统一查询项目介绍
背景介绍
背景说明
项目相关组件现状:
- 多个引擎需要投入多倍的人力,在人员有限的情况下,对引擎的掌控力会减弱
- 语法兼容问题(Hive/Impala/Spark)
- 语义支持问题(Hive/Impala/Oracle)
- 扩展时重复工作量多
- 每一个新引擎的学习成本(Hive/Impala/GreenPlum/Presto/…)
- 每个新功能的维护成本(…)
不能赋能中台:
- 不利于专家知识库的建设(重复问题)
- 多项目会造成成本飙升(…)
项目目标
整体目标
公司内部统一的SQL分析中间件,作为一个简单,安全,快速的跨数据源统一SQL 查询引擎
- 减少在使用不同数据引擎时需要的学习成本和切换成本;
- 忽略不同数据引擎底层存储和数据查询方式的差异
- 使用户仅需要关注查询的业务逻辑和数据本身。
应用场景
数据分析
- 数据分析/挖掘
- 生成报表
- ETL
即时查询
- 数据采样
- 小数据交互查询
支持多数据源查询
- MySQL join ElasticSearch union Hive
运维监控
研发策略
自研不等于自主可控,以“集成式创新”为出发点,拥抱开源和构建开源生态。
- 拥抱开源
- 积极参与社区贡献,加深和社区的合作,和社区融为一体 - 插件化
- 将特异性的需求独立出来,形成插件,降低与主干的耦合性,轻量化的迭代
生态化
- 通用易用的数据访问方式
- 高性能的数据查询能力
- 完备的企业级特性支持
- 丰富的生态支持与构建
产品起步
产品调研
目前市面上已有的产品:
- presto
- quick-sql
- linkis
- XQL/IQL
已有的开源产品的问题
presto:
- 优点
- 性能优越
- 跨源查询
- SQL支持
- 缺点:
- 容错性差,当某个worker的查询失败后,整个query失效,没有重试机制
- 容易OOM,运行过程中对于内存极为敏感,连表查,可能产生大量的临时数据,因此速度会变慢
- 不支持实时
- 学习成本高
linkis
- 缺点:
- 仅作转发
- 学习成本较高
XQL/IQL
- 缺点:
- 不开源
quick-sql:
- 优点:
- 支持实时
- 多引擎支持
- 基本满足当前需求
- 缺点:
- 修改了SQL解析开源实现Calcite,无法跟社区同步
选择自研
调研最终选择的QuickSql,其自身有很多的问题:
- 它将Calcite以源码形式导入到了工程中并做了十几处改动
- 由于导入的Calcite版本较低,很多新功能都无法使用
- QuickSQL去掉导入的Calcite部分,本身只有1万多行
- 我们列出的很多扩展性的功能,QuickSQL也不支持
基于上述原因,我们选择自研,而不是基于QuickSQL做二次开发。
在 第一阶段、第二阶段,整体架构逻辑都参考自QuickSql。
自研时,我们对Calcite不做源码修改,只依赖。
Calcite选择最新的1.26版本
除SQL解析赖于 Calcite,其他并无特别依赖。
其他依赖:
- calcite和avatica
- 日志、commons组件、guava
- jetty
- spark(可选),flink(可选)
产品优势
- 支持跨数据源查询(mysql、oracle、hive、es等),消除数据孤岛,针对数据价值挖掘有着更强大的功能
- 多引擎支持(目前计划支持spark、flink,目前需手动指定)
- 所有查询采用统一的sql语法(减少开发人员使用不同的组件的学习成本和开发成本)
- 易扩展(扩展更多的数据源,目前理论支持所有可JDBC连接的数据源)
- 拥抱开源,核心calcite紧跟开源社区(社区活跃且强大)
架构概述
整体架构
my-project整体分为四层:
- 客户端
- 接入层
- 解析层
- 引擎层
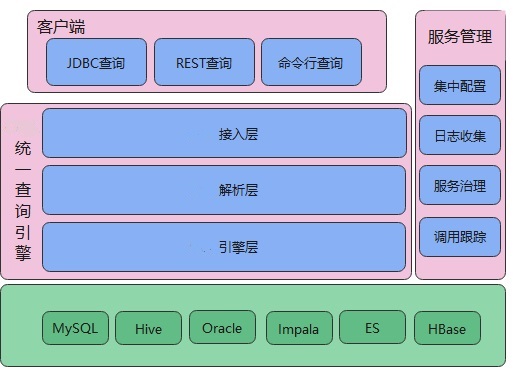
如上图,my-project的核心包括了接入层、解析层、引擎层
接入层提供一个TCP服务,供客户端调用
解析层是最重要的一层,在这一层里会将接入层获取到的查询信息进行分析,之后交给引擎层
引擎层根据解析层的指示,选择spark、flink或者JDBC直连的方式进行查询
引擎层最终调用的就是一个个具体的存储服务
下面是更细节的架构图
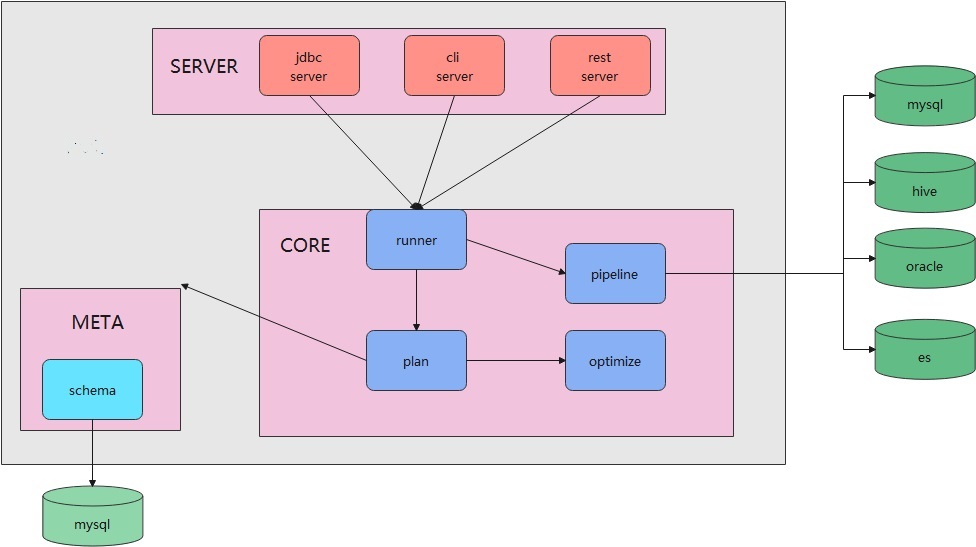
my-project需要将元数据信息注入到服务中,这里的元数据指的是客户端查询的库、表等信息。比如:
|
|
在这个SQL中,客户需要查询my_db这个库,但他并没有将my_db库的配置信息(url、用户名、密码等)告诉my-project,所以要完成上述的SQL查询,需要先将my_db库的配置信息注入到my-project中。
而meta模块就是用来完成元数据注入的,它下面指向的mysql是内部库,仅供my-project使用。
Core模块中,由runner子模块接收服务端解析的请求内容,也就是一个具体的SQL语句,以及相关的配置信息(可选)。
在Core模块中,会将接收到的SQL做法语解析,生成语法树,并根据语法树决定是单数据源查询、还是多数据源查询,而具体的查询动作是交给pipeline子模块完成的,由这个子模块去调用 spark 或者 JDBC完成具体的查询操作。
Core模块中还有一个Optimze子模块,负责对语法树进行优化,将一个查询效率比较差的SQL语句,优化成一个查询效果更高的SQL语句,Optimze这个子模块是可选的。
上图中的my-project是一个JVM进程,my-project本身是无状态的,可以方便的扩容/缩量。
接入层架构
JDBC方式的服务端架构如下:
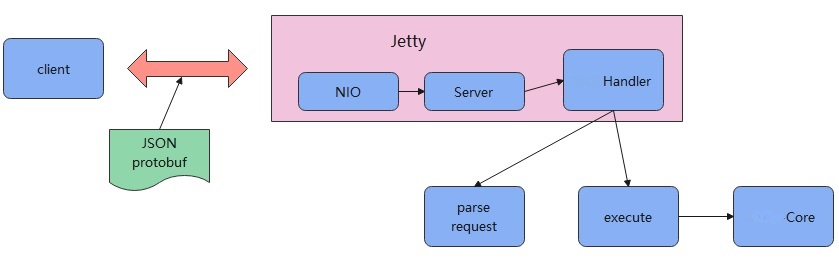
客户端需要先引入my-project驱动。 只需要对传统JDBC方式方式稍作配置即可,传统JDBC查询代码如下:
|
|
使用my-project驱动后,将url和driver替换掉即可使用:
|
|
my-project驱动底层是HTTP方式的通讯,服务端是内嵌的Jetty。
客户端发送的JDBC请求实际是一个HTTP请求,而JDBC的请求内容被封装到HTTP的body中。
HTTP body有两种编码方式:
- JSON
- protobuf
服务端解析到请求后,会交给自定义的my-projectHandler来处理。
my-projectHandler首先会解析请求,根据指定的 JSON 方式或者 protobuf 得到具体的内容,也就是一个具体的SQL。
之后就是执行这个SQL,通过调用my-project-Core模块完成具体的查询操作。
解析层
解析层的执行流程如下:
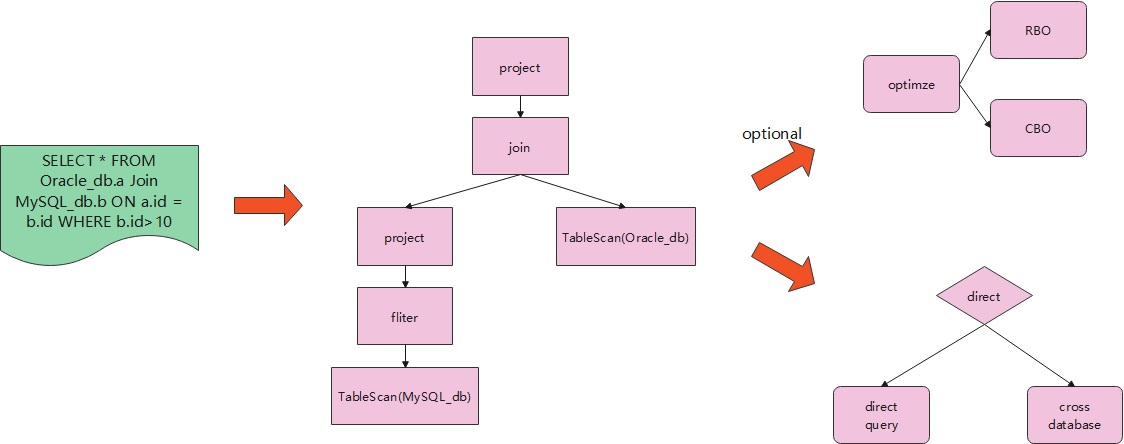
对于一个跨数据源的SQL:
|
|
解析层首先将这个SQL解析,得到一个语法树。
再遍历这棵树,就能确定需要查询的数据源,通过数据源的数量,也就确定了是否为跨数据源查询。
在具体执行之前,有一步可选的优化:
- RBO:基于规则的优化,包括谓词下推、列裁剪、常量折叠等
- CBO:基于代价的优化
如果是单数据源查询,对应的就是一个普通的JDBC查询。
如果是跨数据源查询,则交给 Spark 或者 Flink 去执行。
引擎层
可插拔的引擎层架构如下:
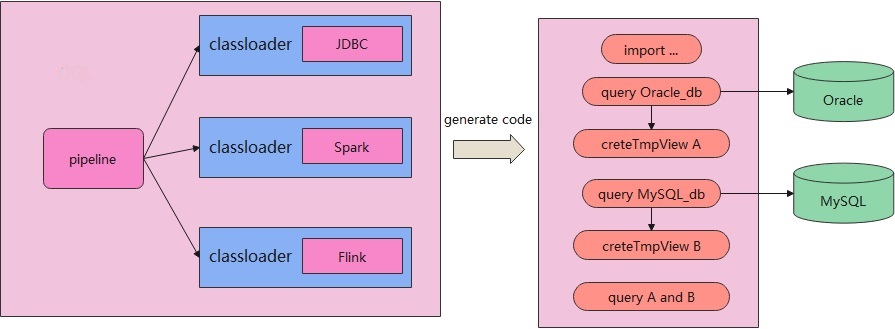
根据前面解析得到语法树,交给pipeline去调用一个具体的引擎来执行。
这里的引擎可以是JDBC、可以是Flink、也可以是Spark。
每种类型的引擎都是以独立的ClassLoader方式引入的,这样可以保证引擎执行不会出现jar冲突。
对于上述的架构,可以引入Spark 2.x作为引擎层;也可以同时引入Spark 3.x作为引擎层;或者可以引入其他任意类型的执行引擎。
my-project并不依赖于某一种具体的引擎,只是把具体的引擎当作黑盒使用。
对于跨数据源查询时(比如选用Spark),会动态的生成一些代码,然后将这些代码提交到 Spark的集群执行:
- 生成import 语句
- 生成查询 Oracle 的代码,并将结果写入到 tempView A 中
- 生成查询 MySQL 的代码,并将结果写入到 tempView B 中
- 最后执行对 A 和 B 执行一个联合查询