语法解析
入口点是 SparkSession#sql 函数
1
2
3
4
5
6
7
|
def sql(sqlText: String): DataFrame = withActive {
val tracker = new QueryPlanningTracker
val plan = tracker.measurePhase(QueryPlanningTracker.PARSING) {
sessionState.sqlParser.parsePlan(sqlText)
}
Dataset.ofRows(self, plan, tracker)
}
|
其中sessionState.sqlParser.parsePlan(sqlText)对文本内容做解析,得到的就是 一颗语法树,具体实现在 AbstractSqlParser
解析如下,这里是将SqlBaseParser 转为LogicalPlan
也就是将 ANTLR 的语法树,转为 Spark 的语法树
1
2
3
4
5
6
7
8
|
override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) { parser =>
astBuilder.visitSingleStatement(parser.singleStatement()) match {
case plan: LogicalPlan => plan
case _ =>
val position = Origin(None, None)
throw QueryParsingErrors.sqlStatementUnsupportedError(sqlText, position)
}
}
|
其中 parse() 就是解析过程,这是调用 ANTLR 去做的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
protected def parse[T](command: String)(toResult: SqlBaseParser => T): T = {
logDebug(s"Parsing command: $command")
val lexer = new SqlBaseLexer(new UpperCaseCharStream(CharStreams.fromString(command)))
lexer.removeErrorListeners()
lexer.addErrorListener(ParseErrorListener)
val tokenStream = new CommonTokenStream(lexer)
val parser = new SqlBaseParser(tokenStream)
parser.addParseListener(PostProcessor)
parser.addParseListener(UnclosedCommentProcessor(command, tokenStream))
parser.removeErrorListeners()
parser.addErrorListener(ParseErrorListener)
parser.legacy_setops_precedence_enabled = conf.setOpsPrecedenceEnforced
parser.legacy_exponent_literal_as_decimal_enabled = conf.exponentLiteralAsDecimalEnabled
parser.SQL_standard_keyword_behavior = conf.ansiEnabled
try {
try {
// first, try parsing with potentially faster SLL mode
parser.getInterpreter.setPredictionMode(PredictionMode.SLL)
toResult(parser)
。。。
。。。
|
注入规则
这里以 org.apache.spark.sql.delta.DeltaAnalysis为列,它是 DeltaLake 扩展了 Spark 的功能,注入了很多规则,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
class DeltaSparkSessionExtension extends (SparkSessionExtensions => Unit) {
override def apply(extensions: SparkSessionExtensions): Unit = {
extensions.injectParser { (session, parser) =>
new DeltaSqlParser(parser)
}
extensions.injectResolutionRule { session =>
new DeltaAnalysis(session)
}
extensions.injectCheckRule { session =>
new DeltaUnsupportedOperationsCheck(session)
}
extensions.injectPostHocResolutionRule { session =>
new PreprocessTableUpdate(session.sessionState.conf)
}
extensions.injectPostHocResolutionRule { session =>
new PreprocessTableMerge(session.sessionState.conf)
}
extensions.injectPostHocResolutionRule { session =>
new PreprocessTableDelete(session.sessionState.conf)
}
extensions.injectOptimizerRule { session =>
new ActiveOptimisticTransactionRule(session)
}
}
}
|
Spark 的注入规则如下:
- injectParser – 添加parser自定义规则,parser负责SQL解析
- injectResolutionRule – 添加Analyzer自定义规则到Resolution阶段,analyzer负责逻辑执行计划生成
- injectCheckRule – 添加Analyzer自定义Check规则
- injectPostHocResolutionRule – 添加Analyzer自定义规则到Post Resolution阶段
- injectOptimizerRule – 添加optimizer自定义规则,optimizer负责逻辑执行计划的优化,我们例子中就是扩展了逻辑优化规则
- injectPlannerStrategy – 添加planner strategy自定义规则,planner负责物理执行计划的生成
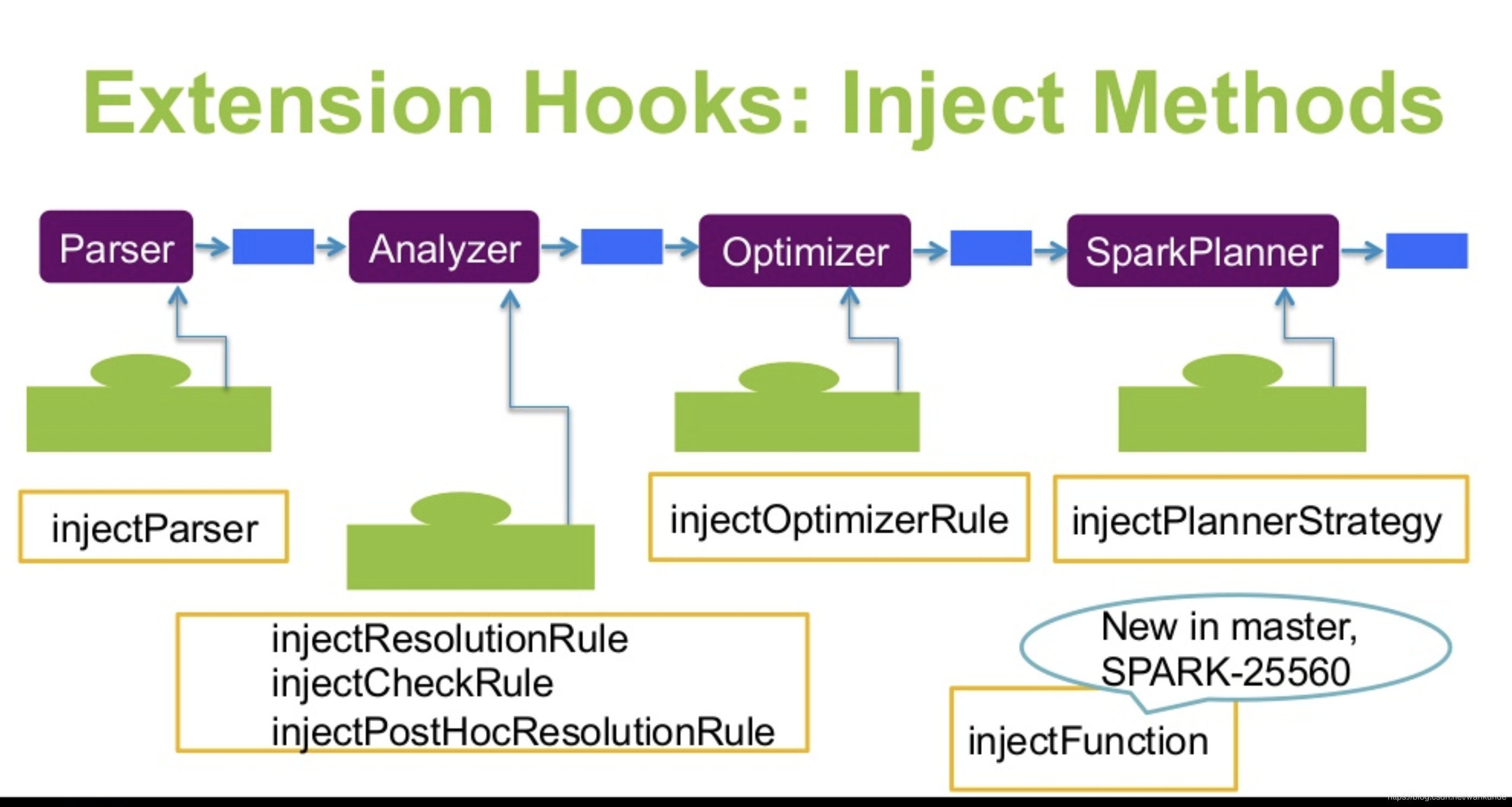
扩展规则的调用
这里的调用过程是:
Analyzer -> RuleExecutor
在 RuleExecutor 里面,会调用一些注入的规则,其中很多是默认的,有些是可以自行注入的
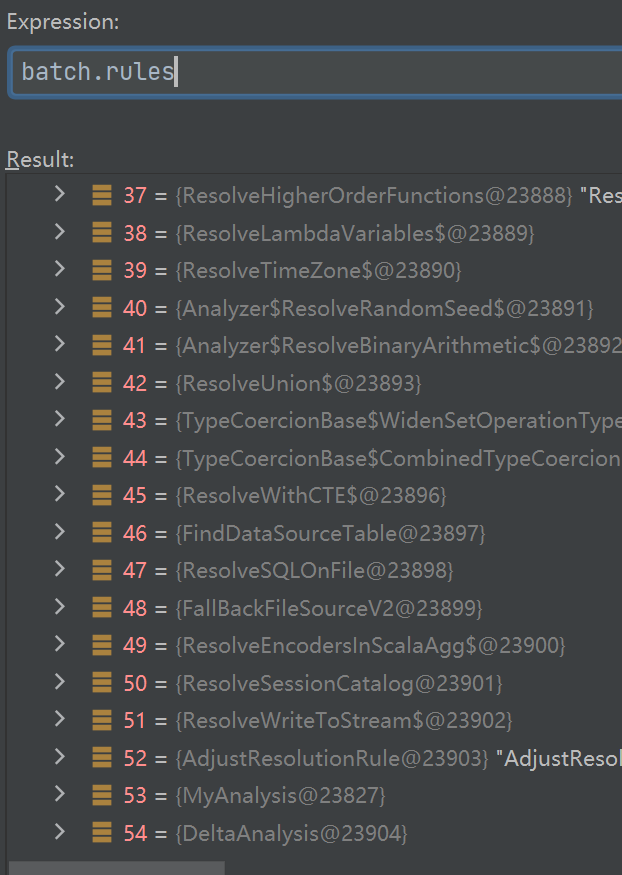
如上,MyAnalysis 就是自行注入的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
class MyAnalysis (session: SparkSession)
extends Rule[LogicalPlan] with AnalysisHelper {
override def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperatorsDown {
case u @ UpdateTable(table, assignments, condition) if u.childrenResolved =>
val (cols, expressions) = assignments.map(a => a.key -> a.value).unzip
table.collectLeaves().headOption match {
case Some(DataSourceV2Relation(_,_,_,_,_)) => {
UpdataTableV2(table, cols, expressions, condition)
}
case o =>
throw DeltaErrors.notADeltaSourceException("UPDATE", o)
}
}
}
|
之后是 调用 ipostHocResolutionRule
这里是生成物理执行逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
class MyPreprocessTableUpdate (sqlConf: SQLConf)
extends Rule[LogicalPlan] with UpdateExpressionsSupport {
override def conf: SQLConf = sqlConf
override def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperators {
case u: UpdataTableV2 if u.resolved => {
u.condition.foreach { cond =>
if (SubqueryExpression.hasSubquery(cond)) {
throw DeltaErrors.subqueryNotSupportedException("UPDATE", cond)
}
}
toCommand(u)
}
}
def toCommand(update: UpdataTableV2): UpdateTableCommand = {
UpdateTableCommand(update, update.expressions, update.updateColumns, update.condition)
}
}
|
优化规则
假设在 spark-shell中输入如下内容:
1
2
|
List(1,2,3,4,5).toDF("a").createOrReplaceTempView("t")
val q = spark.sql("select a * 1 from t").queryExecution
|
打印出来的执行计划如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
q: org.apache.spark.sql.execution.QueryExecution =
== Parsed Logical Plan ==
'Project [unresolvedalias(('a * 1), None)]
+- 'UnresolvedRelation [t], [], false
== Analyzed Logical Plan ==
(a * 1): int
Project [(a#29 * 1) AS (a * 1)#37]
+- SubqueryAlias t
+- Project [value#26 AS a#29]
+- LocalRelation [value#26]
== Optimized Logical Plan ==
LocalRelation [(a * 1)#37]
== Physical Plan ==
LocalTableScan [(a * 1)#37]
|
通过逻辑计划能看出:
Project [(a#29 * 1) AS (a * 1)#37]
这里没有做优化,就是 a * 1
此时,可以增加一个优化规则
代码如下:
1
2
3
4
5
6
7
8
9
10
|
object MyOptimizer extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
case q: LogicalPlan => q transformExpressionsDown {
case mul@Multiply(left,right,_) if(right.isInstanceOf[Literal] &&
right.asInstanceOf[Literal].value.asInstanceOf[Integer] == 1) => {
left
}
}
}
}
|
执行后,显示如下:
1
2
3
4
5
6
|
scala> MyOptimizer(q.analyzed)
res5: org.apache.spark.sql.catalyst.plans.logical.LogicalPlan =
Project [a#29 AS (a * 1)#37]
+- SubqueryAlias t
+- Project [value#26 AS a#29]
+- LocalRelation [value#26]
|
这时候,可以发现其逻辑计划:
Project [a#29 AS (a * 1)#37]
由a * 1 变成了a,说明优化有效果了
具体执行
这里需要实现一个 更新类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
case class UpdateTableCommand(logical: LogicalPlan,
updateExpressions: Seq[Expression],
updateColumns: Seq[Expression],
condition: Option[Expression])
extends LeafRunnableCommand {
override def run(sparkSession: SparkSession): Seq[Row] = {
//spark没有对update做处理,这里需要自己拼接出SQL
val tableName = "处理 table name"
val express = "拼接 SET 后面的表达式"
val filter = JDBCRDD.compileFilter(condition, dialect)
val sql = "UPDATE " + tableName + " SET " + express + " WHERE " + filter
//执行SQL
Seq.empty[Row]
}
}
|
最后在QueryExecution#eagerlyExecuteCommands中触发的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
override def executeCollect(): Array[InternalRow] = sideEffectResult.toArray
private def eagerlyExecuteCommands(p: LogicalPlan) = p transformDown {
case c: Command =>
val qe = sparkSession.sessionState.executePlan(c, CommandExecutionMode.NON_ROOT)
val result = SQLExecution.withNewExecutionId(qe, Some(commandExecutionName(c))) {
qe.executedPlan.executeCollect()
}
CommandResult(
qe.analyzed.output,
qe.commandExecuted,
qe.executedPlan,
result)
case other => other
}
|
最后在 commands.scala 中
1
2
3
4
|
protected[sql] lazy val sideEffectResult: Seq[InternalRow] = {
val converter = CatalystTypeConverters.createToCatalystConverter(schema)
cmd.run(session).map(converter(_).asInstanceOf[InternalRow])
}
|
执行 com.run() 然后调用RunnableCommand的实现类,完整最后的物理执行动作