数据迁移工具DB-bridge
功能介绍
介绍
数据库应用服务迁移(DTS-DBbridge)是一款支持异构数据库和同构数据库之间迁移和同步的企业级产品。DTS-DBbridge 可以帮助企业实现 完整数据库迁移(尤其是 Oracle 数据库),进而降低企业数据库 IT 成本和满足技术复杂度需求,适应企业多样化数据传输、数据汇聚、数 据灾备等数据库架构和业务场景。
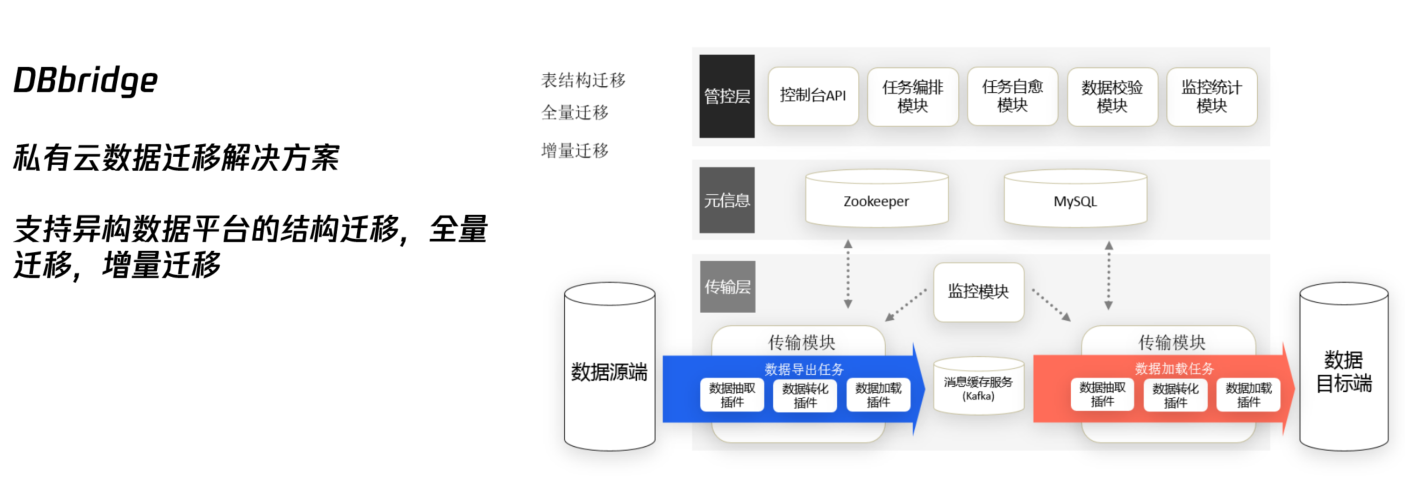
包含功能:
1、迁移评估
2、表结构导出
3、全量迁移
4、增量迁移
5、数据校验
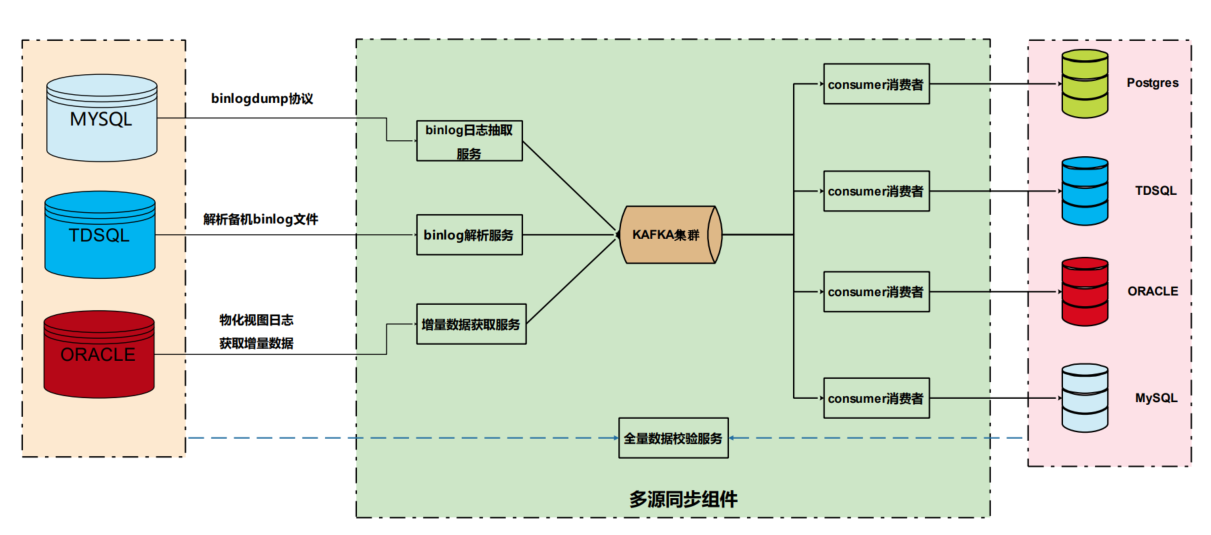
增量迁移的整体架构,增量同步使用到了 kafka
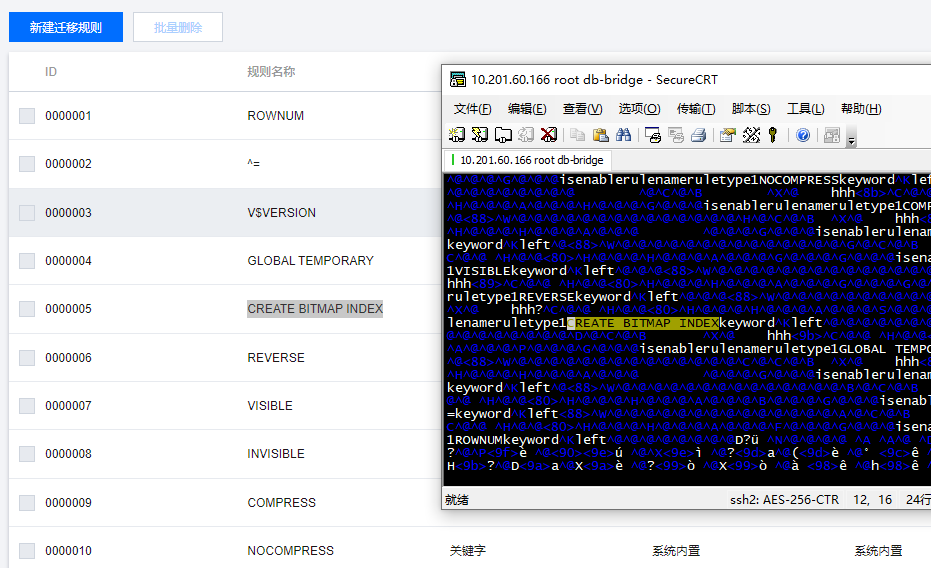
内置了很多迁移规则
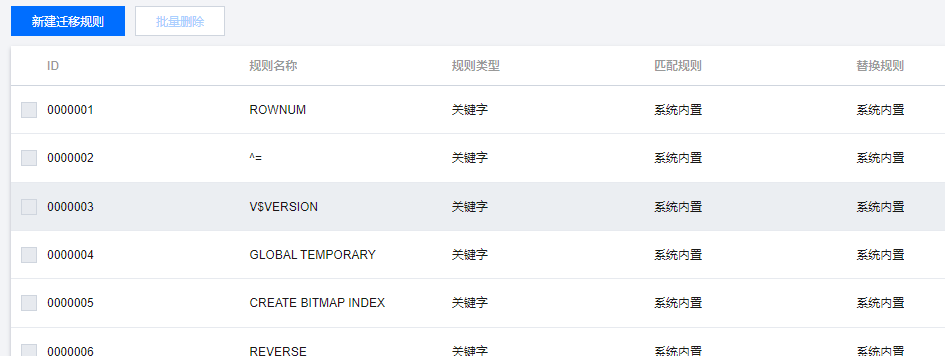
解析语法,将 A -> B,包括:
- 关键字
- 数据类型
- 函数
对应的还有一个迁移模板,一个模板中就带了很多迁移规则
安装
安装步骤
修改 /etc/yum.conf,增加 代理:
|
|
安装相应软件:
|
|
按照官网的文档来就可以了,经测试一步步来,安装正确
文档地址
记得要把 license 拷贝过去,不然服务起不来
有两点需要注意: 1、官方文档说需要提前建立 dbbridge 账号,但我看了脚本,脚本里面也会创建这个账号,所以不要建账号,直接执行脚本即可
2、我把脚本里面的配置防火墙的逻辑给注释掉了
也就是这段:
|
|
可以把防火墙直接关掉:
|
|
注意事项
日志文件路径: /bridge/data/log4engine
增量同步的时候,会有一个坑:
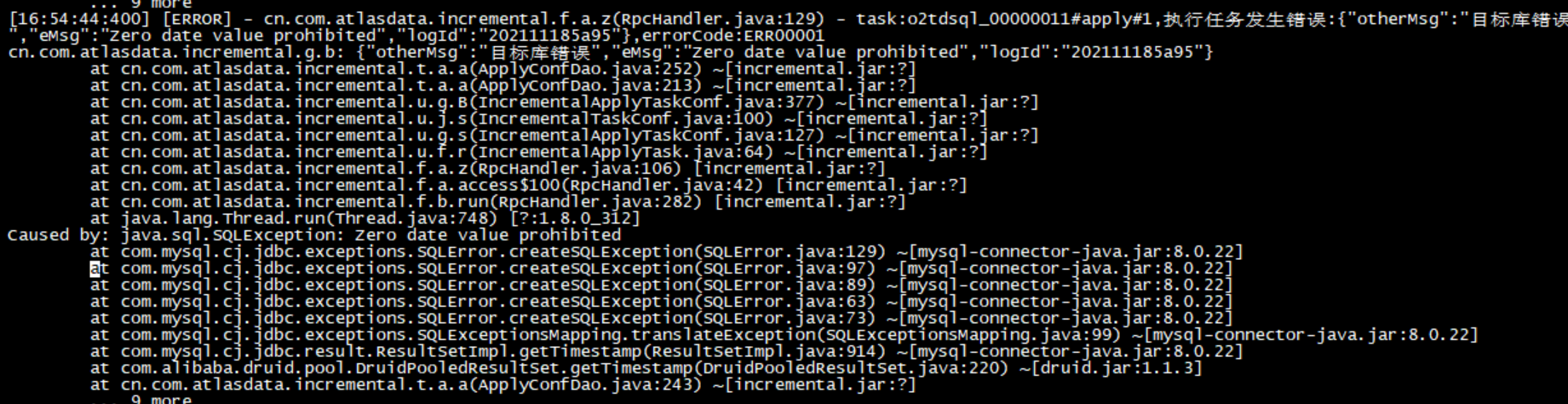
这里显示的是目标端 mysql 的时间类型有问题, Zero date value prohibited
这是因为时间格式不合法,去 TD-SQL里面检查一下,test库里面有个tb_kafkaoffset表
它有两个时间字段,默认值都是 0000-00-00 00:00:00
把它改成CURRENT_TIMESTAMP就可以了
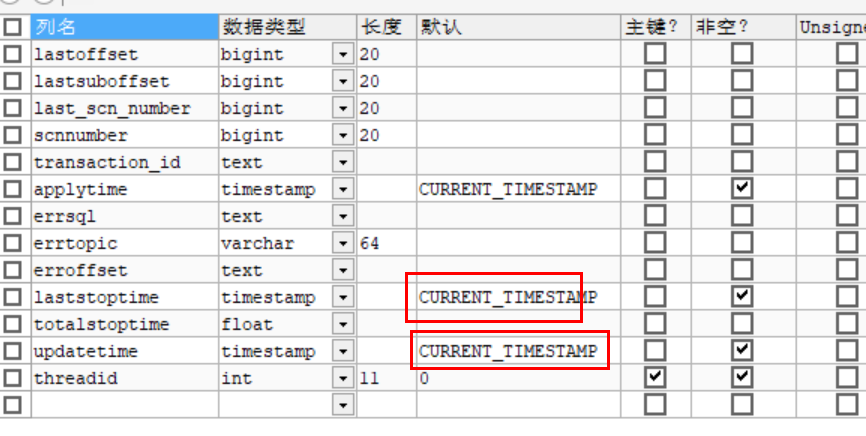
这个表,看名字,可能是给 kafka用的,做增量的偏移量用的
检查 TD-SQL,也就是mysql的binlog 是否开启
|
|
迁移案例
这里有两个 迁移Oralce的案例
四川移动迁移
大体内容 PPT 上面都已经列出来了,这里总结一下
1、原系统采用 Oracle + IBM小型机,包含:产品中心 实时营销中心 两套系统
2、两套系统一共大概 8 个机器,A系统总量 13TB、B系统总量 2.3TB,两套系统峰值TPS 1100
3、产品中心搭建了一套同城双中心读写分离方案,8台机器
4、实时营销 单机房部署,13台机器
5、使用 Oracle自带的 XStream增量同步工具,写入 DBbridge,再通过JDBC写入TBase
6、DB-bridge包含了全量、增量、反向、两边数据一致性校验功能
7、迁移评估对象总数 2037(这里的对象不清楚是什么意思),兼容 7个,可转换对象 1992个,不兼容对象38个,不兼容比列 1.8%
8、迁移总时间为 5个月,四川移动需要重写修改业务逻辑,腾讯方也要配合增强语法支持,总耗时:50人月
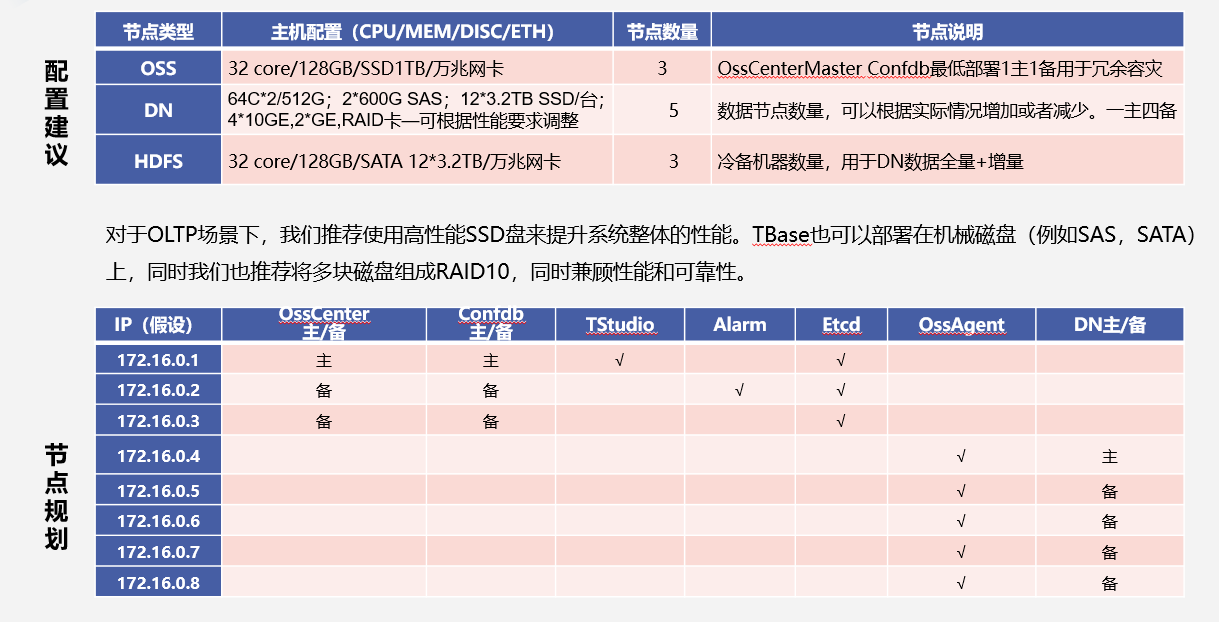
机器配置:
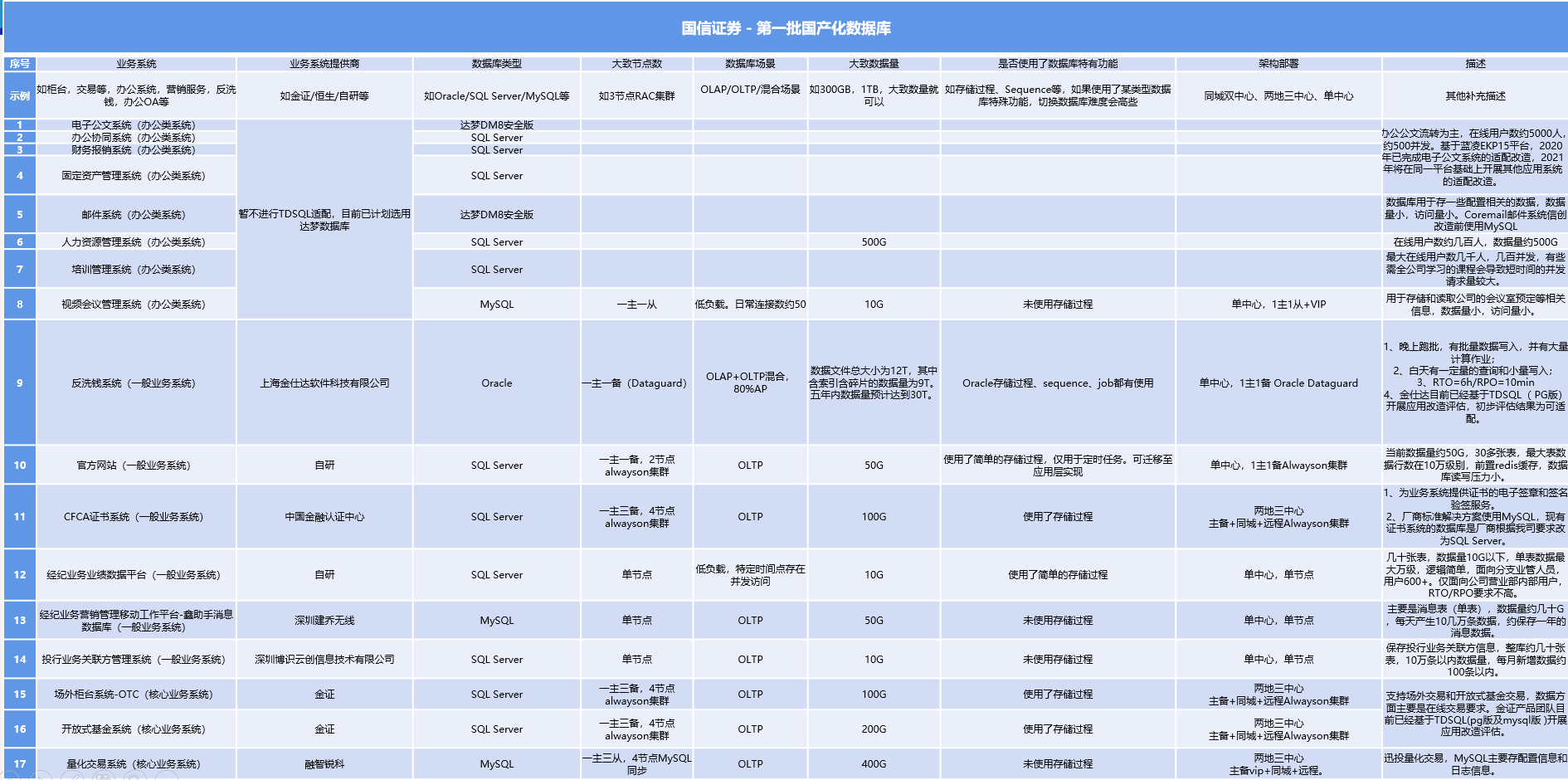
国信证券迁移
这部分内容比较少,从表格看大概有 17个子系统,使用了各种数据库,包括:SqlServer、Oracle、MySQL
国信证券列出了选型的 6种数据库,包括:
- 达梦
- 中兴GoldenDB
- 腾讯TBase
- 阿里OceanBase
- 华为GaussDB
- TiDB
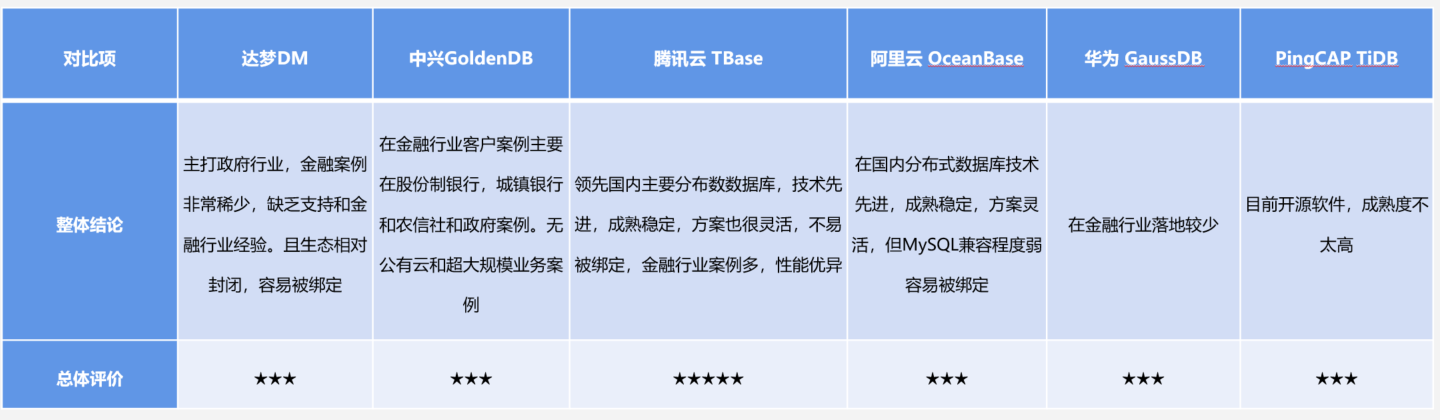
国信证券列出了简单的测试对比,Oracle vs TBase
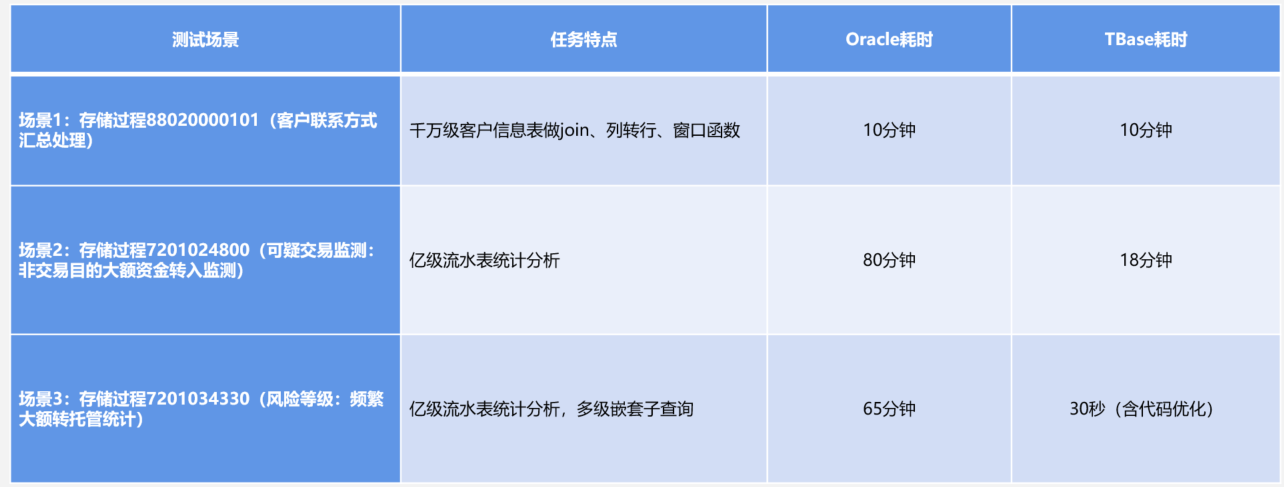
看起来应该是偏 OLAP 方面的,具体硬件、机器数量没有列出来,数据是否有说服力有待商榷
内部实现
规则配置信息,是存储在内部的 atlasdb 中的
deployment目录:
- atlasdb,配置信息库
- dbbridge,控制台,全量同步
- incremental,增量同步,似乎用了atlasdata相关组件,这是java写的,似乎做了代码混淆
- lib,相关so,和jar文件如oracle jdbc客户端
- lic
- scripts
dbbridge的配置文件,这是用spring写的
|
|
db-bridge的jar包里面:
BOOT-INF/lib/dbbridgehelper-2.5-SNAPSHOT.jar
BOOT-INF/lib/sqlparser-3.2-SNAPSHOT.jar
BOOT-INF/lib/migratehelper-2.5-SNAPSHOT.jar
这几个用的都是 atlasdata 的组件
sqlparser-3.2的jar包中,看起来支持的方言还不少
实现原理研究
评估研究
创建评估报告是 dbbridge 实现的,这是一个 java 程序
默认情况下不会连接 Oracle,当开启了【评估】功能时,就会连接到Oracle,用了JDBC的方式去查询元数据
这里要查找 xxx 库下的 DEMO 表
0000 00 00 0c 07 ac 3c 00 15 5d 3c 38 35 08 00 45 00 .....<..]<85..E.
0010 02 92 78 6a 40 00 40 06 31 a9 0a c9 3c a6 0a c8 ..xj@[email protected]...<...
0020 3c 1c 86 e8 05 f1 bf 40 ee f2 ac 0c c6 ee 80 18 <......@........
0030 01 99 90 d7 00 00 01 01 08 0a 23 5f d4 02 2b 58 ..........#_..+X
0040 c9 e2 02 5e 00 00 06 00 00 00 00 00 11 69 0c 01 ...^.........i..
0050 01 01 01 02 03 5e 0d 02 80 29 00 01 02 01 f7 01 .....^...)......
0060 01 0d 00 00 04 ff ff ff ff 01 c8 04 7f ff ff ff ................
0070 01 01 01 00 00 00 00 00 00 00 00 00 01 00 00 00 ................
0080 00 00 53 45 4c 45 43 54 20 28 44 53 2e 42 59 54 ..SELECT (DS.BYT
0090 45 53 20 2b 4e 56 4c 28 4c 53 2e 42 59 54 45 53 ES +NVL(LS.BYTES
00a0 2c 20 30 29 29 20 74 61 62 73 69 7a 65 2c 44 53 , 0)) tabsize,DS
00b0 2e 53 45 47 4d 45 4e 54 5f 4e 41 4d 45 20 46 52 .SEGMENT_NAME FR
00c0 4f 4d 20 44 42 41 5f 53 45 47 4d 45 4e 54 53 20 OM DBA_SEGMENTS
00d0 44 53 20 4c 45 46 54 20 4a 4f 49 4e 20 28 53 45 DS LEFT JOIN (SE
00e0 4c 45 43 54 20 41 4c 2e 4f 57 4e 45 52 2c 41 4c LECT AL.OWNER,AL
00f0 2e 54 41 42 4c 45 5f 4e 41 4d 45 2c 53 55 4d 28 .TABLE_NAME,SUM(
0100 44 53 4c 2e 42 59 54 45 53 29 20 42 59 54 45 53 DSL.BYTES) BYTES
0110 20 46 52 4f 4d 20 41 4c 4c 5f 4c 4f 42 53 20 41 FROM ALL_LOBS A
0120 4c 20 4c 45 46 54 20 4a 4f 49 4e 20 44 42 41 5f L LEFT JOIN DBA_
0130 53 45 47 4d 45 4e 54 53 20 44 53 4c 20 4f 4e 20 SEGMENTS DSL ON
0140 44 53 4c 2e 53 45 47 4d 45 4e 54 5f 54 59 50 45 DSL.SEGMENT_TYPE
0150 3d 27 4c 4f 42 53 45 47 4d 45 4e 54 27 20 41 4e ='LOBSEGMENT' AN
0160 44 20 20 44 53 4c 2e 4f 57 4e 45 52 20 3d 20 41 D DSL.OWNER = A
0170 4c 2e 4f 57 4e 45 52 20 20 41 4e 44 20 44 53 4c L.OWNER AND DSL
0180 2e 53 45 47 4d 45 4e 54 5f 4e 41 4d 45 20 3d 20 .SEGMENT_NAME =
0190 41 4c 2e 53 45 47 4d 45 4e 54 5f 4e 41 4d 45 20 AL.SEGMENT_NAME
01a0 20 47 52 4f 55 50 20 42 59 20 41 4c 2e 4f 57 4e GROUP BY AL.OWN
01b0 45 52 2c 41 4c 2e 54 41 42 4c 45 5f 4e 41 4d 45 ER,AL.TABLE_NAME
01c0 29 20 4c 53 20 4f 4e 20 4c 53 2e 4f 57 4e 45 52 ) LS ON LS.OWNER
01d0 3d 44 53 2e 4f 57 4e 45 52 20 41 4e 44 20 4c 53 =DS.OWNER AND LS
01e0 2e 54 41 42 4c 45 5f 4e 41 4d 45 20 3d 20 44 53 .TABLE_NAME = DS
01f0 2e 53 45 47 4d 45 4e 54 5f 4e 41 4d 45 20 57 48 .SEGMENT_NAME WH
0200 45 52 45 20 44 53 2e 53 45 47 4d 45 4e 54 5f 54 ERE DS.SEGMENT_T
0210 59 50 45 20 69 6e 20 28 27 54 41 42 4c 45 27 2c YPE in ('TABLE',
0220 27 54 41 42 4c 45 20 50 41 52 54 49 54 49 4f 4e 'TABLE PARTITION
0230 27 2c 27 54 41 42 4c 45 20 53 55 42 50 41 52 54 ','TABLE SUBPART
0240 49 54 49 4f 4e 27 29 20 41 4e 44 20 44 53 2e 4f ITION') AND DS.O
0250 57 4e 45 52 3d 3a 31 20 20 20 41 4e 44 20 44 53 WNER=:1 AND DS
0260 2e 53 45 47 4d 45 4e 54 5f 4e 41 4d 45 20 69 6e .SEGMENT_NAME in
0270 20 28 27 44 45 4d 4f 27 29 01 01 00 00 00 00 00 ('DEMO').......
0280 00 01 01 00 00 00 00 00 01 03 00 00 01 18 00 01 ................
0290 10 00 00 02 03 69 01 00 07 06 77 61 6e 67 62 6f .....i....wangbo
之后又连接了一次,这是 通过 抓包后的结果
之后,又测试了 xxxx2 这个库,这个是测试的专用库,里面有不少表、函数、存储过程、触发器等
同样抓包后发现,也是通过 SELECT 去查找 Oracle的元信息,得到表结构,存储过程、函数结构的
抓包后的结果如下,需要用 Wireshark 打开
evaluate是评估单个表的
evaluate_2是评估xxxx2这个库下所有的对象
全量测试
连接Oracle时,抓包结果
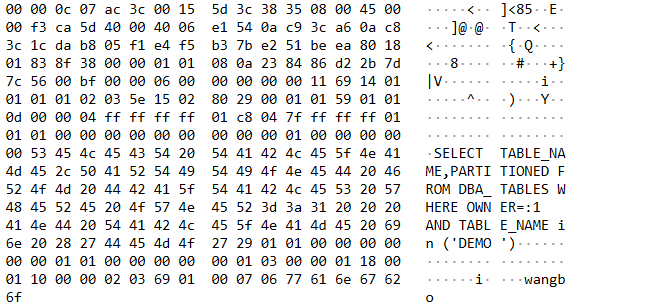
再次请求:
0000 00 00 0c 07 ac 3c 00 15 5d 3c 38 35 08 00 45 00 .....<..]<85..E.
0010 02 a8 ca 5e 40 00 40 06 df 9e 0a c9 3c a6 0a c8 ...^@.@.....<...
0020 3c 1c da b8 05 f1 e4 f5 b4 3a e2 51 bf cf 80 18 <........:.Q....
0030 01 99 90 ed 00 00 01 01 08 0a 23 84 86 d5 2b 7d ..........#...+}
0040 7c 5c 02 74 00 00 06 00 00 00 00 00 11 69 16 01 |\.t.........i..
0050 01 01 01 03 03 5e 17 02 80 29 00 01 02 02 0d 01 .....^...)......
0060 01 0d 00 00 04 ff ff ff ff 01 c8 04 7f ff ff ff ................
0070 01 01 01 00 00 00 00 00 00 00 00 00 01 00 00 00 ................
0080 00 00 53 45 4c 45 43 54 20 44 53 2e 53 45 47 4d ..SELECT DS.SEGM
0090 45 4e 54 5f 4e 41 4d 45 2c 28 44 53 2e 42 59 54 ENT_NAME,(DS.BYT
00a0 45 53 20 2b 4e 56 4c 28 4c 53 2e 42 59 54 45 53 ES +NVL(LS.BYTES
00b0 2c 20 30 29 29 20 74 61 62 73 69 7a 65 20 46 52 , 0)) tabsize FR
00c0 4f 4d 20 44 42 41 5f 53 45 47 4d 45 4e 54 53 20 OM DBA_SEGMENTS
00d0 44 53 20 4c 45 46 54 20 4a 4f 49 4e 20 0a 20 28 DS LEFT JOIN . (
00e0 53 45 4c 45 43 54 20 41 4c 2e 4f 57 4e 45 52 2c SELECT AL.OWNER,
00f0 41 4c 2e 54 41 42 4c 45 5f 4e 41 4d 45 2c 53 55 AL.TABLE_NAME,SU
0100 4d 28 44 53 4c 2e 42 59 54 45 53 29 20 42 59 54 M(DSL.BYTES) BYT
0110 45 53 20 46 52 4f 4d 20 41 4c 4c 5f 4c 4f 42 53 ES FROM ALL_LOBS
0120 20 41 4c 20 4c 45 46 54 20 4a 4f 49 4e 20 44 42 AL LEFT JOIN DB
0130 41 5f 53 45 47 4d 45 4e 54 53 20 44 53 4c 20 4f A_SEGMENTS DSL O
0140 4e 20 44 53 4c 2e 53 45 47 4d 45 4e 54 5f 54 59 N DSL.SEGMENT_TY
0150 50 45 3d 27 4c 4f 42 53 45 47 4d 45 4e 54 27 0a PE='LOBSEGMENT'.
0160 20 41 4e 44 20 20 44 53 4c 2e 4f 57 4e 45 52 20 AND DSL.OWNER
0170 3d 20 41 4c 2e 4f 57 4e 45 52 20 20 41 4e 44 20 = AL.OWNER AND
0180 44 53 4c 2e 53 45 47 4d 45 4e 54 5f 4e 41 4d 45 DSL.SEGMENT_NAME
0190 20 3d 20 41 4c 2e 53 45 47 4d 45 4e 54 5f 4e 41 = AL.SEGMENT_NA
01a0 4d 45 20 0a 20 47 52 4f 55 50 20 42 59 20 41 4c ME . GROUP BY AL
01b0 2e 4f 57 4e 45 52 2c 41 4c 2e 54 41 42 4c 45 5f .OWNER,AL.TABLE_
01c0 4e 41 4d 45 29 20 4c 53 20 4f 4e 20 4c 53 2e 4f NAME) LS ON LS.O
01d0 57 4e 45 52 3d 44 53 2e 4f 57 4e 45 52 20 41 4e WNER=DS.OWNER AN
01e0 44 20 4c 53 2e 54 41 42 4c 45 5f 4e 41 4d 45 20 D LS.TABLE_NAME
01f0 3d 20 44 53 2e 53 45 47 4d 45 4e 54 5f 4e 41 4d = DS.SEGMENT_NAM
0200 45 20 0a 20 57 48 45 52 45 20 44 53 2e 53 45 47 E . WHERE DS.SEG
0210 4d 45 4e 54 5f 54 59 50 45 20 69 6e 20 28 27 54 MENT_TYPE in ('T
0220 41 42 4c 45 27 2c 27 54 41 42 4c 45 20 50 41 52 ABLE','TABLE PAR
0230 54 49 54 49 4f 4e 27 29 20 41 4e 44 20 44 53 2e TITION') AND DS.
0240 53 45 47 4d 45 4e 54 5f 4e 41 4d 45 20 4e 4f 54 SEGMENT_NAME NOT
0250 20 4c 49 4b 45 20 27 42 49 4e 24 25 27 20 41 4e LIKE 'BIN$%' AN
0260 44 20 44 53 2e 4f 57 4e 45 52 3d 3a 31 20 20 20 D DS.OWNER=:1
0270 41 4e 44 20 44 53 2e 53 45 47 4d 45 4e 54 5f 4e AND DS.SEGMENT_N
0280 41 4d 45 20 69 6e 20 28 27 44 45 4d 4f 27 29 01 AME in ('DEMO').
0290 01 00 00 00 00 00 00 01 01 00 00 00 00 00 01 03 ................
02a0 00 00 01 18 00 01 10 00 00 02 03 69 01 00 07 06 ...........i....
02b0 77 61 6e 67 62 6f wangbo
读取数据:
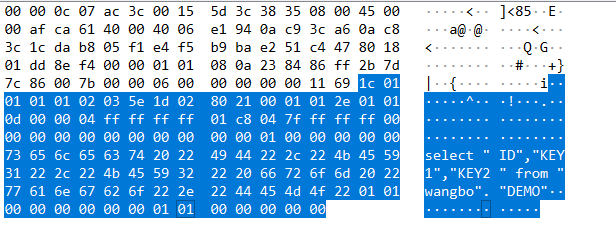
所以,它就是通过JDBC的方式,传入指定的 SQL,来读取数据的
增量测试
通过抓包看,应该是 增量程序 通过SQL的方式写入到目标端的

增量程序会实时的连接到 TD-SQL端
查询 test库下的tb_kafkaoffset表
这个表的表结构是这样的:
|
|
表的内容

即使将增量程序暂停,也会实时的(差不多1-2秒左右)查询 tb_kafkaoffset 表,也会更新tb_kafkaoffset表
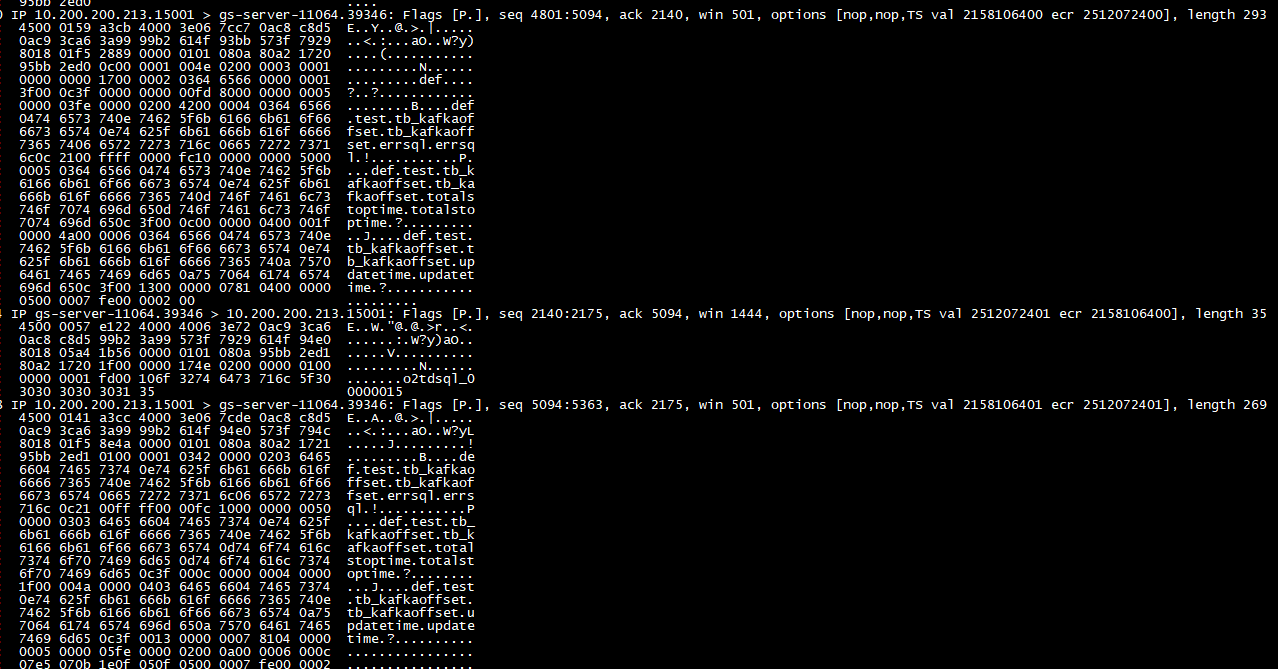
下面是更新逻辑:
amqp-client.jar commons-net.jar ganymed-ssh2.jar kafka-clients.jar mongodb-driver.jar postgresql.jar xdb.jar
bcprov-jdk15on.jar commons-pool2.jar guava.jar libthrift.jar msgpack-core.jar protobuf-java.jar xmlbeans.jar
bson.jar curator-client.jar HikariCP-java6.jar log4j-api.jar mysql-connector-java.jar quartz.jar xmlparserv2.jar
c3p0.jar curator-framework.jar httpclient.jar log4j-core.jar netty.jar serialize.jar xstreams.jar
cache4j.jar curator-recipes.jar httpcore.jar log4j.jar ojdbc8.jar slf4j-api.jar zookeeper.jar
commons-codec.jar curvesapi.jar jconsole.jar log4j-slf4j-impl.jar orai18n.jar snappy-java.jar zstd-jni.jar
commons-collections4.jar druid.jar jedis.jar lz4-java.jar poi.jar sqlparser.jar
commons-lang3.jar eventbus.jar jline.jar mchange-commons-java.jar poi-ooxml.jar stax-api.jar
commons-logging.jar fastjson.jar jsch.jar mongodb-driver-core.jar poi-ooxml-schemas.jar tools.jar
通过 netstat 看,增量程序连接了三个:
- kafka,本地的 9092端口
- 远端oracle库,1521端口
- 目标端的TD-SQL 15001端口
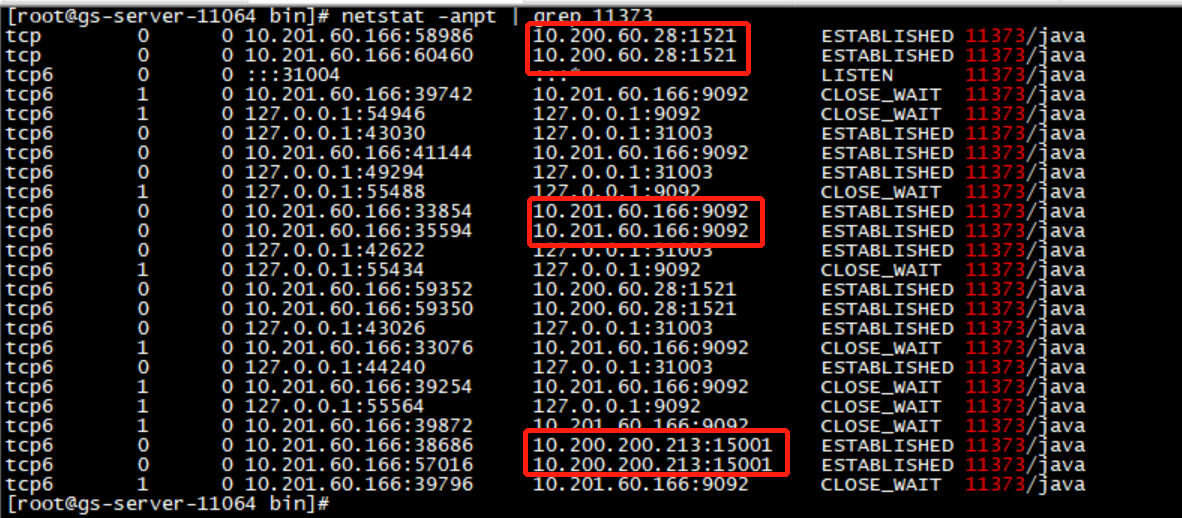
通过 grep 整个安装目录,发现在 Oracle端插入数据后,这个数据可以在 kafka 的数据文件中搜索到
也就是验证了,增量程序,会写入到 kafka

通过 iptables 将 写入 9092 kafka 封掉
|
|
netstat 看下
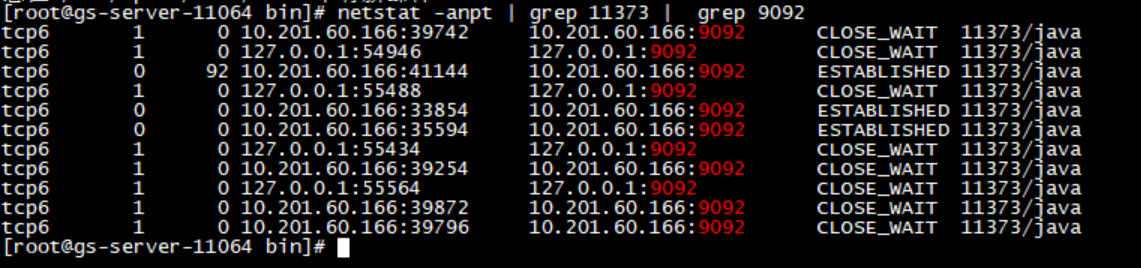
此时,在Oracle端,插入数据,目标端TD-SQL没有任何反映
说明增量的逻辑是:
Oracle <- incremental(生产者) -> kafka <- incremental(消费者) -> TD-SQL
高可用,是将 offset写入到 TD-SQL中的 tb_kafkaoffset 实现的
数据校验
读取元数据
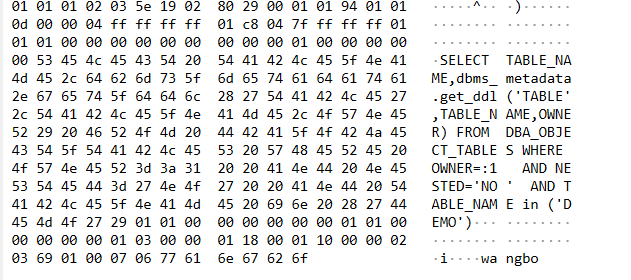
看起来是读所有内容,一行一行对比的
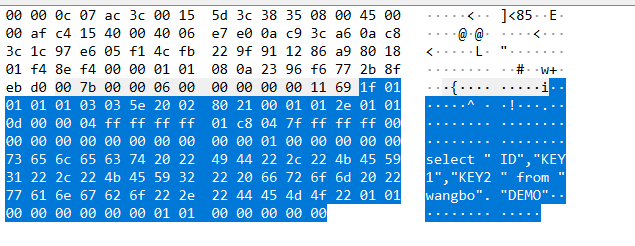
也对比了 count
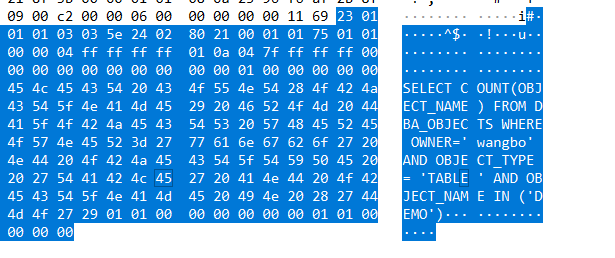
对于TD-SQL端,也是读取了全表数据
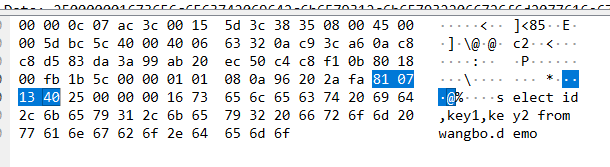
还读了TD-SQL的表结构
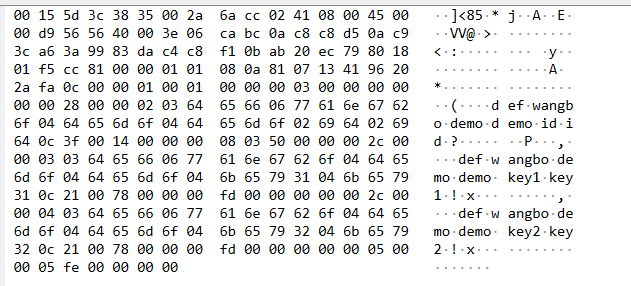
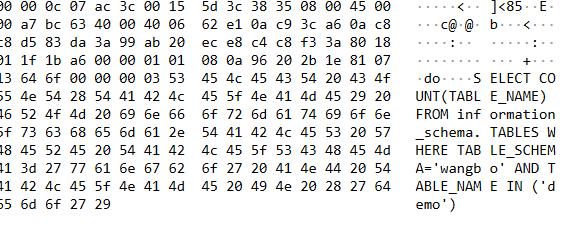
对TD-SQL端,也做了 count
参考
DTS-DBbridge官方文档
腾讯DBbridge产品-典型交付案例介绍.pptx
db_bridge_license.zip
MYSQL报:Zero date value prohibited