几种开源数据库对元数据的管理
背景
想扩展Spark,实现一个自定义的【元数据库】,为实现元数据库,准备参考:
- Hive
- PostgreSQL
- MySQL
这几种的元信息库的表结构
Hive
Hive用的是PG库
下面是Hive元数据的表信息
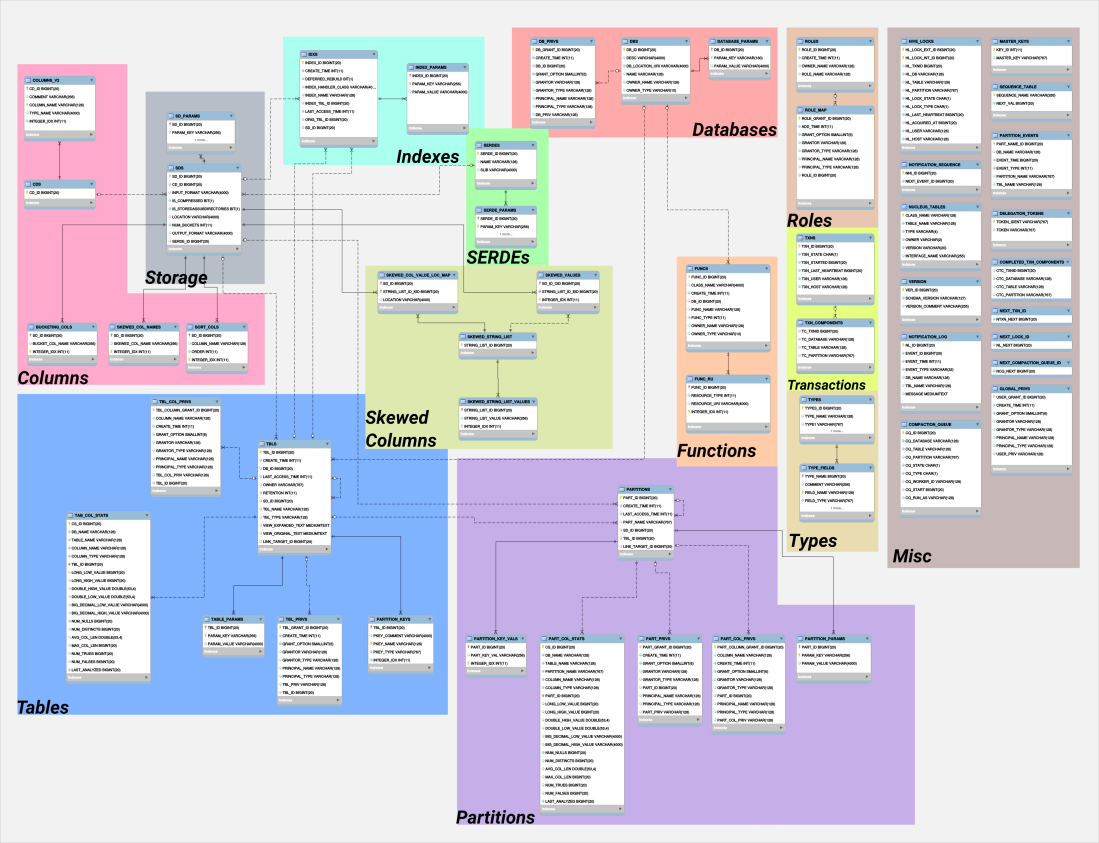
完整的ER图比较大,点击->【这里】 查看完整图
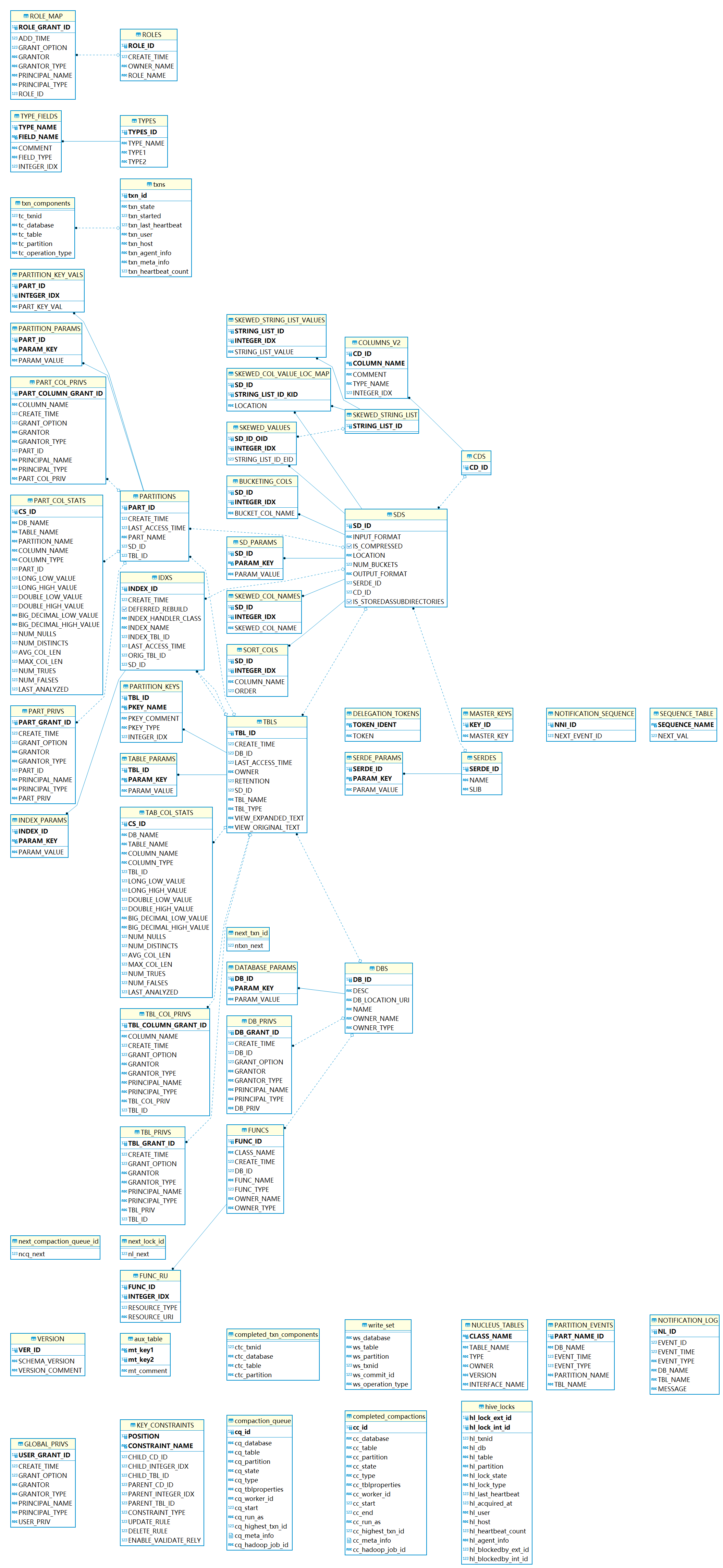{kind=link}
大致分为这么几类:
- 数据库
- 表信息
- 分区
- 函数
- 类型
- 索引
- 存储信息
- 列
- 倾斜列
- SERDE
- 角色
- 杂项
表结构
这里主要列一下 库信息、表信息的定义
数据库表的结构
| 字段 | 解释 |
|---|---|
| DB_ID | 数据库的编号,默认的数据库编号为1,如果创建其他数据库的时候,这个字段会自增,主键 |
| DESC | 对数据库进行一个简单的介绍 |
| DB_LOCATION_URI | 数据库的存放位置,默认是存放在hdfs://ip:9000/user/hive/warehouse,如果是其他数据库,就在后面添加目录,默认位置可以通过参数hive.metastore.warehouse.dir来设置 |
| NAME | 数据库的名称 |
| OWNER_NAME | 数据库所有者名称 |
| OWNER_TYPE | 数据库所有者的类型 |
数据库表对应的参数表
| 字段 | 解释 |
|---|---|
| DB_ID | 数据库的编号 |
| PARAM_KEY | 参数名称 |
| PARAM_VALUE | 参数值 |
表信息
| 字段 | 解释 |
|---|---|
| TBL_ID | 在hive中创建表的时候自动生成的一个id,用来表示,主键 |
| CREATE_TIME | 创建的数据表的时间,使用的是时间戳 |
| DBS_ID | 这个表是在那个数据库里面 |
| LAST_ACCESS_TIME | 最后一次访问的时间戳 |
| OWNER | 数据表的所有者 |
| RETENTION | 保留时间 |
| SD_ID | 标记物理存储信息的id |
| TBL_NAME | 数据表的名称 |
| TBL_TYPE | 数据表的类型,MANAGED_TABLE, EXTERNAL_TABLE, VIRTUAL_VIEW, INDEX_TABLE |
| VIEW_EXPANDED_TEXT | 展开视图文本,非视图为null |
| VIEW_ORIGINAL_TEXT | 原始视图文本,非视图为null |
表信息管理的参数
| 字段 | 解释 |
|---|---|
| TBL_ID | 表id |
| PARAM_KEY | 参数key |
| PARAM_VALUE | 参数value |
参数表内容如下,这里也包含了一些优化方面的参数

还有表的列 stat信息
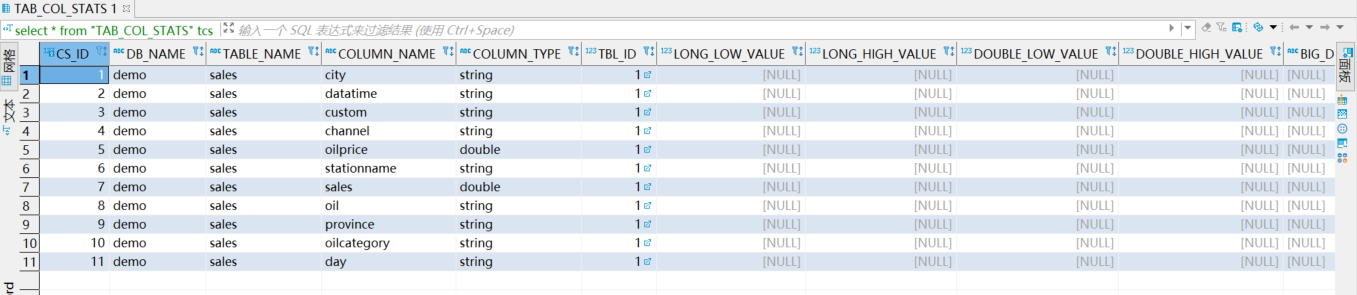

这些主要是做优化用的
结论
Hive的元信息,除了基本的 库、表、索引、函数外
还包含了权限、优化方面的东西
Hive的 库、表都关联了一个参数表,这么设计参数增加起来会很容易,但是参数会很多,quickSql也是这么设计的
可以先实现 库信息、表信息 这两个最主要的
参考
Hive metastore
Hive MetaStore的结构
AdminManual Metastore Administration
HiveMetaStore.pdf
Hive MetaStore数据库表结构
PostgreSQL
用 DBeaver 生成的,图比较大,点击 -> 【这里】
{kind=link}
pg_catalog相关的表和描述如下:
| Catalog Name | Purpose |
|---|---|
| pg_aggregate | aggregate functions |
| pg_am | relation access methods |
| pg_amop | access method operators |
| pg_amproc | access method support functions |
| pg_attrdef | column default values |
| pg_attribute | table columns (“attributes”) |
| pg_authid | authorization identifiers (roles) |
| pg_auth_members | authorization identifier membership relationships |
| pg_cast | casts (data type conversions) |
| pg_class | tables, indexes, sequences, views (“relations”) |
| pg_collation | collations (locale information) |
| pg_constraint | check constraints, unique constraints, primary key constraints, foreign key constraints |
| pg_conversion | encoding conversion information |
| pg_database | databases within this database cluster |
| pg_db_role_setting | per-role and per-database settings |
| pg_default_acl | default privileges for object types |
| pg_depend | dependencies between database objects |
| pg_description | descriptions or comments on database objects |
| pg_enum | enum label and value definitions |
| pg_event_trigger | event triggers |
| pg_extension | installed extensions |
| pg_foreign_data_wrapper | foreign-data wrapper definitions |
| pg_foreign_server | foreign server definitions |
| pg_foreign_table | additional foreign table information |
| pg_index | additional index information |
| pg_inherits | table inheritance hierarchy |
| pg_init_privs | object initial privileges |
| pg_language | languages for writing functions |
| pg_largeobject | data pages for large objects |
| pg_largeobject_metadata | metadata for large objects |
| pg_namespace | schemas |
| pg_opclass | access method operator classes |
| pg_operator | operators |
| pg_opfamily | access method operator families |
| pg_partitioned_table | information about partition key of tables |
| pg_policy | row-security policies |
| pg_proc | functions and procedures |
| pg_publication | publications for logical replication |
| pg_publication_rel | relation to publication mapping |
| pg_range | information about range types |
| pg_replication_origin | registered replication origins |
| pg_rewrite | query rewrite rules |
| pg_seclabel | security labels on database objects |
| pg_sequence | information about sequences |
| pg_shdepend | dependencies on shared objects |
| pg_shdescription | comments on shared objects |
| pg_shseclabel | security labels on shared database objects |
| pg_statistic | planner statistics |
| pg_statistic_ext | extended planner statistics (definition) |
| pg_statistic_ext_data | extended planner statistics (built statistics) |
| pg_subscription | logical replication subscriptions |
| pg_subscription_rel | relation state for subscriptions |
| pg_tablespace | tablespaces within this database cluster |
| pg_transform | transforms (data type to procedural language conversions) |
| pg_trigger | triggers |
| pg_ts_config | text search configurations |
| pg_ts_config_map | text search configurations’ token mappings |
| pg_ts_dict | text search dictionaries |
| pg_ts_parser | text search parsers |
| pg_ts_template | text search templates |
| pg_type | data types |
| pg_user_mapping | mappings of users to foreign servers |
大概分这么几类:
- 访问模式、权限、安全等
- 数据类型
- 库信息
- 表空间
- 表信息、表分区、表的层次关系
- sequence、索引、触发器、函数、存储过程
- 外部数据
- 统计信息
表结构
pg_database 库信息
| 名字 | 类型 | 引用 | 描述 |
|---|---|---|---|
| datname | name | 数据库名字 | |
| datdba | oid | pg_authid.oid | 数据库所有人,通常为其创建者 |
| encoding | int4 | 数据库的字符编码方式(pg_encoding_to_char() 能够将这个数字转换为相应的编码名称) | |
| datistemplate | bool | 如果为真则此数据库可以用于 CREATE DATABASE 的 TEMPLATE 子句,把新数据库创建为此数据库的克隆。 | |
| datallowconn | bool | 如果为假则没有人可以连接到这个数据库。这个字段用于保护 template0 数据库不被更改。 | |
| datconnlimit | int4 | 设置该数据库上允许的最大并发连接数,-1 表示无限制。 | |
| datlastsysoid | oid | 数据库里最后一个系统 OID ;对 pg_dump 特别有用。 | |
| datfrozenxid | xid | 该数据库中中所有在这个之前的事务 ID 已经被一个固定的(“frozen”)事务 ID 替换。这用于跟踪该数据库是否需要为了防止事务 ID 重叠或者允许收缩 pg_clog 而进行清理。它是针对每个表的 pg_class.relfrozenxid 中的最小值。 | |
| dattablespace | oid | pg_tablespace.oid | 该数据库的缺省表空间。在这个数据库里,所有 pg_class.reltablespace 为零的表都将保存在这个表空间里;特别要指出的是,所有非共享的系统表也都存放在这里。 |
| datconfig | text[] | 运行时配置变量的会话缺省值 | |
| datacl | aclitem[] | 访问权限,参阅 GRANT 和 REVOKE 获取详细描述。 |

pg_class 表信息
| 名字 | 类型 | 引用 | 描述 |
|---|---|---|---|
| relname | name | 表、索引、视图等的名字。 | |
| relnamespace | oid | pg_namespace.oid | 包含这个关系的名字空间(模式)的 OID |
| reltype | oid | pg_type.oid | 对应这个表的行类型的数据类型(索引为零,它们没有 pg_type 记录)。 |
| relowner | oid | pg_authid.oid | 关系所有者 |
| relam | oid | pg_am.oid | 如果行是索引,那么就是所用的访问模式(B-tree, hash 等等) |
| relfilenode | oid | 这个关系在磁盘上的文件的名字,如果没有则为 0 | |
| reltablespace | oid | pg_tablespace.oid | 这个关系存储所在的表空间。如果为零,则意味着使用该数据库的缺省表空间。如果关系在磁盘上没有文件,则这个字段没有什么意义。 |
| relpages | int4 | 以页(大小为 BLCKSZ)的此表在磁盘上的形式的大小。它只是规划器用的一个近似值,是由 VACUUM, ANALYZE 和几个 DDL 命令,比如 CREATE INDEX 更新。 | |
| reltuples | float4 | 表中行的数目。只是规划器使用的一个估计值,由 VACUUM, ANALYZE 和几个 DDL 命令,比如 CREATE INDEX 更新。 | |
| reltoastrelid | oid | pg_class.oid | 与此表关联的 TOAST 表的 OID ,如果没有为 0 。TOAST 表在一个从属表里"离线"存储大字段。 |
| reltoastidxid | oid | pg_class.oid | 对于 TOAST 表是它的索引的 OID ,如果不是 TOAST 表则为 0 |
| relhasindex | bool | 如果它是一个表而且至少有(或者最近有过)一个索引,则为真。它是由 CREATE INDEX 设置的,但 DROP INDEX 不会立即将它清除。如果 VACUUM 现一个表没有索引,那么它将清理 relhasindex 。 | |
| relisshared | bool | 如果该表在整个集群中由所有数据库共享则为真。只有某些系统表(比如 pg_database)是共享的。 | |
| relkind | char | r = 普通表, i = 索引, S = 序列, v = 视图, c = 复合类型, t = TOAST 表 | |
| relnatts | int2 | 关系中用户字段数目(除了系统字段以外)。在 pg_attribute 里肯定有相同数目对应行。又见 pg_attribute.attnum | |
| relchecks | int2 | 表里的检查约束的数目;参阅 pg_constraint 表 | |
| reltriggers | int2 | 表里的触发器的数目;参阅 pg_trigger 表 | |
| relukeys | int2 | 未使用(不是唯一值的数目) | |
| relfkeys | int2 | 未使用(不是表中外键的数目) | |
| relrefs | int2 | 未使用 | |
| relhasoids | bool | 如果为关系中每行都生成一个 OID 则为真 | |
| relhaspkey | bool | 如果这个表有一个(或者曾经有一个)主键,则为真。 | |
| relhasrules | bool | 如表有规则就为真;参阅 pg_rewrite 表 | |
| relhassubclass | bool | 如果有(或者曾经有)任何继承的子表,为真。 | |
| relfrozenxid | xid | 该表中所有在这个之前的事务 ID 已经被一个固定的(“frozen”)事务 ID 替换。这用于跟踪该表是否需要为了防止事务 ID 重叠或者允许收缩 pg_clog 而进行清理。如果该关系不是表则为零(InvalidTransactionId)。 | |
| relacl | aclitem[] | 访问权限。参阅 GRANT 和 REVOKE 获取详细信息。 | |
| reloptions | text[] | 访问方法特定的选项,使用"keyword=value"格式的字符串 |


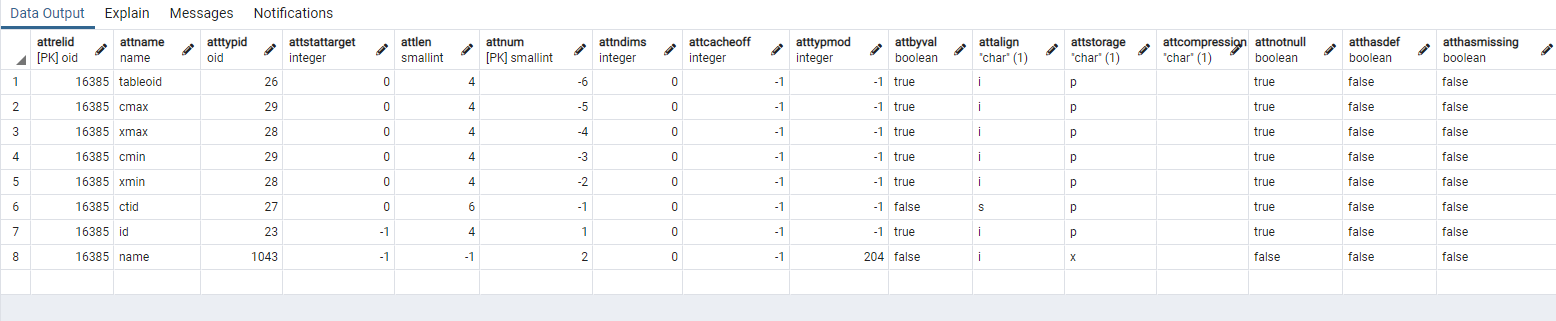
pg_attribute 字段信息
| 名字 | 类型 | 引用 | 描述 |
|---|---|---|---|
| attrelid | oid | pg_class.oid | 此字段所属的表 |
| attname | name | 字段名字 | |
| atttypid | oid | pg_type.oid | 这个字段的数据类型 |
| attstattarget | int4 | 控制 ANALYZE 为这个字段积累的统计细节的级别。零值表示不收集统计信息。负数表示使用系统缺省的统计对象。正数值的确切信息是和数据类型相关的。对于标量数据类型,attstattarget 既是要收集的"最常用数值"的目标数目,也是要创建的柱状图的目标数量。 | |
| attlen | int2 | 是本字段类型的 pg_type.typlen 的拷贝 | |
| attnum | int2 | 字段数目。普通字段是从 1 开始计数的。系统字段(比如 oid)有(任意)正数。 | |
| attndims | int4 | 如果该字段是数组,那么是维数,否则是 0 。目前,一个数组的维数并未强制,因此任何非零值都表示"这是一个数组"。 | |
| attcacheoff | int4 | 在磁盘上的时候总是 -1 ,但是如果加载入内存中的行描述器中,它可能会被更新以缓冲在行中字段的偏移量。 | |
| atttypmod | int4 | 记录创建新表时支持的类型特定的数据(比如一个 varchar 字段的最大长度)。它传递给类型相关的输入和长度转换函数当做第三个参数。其值对那些不需要 atttypmod 的类型通常为 -1 。 | |
| attbyval | bool | 这个字段类型的 pg_type.typbyval 的拷贝。 | |
| attstorage | char | 这个字段的类型的 pg_type.typstorage 的拷贝。对于可压缩的数据类型(TOAST),这个字段可以在字段创建之后改变,以便于控制存储策略。 | |
| attalign | char | 这个字段类型的 pg_type.typalign 的拷贝 | |
| attnotnull | bool | 这代表一个非空约束。可以改变这个字段以打开或者关闭这个约束。 | |
| atthasdef | bool | 这个字段有一个缺省值,此时它对应 pg_attrdef 表里实际定义此值的记录。 | |
| attisdropped | bool | 这个字段已经被删除了,不再有效。一个已经删除的字段物理上仍然存在表中,但会被分析器忽略,因此不能再通过 SQL 访问。 | |
| attislocal | bool | 这个字段是局部定义在关系中的。请注意一个字段可以同时是局部定义和继承的。 | |
| attinhcount | int4 | 这个字段所拥有的直接祖先的个数。如果一个字段的祖先个数非零,那么它就不能被删除或重命名。 |
外部表
包含三个表:
- pg_foreign_data_wrapper
- pg_foreign_server
- pg_foreign_table
表结构如下:
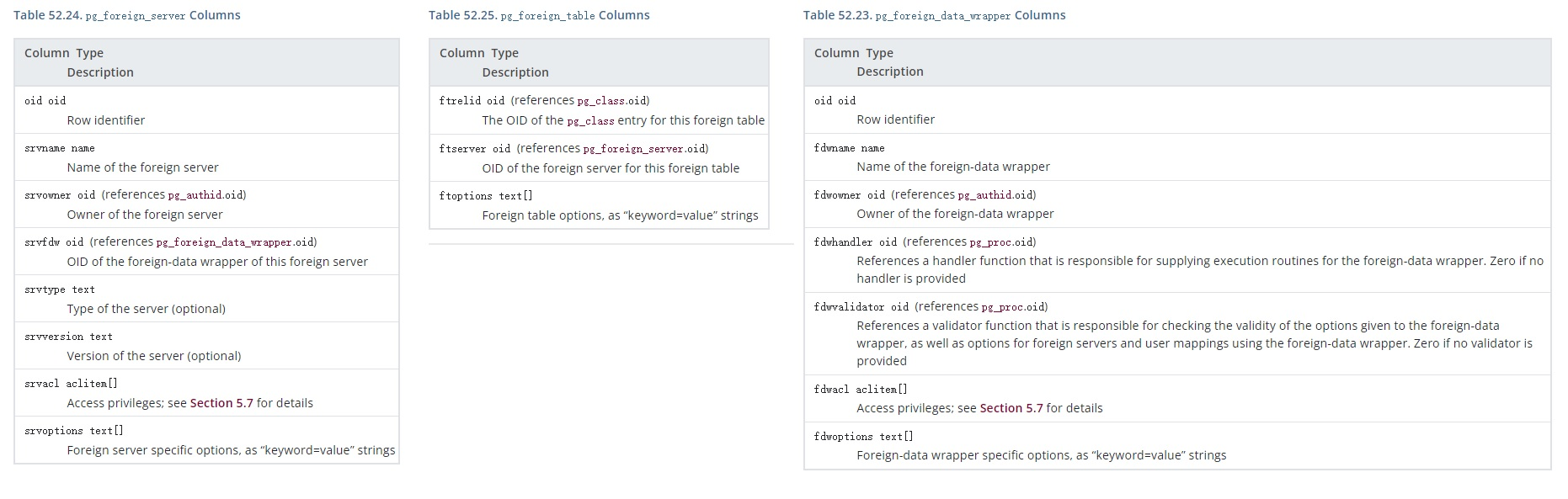
结论
PG的库、表、字段信息跟Hive一样,也包含了权限认证方面的东西
此外还有很多PG自己的东西,比如
- 库信息:模板库,库的最大连接,清理标记
- 表信息:表空间、索引类型、页大小、表类型(普通表、索引、序列、视图),统计信息
- 字段信息:字段类型、字段数目、压缩情况、缺省值、约束、统计信息
基本是包含了很多存储细节、优化信息,数据是PG自己管理的,所以它可以这么存
如果是外部表,可以更多参考Hive的实现,内部表可以参考PG的
参考
pg_catalog Overview
System Catalogs
PG文档
MySQL
E-R图如下:
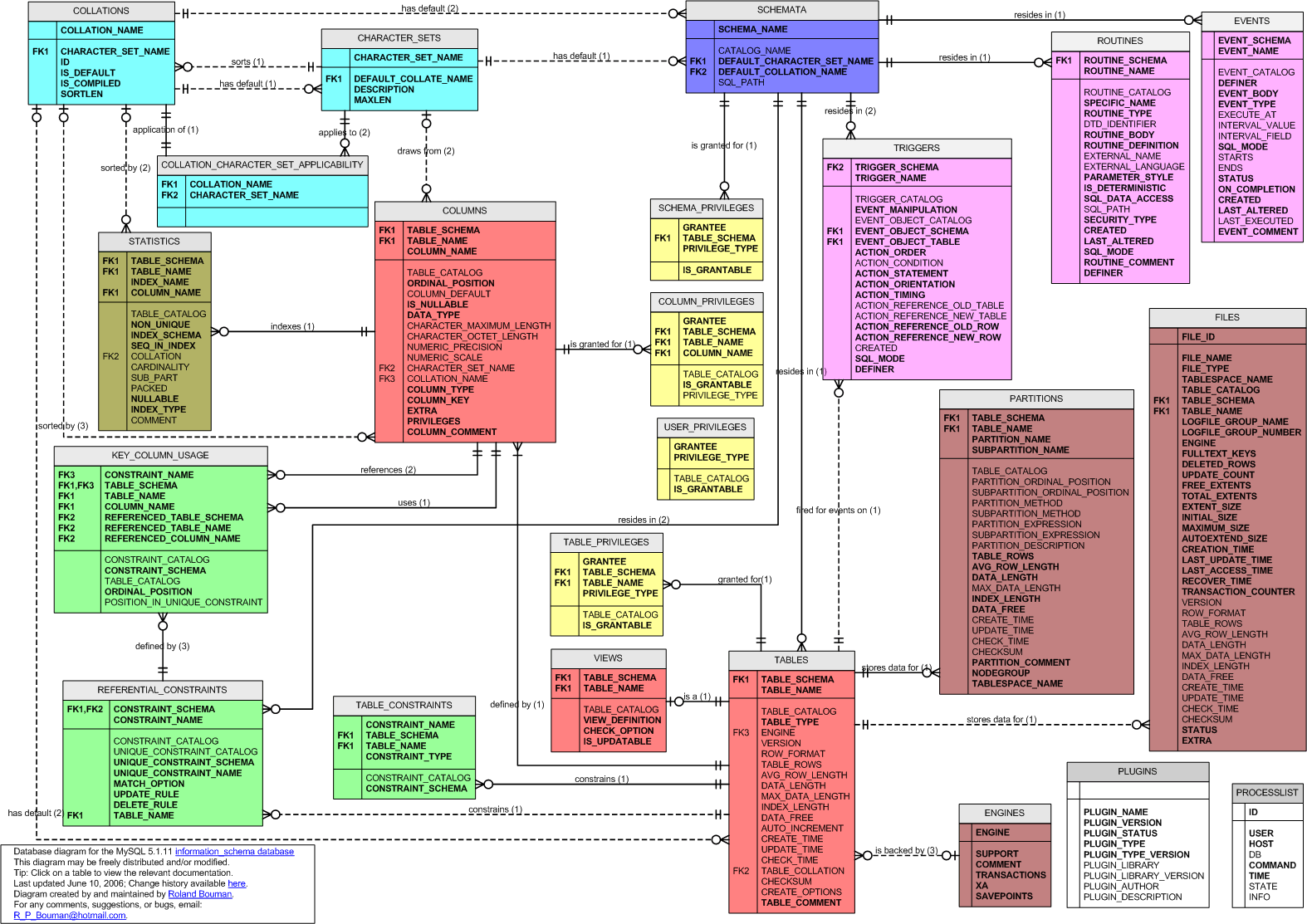
大致分为这么几类:
- 字符集和排序规则相关
- 权限相关
- 库、表、字段、以及表空间、分区和相关参数
- 视图、存储过程、触发器、函数和相关参数
- 约束、外键等
- 全局状态和变量、session状态和变量、processlist等
- 插件、引擎、存储空间
- InnoDB相关参数
表结构
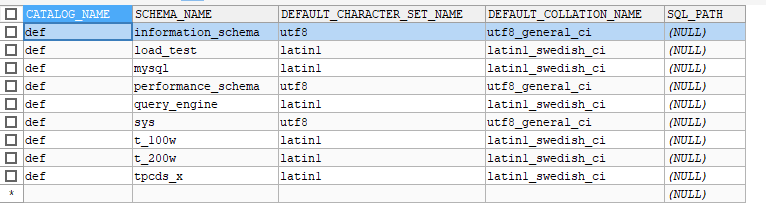
库信息表结构
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| CATALOG_NAME | varchar(512) | NO | |||
| SCHEMA_NAME | varchar(64) | NO | |||
| DEFAULT_CHARACTER_SET_NAME | varchar(32) | NO | |||
| DEFAULT_COLLATION_NAME | varchar(32) | NO | |||
| SQL_PATH | varchar(512) | YES | NULL |
Table信息表结构
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| TABLE_CATALOG | varchar(512) | NO | |||
| TABLE_SCHEMA | varchar(64) | NO | |||
| TABLE_NAME | varchar(64) | NO | |||
| TABLE_TYPE | varchar(64) | NO | |||
| ENGINE | varchar(64) | YES | NULL | ||
| VERSION | bigint(21) unsigned | YES | NULL | ||
| ROW_FORMAT | varchar(10) | YES | NULL | ||
| TABLE_ROWS | bigint(21) unsigned | YES | NULL | ||
| AVG_ROW_LENGTH | bigint(21) unsigned | YES | NULL | ||
| DATA_LENGTH | bigint(21) unsigned | YES | NULL | ||
| MAX_DATA_LENGTH | bigint(21) unsigned | YES | NULL | ||
| INDEX_LENGTH | bigint(21) unsigned | YES | NULL | ||
| DATA_FREE | bigint(21) unsigned | YES | NULL | ||
| AUTO_INCREMENT | bigint(21) unsigned | YES | NULL | ||
| CREATE_TIME | datetime | YES | NULL | ||
| UPDATE_TIME | datetime | YES | NULL | ||
| CHECK_TIME | datetime | YES | NULL | ||
| TABLE_COLLATION | varchar(32) | YES | NULL | ||
| CHECKSUM | bigint(21) unsigned | YES | NULL | ||
| CREATE_OPTIONS | varchar(255) | YES | NULL | ||
| TABLE_COMMENT | varchar(2048) | NO |

列信息表结构
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| TABLE_CATALOG | varchar(512) | NO | |||
| TABLE_SCHEMA | varchar(64) | NO | |||
| TABLE_NAME | varchar(64) | NO | |||
| COLUMN_NAME | varchar(64) | NO | |||
| ORDINAL_POSITION | bigint(21) unsigned | NO | 0 | ||
| COLUMN_DEFAULT | longtext | YES | NULL | ||
| IS_NULLABLE | varchar(3) | NO | |||
| DATA_TYPE | varchar(64) | NO | |||
| CHARACTER_MAXIMUM_LENGTH | bigint(21) unsigned | YES | NULL | ||
| CHARACTER_OCTET_LENGTH | bigint(21) unsigned | YES | NULL | ||
| NUMERIC_PRECISION | bigint(21) unsigned | YES | NULL | ||
| NUMERIC_SCALE | bigint(21) unsigned | YES | NULL | ||
| DATETIME_PRECISION | bigint(21) unsigned | YES | NULL | ||
| CHARACTER_SET_NAME | varchar(32) | YES | NULL | ||
| COLLATION_NAME | varchar(32) | YES | NULL | ||
| COLUMN_TYPE | longtext | NO | NULL | ||
| COLUMN_KEY | varchar(3) | NO | |||
| EXTRA | varchar(30) | NO | |||
| PRIVILEGES | varchar(80) | NO | |||
| COLUMN_COMMENT | varchar(1024) | NO | |||
| GENERATION_EXPRESSION | longtext | NO | NULL |


结论
MySQL的元数据,抛开数据库独有的部分,大体上跟PG差不多,只是多了InnoDB相关的信息
参考
A Diagram of the MySQL information schema
Introduction information schema
INFORMATION_SCHEMA Table Reference
ER-DIAGRAM OF THE INNODB DATA DICTIONARY
INFORMATION_SCHEMA Tables
MySQL 5.7 INFORMATION_SCHEMA 详解
MySQL information_schema 详解