JDBC服务端解析
架构
服务端整体架构如下:
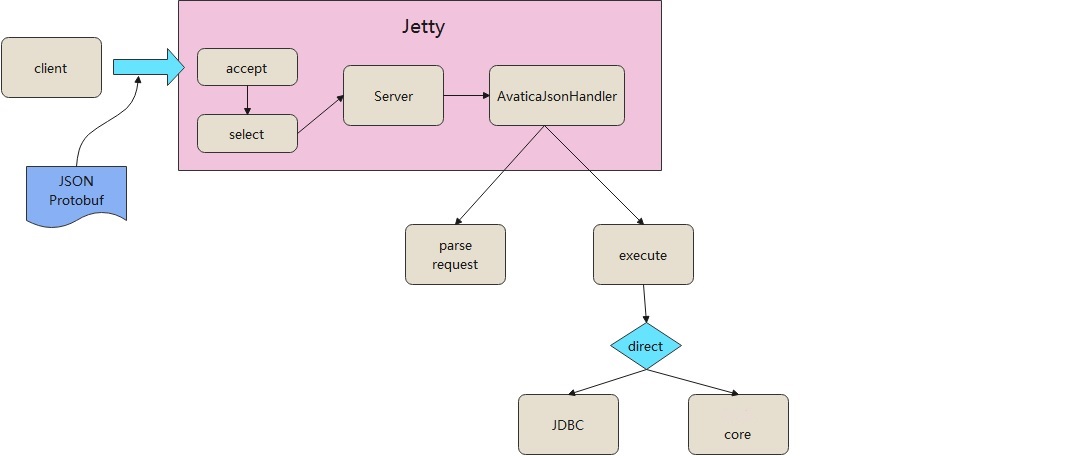
服务端依托于Jetty运行的,通过内嵌的方式启动一个jetty,将AvaticaJsonHandler注册到jeety中。
客户端发送的是JSON或者Protobuf格式的协议,服务端接收到请求后会调用AvaticaJsonHandler来处理这个请求。
AvaticaJsonHandler首先解析请求,然后执行请求内容,在执行的时候根据是否是直连会选择两种执行方式:
- 原始的JDBC方式执行
- 调用my-project来执行,这里就是调用SqlRunner、Pipeline那套流程
客户端和服务端进行交互的时候,是根据不同的操作,调用对应的对象,再将这些对象 编码/解码
比如,要执行创建连接,那么会触发一个openConnection的操作,之后生成OpenConnectionRequest的对象。客户端会将这个对象编码为 JSON 或者 Protobuf。
类似的,服务端会接收到这个 JSON,然后将其解码成OpenConnectionRequest对象,再触发对应的操作。
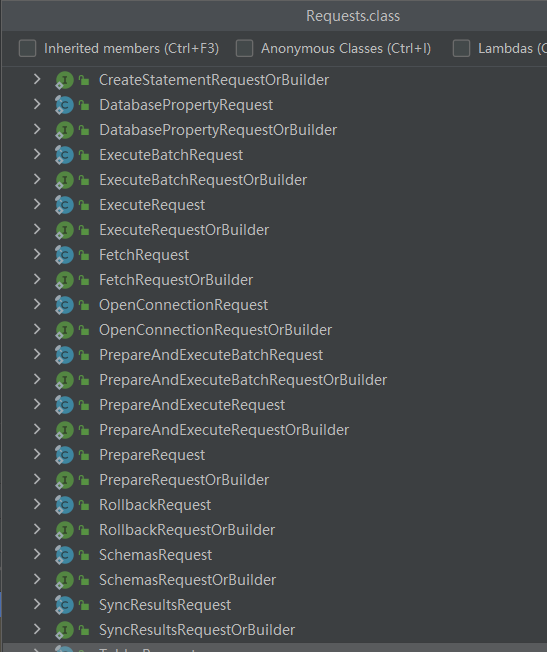
客户端封装的请求类型如下(下面的都是一系列操作对象,发送前会被编码为JSON格式):
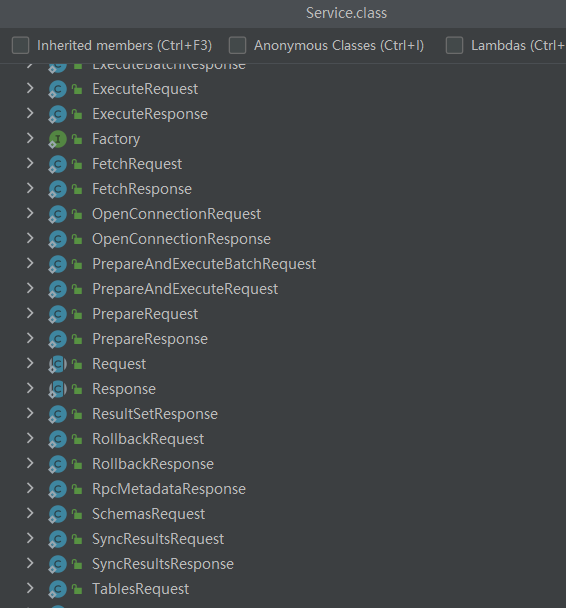
服务端封装的请求类型如下(将JSON格式解码为下面这些对象):
客户端 -> 服务端的交互概览如下:
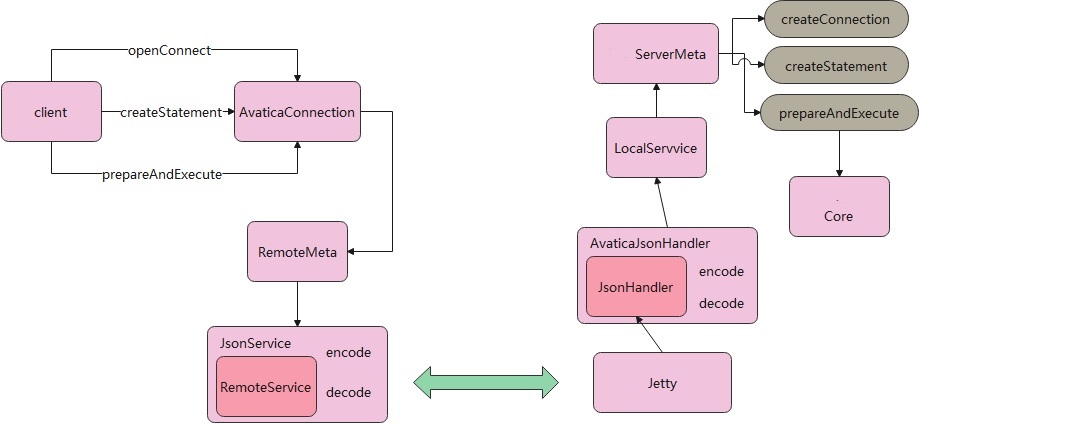
客户端执行 JDBC 查询,比如openConnect、createStatement等操作,这会委托给 AvaticaConnection 这个类去做。
AvaticaConnection 又会调用到Meta,Meta只是一个接口,所以需要一个具体的实现类。
这里的实现类是QuicksqlRemoteMeta,但看起来RemoteMeta也能完成,不清楚 quicksql 的实现有何用处
似乎Meta的实现类只是作为一个桥接用的,用来连接 AvaticaConnection 和 具体发送者之间的桥梁。
RemoteMeta 最后会交给 JsonService 来完成。在 JsonService 内部完成对象的编码 和 解码,HTTP发送动作是由 RemoteService来做的。
以上就是客户端的工作了,再看服务端:
服务端是依托于 Jetty 的,jetty 接收到请求会交给自定义的 AvaticaJsonHandler, 再交给 JsonHandler 来完成 decode 和 encode
所谓的 decode 就是将请求的 json 解码(用jackson将json解析成对象类型),之后交给 my-projectServiceMeta,这个类也类似于桥梁的作用,真正执行的是交给后面的 my-project-code去做的。
查询过程
创建连接
执行一个创建连接的动作:
1
|
Connection connection = DriverManager.getConnection(url, properties);
|
客户端会发送一个UUID,服务端根据这个UUID会将连接java.sql.Connection、java.sql.Statement给缓存(Guava)起来。
下次再有请求过来会首先从缓存中查找。
这里客户端需要服务端执行一个openConnection操作,也就是下面 json 中request中表示的
客户端发送json:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
{
"request": "openConnection",
"connectionId": "cebe4551-9788-439e-8d1a-792064cd7a00",
"info": {
"schemaPath": {
"version": "1.0",
"defaultSchema": "my_test",
"schemas": [{
"name": "my_test",
"type": "custom",
"factory": "org.apache.calcite.adapter.jdbc.JdbcSchema$Factory",
"operand": {
"jdbcDriver": "com.mysql.jdbc.Driver",
"jdbcUrl": "jdbc:mysql://10.200.64.11:3306/my_test?useSSL=false",
"jdbcUser": "name",
"jdbcPassword": "password",
"dbType": "mysql"
}
}]
}
}
}
|
服务端返回的json:
1
2
3
4
5
6
7
|
{
"response": "openConnection",
"rpcMetadata": {
"response": "rpcMetadata",
"serverAddress": "KJBJ-01-DN-004889:15888"
}
}
|
创建statement
再执行一个创建statement的动作:
1
|
Statement statement1 = connection.createStatement();
|
这里会继续触发一个 HTTP 请求,客户端会继续使用之前的 UUID,服务端根据 请求的 UUID 从缓存中取出连接。
这次客户端会要求执行connectionSync这个操作:
客户端发送的json:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
{
"request": "connectionSync",
"connectionId": "cebe4551-9788-439e-8d1a-792064cd7a00",
"connProps": {
"connProps": "connPropsImpl",
"autoCommit": null,
"readOnly": null,
"transactionIsolation": null,
"catalog": null,
"schema": null,
"dirty": true
}
}
|
服务端返回的json:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
{
"response": "connectionSync",
"connProps": {
"connProps": "connPropsImpl",
"autoCommit": null,
"readOnly": null,
"transactionIsolation": null,
"catalog": null,
"schema": null,
"dirty": false
},
"rpcMetadata": {
"response": "rpcMetadata",
"serverAddress": "KJBJ-01-DN-004889:15888"
}
}
|
之后客户端会要求执行createStatement这个操作
客户端再次发送:
1
2
3
4
|
{
"request": "createStatement",
"connectionId": "cebe4551-9788-439e-8d1a-792064cd7a00"
}
|
服务端响应:
1
2
3
4
5
6
7
8
9
|
{
"response": "createStatement",
"connectionId": "cebe4551-9788-439e-8d1a-792064cd7a00",
"statementId": 0,
"rpcMetadata": {
"response": "rpcMetadata",
"serverAddress": "KJBJ-01-DN-004889:15888"
}
}
|
执行查询
执行的时序图如下:
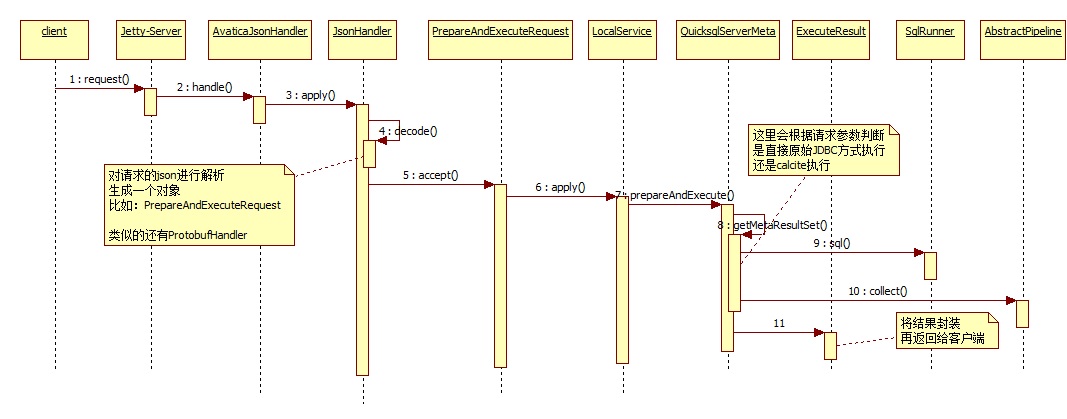
首先客户端发送请求给jetty,jetty接受到请求后,会调用到自定义的handler,也就是AvaticaJsonHandler。
AvaticaJsonHandler是真正执行具体逻辑的地方,这里主要干两件事:
- 根据请求对象解析出传递的内容,也就是解析json;根据json格式生成对应的对象
- 执行这个对象,并生成json结果,最后返回给客户端
这里解析完json后,得到的是PrepareAndExecuteRequest这么一个对象,之后会触发到QuicksqlServerMeta来执行prepareAndExecute函数。
这个函数就是用于执行具体sql的,它会根据客户端传递的参数,来决定执行方式:
- 如果客户端传递的直连查询,就用原始的JDBC方式查询,比如创建mysql驱动再查询mysql,或者创建oracle驱动再查询oracle
- 非直连查询,这里走的就是正常的calcite逻辑,也就是调用 SqlRunner解析sql并得到一个pipeline,再执行pipeline,最后将结果封装成ExecuteResutl并返回给客户端
客户端发送查询,要求执行prepareAndExecute操作
1
2
3
4
5
6
7
8
|
{
"request": "prepareAndExecute",
"connectionId": "0f276a88-335f-4f01-8916-36d11075e223",
"statementId": 1,
"sql": "select * from my_test",
"maxRowsInFirstFrame": -1,
"maxRowCount": -1
}
|
服务端返回结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
|
{
"response": "executeResults",
"missingStatement": false,
"rpcMetadata": {
"response": "rpcMetadata",
"serverAddress": "KJBJ-01-DN-004889:5888"
},
"results": [{
"response": "resultSet",
"connectionId": "0f276a88-335f-4f01-8916-36d11075e223",
"statementId": 1,
"ownStatement": true,
"signature": {
"columns": [{
"ordinal": 0,
"autoIncrement": true,
"caseSensitive": false,
"searchable": true,
"currency": false,
"nullable": 0,
"signed": true,
"displaySize": 11,
"label": "id",
"columnName": "id",
"schemaName": "",
"precision": 11,
"scale": 0,
"tableName": "my_test",
"catalogName": "linkis_test",
"type": {
"type": "scalar",
"id": 4,
"name": "INT",
"rep": "PRIMITIVE_INT"
},
"readOnly": false,
"writable": true,
"definitelyWritable": true,
"columnClassName": "java.lang.Integer"
}, {
"ordinal": 1,
"autoIncrement": false,
"caseSensitive": false,
"searchable": true,
"currency": false,
"nullable": 1,
"signed": false,
"displaySize": 200,
"label": "name",
"columnName": "name",
"schemaName": "",
"precision": 200,
"scale": 0,
"tableName": "my_test",
"catalogName": "linkis_test",
"type": {
"type": "scalar",
"id": 12,
"name": "VARCHAR",
"rep": "STRING"
},
"readOnly": false,
"writable": true,
"definitelyWritable": true,
"columnClassName": "java.lang.String"
}],
"sql": null,
"parameters": [],
"cursorFactory": {
"style": "LIST",
"clazz": null,
"fieldNames": null
},
"statementType": null
},
"firstFrame": {
"offset": 0,
"done": true,
"rows": [
[1, "aaaaa"],
[2, "bbbb"],
[3, "ccccc"],
[4, "dddd"],
[5, "eeee"],
[8, "xxxxxxxx!!!"],
[9, "kkkkkkk"],
[10, "wokao"],
[11, null],
[12, "xxxxx!!!"]
]
},
"updateCount": -1,
"rpcMetadata": {
"response": "rpcMetadata",
"serverAddress": "KJBJ-01-DN-004889:5888"
}
}]
}
|
调试记录
正确的结果
需要解析的json:
1
2
|
{"request":"prepareAndExecute","connectionId":"1c5b48cf-78b9-4373-a256-3a28ed11a6b5","statementId":0,
"sql":"select * from my_test","maxRowsInFirstFrame":-1,"maxRowCount":-1}
|
class类型:
1
|
class org.apache.calcite.avatica.remote.Service$Request
|
com.fasterxml.jackson.databind.ObjectMapper 版本:
result = {ProtectionDomain@3518} "ProtectionDomain (file:/E:/maven_repository/com/fasterxml/jackson/core/jackson-databind/2.6.5/
jackson-databind-2.6.5.jar <no signer certificates>)
jdk.internal.loader.ClassLoaders$AppClassLoader@2f0e140b\n <no principals>
java.security.Permissions@2cc846be (\n ("java.lang.RuntimePermission" "exitVM")
("java.io.FilePermission" "E:\maven_repository\com\fasterxml\jackson\core\jackson-databind\2.6.5\jackson-databi
nd-2.6.5.jar" "read"))"
codesource = {CodeSource@3527} "(file:/E:/maven_repository/com/fasterxml
/jackson/core/jackson-databind/2.6.5/
jackson-databind-2.6.5.jar <no signer certificates>)"
错误的结果
需要解析的json:
1
2
3
|
{"request":"prepareAndExecute","connectionId":"aaca743e-5dda-48e8-ae38-e419afd592ae",
"statementId":0,"sql":"select * from
my_test","maxRowsInFirstFrame":-1,"maxRowCount":-1}
|
class类型:
1
|
class org.apache.calcite.avatica.remote.Service$Request
|
com.fasterxml.jackson.databind.ObjectMapper 版本:
1
2
3
4
5
6
7
8
|
result = {ProtectionDomain@3478} "ProtectionDomain (file:/E:/maven_repository/com/fasterxml/jackson/core/
jackson-databind/2.6.5/jackson-databind-2.6.5.jar <no signer certificates>)
jdk.internal.loader.ClassLoaders$AppClassLoader@2f0e140b\n <no principals>
java.security.Permissions@e84bed7 (\n ("java.lang.RuntimePermission" "exitVM")
("java.io.FilePermission" "E:\maven_repository\com\fasterxml\jackson\core\jackson-databind\2.6.5
\jackson-databind-2.6.5.jar" "read")\n)"
codesource = {CodeSource@3488} "(file:/E:/maven_repository/com/fasterxml/jackson/core/jackson-databind/
2.6.5/jackson-databind-2.6.5.jar <no signer certificates>)"
|
PrepareAandExecuteRequest
{"request":"prepareAndExecute","connectionId":"56fca4c8-495a-4024-9c6e-5c5d54e36ddc","statementId":0,"sql":"select * from my_test","maxRowsInFirstFrame":-1,"maxRowCount":-1}
真正出错的地方:
1
2
3
4
5
6
7
8
9
10
11
|
public HandlerResponse<T> apply(T serializedRequest) {
try {
Request request = this.decode(serializedRequest);
Response response = request.accept(this.service); //这里出错的
return new HandlerResponse(this.encode(response), 200);
} catch (Exception var4) {
return this.convertToErrorResponse(var4);
}
}
原因:
java.lang.NoClassDefFoundError: Could not initialize class com.my-project.utils.JdbcSourceInfo
|
Calcite自身对Spark的整合分析
引入Spark
Calcite自身就可以支持Spark,只需要引入相关的类就可以。
依赖的类以 org.apache.calcite.adapter.spark 开头。
不过这些类并不在 Calcite 1.26 的库中,需要单独引入进来。
下载Calcite的源码,就可以拿到这些类了,然后将这些类以源码的方式引入工程中。
再引入相关依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.jetbrains</groupId>
<artifactId>annotations</artifactId>
<version>RELEASE</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>commons-compiler</artifactId>
<version>3.0.11</version>
</dependency>
<dependency>
<groupId>org.checkerframework</groupId>
<artifactId>checker-qual</artifactId>
<version>2.0.0</version>
</dependency>
|
测试执行
这个很简单,增加一句话就可以了,如下面代码,增加第二行即可。
1
2
3
4
|
Properties properties = new Properties();
properties.setProperty("spark", "true");
Connection connection = CalciteUtil.getConnect("/cross_join.json", properties);
Statement statement = connection.createStatement();
|
原理分析
从Test类开始,经过一路调用:
Test
|
AvaticaStatement#executeQuery
|
AvaticaConnection#prepareAndExecuteInternal
|
CalciteMetaImpl#prepareAndExecute
|
CalcitePrepareImpl#parseQuery
|
create spark handler
最后由ContextImpl这个类完成创建SparkHanlder,它继承自CalcitePrepare.Context:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
public CalcitePrepare.SparkHandler spark() {
final boolean enable = config().spark();
return CalcitePrepare.Dummy.getSparkHandler(enable);
}
public static synchronized SparkHandler getSparkHandler(boolean enable) {
if (sparkHandler == null) {
sparkHandler = enable ? createHandler() : new TrivialSparkHandler();
}
return sparkHandler;
}
private static SparkHandler createHandler() {
try {
final Class<?> clazz =
Class.forName("org.apache.calcite.adapter.spark.SparkHandlerImpl");
Method method = clazz.getMethod("instance");
return (CalcitePrepare.SparkHandler) method.invoke(null);
} catch (ClassNotFoundException e) {
return new TrivialSparkHandler();
} catch (IllegalAccessException | ClassCastException | InvocationTargetException | NoSuchMethodException e) {
throw new RuntimeException(e);
}
}
|
创建SparkHandler时,还有会启动一个内嵌的Jetty服务器,之后程序继续执行,并交给Prepare这个类。
CalcitePrepareImpl -> Prepare
Prepare这类看起来是Avtical和Calcite内部的桥梁。
Prepare又会委托CalciteConnectionImpl获取DataContext的实现类。
而到这里,就出问题了:
1
2
3
4
5
6
7
|
public DataContext createDataContext(Map<String, Object> parameterValues,
CalciteSchema rootSchema) {
if (config().spark()) {
return new SlimDataContext();
}
return new DataContextImpl(this, parameterValues, rootSchema);
}
|
这里返回的SlimDataContext 内部实现全部都是空:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
private static class SlimDataContext implements DataContext, Serializable {
public SchemaPlus getRootSchema() {
return null;
}
public JavaTypeFactory getTypeFactory() {
return null;
}
public QueryProvider getQueryProvider() {
return null;
}
public Object get(String name) {
return null;
}
}
|
再往后,就是 Calcite调用逻辑表达式,转换成物理表达式,利用linq4j将物理表达式转换成对应的代码片段。
生成的代码,再编码代码片段并执行。
代码片段很长,这里截取其中一小段,注意root.getRootSchema():
1
2
3
|
final org.apache.calcite.linq4j.Enumerable _inputEnumerable =
org.apache.calcite.schema.Schemas.enumerable((org.apache.calcite.schema.ScannableTable)
root.getRootSchema().getSubSchema("TEST_CSV").getTable("CSV_TEST03"), root);
|
代码片段被编译为Bindable接口的实现类,由于是动态编译的,所以无法看到具体实现代码,不过可以通过编译后的class文件反编译。
在CalcitePrepare中,调用动态生成的代码:
1
2
3
4
5
6
7
8
9
|
public Enumerable<T> enumerable(DataContext dataContext) {
Enumerable<T> enumerable = bindable.bind(dataContext);
if (maxRowCount >= 0) {
// Apply limit. In JDBC 0 means "no limit". But for us, -1 means
// "no limit", and 0 is a valid limit.
enumerable = EnumerableDefaults.take(enumerable, maxRowCount);
}
return enumerable;
}
|
最终会调用到SlimDataContext,进而返回null,导致程序执行出错:

一个可以测试的demo例子
这个例子可以执行,但没有没法做数据源拆分,单数据源可以这么用,但跨数据源就不行了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
Properties properties = new Properties();
properties.setProperty("spark", "true");
CalciteConnection calciteConnection = null;
Class.forName("org.apache.calcite.jdbc.Driver");
Connection aConnection = DriverManager.getConnection("jdbc:calcite:", properties);
DatabaseMetaData metaData = aConnection.getMetaData();
System.out.println("productName="+metaData.getDatabaseProductName());
calciteConnection = aConnection.unwrap(CalciteConnection.class);
// 必须是CalciteConnection继承关系一条链中的才可相互强制转换,如果是自定义的类,就不是那条链上的,会报错
// calciteConnection = aConnection.unwrap(MyCalciteConnection.class); 这么写会报错的
CalcitePrepare.Context context = calciteConnection.createPrepareContext();
CalcitePrepare.SparkHandler sparkHandler = context.spark();
JavaSparkContext sparkcontext = (JavaSparkContext) sparkHandler.sparkContext();
JavaRDD<String> input = sparkcontext.parallelize(Arrays.asList("abc,1", "test,2"));
JavaRDD<Person> persons = input.map(s -> s.split(",")).map(s -> new Person(s[0], Integer.parseInt(s[1])));
System.out.println(persons.collect());
SparkSession spark = SparkSession.builder().appName("Test").getOrCreate();
Dataset<Row> df = spark.createDataFrame(persons, Person.class);
df.show();
df.printSchema();
SQLContext sqls = new SQLContext(spark);
sqls.registerDataFrameAsTable(df, "person");
sqls.sql("SELECT * FROM person WHERE age>1").show();
sparkcontext.close();
}
public static class Person implements Serializable {
private static final long serialVersionUID = -6259413972682177507L;
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return name + ": " + age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
|
总结
Calcite虽然内部有对Spark的支持,但实现的不完善。
Calcite从connection逻辑到内部的数据源拆分,整个逻辑绑定的比较紧- 生成的代码会用到
SlimDataContext,而这个类完全不可用
- 从调用链看,想用
Spark但不好扩展
- 只支持
Spark,不支持其他引擎
ElasticSearch解析问题分析
问题描述
通过 Calcite 查询 ES,只能做 SELECT 查询,加一个 WHERE条件都会报错。
注册到 Calcite 的model.json如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
inline:{
"version": "1.0",
"defaultSchema": "TEST_CSV",
"schemas": [
{
"type": "custom",
"name": "esTest",
"factory": "io.myproject.schema.elasticsearch.ElasticsearchSchemaFactory",
"operand": {
"coordinates": "{'localhost': 9025}",
"userConfig": "{'bulk.flush.max.actions': 10, 'bulk.flush.max.size.mb': 1,'esUser':'username','esPass':'password'}",
"index": "student"
}
}
]
}
|
服务端是本地启动的 ES,查询的SQL如下:
1
|
SELECT * FROM esTest.student
|
如果改成下面这样就报错了:
1
2
|
SELECT * FROM esTest.student WHERE city in ('FRAMINGHAM', 'BROCKTON', 'CONCORD')
SELECT * FROM esTest.student AS t WHERE t.city = 'FRAMINGHAM'
|
报错原因是在校验的时候,找不到city这个字段。
解析问题
首先看下 ES包下的整体结构,类图如下:
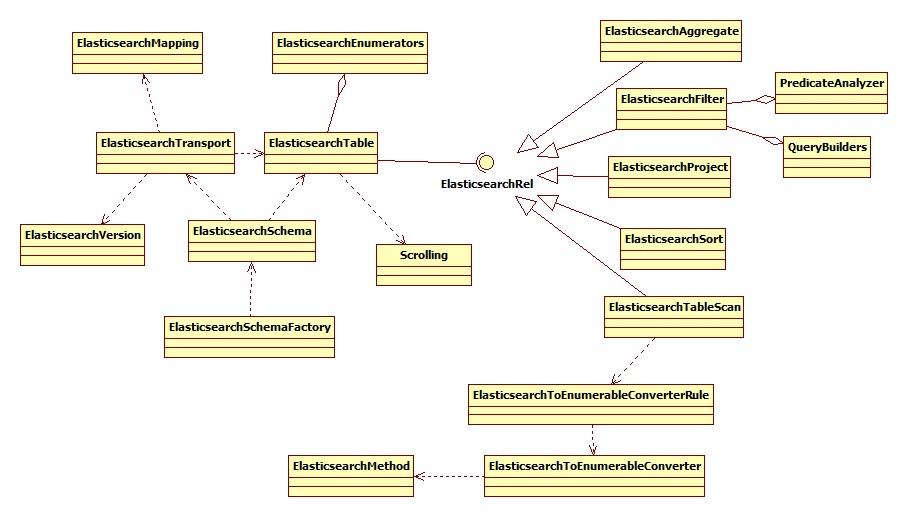
Calcite 在校验的时,会根据注册的RelDataType做校验,RelDataType是在查询元数据信息时生成的。
比如,查询MySql时,会返回当前库下所有的表信息,然后拿到这个表的所有字段信息,并生成RelDataType对象,注册到Calcite中。
具体是在ElasticsearchTable#getRowType中实现的,正确的 RelDataType 大致是这样的:
RecordType(VARCHAR stu_id, VARCHAR province, VARCHAR city, BIGINT digest, VARCHAR type) NOT NULL
未修改前,错误的RelDataType是这样的:
RecordType((VARCHAR NOT NULL, ANY) MAP NOT NULL _MAP) NOT NULL
代码中,这段生成的逻辑是固定的,根本不管表中的类型是啥,字段名叫啥,每次都返回这么一个固定的RelDataType。
后面SqlValidatorImpl在做校验的时候,会判断 SELECT 中的每个字段,以及 WHERE 中的字段信息,这会触发到DelegatingScope#fullyQualify这个函数。
这个函数很长,出错的原因是,拿一个具体的字段比如city去RelDataType中查询,这当然找不到了,于是报错。
解决办法:
在创建ElasticsearchSchema时,会生成一个HTTP请求,去 ES 那边拿到索引下的所有字段和类型,也就是说字段名、类型这些都是可以拿到的,他们就保存在ElasticsearchTransport中。
在ElasticsearchTable#getRowType中,根据已经拿到的具体字段名、字段类型再创建对应的 RelDataType就可以了。
具体修改内容参考:ElasticsearchTable#getRowType
生成JSON问题
经过上面一通修改后,校验就可以通过了。但后面还是会报错,比如这个 SQL:
1
|
SELECT * FROM esTest.student AS t WHERE t.city = 'FRAMINGHAM'
|
在生成物理表达式时,会将 一个 SQL 节点,转换为对应的 JSON,具体是在PredicateAnalyzer中完成的。
而执行到
1
|
public Expression visitCall(RexCall call) {
|
这句时,上述的 SQL 的节点类型是:INTERNAL,由不认这个类型,所以报错了。
这个简单,直接在 switch 中把这个类型加上即可。
在执行,会发现虽然执行是成功了,但是没结果。这是因为在ElasticsearchFilter中,生成的 JSON 内容不对。
具体是在ElasticsearchFilter#implement中出问题的,而这个函数 是通过访问者模式,一层一层的被调用下来的。
在ElasticsearchFilter#translateMatch中,返回的 JSON如下:
1
2
3
4
5
6
7
8
9
10
11
|
{
"query": {
"constant_score": {
"filter": {
"term": {
"$0": "FRAMINGHAM"
}
}
}
}
}
|
term中有一个$0,这个生成的不对,如果改成city,这个 FILTER 条件就对了,最后就能查询出结果了。
ES 查询语句:
查询索引
POST /[索引名]/_search?scroll=1m HTTP/1.1
1
2
3
4
5
6
7
8
9
10
11
12
|
{
"query": {
"constant_score": {
"filter": {
"term": {
"city": "FRAMINGHAM"
}
}
}
},
"size": 5196
}
|
一个 MySql -> ES 的在线转换工具:
http://www.ischoolbar.com/EsParser/
目前 ES 的问题
ES 不支持 JOIN、不支持子查询,CASE-WHEN等,只能做单表(索引)查询
支持的函数有限,包括:
经过测试和修改,已支持的功能:
1、四个比较 >=、>、<=、<
2、SELECT *、SELECT 某些字段
3、ORDER BY、ORDER BY DESC
4、GROUP BY
5、LIKE
6、BETWEEN
7、IN
8、NOT AND OR
目前发现的问题:
1、HAVING
这个功能还没实现
2、range
BETWEEN、IN 都会被优化为 Sarg类型,这是一个范围集合,类似List、List这样。
整数类型 和 字符串类型 所处理的方式不同
具体修改参见: PredicateAnalyzer$SimpleQueryExpression#range
测试中发现的bug记录
非BUG
- 表中是数据值不合法
- 无符号的整数超过范围了
- 查询语句缺少库名
通用问题
- SqlNode解析错误
- SqlNode没解析出库
- 返回的数据类型不支持
- 客户端查询出发了assert错误
- 服务端返回的逻辑有问题,不支持批量查询
MySql 问题
- SqlNode转换成具体的方言有问题
- 方言转换时,缺少转义符号
- 非内置函数,转换成方言有问题
Oracle 问题
- BETWEEN带中文报错
- 返回的数据类型不支持
- 双引号问题
- WITH 语法不支持
- 关键字冲突
- 二进制类型不支持
- 一些保留字支持
跨数据源问题RelNode做校验时报错
精简client驱动依赖
依赖包
目前 client 驱动依赖包太多,主要依赖如下:
- my-project自身的 core、common依赖
- avatica-metrics 1.17.0
- avatica-core 1.17.0
- httpclient 4.5.9
- httpcore 4.4.11
- commons-codec 1.11
- commons.logging 1.2
- jackson-annotations 2.6.5
- jackson-core 2.10.0
- jackson-databind 2.6.5
- protobuf 3.6.1
- slf4j-api 1.7.25
httpclient 4.5.9
httpcore 4.4.11
这两个jar引用了commons-logging,我在导入源码的时候,将commons-logging改为了slf4j
发现的问题
protobuf
需要下载 3.6.1 的linux-64.zip 包,然后在 linux环境下 用protoc命令编译三个 .proc 文件
再将编译后的 .java 文件拷贝回工程中
slf4j
slf4j只是一个日志门面类,需要具体的日志实现,如 log4j,logback等
slf4j在源码中有三个实现类 StaticLoggerBinder 、 StaticMarkerBinder、 StaticMDCBinder。
以第一个为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
public class StaticLoggerBinder {
/**
* The unique instance of this class.
*/
private static final StaticLoggerBinder SINGLETON = new StaticLoggerBinder();
/**
* Return the singleton of this class.
*
* @return the StaticLoggerBinder singleton
*/
public static final StaticLoggerBinder getSingleton() {
return SINGLETON;
}
/**
* Declare the version of the SLF4J API this implementation is compiled against.
* The value of this field is modified with each major release.
*/
// to avoid constant folding by the compiler, this field must *not* be final
public static String REQUESTED_API_VERSION = "1.6.99"; // !final
private StaticLoggerBinder() {
throw new UnsupportedOperationException("This code should have never made it into slf4j-api.jar");
}
public ILoggerFactory getLoggerFactory() {
throw new UnsupportedOperationException("This code should never make it into slf4j-api.jar");
}
public String getLoggerFactoryClassStr() {
throw new UnsupportedOperationException("This code should never make it into slf4j-api.jar");
}
}
|
直接就抛出异常了,这里的集成方式很奇怪。
门面类在打包的时候,将这三个 impl 类不打入jar包中(但是源码提供了)
然后某个具体日志实现类,比如 nop、或者 log4j 提供一个 同名的 StaticLoggerBinder 类,完成扩展。