HANA调研
调研
架构
High-Performance Analytic Appliance ,简称HANA
只能运行于 SUSE Linux
各组件结构:
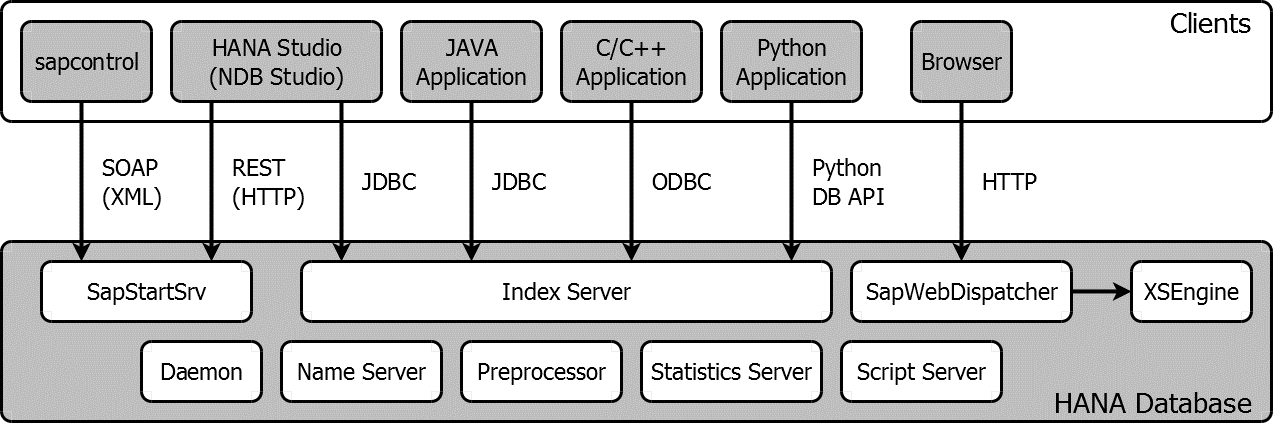
1、SapStartSrv,提供 web-service
2、name-server,存储集群的拓扑,可以有多个name-server,每个机器都有全局拓扑
3、Statistics-server,用于收集历史信息,信息会存入HANA自身的表中,支持邮件报警
4、web-dispathcer,提供REST-AP服务
5、daemon,停止和启动其他服务
6、XSEngine,可以在DB端运行javascript应用
多节点数据复制,使用了 Sybase Replication Server(被HANA收购),包括:
- 两阶段提交
- 异步事务
存储模式:
- TRex,SAP内部的列存引擎
- P*TIME,SAP内部的行存引擎,收购自一家韩国公司
index-server
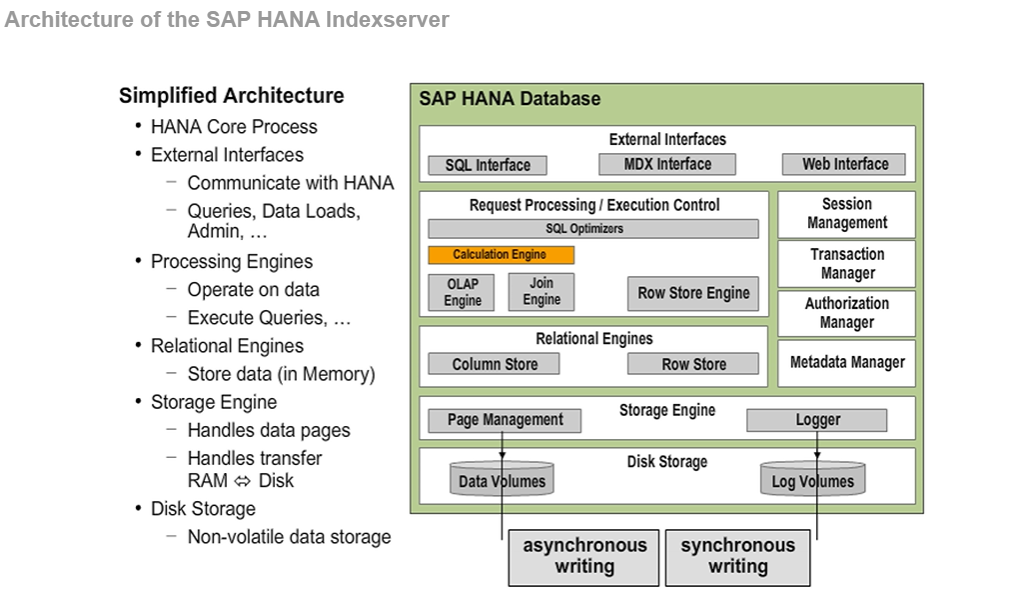
另一个视角的 index-server:
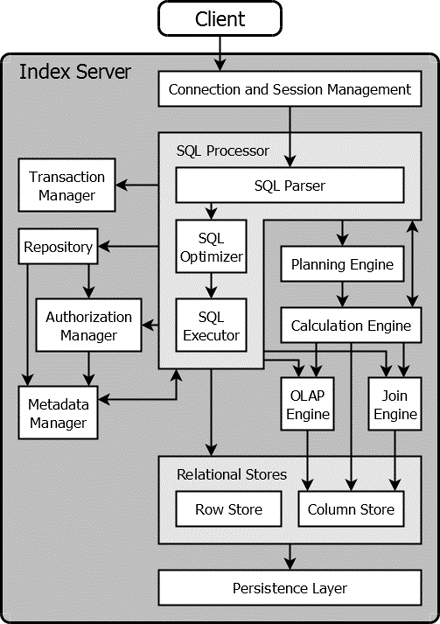
- Repository,提供HTTP通讯的
- Metadata Manager,在所有节点共享,主/从模式,主节点服务,从节点只是复制数据
- SQL Processor,调用元数据检查sql,事务交给事务管理器,planning交给planning engine
高可用
基于分布式文件系统的
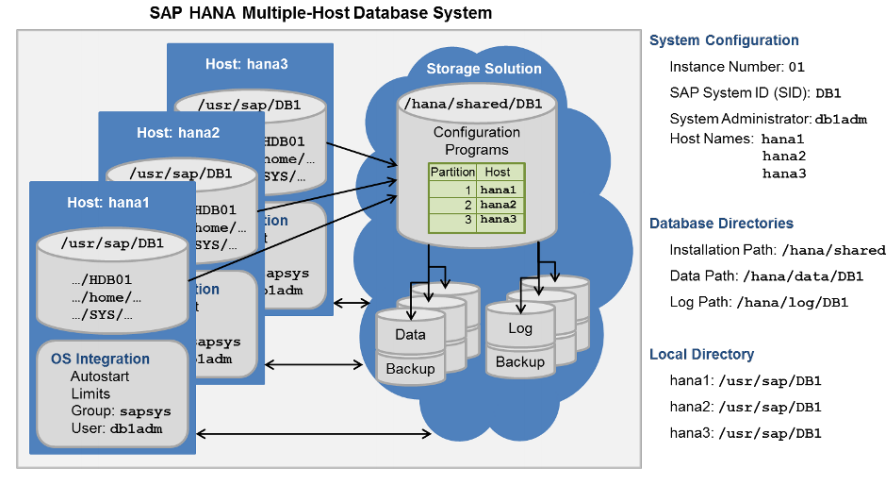
多个数据库共享同一个存储
底层是基于IBM的 GPFS
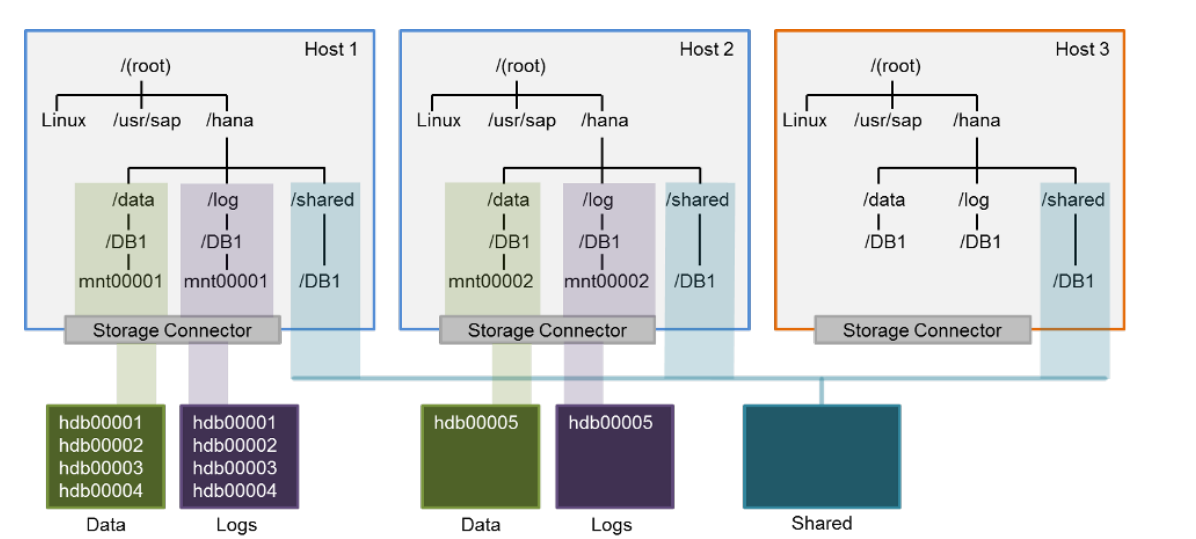
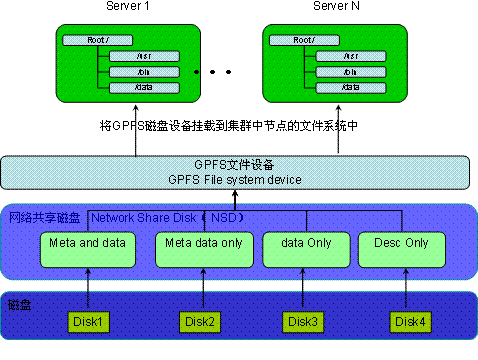
GPFS是三层结构
磁盘、网络共享磁盘、GPFS文件设备
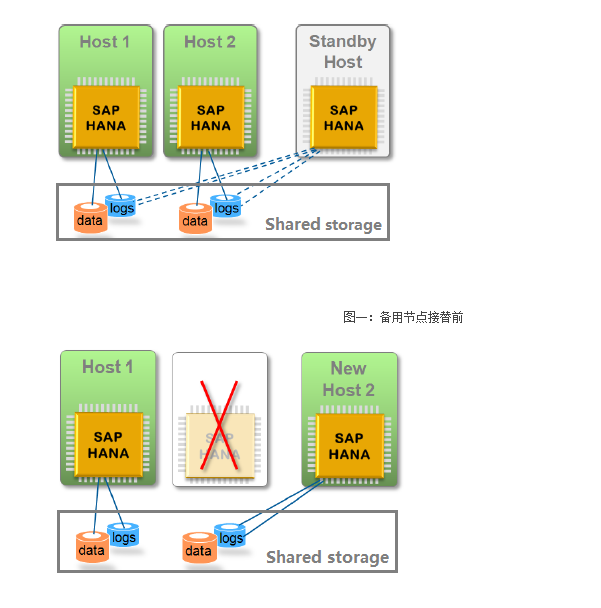
另一种是基于经典的主从结构
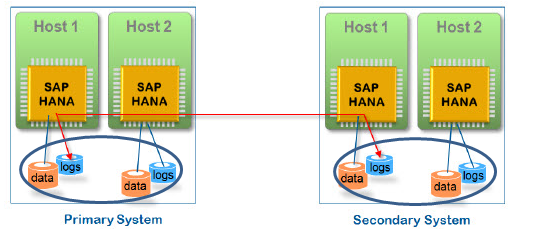
当name-server检查到主宕机后,自动完成切换
对于复制,HANA提供了三种方式:
- 基础触发器的方式,可以实现 HANA -> 非HANA系统同步
- 基于ETL工具
- 基于日志复制,这个是基于 Sybase Replication 实现的,参考 -> 这里
主要特点
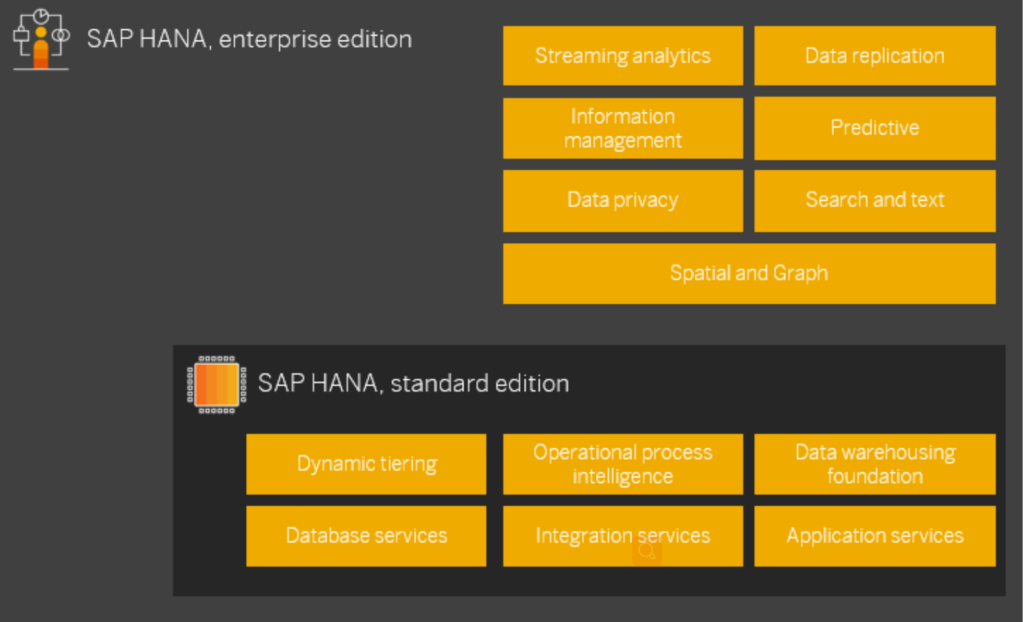
SAP HANA平台
利用内存计算技术,完美融合数据库与应用平台功能,进而变革事务处理、分析处理、文本分析、图形、预测和空间处理模式,从而帮助企业实现实时运营,其突破性的数据和应用处理技术将整个软件架构带入实时计算模式,帮助IT简化运营
普通版功能
Database Services
1、CURD基于内存的数据库,有行存和列存
2、有容灾、监控、诊断、建模、安全等功能
3、并非纯内存,也有持久化存储
4、有租户功能
5、底层支持多核并行计算
6、支持分片
7、全量、增量备份
8、有自动诊断工具、故障排查和分析工具,有系统收集报警功能、也能检测整个集群状态
9、数据建模
10、支持SSO、审计日志、列数据加密
11、支持结构和半结构化数据
Integration Services
1、可以上传和复制各种类型数据,如:csv、xls等
2、可以创建外表表,数据不用导入到HANA,包括在其他数据库和HDFS上建外部表
3、支持JDBC、ODBC、语言包括java、python、go、js、ruby
4、支持分布式事务
Application Services
1、提供应用开发平台,开发js、java、python应用部署到类似javaEE服务器上
2、可以写各种SQL、存储过程
3、可以发布、管理这些应用
Dynamic Tiering
动态分级存储,可以自动的将热数据放入内存
将冷数据,访问频率较低的数据放入外部存储
Operational Process Intelligence
1、可以开发自动化决策的解决方案应用
2、主要用于BI场景
Data Warehousing Foundation
1、数据智能分布
企业版功能
在普通版基础上,又增加了一些功能
Spatial and Graph
- 支持地理位置数据
- 包括 距离、表面、面积、周长、体积等
- 内置了相关函数
Data Privacy
- 基于列的加密
- 对HANA业务数据的认证访问
- 对表和视图的访问控制
Search and Text
- 可以对文本进行搜索处理,分析各种文本数据
- 支持全文搜索,包括文本和仅仅只,包括精确和模式匹配
- 识别相似文档、文件中的关键词,用于对数据做训练
Information Management
- 可以连接各种数据库,文件、云端
- 通过提供的接口,可以访问各种外部数据库、文件、云端
- 做数据整合ETL,数据转换,支持各种数据库
- 数据复制时的监控功能
- 提供REST-API
Smart Data Quality
- 数据清理:可以识别各种地址、任命、组织名称、职业头衔、电话,邮件等数据
- 可以识别重复的数据
Predictive
- 包括经典的预测和基于机器学习场景的分析
- 分类、回归、聚类分析、时间序列分析、关联分析、社会网络分析等
Streaming Analytics
- 通过内存流处理引擎 处理 实时的数据流和相应的历史数据
- 包括识别模式、计算聚合、检查问题、生成报警
- 确保流项目从输入到输出中不丢失数据
- 有高可用机制
- 可以跟机器学习算法结合
- 可以捕获HANA、其他数据库的派生数据
- 可以将流分析程序部署到远端
- 自定义适配器
- 支持REST-API
- 可以监控、管理正在运行的流适配器
Data Replication
- 支持将源数据复制到HANA
- 支持触发器、增量的方式复制
安装
安装包下载:地址
安装包有这些组件:
- 服务端 1.8G
- 应用 5G,不清楚具体是什么
- 文本分析
- 流处理分析和相关套件
- 机器学习组件
- 交互式组件
- 客户端,有linux、windows、mac环境
- 数据集成
|
|
用虚拟机安装时,默认的密码为:
hxeadm/HXEHana1
附件
compat-sap-c++-9-9.1.1-2.3.el7.x86_64.rpm
测试
准备环境
二进制版本很难安装,用的是虚拟机环境:
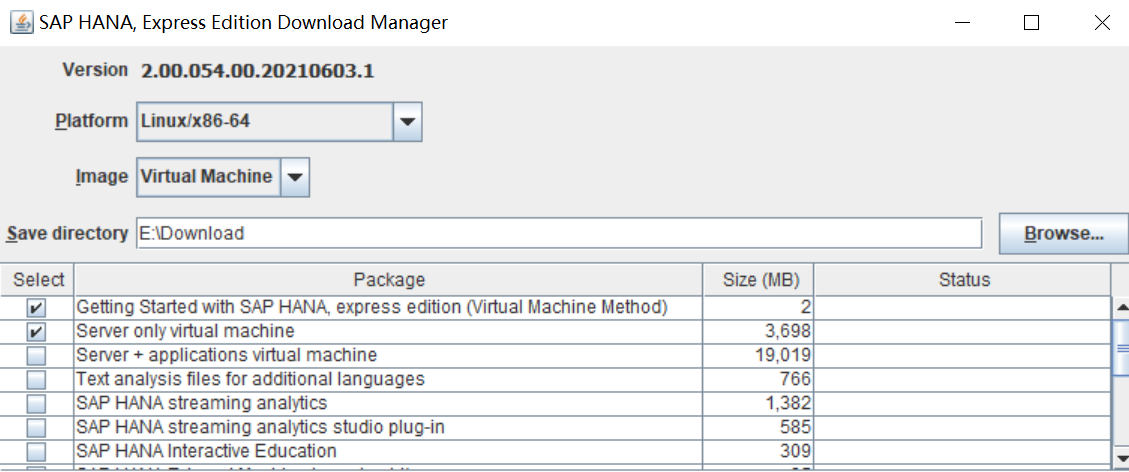
这是一个下载工具,实际安装的话,必须在 linux 环境上安装
二进制安装碰到的几个问题:
1、指令集不支持,公司内部系统上申请的虚拟机,不支持sse4.2指令集,装不上
2、缺少compat-sap-c++-9-9.1.1-2.3.el7.x86_64 rpm包,这个要去 红帽网站上下载
3、最后一个错误很难解决,错误日志中,只提示 数据库安装错误,但是具体没说什么错误
网上有说是缺少一个 so 文件,不过加上也不行
目前搭建的环境:
1、虚拟机上装了suse系统,上面跑了hana
2、装了一个centos环境,上面跑了 mysql和PG
3、将数据灌入pg、mysql、hana
4、mysql可以直接将tpc-ds的dat文件导入
5、PG是通过 datax导入的,读mysql,写入PG
6、hana没有对应的 datax写插件,基于sql-server的写插件,重新开发了一个,具体步骤 按照 ##参考 里面的内容来即可
7、hana的 datax插件扩展比较简单,但要注意增加相关的数据库类型,默认是没有hana这个类型的
连接
使用 hdbsql命令连接
|
|
查询命令
|
|
SQL 兼容性测试
TPC-DS 99个SQL,是否可以执行
| 查询编号 | mysqlv5.7 | PGv10 | PGv12 | hana | Sql-Server | Orale |
|---|---|---|---|---|---|---|
| query1 | - | yes | yes | yes | yes | - |
| query2 | - | - | - | yes | - | yes |
| query3 | yes | yes | yes | yes | yes | - |
| query4 | - | yes | yes | yes | yes | - |
| query5 | - | - | - | - | - | - |
| query6 | yes | yes | yes | yes | yes | - |
| query7 | yes | yes | yes | yes | yes | - |
| query8 | - | yes | yes | yes | - | - |
| query9 | yes | yes | yes | yes | yes | yes |
| query10 | yes | yes | yes | yes | yes | - |
| query11 | - | yes | yes | yes | yes | - |
| query12 | - | - | - | - | - | - |
| query13 | yes | yes | yes | yes | yes | yes |
| query14 | - | - | - | - | - | - |
| query15 | yes | yes | yes | yes | - | - |
| query16 | - | - | - | - | - | - |
| query17 | yes | yes | yes | yes | - | - |
| query18 | - | yes | yes | yes | yes | - |
| query19 | yes | yes | yes | yes | - | - |
| query20 | - | - | - | - | - | - |
| query21 | - | - | - | - | - | - |
| query22 | - | yes | yes | yes | yes | - |
| query23 | - | - | - | - | - | - |
| query24 | - | - | - | - | yes | - |
| query25 | yes | yes | yes | yes | yes | - |
| query26 | yes | yes | yes | yes | yes | - |
| query27 | - | yes | yes | yes | yes | - |
| query28 | yes | yes | yes | yes | yes | - |
| query29 | yes | yes | yes | yes | yes | - |
| query30 | - | - | - | - | - | - |
| query31 | - | yes | yes | yes | yes | yes |
| query32 | - | - | - | - | - | - |
| query33 | - | yes | yes | yes | yes | - |
| query34 | yes | yes | yes | yes | yes | yes |
| query35 | yes | yes | yes | yes | yes | - |
| query36 | - | - | - | - | - | - |
| query37 | - | - | - | - | - | - |
| query38 | - | yes | yes | yes | yes | - |
| query39 | - | - | - | - | - | - |
| query40 | - | - | - | - | - | - |
| query41 | yes | yes | yes | yes | - | - |
| query42 | yes | yes | yes | yes | yes | - |
| query43 | yes | yes | yes | yes | yes | - |
| query44 | - | yes | yes | yes | yes | - |
| query45 | yes | yes | yes | yes | - | - |
| query46 | yes | yes | yes | yes | yes | - |
| query47 | - | yes | yes | yes | yes | - |
| query48 | - | yes | yes | yes | yes | yes |
| query49 | - | - | - | yes | - | - |
| query50 | yes | yes | yes | yes | yes | - |
| query51 | - | yes | yes | yes | yes | - |
| query52 | yes | yes | yes | yes | yes | - |
| query53 | - | yes | yes | yes | yes | - |
| query54 | - | yes | yes | yes | yes | - |
| query55 | yes | yes | yes | yes | yes | - |
| query56 | - | yes | yes | yes | yes | - |
| query57 | - | yes | yes | yes | yes | - |
| query58 | - | yes | yes | yes | yes | - |
| query59 | - | yes | yes | yes | yes | - |
| query60 | - | yes | yes | yes | yes | - |
| query61 | yes | yes | yes | yes | yes | - |
| query62 | yes | yes | yes | yes | - | - |
| query63 | - | yes | yes | yes | yes | - |
| query64 | - | yes | yes | yes | yes | yes |
| query65 | yes | yes | yes | yes | yes | - |
| query66 | yes | yes | yes | - | - | - |
| query67 | - | yes | yes | yes | yes | - |
| query68 | yes | yes | yes | yes | yes | - |
| query69 | yes | yes | yes | yes | yes | - |
| query70 | - | - | - | - | - | - |
| query71 | yes | yes | yes | yes | yes | yes |
| query72 | yes | yes | yes | - | - | - |
| query73 | yes | yes | yes | yes | yes | yes |
| query74 | - | yes | yes | yes | yes | - |
| query75 | - | yes | yes | yes | yes | - |
| query76 | yes | yes | yes | yes | yes | - |
| query77 | - | - | - | - | - | - |
| query78 | - | yes | yes | yes | yes | - |
| query79 | yes | yes | yes | yes | - | - |
| query80 | - | - | - | - | - | - |
| query81 | - | yes | yes | yes | yes | - |
| query82 | - | - | - | - | - | - |
| query83 | - | yes | yes | yes | yes | - |
| query84 | yes | yes | yes | yes | - | - |
| query85 | yes | yes | yes | yes | - | - |
| query86 | - | - | - | - | - | - |
| query87 | - | yes | yes | yes | yes | - |
| query88 | yes | yes | yes | yes | yes | yes |
| query89 | - | yes | yes | yes | yes | - |
| query90 | yes | - | - | yes | yes | - |
| query91 | yes | yes | yes | yes | yes | yes |
| query92 | - | - | - | - | - | - |
| query93 | yes | yes | yes | yes | yes | - |
| query94 | - | - | - | - | - | - |
| query95 | - | - | - | - | - | - |
| query96 | yes | yes | yes | yes | yes | - |
| query97 | - | yes | yes | yes | yes | - |
| query98 | - | - | - | - | - | - |
| query99 | yes | yes | yes | yes | - | - |
| 总计 | 42 | 73 | 73 | 74 | 62 | 11 |
预备性能对比
count(*) 99个sql,单位 ms
- mysql 6383
- pg 1953
- hana 394
1W 个 socket连接,对端启动一个python
- centos, 2852
- suse, 2789
1K 个 socket连接,测试对端 JDBC 服务端口
- hana(suse), 8268
- mysql(centos), 1015
- pg(centos), 3071
收发文件,单位 ms
| 操作系统 | 100M | 500M |
|---|---|---|
| centos 接收 | 446 | 3940 |
| centos 发送 | 904 | 3625 |
| suse 接收 | 558 | 1909 |
| suse 发送 | 1056 | 3837 |
性能对比
HANA
读取数据和服务器启动时
2核1线程
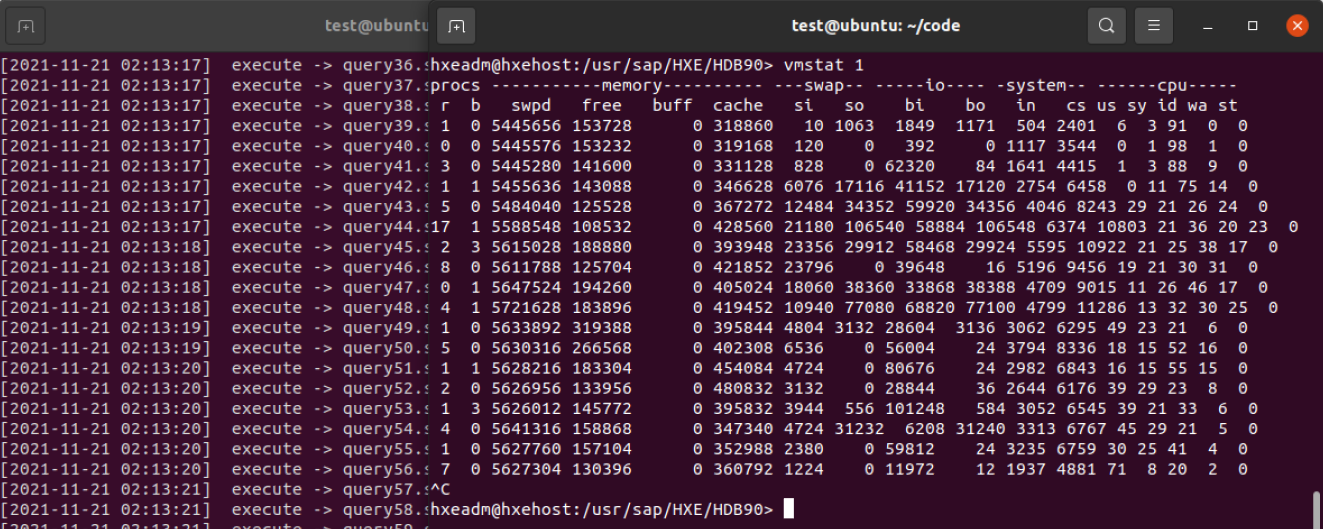
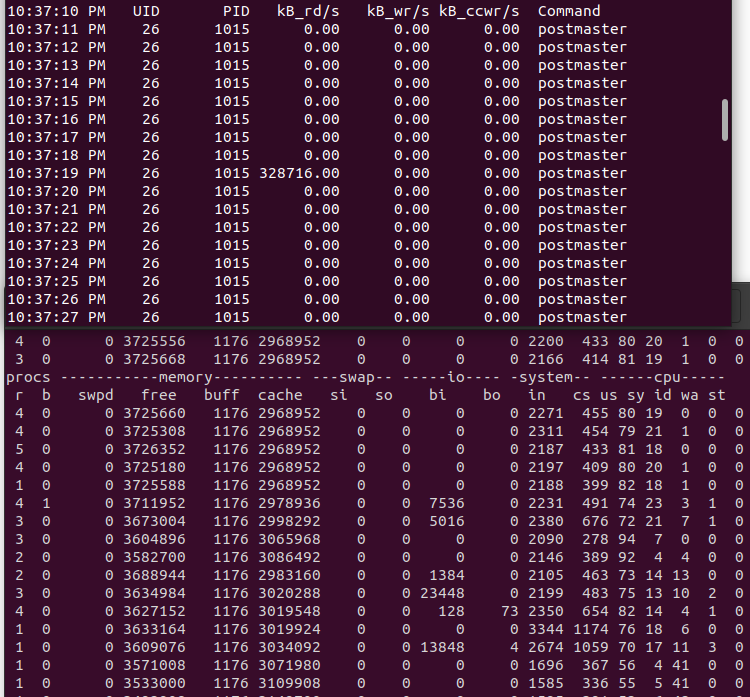
在 suse机器上执行 vmstat,发现数据并不是全部加载到内存的,在执行的过程中依然有 I/O读取操作:
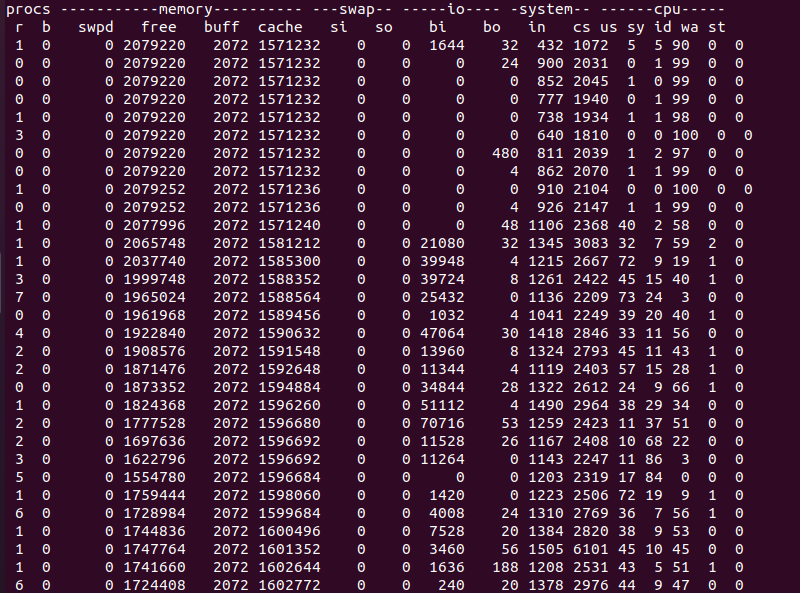
index-server看起来内存使用很高,这个机器分配了8G内存
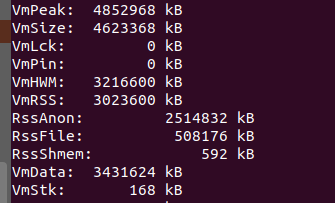
这是hana为什么快的原因,执行过程中,没有任何I/O,唯一那个I/O操作读取 vmstat命令本身:
反复执行了几遍TPC-DS,速度非常快,而且没有任何I/O
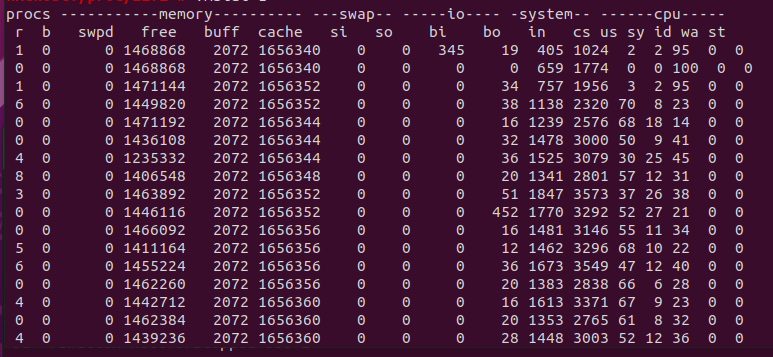
hana在启动的非常慢,明显比mysql、PG要慢的多,在启动过程有很多I/O读操作,可能是在读数据
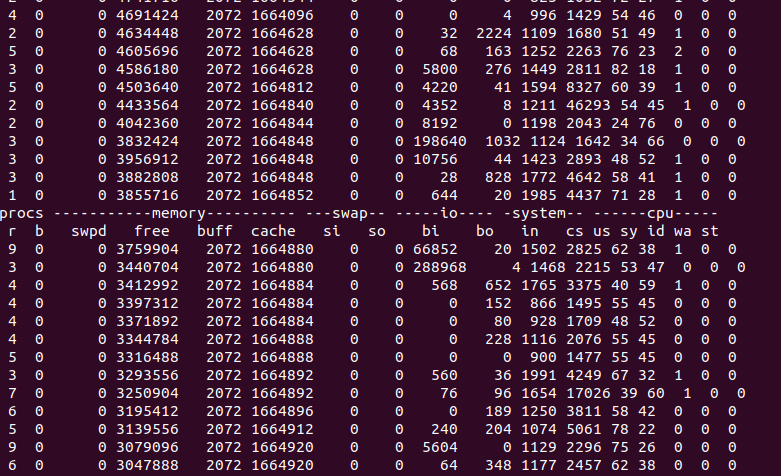
内存不足时,无法启动,
测试发现到 6G时,才可以正常启动,5G内存 index-server可以启动,但是其他服务器启动失败了
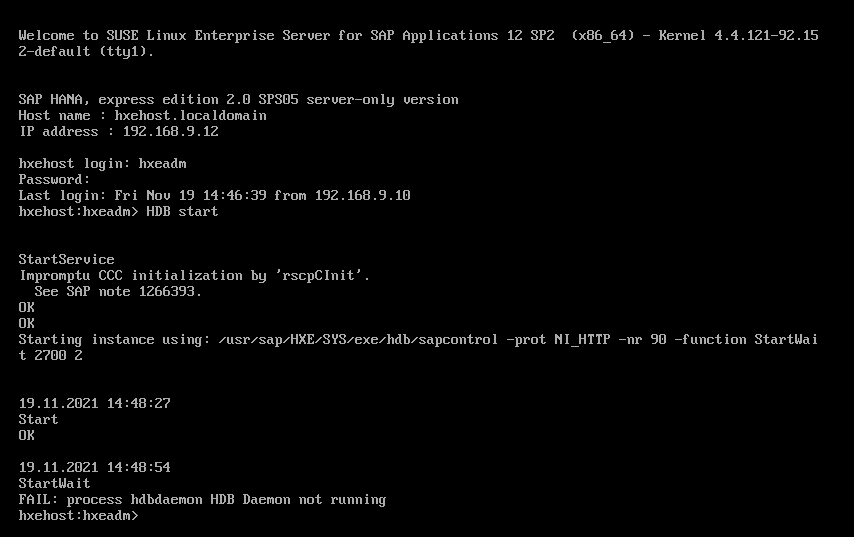
内存不足时的表现
物理内存为8G,hana正常启动,此时启动 40个额外进程,每个进程占用100M内存
此时可用空间严重不足,会触发大量的swap,也就是将哪些进程 写入到swap,此时执行速度依然很快
直接将 swap关闭
|
|
再做测试,此时发现 所有的 99个 查询全部失败
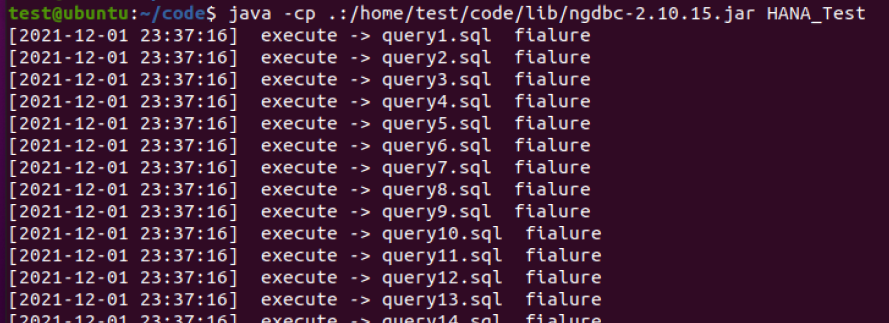
看了机器的进程状态,不是执行抛错,而是 index-server 直接就挂掉了,而且都无法启动
等把 swap 还原,index-server才能启动
从上述测试可以得出结果,hana跟impala类似,对内存要求非常高
内部数据表示
HANA的表结构和数据是放在一个dat文件里的

删除了 “xxxxxxxxx” 之后,数据还在,说明用的是标记方式

插入一个数据:
|
|
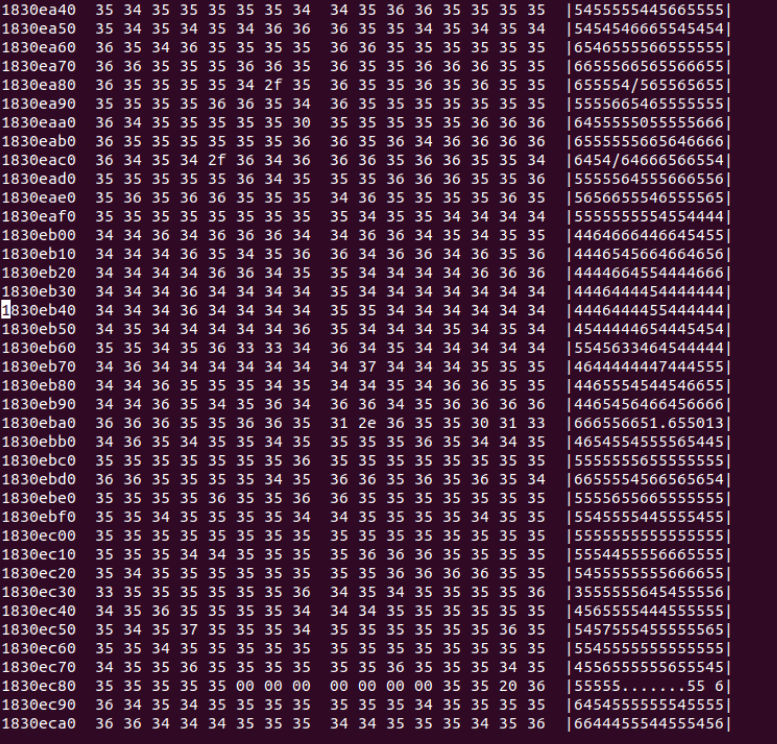
用hexdump的方式,直接将二进制文件内容dump出来,此时发现 “55555"的附近,又有"44444”,也有"66666666666"
也可能是 行存、列存 混合在一起的
grep 另外一个文件,很明显是 列存的
HANA包含的数据文件,都挺大的:
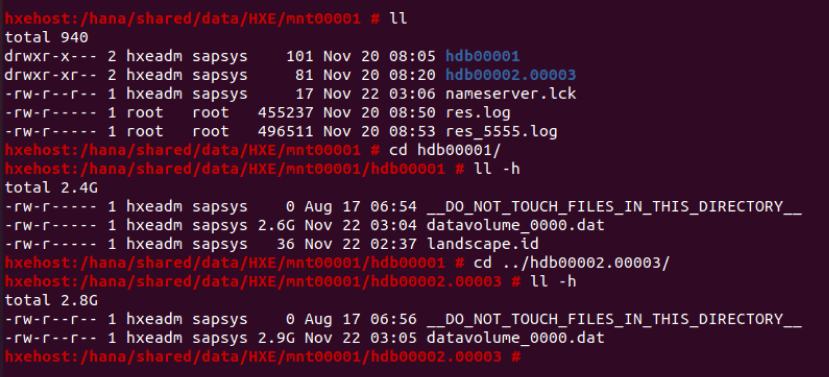
而且这两个数据文件,在启动、停止、再启动时都会发送变化
对比一下,一个新的hana,刚刚装好后,数据文件也有1.7G
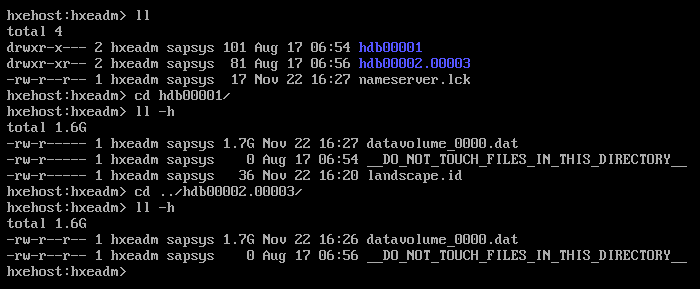
数据文件,在没有数据更新的情况下, 启动(做一次MD5),停止(做一次MD5),再启动(做一次MD5)的结果:
|
|
PG
1核1线程
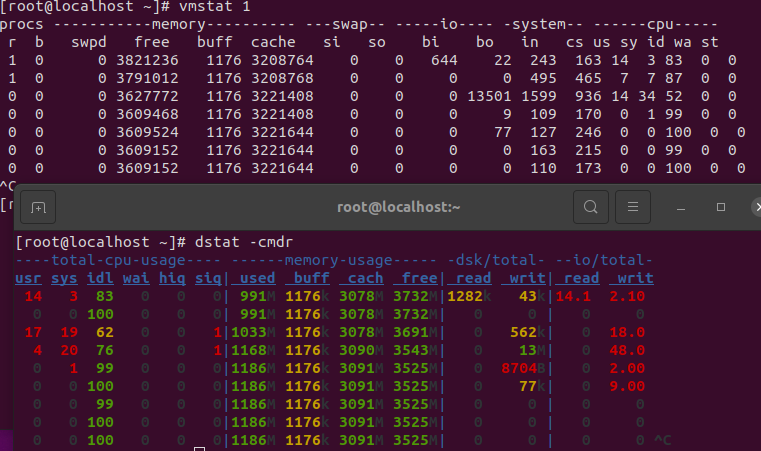
执行过程中,发现 PG 的I/O很低,但是CPU使用率很高
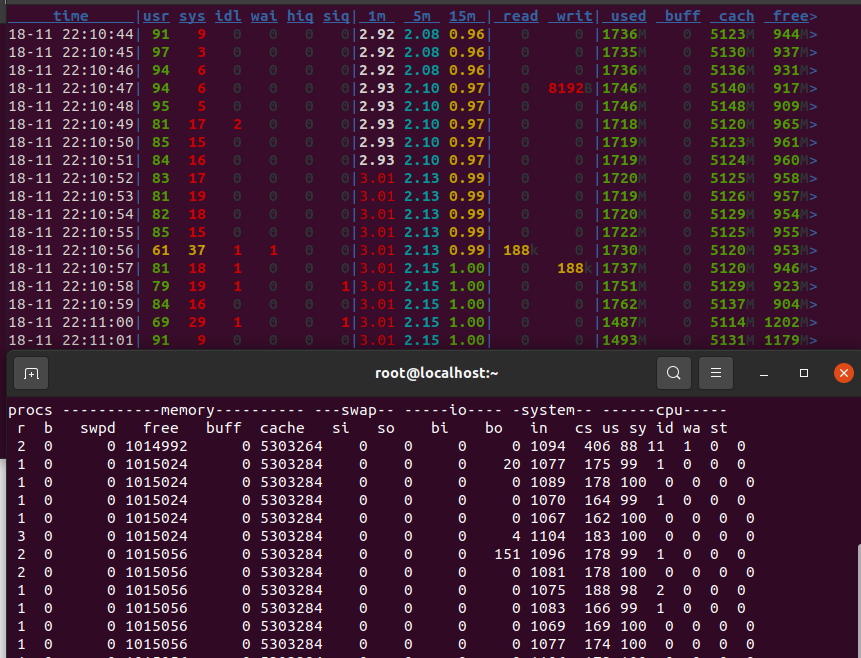
PG在启动的时候,几乎没有什么I/O
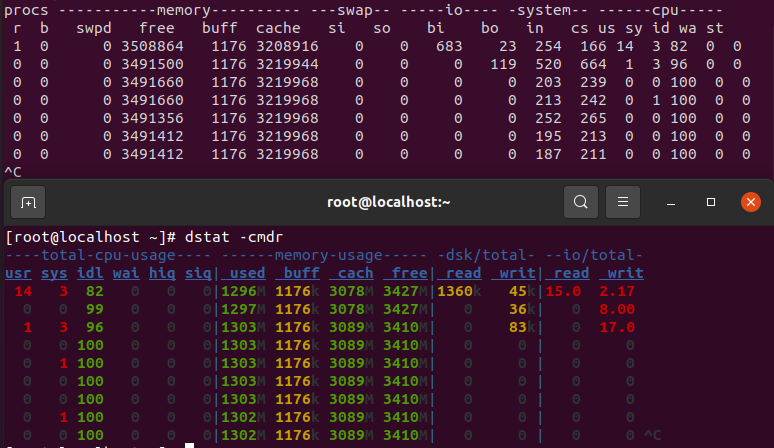
2核1线程
同样是 I/O很少,大部分都花在了 cpu上,由于是数据库做了裸I/O,所以buff、cache都没什么变化
以下是 pidstat + vmstat 的结果
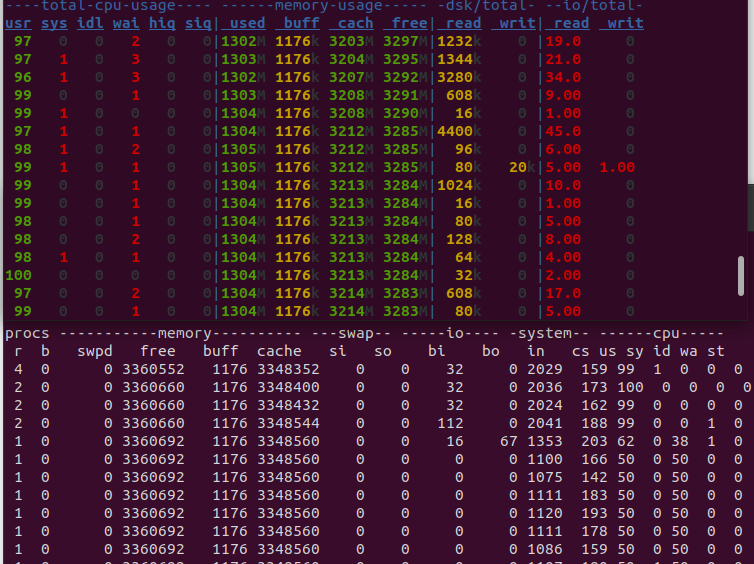
myql
mysql启动的时候,也没有什么I/O操作
2核1线程
mysql的CPU使用率很高,几乎满了,它在计算的时候会有I/O读,但计算过程中就没有I/O了
总体对比
默认使用了:2核1线程
为了对比HANA的并行情况,测试了 HANA的1核1线程、4核2线程情况
| 查询编号 | mysql | PGv12 | HANA | HANA(1核1线程) | HANA(4核2线程) |
|---|---|---|---|---|---|
| query1 | 5374295 | 639 | 1211 | 1021 | |
| query2 | 574 | 727 | 440 | ||
| query3 | 31 | 87 | 57 | 216 | 266 |
| query4 | 11262614 | 878 | 1741 | 1204 | |
| query5 | |||||
| query6 | 123020 | 202187 | 153 | 195 | 183 |
| query7 | 13411 | 3574 | 358 | 213 | 226 |
| query8 | 996 | 255 | 260 | 187 | |
| query9 | 11220 | 3780 | 237 | 283 | 162 |
| query10 | 1224 | 121 | 176 | 150 | |
| query11 | 494 | 663 | 434 | ||
| query12 | |||||
| query13 | 2842 | 1416 | 178 | 204 | 223 |
| query14 | |||||
| query15 | 6147 | 597 | 68 | 87 | 74 |
| query16 | |||||
| query17 | 1262 | 932 | 271 | 318 | 333 |
| query18 | 1962 | 246 | 372 | 217 | |
| query19 | 181 | 168 | 82 | 77 | 73 |
| query20 | |||||
| query21 | |||||
| query22 | 40907 | 1432 | 2430 | 1096 | |
| query23 | |||||
| query24 | |||||
| query25 | 1036 | 863 | 85 | 222 | 145 |
| query26 | 6311 | 1541 | 107 | 161 | 117 |
| query27 | 2936 | 172 | 219 | 113 | |
| query28 | 8348 | 3478 | 161 | 159 | 113 |
| query29 | 953 | 576 | 92 | 127 | 120 |
| query30 | |||||
| query31 | 24365 | 108 | 190 | 156 | |
| query32 | |||||
| query33 | 1057 | 99 | 157 | 125 | |
| query34 | 8013 | 1123 | 134 | 156 | 136 |
| query35 | 1740 | 260 | 420 | 329 | |
| query36 | |||||
| query37 | |||||
| query38 | 6063 | 299 | 309 | 228 | |
| query39 | |||||
| query40 | |||||
| query41 | 2332 | 3078 | 64 | 76 | 71 |
| query42 | 102 | 136 | 63 | 81 | 77 |
| query43 | 8521 | 1173 | 197 | 262 | 126 |
| query44 | 1018 | 128 | 127 | 98 | |
| query45 | 1359 | 365 | 88 | 116 | 102 |
| query46 | 9767 | 1330 | 373 | 331 | 193 |
| query47 | 5509 | 336 | 319 | 158 | |
| query48 | 1556 | 138 | 137 | 141 | |
| query49 | 371 | 297 | 253 | ||
| query50 | 525 | 216 | 63 | 92 | 103 |
| query51 | 4815 | 1303 | 1298 | 530 | |
| query52 | 110 | 130 | 55 | 64 | 58 |
| query53 | 348 | 62 | 75 | 70 | |
| query54 | 45474 | 65 | 349 | 370 | |
| query55 | 81 | 94 | 58 | 66 | 66 |
| query56 | 258 | 87 | 151 | 145 | |
| query57 | 2253 | 183 | 225 | 136 | |
| query58 | 950 | 79 | 155 | 131 | |
| query59 | 3502 | 645 | 714 | 270 | |
| query60 | 736 | 99 | 156 | 128 | |
| query61 | 9 | 120 | 53 | 107 | 74 |
| query62 | 3245 | 548 | 88 | 125 | 109 |
| query63 | 306 | 71 | 79 | 65 | |
| query64 | 1140 | 104 | 288 | 270 | |
| query65 | 10228 | 2319 | 205 | 287 | 192 |
| query66 | 3066 | ||||
| query67 | 9599 | 2056 | 1360 | 453 | |
| query68 | 9634 | 847 | 467 | 175 | 140 |
| query69 | 1096 | 89 | 172 | 128 | |
| query70 | |||||
| query71 | 8526 | 803 | 129 | 135 | 107 |
| query72 | 198123 | 2447 | |||
| query73 | 6104 | 666 | 90 | 97 | 83 |
| query74 | 875881 | 409 | 545 | 434 | |
| query75 | 2892 | 481 | 490 | 244 | |
| query76 | 2351 | 680 | 53 | 72 | 78 |
| query77 | |||||
| query78 | 5263 | 1153 | 1730 | 1013 | |
| query79 | 7047 | 1194 | 196 | 194 | 187 |
| query80 | |||||
| query81 | 18497 | 96 | 106 | 125 | |
| query82 | |||||
| query83 | 328 | 71 | 131 | 149 | |
| query84 | 9351 | 153 | 57 | 86 | 86 |
| query85 | 532 | 296 | 82 | 154 | 164 |
| query86 | |||||
| query87 | 7263 | 1089 | 1474 | 717 | |
| query88 | 19601 | 4008 | 250 | 366 | 200 |
| query89 | 466 | 99 | 96 | 115 | |
| query90 | 1778 | 374 | 68 | 95 | 93 |
| query91 | 287 | 165 | 57 | 94 | 113 |
| query92 | |||||
| query93 | 213 | 257 | 168 | 75 | 86 |
| query94 | |||||
| query95 | |||||
| query96 | 2046 | 606 | 75 | 71 | 83 |
| query97 | 2097 | 606 | 590 | 304 | |
| query98 | |||||
| query99 | 4584 | 1019 | 166 | 119 | 101 |
参考
hana的前身今世
SAP HANA 基础架构简介
SAP HANA分布式系统及高可用性(一)
SAP HANA 基础架构简介(二)
SAP HANA Express Edition (HXE)-虚拟机模板安装使用步骤
HANA数据存储方式及其他介绍
linux安装pgv12
PostgreSQL 允许远程访问设置方法
DATAX,HANA数据库
DataX 使用rdbms插件同步数据库
mysql连接超时问题
HANA在线文档
HANA官网介绍最近10年发展历程
HANA管理教程