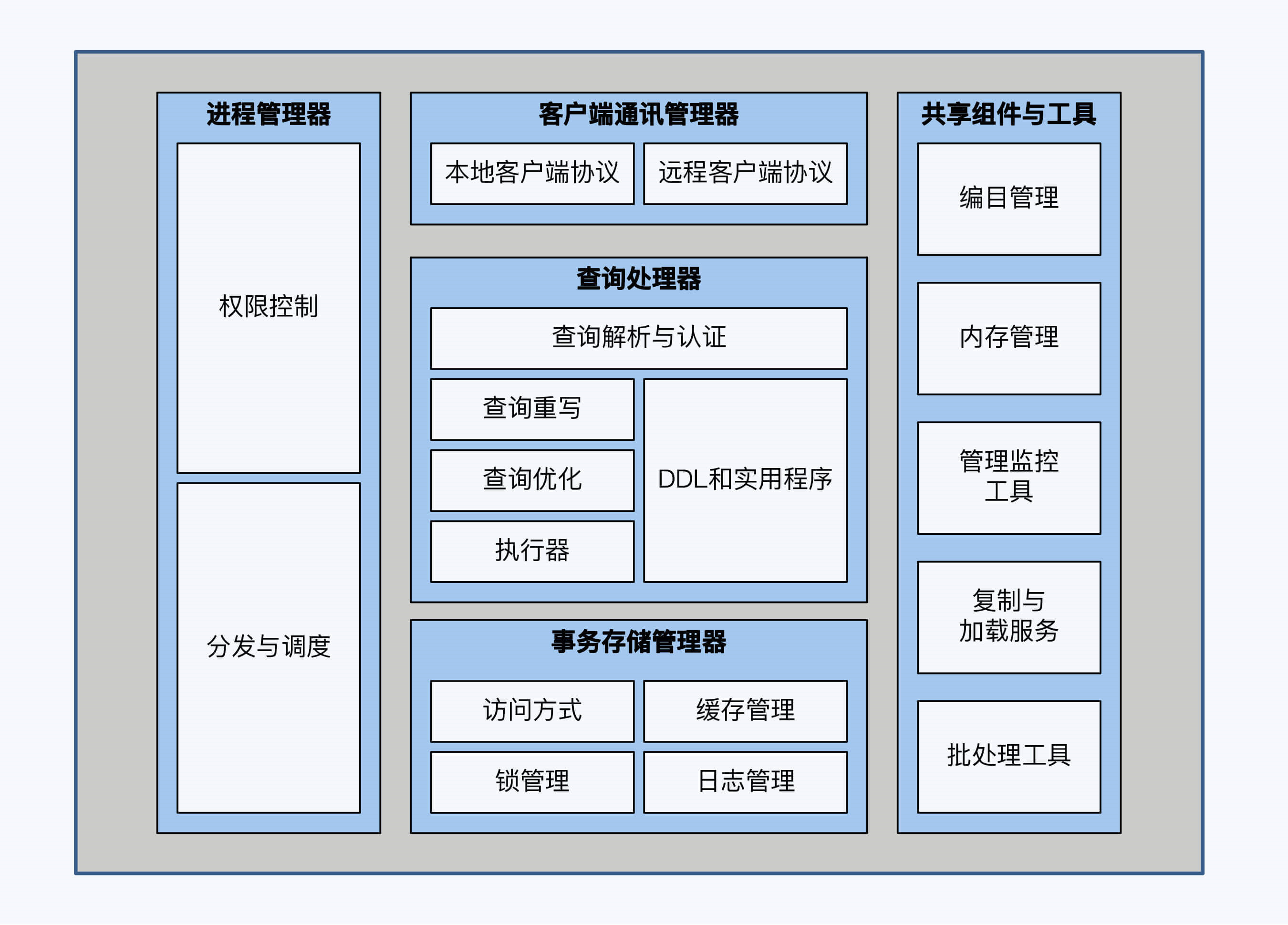
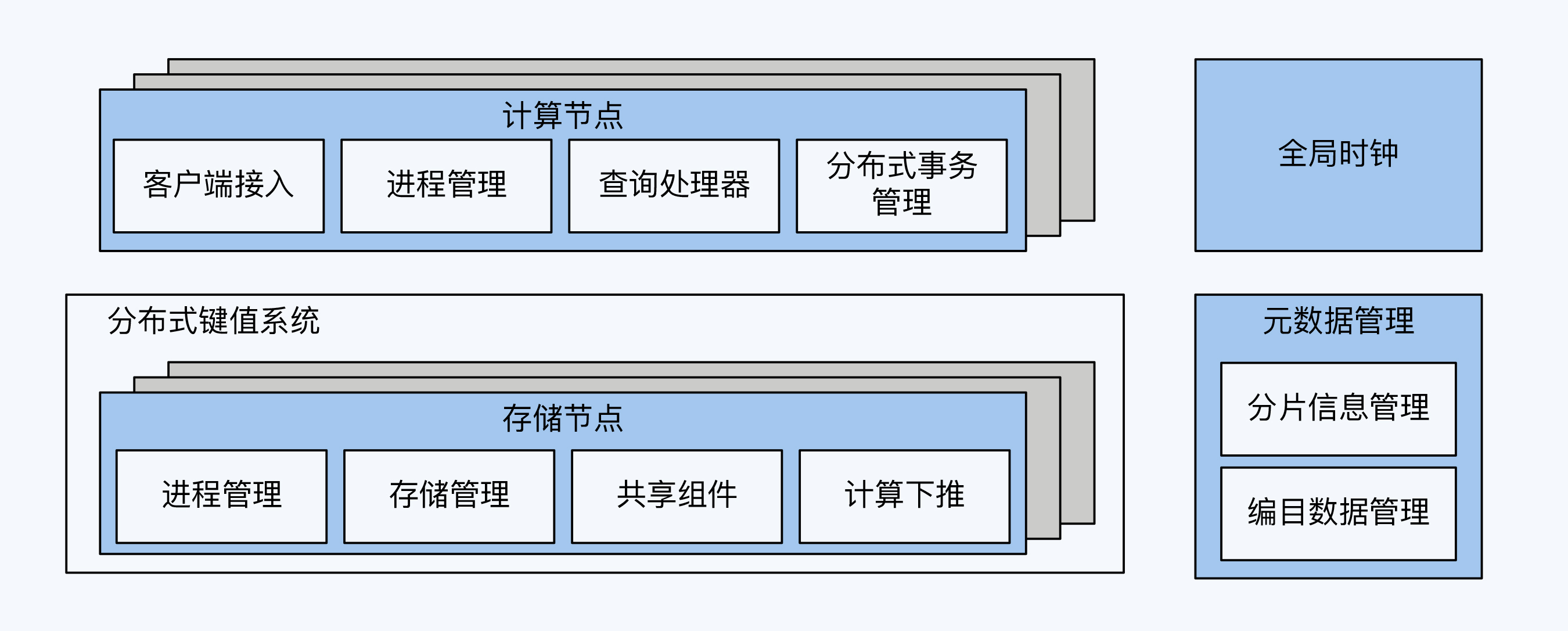
- 数据库的基本架构
- 客户端通讯管理器
- 进程管理器
- 查询处理器
- 事务存储管理器
- 共享组件和工具
- 架构风格
- PGXC 单体数据库演进的架构
- NewSQL风格,spanner架构
- 全局时钟
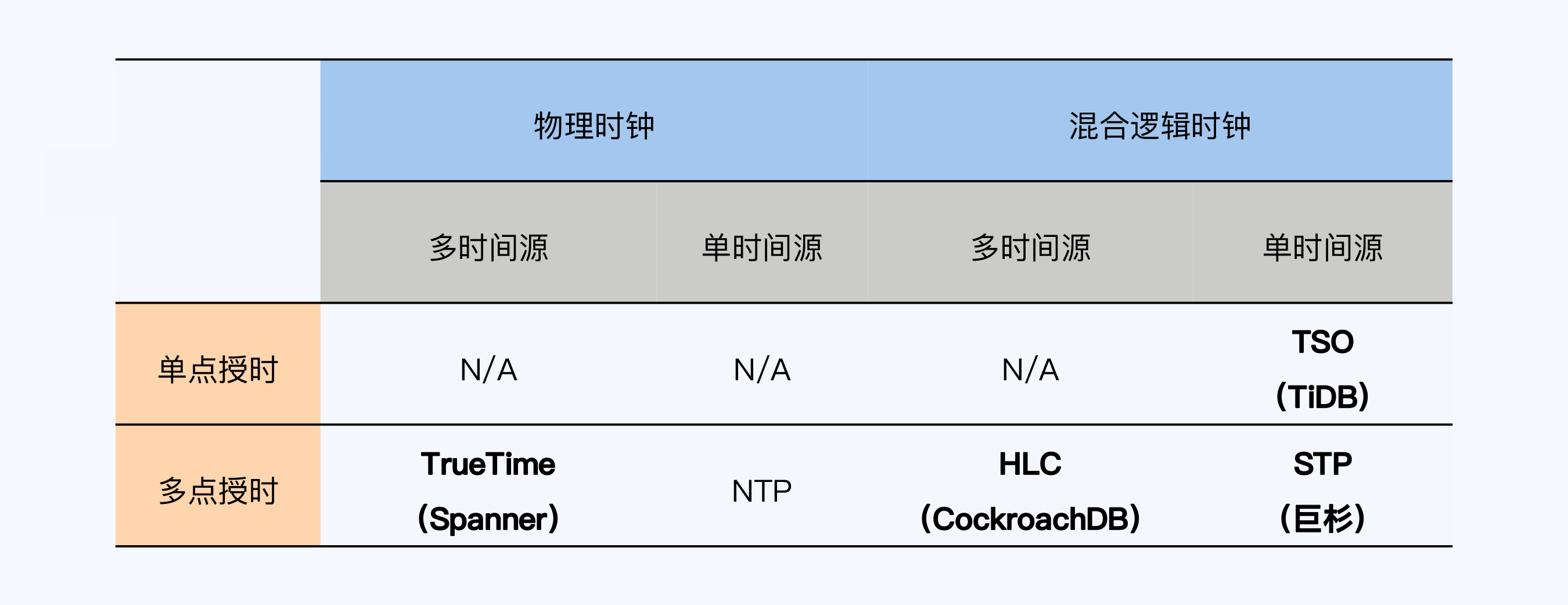
- 时间源:单个还是多个
- 使用的时钟类型:物理时钟、混合逻辑时钟
- 授时点:一个还是多个
- 分类
- TrueTime,多时间源 + 多点授时 + 物理时钟
- HLC,多时间源 + 多点授时 + 混合逻辑时钟
- TSO(Timestamp Oracle),PGXC架构中的GTM,单时间源 + 单点授时 + 混合逻辑时钟
- STP(SequoiaDB Time Protocol)巨杉数据库的方式,单时间源 + 多点授时 + 混合逻辑时钟
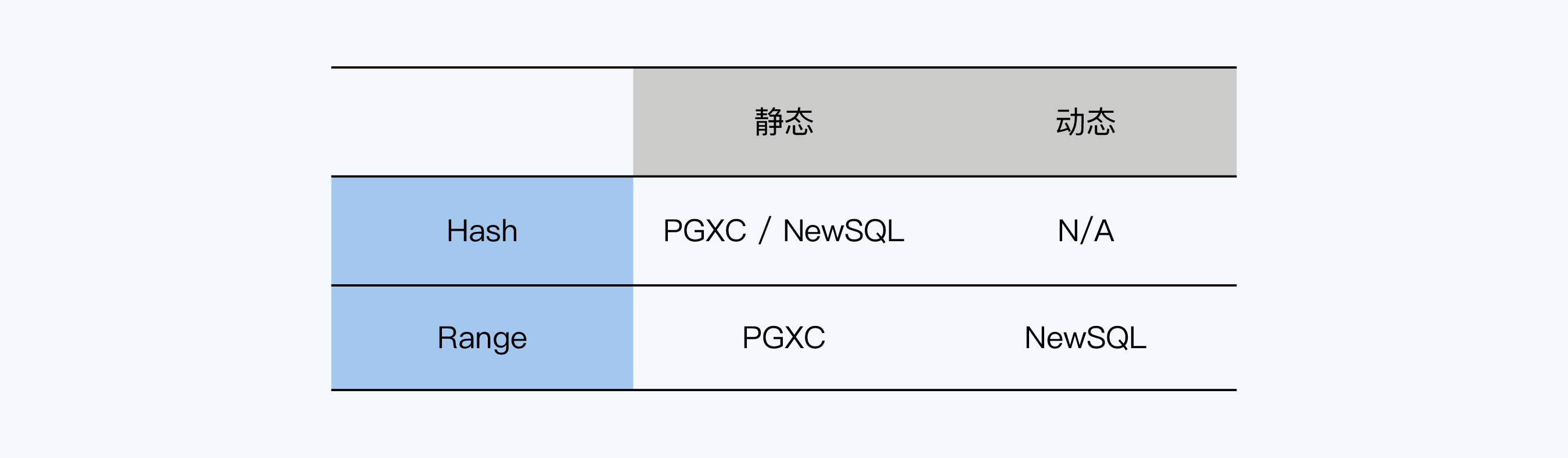
- 分片策略
- hash分片,一致性hash;属于静态分片,写性能好
- range分片-静态,PGXC风格 查性能好
- range分片-动态,newsql风格,如bigtable这样的
- 分片 + 共识
- 数据复制
- 静态分片
- TiDB,无存储状态,每次上报全副本,方便raft选主
- CockroachDB,去中心化,采用p2p方式大规模部署效率高
- raft复制的问题:基于顺序投票,不能出现空洞
- TiDB的raft优化
- 批操作提交日志
- 流水线,没发送一个batch后,不等follower,立刻进行下一个
- 并行追加日志,发送给follower的同时,并发执行本地的append日志
- 异步应用日志
分布式数据库的强一致性
左边的是事务一致性,最高等级是:可串行化;右边是数据一致性,最高等级是:可线性化
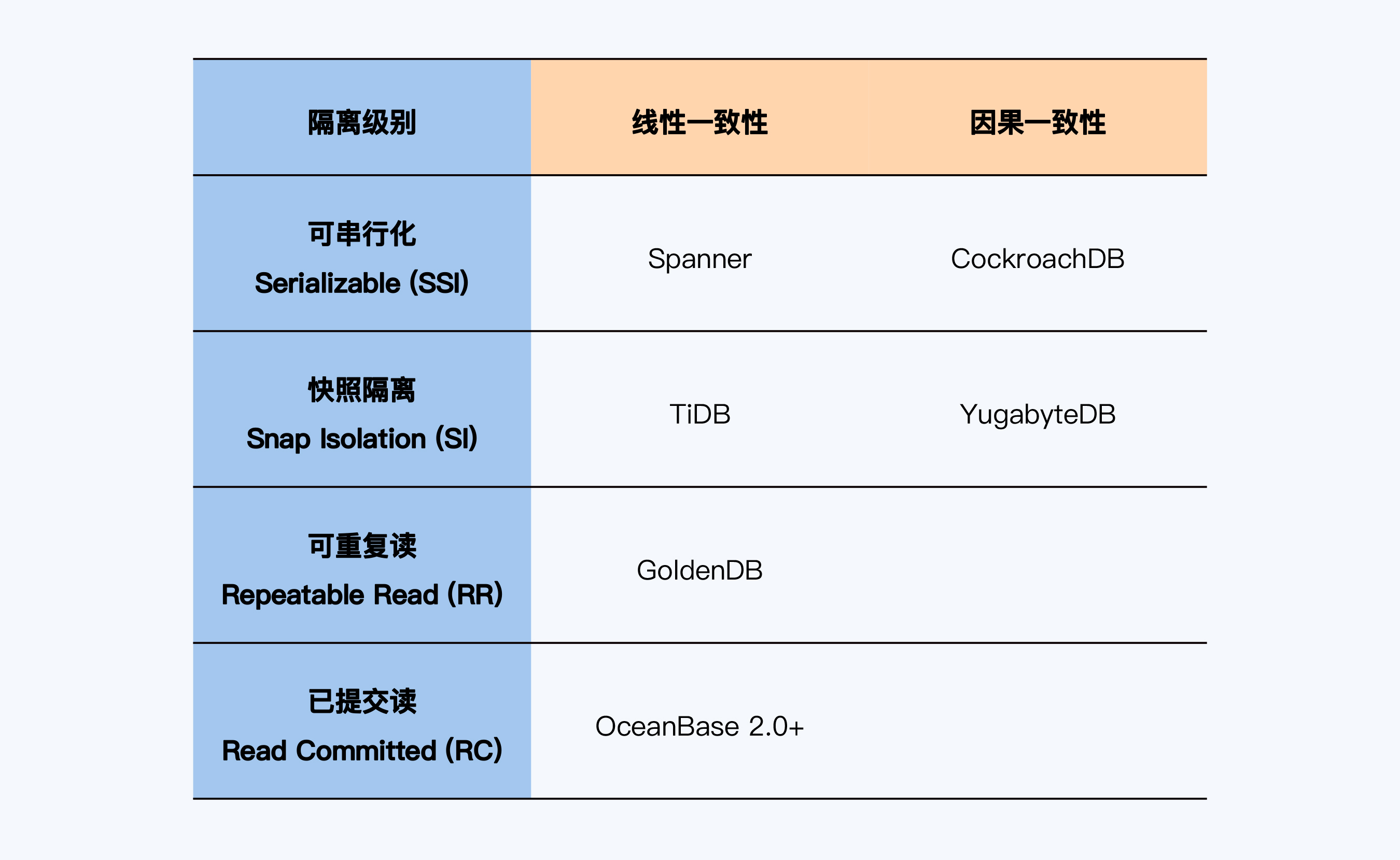
不同数据库的一致性比较
数据库的架构风格
PGXC风格的架构
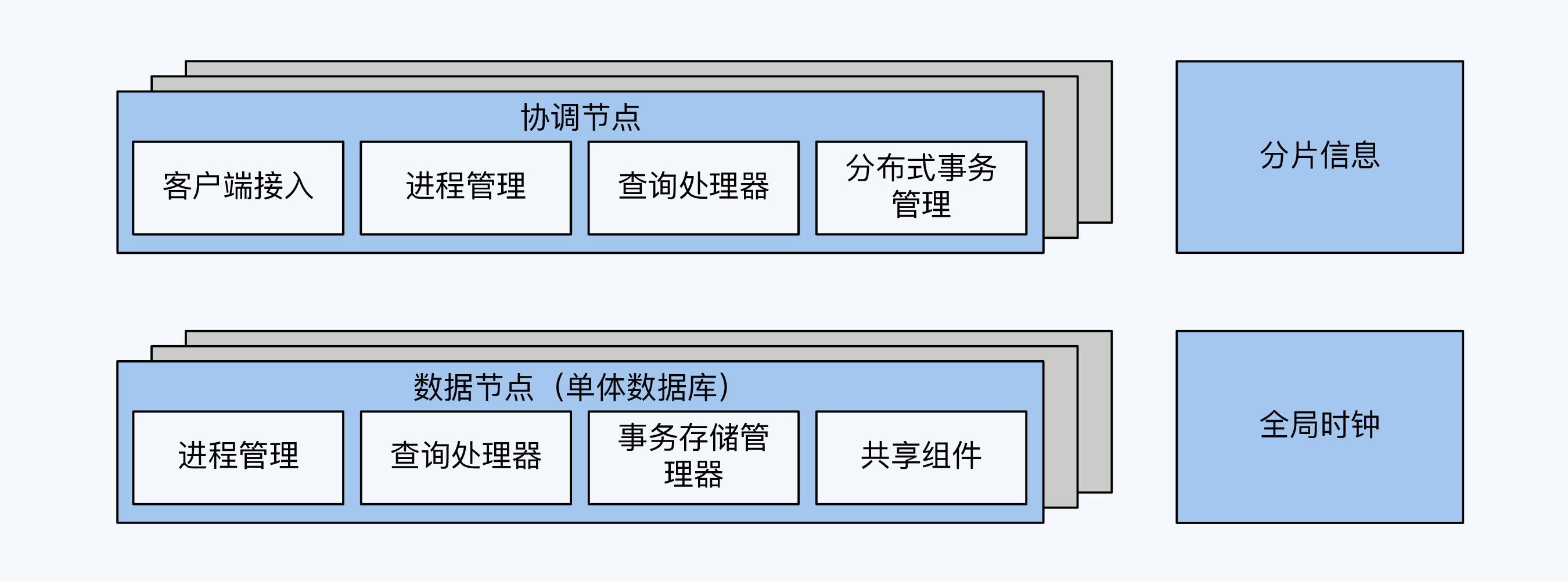
NewSQL风格的架构
全局时钟的设计方式
分片类型
论文
- 谷歌的论文 Failure Treads in Large Disk Drive
- The many faces of consistency
- Lamport’s Paper: Time,Clocks, and the Ordering of Events in a Distributed System
- Consistency levels in Azure Cosmos DB
- A Critique of ANSI SQL Isolation Levels
- Highly Available Transactions:Virtues and Limitations
- Jepsen网站简化版
- Architecture of a Database System
- 《数据库系统实现》
- Large-scale Incremental Processing Using Distributed Transactions and Notifications
- Logical Physical Clocks
- Consistent Hashing and Random Trees
- Bigtable: A Distributed Storage System for Structured Data
- Hbase reference
- spanner
分布式事务
总结
- 原子性
- Either all the changes from the transaction occur(writes, and messages sent), or none occur.
- 实现事务原子性的两种协议
- 面向应用层的TCC,try confirm cancel
- TCC是应用层的分布式事务框架,完全依赖应用层编码
- 面向资源层,2PC协议
- 2PC的问题:同步阻塞、单点故障、数据不一致
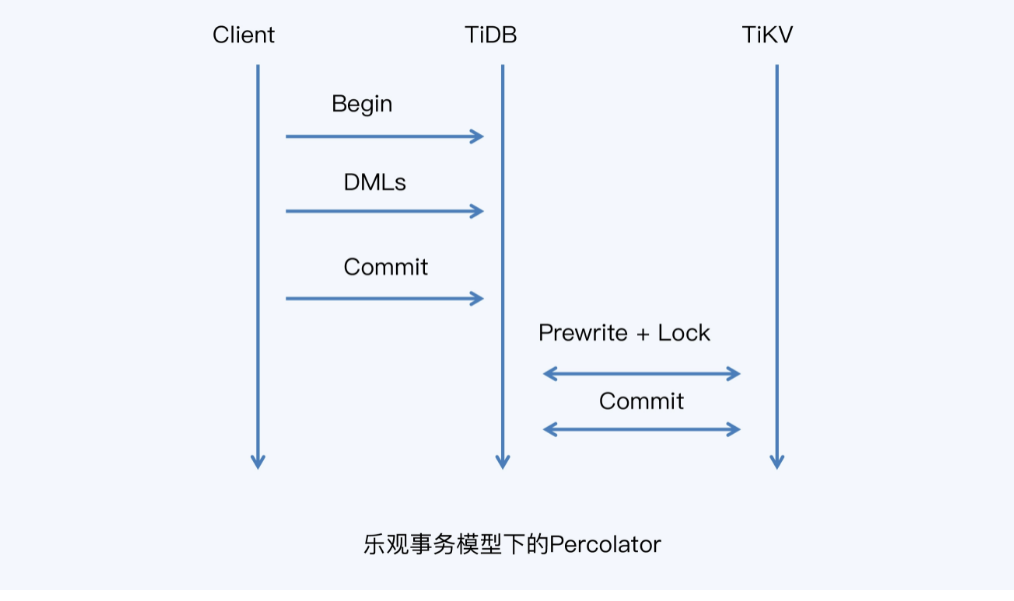
- 2PC的改进,NewSQL的Percolator
- 需要数据库支持MVCC 多版本并发控制
- 多个节点中只有一个节点拥有 主锁primary key,其他事务参与者指向主锁
- 提交阶段就记录主锁,并记录最终数据(暂时不可见)
- commit阶段,将主锁去掉,之后在读其他分片时,根据指向的主锁记录,可以认定为最终提交成功
- 实际会有异步线程来处理从节点数据中的:指向主锁的信息
- 2PC中的不一致,因为事务管理器只和主锁通信,单节点本身就是原子的,即可以解决一致性问题
- 异步线程在事务管理器宕机后回滚分片上的事务
- 事务管理器通过记录日志使自身无状态化,日志通过共识算法保存在其他节点
- TiDB、CockroachDB都使用了Percolator算法
- GoldenDB的一阶段提交
- 这是标准的PGXC架构,其实分为两个阶段
- 第一阶段,GoldenDB的协调者收到事务后,在全局事务管理器的全局事务列表中将事务标记为活跃状态
- 协调节点把一个全局事务拆分成若干子事务,分配给对应的MySQL去执行
- 并发控制从锁调度 改为 时间戳排序
- 事务的延迟
- 2PC的延迟公式: Ltxn = Lprep + Lcommit, prep是准备、commit是提交延迟
- 准备阶段 Lprep = R * Lr + W * Lw
- 读时 读本地,可以忽略,所以延迟又等于: Lprep = W * Lw
- 而分布式需要多轮共识的,所以延迟等于: Lprep = W * Lc
- 提交阶段,只有共识,所以: Lcommit = Lc
- 总延迟为: Ltxn = (W + 1) * Lc
- TiDB,缓存写提交
- 缺点,长事务+海量并发,会成为瓶颈;MySQL是【first write win】,TiDB变成了【first comit win】语义变了
- 管道,CockroachDB采用的方式,相当于最慢的一个写操作延迟
- 整体延迟:Ltxn = 2 * Lc
- 并行提交,把prep和commit也做成并行的
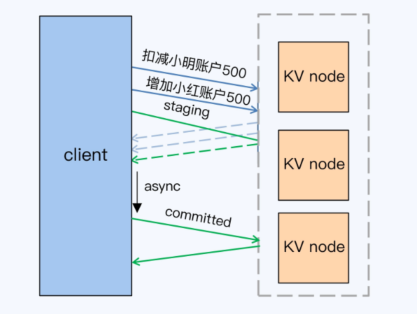
- 准备阶段,在CockroachDB中称为意向写,引入一个新的状态 “staging”表示正在进行事务
- 意向写中的key,是留给后面异步线程的线索,通过这些key是否写成功,可以倒推出事务是否提交成功
- 客户端提交事务后就直接返回了;之后由异步线程根据事务表中的线索,再次确认事务的状态,并落盘维护状态记录
- 2PC的延迟公式: Ltxn = Lprep + Lcommit, prep是准备、commit是提交延迟
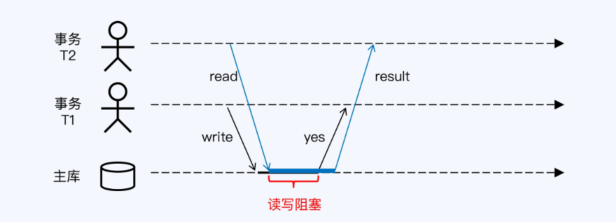
- 读写冲突
- 多版本并发控制 Multi-Vesin Concurrency Control MVCC
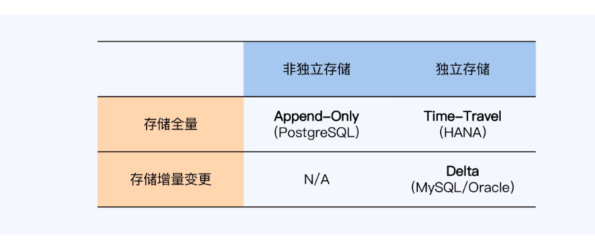
- 单体数据库的MVCC
- 将历史版本直接存在数据表中, append-only,如PG
- 存储在独立的表空间中,增量方式,MySQL、Oracle
- 存储在独立的表空间中,全量方式,Time-Travel,HANA
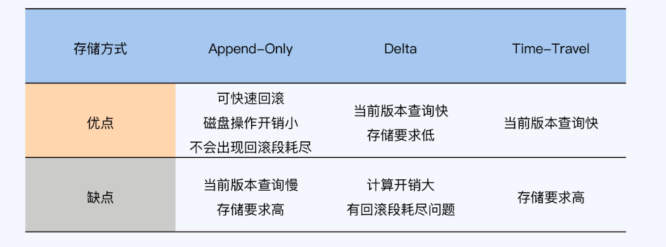
- append-only:
- 在事务包含大量更新时候也能保存较高效率,因为更新被转为delete+insert,数据并未被迁移,只是有当前版本被标记为历史版本,磁盘操作开销小
- 可以追溯更多历史版本
- 因为执行更新操时,历史版仍在数据表中,出现问题事务能快速完成回滚
- 新老数据放在一起,增加磁盘寻址的开销,历史版本增多,导致查询速度变慢
- Delta方式
- 历史数据独立存不影响当前读效率,增量占用空间小
- 历史版本再回滚段中,如果事务执行视角长,历史版本会被其他数据覆盖,无法查询
- 此模式下的历史版本,是基于当前版本+多个增量版本计算来的,计算开销较大
- TimeTravel
- 同样是历史版本独立存储,不影响当前读效率,历史版本全量存储直接访问,计算开销小
- 相比delta要占用更多空间
- MVCC工作过程,读已提交、可重复读
- PGXC模式下的RR,会碰到的问题
- 如何保证单调递增的事务ID,需要一个集中点来统一生成
- 如何提供全局快照,由一个集中点,维护一个全局事务列表,并向所有事务提供快照
- NewSQL读写冲突处理
- TiDB,没有试用快照读,所以对同一条数据读写会阻塞,没有设计全局事务列表导致的
- CockroachDB,是可串行的隔离级别,对于读写/写写冲突,采用事务重启的方式
- 读写冲突时的不确定时间
- 处理方式:写等待spanner、读等待CockroachDB
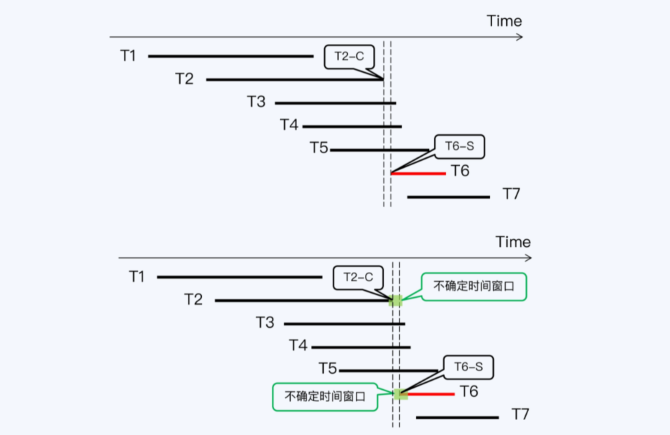
- 读写冲突时,会出现一个不确定的时间窗口,只能确定 T1、T2落在这个区间内,冲突了
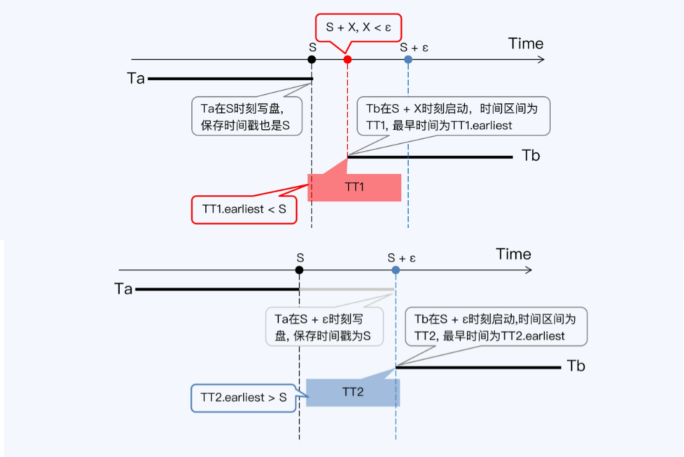
- Spanner,写等待,如果Tb 在 Ta之后启动,但启动时间小于一个窗口,那么Tb 可能读不到 Ta的数据,不满足一致性
- 分为两阶段,预备阶段获取一个“预备时间戳”, 第二阶段 协调节点需要一个“提交时间戳”,必须大于任何参与者的“预备时间戳”
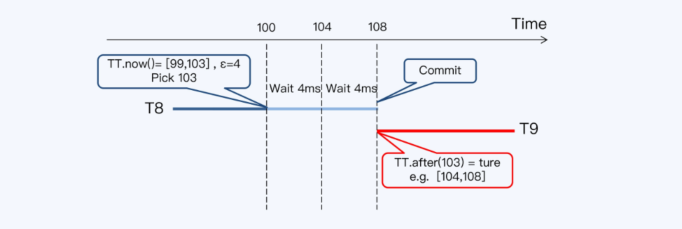
- 事务从拿到提交时间戳,到TT.after(s)为true,实际等待了两个时间窗口 8毫秒
- spanner对于读写有重叠时,TPS就是125,TrueTime的平均误差为4毫秒,commit-wait需要等待两个周期
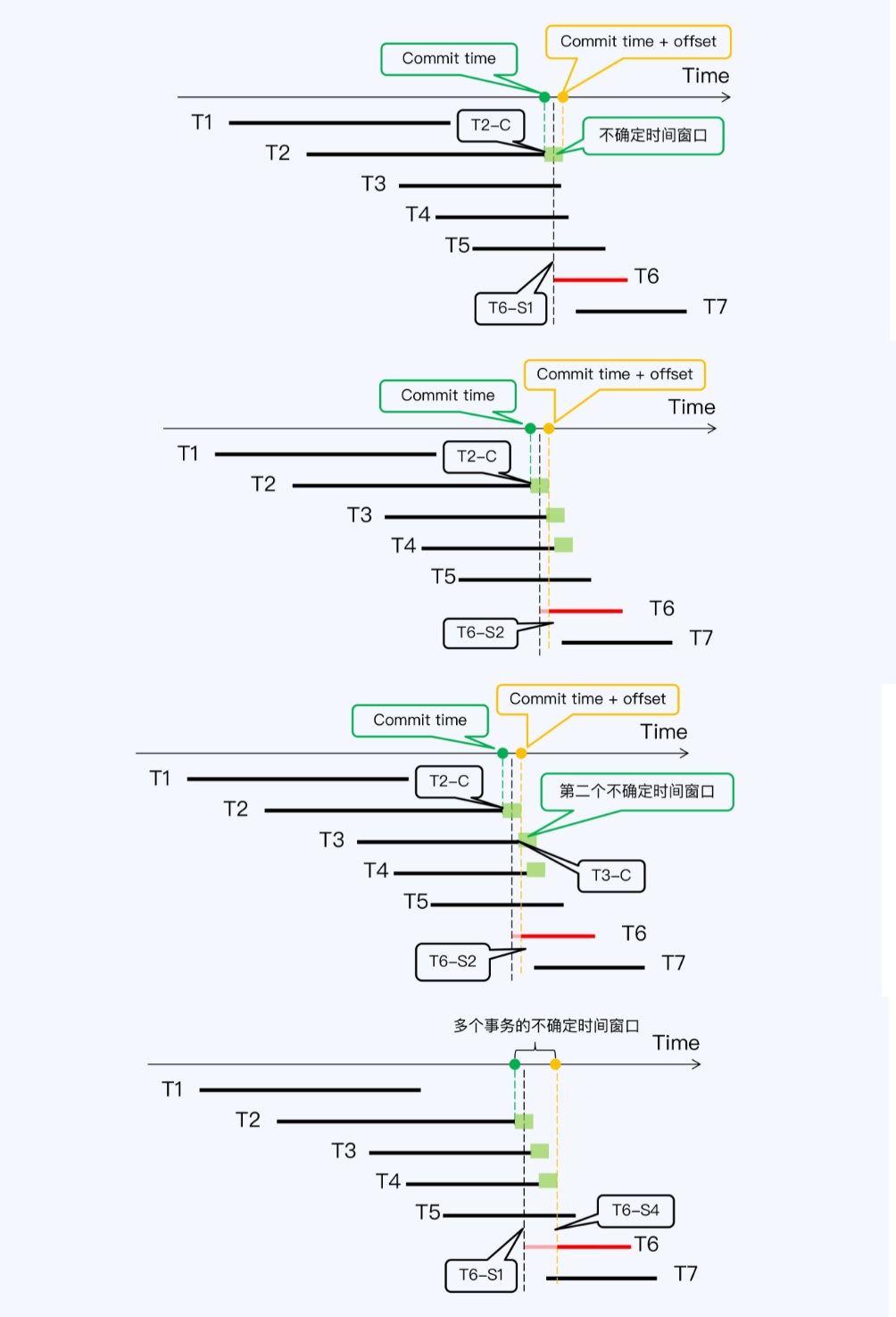
- CockroachDB的写等待,B-1时间读取,但中间有不确定时间窗口,B-1可能小于A-s的提交时间
- 重启B事务 相当于等待一会,最大时间为250ms,如果中间还有其他写事务,又会继续重启B事务
- 比较
- 写等待影响范围更大,所有包含写的事务至少要等待一个误差周期,适合误差更小的系统
- 读等待影响范围小,只有当读时间戳访问数据项的提交时间戳落入不确定窗口才会触发,会等数个周期,适合误差更大的系统
- 乐观锁和悲观锁
- 乐观就是直接提交,遇到冲突就回滚;悲观是在提交前加锁
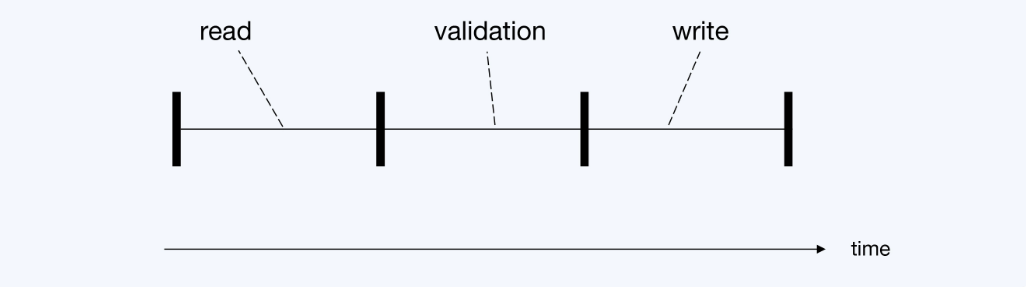
- 乐观协议 和 悲观协议都分成了四个阶段:有效验证(V)、读(R)、计算(C)、写(W)
- 悲观协议的操作顺序是 VRCW,计算没有实质影响去掉后简化为: VRW
- 乐观协议的操作顺序是 RCVW,简化为 RVW
- 三阶段说明
- 读阶段,这里也包含了写,是写到一个临时区域,所以更新对其他事务是不可见的
- 有效性检查,检查于隔离性目标有直接联系;可以基于锁的检查,也可以基于时间戳
- 将读阶段的更新结果写入数据库中,提交事务
- TiDB的三阶段
- 根据 Precolator 模型实现的乐观锁
- 收集所有参与修改的行,随机选择一行作为 primary row,这行有所,成为primary lock,这个锁用来标记整个事务的完成
- 每个修改都会上锁并执行"prewrite",将数据写入私有版本,如果碰到冲突就终止,如果完成则第一阶段介绍
- 提交 primary row 写入并提交记录清除 primary lock,剩余的 secondary rows由异步线程根据primary lock状态去清理
- 狭义的乐观并发控制,验证遵循 RVW 顺序,但工业界很少有使用狭义 OCC 进行控制的(FoundationDB除外),而TiDB则是广义的乐观并发
- 乐观锁的挑战
- 频繁的事务冲突,如企业给1W个员工发工资,就是一个大事务,如果冲突了需要频繁重启,还不如悲观锁
- 需要兼容单体数据库的协议,如: SELECT FOR UPDATE ,这并不是标准的语法,但大多数据库都支持,但乐观锁没有这种语义
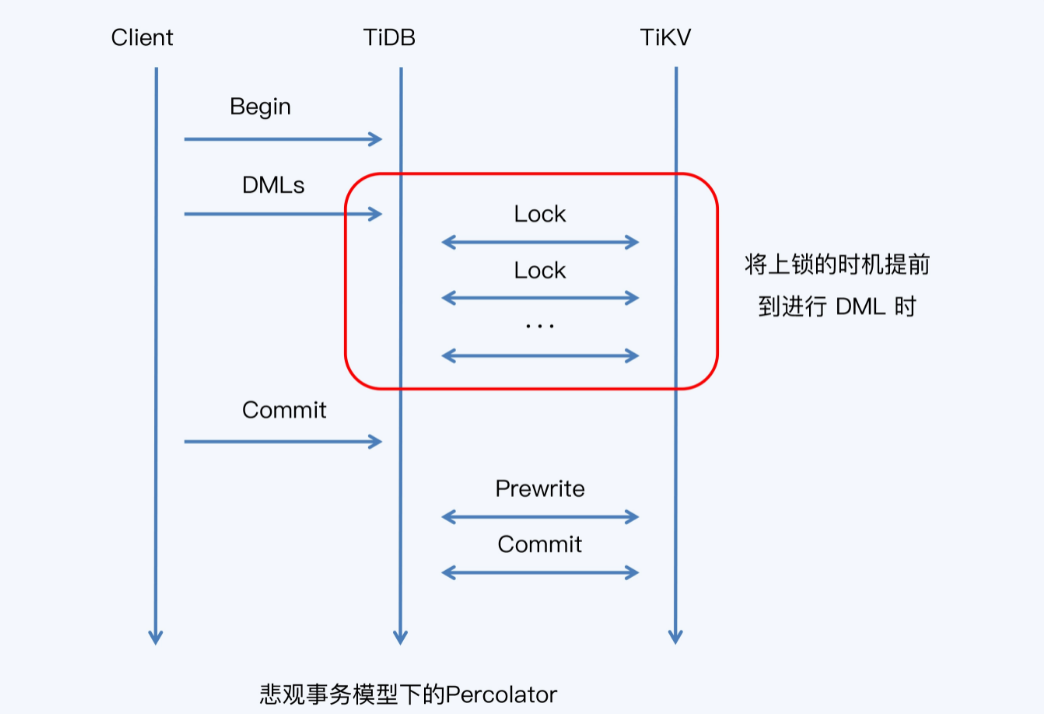
- TiDB的悲观锁,在局部有效性检查之前,增加一个全局检查,这样就是悲观锁了
- 锁的类型
- 学术上悲观锁、乐观锁的分类也比较含糊
- 锁的种类(下面集中在真实数据库中很少使用):
- 有序共享 Ordered sharding 2PL, O2PL
- 利他锁 Altruistic Locking,AL
- 只写封锁树 Write-only Tree Locking,WTL
- 读写封锁住 Read/Write Tree Locking,RWTL
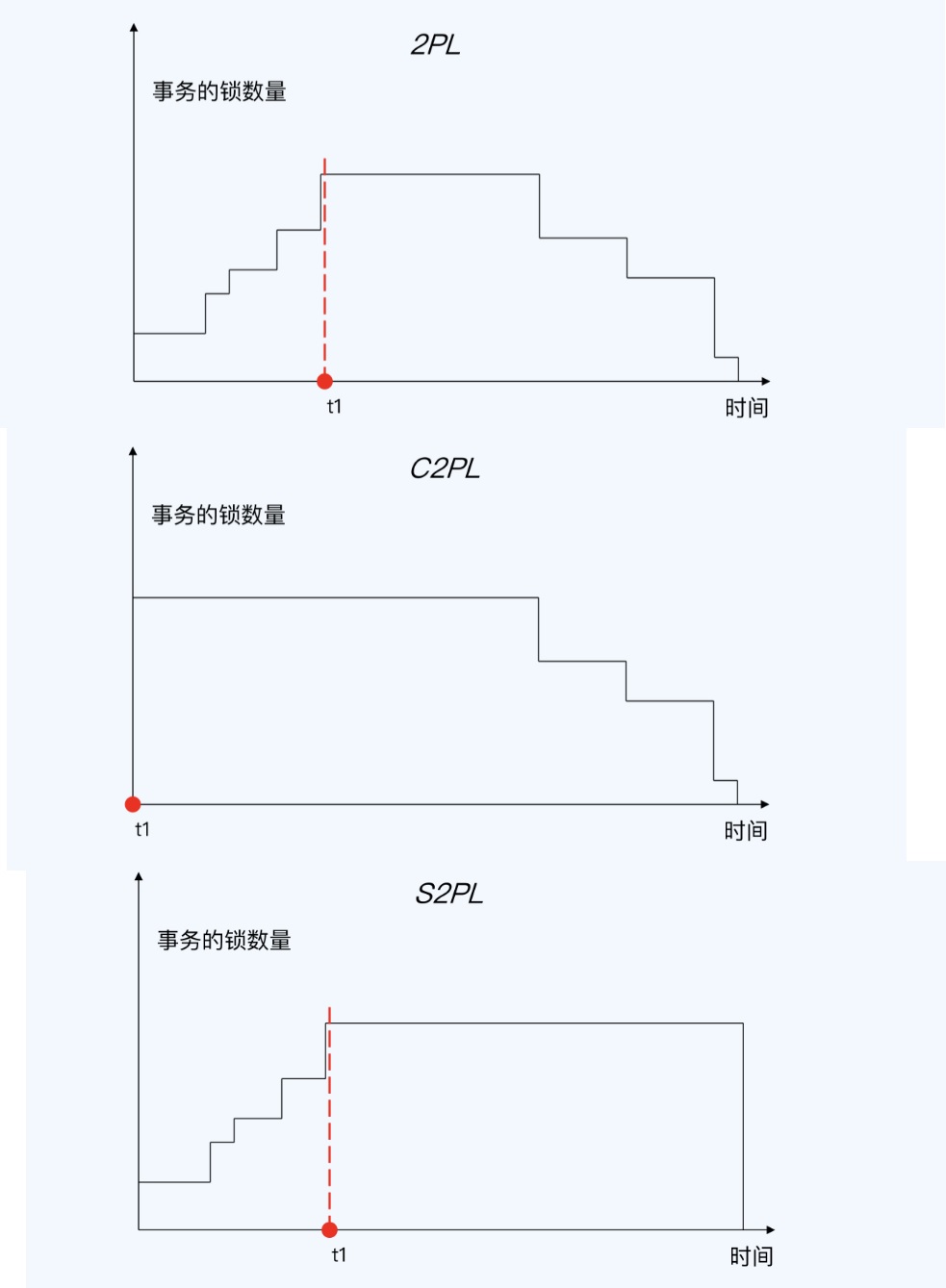
- 2PL,关键是释放锁之后,不能再加锁
- 2PL,加锁严格区分释放锁
- Conservative 2PL,C2PL,保守两阶段封锁协议,在事务开始时就要设置它需要的所有锁
- Strict 2PL,S2PL,事务一直持有获得的所有写锁,直到事务终止
- Strong Strict 2PL,SS2PL,强两阶段封锁协议,事务一直持有获得的所有锁,包括读和写锁
- SS2PL,S2PL差别只是持有锁的类型
- Percolator也属于 S2PL
- 可串行化快照隔离 SSI
- CockroachDB的 串行化图检测 SGT
- 事务作为节点,当一个操作于另一个操作冲突时,在连个事务节点之间画上一条有向边
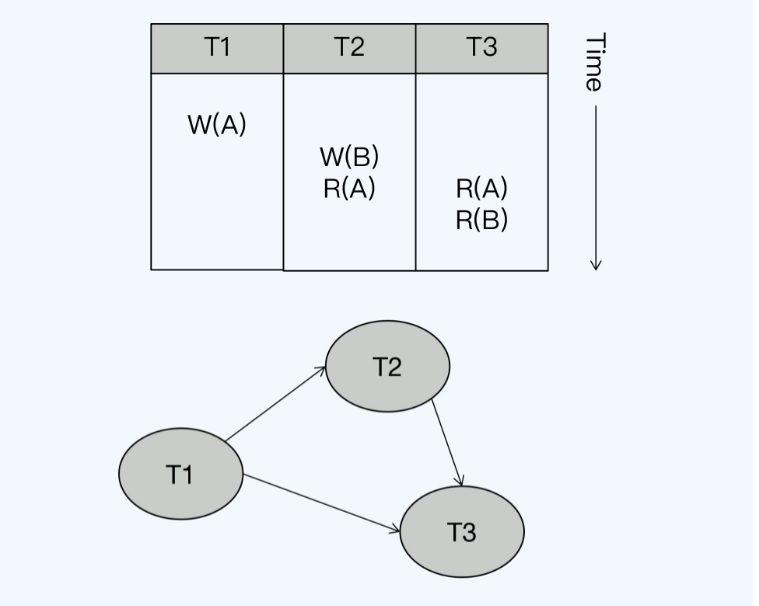
- 写读依赖 WR-Dependencies,第二个操作读取了一个操作写入的值
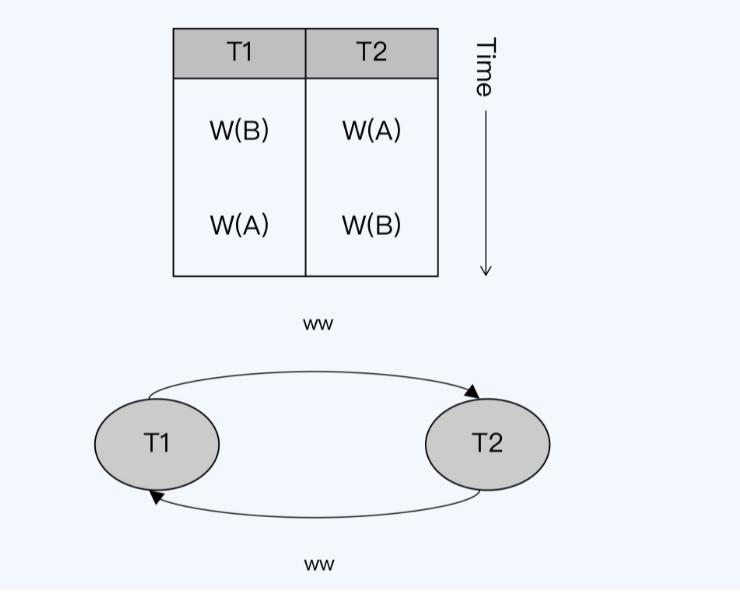
- 写写依赖 WW-Dependencies,第二个操作覆盖了第一个操作写入的值
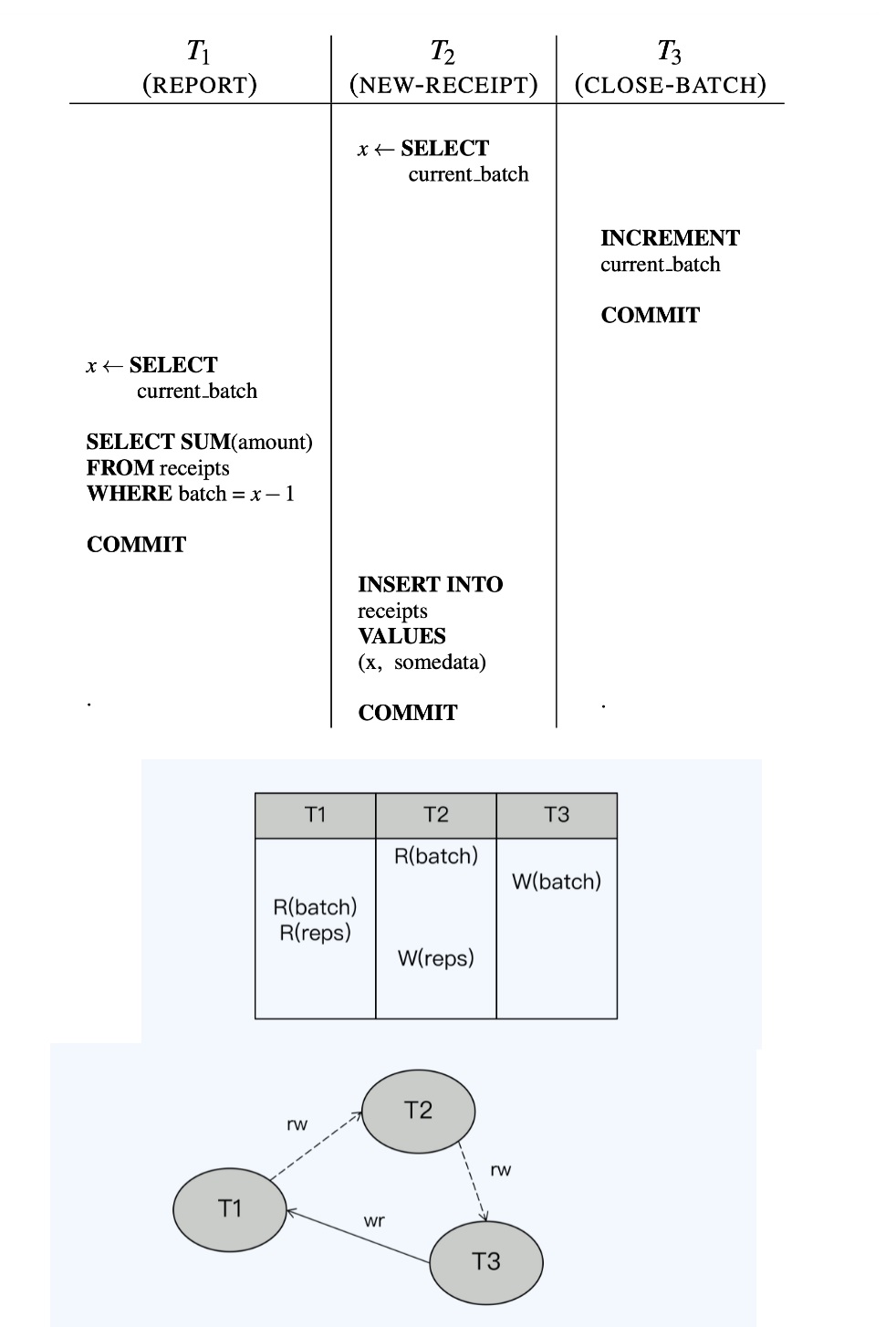
- 读写反依赖 RW-Antidependencies,第二个操作覆盖了第一个操作读取的值,可能导致读到过期值
- 读写反依赖,应该是顺序是 T2、T3、T1,实际T2先开始,T3执行关闭这样T2拿到的就是过期了
- T1读取数据但此时T2还没提交,最后T2更新,这笔更新就会丢失
- CockroachDB的反向依赖如果用快照成本太高,实际为: 读时间戳缓存 RTC
- 任何读取操作时,时间戳都会记录在所访问节点的本地 RTC 中
- 写的时候以key作为输入,向RTC查询最大读时间戳,如果时间戳>写入时间戳就会形成RW依赖,此事务需要重启
- RTC是大小有限的,采用LRU缓存
- SGT没有锁管理,性能比S2PL更好
- CockroachDB局部是悲观的,但不符合严格的VRW顺序,在全局看仍是相对乐观的
- CockroachDB 通过增加全局的锁表,就变成悲观锁了
Percolator的执行过程

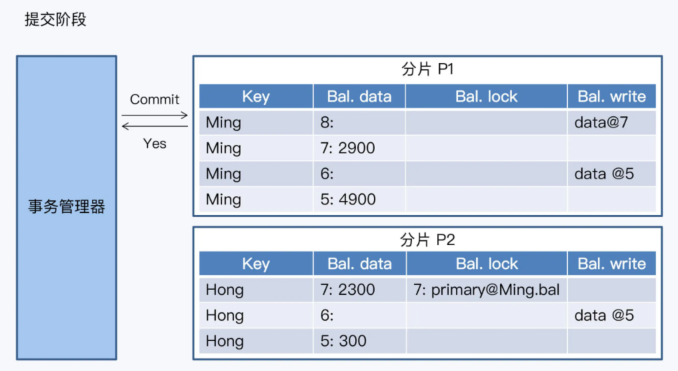
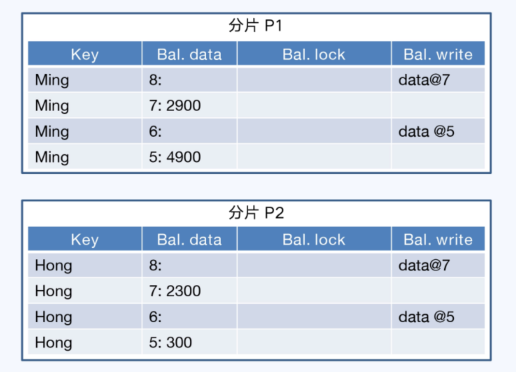
GoldenDB的一阶段提交

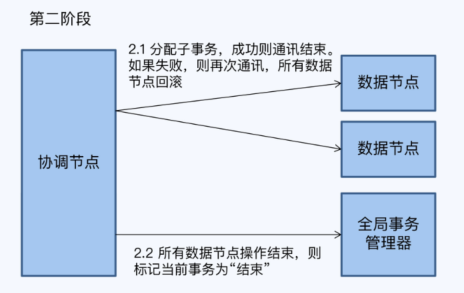
MySQL的first write win、TiDB的first commit win
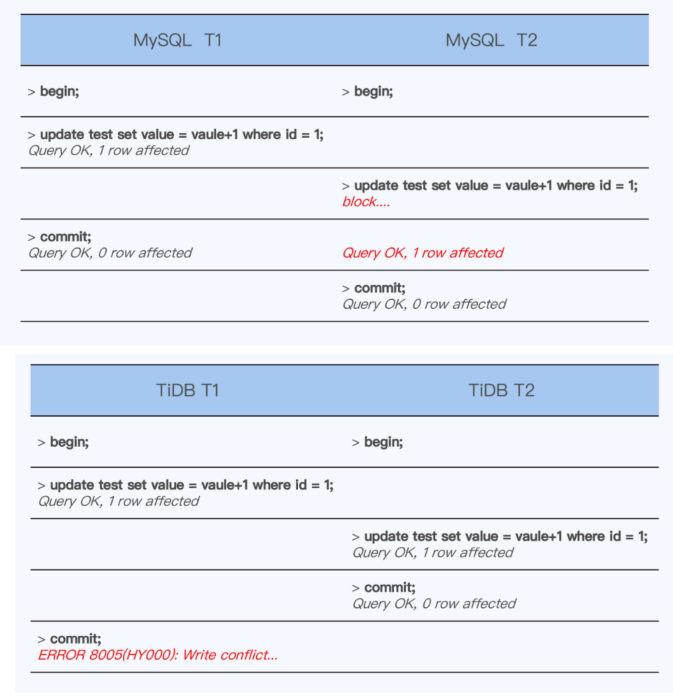
全球各个地区的机房延迟,延迟最大为 新加坡 <-> 圣保罗,理论光速延迟为 106.7毫秒,实际RTT为 362.8毫秒 Ltxn为 1.3秒
并行提交
没有MVCC下的读/写冲突,会阻塞
单体数据库实现MVCC时的存储方式和优缺点
RC隔离方式,启动时可以看到T1、T2的最新数据
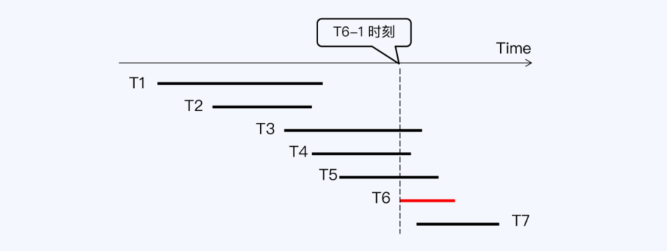
RR隔离方式
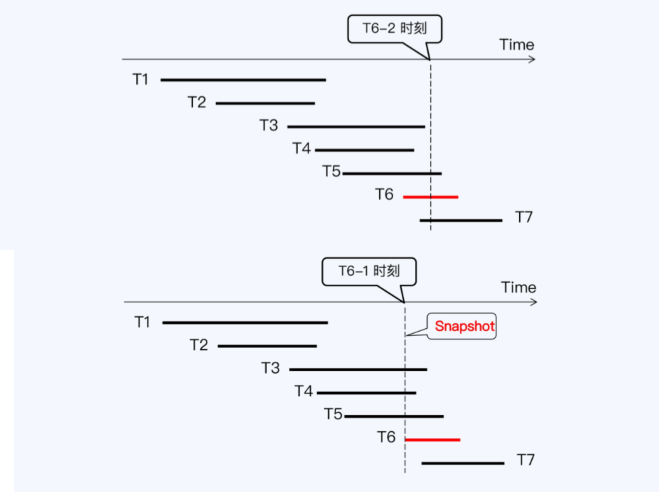
TiDB的读写冲突处理
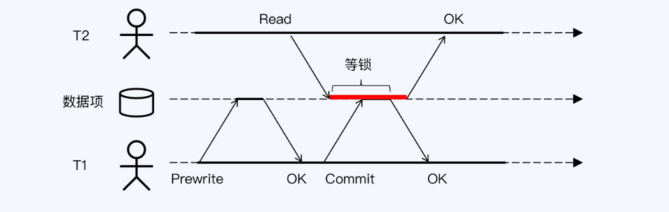
CockroachDB的冲突处理,事务重启
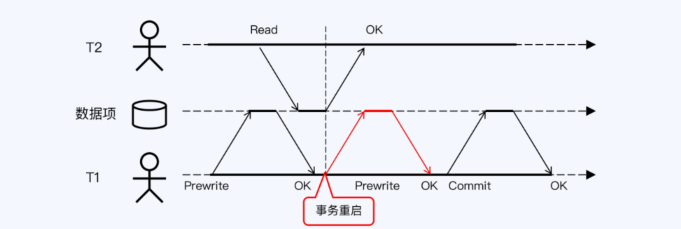
不确定的时间窗口
spanner对于事务重叠的处理,采用wait-commit
在预备阶段拿到了时间窗口是[99,103],采用103作为提交时间戳,然后再等待一个周期,相当于等待2个周期,这样 T9启动时就肯定能读到 T8的最新数据
CockroachDB的读等待,可能会有经历多个等待窗口
TiDB的乐观锁模式
乐观锁模式 RVW
TiDB的悲观锁模式
锁的类型
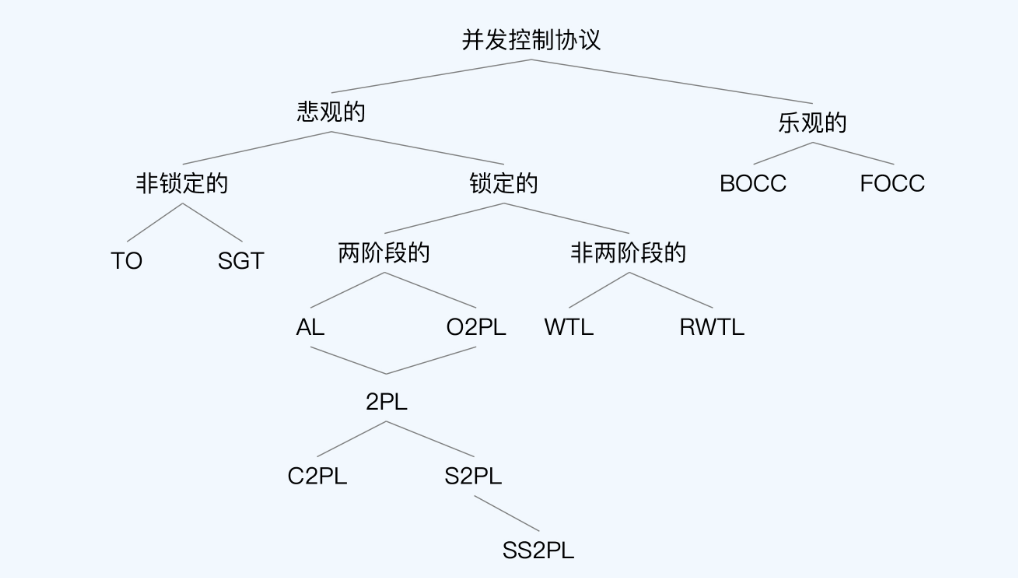
2PL、C2PL、S2PL
读写依赖的图检测
死锁的图检测
读写反依赖的图检测
论文
- 2pc Nodes on Data Base Operating System
- Percolator:Large-scale Incremental Processing Using Distributed Transactions and Notifications
- Highly Available Transactions: Virtues and Limitations
- Randy Wigginton et al. : Distributed Transactions in MySQL
- Highly Available Transactions: Virtues and Limitations
- Distributed Transion in MySQL
- Principles Of Distributed Database System
- On Optimistic Methods for Concurrency Control
- Transactional Information System
- Serializable Snapshot Isolation In PostgreSQL
- Spanner:Google’s Globally-Distributed Database
- Consensus on Transaction Commit
- Time,Clocks,and the Ordering of Events in a Distributed System
数据库查询
总结
- 不要使用存储过程
- C/S时代,数据库的存储过程,其实承担了业务逻辑,业务逻辑是用存储过程完成的
- B/S时代,存储过程被抛弃,应用服务器承担了业务逻辑,触发器使用的很多
- 触发器多了之后,根本搞不清各个表的触发器关系,改了一个表可能会引发大量的触发器
- 每个数据库厂商的存储过程标准不一样,难以迁移和调试
- 阿里的规范中就明确定义禁止使用存储过
- 随着敏捷开发、DevOps工具链的发展,存储过程更不适合了
- 一种技术必须要匹配同时代的工程化水平,于整个技术生态融合,否则它就会退出绝大多数应用场景
- OceanBase支持存储过程,但这是因为想替换Oracle而必须做的商业考虑
- 谷歌的F1支持UDF,但不是存储过程,而是自定义函数,兼容性比较好
- 谷歌的F1不一定能能适用普通的环境
- VoltDB以存储过程作为主要的操作定义方式,支持Java开发
- VoltDB的基础就是存储过程这种预定义事务方式,存储过程、内存存储、单线程相互影响,使其性能优越
- 不用使用自增主键
- MySQL无法保证自增,事务异常后就会导致出现空洞
- 无法保证单调递增
- 海量并发下性能不行,高位数据库自增控制,低若干位机器自己生成
- 分布式情况下 TSO会有单点性能问题
- range分区下会有尾部热点问题
- 随机主键
- UUID
- TiDB的AutoRandom, 1个符号位+5个事务时间+58个序列号,可以保证表内主键唯一
- snowflake,1个符号位+41个本地毫秒时间+10个长度机器编码+12位序列号
- snowflake支持的TPS为 2 ^22 * 1000,为 419W
- snowflake的问题,要注意时间回拨,可能会导致重复
- HTAP数据库
-
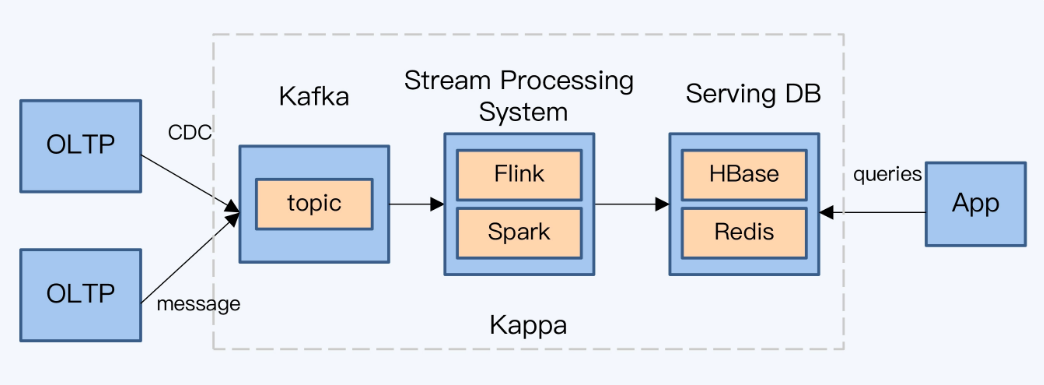
通过ETL在OLTP和OLAP之间导数据,可能会有T+1问题,时效性太差
-
重建OLAP体系
- 流计算无法替代批计算,kafka+flink
- serving DB也无法满足各种类型的分析查询需求,,clickhouse
-
HTAP hybrid Transaction/Analytical Processing 混合事务分析处理
- 由于数据出现在OLTP以免,HTAP往往偏向OLTP了
- 目前号称支持HTAP的: TiDB、TBase、OceanBase
-
HTAP的实现方式
- 分布式数据库是存储计算分离的,一个HTAP内可以有多个计算引擎
- 行存和列存才是OLTP和OLAP最根本的区别,所以HTAP的难点在存储
- Spanner的存储合一
- NSM,n-ary storage model行存储
- decomposition storage model 列式存储,C-store、Vertica,很难将不同列高效关联
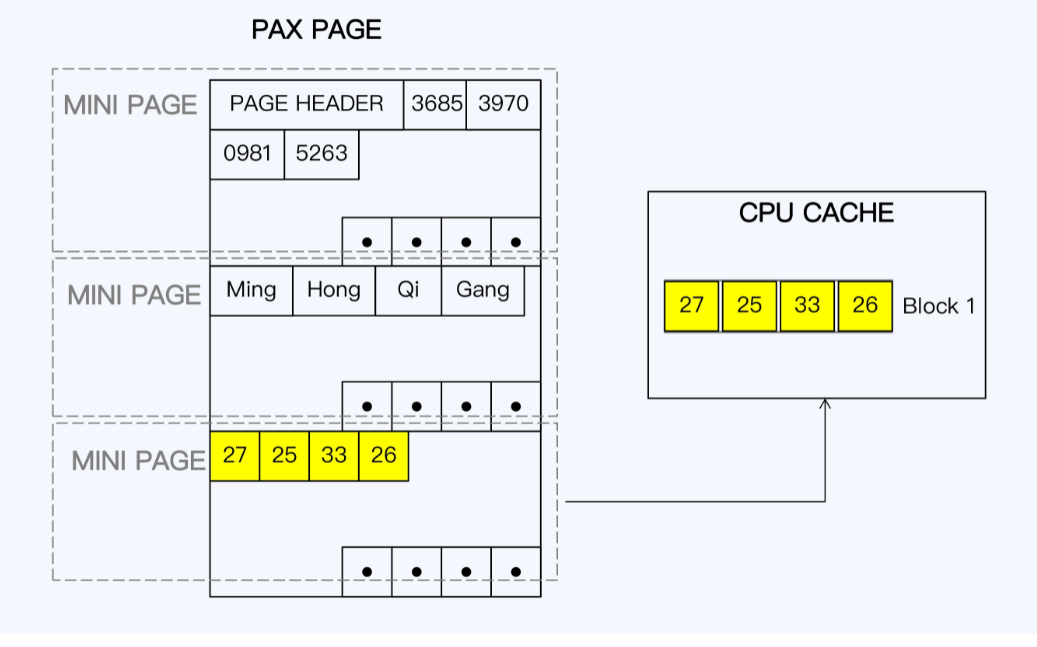
- PAX增加了minipage概念,是原有数据页下的二级单位,一行数据页上的基本分布不会破坏
- 相同数据被集中存在一起,本质更偏向行存
- 类似的思路还有 HyPer的 DatBlock,独有的数据结构,同时面向OLTP和OLAP
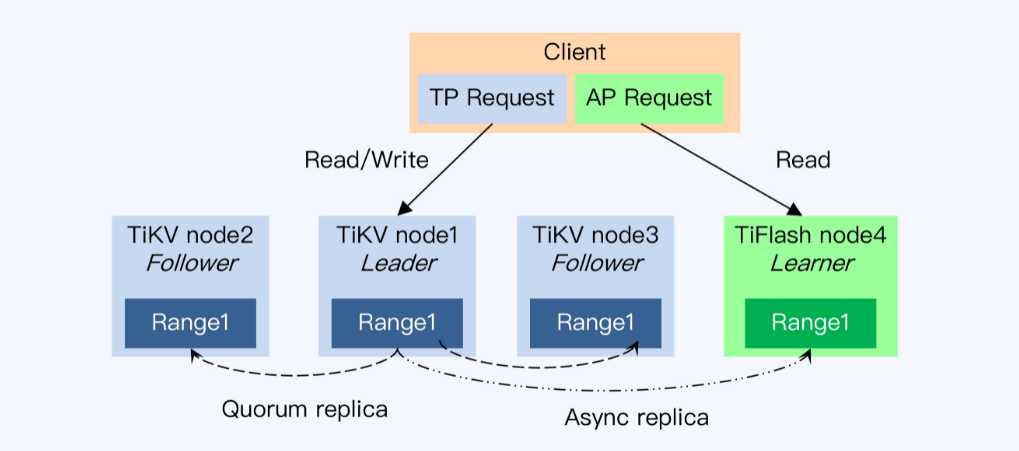
- TiDB存储分离,TiKV行存,TiFlash列存
- learner每次都会拿事务的时间戳向leader发起请求,获得最新的commit index,一直等待直到超时
- TiFlash的存储层是Delta Tree,分为Delta Layer和Stable Layer,对列存储做了优化,类似LSM
- TiFlash是OLAP系统,所以读比写优先级更高,要优先做读优化
-
查询性能优化
-
查询下推,也就是谓词下推
-
TiDB的问题
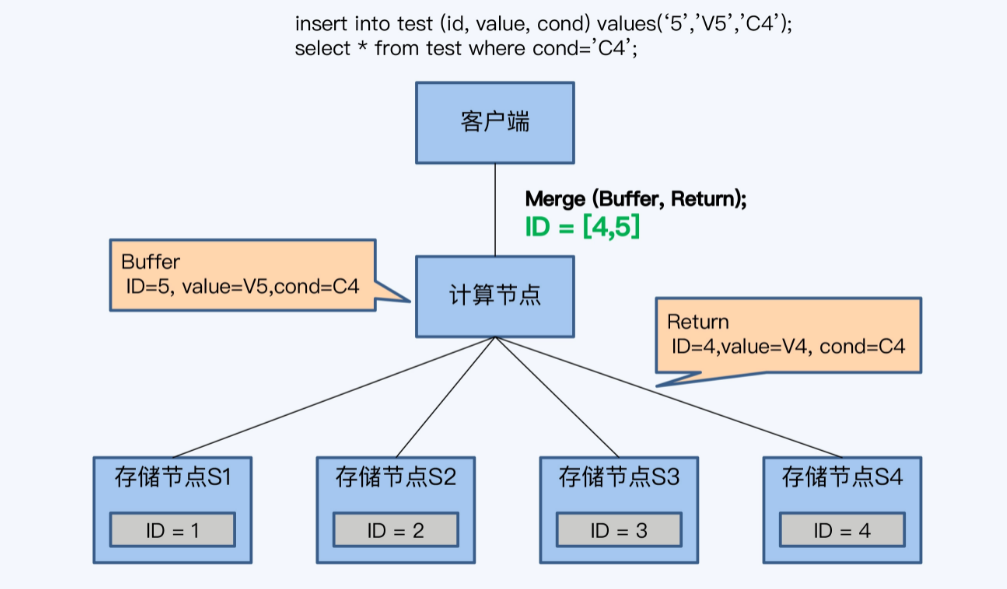
- 如果一个事务中包含了insert、select则比较麻烦,因为TiDB采用了 缓存写提交技术,所有的SQL直到commit才发送
- 当计算节点没有缓存数据时,就下推,否则不下推
- 改进,将缓存数据组织成Row格式,将缓存和存储节点返回结果做merge,就得到了最终结果
-
分区键和 join下推
- 分区键,就是分片,SQL中谓词条件中包含分区键,可以下推到各个存储节点执行
- 多表关联时,使用了相同的分区键
- PolarDB称为join下推,Greenplumn称为本地连接
- 不是所有的计算都能下推,如排序操作
-
分区索引
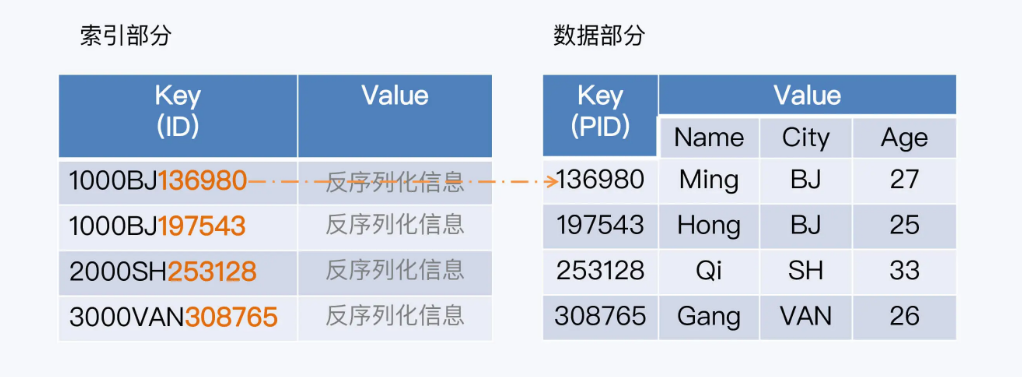
- 分区的索引和数据放在一起
- Spanner的父子表模式,通过键的左前缀匹配key区间特性,设置字表记录与父表记录保持相同的前缀,实现两种同分布
- HBase中主键是唯一的,在主键前面加上前缀也是唯一的
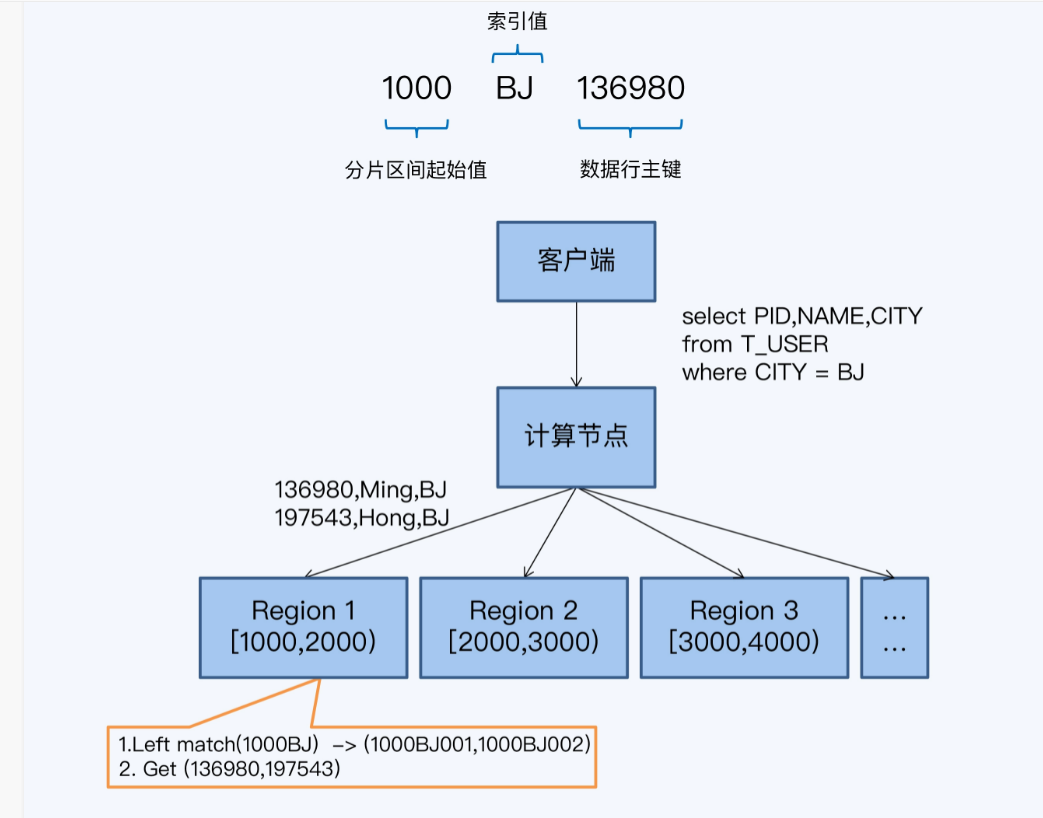
- 存储节点在每个region上执行下推计算,取region的起始值+查询条件中的索引值,拼在一起作为左前缀,扫描索引数据行
- 根据索引扫描结果中的PID,回表查询,最后返回给计算节点
- 难点,如果时钟保持索引与数据的同分布,尤其是发生分片分裂时,有的方案是重建索引
- 将索引和数据装入一个更小的单元,而分裂时保持这个单元的完整性,就可以继续维持同分布了
-
全局索引
- 分区索引无法确定全局唯一性
- 全局索引和数据不是同部分,读操作成本更高,需要先走全局索引,再回表查数据
- 写操作延迟更长,同部分情况下可以用本地事务完成,而全局索引就变成分布式事务了
- TiDB的二级索引只支持全局索引
-
- 关联查询
- 循环嵌套关联 nested loop join
- 外表为驱动表,里面的为inner内表
- Simple Nested-Loop Join SNLJ,遍历外表取r1,遍历内表不断跟r1做关联
- Block Nested-Loop Join BNJ,外表一次取 n 条数据,这样内标遍历时一次可以比较n个记录
- MySQL有一个Join Buffer选项,直接影响了BNJ的效率
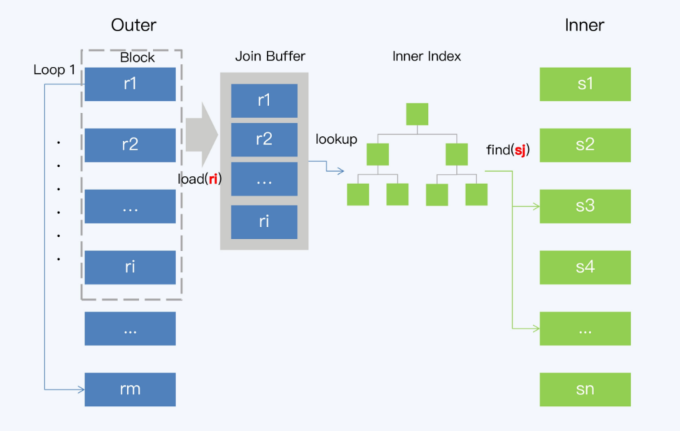
- Index Loopup Join,ILJ,在BNJ基础上对内表加了索引,遍历外表取一个批次,然后跟内表索引关联,得到结果
- 归并排序关联 sort-merge join SMJ
- 先对外表、内表做排序,排序好之后,一次循环遍历就可以得到结果
- 时间复杂度为:两次排序+两次遍历,索引本身是有序的,如果连接的正好是索引,SMJ就是三种嵌套循环中效率最高的
- hash关联 hash join
- simple hash join,包括建立阶段、探索阶段
- 使用小表来建立,根据记录上的连接属性使用hash函数得到hash值,从而建立hash表
- 扫描外表,对每一行连接属性计算hash值,与之前的hash表对比
- SHJ 的缺点是小表必须完全放入内存中
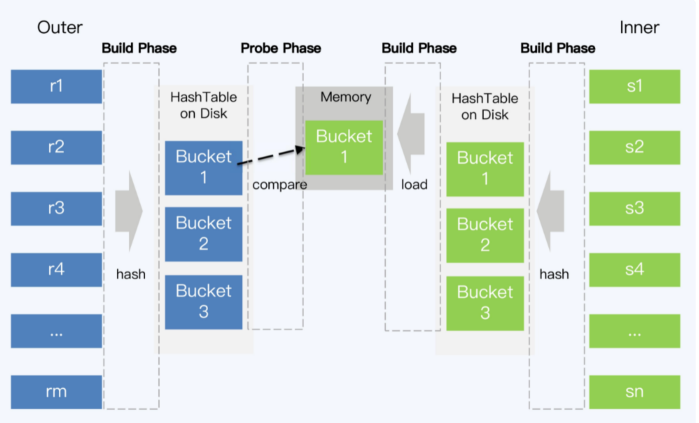
- Grace hash join,内表根据hash值分为若干个bucket写入磁盘(必须小于内存容量),外表同样分bucket写盘,但不受内存限制
- 将内表的bucket放入内存,再读取外表的bucket进行匹配,所有的bucket读取玩后就得到了最终结果
- Hybrid hash join,对于内存足够情况下,将内表第一个bucket和外表bucket都放入内存,这样建立阶段一结束就可以匹配
- 分布式数据库实现,合理的划分和调度子任务需要引入更复杂的计算引起,在OLAP中很常见,如MPP架构
- TiDB + TiKV体系中就没有MPP引擎,存储节点不能相互通讯,后引入Spark来处理复杂的OLAP计算任务,TiSpark组件
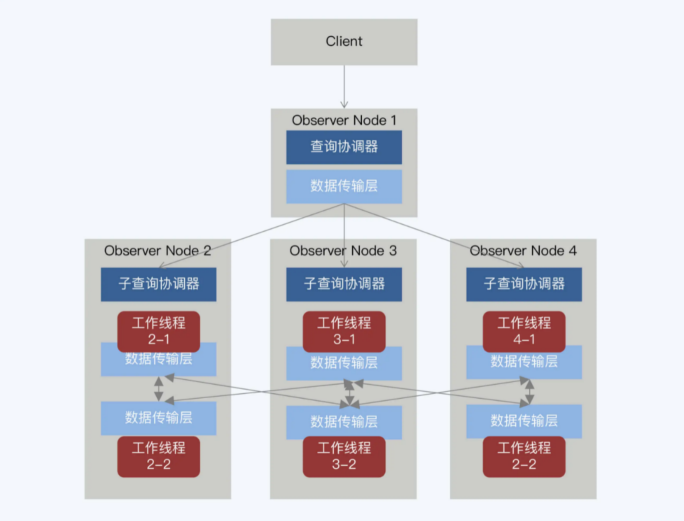
- OceanBase中扩展了并行计算框架,存储节点之间也可以进行数据交换
- OceanBase是P2P架构,每个Observer部署了相同服务,运行中动态承担不同角色
- 大小表关联-复制表
- 静态方式,建表的时候声明为复制表,这样每个节点都有一份考虑,如TBase、TDSQL等,都支持复制表
- 动态方式,如小表广播,Spark的broadcast hash join就是这种方式
- 大表关联-重分布
select A.C1,B.C2 from A,B where A.C1=B.C1- 如果 C1是A表的分区键,但不是B表的分区键,则B表按C1做重分布,推送到A的各个分片上,实现本地关联
- 如果都不是,两个表都需要根据C1做重分布,然后在多个节点上再做本地关联,代价会比较高
- 本质上跟MapReduce、Spark的shuffle类似
- Spark的shuffle hash join,将两个表按照连接键做分区,将相同连接键的记录重分布同一节点,数据就会被分片到尽可能多的节点上,增加并行度
- hash join阶段,每个节点上的数据执行单机的hash join操作
- 循环嵌套关联 nested loop join
- 查询引擎优化
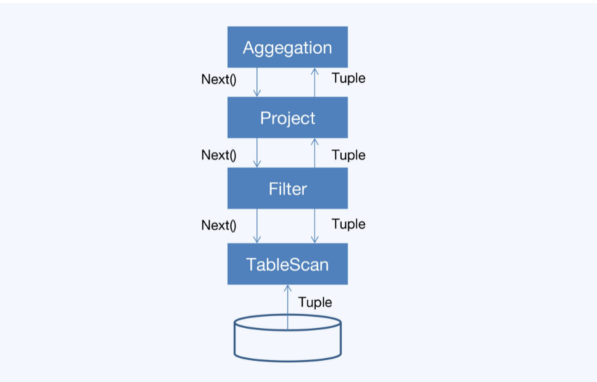
- 火山模型,迭代模型
- 调研子节点operator的next接口,获取一个元组 tuple
- 对元祖执行operator特定的处理
- 返回处理后的元组
- 对虚函数调用次数过多,造成CPU的浪费
- 数据以行为单位进行处理,不利于发挥现代CPU特性
- 以行为组织单位很容易造成CPU缓存失效
- 运行简单的循环时,编译器和CPU可以做循环展开,使用SIMD指令处理多个单元,可以并行执行16个4字节整数
- 运算符融合,OceanBase中将常见的Operator融合到其他Operator中,减少虚函数调研
- 分支预测,当执行跳转时无法确定下一条指令,就从专门寄存器中取出最近几次某个地址的跳转指令,这样避免了盲等
- 但会造成分支预测失败的场景,白做了一些无用功
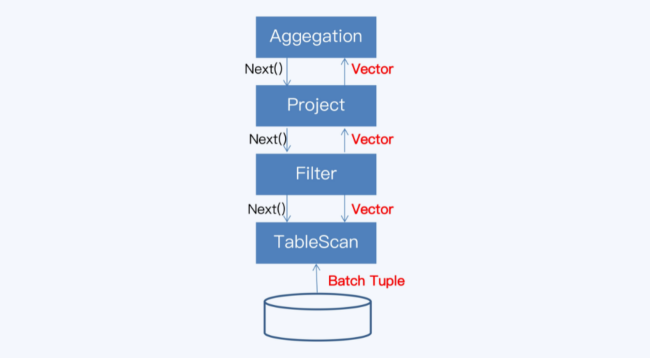
- 向量化模型
- TiDB、CockroachDB、ClickHouse
- 其Operator是向量化运算符,跟火山模型类似,但是每次拉取一批数据,每批返回一个向量块
- 背后思想是,按列组织数据和计算,充分利用CPU,把从多列到元组的转换推迟到较晚的时候执行,在不同的操作符间平摊了函数调用的开销
- 减少虚函数调研,提高分支预测准确性;以向量块为单独,提高CPU缓存命中率;SIMD并行处理
- 代码生成
- 使用push模型,跟火山模型的pull正好相反
- 自底向上的执行,执行逻辑的起点直接在最底层的Operator
- Hyper是一个深入使用代码生成技术的数据库
- 整个查询计划粒度,是全代码生成 whole-stage-code generation,难度最大
- 相对容易的是生成对应的表达式求值 expression evaluation,OceanBase在2.0中实现这个功能
- 火山模型,迭代模型
- RUM猜想
- append操作对于写是最优的,但是对读不友好,没有额外的数据结构辅助,必须从头扫描文件
- 而为更高效的读,需要复杂的数据结构,写入速度会降低
- 2016年的RUM论文,在read overhead(读)、update overhead(写)、memory or storage overhead(存储)中,只能三选二
- 同时优化两项时,需要另一项劣化为代价
- 存储结构 B+树
- 写放大,本来只需一条写入记录,但要更新3个页表中的7条索引记录,额外的6条记录,是维护 B+树结构产生的写入放大
- 写入放大系数,Write Amplification Factor WAF
- 空间放大系数 Space Amplification Factor SAF
- 上面提到的更新了7条记录,WAF是 7
- 存储不连续,新增叶节点会放入原有叶节点的有序链表中,逻辑上是连续的,但磁盘存储可能不是连续的
- 如果进行大量随机写会造成存储碎片化,导致写放大、读放大
- 填充因子,Factor Fill,在页表中预留一些空间,不会因为少量写入造成树结构大幅变动
- 填充因子过大无法解决写入放大问题,过小导致也表数量膨胀,增大磁盘扫描范围,降低查询性能
- 存储结构 LSM树
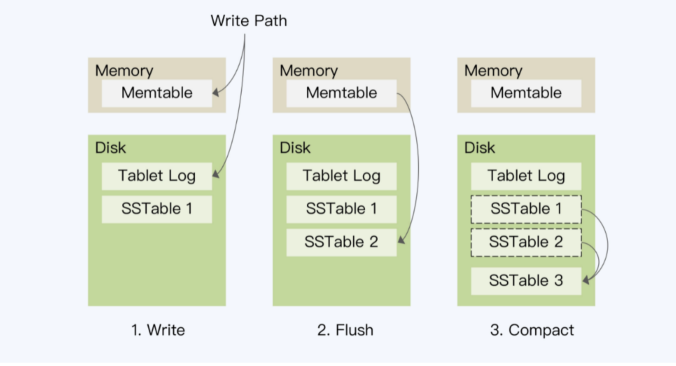
- 写先进入到mem-store中,并记录到HLog中
- 当mem-store到一定阈值后,写入有序文件sorted string table SSTable,系统会创建新的mem-store
- 定期将多个SSTable合并为更大的SSTable
- LSM将随机写转为顺序写,flush不会产生写放大,但在compact的时候,会产生写放大
- Size-Tiered Compact Strategy,Tiered,BigTable和HBase的合并策略
- Tiered的读放大,因为有M个文件所以都要读一遍,合并后将为O(LOG(M*N)),只有一个SSTable时没有读放大
- Tiered的写放大比B+树 还严重,持续的写入后需要一部分I/O用于compact,而这个操作也影响了I/O读
- Tiered空间放大,需要 2倍空间,存储合并前的多个SSTable、合并后的1个SSTable,而B+树的空间放大SAF为1.33
- LSM的Leveled Compact Strategy
- Tiered的问题每次Compact要全量数据参与,开销很大
- 将数据分成一系列Key互不重叠且固定大小的SSTable文件,并分层处理,同时记录每个SSTable文件存储的Key范围
- LevelDB、RocksDB
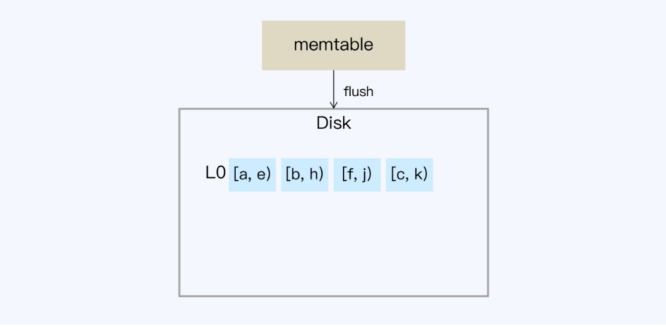
- 当内存数据较多时,会flush到SSTable,此时对应L0,其他层级同样采用Ln形式表示,n为对应层级,L0不做整理,按时间顺序生成
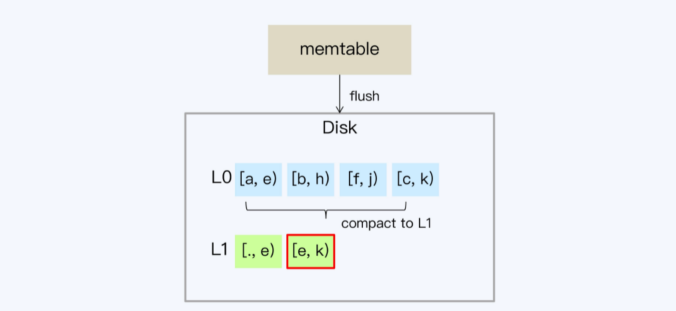
- L0的SSTablekey是交叉的,会重叠,当L0超过一定数量后,会写入L1,从L1开始,SSTable的key都不重叠
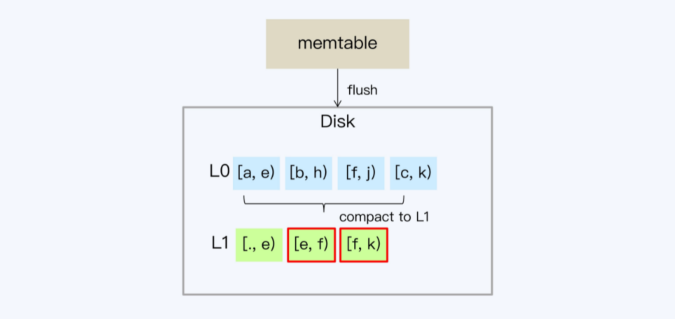
- 随着L1层的数据增多,SSTable会重新划分边界,目的是保证相对均衡的存储
- L1超过一定阈值后,触发L1写入到L2,因为L1文件不重叠,不用所有文件都参与compact,降低I/O开销,从L1->L2往后,每层增大10倍,Ln->Ln+1只会牵涉少数SSTable
- 读放大,每层有M个SSTable文件,借助Bloom Filter,多个SSTable只需要O(1),优化后 O(X + L - 1 + logN),X是L0 SSTable数量
- Leveled对写放大有明显改善,但是L0的compcat会比较频繁,仍然是读写操作的瓶颈
- 空间放大,不同层不重复,每层按比例递增,大部分数据会存在在底层,空间放大得以控制
- 分布式数据库实现
- 数据存储在每个数据节点上进行的,单机过程是一样的
- TiDB、CockroachDB直接使用了 RocksDB 作为单机存储引擎,RocksDB位于Raft协议之下
- OceanBase也使用了LSM树,引入了宏块、微块的概念,在进行compcat时,可以在宏、微两个级别判断,是否可以复用
- 复用的话,直接文件拷贝,省去了解析、编码、校验等操作
- OceanBase轮转合并,将compcat操作放在与leader保持数据同步的follower上执行,leader继续对外提供查询,等compcat玩后,切换follower为leader
- WiscKey ,在合并的时候主要是对key处理value只是拷贝而已,将value从sstable中单独拿出来存储,降低写放大
- value单独存储问题是 不连续,WiscKey设计使用SSD替换HDD,SSD随机写接近顺序写,而过高的写也降低SSD寿命,WiscKey是针对SSD设计的模型
- CGo Barrier,CockroachDB采用GO实现,而RocksDB是C++的,Go调用C++有开销
- TiDB放弃Go作为存储引擎,改用Rust,因为Rust和C++之间调用成本非常小
- CockroachDB的存储引擎 Pebble; TiDB的存储引擎 TiTan
- RocksDB最初只有30K代码,但现在已经膨胀到350K+
- TiDB的TiFlash,其存储层模型Delta Tree类似LSM结构,Delta Layer对应L0层,Stable Layer对应L1层
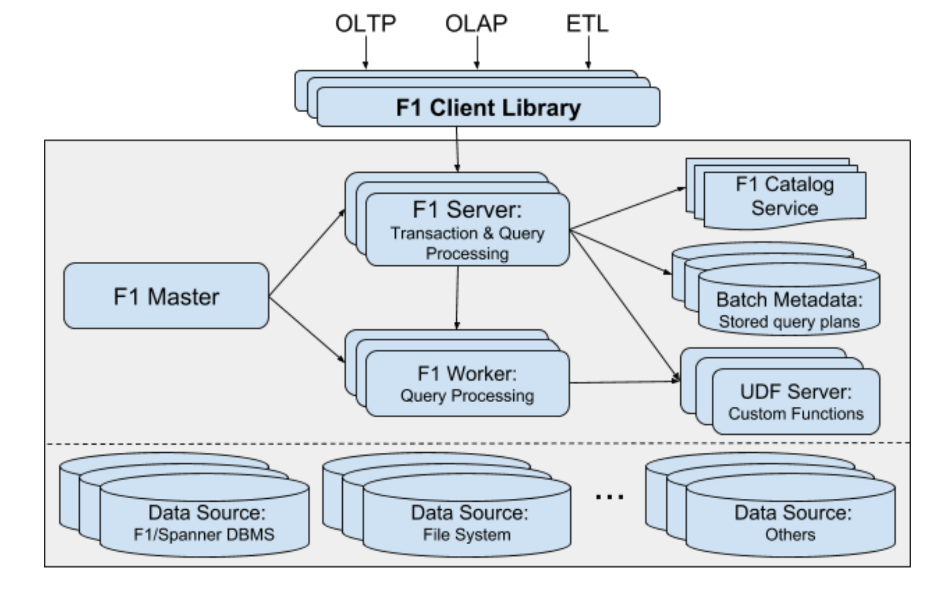
F1的架构
重建OLAP体系
行列混存PAX结构
TiDB的HTAP架构
计算下推
HBase的索引前缀
HBase索引前缀计算示例
Index Lookup Join
Grace Hash Join
OceanBase的MPP架构,observer节点可以动态改变身份
火山模型
向量化模型
火山模型 VS 代码生成
SQL解析后得到左边的查询树,找到R1、R2、R3对应的三个分支
要获得最优的CPU执行效率,数据尽量不要离开CPU寄存器,这样可以在一个CPU流水线上完成数据处理
但查询计划的Join操作要生成hash表加载到内存中,这个动作使数据必须离开寄存器,称为物化 materilaize
整个过程会被物化为4个pipeline,而join的这种操作,在Hyper论文中被称为pipleline-breaker
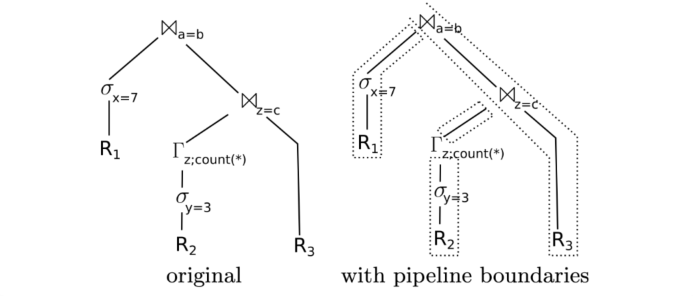
通过即使遍历省的代码得到对应pipeline的四个阶段,伪代码

RUM猜想
B+树
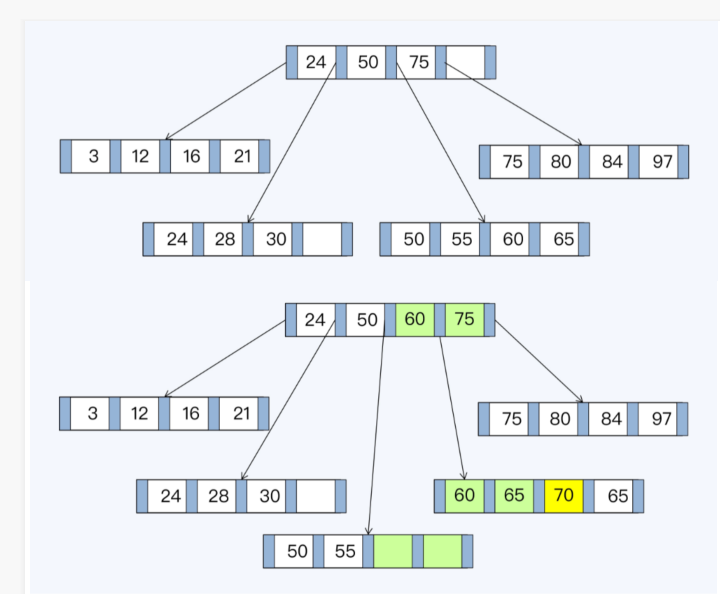
LSM树
LSM树 Leveled策略,L0层
当内存数据较多时,会flush到SSTable,此时对应L0,其他层级同样采用Ln形式表示,n为对应层级,L0不做整理,按时间顺序生成
L0的SSTablekey是交叉的,会重叠,当L0超过一定数量后,会写入L1,从L1开始,SSTable的key都不重叠
随着L1层的数据增多,SSTable会重新划分边界,目的是保证相对均衡的存储
L1超过一定阈值后,触发L1写入到L2,因为L1文件不重叠,不用所有文件都参与compact,降低I/O开销,从L1->L2往后,每层增大10倍,Ln->Ln+1只会牵涉少数SSTable
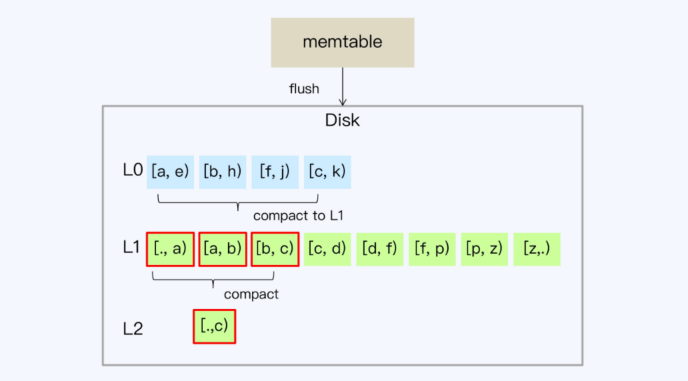
TiDB的RocksDB架构
论文
- http://vldb.org/pvldb/vol11/p1835-samwel.pdf
- Yugabyte vs CockroachDB: Unpacking Competitive Benchmark Claims
- Data Page Layouts for Relational Databases on Deep Memory Hierarchies
- Data Blocks
- Questiong the lambda Architecture
- Gartner的HTAP分析报告
- Spanner: Becoming a SQL System
- Volcano, an Extensible and Parallel Query Evalution System
- MonetDB/X100:Hyper-Pipleling Query Execution
- Apache Spark as a Compiler: Joining a Billion Row per Second on a Laptop
- Efficiently Compling Efficient Query for Modern Hardware
- Bigtable: A distributed Storage System for Structured Data
- WiscKey: Separating Keys from Values in SSD-conscious Storage
- Designing Access Methods: The RUM Conjecture
- The Log-Structured Merge-Tree(LSM-Tree)
实践部分
总结
- 全球化部署
- 异地多活
- 单体数据库
- 异地容灾
- 异地读写分离
- 异地双向同步
- 分布式数据库
- 机房级容灾(两地三中心五副本)
- 城市级容灾(三地三中心五副本)
- 三地五中心七副本
- 架构问题
- paxos风格的架构必须有一个主节点,一般在主机房
- 只有一个全局时钟,异地写入增加通信延迟
- 异地机器A获取的时间戳早,本地机器时间戳靠后,加上延迟,导致A写入比B迟,会失败
- 类似问题:网购付款时会出现多个事务在短时间内竞争修改商户的账户余额
- 全球化部署:多个时间源,多点授时,不同分片主副本可以分散在多个机房
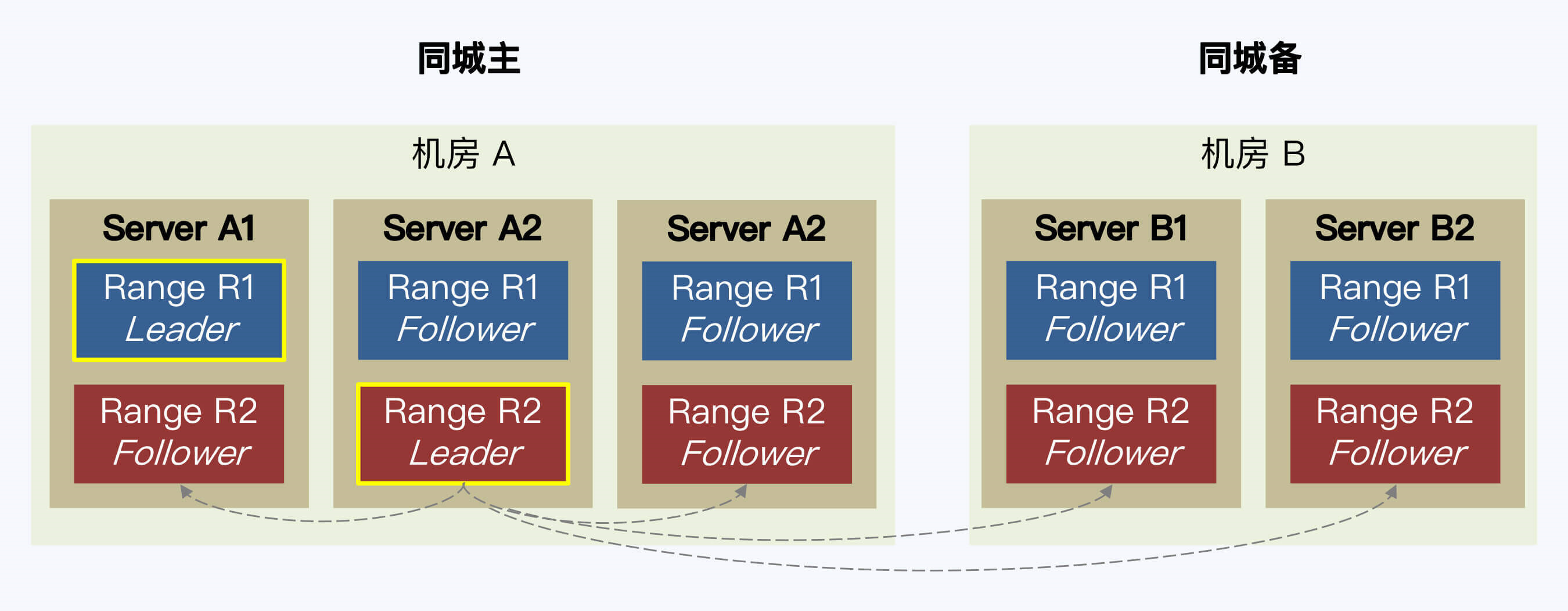
- 同城双机房
- 为保证主机房高可用,raft在主机房部署多个副本
- 理想的架构是:三地五副 + raft降级
- follower read,源端读取无法保证一致性
- CockroachDB支持,但无法保证一致性,TiDB的follower不支持跨机房部署
- 利用raft无日志空洞,在数据密集情况下,日志时间戳 > 查询时间戳 即可保证最新
- 分片数据比较冷时,将时间戳更新时间 附加到raft通信包中打包发送,其他节点判断
- 全球化的意义
- 真正的异地机房读和写
- 异地机房如果是容灾需要定期演练,相比于时刻运行的系统,仍不能让人放心
- 容灾与备份
- 选择一个稳定成熟的逃生库
- 异构数据库之间的复制方案
- 数据文件,通过文件导入导出方式同步(全量)
- ETL(Extract-Transform-Load)
- CDC(Change Data Capture),业务入侵小
- Oracle的OGG(Gold Gate)
- DB2的Inforsphere CDC
- 逃生方案
- 日志格式适配,一般分布式数据库都兼容MySQL、PostgreSQL
- 选择更强的单体数据库如Oracle,分布式数据库 -> 消息队列 <-> 逃生库 的架构
- 事务一致性
- 事务处理
- 每个Raft Group的leader发送Raft日志
- 难点在于跨分片日志的处理
- 通过时间戳可以判断出 ts1 < ts2,然后重放ts1时刻的日志
- ts1时刻可能产生了多条变更,逃生库在同一时间可能没有收到所有时间戳变更日志
- CockroachDB引入了"Resolved"消息
- 容器化
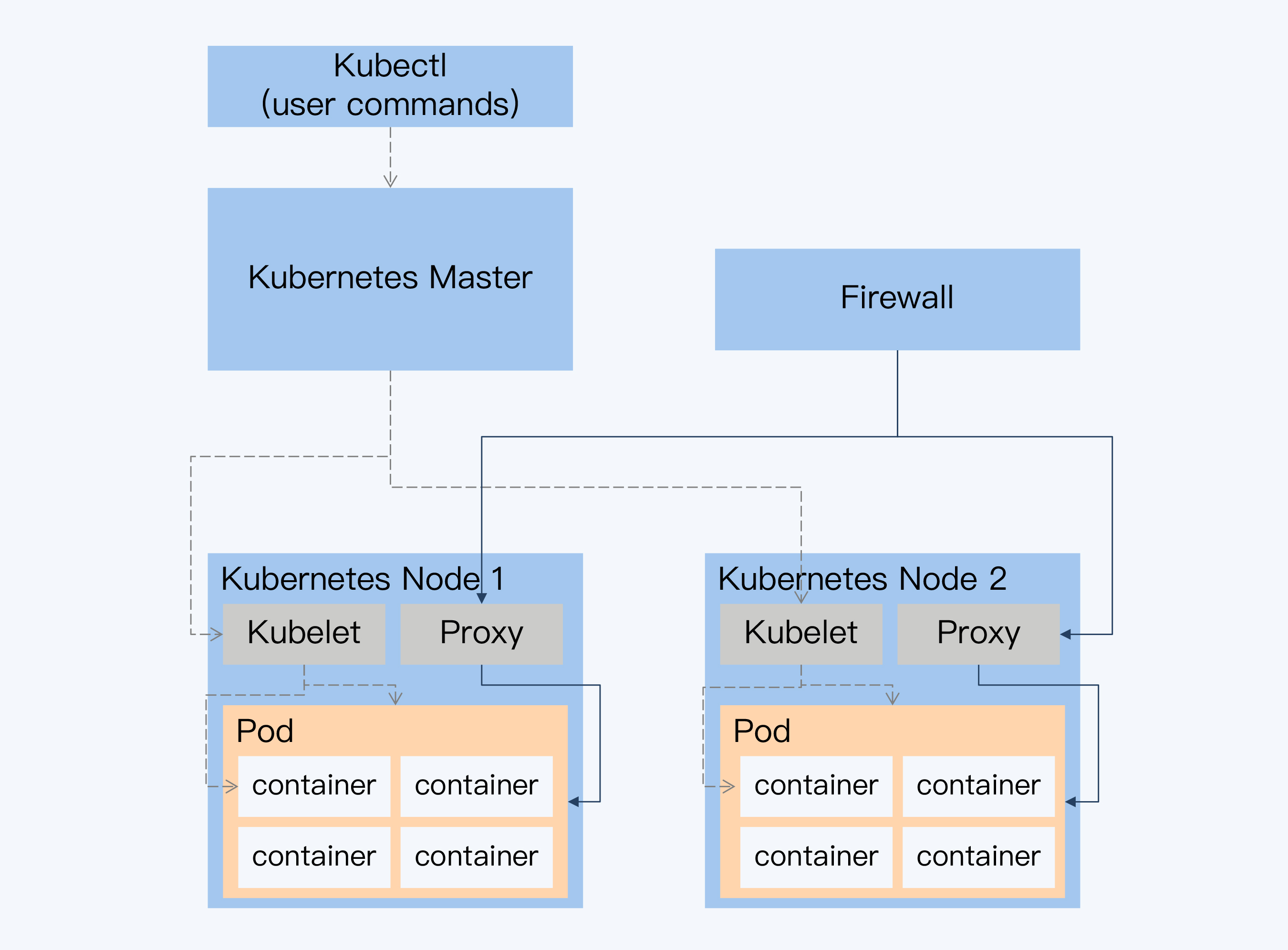
- Kubernetes:
- Container:Cgroup、Namespace、AUFS
- Pod
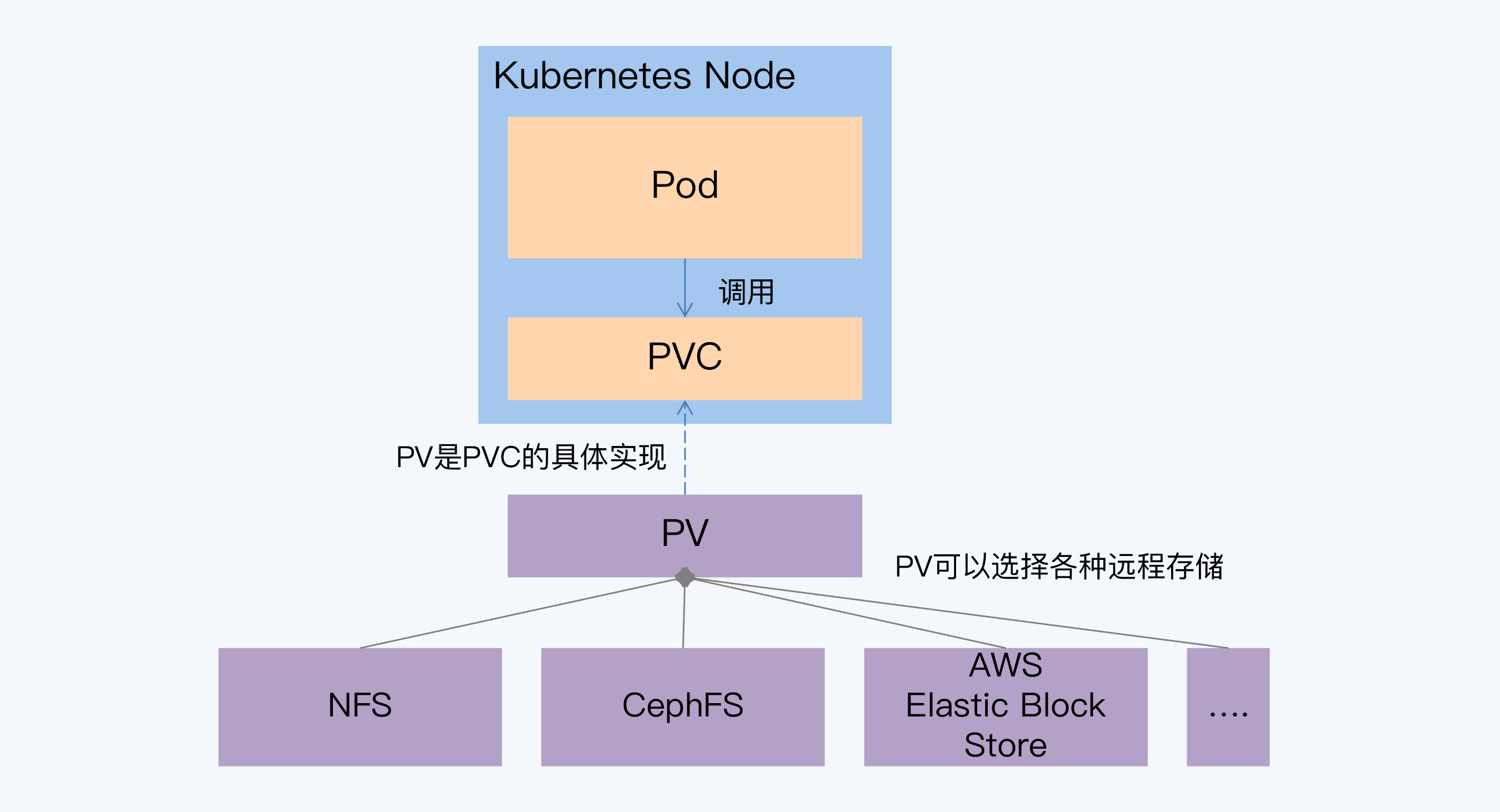
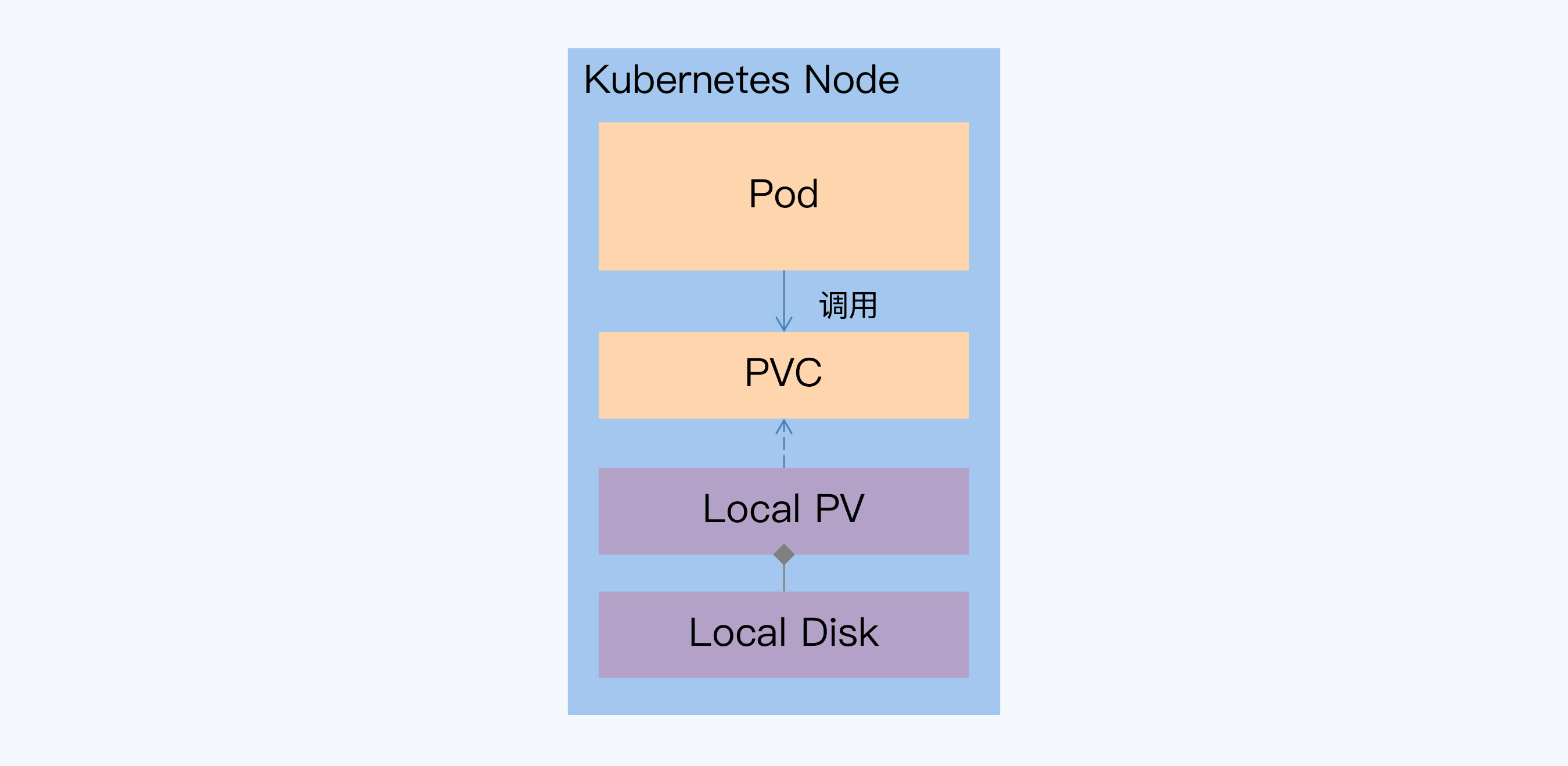
- 有状态服务,存储状态,还有状态拓扑,因为集群中不同角色作用不同
- 底层基于分布式文件系统、挂本地盘方式
- Operator:利用k8s自定义资源来描述用户期望的部署状态;在控制器里根据自定义API对象变化,完成部署和运维工作
- 大数据可用性低于OLTP场景,但集群规模更大,更适合容器化
- Kubernetes:
- 产品测试
- TPC-C(Transaction Processing Performance Council),国际事务性能委员会,针对OLTP场景
- TPC-H 针对OLAP场景
- 针对数据仓库建模又推出了TPC-DS
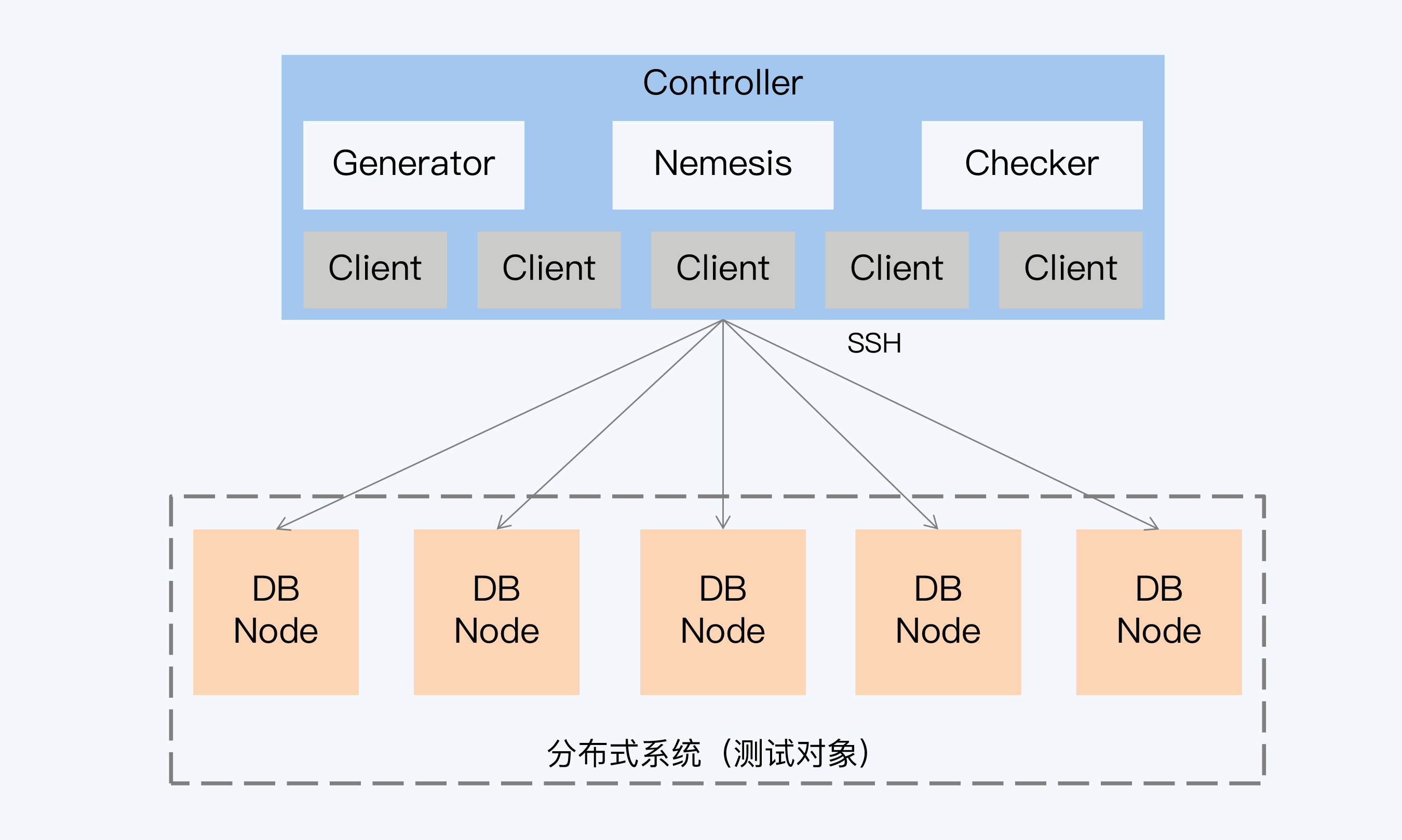
- 开源的分布式一致性验证框架:Jepsen
- 测试分布式数据库、键值系统、消息队列
- 工作方式:Generator生成客户端操作;Nemesis实现故障注入;Checker分析每个客户端一致性
- 混沌工程
- 复杂性、实验、生成环境
- TLA(Temporal Logical of Actions 行为时态逻辑)
- 形式化验证(Formal Verification),用数学方法去证明系统是无Bug的
- 需要用数学语言重写一遍,代价太高
- 用TLA验证关键逻辑,剩余大部分靠测试验证
- 银行案例
- 工行OLTP:分布式中间件+开源单体数据库;OLAP联合华为GaussDB200,对标TeraData和GreenPlum
- 邮政储蓄:PG,单元化架构,但是改造起来也很麻烦
- 交通银行:自研NewSQL数据库CBase
- 中信银行:自研GoldenDB,属于PGXC架构
- 北京银行:OceanBase,南京银行也选用了这个数据库
- 张家港银行:TDSQL
- 城商行选择NewSQL的原因
- 国产化诉求
- 实际收益
- 技术潮流
- 光大银行:NewSQL+分库分表
- 选型建议
- 产品选型要服从项目整体目标
- 先进的产品可能会延长项目交付时间
- 当产品选型可能导致业务流程变更时,谨慎对待
- 产品选中的非技术因素
- 评估技术潮流对选型的影响
- 分布式数据库
- Spanner,F1(前端),兼顾OLTP和OLAP场景
- CockroachDB
- YugabyteDB
- TiDB
- PGXC,TDSQL、TBase、GoldenDB
- VoltDB
- SequoiaDB
全球化部署
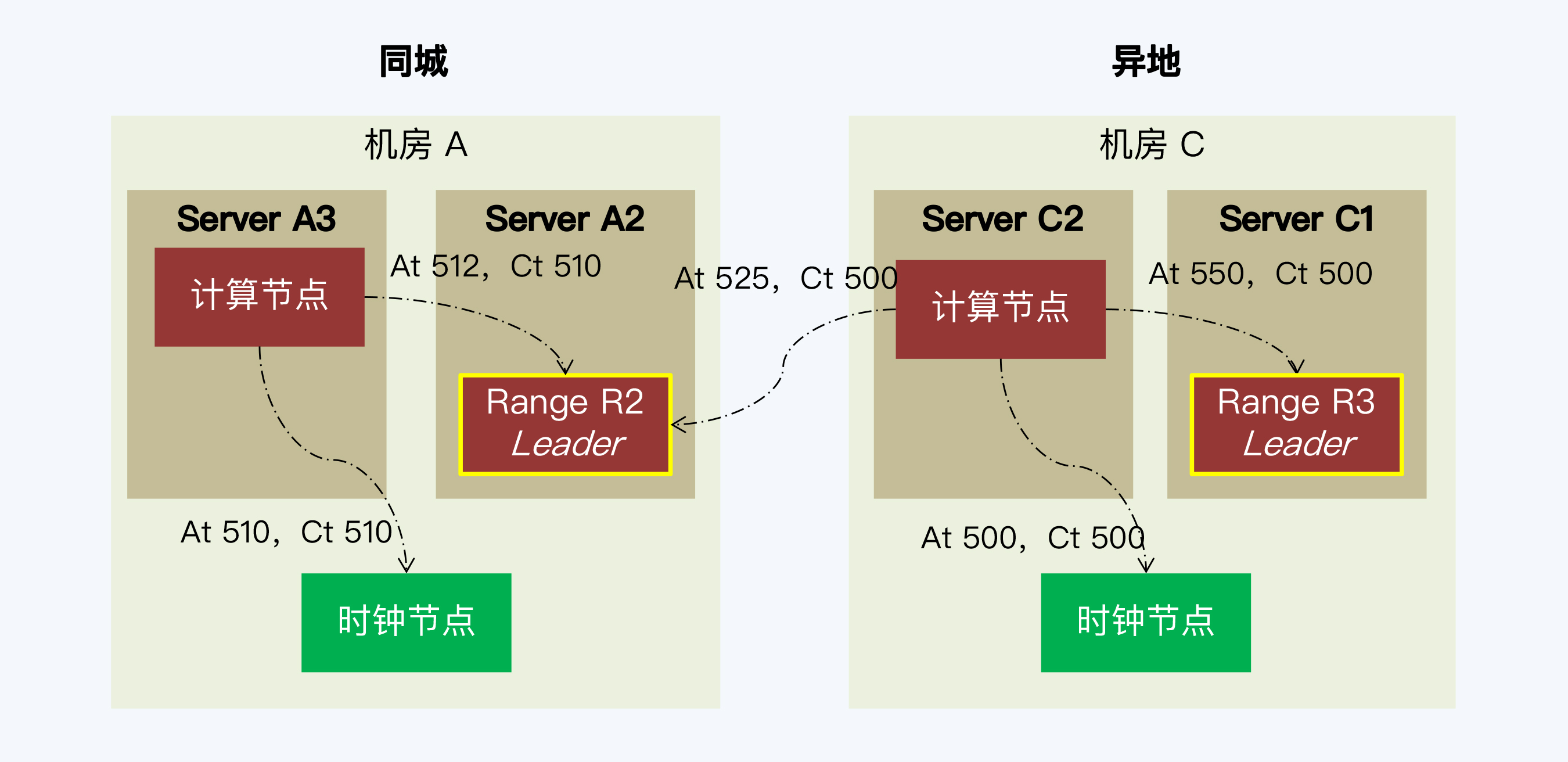
同城双机房的退化模式
逃生库的分片日志复制方式
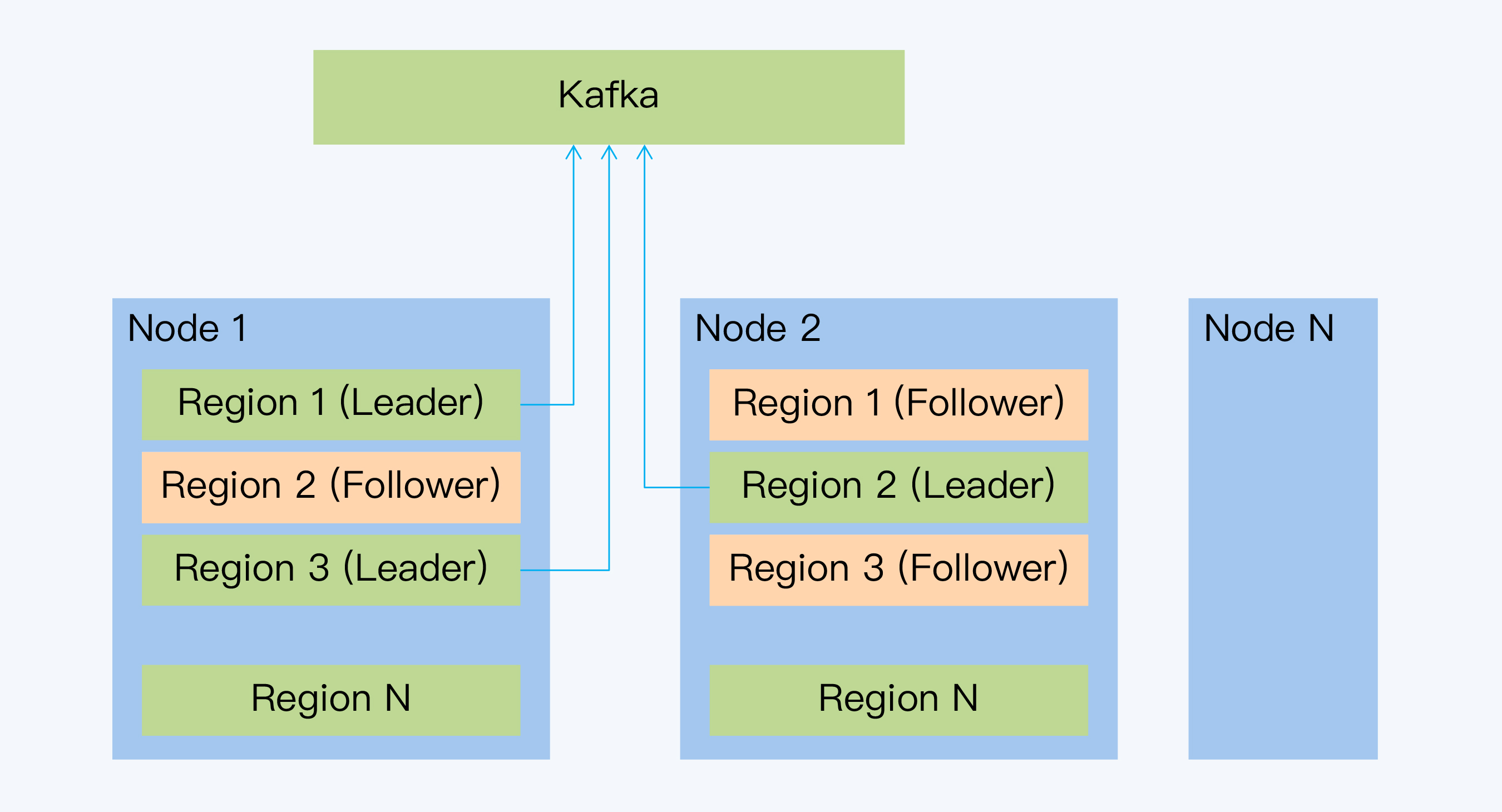
逃生库的事务一致性

Kubernetes架构
Kubernetes有状态存储-分布式文件系统方式
Kubernetes有状态存储-挂本地盘方式
论文
- Jepsen Github
- Jepsen Analyses
- A Temporal Logic of Actions
- Specifying Concurrent System with TLA+
- Specifying Systems:The TLA+ Language and Tools for Software Engineers
- Transaction Processing Performance Council
- 分布式数据库在金融应用场景中的探索与实践
- F1 Query:Declarative Querying at Scale
- Spanner:Becoming a SQL System
- TiDB, A Raft-based HTAP Database
- F1:A Distributed SQL Database That Scales
- Spanner: Google’s Globally-Distributed Database
- CockroachDB:The Resilient Geo-Distributed SQL Database
思维导图
