执行过程
时序图分析
生成pipeline的过程:
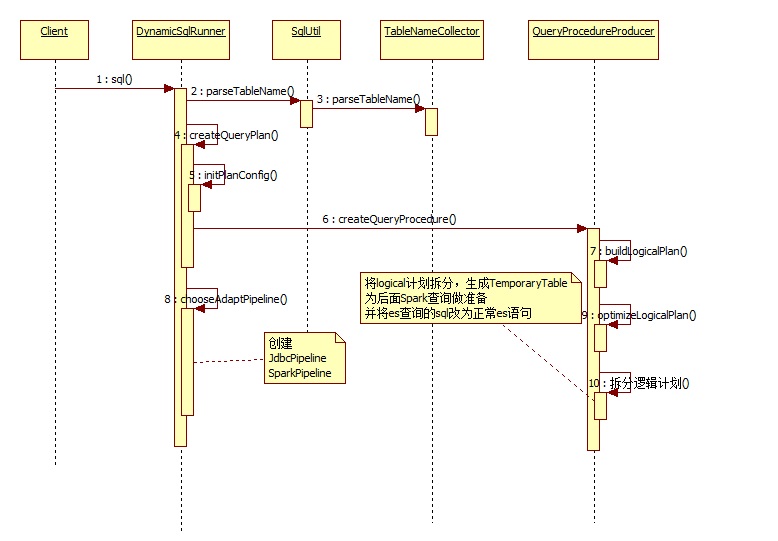
spark pipeline的执行过程:
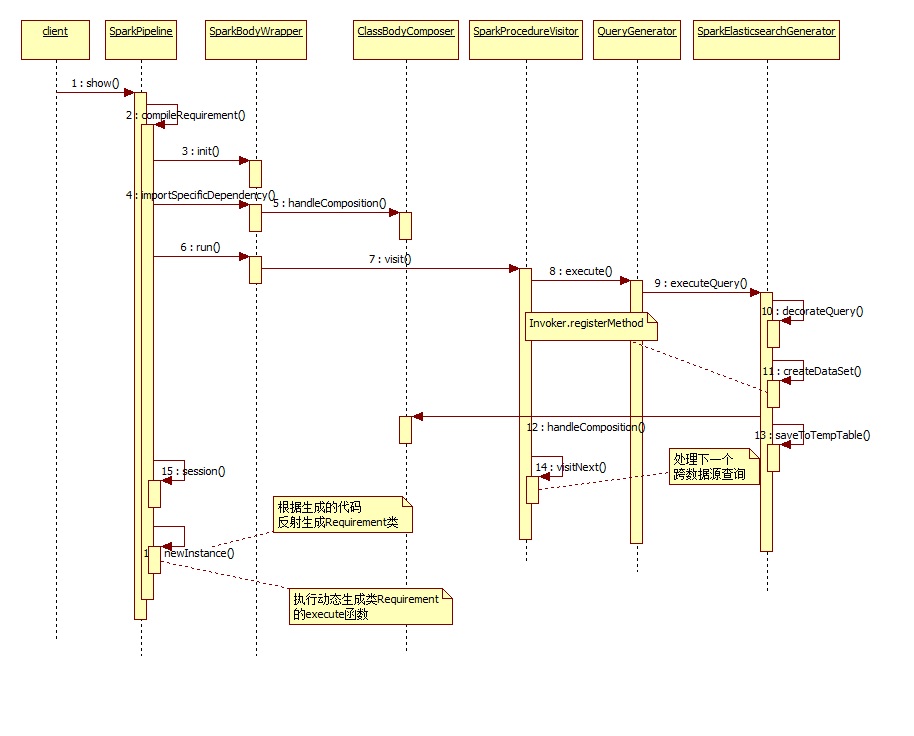
jdbc pipeline的执行过程:

一条sql的执行过程
一个跨数据源的查询,sql如下:
1
|
SELECT * FROM depts INNER JOIN (SELECT * FROM student WHERE city in ('FRAMINGHAM', 'BROCKTON', 'CONCORD')) FILTERED ON depts.name = FILTERED.type
|
首先进行sql解析、验证、优化,得到的语法树如下:
LogicalProject(deptno=[$0], name=[$1], city=[$2], province=[$3], digest=[$4], type=[$5], stu_id=[$6]): rowcount = 375.0, cumulative cost = {910.0 rows, 2961.1 cpu, 0.0 io}, id = 21
LogicalJoin(condition=[=($1, $5)], joinType=[inner]): rowcount = 375.0, cumulative cost = {535.0 rows, 336.1 cpu, 0.0 io}, id = 19
LogicalTableScan(table=[[custom_name, depts]]): rowcount = 100.0, cumulative cost = {100.0 rows, 101.0 cpu, 0.0 io}, id = 7
LogicalProject(city=[$0], province=[$1], digest=[$2], type=[$3], stu_id=[$4]): rowcount = 25.0, cumulative cost = {60.0 rows, 235.1 cpu, 0.0 io}, id = 17
LogicalFilter(condition=[OR(=($0, 'FRAMINGHAM'), =($0, 'BROCKTON'), =($0, 'CONCORD'))]): rowcount = 25.0, cumulative cost = {35.0 rows, 110.1 cpu, 0.0 io}, id = 15
ElasticsearchTableScan(table=[[esTest, student]]): rowcount = 100.0, cumulative cost = {10.0 rows, 10.100000000000001 cpu, 0.0 io}, id = 8
quick sql会将不同的数据源,组装成TemporaryTableScan类,于是上面的语法树就变成了:
LogicalProject(deptno=[$0], name=[$1], city=[$2], province=[$3], digest=[$4], type=[$5], stu_id=[$6]): rowcount = 1500.0, cumulative cost = {3200.0 rows, 10702.0 cpu, 0.0 io}, id = 21
LogicalJoin(condition=[=($1, $5)], joinType=[inner]): rowcount = 1500.0, cumulative cost = {1700.0 rows, 202.0 cpu, 0.0 io}, id = 19
TemporaryTableScan(table=[[custom_name_depts_0]]): rowcount = 100.0, cumulative cost = {100.0 rows, 101.0 cpu, 0.0 io}, id = 24
TemporaryTableScan(table=[[esTest_student_1]]): rowcount = 100.0, cumulative cost = {100.0 rows, 101.0 cpu, 0.0 io}, id = 26
生成过程中,还会对不同数据源查询的语句做详细解析,也就是查es的sql变成正常的es查询语句:
List<ExtractProcedure>:
CSV:SELECT deptno, name FROM custom_name.depts
ES:{"query":{"constant_score":{"filter":{"bool":{"should":[{"term":{"city":"FRAMINGHAM"}},{"term":{"city":"BROCKTON"}},{"term":{"city":"CONCORD"}}]}}}},"_source":["city","province","digest","type","stu_id"]}
之后在运行期间,动态生成一个类,然后再编译这个类,生成的类如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
import com.qihoo.qsql.exec.Requirement;
import org.apache.spark.sql.catalyst.expressions.Attribute;
import org.apache.spark.sql.Row;
import java.util.stream.Collectors;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import java.util.Collections;
import java.util.Map;
import java.util.HashMap;
import com.qihoo.qsql.exec.spark.SparkRequirement;
import java.util.regex.Pattern;
import scala.collection.JavaConversions;
import java.util.AbstractMap.SimpleEntry;
import java.util.regex.Matcher;
import com.qihoo.qsql.codegen.spark.SparkElasticsearchGenerator;
import org.apache.spark.api.java.JavaRDD;
import org.elasticsearch.spark.sql.api.java.JavaEsSparkSQL;
import org.apache.spark.sql.Dataset;
import java.util.Arrays;
import org.apache.commons.lang.StringEscapeUtils;
import java.util.List;
public class Requirement32110 extends SparkRequirement {
public Requirement32110(SparkSession spark){
super(spark);
}
public Object execute() throws Exception {
Dataset<Row> tmp;
{
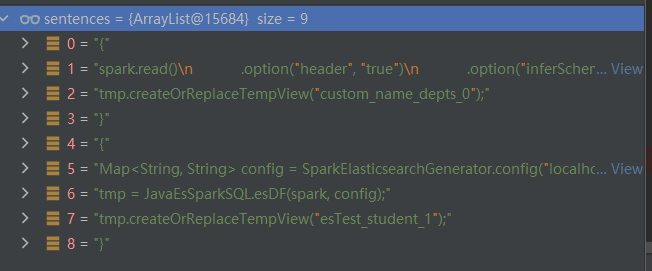
Map<String, String> config = SparkElasticsearchGenerator.config("localhost", "9025", "username", "password", "student",
"{\"query\":{\"constant_score\":{\"filter\":{\"bool\":{\"should\":[{\"term\":{\"city\":\"FRAMINGHAM\"}},{\"term\":{\"city\":\
"BROCKTON\"}},{\"term\":{\"city\":\"CONCORD\"}}]}}}},\"_source\":[\"city\",\"province\",\"digest\",\"type\",\"stu_id\"]}",
"1");
tmp = JavaEsSparkSQL.esDF(spark, config);
tmp.createOrReplaceTempView("esTest_student_1");
}
{
spark.read()
.option("header", "true")
.option("inferSchema", "true")
.option("timestampFormat", "yyyy/MM/dd HH:mm:ss ZZ")
.option("delimiter", ",")
.csv("D:\\code\\Quicksql\\data\\sales\\DEPTS.csv")
.toDF()
.createOrReplaceTempView("custom_name_depts");
tmp = spark.sql("SELECT deptno, name FROM custom_name_depts");
tmp.createOrReplaceTempView("custom_name_depts_0");
}
String sql = "SELECT custom_name_depts_0.deptno, custom_name_depts_0.name, esTest_student_1.city, esTest_student_1.province,
esTest_student_1.digest, esTest_student_1.type, esTest_student_1.stu_id FROM custom_name_depts_0 INNER JOIN esTest_student_1 ON
custom_name_depts_0.name = esTest_student_1.type";
tmp = spark.sql(sql);
tmp.show(200);
return null;
}
}
|
这里可以很明显的看到,先查询了es,将结果保存到esTest_student_1中,之后再查询csv,将结果保存到custom_name_depts_0。
最后,再做一个联合查询,也就是下面这个sql:
1
2
3
|
SELECT custom_name_depts_0.deptno, custom_name_depts_0.name, esTest_student_1.city, esTest_student_1.province, esTest_student_1.digest,
esTest_student_1.type, esTest_student_1.stu_id FROM custom_name_depts_0 INNER JOIN esTest_student_1 ON custom_name_depts_0.name =
esTest_student_1.type
|
这里也有很多优化的地方,比如上面的执行过程,看起来是串行的。
跨数据执行详解
从逻辑计划到物理计划
一个跨数据源的sql:
1
|
select * from CSV join ES where .... on ...
|
对应完整的解析过程:
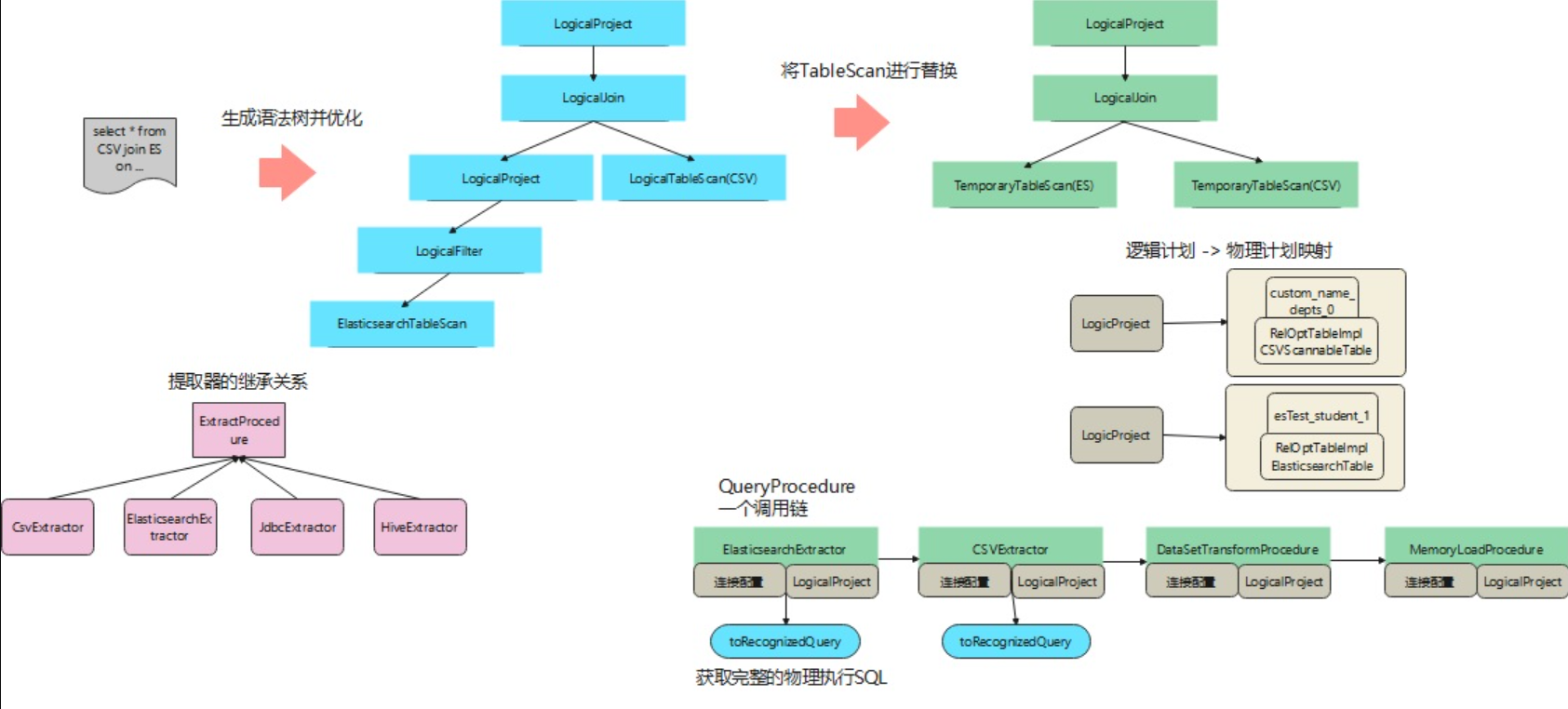
执行步骤:
- 首先将这个sql解析并优化,生成一个语法树
- 之后会遍历这棵树,从根节点递归遍历,然后将
TableScan替换成TemporaryTableScan
- 这里有些不确定的地方,蓝色图中有
LogicalFilter,这代表一个where条件,但转换成TemporaryTableScan就没了
- 替换过程会将语法树修改,之后还会得到一个逻辑计划 到 物理计划的映射,对应上图米黄色部分。
- 最后拼装一个QueryProcedure,这是一个单链表,头结点是ES,next指向CSV,然后是一个DataSetTransformProcedure,这个对应是一个混合查询,尾节点是用于展示的
回答一下刚才自己的问题,为什么转成成TemporaryTableScan后,LogicalFilter好像丢失了?
大致原因可能是,生成TemporaryTableScan只是做拆分的。
因为一个TemporaryTableScan对应一个查询计划,这样就可以拆分成N个查询丢给Spark。
在封装QueryProcedure时,给每个 提取器传入的不是 TemporaryTableScan,而是LogicalProject,比如传给ES的就是一个逻辑执行计划,对应上图蓝色部分 LogicalProject -> LogicalFilter -> ElasticsearchTableScan。
有了这么一层关系,where条件就不会丢失了。
之后根据QueryProcedure生成对应的Pipeline,pipeline在查询的时候,会调用 提取器,获得一个完整的可以执行的SQL。
ES这个提取器比较有意思,它是根据逻辑计划,再反向转换成一个sql,然后又一次解析了这个sql(生成token并校验),接着是得到物理计划,最后根据物理计划转成真实的ES查询语句:
1
2
|
{"query":{"constant_score":{"filter":{"bool":{"should":[{"term":{"city":"FRAMINGHAM"}},
{"term":{"city":"BROCKTON"}},{"term":{"city":"CONCORD"}}]}}}},"_source":["city","province","digest","type","stu_id"]}
|
如果这么看的话,TemporaryTableScan丢失一部分信息,确实是没关系。
下面是生成query_procedure过程的时序图:
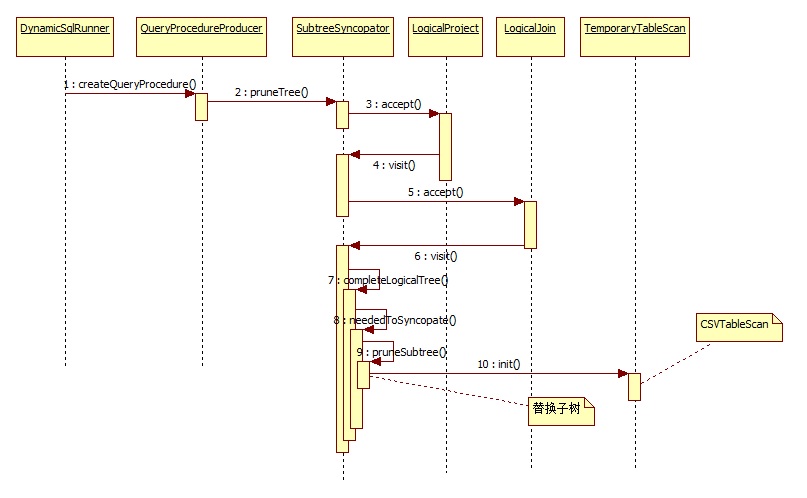
执行原理
根据前面生成的QueryProcedure单链表,动态拼装出执行类:
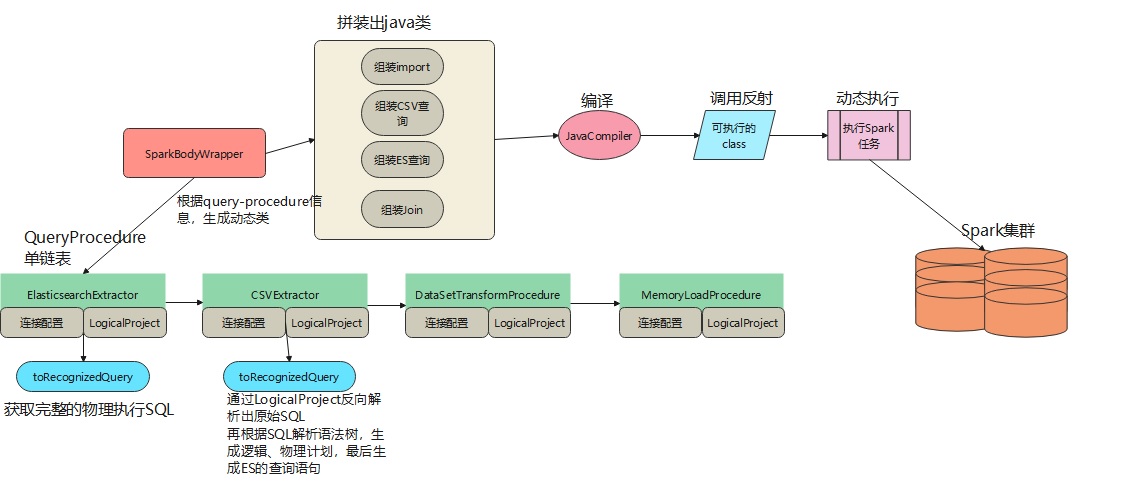
执行过程如下:
QueryProcedure是一个单链表,每个节点都是一个具体的ScanTable,之后将每个节点的信息挨个取出,调用toRecognizedQuery生成一个可以执行的语句,如果是ES就对应一个json查询语句。- 将信息交给
SparkBodyWrapper进行拼装,这里拼装的比较原始,就是利用字符串进行拼接
- 生成import信息
- 生成
csv查询的java语句
- 生成
es查询的java语句
- 拼装出一个
join语句,对前面csv和es的查询结果进行合并查询
- 完整拼装,拼出一个完整的
java类
- 将拼装的 java 类交给
JavaCompiler进行编译,编译后得到一个class,然后再反射生成一个对应
- 执行这个对象的
execute函数,执行一个 spark 任务
下面是spark pipeline的执行过程,这里主要是拼接成一个java类
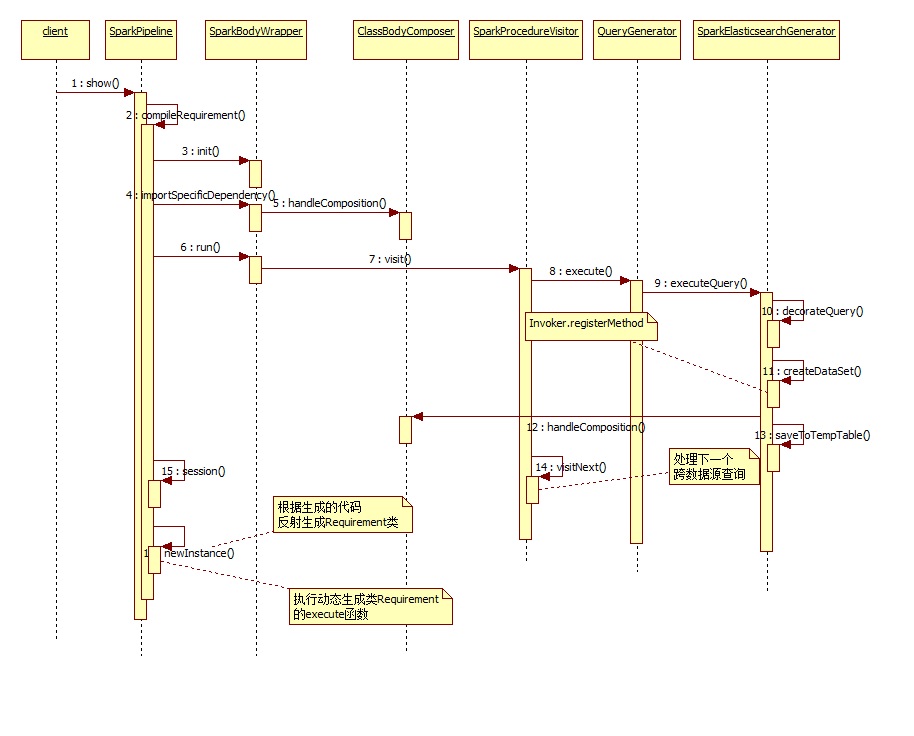
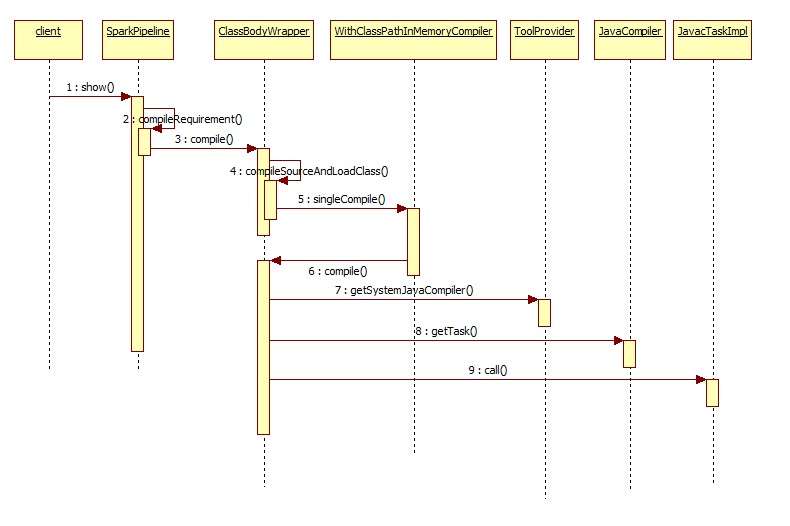
下面是动态编译的时序图,这里是编译再反射执行
跨数据拼装过程
背景
假设有一个跨数据源的SQL查询:
1
|
SELECT t1.name,t2.name FROM MySQL.test1 AS t1 JOIN Oracle.test_2 AS t2 WHERE t2.id > 10 ON t1.id = t2.id
|
想要完成跨数据源查询,就得把SQL做拆分,将查询mysql的部分剥离出来,同时将查询oracle的部分也剥离出来。
查询完mysql之后,将结果写到一个地方,记作a
查询完oracle之后,也将结果写到一个地方,记作b
再用join查询,执行a JOIN b这样的操作
假设我们已经把SQL拆分好了,将各个拆分后的查询拼接成一个单链表结构:
链表头结点(查询mysql相关配置信息) -> 链表节点(查询oracle相关配置信息) -> 链表节点(a join b信息)
之后,我们拿到这个单链表结构,再拼装出具体的可执行代码,并执行这个拼装后的代码。
本文主要介绍如何拼装代码、如何动态编译的过程。
整体结构
相关类图如下:
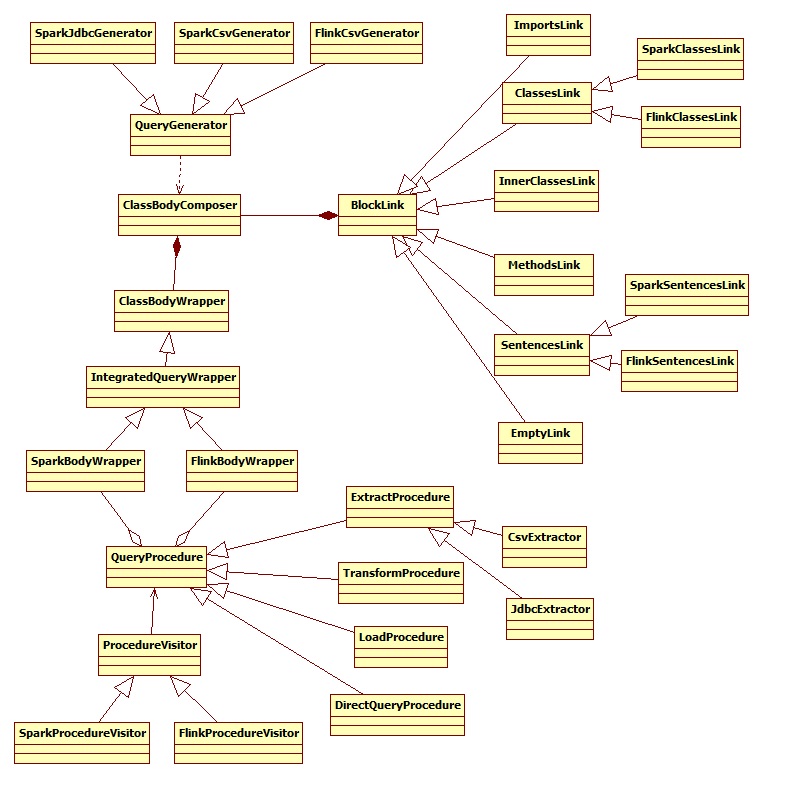
上图就是codegen包下的几乎所有类了,这个包的作用是将拆分后的sql拼装成具体的代码。
BlockLink这个类表示的是,需要拼装哪个部分的代码,他有好几个实现类:
ImportsLink这个实现类表示专门处理代码的import部分ClassLink这个表示专门处理代码的整体InnerClassLink处理拼装内部类MethodLink处理函数拼装SentencesLink处理一行代码,对一行代码做拼装用的
其他核心类:
QueryProcedure,这个类是sql拆分后的调用链最高层抽象类。也就是把 a JOIN b这样的查询语句拆分成a和b两个子语句。QueryProcedure的子类CsvExtractor、JdbcExtractor则代表链表中一个具体的节点。ProcedureVisitor是访问者模式的抽象类,专门用来访问查询链表中节点的。ClassBodyComposer用来收集所有的代码片段,最终可以组装成一个完整的Java类ClassBodyWrapper将ClassBodyComposer组装的完整类做编译QueryGenerator这是一个抽象类,其实现类对应一个具体的数据源,比如SparkCsvGenerator专门生成CSV相关的代码片段。
组装过程
QueryProcedure是拆分sql后,生成的一个单链表,每个链表节点都代表一个具体数据源的查询。
ImportLink、SparkClassLink、InnerClassLink、MethodLink这些是具体的实现类,用来处理代码片段的。
不同的代码片段需要放到不同的地方,比如import是由ImportLink处理的;一条语句是由SparkSentencesLink处理的。
ClassBodyComposer关联了ImportLink,当有代码片段交给ClassBodyComposer处理时,它就将这个代码片段交给ImportLink。
如果ImportLink能处理,就自己处理,否则继续往后传递。
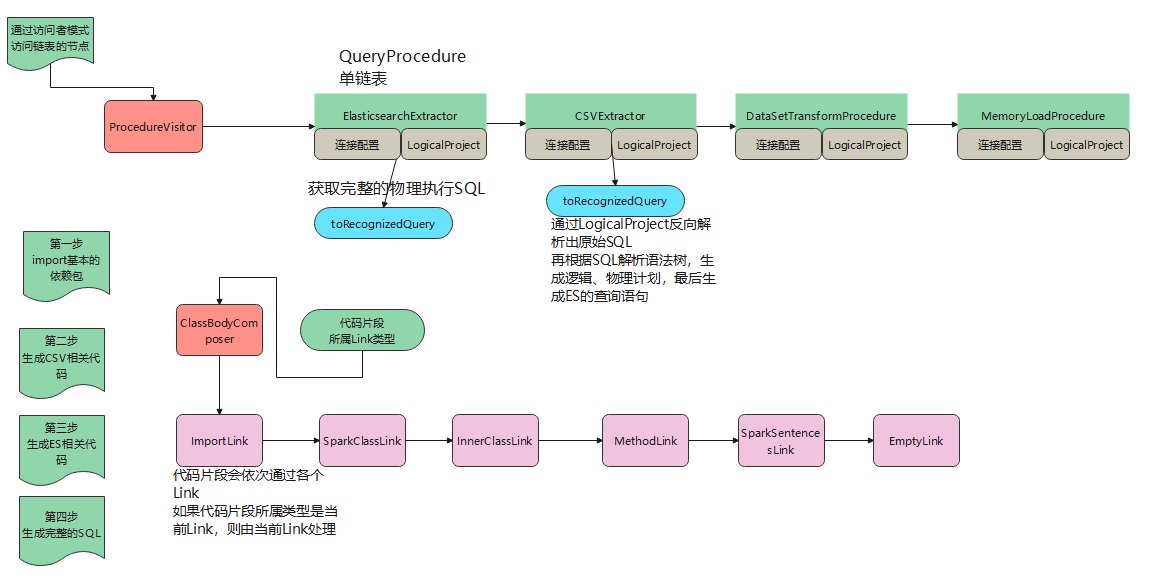
下面是处理各个数据源的核心代码:
1
2
3
4
5
6
7
8
9
|
public void visit(ExtractProcedure extractProcedure) {
composer.handleComposition(CodeCategory.SENTENCE, "{");
QueryGenerator queryBuilder = QueryGenerator.getQueryGenerator(
extractProcedure, composer, true);
queryBuilder.execute();
queryBuilder.saveToTempTable();
composer.handleComposition(CodeCategory.SENTENCE, "}");
visitNext(extractProcedure);
}
|
composer.handleComposition(CodeCategory.SENTENCE, "{");这句定义了需要将{由哪个BlockLink处理。这里定义的是SENTENCE,所以是由SentencesLink处理的。
之后由QueryGenerator.getQueryGenerator生成一个具体的实现类,比如SparkCsvGenerator。
CSV代码片段实现类,负责生成CSV相关的代码片段:
{
spark.read()
.option("header", "true")
.option("inferSchema", "true")
.option("timestampFormat", "yyyy/MM/dd HH:mm:ss ZZ")
.option("delimiter", ",")
.csv("D:\\code\\Quicksql\\data\\sales\\DEPTS.csv")
.toDF()
.createOrReplaceTempView("custom_name_depts");
tmp = spark.sql("SELECT deptno, name FROM custom_name_depts");
tmp.createOrReplaceTempView("custom_name_depts_0");
}
最后调用visitNext(extractProcedure)处理下一个链表节点。
importlink组装后的样子:
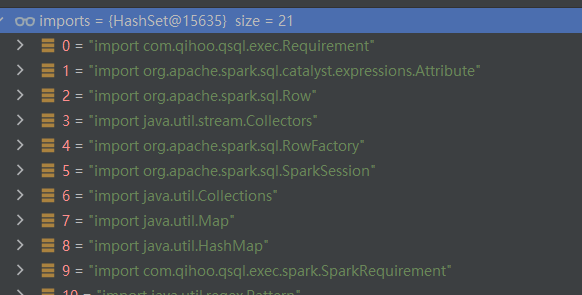
sentenceslink组装后的样子:
编译过程
依赖
编译是在内存中进行的,需要依赖:
picadoh,这是一个开源工具,com.github.picadoh.imc.compilerjavax.tools包下的编译类
有了完整的类,就可以直接编译了:
1
2
3
4
5
6
7
8
9
10
11
|
protected Requirement compileRequirement(IntegratedQueryWrapper wrapper, Object argument, Class clazz) {
Class requirementClass = wrapper.compile();
try {
final Constructor<Requirement> constructor = requirementClass.getConstructor(clazz);
return constructor.newInstance(argument);
} catch (NoSuchMethodException | IllegalAccessException
| InvocationTargetException | InstantiationException ex) {
ex.printStackTrace();
throw new RuntimeException(ex);
}
}
|
下面是wrapper.compile()内部细节,大致过程就是编译源文件并返回Class对象。
1
2
3
4
5
6
7
8
9
10
11
12
|
public static Class compileSourceAndLoadClass(String source, String name, String extraJars)
throws InMemoryCompiler.CompilerException,
ClassNotFoundException {
WithClassPathInMemoryCompiler compiler = new WithClassPathInMemoryCompiler();
CompilationPackage compilationPackage = compiler.singleCompile(name, source, extraJars);
CompilationPackageLoader loader = new CompilationPackageLoader();
Map<String, Class<?>> classes = loader.loadAsMap(compilationPackage);
if (! classes.containsKey(name)) {
throw new RuntimeException("Compile or load class failed!!");
}
return classes.get(name);
}
|
编译之前需要拿相关环境变量,和依赖:
1
2
3
4
5
6
7
8
9
10
|
String belongingJarPath = ClassBodyWrapper.class.getProtectionDomain().getCodeSource()
.getLocation()
.getPath();
List<String> options = Arrays
.asList("-classpath", extraJars
+ System.getProperty("path.separator")
+ System.getProperty("java.class.path")
+ System.getProperty("path.separator")
+ belongingJarPath
);
|
通过java.class.path会把所有的依赖包全部引入。
真正负责编译的类是com.sun.tools.javac.api.JavacTool
动态编译的类是Requirement的子类,拿到类的Class后,就通过反射创建一个实例,并返回。
最后是调用动态类的execute()函数。
问题
1、ClassBodyWrapper类在编译时,源码中有个注释,是说当前动态编译器有bug,加载多个级别的内部类时会触发。
2、内部类是什么时候生成的?
3、Javac编译时需要引入各种依赖包,会不会出现包冲突问题?
4、因为是动态生成的类,调试可能是一个麻烦
5、负责真正编译的是 javac.aip.JavacTool,如果更换了 JDK 是否还能正常编译?
6、大量编译、频繁会不会有性能问题,如果类非常大会不会出现OOM?
7、Calcite和QuickSql在编译的时候,本质都是动态拼接代码片段,这里要非常小心,一旦拼错了代码就无法编译
拼装的跨数据源代码
查询的SQL如下:
1
|
SELECT a.id,b.id FROM db_1.a JOIN db_2.b ON a.id = b.id WHERE b.id > 10 AND a.id < 10
|
生成的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
|
import com.qihoo.qsql.exec.Requirement;
import org.apache.spark.sql.catalyst.expressions.Attribute;
import org.apache.spark.sql.types.StructType;
import org.apache.spark.sql.Row;
import org.apache.hadoop.fs.Path;
import java.util.stream.Collectors;
import org.apache.spark.sql.RowFactory;
import java.util.concurrent.ArrayBlockingQueue;
import org.apache.spark.sql.SparkSession;
import java.util.Collections;
import com.qihoo.qsql.codegen.spark.SparkJdbcGenerator.SpecificFunction;
import java.util.ArrayList;
import java.util.concurrent.ExecutorService;
import com.qihoo.qsql.codegen.spark.SparkJdbcGenerator.ResultSetWrapper;
import com.qihoo.qsql.codegen.spark.SparkJdbcGenerator.ResultsTransporter;
import com.qihoo.qsql.codegen.spark.SparkJdbcGenerator.ResultSetInMemoryWrapper;
import scala.collection.JavaConversions;
import java.util.AbstractMap.SimpleEntry;
import java.net.URI;
import java.math.BigInteger;
import org.apache.spark.api.java.JavaRDD;
import org.apache.hadoop.fs.FileSystem;
import org.apache.spark.sql.Dataset;
import java.util.Arrays;
import java.sql.*;
import org.apache.hadoop.conf.Configuration;
import java.util.Enumeration;
import org.apache.spark.sql.types.DataTypes;
import java.util.Queue;
import org.apache.spark.sql.types.StructField;
import java.sql.Driver;
import java.util.Map;
import java.util.concurrent.Executors;
import com.qihoo.qsql.exec.spark.SparkRequirement;
import java.io.IOException;
import org.apache.spark.sql.types.DataType;
import java.util.concurrent.BlockingQueue;
import com.qihoo.qsql.codegen.spark.SparkJdbcGenerator.ResultSetInFileSystemWrapper;
import java.sql.DriverManager;
import java.util.ArrayDeque;
import java.util.List;
public class Requirement32420 extends SparkRequirement {
public Requirement32420(SparkSession spark){
super(spark);
}
private List<StructField> getDataTypes(ResultSet resultSet) {
List<StructField> columns;
try {
int n = resultSet.getMetaData().getColumnCount();
String labelName;
columns = new ArrayList<StructField>();
for (int index = 1; index <= n; index++) {
labelName = resultSet.getMetaData().getColumnLabel(index);
columns.add(DataTypes.createStructField(labelName, getColumnType(resultSet.getMetaData().getColumnType(index)), true));
}
} catch (SQLException e) {
throw new RuntimeException(e.getMessage());
}
return columns;
}
private DataType getColumnType(int dataType) {
switch (dataType) {
case Types.BINARY:
return DataTypes.BinaryType;
case Types.BIT:
case Types.BOOLEAN:
return DataTypes.BooleanType;
case Types.DATE:
return DataTypes.DateType;
case Types.TIMESTAMP:
return DataTypes.TimestampType;
case Types.DECIMAL:
case Types.NUMERIC:
return DataTypes.createDecimalType();
case Types.DOUBLE:
return DataTypes.DoubleType;
case Types.FLOAT:
case Types.REAL:
return DataTypes.FloatType;
case Types.BIGINT:
return DataTypes.LongType;
case Types.INTEGER:
return DataTypes.IntegerType;
case Types.SMALLINT:
return DataTypes.ShortType;
case Types.TINYINT:
return DataTypes.IntegerType;
case Types.NULL:
return DataTypes.NullType;
case Types.VARCHAR:
case Types.NVARCHAR:
case Types.CHAR:
case Types.NCHAR:
default:
return DataTypes.StringType;
}
}
private ResultSetWrapper persist(String url, String user, String password,String driver, String sql) {
String baseURI = "nullnull";
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
StructType schema;
final int THRESHOLD = 0x400000;
final int BUFFER_SIZE = 0x40000;
final int CONCURRENT_PACKAGE_NUM = 8;
int rowCount = 0;
int rowPartition = 0;
long partitionStamp = System.currentTimeMillis();
BlockingQueue<List<Object[]>> queue = new ArrayBlockingQueue<List<Object[]>>(CONCURRENT_PACKAGE_NUM);
Queue<String> partitionQueue = new ArrayDeque<String>();
ExecutorService executor = Executors.newFixedThreadPool(CONCURRENT_PACKAGE_NUM);
try {
Class.forName(driver);
connection = DriverManager.getConnection(url, user, password);
statement = connection.prepareStatement(sql);
resultSet = statement.executeQuery(sql);
schema = DataTypes.createStructType(getDataTypes(resultSet));
List<Object[]> rows = new ArrayList<Object[]>();
int n = resultSet.getMetaData().getColumnCount();
while (resultSet.next()) {
Object[] rowValue = new Object[n];
for (int index = 1; index <= n; index++){
Object value = resultSet.getObject(index);
if (value instanceof BigInteger) {
rowValue[index - 1] = ((BigInteger) value).longValue();
} else {
rowValue[index - 1] = value;
}
}
rows.add(rowValue);
rowCount++;
if (rowCount > BUFFER_SIZE) {
queue.offer(rows);
//magic value '#'
partitionQueue.offer(baseURI + "/" + partitionStamp +
"/partition#" + rowPartition);
if (rowPartition * BUFFER_SIZE > THRESHOLD) {
while (!queue.isEmpty()) {
transferContents((List<Object[]>) queue.poll(), (String) partitionQueue.poll(), executor);
}
}
rows = new ArrayList<Object[]>();
rowCount = 0;
rowPartition++;
}
}
if (!rows.isEmpty()) {
queue.offer(rows);
partitionQueue.offer(baseURI + "/" + partitionStamp +
"/partition#" + rowPartition);
if (rowPartition * BUFFER_SIZE > THRESHOLD) {
while (!queue.isEmpty()) {
try {
transferContents((List<Object[]>) queue.take(), (String) partitionQueue.poll(), executor);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
// Row row = RowFactory.create(rowValue.toArray());
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
if (resultSet != null)
resultSet.close();
if (statement != null)
statement.close();
if (connection != null)
connection.close();
} catch (SQLException ignored) {
}
}
if (!queue.isEmpty()) {
List<Row> rows = new ArrayList<Row>(queue.size() * rowPartition);
for (List<Object[]> rowSet : queue) {
for (Object[] rowFields : rowSet)
rows.add(RowFactory.create((Object[]) rowFields));
rowSet.clear();
}
return new ResultSetInMemoryWrapper(rows, schema);
} else {
executor.shutdown();
try {
while (!executor.isTerminated())
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return new ResultSetInFileSystemWrapper(baseURI, schema);
}
}
private void transferContents(List<Object[]> rows,
String url,
ExecutorService executor) {
Configuration conf = new Configuration();
String hadoopConfDir = System.getenv("SPARK_HOME") + "/hadoopconf/";
conf.addResource(new Path(hadoopConfDir + "core-site.xml"));
conf.addResource(new Path(hadoopConfDir + "hdfs-site.xml"));
FileSystem fs = null;
try {
fs = FileSystem.get(URI.create("null"), conf);
Path path = new Path(url.substring(0, url.lastIndexOf('/')));
if (!fs.exists(path))
fs.mkdirs(path);
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fs != null) {
try {
fs.close();
} catch (IOException ignored) {}
}
}
executor.execute(new ResultsTransporter(url, rows, conf));
}
public Object execute() throws Exception {
Dataset<Row> tmp;
{
ResultSetWrapper wrapper_tmp = persist("jdbc:mysql://10.200.64.11:3306/db_1?useSSL=false", "name", "password",
"com.mysql.jdbc.Driver", "SELECT `a`.`id`, `b`.`id` FROM `db_1`.`a` AS `a` INNER JOIN `db_2`.`b` AS `b` ON `a`.`id`
= `b`.`id` WHERE `b`.`id` > 10 AND `a`.`id` < 10");
if(wrapper_tmp instanceof ResultSetInMemoryWrapper)
tmp = spark.createDataFrame(((ResultSetInMemoryWrapper) wrapper_tmp).getRows(), wrapper_tmp.getType());
else {
JavaRDD<String> lines = spark.sparkContext()
.textFile(((ResultSetInFileSystemWrapper) wrapper_tmp).getPath(), 100).toJavaRDD();
JavaRDD<Row> rows = lines.map(new SpecificFunction());
tmp = spark.createDataFrame(rows, wrapper_tmp.getType());
}
tmp.createOrReplaceTempView("db_1_a_0");
}
{
ResultSetWrapper wrapper_tmp = persist("jdbc:mysql://10.200.64.11:3306/db_2?useSSL=false", "name", "password",
"com.mysql.jdbc.Driver", "SELECT `a`.`id`, `b`.`id` FROM `db_1`.`a` AS `a` INNER JOIN `db_2`.`b` AS `b` ON `a`.`id`
= `b`.`id` WHERE `b`.`id` > 10 AND `a`.`id` < 10");
if(wrapper_tmp instanceof ResultSetInMemoryWrapper)
tmp = spark.createDataFrame(((ResultSetInMemoryWrapper) wrapper_tmp).getRows(), wrapper_tmp.getType());
else {
JavaRDD<String> lines = spark.sparkContext()
.textFile(((ResultSetInFileSystemWrapper) wrapper_tmp).getPath(), 100).toJavaRDD();
JavaRDD<Row> rows = lines.map(new SpecificFunction());
tmp = spark.createDataFrame(rows, wrapper_tmp.getType());
}
tmp.createOrReplaceTempView("db_2_b_1");
}
String sql = "SELECT a.id, b.id id0 FROM db_1.a INNER JOIN db_2.b ON a.id = b.id WHERE b.id > 10 AND a.id < 10";
tmp = spark.sql(sql);
tmp.show(200);
return null;
}
}
|