TD-SQL-PG版总结
概览
发展历程
- PostGreSQL 在2008年的时候引入,比MySQL要晚了几年
- PG版为 游戏、逛逛、微信等业务提供服务,单机版很快遇到瓶颈
- 2011年开始探索分布式化
- 2013年微信支付商户迁移到了 PG分布式版,从原来手动分库分表,到自动分库分表
- PG版随着公有云一起发展,开始对接外部用户,增加了安全性、列存储、压缩、读写分离、资源隔离等特性
- 截止到2021年,在银行、保险、证券、微信支付、政府、电力都多个行业提供支持
PG版本要解决的问题:
- 方便业务迁移,PG还兼容部分Oracle语法
- 分布式事务一致性
- 服务高可用
- 集群可扩展能力
- 数据安全保证
- HTAP双引擎
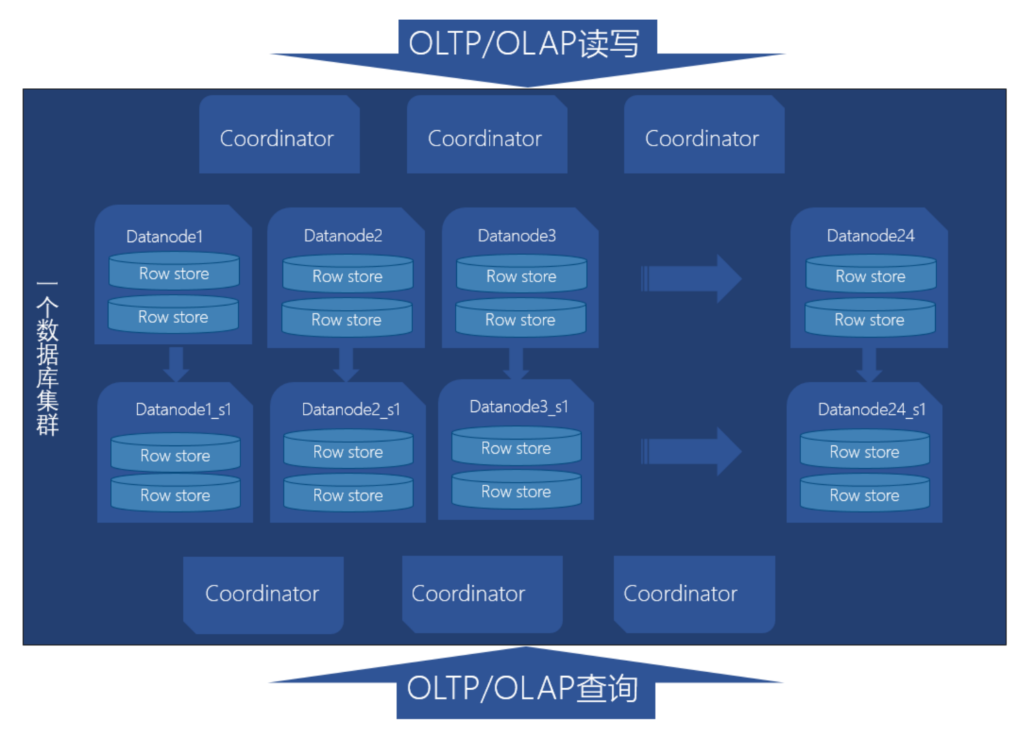
整体架构
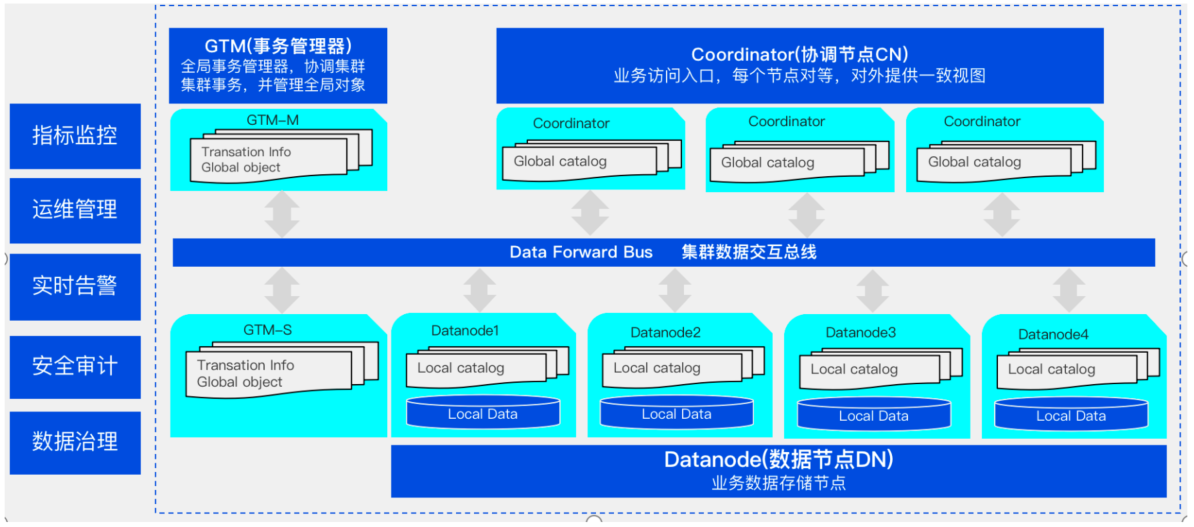
功能介绍
- Coordinator,对外接口,负责数据的分发和查询,多个节点对等,每个节点都提供相同的全局元数据
- DataNode,存储了本地的元数据,和数据分片
- GTM,全局事务管理器,还管理集群的全局对象,如序列等
看起来跟 GreenPlum 有点类似,但多了一个全局事务管理器
产品核心功能
兼容性
兼容大多数 原生PG 的语法,包括查询、外键、触发器、视图、存储过程等
还兼容大部分 Oracle的语法,在源码方面做了改动,支持很多Oracle的函数
实现SQL2011标准
数据类型,支持常规的原生PG类型,还支持
- 自增序列
- 货币
- 几何
- UUID
- Array
- JSON
- Range
接口兼容
- JDBC
- ODBC
- shell
- C
- Python
- PHP
- .NET
语法上的支持
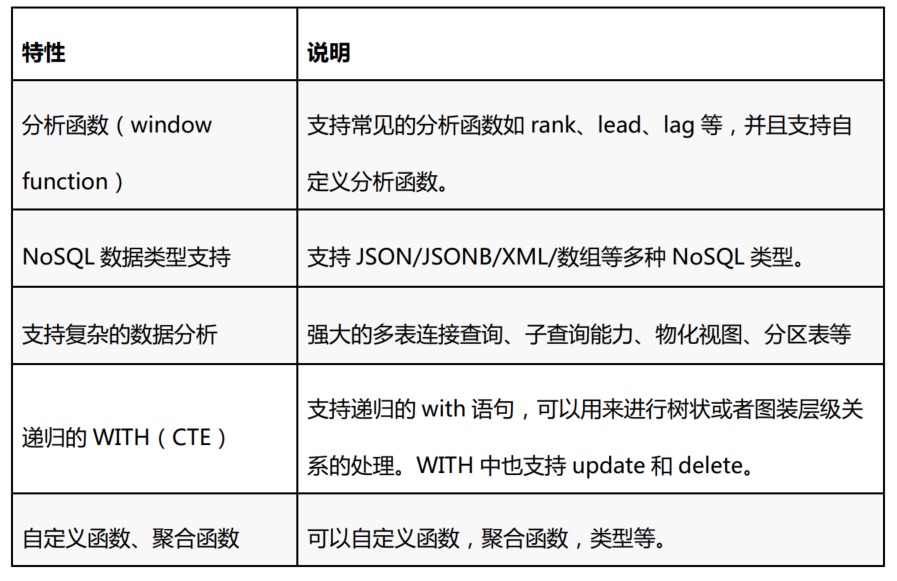
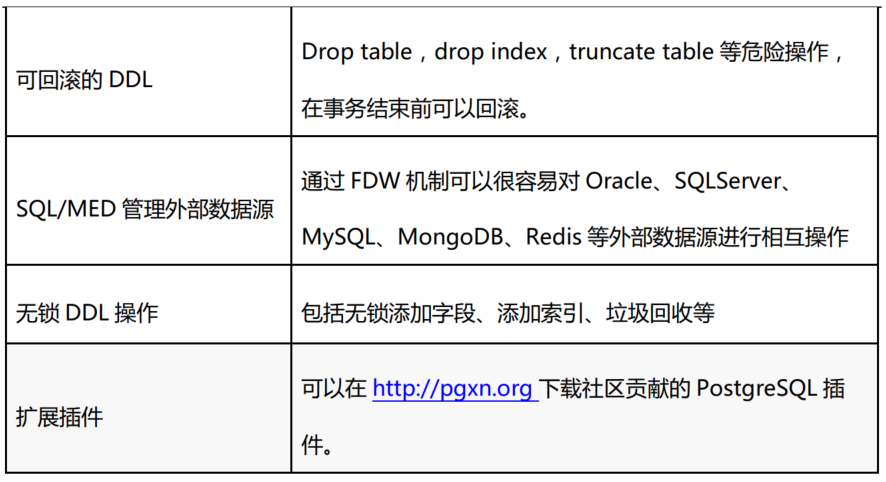
支持存储过程、触发器、自定义函数、视图、物化视图、游标、全局序列、窗口函数、递归cte、全局分布式事务、分布式JOIN。原生支持整数、浮点数、字符、time、date、datetime、bytea(二进制)、数组、Json、Jsonb、XML、uuid、GIS(几何类型点,线,面),复合、范围以及全文搜索等数据类型,支持自定义数据类型。
分布式事务
自研的分布式事务一致性,包括两阶段提交,全局时钟
对GTM的优化
- 网络带宽的优化,取消系统的集群快照,改为逻辑时钟来判断事务的集群可见性,大幅减少对GTM的网络带宽的占用,同时还降低了GTM的CPU占用
- CPU使用率的优化,通过线程资源复用的方式大大减少GTM的线程数据,减少系统调度CPU占用率,大幅的提升GTM的处理效率
- 系统锁的优化,在系统吞吐量达到百万级时GTM原来使用的系统互斥锁占用了绝大多的CPU,我们编写了用户态的互斥锁,使得CPU使用率只有原来的十分之一,提升了系统的处理能力上限
- 免锁队列的使用,使用免锁队列取代原来的带锁队列,减少系统的锁使用,大幅提升系统的处理效率
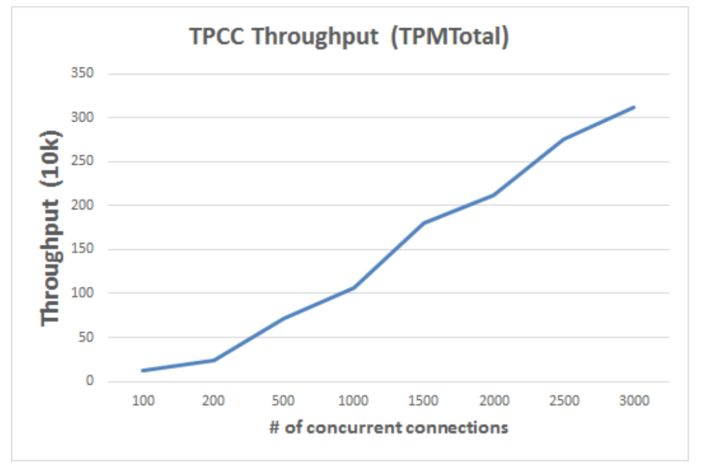
60 台机器的吞吐量
两阶段提交的问题:
- 资源阻塞问题:残留的存在prepare状态的两阶段事务仍然持有一些资源锁,这将会阻塞之后对部分数据的访问和更新操作
- 数据不一致问题:数据不一致问题集中体现在第二阶段的故障场景中。当两阶段提交事务出现了部分commit部分prepare,那么更新数据在部分commit的节点可见;当两阶段提交事务出现了部分commit部分rollback,那么数据在所有节点出现了不可恢复的不一致状态。
- 协调节点宕机问题:当出现协调节点宕机的情况,即便是有做了主备倒换,产生了新的协调节点,参与节点中的异常两阶段事务将一直残留下来
修复方案
- 首先内核处理机制上:这个部分我们做了两件事,第一,在两阶段事务执行过程中记录信息,用于恢复残留两阶段事务;第二, 避免进入“Commit Prepared”的两阶段事务在所有参与节点回滚该事务。
- 其次在异常处理上:TDSQL PostgreSQL版提供了一个两阶段事务的自动处理工具,在系统监测到残留的2PC事务时,运行工具来处理系统的两阶段事务,保证业务的正常运行。通过访问残留两阶段事务的信息,来判断其在各个参与节点中的状态,根据事务的全局状态,我们对其进行异常事务清理,最终使得数据恢复至全局一致状态。
根据 prepared、commit、rollback状态判断的补偿机制
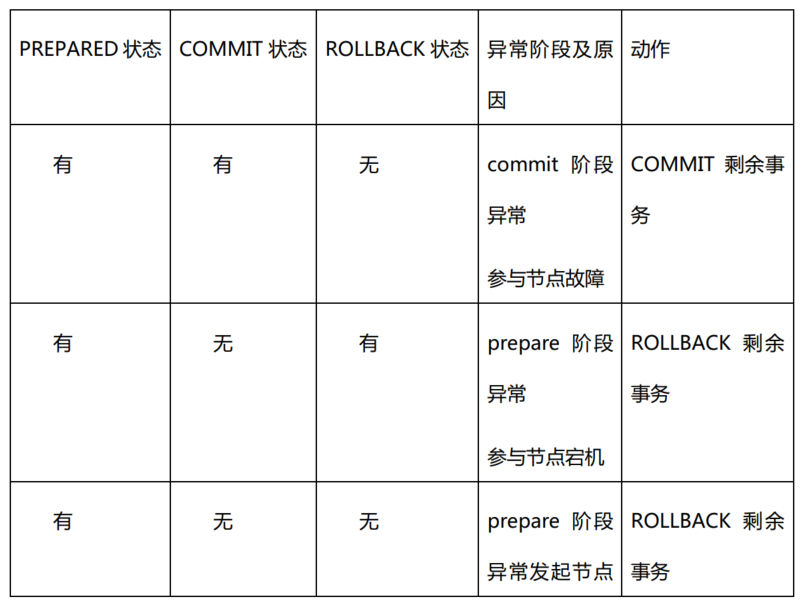
这个检查动作由后台定时器完成
文档中没有提到协调节点故障问题,可能是有超时机制
如果是 commit 阶段,协调节点向所有库发送了commit,3个库有两个返回ack,但一个库因网络问没收到
之后协调节点宕机
那剩余的库是否能处理 残留事务问,文档上没有说怎么实现的
在线扩容
普通的 hash 扩展简单,但是新增/删减机器时会比较麻烦
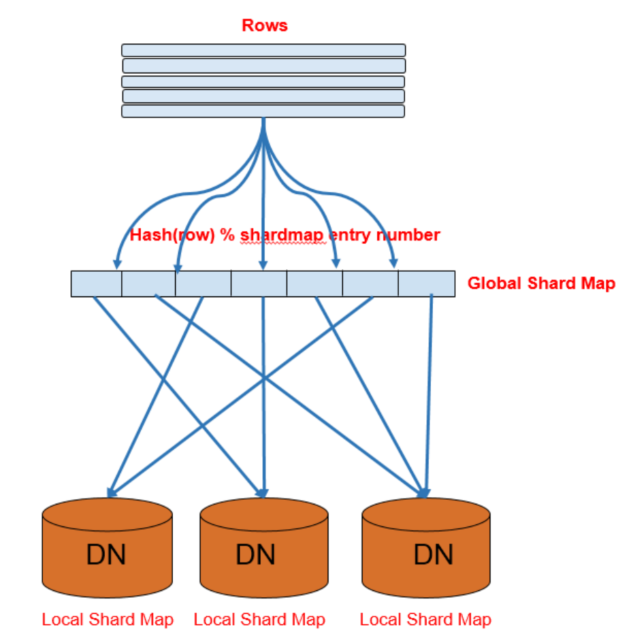 因为 shard-map,它的每一项是<shard-id, data-node> 这种结构
因为 shard-map,它的每一项是<shard-id, data-node> 这种结构
shard-id跟 data-node是一一映射的,通过id就可以找到 data-node
shard-table的记录通过 hash(row) % shard-map entry 来决定存储到哪个shard-id,再通过查询shard-map就可以直到对应的data-node
增减机器时,修改shard-map中的shard-id即可
HTAP
能同时支持 OLTP 和 OLAP
分布式 join实现
假设语句为
|
|
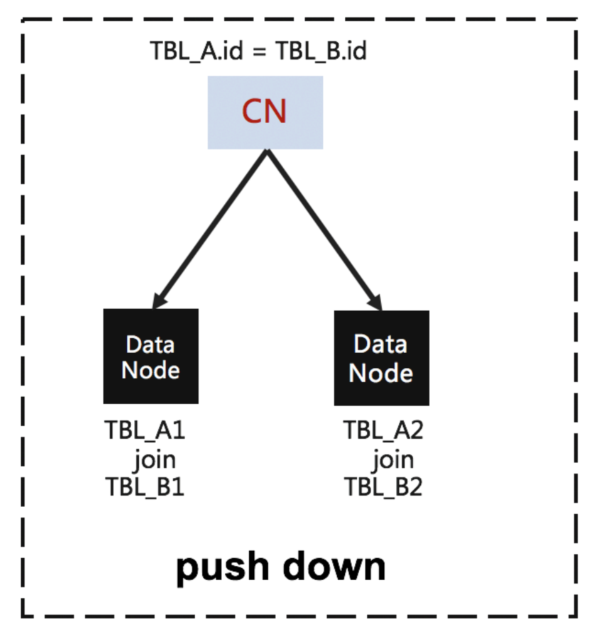
其中 A 表的 id是分布式key,B的id也是分布式key
由于 key 一样,hash后会都会落到同一台机器,所以可以直接下推
如果表很小,可以广播
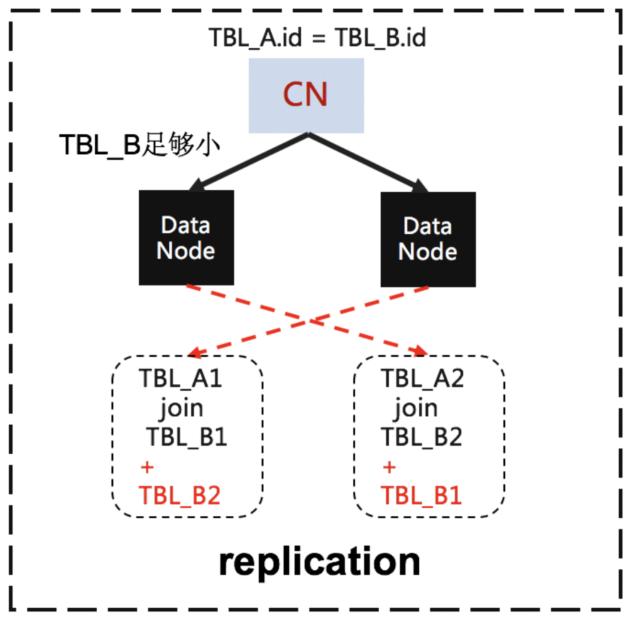
大表join,不可下推,PG版使用数据重分布方式并行查询的
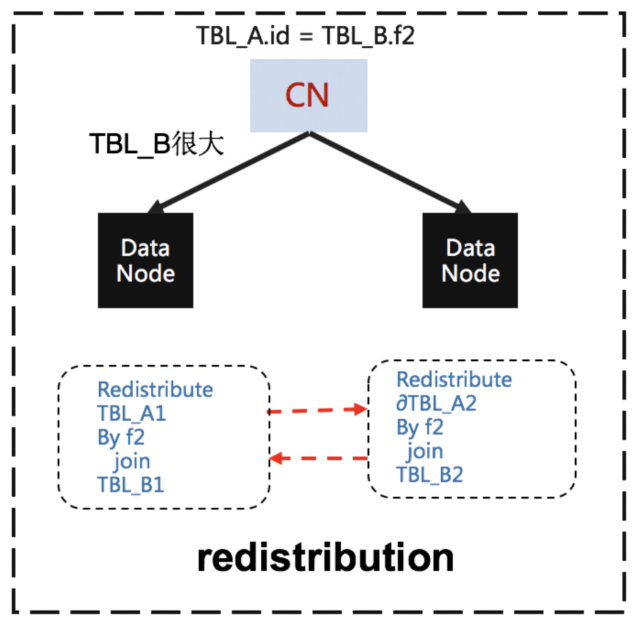
这里文档没有太详细说明,是把 一个节点的数据 -> 另一个节点,保证每个节点都可以在本地做join ?
并行化
PG版本,每个节点根据数据大小,来启动多个进程,并行查询
使用最多的是 join 和 agg
并行版的 hash-join如下:
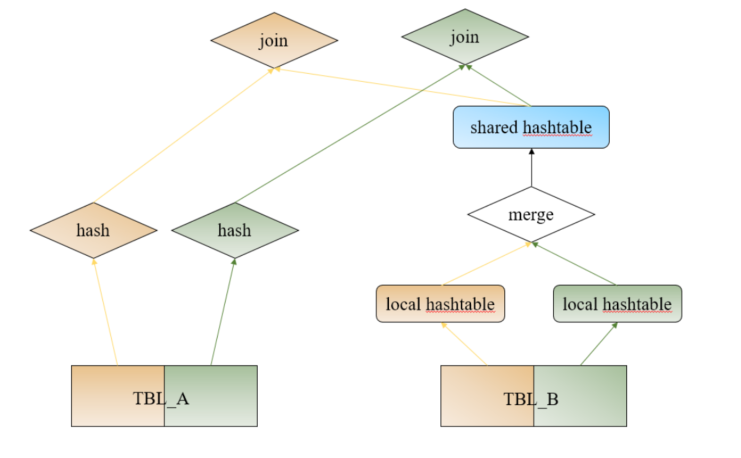
对 B 表会启动两个进程,然后分表构建 hash表,再做合并,变成一个hash表
A表也是两个进程同时查询,再做join的时候,会去共享的hash表中查找
聚合操作并行化
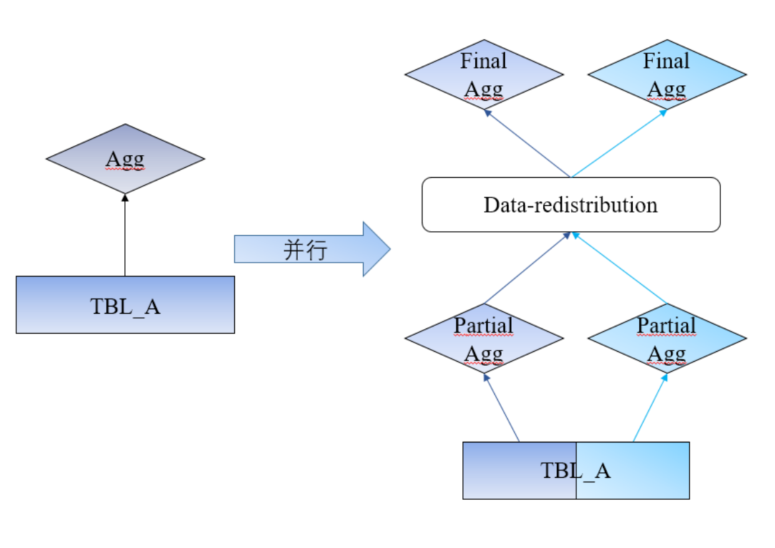
两个进行分别读取 A 表的一部分,然后重新分布,再次group by 聚合,这样就得到了最终数据
支持并行的操作有:
- hash-join
- aggregate
- nest-loop-join
- merge-join
- 并行scan
相关参数:
- 一个查询的最大并行度
- 一个节点的最大并行度
- 一个节点可以启动的最大进程数
多级容灾能力
跟 MySQL 版本类似, PG 版本也有强同步复制,data-node主节点等待 从节点复制完后,才算完成
除了正常的 主从切换外,PG版还支持:
- 故障自动转移,自动在从节点中选主,这是基于强同步复制前提下保证的,不知道有没有用
raft选主 - 支持故障恢复,因磁盘点故障导致数据丢失,DBA可以通过重做备机恢复备机的可靠性;可以选择新的物理节点上添加备机,恢复主从的备份关系,提供系统的可靠性
- 每组主从节点(可以是1主N从), 每个节点都包含完整的数据副本,可以根据DBA需求切换
- 支持手动禁止故障转移
- 支持跨可用区部署,节点的主机和从机可分处于不同机房,数据之间通过专线网络进行实时的数据复制。本地为主机,远程为从机,首先访问本地的节点,若本地实例发生故障或访问不可达,则远程的从机升主提供服务
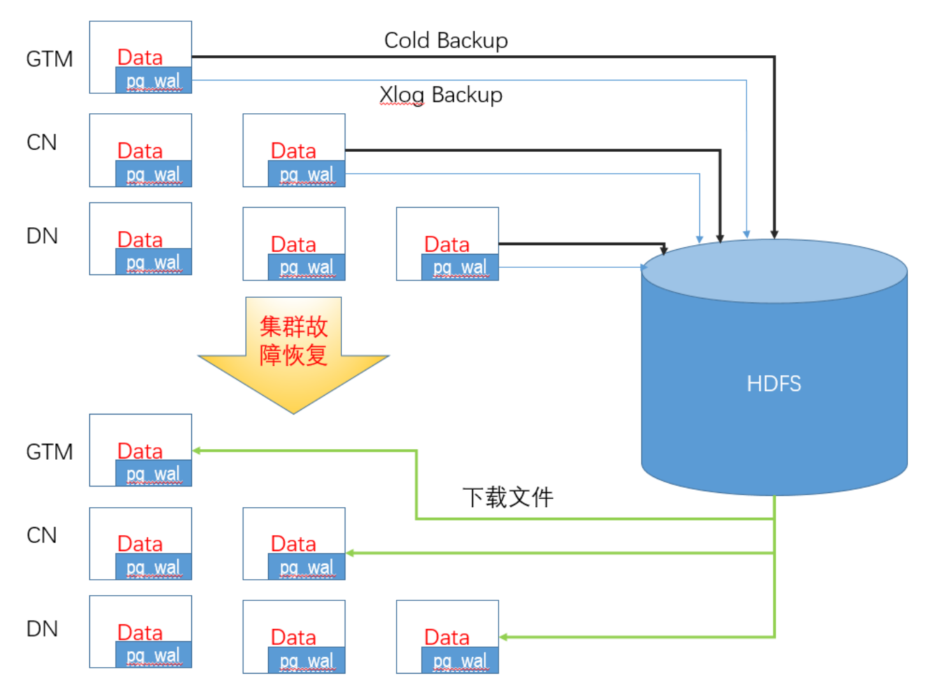
支持 全量、增量备份
读写多平面
协调节点有主备、数据节点也有主备
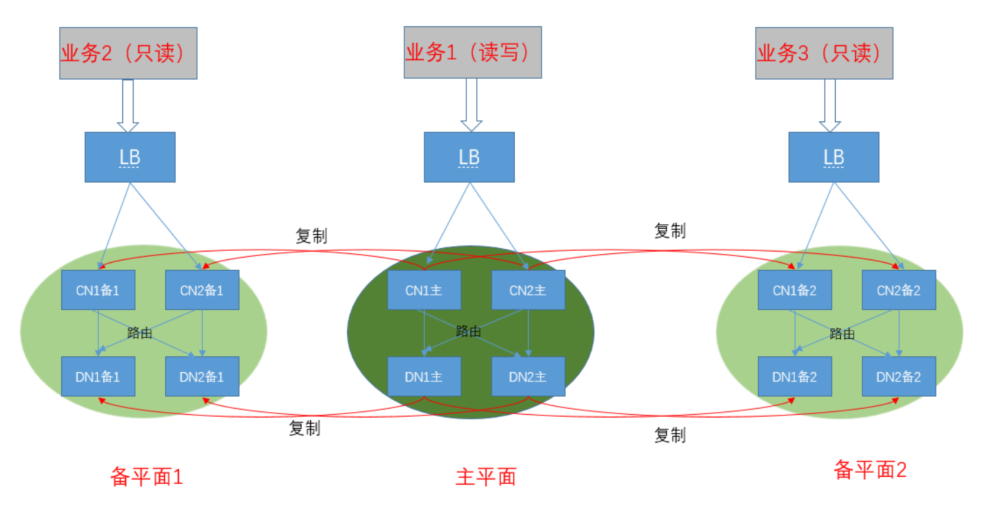
协调主 + 数据主,负责处理 OLTP 的读写业务
协调从 + 数据从,负责处理 OLAP 的只读业务
安全保障
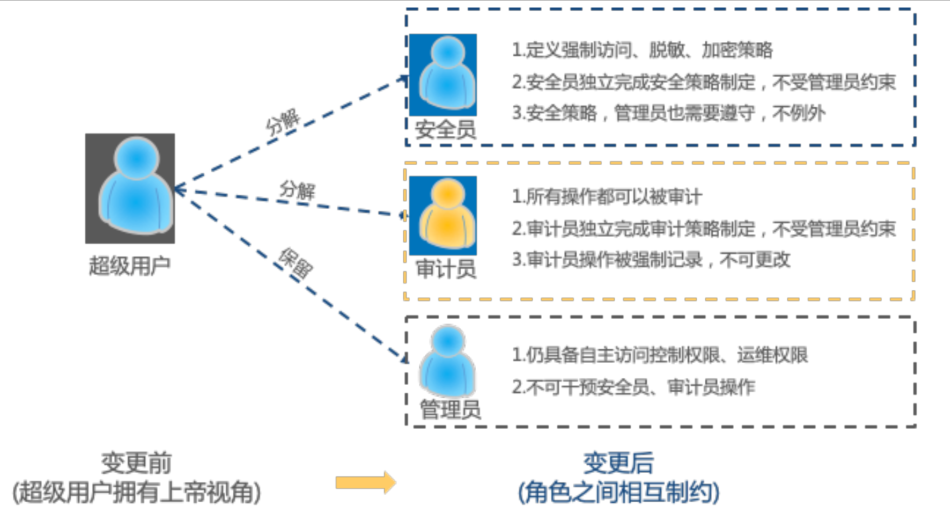
将传统数据库系统DBA的角色分解为三个相互独立的角色,
- 安全管理员
- 审计管理员
- 数据管理员
在此基础上构建安全策略
- 数据加密
- 数据脱敏
- 强制访问控制
安全体系如下:

root 角色分离后结构如下,这个 MySQL 也有
数据加密:
- 提供函数,业务层自己完成
- 内核层自动完成加密,加密策略由安全管理员配置,加密会增加写入/查询时间,但对业务方是透明的
加密级别
- 列加密
- 文件加密
内核实现加密计算时,使用异步加密 目前支持的加密算法:
- AES128
- AES192
- AES256
- 国密SM4
安全管理员可以定义某些字段,做脱敏处理
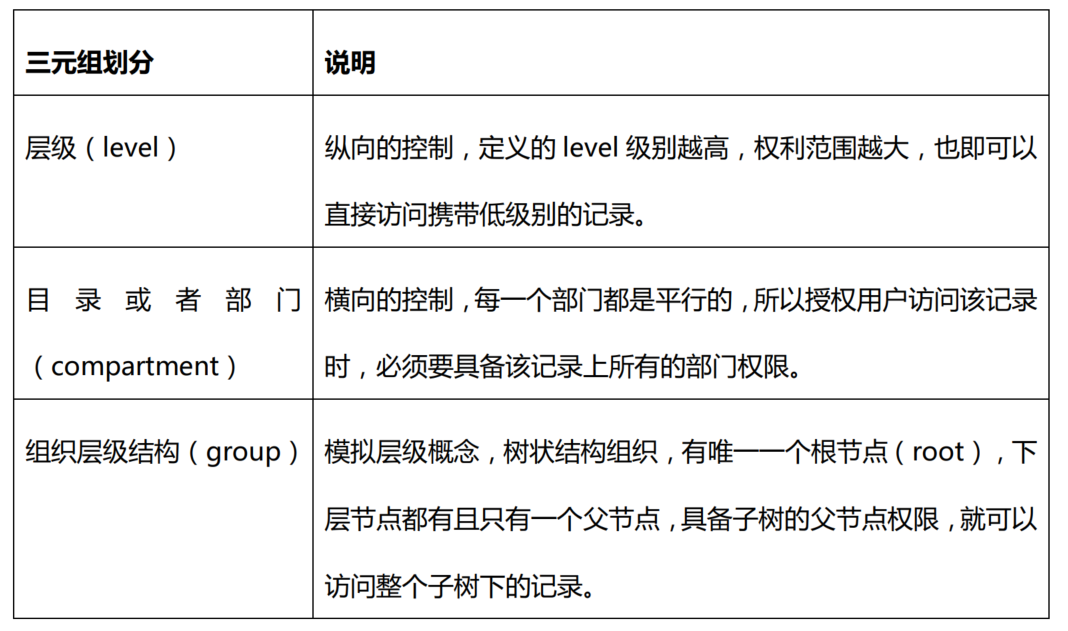
三元组安全访问级别,这个 MySQL 也有
审计包括如下:
- 语句审计,如
audit create view - 对象审计,如
audit alter on jason.tbl_test; - 用户审计,如
audit view by jason - 细粒度审计,可以设计复杂的条件
|
|
数据治理
要解决两个问题
- 数据倾斜问题
- 冷热存储问题
解决数据倾斜,把 data-node 分为group,每个group里面包括一个或者多个data-node
每个group里面有一个shard-map,协调节点可以访问所有group

对于普通用户,还是正常访问,对于大客户,加白名单,通过另一种 hash策略访问
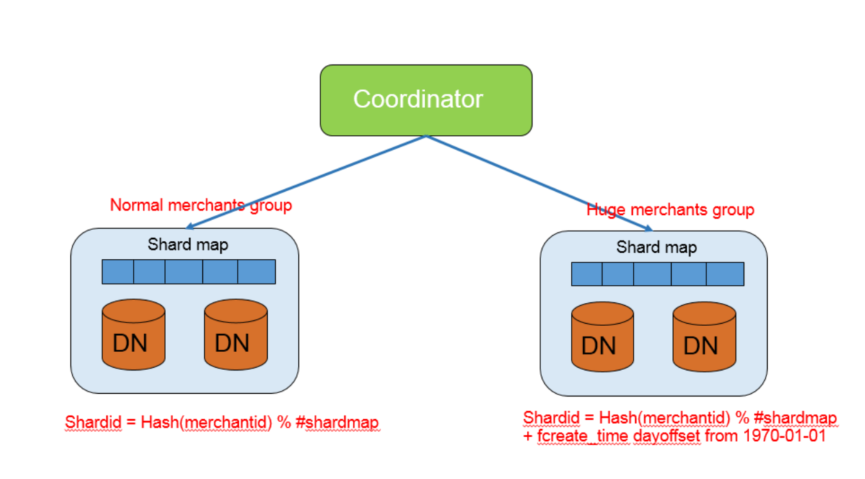
文档中用了京东举了例子,不知道真实场景,京东是不是跑在 PG 集群上
普通用户的:
Shardid = Hash(merchantid) % #shardmap
京东这样的大客户的
Shardid = Hash(merchantid) % #shardmap + fcreate_time dayoffset from 1970-01-01
通过加上时间偏移量,实现同一个用户在group内部多个节点均匀分布
实际处理方式
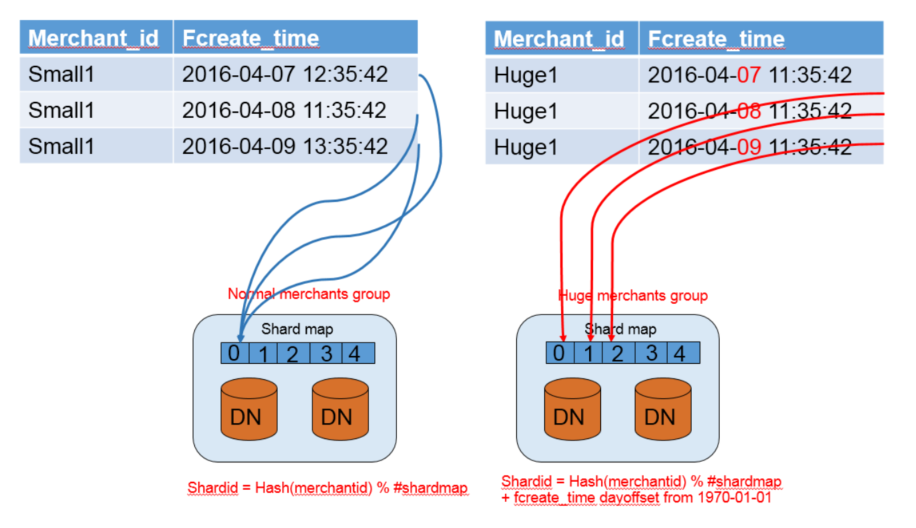
如上,大客户每天都有不同的 shard-id,也就是不同的数据库节点,从而达到在 group 内平衡
内核层应该是做了改动,自动支持冷热分离,对业务无感知
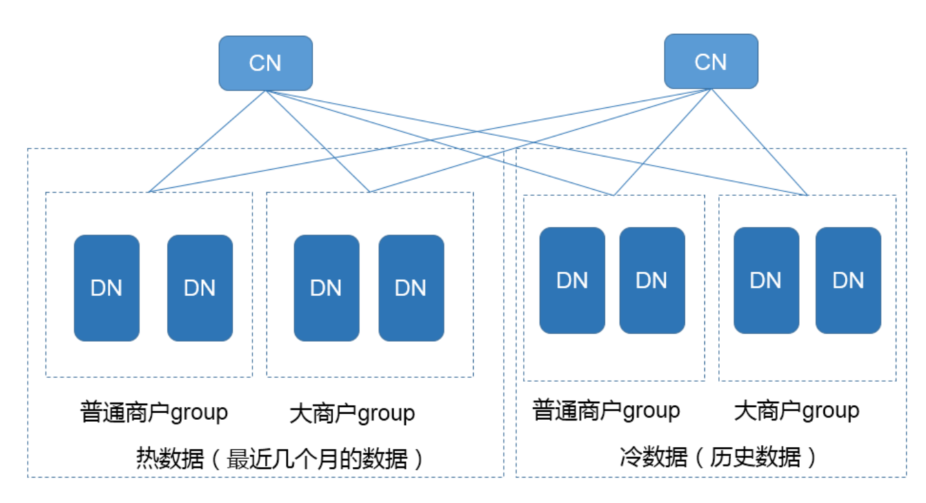
处理逻辑
- 冷热数据使用不同的节点group存储,这些节点组内部使用的物理机型配置不同,从而达到冷热分离节省成本的目的
- 后台的定时任务会根据用户配置的冷热数据规则,自动的进行数据的迁移
运维
PG 版本也用了 OSS系统,这个MySQL也用到了
OSS系统包括:
- 租户管理
- 服务器资源管理
- 项目管理
- 实例监控运维管理
- 指标实时监控、告警
- 部分故障自动修复
- 在线扩容
- 数据搬迁等功能
多租户文档上说将 cpu、内存、磁盘 贵规格切分成多个单元,用到了cgroup
在线扩容,先是全量copy,再增量复制,然后停止对源节点写,再校验,修改路由,完成
这个过程 跟 MySQL 非常类似,可能用的是通用的框架和工具
支持 灰度升级、不停机升级, 这两个MySQL版没有,但也可能是没说,实际是有的
周边生态
使用PostGis插件,支持空间数据库
PostGIS 实现了Open Geospatial Consortium 所提出的基本要素类
(点、线、面、多点、多线、多面等)的SQL实现参考。
PostGIS使用well-known text与well-known binary在数据库中存储空间对象
前者是一种用文本表示空间对象的注记方法
后者是一种用二进制流表示空间对象的存储方法。
DBbridge工具,支持不同数据库,NoSQL之间的同步
数据一致性是用MQ来保证的
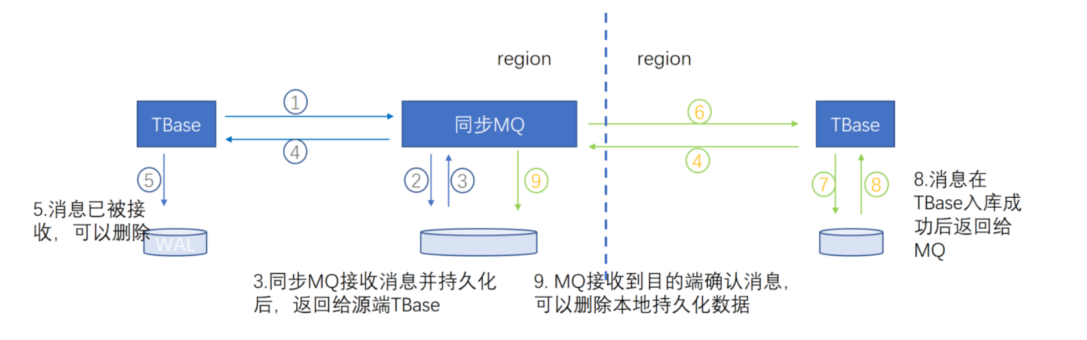
同步方式
- 支持全量同步
- 增量同步
- 定时同步
支持JSON
联邦查询,通过现有插件支持
Foreign Data Wrappers (FDW)。FDW功能提供一套编程接口,用户可以在这上面进行插件式的二次开发,建立外部数据源和数据库间的数据通道。
支持的种类包括:
- Oracle_fdw
- Mysql_fdw
- postgres_fdw
- redis_fdw
- MangoDB_fdw
- hive_fdw
- hdfs_fd
私有云
整体架构跟 公有云的那套差不多
也是全局管理器,协调节点,数据节点
PG版v2相比v1, data-node之间可以相互通信
配置安装
- 全局事务管理节点
- 协调节点
- 数据节点
- OSS
- HDFS(冷备)
每个机器都是 16core、64G、SAS1T盘、万兆网卡
推荐的部署拓扑结构

最小规模部署的拓扑结构
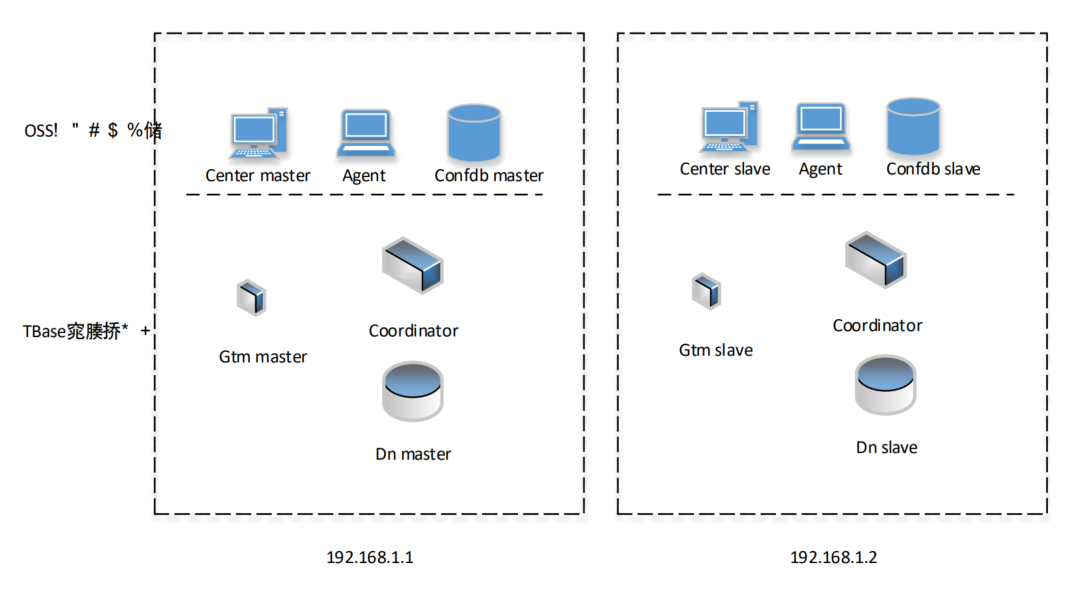
单机房部署
主要需要考虑如下几种故障:
- 交换机、网卡等网络设备的单点故障;
- 机架的电源、风扇等物理设备的故障;
- 物理服务器的磁盘,内存等硬件或者是操作系统等软件的单点故障
部署建议
- 交换机、网卡等网络设备具备容灾能力
- TDSQL PostgreSQL版 core的各个组件,包括GTM,coordinator,datanode等节点都必须采用一主两从的部署模式;其他辅助组件,包括OSS center,confdb等也必须满足一主两从的部署模式
- 同一个组件所在的设备必须跨机架部署
同城双中心部署建议
部署架构
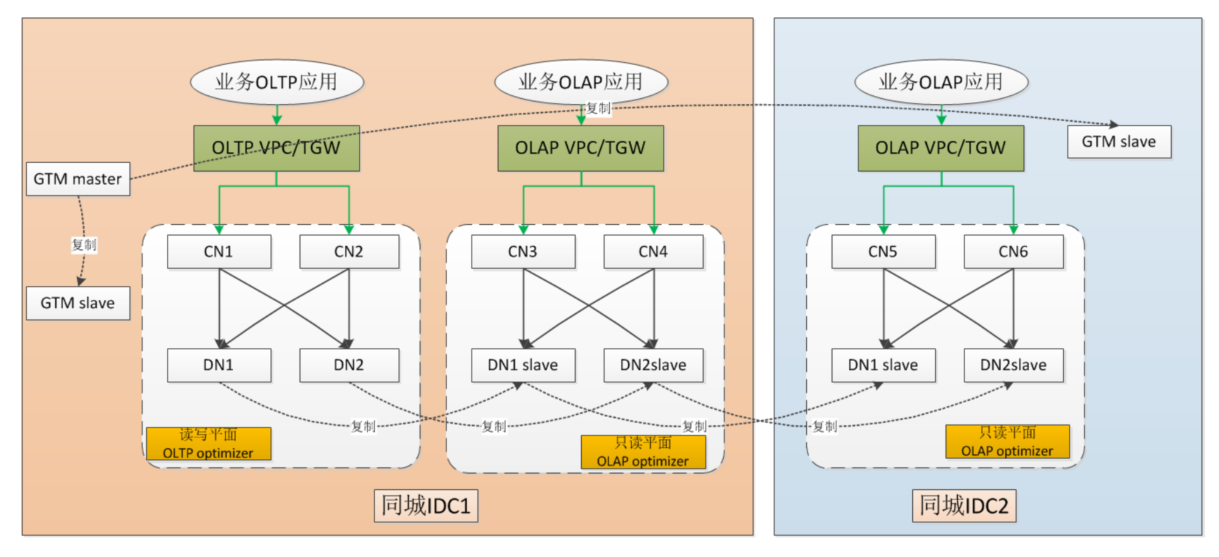 一个机房内 部署两套,另一个同城机房再部署一套
一个机房内 部署两套,另一个同城机房再部署一套
第一个机房内,主的负责 OLTP 业务
从节点负责 OLAP 业务,另一个机房内也负责 OLAP
这里的同步,文档上没有说是否是强同步的
两地三中心部署建议
部署架构如下
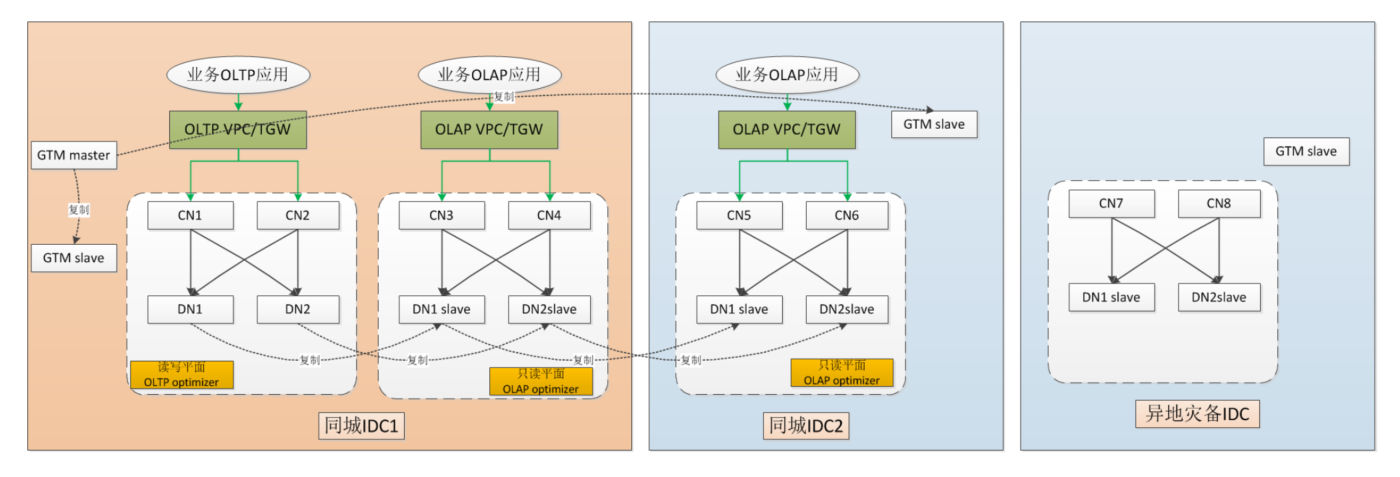 整体看 跟 同城双机房差不多
整体看 跟 同城双机房差不多
异地的机房,也有一套,但不提供服务,只做灾备用
数据应该是通过 异步的方式复制过去的
数据一致性怎么解决,这里没说
和其他 腾讯平台集成
腾讯云TStack(腾讯企业云)诞生于腾讯内部私有云使用场景
基于开源OpenStack进行二次开发,在开源平台上进行大量优化和自主创新,例如对OpenStack单Region规模的调优,对多平台兼容处理和内网级的混合云管理等
TStack跟TD-SQL也有深度集成
TStack主要客户是企业、政府
腾讯云专有云(Tencent Cloud Enterprise, TCE)包括
服务器、网络、存储等IaaS基础组件
同时提供包括云数据库、大数据处理,容器、微服务PaaS相关的组件
TD-SQL跟 TCE也做了深度集成
PG版产品特有优势
HTAP融合,也就是前面介绍的 OLTP 和 OLAP 混合部署
全局分布式事务,引入了全局事务管理器,包括两阶段提交 和 全局时钟(没有详细介绍)
安全策略,root三权分离、数据加密、数据脱敏
运维管理体系
获得的认证
- ITSS 认证
- 金牌等级通过CSA STAR认证,同时获得CNAS和UKAS国内外双认可信息安全管理体系认证
- 信通院分布式事务型数据库、分布式分析型数据库资质认证
- 信创相关集中式、分布式测试
- 自主原创性测试
- 公安部分布式数据库测试
应用场景
HTAP混合,目前有不少实际落地场景
物联网地理信息系统,使用了PostGIS插件
实时高并发事务系统,有6-18等大规模的支付场景
海量存储计算需求,支撑PB级别规模数据,并有冷热存储功能
数据高安全依赖型系统,在 政务、民生、金融 等有使用
去Oracle
多点汇聚业务系统,很多企业以 总部-分部-支部建设,TD-SQL采用异构数据复制来解决
案例
某省办事系统核心OLTP后台系统
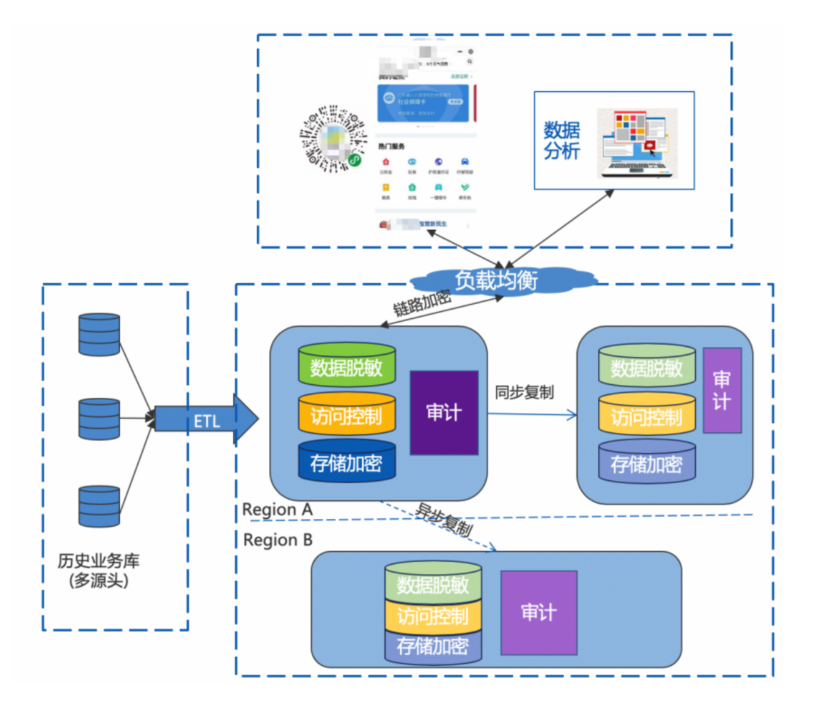
前面一个公众号,一个数据分析后台,通过 LB 到集群
历史业务通过 ETL 灌入集群,加密表有 6000+,采用两地三中心架构
region-a 的主负责处理业务,同region内强同步到 另一个集群,region-b通过异步复制
某省公安厅汇聚库建设
Oracle RAC集群,数据量 300亿,此时已经到极限了,经常超时、宕机,写入速率是 3000条/秒

汇集库在系统中承担着数据汇集处理的作用,既要对接其他关系数据库,消息中间件等,还要运行部分核心系统的OLTP业务,并在这两者数据的基础上运行模型构建,离线行为分析等OLAP类计算。是一个典型的HTAP系统。
做了多平面资源隔离,业务的写入在主平面,查询类请求根据计算复杂度和实时性,分别划分到 备用平面 和 主平面
改造后的结构:
汇集库当前存储量超过145TB,入库效率达到9.8W/s,出库效率6W/s,120亿数据的OLTP类业务1秒内完成处理,每次处理数据5700+条数据
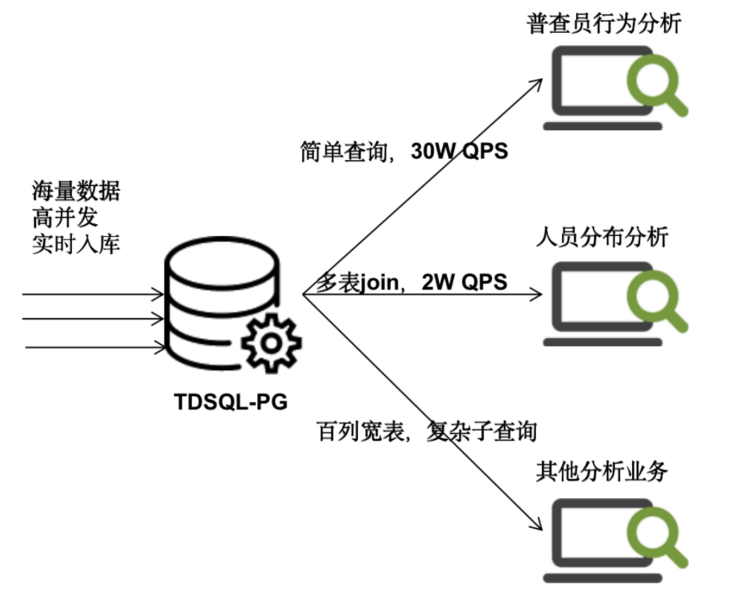
第七次人口普查人口库HTAP业务
从第七次全国人口普查开始第一天起,系统每秒查询率(QPS)就猛增到7万,峰值一举达到了30万左右
大表数据量 20亿+
和泰人寿
利用TDSQL PostgreSQL版的读写平面双平面特性来承载实时交易和订单实时查询需求
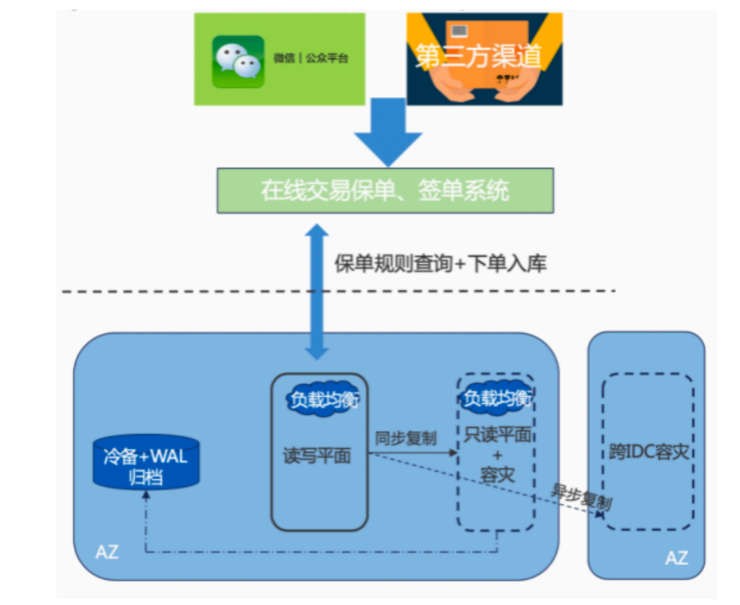
这里使用了 同城双机房做的
东阳人民医院
PG作为数据结构汇聚平台,形成统一的数据出口,供多种分析系统及数据门户使用。
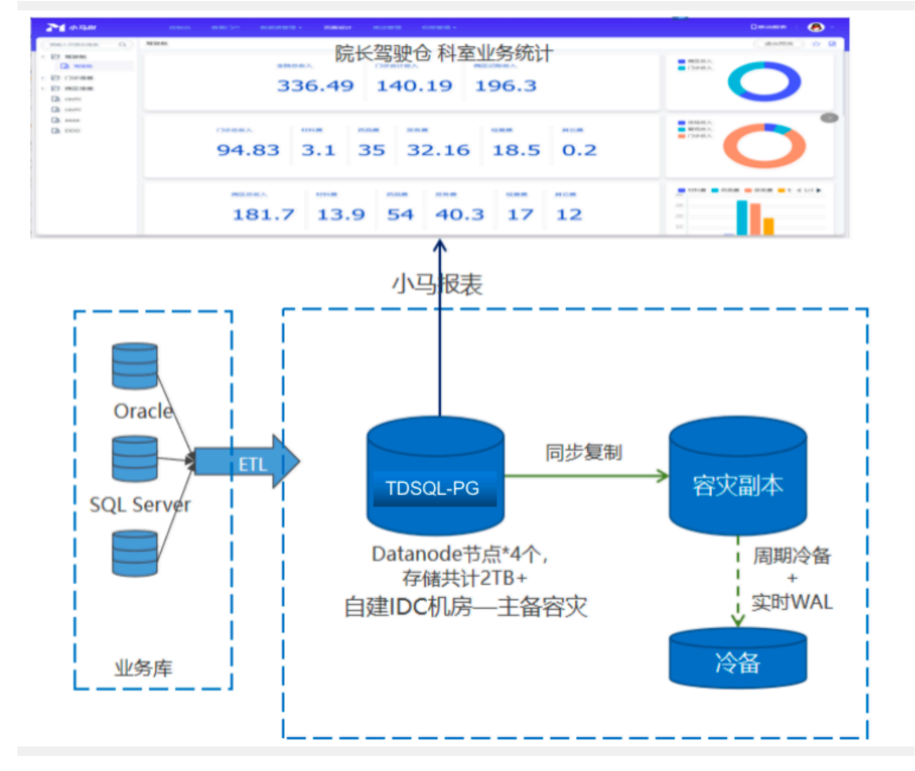
许继电器(智能电表物联应用)
落地于该企业的智能电表监控物联网系统,实时采集所有电表的运行数据以及位置信息,该系统的核心功能是要对地理位置信息进行关联计算和查询,利用了 PostGIS
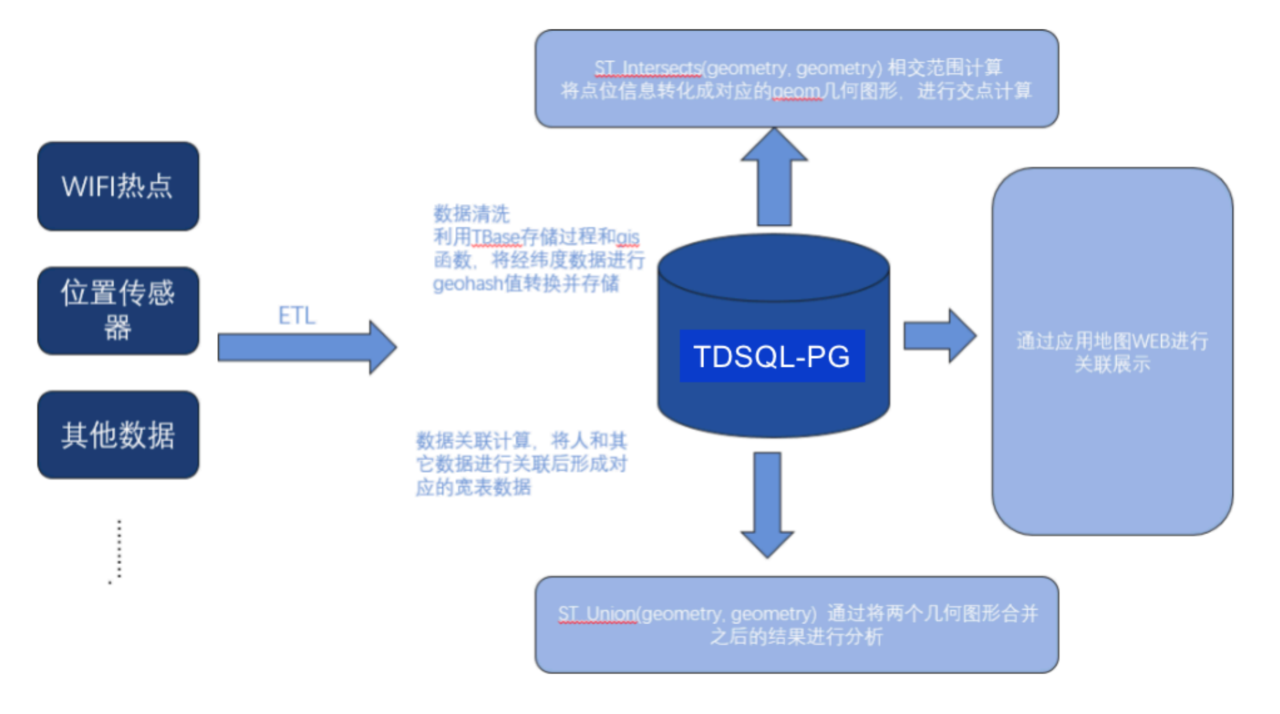
上游对接接业务传感器后端的ETL
数据进入集群后先对清洗变换
把人和位置信息进行关联形成宽表
在宽表的基础上进行GIS OLAP分析
微信支付商户订单系统
该集群于2015年上线,期间经过多次扩容,机房搬迁等
该系统提供微信支付平台的所有商户支付交易订单的实时写入、前端实时查询、离线账单下载,订单退款等多种服务。
目前该集群规模在200个节点,月增数据量200亿,月新增存储为10TB以上
该业务后台数据库一开始采用MySQL加上业务分库分表的模式提供服务
业务规模很大之后,该模式开发复杂度很高,存储成本很高,数据倾斜严重,扩容对业务影响大等
PG版解决方案:
- 大小商户分离
- 冷热数据分离
- 通过在线线性扩容跟随业务的增长平滑扩容集群
- 在容灾上采用跨机房部署
PG版本总结
- 不是简单的开源+插件,而是做了很多源码级改造,改动没有MySQL那么多,但也绝不简单
- 2008年开启,2011年开始分布式化,2013年被微信支付使用,现已用在银行、保险、证券、支付、政府、电力等多个行业
- 整体有点类似GreenPlum,多了全局事务管理,这是很大的改造,修复了两阶段提交的问题,并做了大量性能优化
- 大部分兼容原生PG语法,大部分兼容Oracle,支持SQL2011标准,支持空间数据库,联邦查询
- 通过中间层解决hash扩容/缩容问题,支持自动缩/扩容
- 通过node-group解决数据倾斜问题,支持多种join下推,支持单节点多进程并行查询
- 将root分为安全管理员、审计管理员、系统管理员,内核级加密(支持国密),行、列加密
- 支持内核级别冷热分离(HDFS)、数据倾斜处理,支持多租户、在线扩容、监控、DBbridge异构数据同步等
- HTAP架构,主架构处理OLTP,从架构处理OLAP,这种可以扩展到同城双机房模式
- 微信支付商户集群200个节点,月增数据量200亿+,月新增存储10TB+