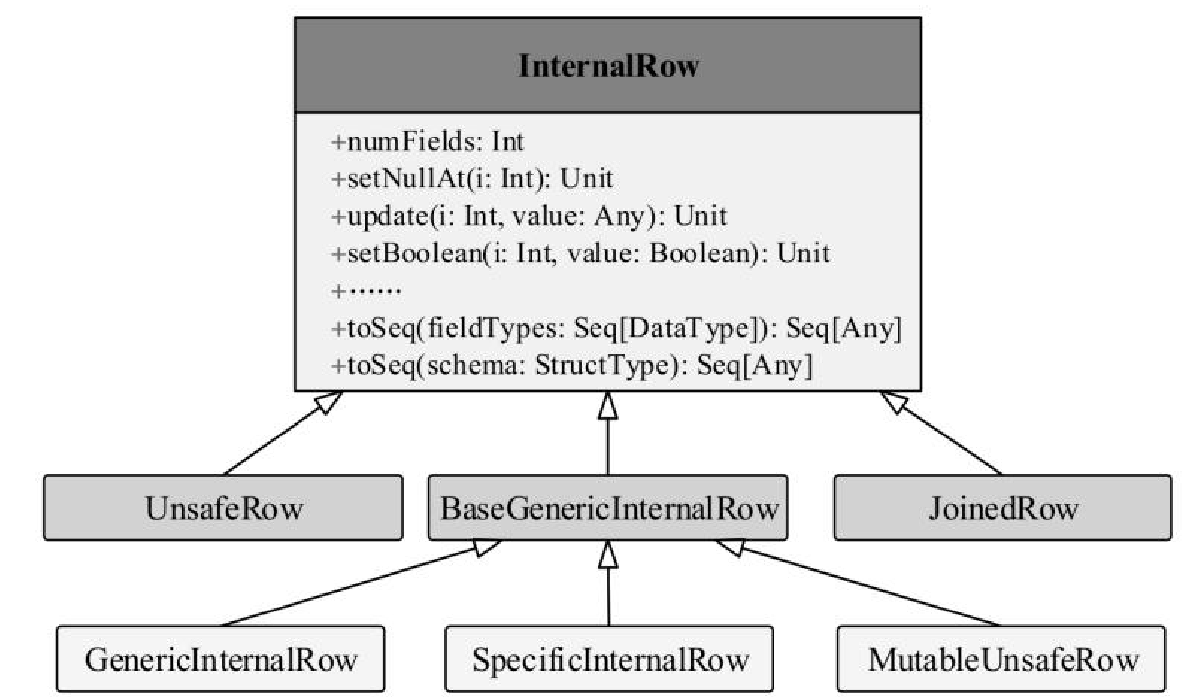
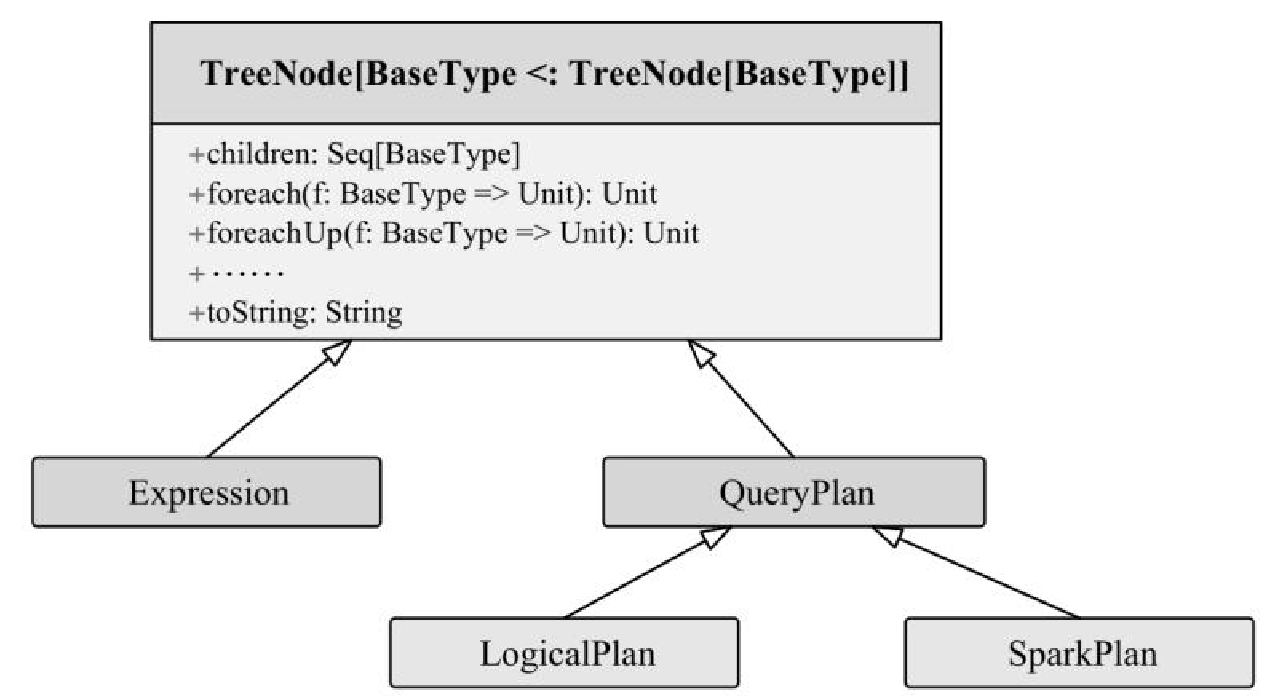
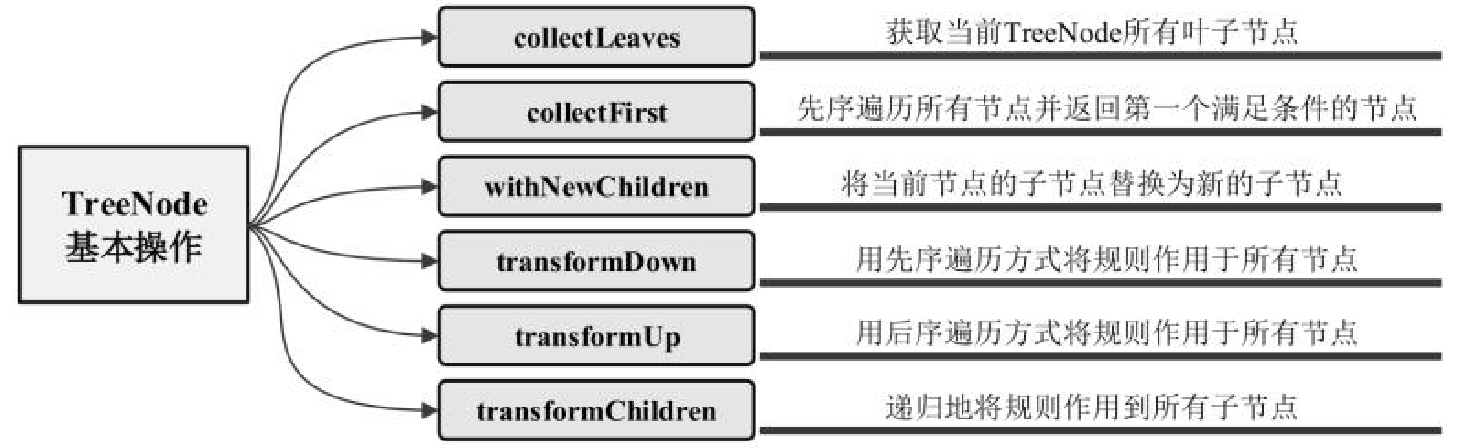
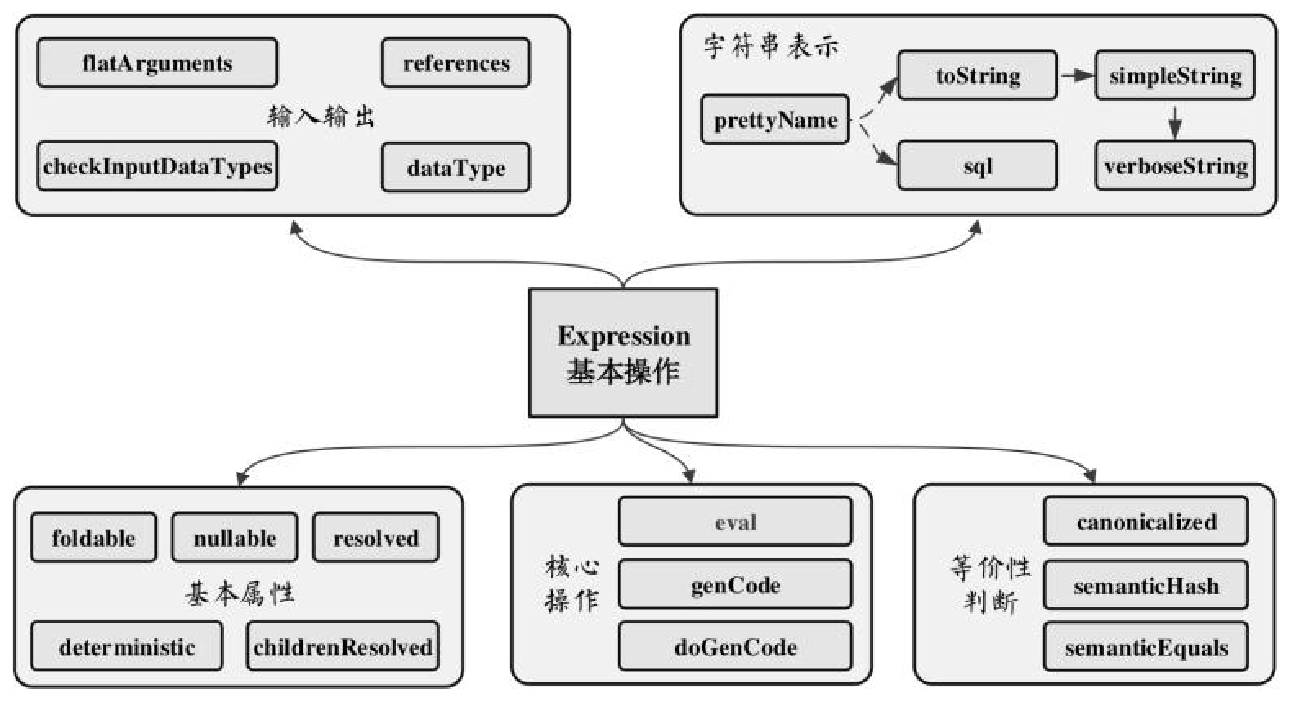
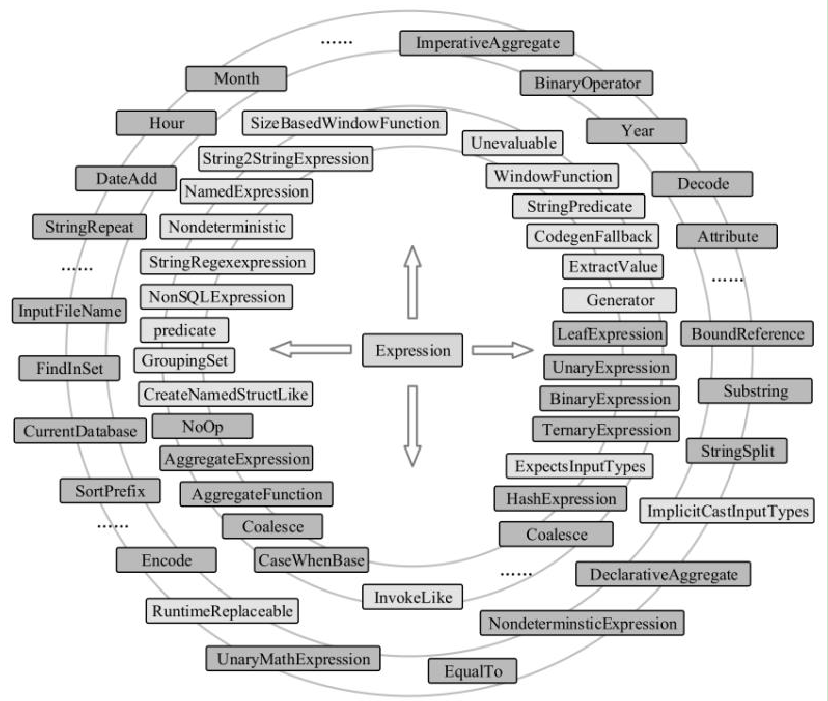
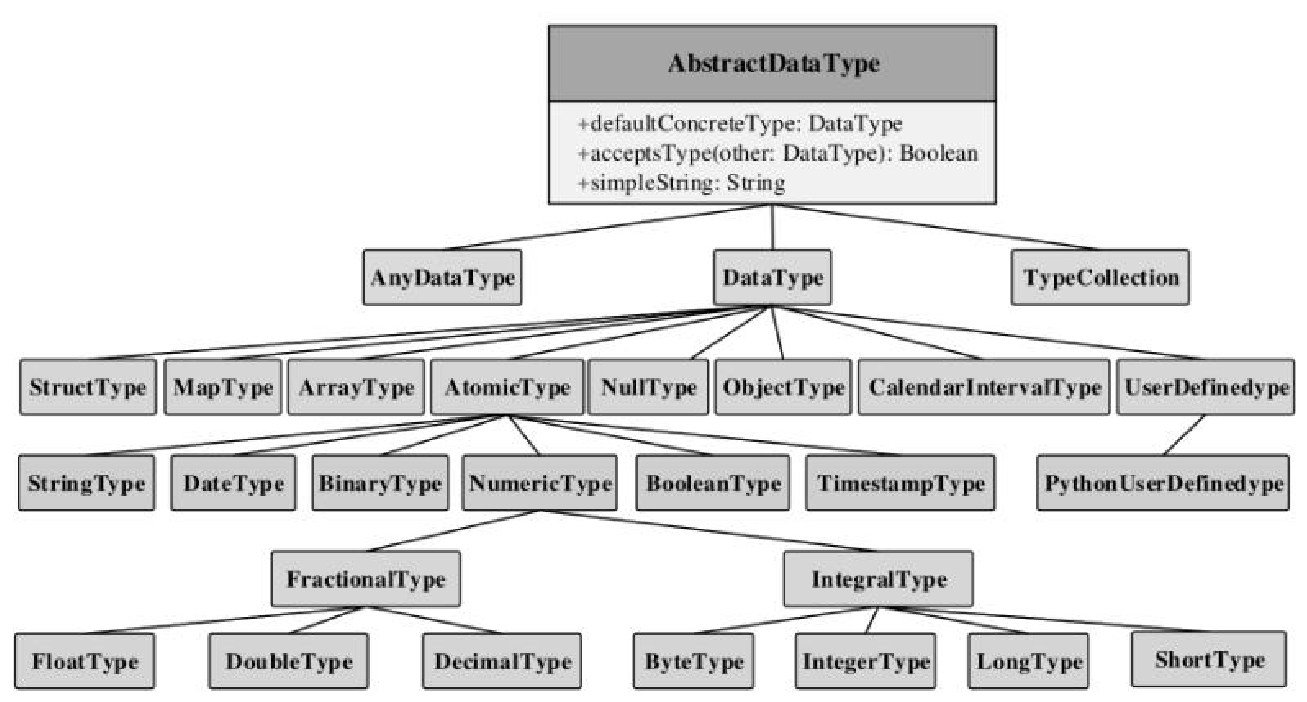
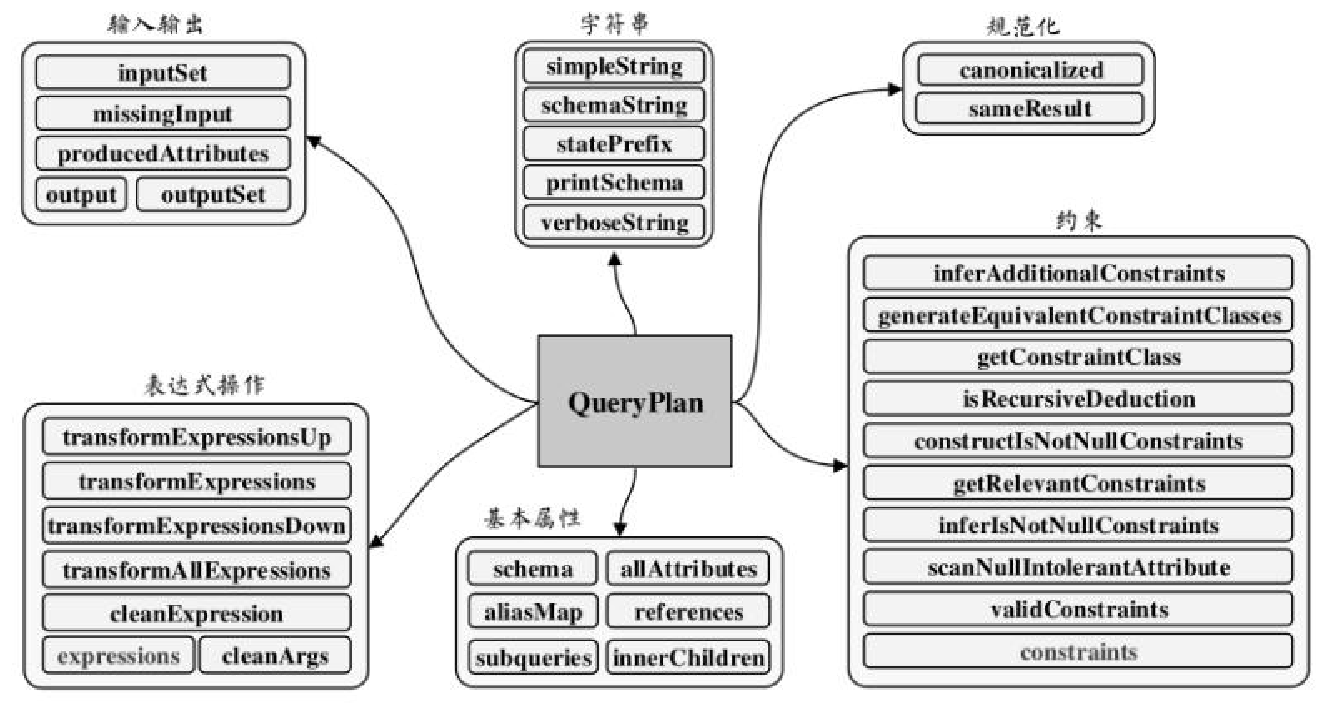
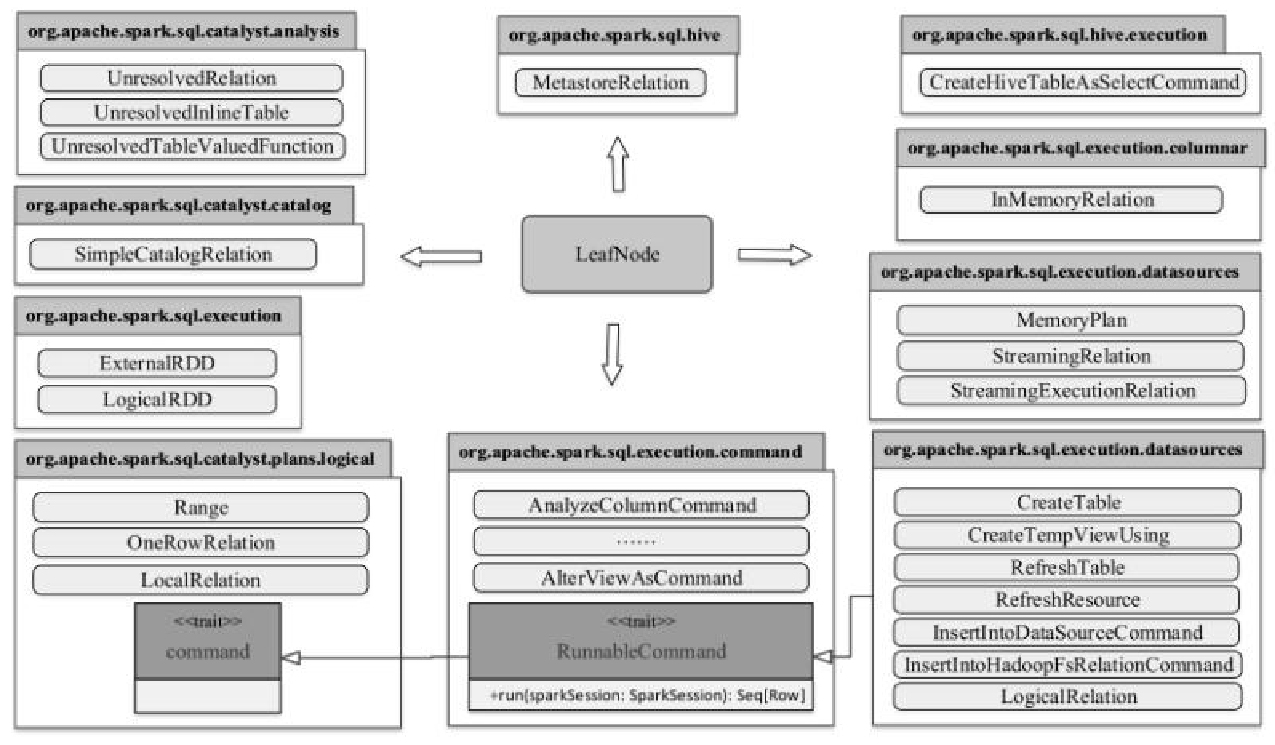
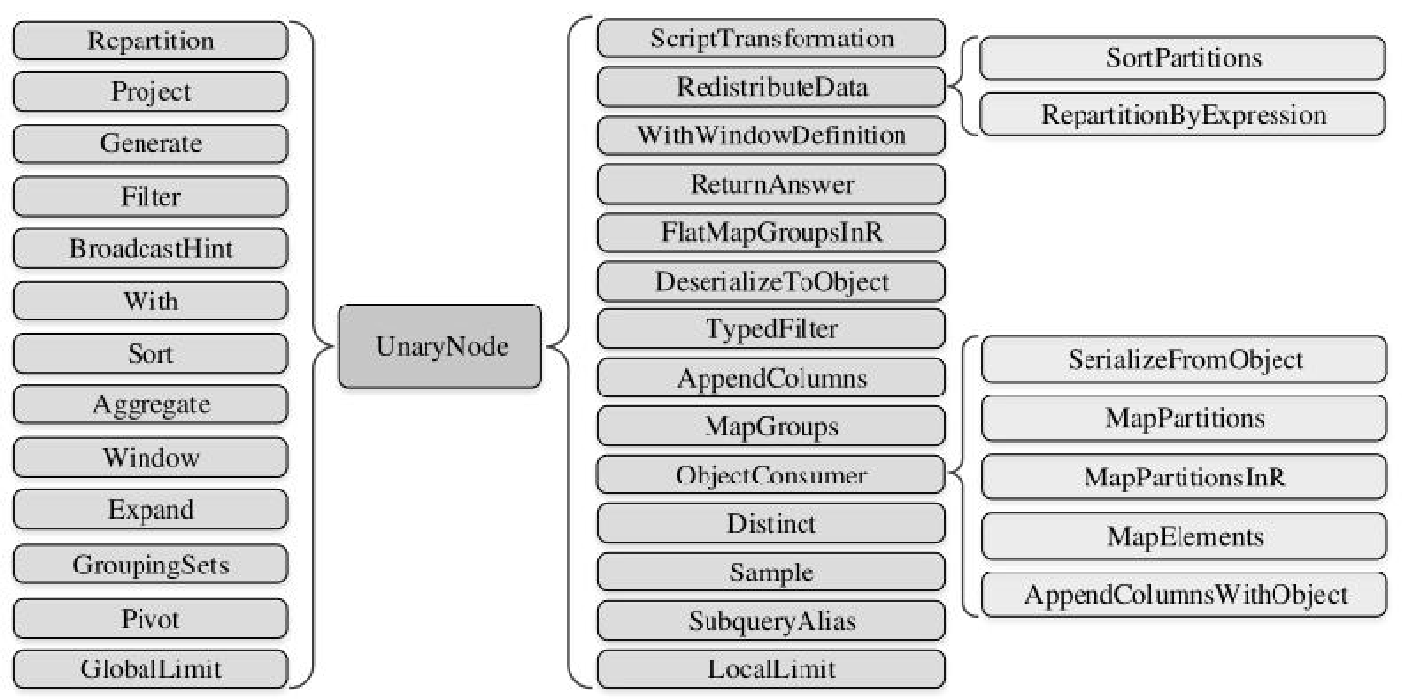
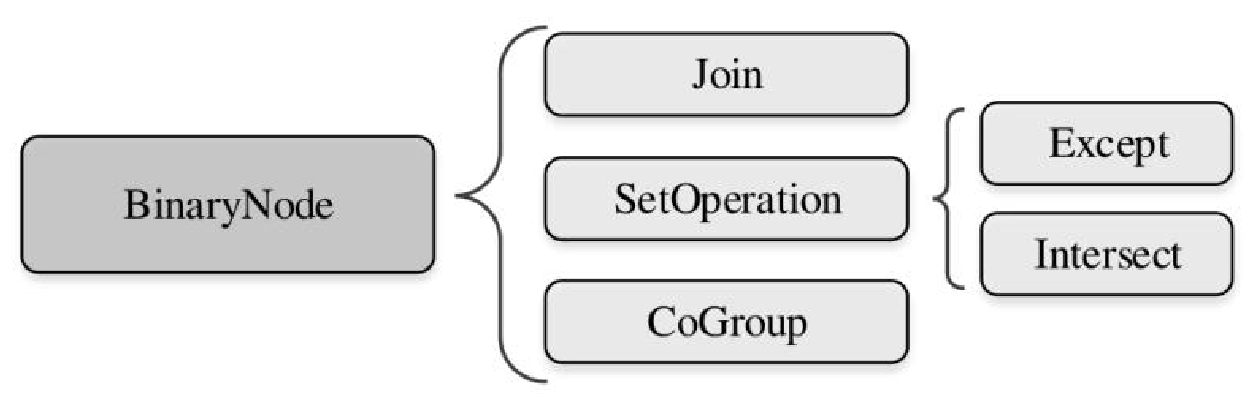
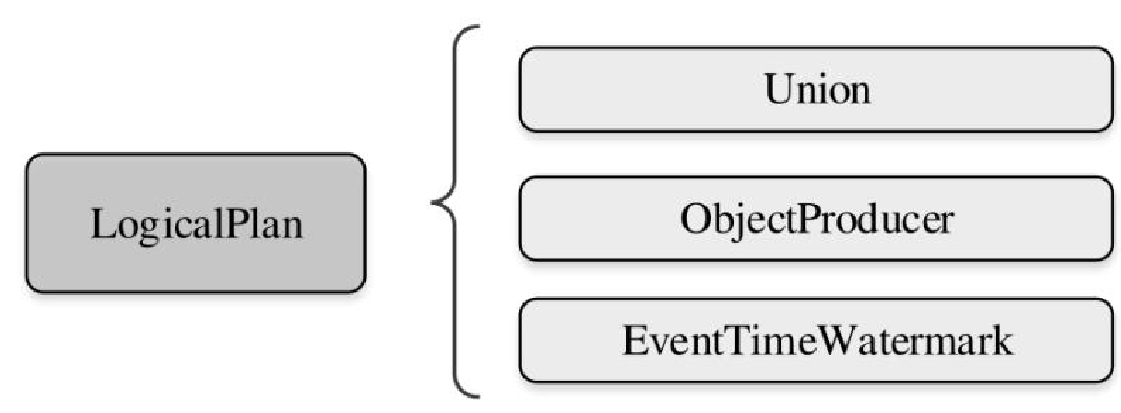
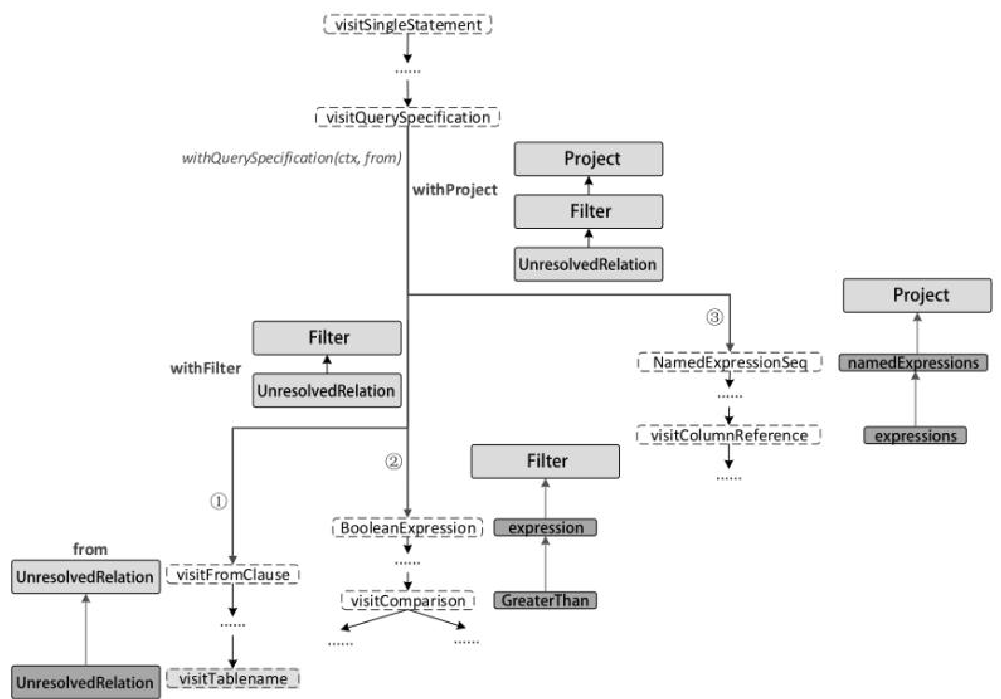
相关逻辑和类
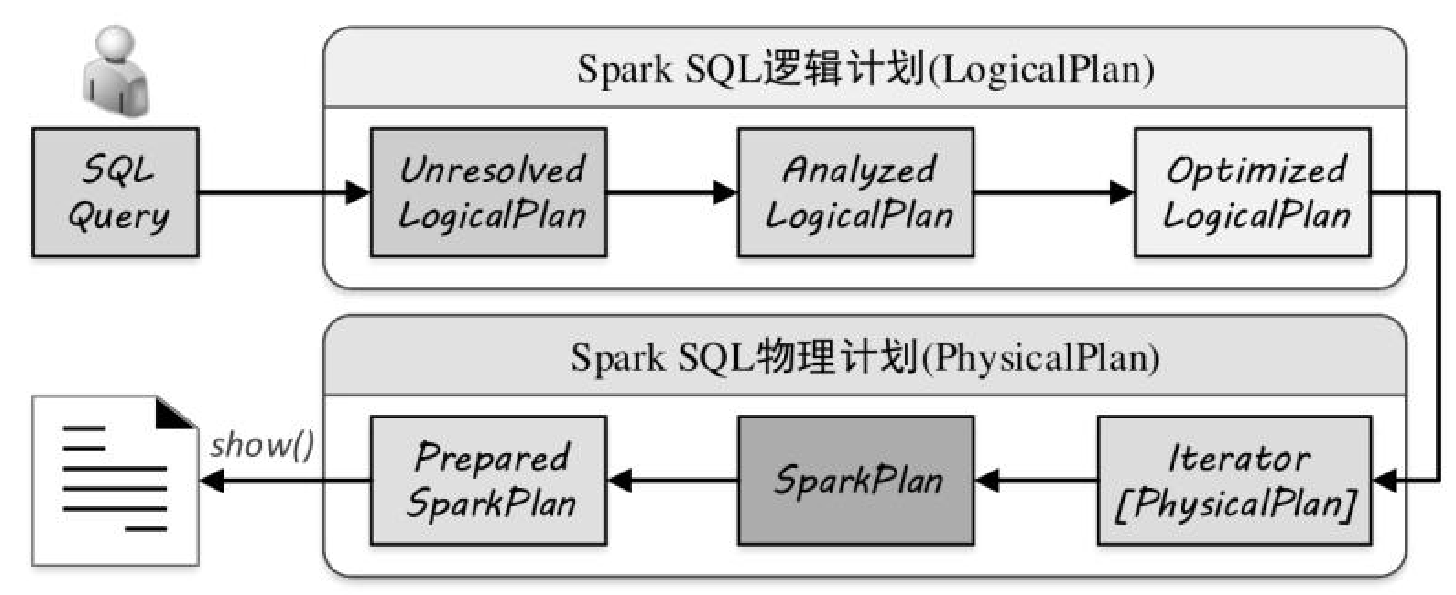
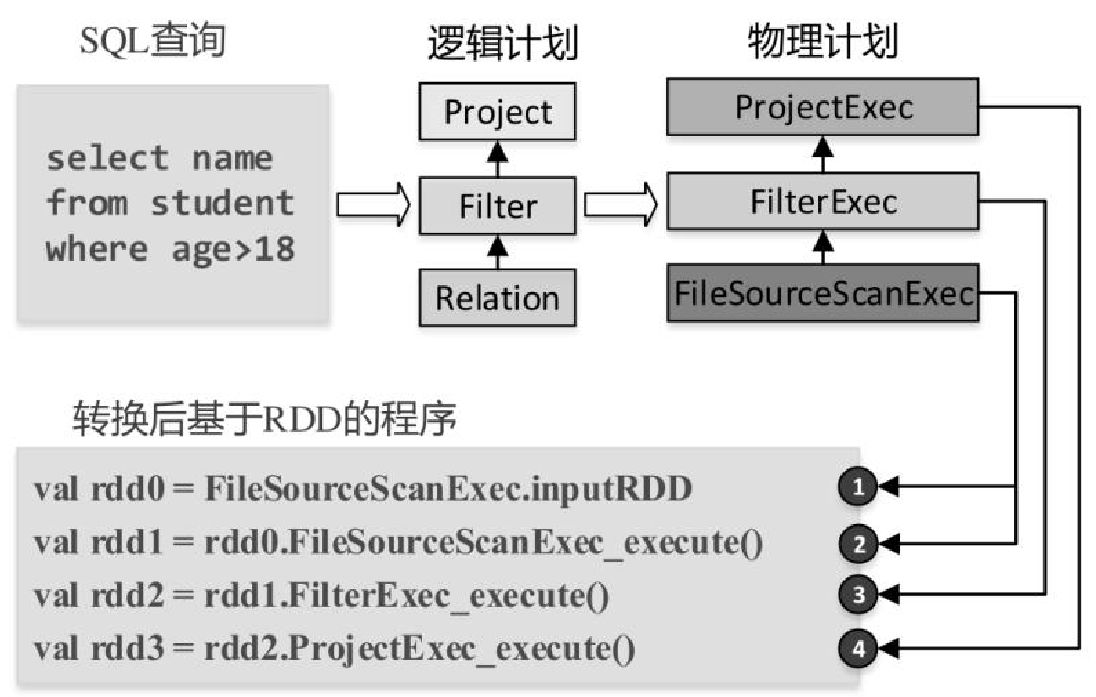
SQL解析
这块没什么好说的,就是用 ANTLR 做的解析
将 ANTLR 的语法树 -> Spark的语法树
入口点是 SparkSession#sql:
1
2
3
4
5
6
7
|
def sql(sqlText: String): DataFrame = withActive {
val tracker = new QueryPlanningTracker
val plan = tracker.measurePhase(QueryPlanningTracker.PARSING) {
sessionState.sqlParser.parsePlan(sqlText)
}
Dataset.ofRows(self, plan, tracker)
}
|
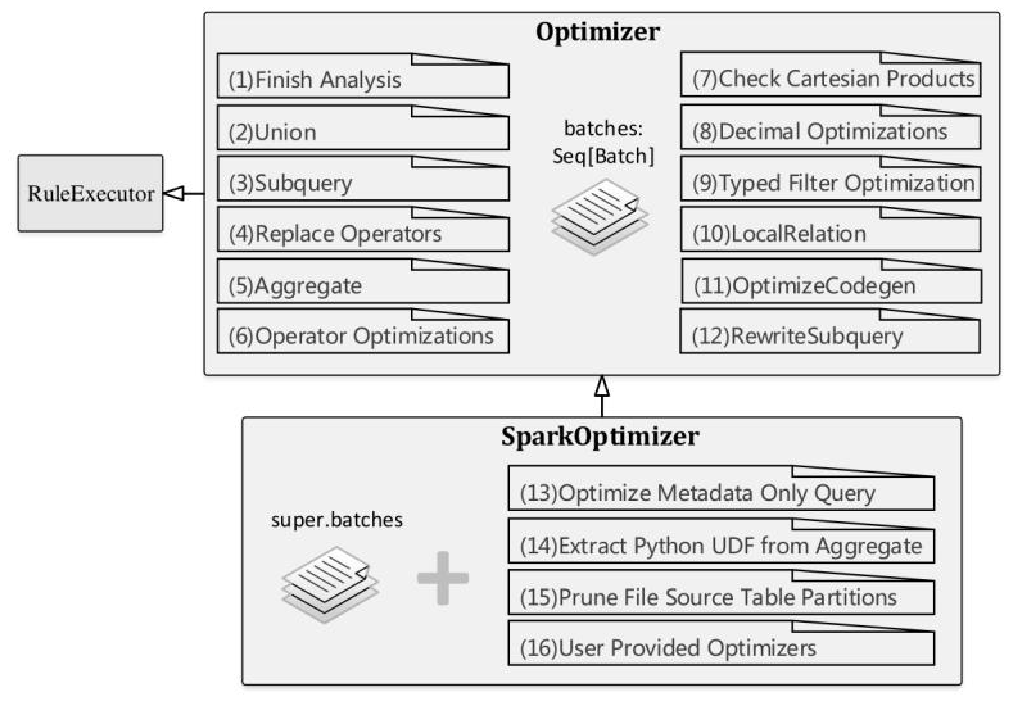
解析逻辑计划
入口点是 Dataset#ofRows,这里会通过 QueryExecution做解析
从这里可以看出,可以单独将这个 QueryExecution 拿出来
比如
- 可以用 Spark的SQL语法解析规则,.g4文件做一些扩展
- 然后生成自定义的 AstBuilder,并扩展LogicPlan
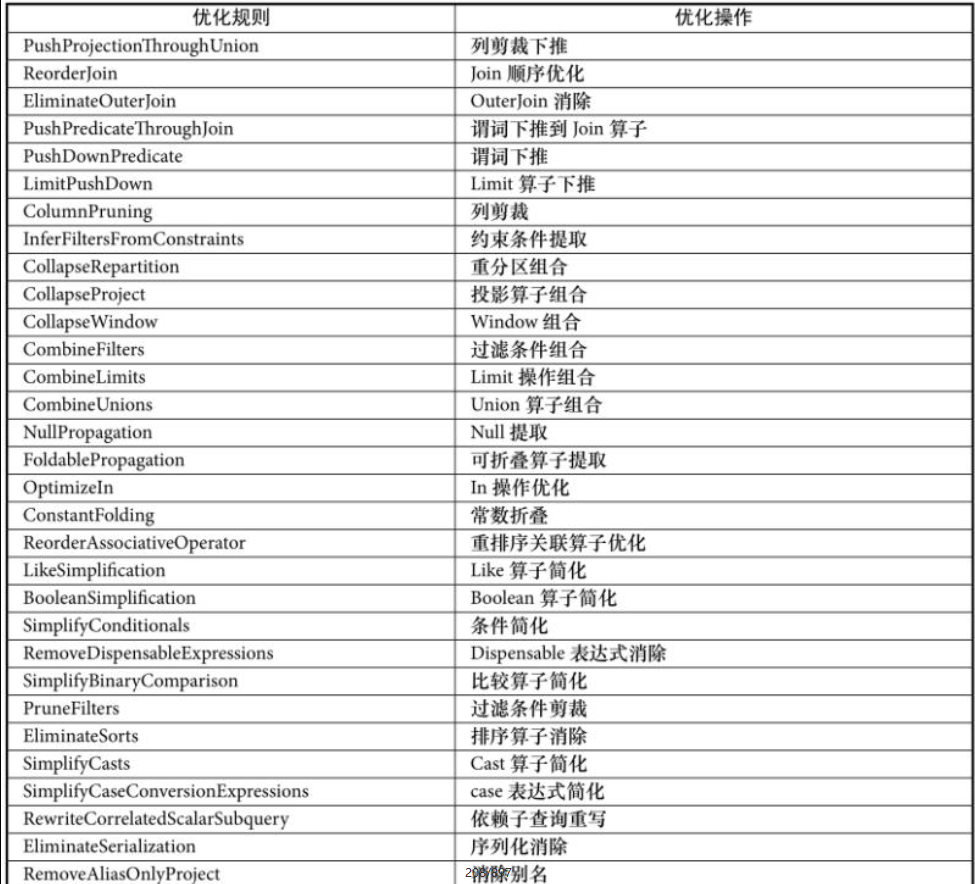
- 得到LogicalPlan之后,再调用 QueryExection,做解析和优化
- 这里可以增加自己的解析、优化规则
- 得到的就是一个优化后的SQL的逻辑计划
- 后面可以考虑继续用Spark,也可以将这个跟其他MPP数据库做一些整合
- 底层的存储也可以考虑接入分布式文件系统,这样还要修改相应的算子
1
2
3
4
5
6
|
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan, tracker: QueryPlanningTracker)
: DataFrame = sparkSession.withActive {
val qe = new QueryExecution(sparkSession, logicalPlan, tracker)
qe.assertAnalyzed()
new Dataset[Row](qe, RowEncoder(qe.analyzed.schema))
}
|
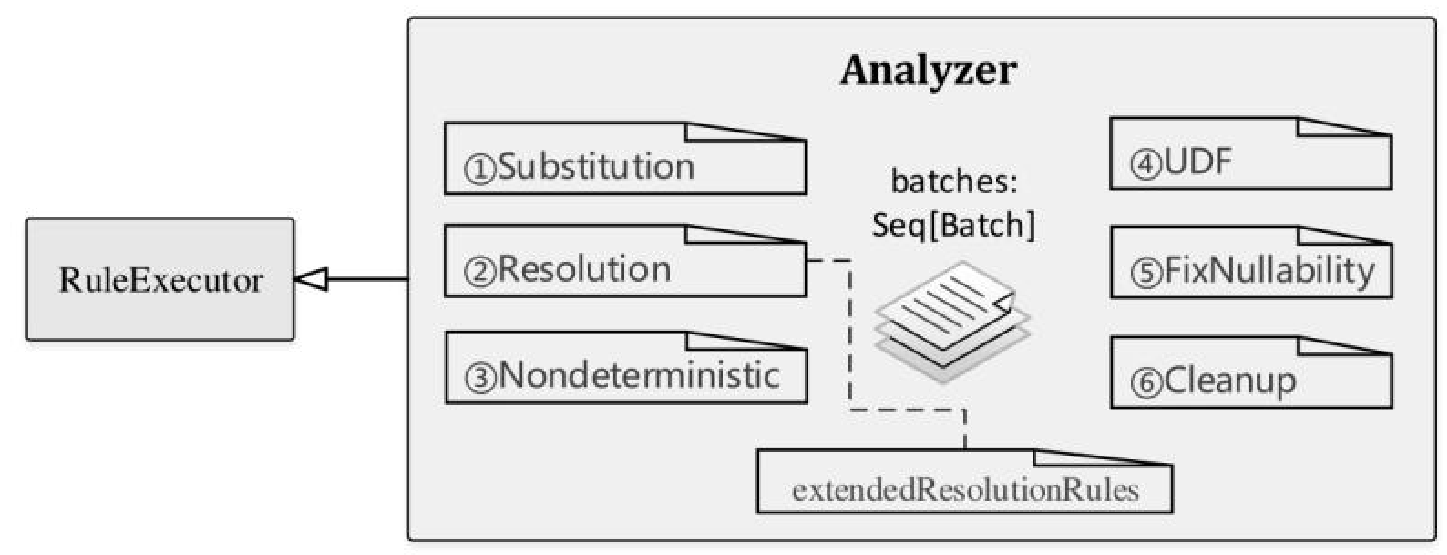
这里将 Analyzer 绑定到 SessionState中,后者属于SparkSession
1
2
3
4
|
lazy val analyzed: LogicalPlan = executePhase(QueryPlanningTracker.ANALYSIS) {
// We can't clone `logical` here, which will reset the `_analyzed` flag.
sparkSession.sessionState.analyzer.executeAndCheck(logical, tracker)
}
|
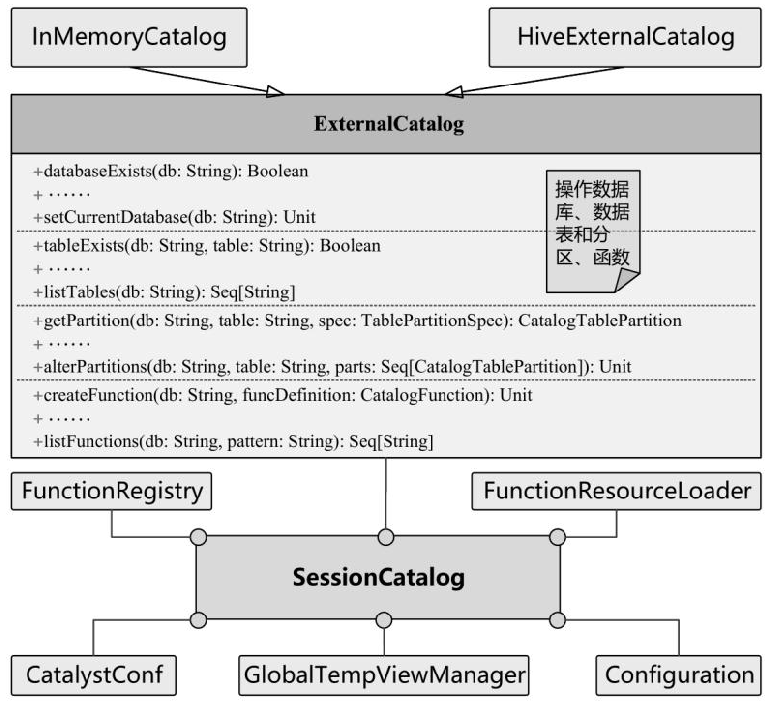
SessionState 中也绑定了其他一些对象:
1
2
3
4
|
lazy val catalog: SessionCatalog = catalogBuilder()
lazy val analyzer: Analyzer = analyzerBuilder()
lazy val optimizer: Optimizer = optimizerBuilder()
lazy val resourceLoader: SessionResourceLoader = resourceLoaderBuilder()
|
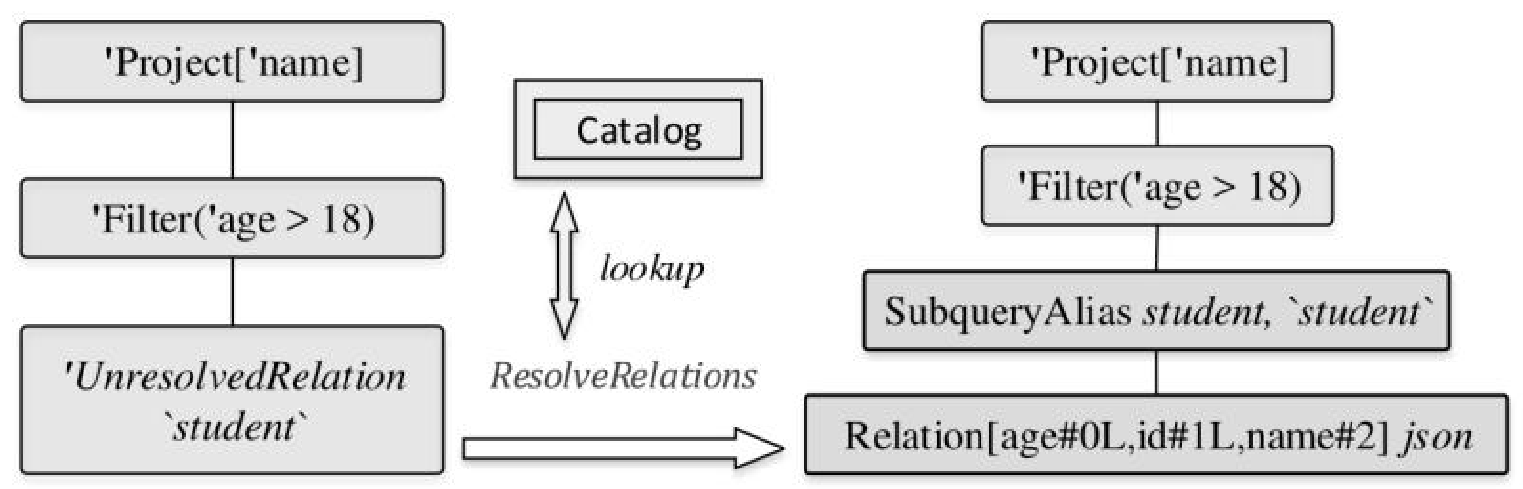
对于 SELECT * FROM hello.gg LIMIT 10 这么一个操作
首先要解析 hello.gg 这些库表
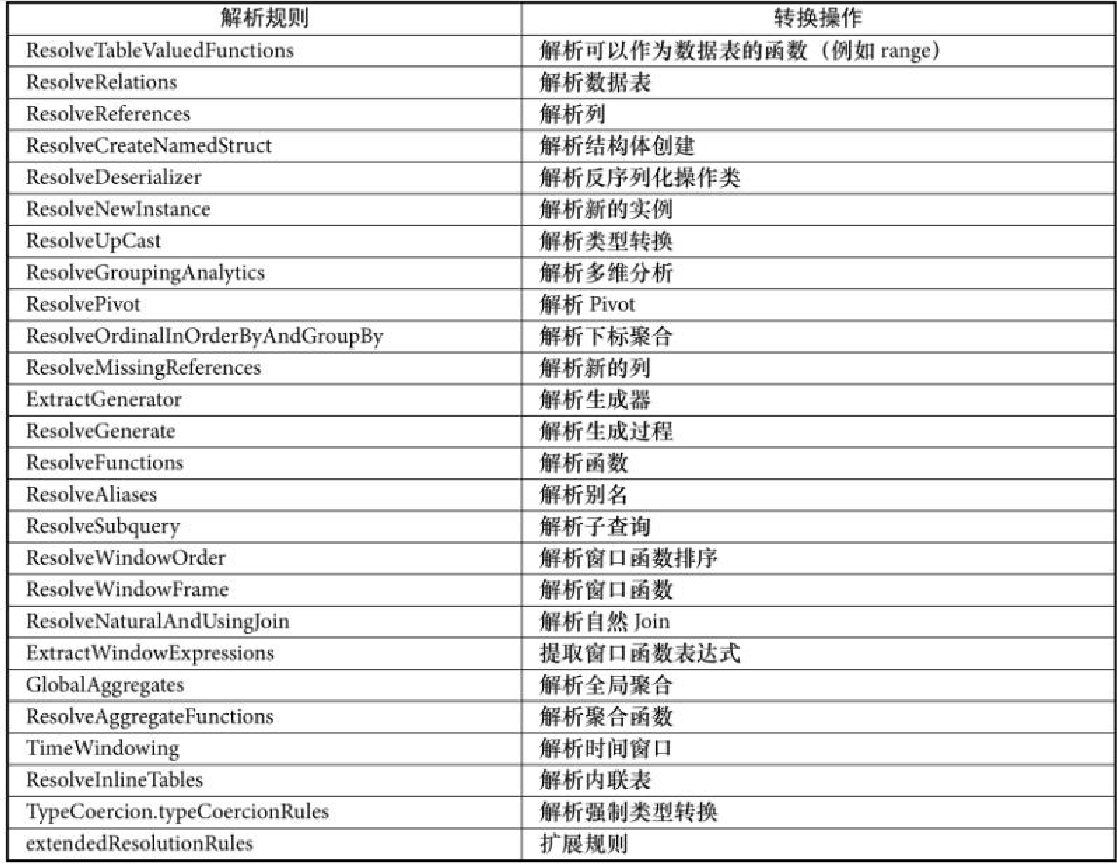
在 Analyzed 中是由ResolveTables规则去做的
而 ResolveTables 规则,是 Analyzed 的众多内置规则中的一个
1
2
3
4
5
6
7
8
9
10
11
12
|
object ResolveTables extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = ResolveTempViews(plan).
resolveOperatorsUpWithPruning(AlwaysProcess.fn, ruleId) {
case u: UnresolvedRelation =>
lookupV2Relation(u.multipartIdentifier, u.options, u.isStreaming)
.map { relation =>
val (catalog, ident) = relation match {
case ds: DataSourceV2Relation => (ds.catalog, ds.identifier.get)
case s: StreamingRelationV2 => (s.catalog, s.identifier.get)
}
SubqueryAlias(catalog.get.name +: ident.namespace :+ ident.name, relation)
}.getOrElse(u)
|
而 lookupV2Relation 的主要内容如下:
1
|
CatalogV2Util.loadTable(catalog, ident)
|
这会触发到 我们自定义的 Catalog#loadTable,去获取真实的表的元数据信息
其他