背景
jdbc 客户端需要支持 kerberos 认证,之前使用的jdbc客户端是 calcite-avatica,虽然它的官网上说是可以支持kerberos的
但文档比较旧了,相关资料也比较少
另一个问题是,他是基于HTTP方式实现kerberos的,不确定这块是否有坑,所以考虑换一个 客户端
由于hive jdbc对kerberos支持的比较好,所以考虑使用原生hive server来实现
将原生hive server的RPC连接部分,单独抽出来,这样hive的客户端就不用动了,服务端只要能拿到SQL,后面的逻辑也不用动
实现原理
RPC扩展
这里将 原生HiveServer的RPC部分单独拿了出来,不使用 session manager等其他组件,这样的话,客户端不用变,仍然是使用原生的hive client
client 和 server端的通讯使用 thrift完成,下图是 thrift的协议栈
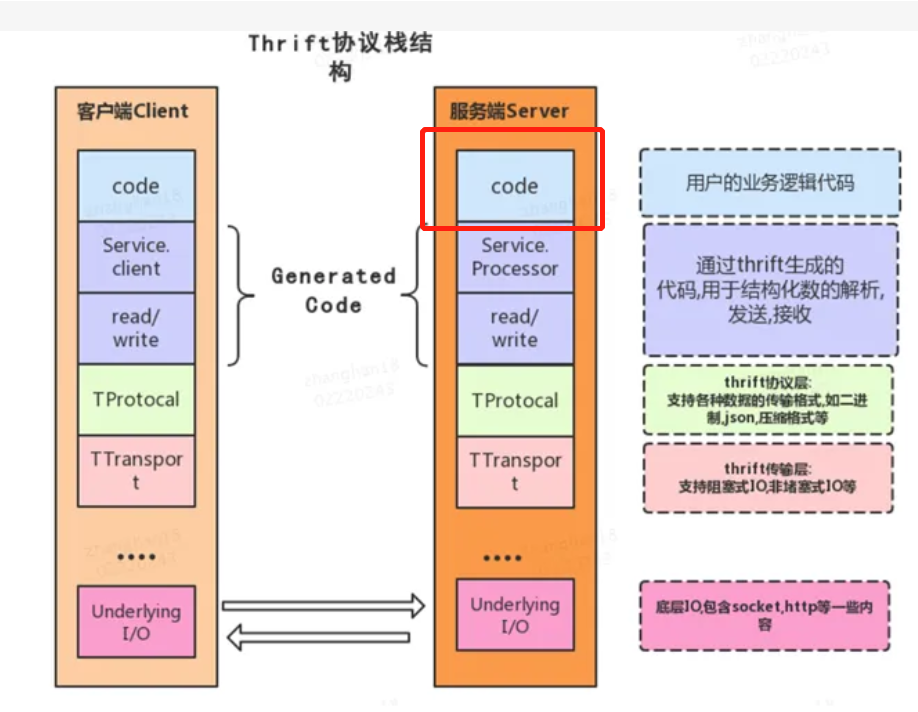
上图中主要的三层:
- transport 是通讯协议,如HTTP、SASL IO、plain IO等等
- protocol 是传输协议,如json、binary等
- processor 是要处理的业务逻辑,其中骨架代码是 自动生成的,我们只需要 重写上图红色部分即可
对于hive server的原生逻辑,上图红色部分就是 调用 session manager,然后解析sql,再调用map/reduce、tez等执行
将红色替换掉后,就可以自由发挥了,拿到 SQL之后,直接调用自定义的后端服务即可
在原生Hive中,红色部分 对应的是 TCLIService 接口,可以继承这个实现 自定义的 HiveCLI扩展
和原生的对比
原生的hive-server、spark-thrift 不能直接使用
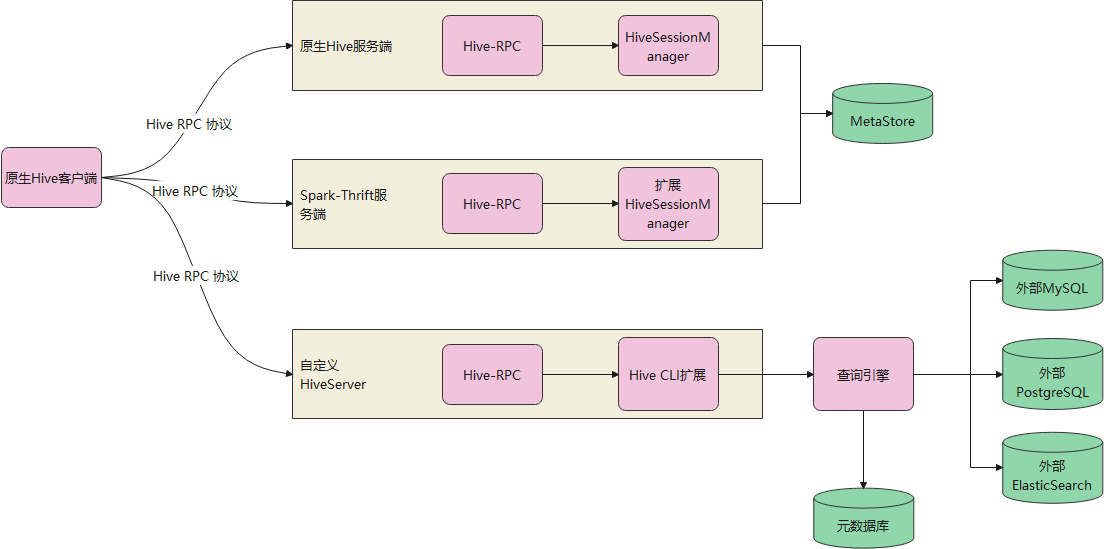
因为他们最后走hive逻辑,会生成 hive session manager,并去hive 元数据库中做查询
这不是我们想要的,我们只需要拿到 SQL 就可以了,后面就跟hive没任何关系了
所以直接拿 原生的方式是不行的
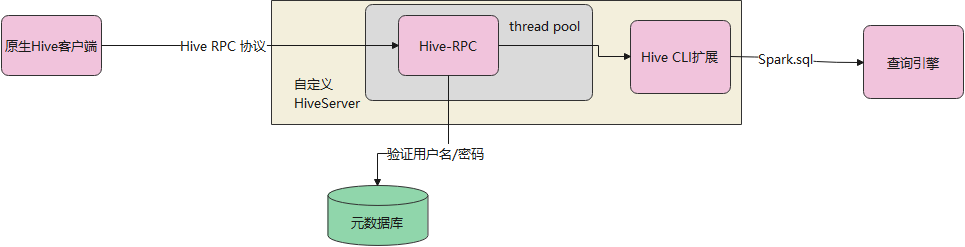
执行逻辑
下面是 Simple 方式的(基于用户名/密码验证),跟原先的 JDBC-Server类似
下面是 Kerberos 方式验证
首先要在 kerberos 环境上生成 keytab,并将 keytab和conf 放到服务端
之后客户端用 同样的 keytab,conf就可以跟服务端交互了
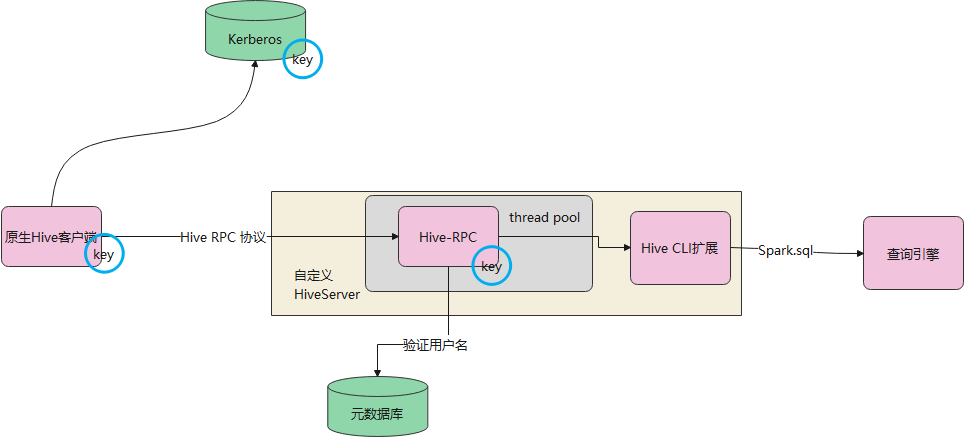
从kerberos协议来说,客户端 会跟 kerberos,以及服务端有交互,而服务端和 kerberos是没有交互的
Hive server本身已经包含了 kerberos认证,核心类是 HiveAuthFactory,通过这个类,可以到一个SASL的 transport、processor
也就是上层的代码不用动,只需要将传输层等部分,做一下包装,变成 SASL方式传输即可
安全部分的整体代码很少,基本都是复用了Hive的逻辑
如果看 网易kyuubi,会发现它的安全部分代码会比较多,因为它对 原生Hive这块做了很多重写,有不少是直接把代码拿过来用的
另外除了 Kerberos,hive还支持其他方式认证,如 LDAP、PAM、TOKEN等,这些,kyuubi都有支持所以代码会比较多
交互方式
Hive jdbc的查询可以是异步的,一个查询分成了好几步完成
1
2
3
4
5
6
7
8
|
Connection conn = DriverManager.getConnection(url, "test", "123456");
String sql = "select * from hello.gg";
PreparedStatement ps = conn.prepareStatement(sql);
ResultSet rs = ps.executeQuery();
while(rs.next()) {
......
}
//close.....
|
整个执行过程如下:
1、首先是打开连接,当执行DriverManager.getConnection这段后,会触发到服务端的openSession函数
2、提交SQL,ps.executeQuery()只是提交一个SQL,但不会返回结果
- 这一步会触发多个函数:
- (2.1)会触发 ExecuteStatement,这里函数会得到一个SQL,并通过Spark执行查询,并等待Spark执行完返回
- (2.2)Hive客户端支持异步查询,所以发送完SQL后,会检查执行状态,触发函数:GetOperationStatus
- (2.3)当检查到查询成功后,会获取查询数据的元数据信息(也就是表结构),会触发函数:GetResultSetMetadata
3、调用rs.next这时候会真正的获取数据
在具体实现时,将上述逻辑全部改为 阻塞方式,在(2)中,拿到提交的SQL,然后传给查询引起执行,并等待 spark端执行完后,返回 data-frame
之后将 data-frame放到session中
后面再检查执行结果时,就直接返回 成功
最后获取数据时,从session中拿到data-frame,真正的拿到数据并返回给客户端
具体实现
Hive-Server的实现逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
// 启动类
def start(): Unit = {
val processor: ThriftCLIService = new 定义自己的ThriftCLIService实现类(null, "")
val serverSocket: TServerSocket = new TServerSocket(port)
createThreadPoolServer(serverSocket, processor)
}
def createThreadPoolServer(serverSocket: TServerSocket, processor: ThriftCLIService): Unit = {
val executor: ThreadPoolExecutor = new ThreadPoolExecutor(10, 100, 10, TimeUnit.SECONDS,
new SynchronousQueue[Runnable](),
new NameTreadFactory("name...."))
val args: MyTThreadPoolServerArgs = new MyTThreadPoolServerArgs(serverSocket)
if(启动类安全) {
val conf: HiveConf = 获取HiveConf()
val hiveAuthFactory = new MyAuthFactory()
hiveAuthFactory.init(conf)
val transportFactory: TTransportFactory = hiveAuthFactory.getAuthTransFactory()
val processorFactory: TProcessorFactory = hiveAuthFactory.getAuthProcFactory(processor)
args.transportFactory(transportFactory).processorFactory(processorFactory)
}
else {
//这块就是创建 processor,对业务逻辑做一层封装
val plainProcessor: TProcessor = new TCLIService.Processor[TCLIService.Iface](processor)
args.transportFactory(new PlainScoketTransportFactroy()).processor(plainProcessor)
}
// 启动
args
.protocolFactory(new TBinaryProtocol.Factory)
.requestTimeout(30).requestTimeoutUnit(TimeUnit.SECONDS)
.beBackoffSlotLength(100)
.beBackoffSlotLengthUnit(TimeUnit.MILLISECONDS)
.executorService(executor)
val threadPoolServer: MyTThreadPoolServer = new MyTThreadPoolServer(args)
threadPoolServer.init()
threadPoolServer.serve()
}
|
TCLIService.Iface,服务端需要将这些函数都实现了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public TOpenSessionResp OpenSession(TOpenSessionReq req) throws org.apache.thrift.TException;
public TCloseSessionResp CloseSession(TCloseSessionReq req) throws org.apache.thrift.TException;
public TGetInfoResp GetInfo(TGetInfoReq req) throws org.apache.thrift.TException;
public TExecuteStatementResp ExecuteStatement(TExecuteStatementReq req) throws org.apache.thrift.TException;
public TGetTypeInfoResp GetTypeInfo(TGetTypeInfoReq req) throws org.apache.thrift.TException;
public TGetCatalogsResp GetCatalogs(TGetCatalogsReq req) throws org.apache.thrift.TException;
public TGetSchemasResp GetSchemas(TGetSchemasReq req) throws org.apache.thrift.TException;
public TGetTablesResp GetTables(TGetTablesReq req) throws org.apache.thrift.TException;
public TGetTableTypesResp GetTableTypes(TGetTableTypesReq req) throws org.apache.thrift.TException;
public TGetColumnsResp GetColumns(TGetColumnsReq req) throws org.apache.thrift.TException;
public TGetFunctionsResp GetFunctions(TGetFunctionsReq req) throws org.apache.thrift.TException;
public TGetPrimaryKeysResp GetPrimaryKeys(TGetPrimaryKeysReq req) throws org.apache.thrift.TException;
public TGetCrossReferenceResp GetCrossReference(TGetCrossReferenceReq req) throws org.apache.thrift.TException;
public TGetOperationStatusResp GetOperationStatus(TGetOperationStatusReq req) throws org.apache.thrift.TException;
public TCancelOperationResp CancelOperation(TCancelOperationReq req) throws org.apache.thrift.TException;
public TCloseOperationResp CloseOperation(TCloseOperationReq req) throws org.apache.thrift.TException;
public TGetResultSetMetadataResp GetResultSetMetadata(TGetResultSetMetadataReq req) throws org.apache.thrift.TException;
public TFetchResultsResp FetchResults(TFetchResultsReq req) throws org.apache.thrift.TException;
public TGetDelegationTokenResp GetDelegationToken(TGetDelegationTokenReq req) throws org.apache.thrift.TException;
public TCancelDelegationTokenResp CancelDelegationToken(TCancelDelegationTokenReq req) throws org.apache.thrift.TException;
public TRenewDelegationTokenResp RenewDelegationToken(TRenewDelegationTokenReq req) throws org.apache.thrift.TException;
|
测试说明
使用原生的 Hive客户端即可,之前的测试逻辑不用动
改一下驱动和连接的URL
再增加一个 maven配置:
1
2
3
4
5
|
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.3.9</version>
</dependency>
|
Simple方式
用户名/密码跟 之前的一致
参考代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public void simple()throws Exception {
String url = "jdbc:hive2://hive的ip:hive的port/default;useSSL=false;auth=noSasl";
initH2Kerberos();
Class.forName("org.apache.hive.jdbc.HiveDriver");
String sql = "select * from hello.gg";
Connection conn = DriverManager.getConnection(url, "test", "123456")
PreparedStatement ps = conn.prepareStatement(sql);
ResultSet rs = ps.executeQuery();
while(rs.next()) {
int id = rs.getInt("id");
String sname = rs.getString("sname");
String LastName = rs.getString("LastName");
Timestamp t = rs.getTimestamp("dob");
System.out.println("id->" + id +"\tsname->"+ sname + "\tlast_time->" + LastName +"\tODB->" + t);
}
rs.close();
ps.close();
}
|
kerberos 方式
需要提前配置好 /etc/hosts
参考代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
public void kerberos()throws Exception {
String url = "jdbc:hive2://hive-server:port/default;principal=你的principal";
initH2Kerberos();
Class.forName("org.apache.hive.jdbc.HiveDriver");
String sql = "select * from hello.gg";
Connection conn = DriverManager.getConnection(url, "test", "123456")
PreparedStatement ps = conn.prepareStatement(sql);
ResultSet rs = ps.executeQuery();
while(rs.next()) {
int id = rs.getInt("id");
String sname = rs.getString("sname");
String LastName = rs.getString("LastName");
Timestamp t = rs.getTimestamp("dob");
System.out.println("id->" + id +"\tsname->"+ sname + "\tlast_time->" + LastName +"\tODB->" + t);
}
rs.close();
ps.close();
}
private void initH2Kerberos() {
org.apache.hadoop.conf.Configuration conf = new org.apache.hadoop.conf.Configuration();
try {
String krb5 = "你的krb5.conf 文件的绝对路径";
String keytab = "你的 krb5.keytab 文件的绝对路径";
String principelName = "hive/[email protected]";
initKerberosEnv(conf, principelName, keytab, krb5);
} catch (Exception e) {
System.out.println("初始化kerberosInitor失败");
e.printStackTrace();
}
}
public static void initKerberosEnv(Configuration conf, String principalName, String keytabPath, String krb5ConfPath) throws Exception {
System.setProperty("java.security.krb5.conf", krb5ConfPath);
conf.set("hadoop.security.authentication", "Kerberos");
System.setProperty("java.security.krb5.conf", krb5ConfPath);
UserGroupInformation.setConfiguration(conf);
UserGroupInformation.loginUserFromKeytab(principalName, keytabPath);
}
|
参考