卡内基梅隆的数据库课程-1
课程地址
https://15445.courses.cs.cmu.edu/fall2021/schedule.html
Backgroup
A database management system (DBMS) is software that allows applications to store and analyze information in a database.
A general-purpose DBMS is designed to allow the definition, creation, querying, update, and administration of databases.
发展历史
- 早起的数据存储、数据管理是 紧耦合的
- 1960年代末期,有学者提议将数据和操作分离
- 1970年代,codd 提出了关系模型,将存储和操作分离,并提供了高级操作API
- 访问是通过高层语言,DBMS找到最佳的访问策略,物理存储留给DBMS实现
数据模型
- Relational Most DBMS
- Key/value nosql
- Graph
- Doucument
- Column-family
- Array/Matrix machine learning
- hierarchical obsolete/legacy/rare
- network
- multi-value
Current standard is SQL:2016
- SQL:2016 → JSON, Polymorphic tables
- SQL:2011 → Temporal DBs, Pipelined DML
- SQL:2008 → Truncation, Fancy Sorting
- SQL:2003 → XML, Windows, Sequences, Auto-Gen IDs.
- SQL:1999 → Regex, Triggers, OO
将查询结果保存到另一个表中
|
|
子查询很难优化
- ALL,Must satisfy expression for all rows in the sub-query.
- ANY,Must satisfy expression for at least one row in the sub-query.
- IN,Equivalent to ‘=ANY()’ .
- EXISTS,At least one row is returned.
关系代数


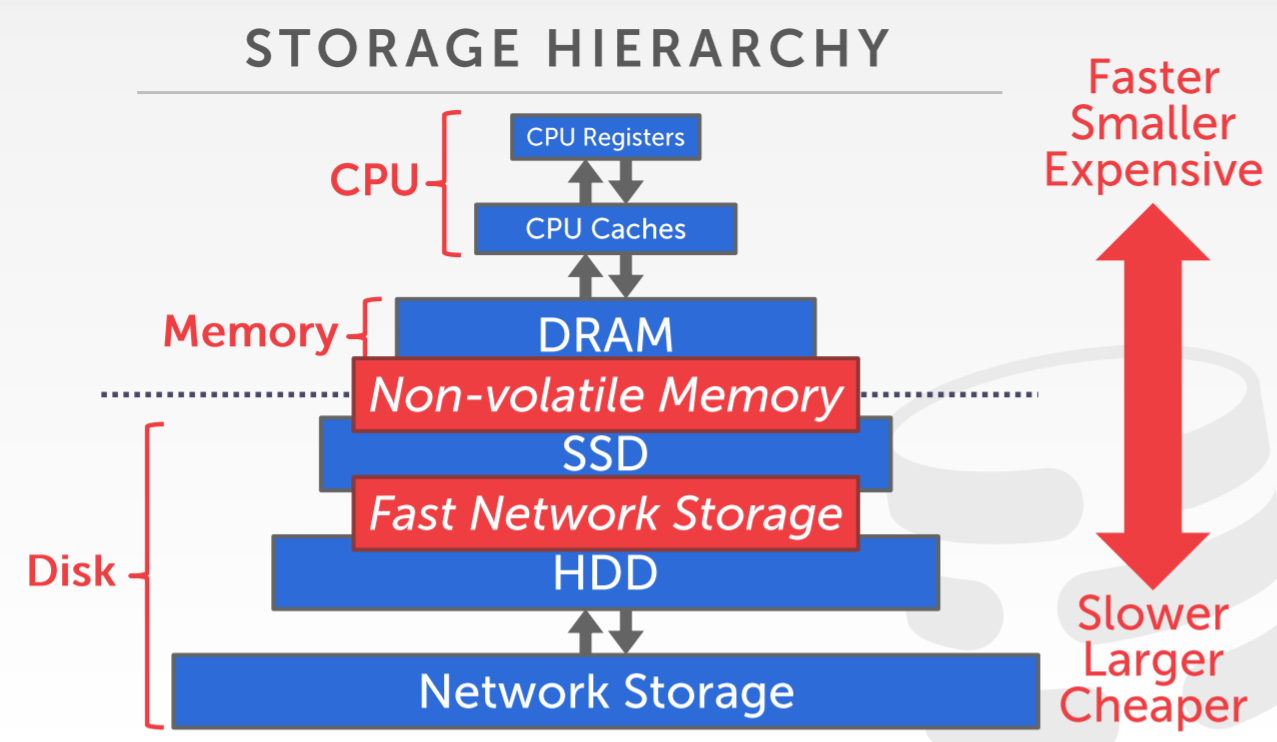
数据库的层次结构

相关文章
- Derivability, redundancy and consistency of relations stored in large data banks
- A relational model of data for large shared data banks
- SQL 1992
Database Storage
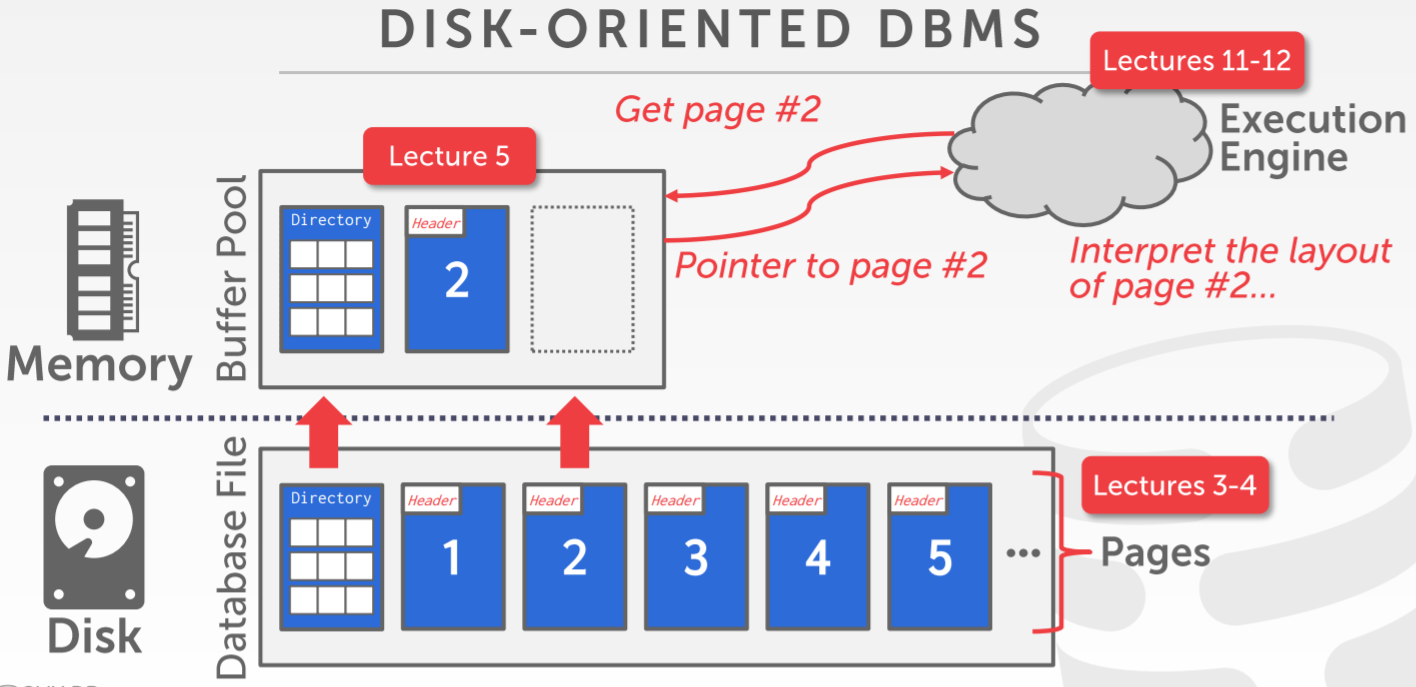
用 OS来管理内存
- mmap来映射文件内容,到用户程序地址空间中
- OS 负责in/out内存
OS管理内存的问题
- 只读会很好,并发情况下不好处理
- madvise,告诉OS期待读的特定page
- mlock,一段内存不要换出
- msync,将内存flush到磁盘
- flush脏页
- 指定的预抓取
- buffer替换策略
- 线程、进程调度
- DBMS根据SQL得到查询计划,可以更好的管理内存: 内存分配、预抓取、驱逐策略
数据库的page布局
- 硬件一般是4K
- 数据库 512B - 16K
- Oracle 4K、SqlServer/PG 8K、MySQL 16K
page的文件布局方式
- linked list布局
- page directory布局
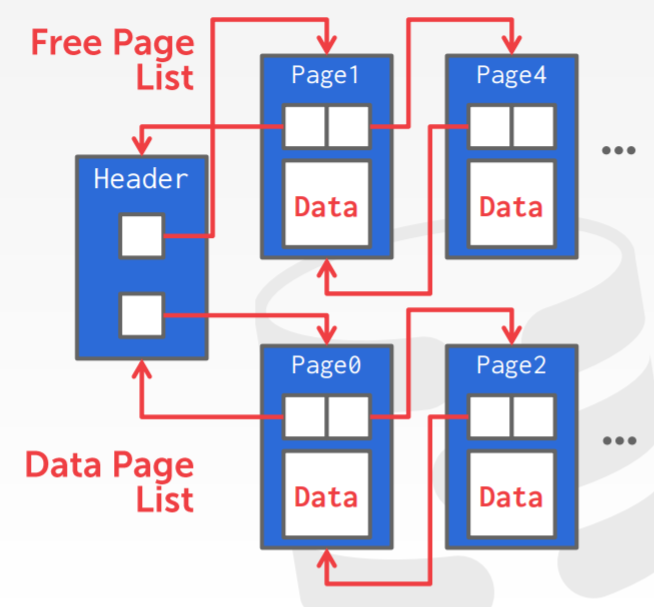
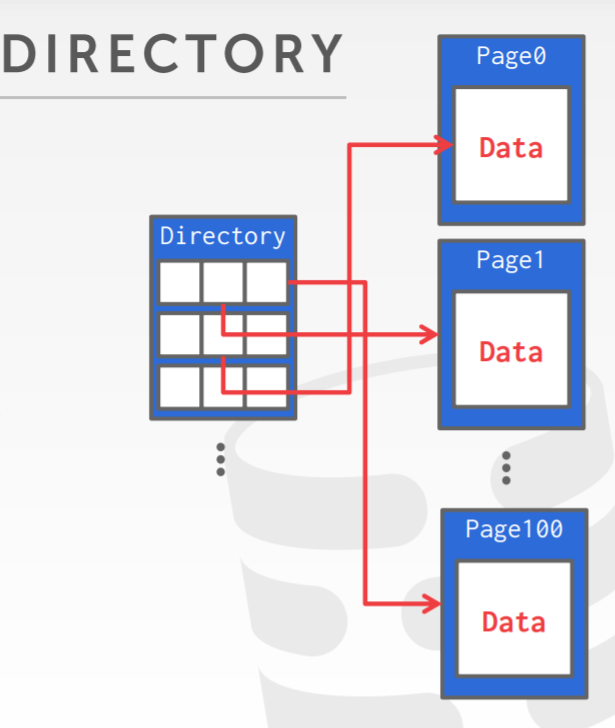
页布局方式
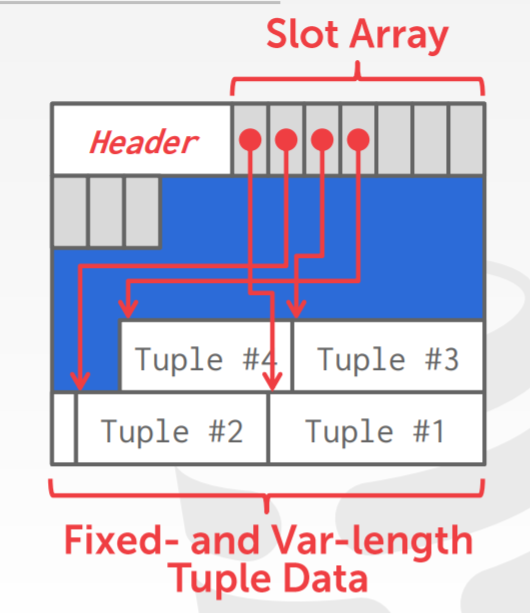
- slotted pages
- 每个数据库都会包含一个唯一ID,page_id + offset/slot 组成的
- log-structured file organization
- level compaction
tuple 布局
- 本质上市一系列的byte
- DBMS的任务是解释这些字节到 属性和值中
- DBMS的catalog包含关于表的schema信息,使用这些信息,系统就可以找到表的布局
- 物理的非规范化表示,关联的tuple存储在相同page中
- 比如foo表和bar表,bar表的外键指向foo表主键,将foo表内容全部内嵌到bar表中
- 通常可以减少I/O数量,但update代价更高
- Not a new idea, IBM System R dis this in 1970s
- Several NoSQL DBMSs do this without calling it physical denormalization


日志结构合并树

数据表示
- decimal类型,底层是用各种int存储的
- int ndigist、int weight、int scale、int sign
- pg的decimal表示
- mysql的decimal表示
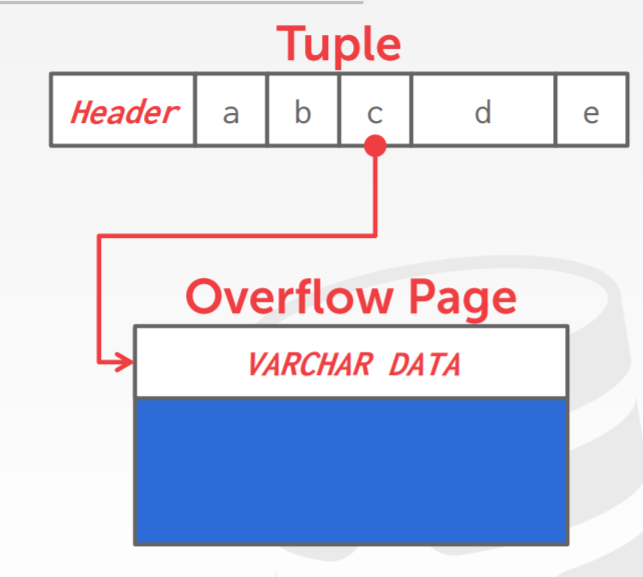
- 超长的值,用 overflow存储页实现
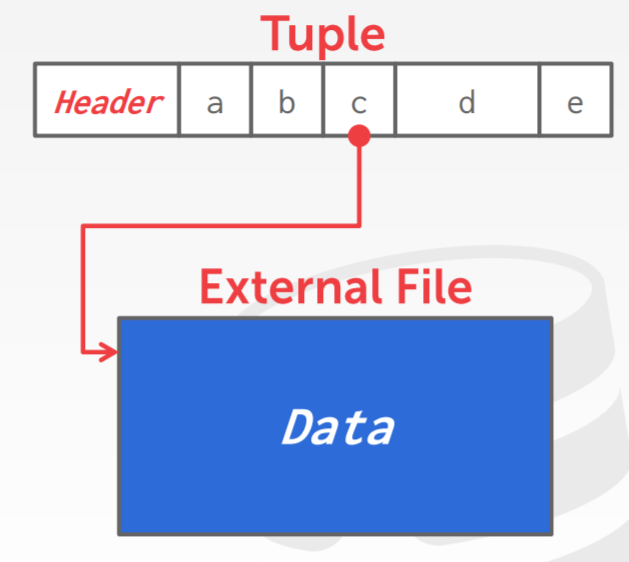
- 外部数据存储,如Oracle的BFILE类型,指向一个外部文件,但DB不负责管理此文件

大值的存储
- DBMS使用了一个独立的页,overflow,来存储这个page
- 将大值存储在一个额外的文件中,当做BLOB类型
- Oracle BFILE数据类型,SQLServer的FILESTREAM 类型
- 数据库不管理这些额外文件的内容,没有持久化保证,没有事务保证
系统catalog
- 存储数据库的元数据到内部catalog中
- 表、列、索引、视图
- 用户、权限,内部统计信息
- 对这些tuple做包装抽象
- 特殊的代码寻找这些catalog表
系统catalog,标准SQL 92语法
|
|
各种场景
- OLTP
- OLAP
- HTAP
数据存储模型
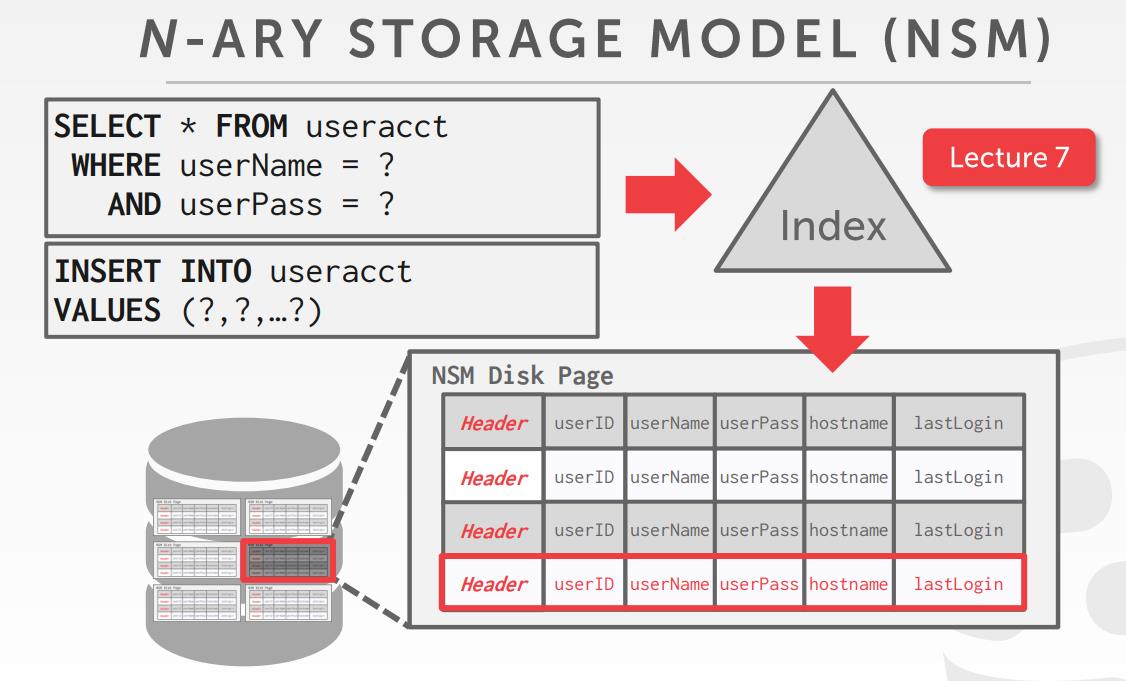
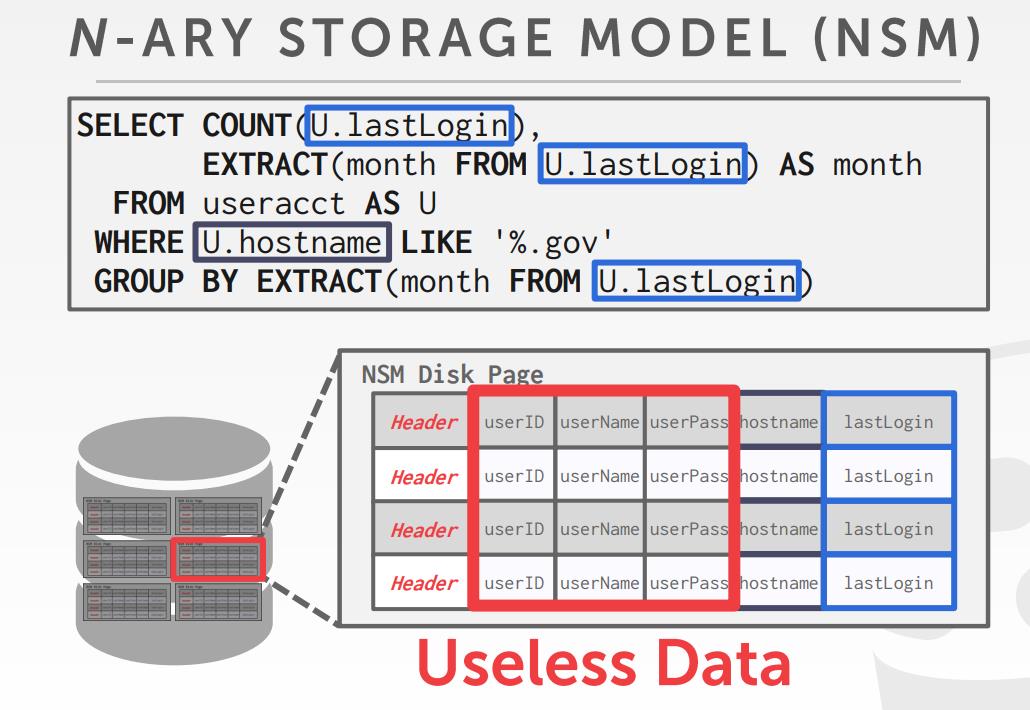
- N-ary storage model NSM,适合行存
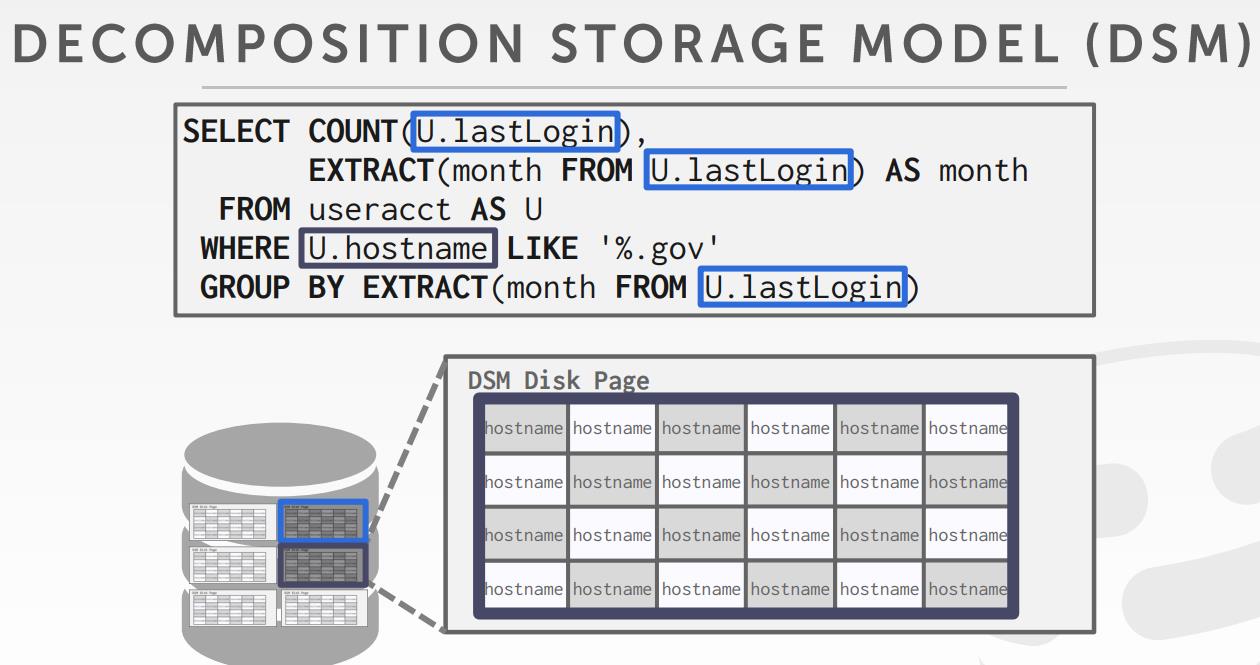
- decomposition storage model DSM,适合列存
N-ary的存储模式
- 适合快速的增删改查
- 对于需要整个tuple的场景也合适
- 对于需要扫描表的大部分数据则不合适
- 对于只查找部分属性也不合适
decomposition storage model存储模式
- 减少了总I/O数量,DBMS只需要读取需要的数据
- 更好的查询处理和数据压缩
- 对于点查、insert、update、delete都比较慢,因为tuple需要分解、缝合


相关文章
- Non-Volatile Memory Database Management Systems
- IEEE754
- To BLOB or Not To BLOB: Large Object Storage in a Database or a Filesystem
- A Query Processing Strategy for the Decomposed Storage Model
Buffer Pool
目标
- 让经常一起使用的页,物理布局尽可能靠近
- 尽量减少读/写 地盘的次数
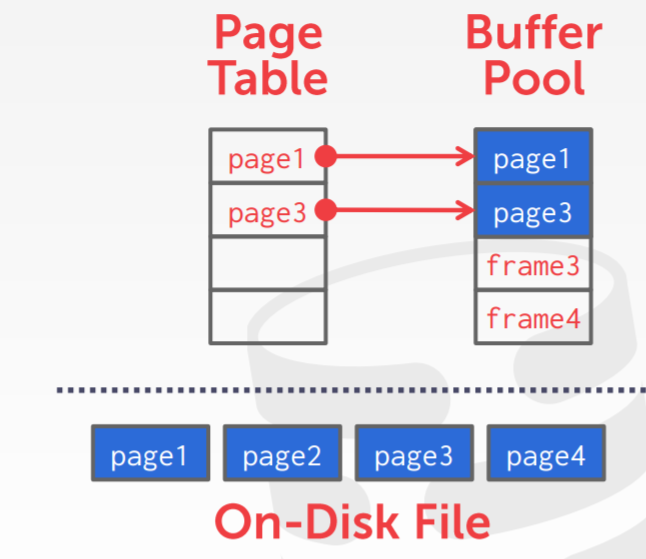
buffer pool
- 按照数组方式组织的,固定大小的多个页
- 一个数组条目叫做: frame
- page table维护了当前哪些页在内存中
- 也维护了一些元信息:脏页标记、固定页(不换出)、引用计数
locks vs latches
- 锁在事务时保护数据的逻辑;锁闩包含并发时数据内不会被其他线程写坏
- 锁只在事务中;锁闩在更长时间内
- 锁需要能被rollback;锁闩不需要
page table VS page directory
- 页字典维护了:数据库文件中 page id 到具体位置的映射,需要写入到磁盘
- 页表:page id 到缓冲池frame的映射,不需要持久化
分配策略
- 全局策略,对于所有活跃的事务
- 本地策略,分配frame对于一个指定的事务,但仍需要支持共享page
buffer pool优化
- 多个buffer pool,如每个数据库的buffer pool,每个页类型的buffer pool
- 预抓取
- scan共享
- buffer pool bypass
多个buffer pool
- 一条记录如何找到一个固定的buffer pool的?
- 通过object id
- 通过hash, GET RECORD 123,计算 hash(123)%n,找到具体的缓冲池
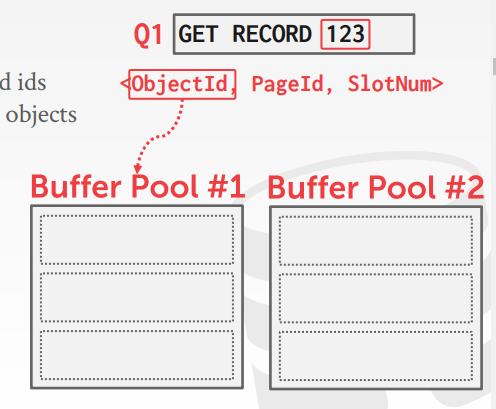
预抓取
- 基于查询计划,可以提前抓取一些页
- 顺序扫描
- 索引扫描
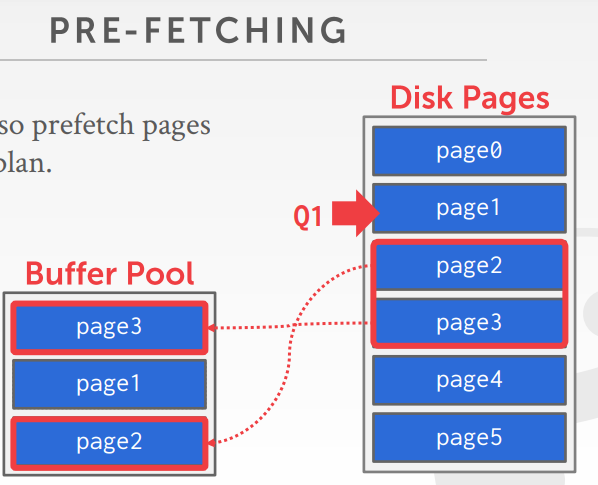
基于索引的预抓取,假设有如下SQL
|
|
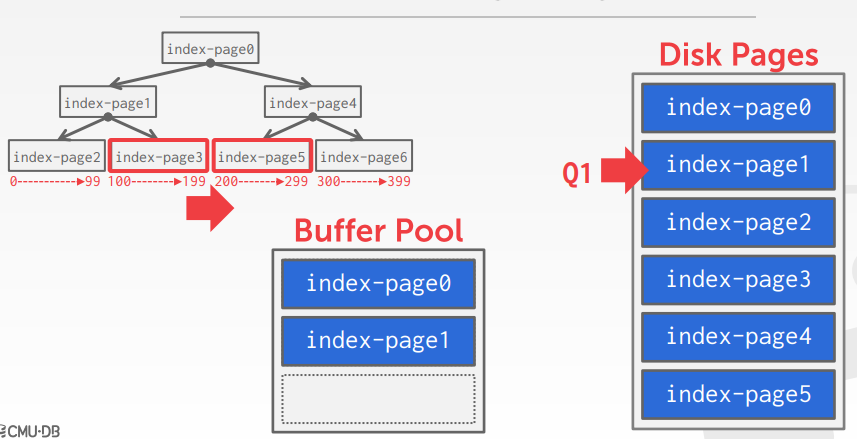
如上,在扫描索引时,会加载 index-page0、index-page1,之后就会把 index-page3、index-page5都加载到内存中
scan共享
- 查询可以重用 存储、操作计算的数据检索
- 也叫作 synchronized scans
- 跟结果缓存不同
- 可以让多个线程附属到一个scan游标上,Oracle、PG、mysql
- 查询可以不是相同的
- 可以共享中间结果
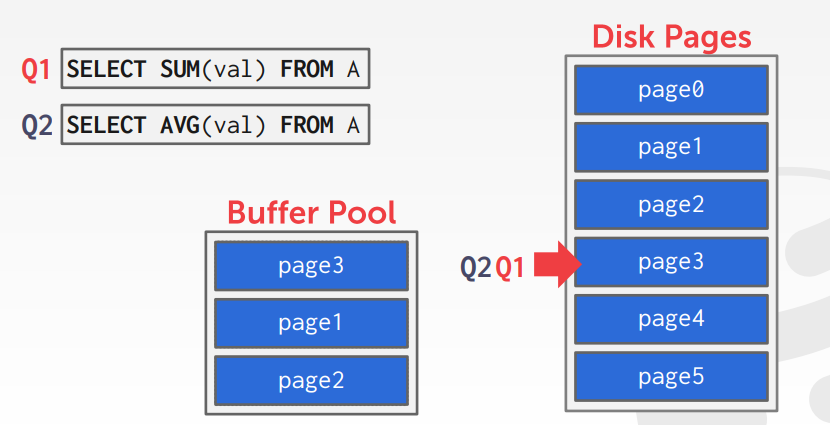
如上,查询1当前已经将 page-3、page-1、page-2放入了缓冲池中
查询2 来了,可以共享之前的页,注意看 查询2和查询1不是完全相同的,但是可以重用一些页
于是查询2 共享了查询1的游标
buffer poll bypass
- 需要大量顺序扫描,此时页会不断的放入内存,造成不必要的开销
- 本地内存查询
- 临时文件,如排序,join时候
OS page
- 默认情况下,读取文件时,操作系统会将其缓存
- 使用裸OS,O_DIRECT可以绕过操作系统缓存
- 避免重复拷贝
- 需要定义自己的驱逐策略
PG的一个查询例子
- SELECT pg_prewarm(’testreals’)
- SHOW shared_buffers;
buffer替换策略
- 目标:正确性、准确性、速度、元数据的开销
- LRU算法
- clock算法,类似于LRU,但是不需要每个页指明timestamp
- 每个页都有一个bit引用,当访问时设置为1
- 组织页为一个环形buffer类似时钟,当清扫时碰到1设置为0,碰到0时则驱逐
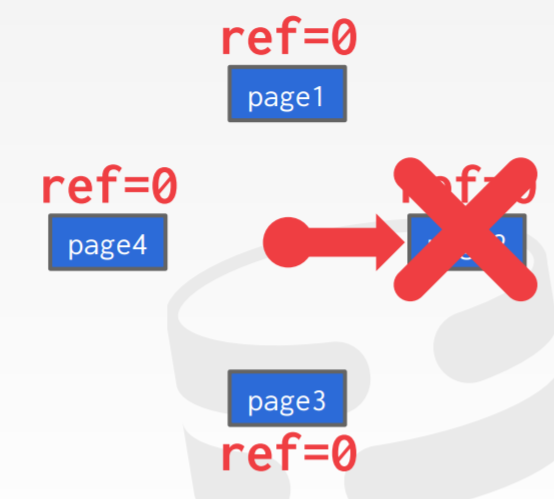
如上,clock算法,顺时针扫描每个页,page1一开始是1,然后被设置为0,之后扫描到page2位0,将其驱逐
如果每个页都是1,那么一轮下来之后,12点方向的页因为被置0了,会被驱逐
问题
- LRU和clock都会出现 sequential flooding 问题
- 顺序扫描大量页时,会造成buffer pool的污染,某些页可能就读一次,以后不再读了
更好的策略
- LRU-K
- 以时间戳的形式,记录每个页面最后K次引用的历史,并计算后续访问之间的间隔
- DBMS之后使用历史来估算下次被访问的时间
- localization
- 根据每个请求、事务来决定要驱逐的页面,可以将buffer pool的污染最小化
- PG管理一个小的环形buffer来私有化处理查询
- priority hint
- DBMS知道查询的上下文,可以将这个信息提供给buffer pool,判断这个页面是否重要
脏页
- 如果buffer pool中的页面不是脏的,可以简单的删掉,很快
- 脏页需要写入到磁盘,保证持久化,较慢
- 需要在 快速删除,未来可能不会再读的脏页 之间做出权衡
- 脏页被安全的写到磁盘后,DMBS可以驱逐脏页,也可以只设置脏页的flag
- 在写脏页之前,需要先记录log
其他的 内存池
- 他们不一定是基于磁盘的,看具体实现
- 排序、join buffer
- 查询 cache
- 维护buffer
- 日志buffer
- 字典cache
相关文章
- Shared Scanning in Postgres
- Version and Platform Compatibility
- Google C++ Style Guide
- Documenting the code
- Light scans
- O_DIRRECT
Hash Table
主要目标
- 内部元数据
- 核心数据存储
- 临时数据结构
- 表索引
设计要点
- 将大量的key映射到一个较小的空间中
- 快速访问和冲突比列 之间做出权衡
- 冲突之后如何处理
- 分配大hash表 和 额外的find/insert key指令 之间做出权衡
hash function
- CRC-64 (1975),Used in networking for error detection.
- MurmurHash (2008),Designed as a fast, general-purpose hash function.
- Google CityHash (2011),Designed to be faster for short keys (<64 bytes).
- Facebook XXHash (2012),From the creator of zstd compression.
- Google FarmHash,(2014)Newer version of CityHash with better collision rates
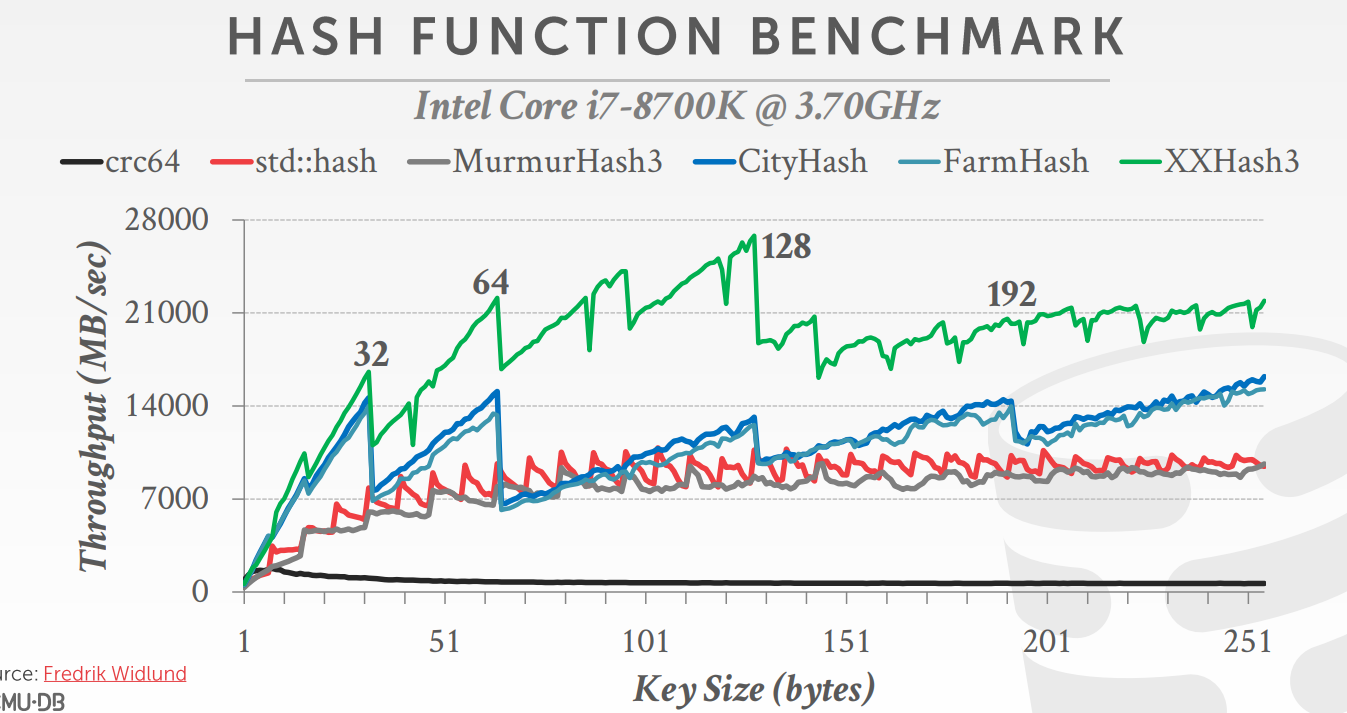
不同hash函数的性能测试
static hash schema
- Approach #1: Linear Probe Hashing
- 冲突时继续往下探测
- 删除元素用墓碑替代,这样查找冲突时,就会继续往下探测
- 或者直接删除,将后面的元素全部往前移动
- Approach #2: Robin Hood Hashing
- 是 线性探测的变种,每个槽位包含了:离最佳位置的距离
- 如果新元素的 距离 > 旧元素的距离,则旧元素需要重新挪位置,让位给新的
- Approach #3: Cuckoo Hashing
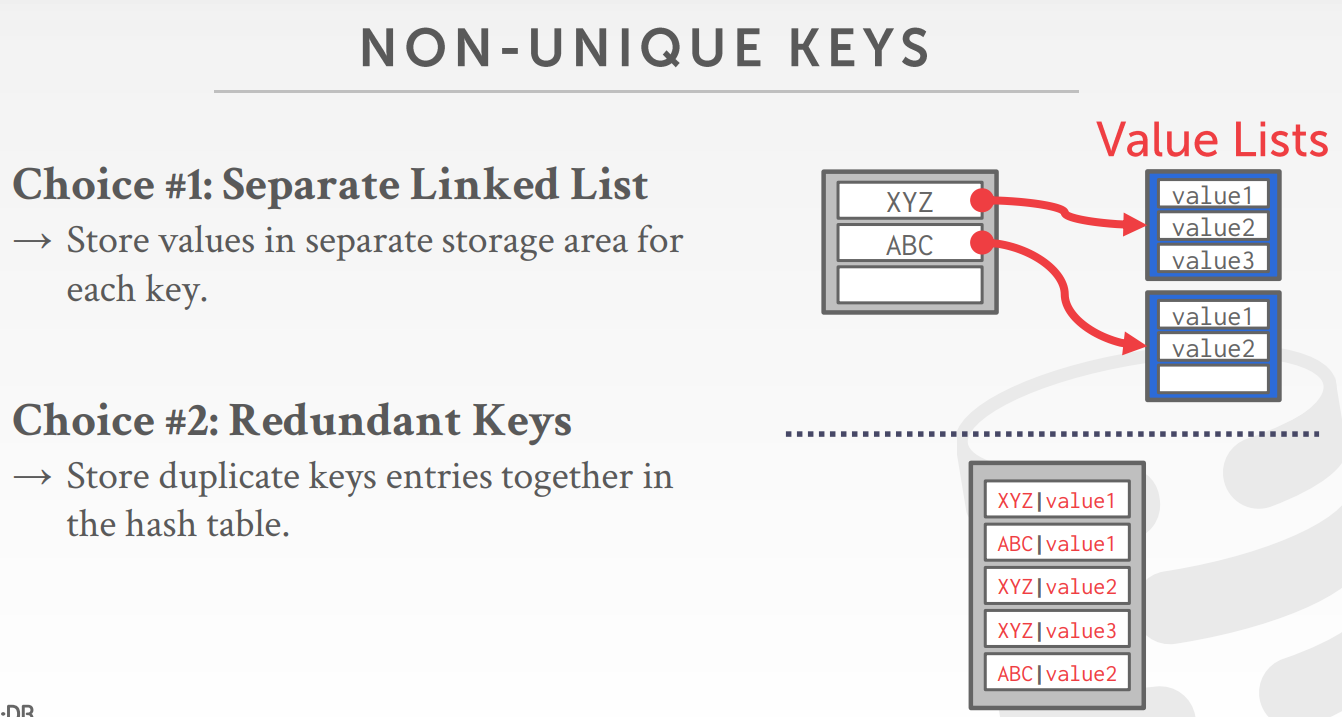
非唯一key的处理方式
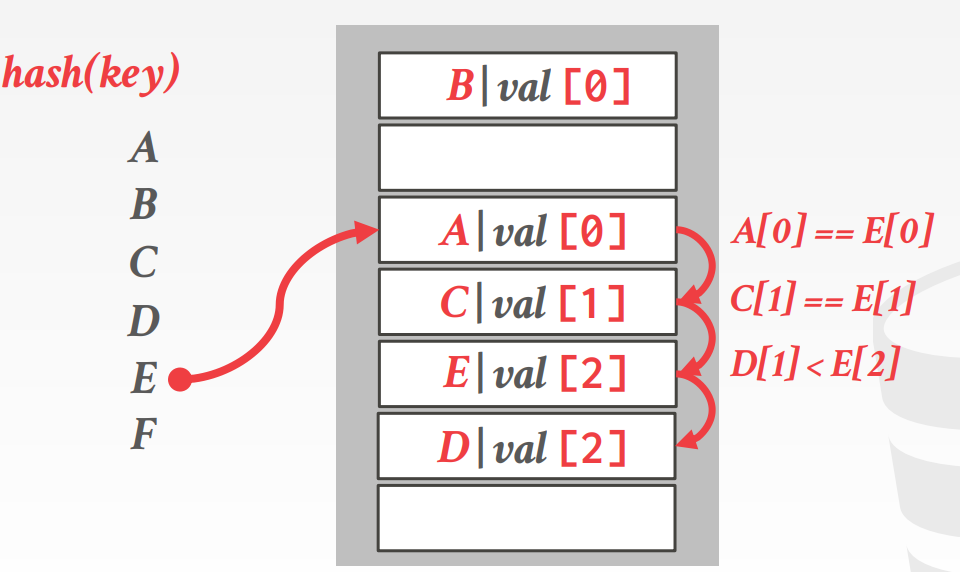
罗宾汉hash的例子
E的hash跟A冲突了,A的距离是0,再往下找,C的距离是1
再往下此时D的距离是1,小于E(2),将D的位置插入E,再重新寻找D的位子
罗宾汉hash的好处是,可以让所有的key距离更均衡,相当于做了 rebalance
cuckoo hash冲突的例子如下:
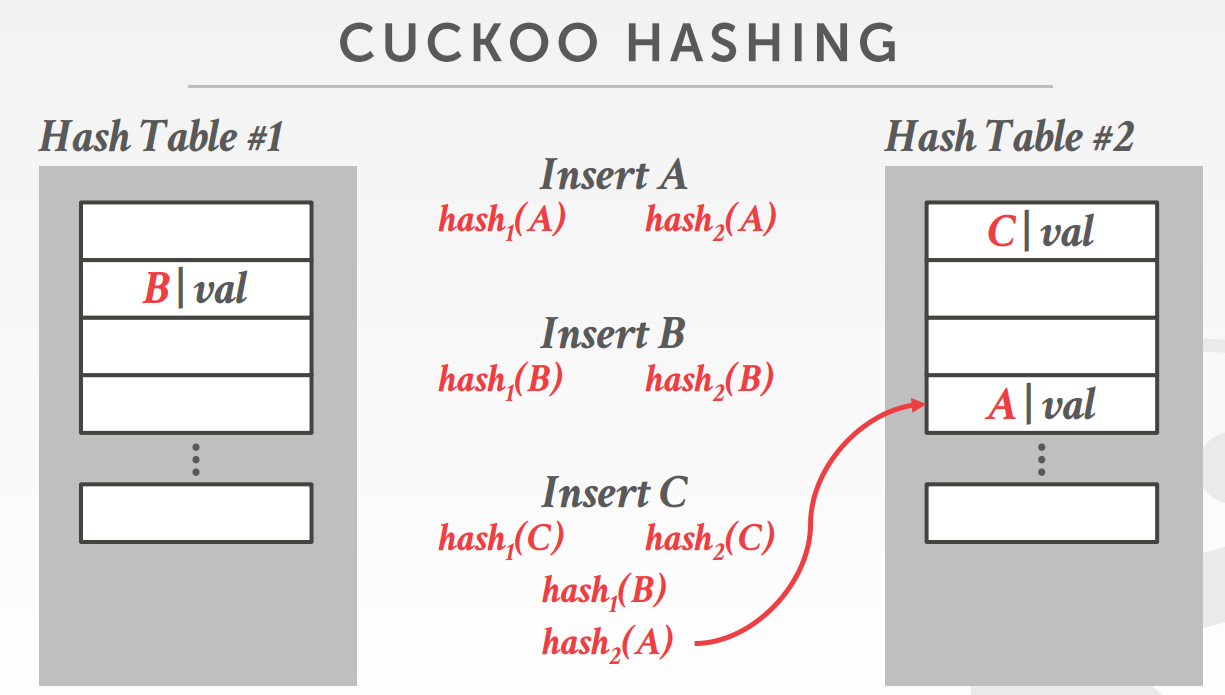
A 和 B 都找到了合适的位置,此时 insert C,hash1和hash2计算出来的都冲突
hash1跟A冲突, hash2跟B冲突
于是将B替换为C,重新计算B
B计算出来的位置是原先A的位置,于是将 A 替换为B
最后重新计算A的位置,于是放入第二个hash表中,整个过程完成
dynamic hash schema
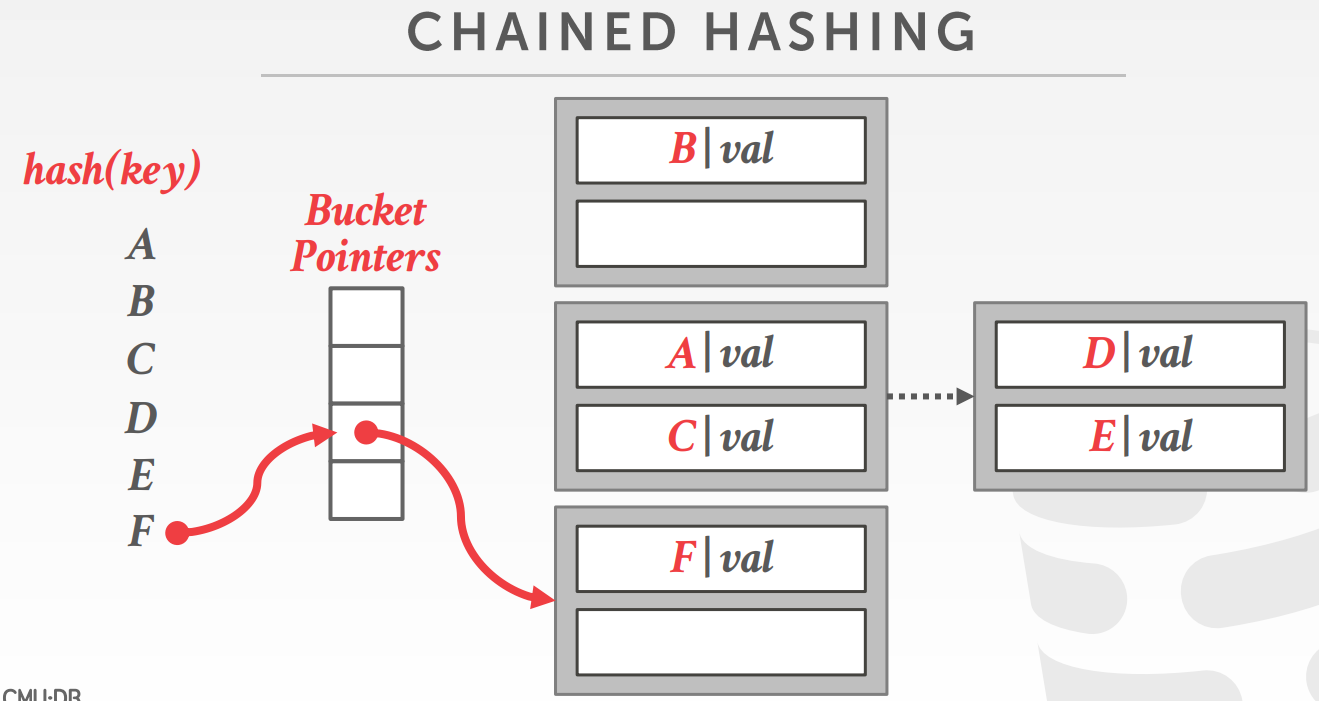
- Chained Hashing
- 为哈希表中的每个槽维护一个桶链表
- insert和delete泛化为lookup
- Extendible Hashing
- 链式hash的方式需要split桶,而不是让其无限增长
- 在拆分的时候需要重新shuffle
- Linear Hashing
链式hash,每个键对应一个链表,每个节点是一个桶
桶中装着发生冲突的元素,当桶满了,就再往后挂一个
最坏的情况,可能会退化成链表
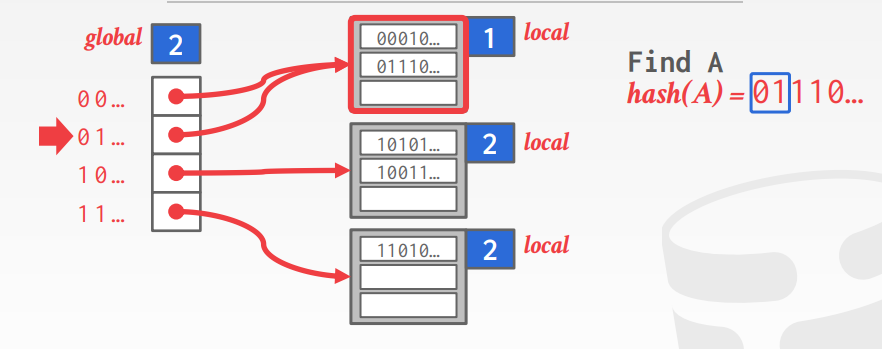
可扩展的hash(如下图)
有一个可扩展的目录数组,相当于指针
global表示全局深度,loal表示桶的局部深度
如果local深度小于glocal深度,则只需要扩展local部分的,将local的桶一分为二即可
查找时,根据hash函数得到的整数 y, 对y的二进制取前global位,不足的补0
如下,根据hash函数和global得到 01,去01桶里面取,在桶里面挨个比较就能得到最终值了
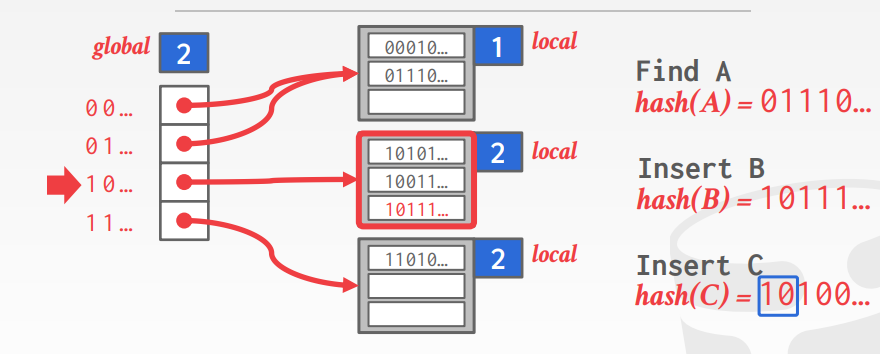
插入时,如果local的深度不够了,则+1,如果此时local深度 > global深度,则整个 global槽位需要范围扩容
扩容后需要重新做hash
线性hash,如下图
用一个针跟踪下一个 bucket 的分裂点
当任何一个bucket溢出时,在指针点的位置做分裂
对于给定的key,使用多个hash函数来找到合适的位置
分裂的标准有很多,比如空间利用率、链的溢出平均长度等
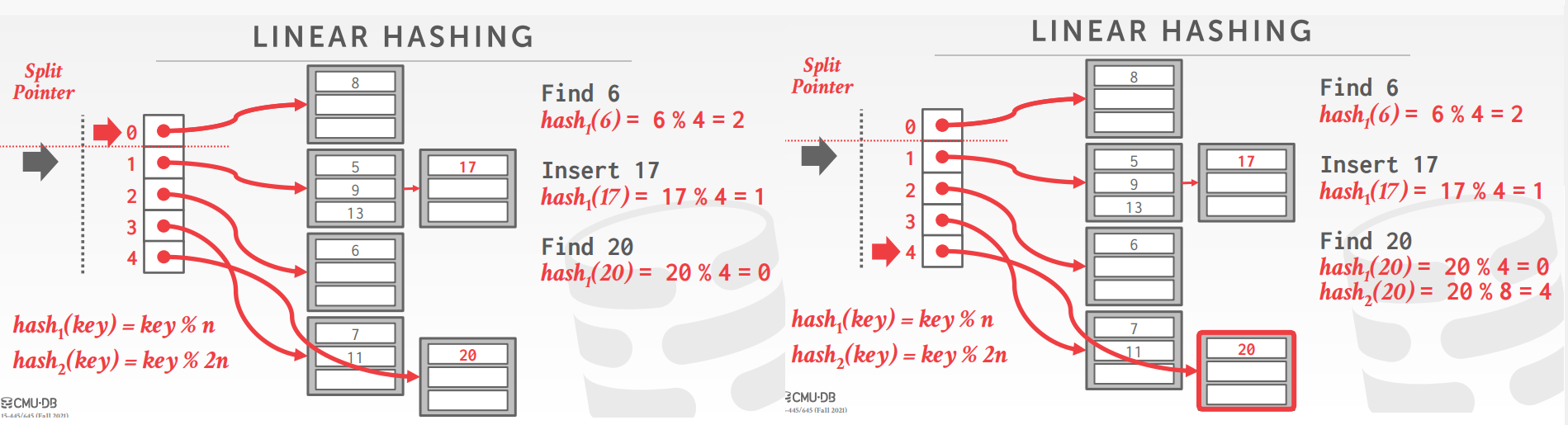
如上,一开始的分裂指针指向0,之后bucket1 溢出,然后将bucket0分裂
将bucket0 的20重新hash,放到bucket4的链表后面
相关文章
Table Index
A table index is a replica of a subset of a table’s attributes that are organized and/or sorted for efficient access using those attributes.
The DBMS ensures that the contents of the table and the index are logically synchronized.
DBMS根据查询计划,找到最合适的索引
权衡每个创建的索引数量,存储开销、维护开销
B树家族
- B-Tree (1971)
- B+Tree (1973)
- B*Tree (1977?)
- B link-Tree (1981)
B+树
- 一种自平衡的树 数据结构,维护了数据有序性
- 支持查找、顺序访问、查询、删除,时间复杂度 O(logN)
- 通过读/写 大数据块来做优化
- 完美平衡的,每个页节点都有相同的深度
- 除了root外,每个节点至少是半满的,
M/2-1 <= #keys <= M-1
页节点的值
- 方式1:指向 索引项对应的元组位置的指针;PG、SqlServer、DB2、Oracle
- 方式2:页节点存储真实的元组内容,二级索引以记录ID作为它的值;SQLLite、MySQL、SqlServer、Oracle
查找方式,查找 index(A,B)
以及查找 index(A,*)
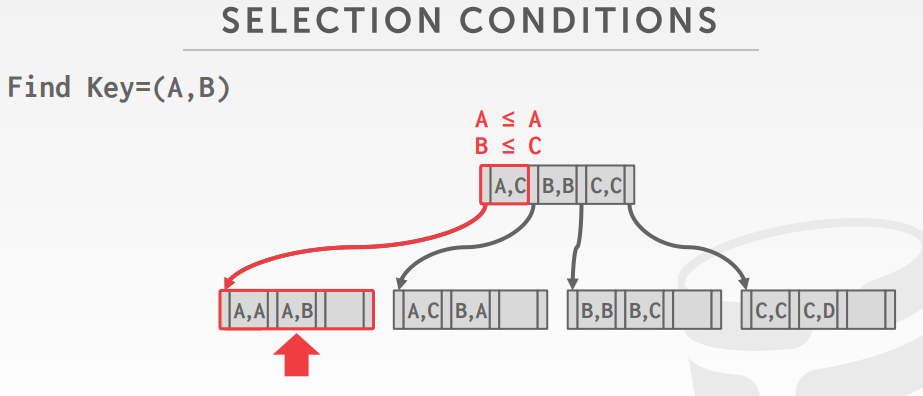
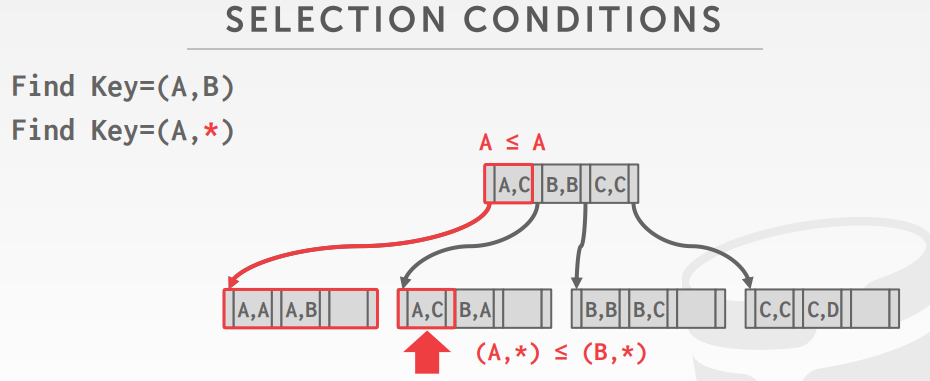
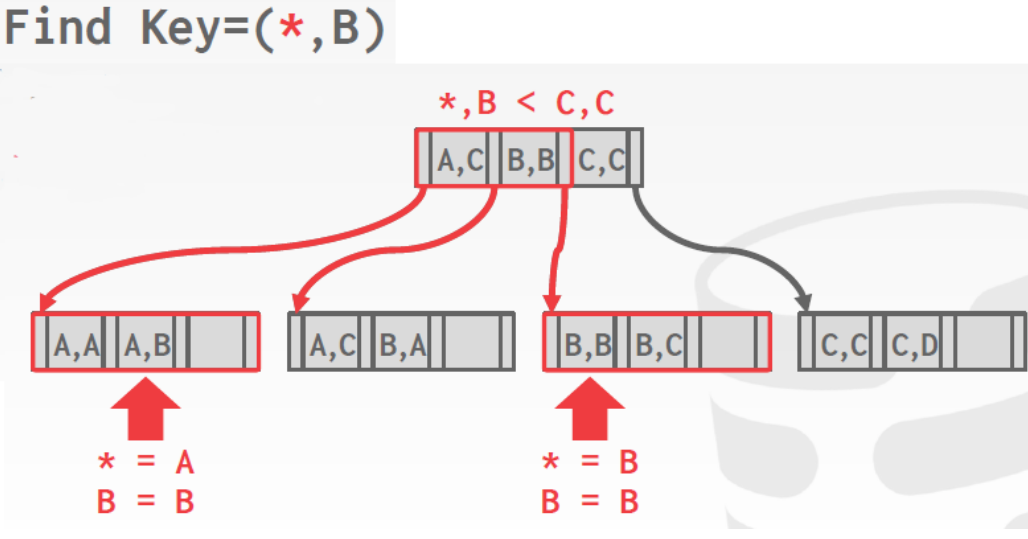
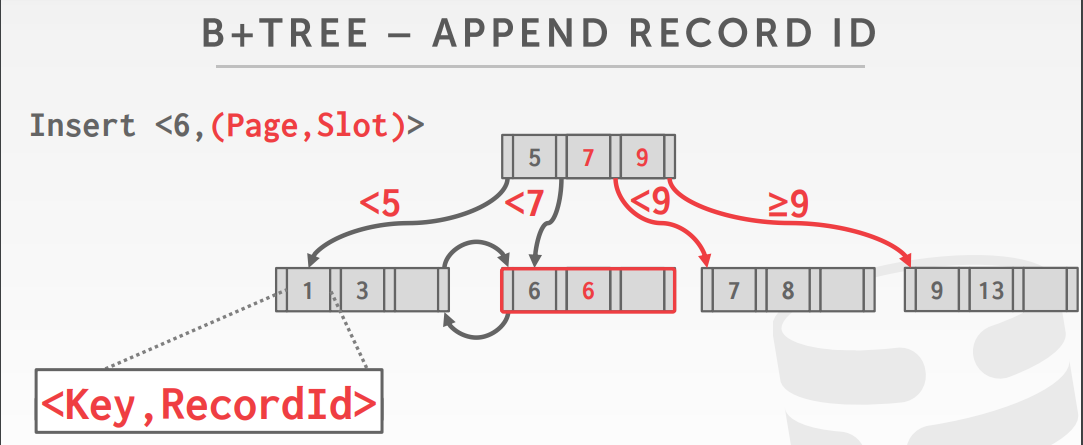
INSERT
- 找到页节点 L,将数据查询到L 中,并保持有序
- 如果L 的空间足够则返回
- 否则将L 拆分为 L和 L2,重新分布数据,以中间key作为分割点
- 在L的父节点中,增加一个指向L2的指针
DELETE
- 从root开始,找到页节点L,删除条目
- 如果L 至少是半满的,则返回
- 如果L 只有M/2-1个条目,则重新分布,从兄弟节点(相邻节点有共同父节点)借一个条目
- 如果重分布式失败,则合并L和兄弟节点
- 合并完后,从L的父节点中删除 指向L或者L兄弟的指针
实践中的B+树
- 填充因子 67%
- 能力,高度4: 1334 = 312900721 个条目
- 高度3: 1333 = 2406104 个条
- 每个级别的页大小
- Level 1: 1page = 8K
- Level2: 134pages = 1M
- Level3: 17956pages = 140M
- 估计4级 有18G
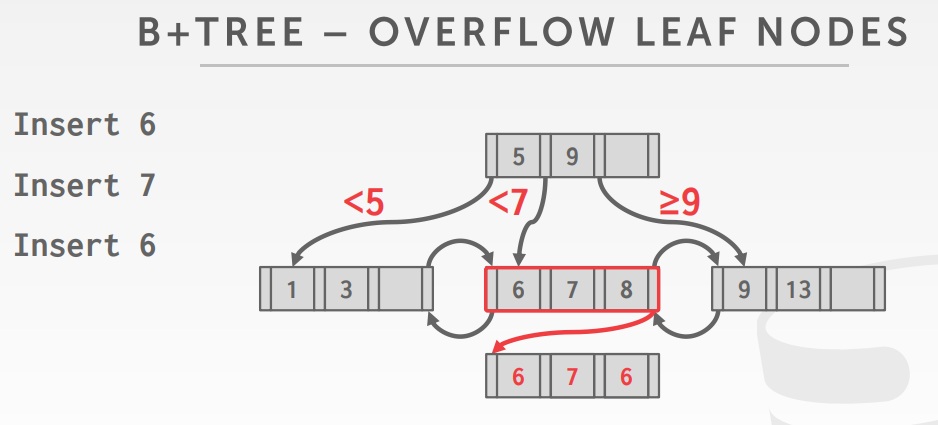
重复key的处理方式
- 在原有key基础上,增加一个额外的标识,如page+colt信息
- 页节点溢出到一个页记录这些重复记录,但会增加维护和修改的复杂度
聚集索引,主键索引,没有就默认建一个
非聚集索引,找到数据页id,然后再找到具体的数据页
B+树 的设计选择
- 节点大小
- HDD 1M; SSD 10K;memory:512B
- 非常依赖场景
- 页节点的scan vs root->leaft的扫描 使用的大小是不同的
- 合并的阈值
- 一些DBMS在页节点半满时,并不总是合并
- 延迟合并可以降低重新排列的数量
- 更好的方式:让小的节点存在,周期性的rebuild整个树
- 可变长度key
- 指针:将key当做指向元组的指针,并存储
- 变长节点:索引节点的每个大小都不同,需要很好的内存管理
- 填充:总是填充key类型的最大长度
- key map/间接的:内嵌一个指针数组,此数组映射到内节点的key+value的列表
- 内部节点查找
- 线性,从头扫描到尾
- 二分查找
- 插入式,根据已知的key分布,得到想要的key的大致位置

优化
- 前缀压缩,可能有很多变种
- 去重,非唯一索引可能会存多份,可以维护一个包含key的元组列表,类似hash table那样
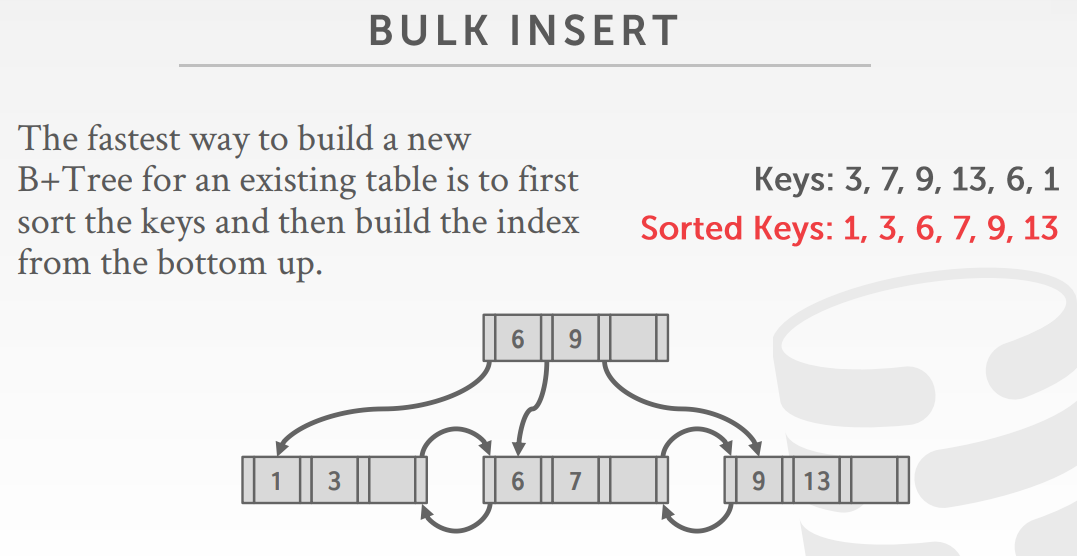
- bulk insert,基于现有的table构建一颗新B+树(最快的方式),先排序key,再字底向上构建
B+ 树的合并
- 离线合并,阻塞所有操作,直到合并完
- 访问期间合并,批量合并
- copy+merge 后台更新,应用缺失的更新
- 延迟,设置主页和其他二级页,在主页中则不更新,从对应的二级页中合并对应的key范围


创建部分索引,减少了I/O和管理开销,比如分区索引
|
|
覆盖索引,只需要查询索引即可,不需要查询tuples
|
|
内嵌索引,创建的列 c 不是索引的一部分,额外的字段存储在叶节点上
|
|
函数,表达式索引

观察:
- The inner node keys in a B+Tree cannot tell you whether a key exists in the index. You must always traverse to the leaf node.
- This means that you could have (at least) one buffer pool page miss per level in the tree just to find out a key does not exist.
Trie Index
- 使用key的数字表示,来一个一个的检测前缀,而不是比较整个key
- 也叫作:Digital Search Tree、Prefix Tree

Trie Index 特性
- 树的形状依赖于 key的空间和长度
- 不依赖存在的kye、或者插入顺序
- 不需要重新平衡操作
- 所有的操作需要 $O(k)$的时间复杂度,其中 k 也是 key的长度
- 到叶节点的路径表示叶的键
- key的存储是通过一条路径来表示的
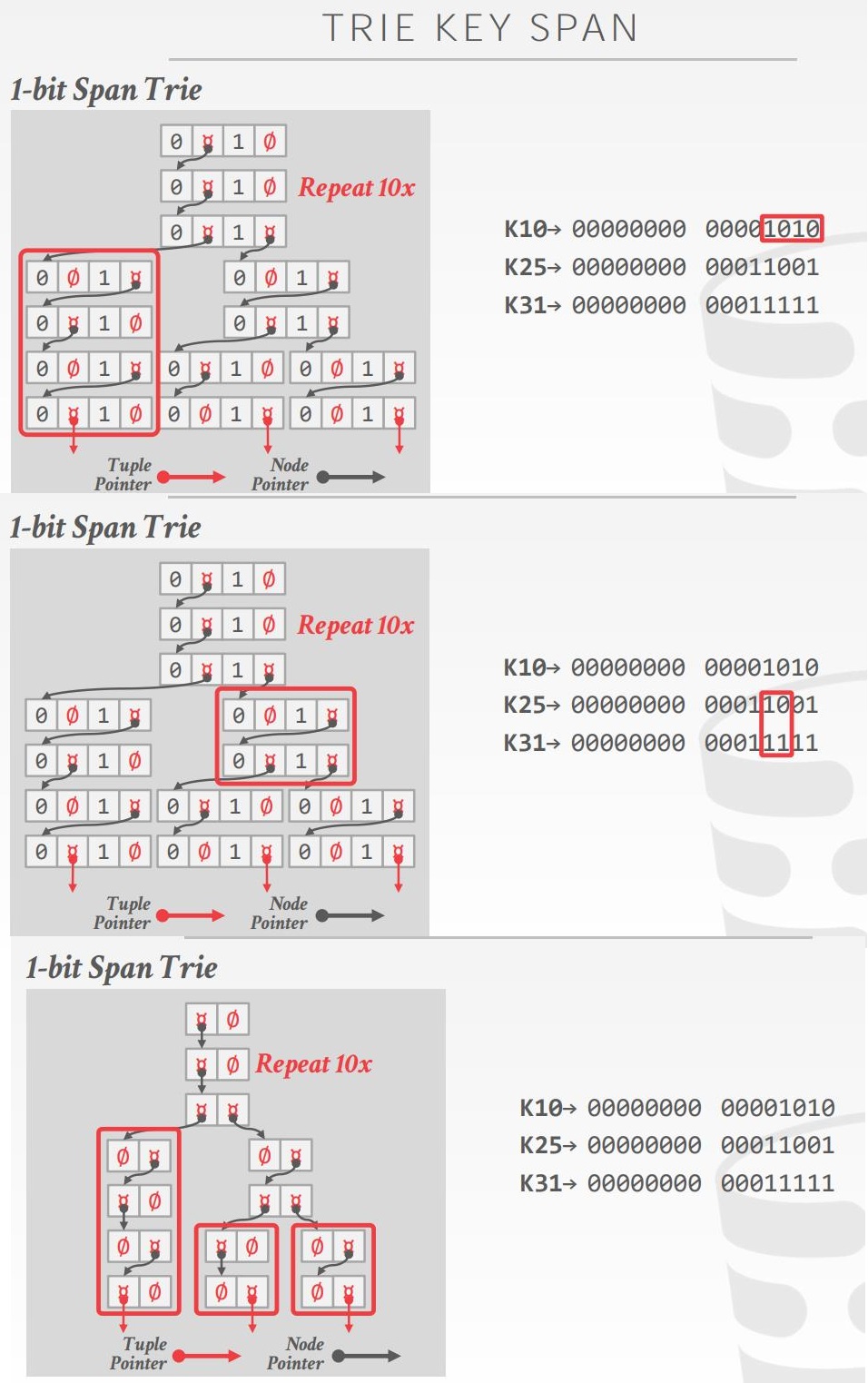
Tire Key span
- 这里的span,表示每个部分key/数字所表示的 bit数
- 如果该数字存在于这个块中,则trie分支的指针 指向下一级,否则存储空
- 这也决定了每个节点的 fan-out,以及树的物理高度
- n-way Trie = fan-out of n
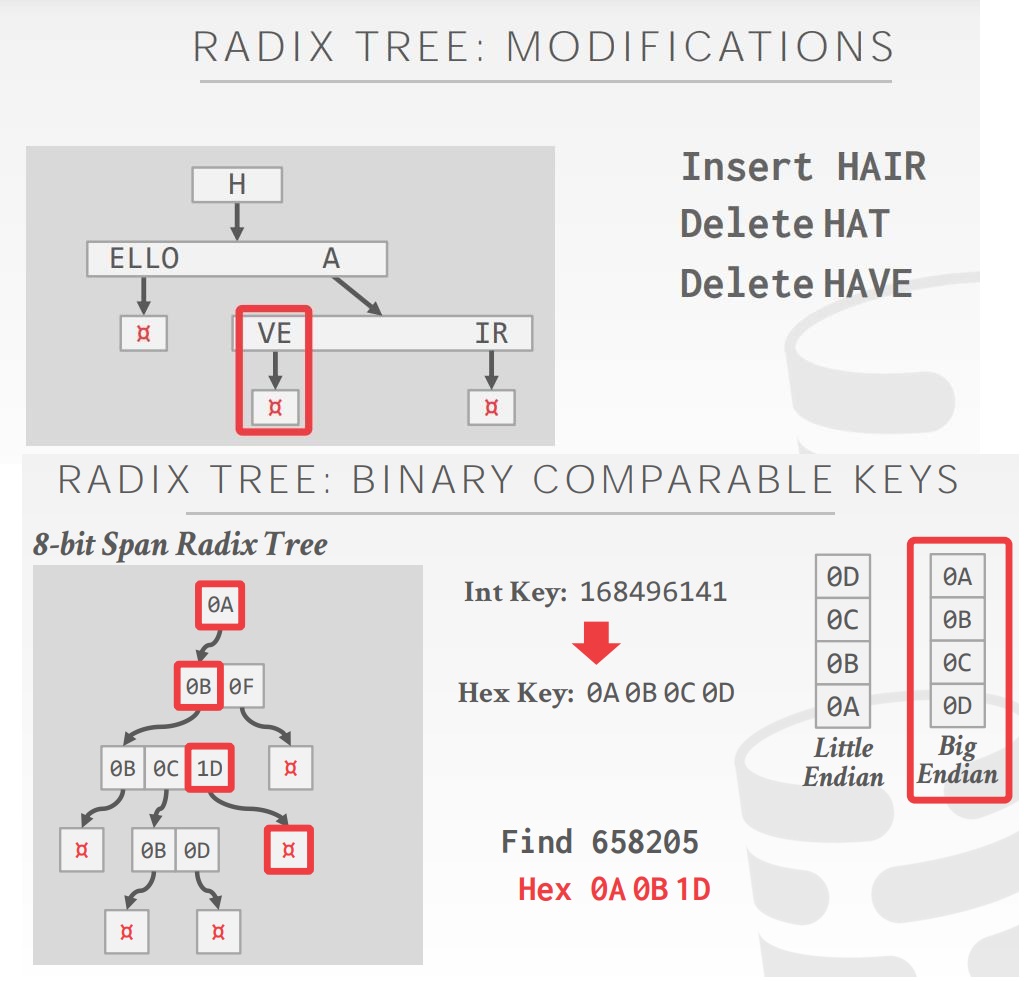
Radix Tree,前缀树主要存储字符串,基数树存储数字类型
不是所有的属性类型都能分解到 radix tree的二进制比较数字中
- 无符号整数,字节顺序必须反转为小端派
- 有符号的整数,反转两个补码,使的负数 小于 正数
- 浮点数,将其分组归类,如 负数vs正数,规范化vs非规范化
- 复合类型:转换为每个独立的属性
倒排索引
- 目前将到的 tree index,适用于 点查、范围查询
- 如查找所有zip code为15217的客户
- 查询在 2018-06 到 2018-09范围的订单
- 并不适合 keyword查询,比如查找维基百科中,包含 pavlo 的文章
- 倒排索引包含: 单词 到 目标端属性中包含这些单词的记录映射
- 也叫做:full-text search index.
- 在很古老的时代也叫做:concordance
- 很多DBMS都支持,也有专门的DBMS,如:
- Lucene、elasticsearch、Xapian、Solr、Sphinx
使用索引查询出来的并非我们想要的结果,而且效率还很差
|
|
倒排索引的查询类型、设计决策
- 短句搜索:查找包含给定顺序的单词列表 记录
- 邻近搜索:查找 N 个单词中出现两个单词的记录
- 通配符搜索:查找匹配某些正则表达式的单词记录
- Decision #1: What To Store
- 索引需要存储每条记录中至少包含的单词,由标点符号分割
- 也可以存储频率、位置、其他元数据
- Decision #2: When To Update
- 存储一些辅助的数据结构,以 分段更新,然后批量更新索引
其他
- 倒排索引课程 -> CMU 11-442
- 这里也没有讨论 空间树索引,如 R-tree,Quad-Tree,KD-Tree
- 这些包含在课程 -> CMU 15-826
相关文章
- Efficient locking for concurrent operations on B-trees
- Ubiquitous B-Tree
- Modern B-Tree Techniques
- Online B-Tree Merging
- Tree Indexes Part II
Index Concurrency Control
并发控制
- 逻辑正确性:让线程看到它期望看到的
- 物理正确性:内部的对象表示是否合理
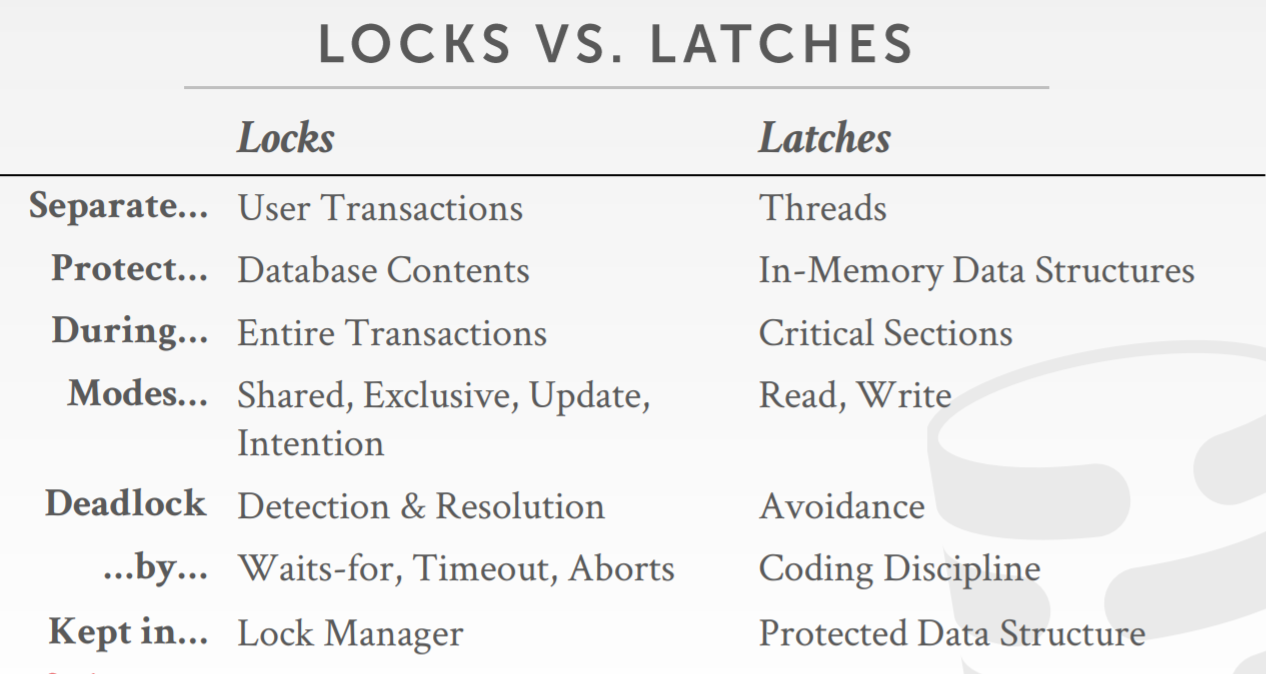
locks VS latches
- Protect the database’s logical contents from other txns.
- Held for txn duration.
- Need to be able to rollback changes
- Protect the critical sections of the DBMS’s internal data structure from other threads.
- Held for operation duration.
- Do not need to be able to rollback changes
lock vs latch的比较如下图:
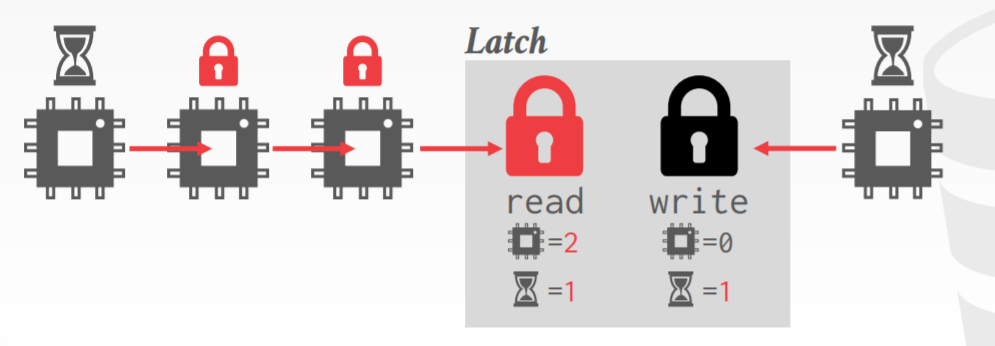
latch mode
- 读,多个线程可以同时读相同的对象
- 如果其他线程也是读模式,则当前线程可以获得 read latch
- 写,只有一个线程可以访问对象
- 如果有任何线程有读/写latch,则当前线程无法获取
latch 实现
- Blocking OS Mutex,依靠 pthread_mutex_t 实现加锁
- Test-and-Set Spin Latch,通过CAS的方式加锁
- Reader-Writer Latches,必须要有读/写队列避免饥饿,可以用spin latch来实现
mutex lock的实现
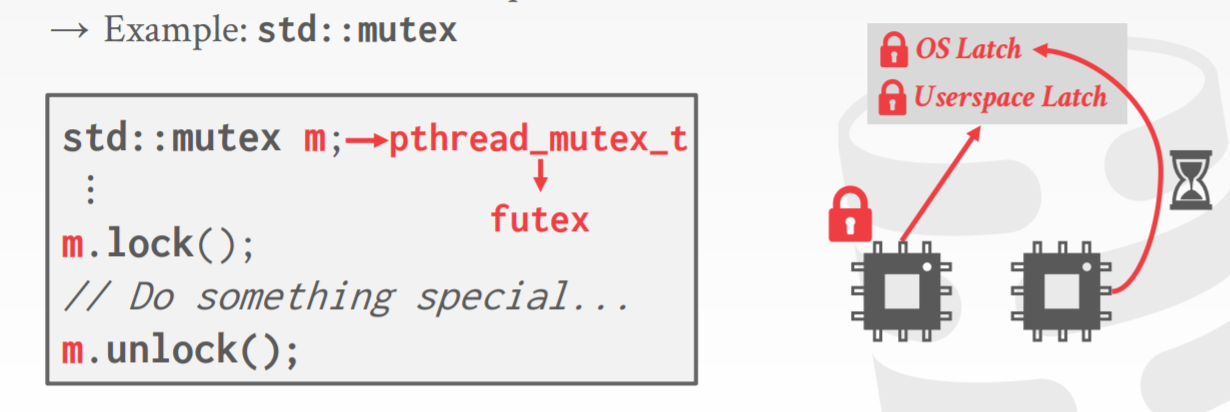
cas 实现

读写锁
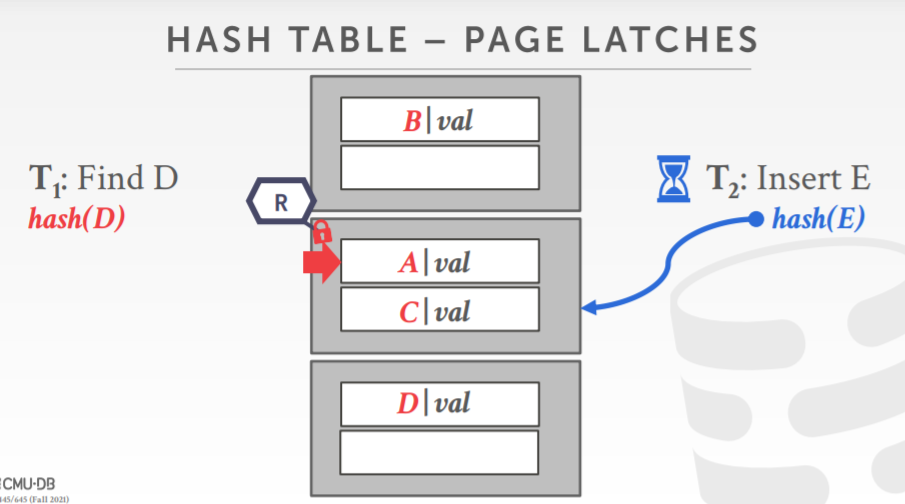
hash table latch
- 因为限制了访问方式,所以控制并发也容易了
- 只能在同一时间访问单个 页面/slot
- 不可能出现死锁
- 为支持扩容,需要有一个全局写锁
- page latch,每个页都有它自己的读/写latch,请求只能获得一个读、后者写锁
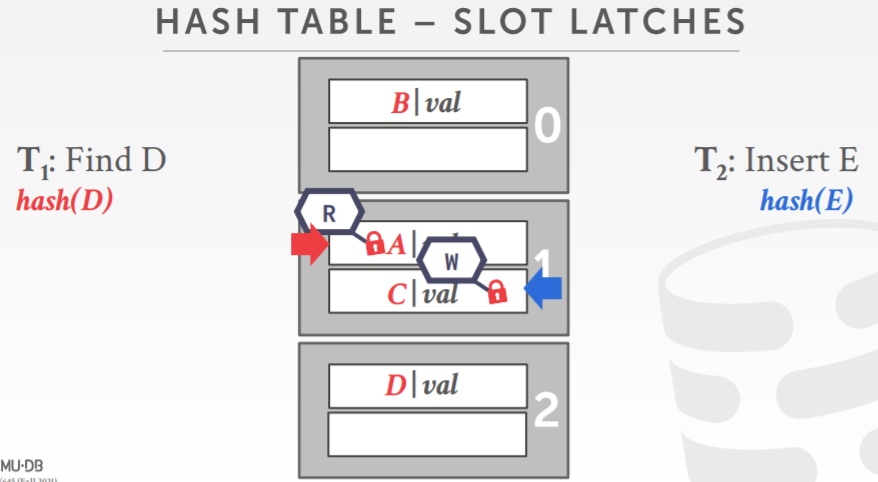
- solt latch,每个slot都有它自己的锁
page latch
slot latch
B+树的并发控制
- 让多个线程同时读、更新B+树,两种类型问题
- 相同时间,线程修改节点的内容
- 一个线程在遍历树、另一个线程在split/merge树
- Get latch for parent
- Get latch for child
- Release latch for parent if “safe”
- A safe node is one that will not split or merge when updated.
- Not full (on insertion)
- More than half-full (on deletion)
latch 的捕获/耦合
- find,从root开始下降,获取 R latch on child,Then unlatch parent
- delete/insert,从root开始下降,按需获取W latch,一旦child被锁住检查是否安全
- 一旦孩子是安全的,则释放所有祖先
B+树 读 latch过程,给当前节点加锁,再给子节点加锁,之后释放父节点的锁
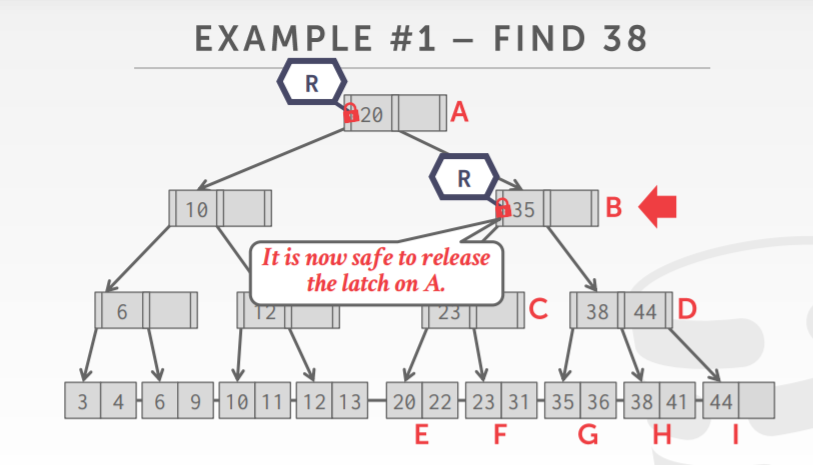
B+树的删除,自顶向下,给子节点加锁,如果子节点不会被merge,则表示安全,可以将父节点的锁释放
如果子节点不能确定自身是否会merge,则需要继续往下递归执行到孙子节点,给孙子加锁
下图中孙子不会merge,则释放它上面的父节点,父节点的父节点锁
可能比较糟糕的情况是,一直从 root到页节点都在加锁,直到页节点才能确定结果,释放所有祖先的锁
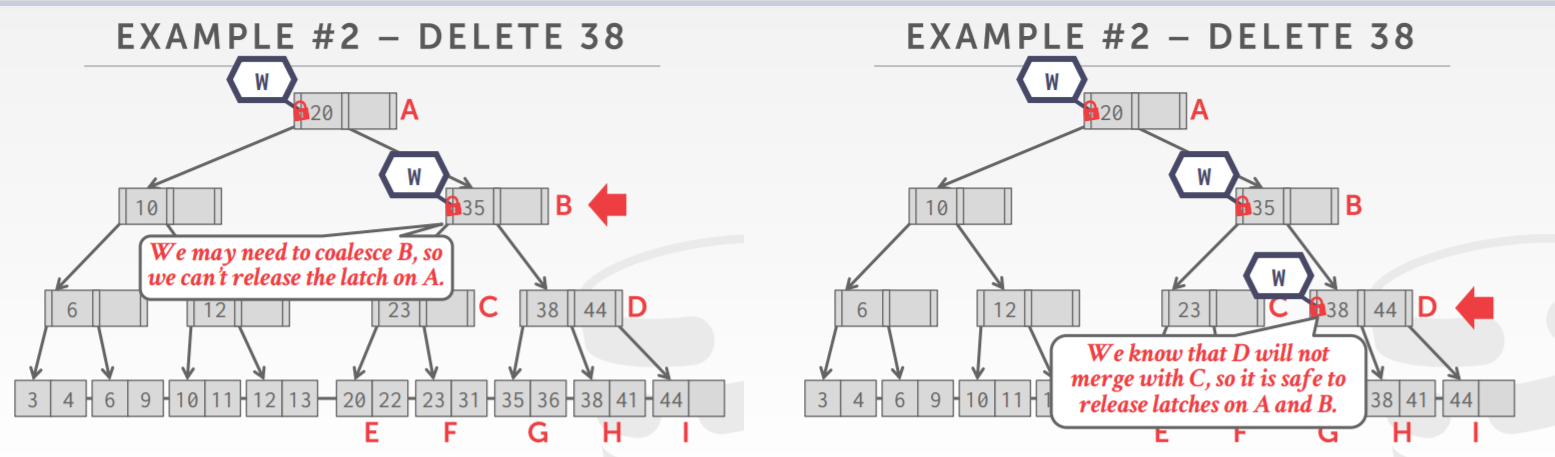
B+树的插入,自顶向下,因为插入会导致split
由于担心子节点可能要分离,当前节点就需要留出一定的空间
如下,B有足够的空间,即使子节点分离也不用担心,所以可以释放父节点的锁
但由于不知道哪一层会split,所以一直往下都在加锁,直到页节点确定了不会split,则可以释放祖先的锁
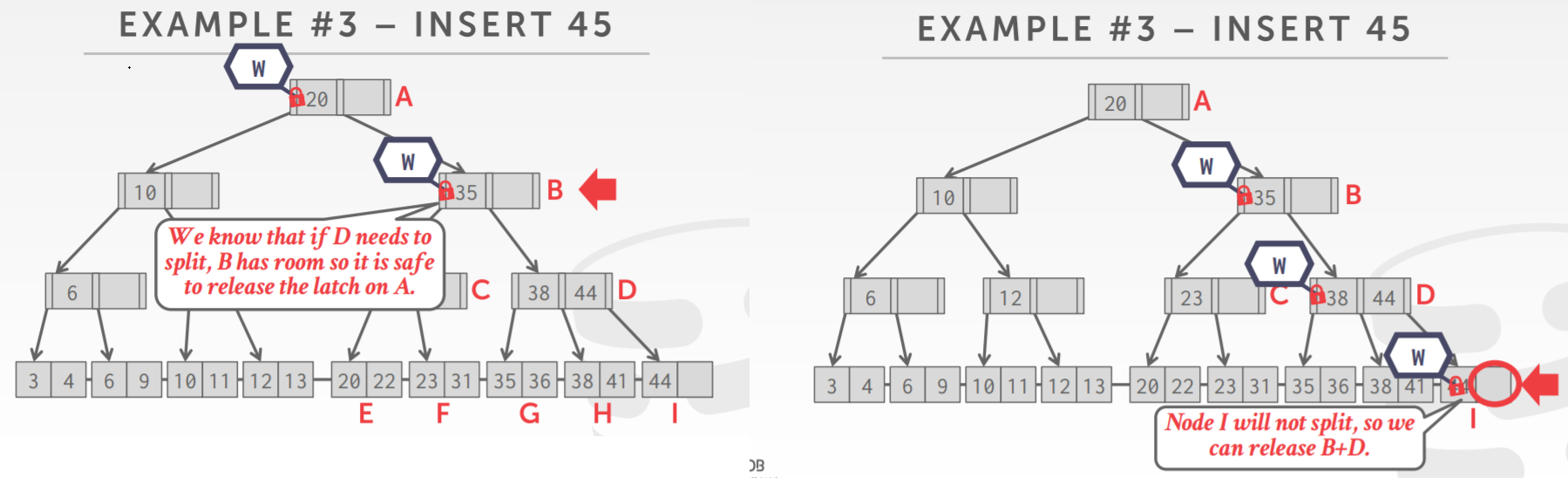
另一个insert的例子,插入25,一路下来,各个中间几点都有足够的空间,于是都释放锁了
直到倒数第二个节点,因为担心子节点会split,所以不能释放锁
而子节点真是要split了,split后生成了新的节点
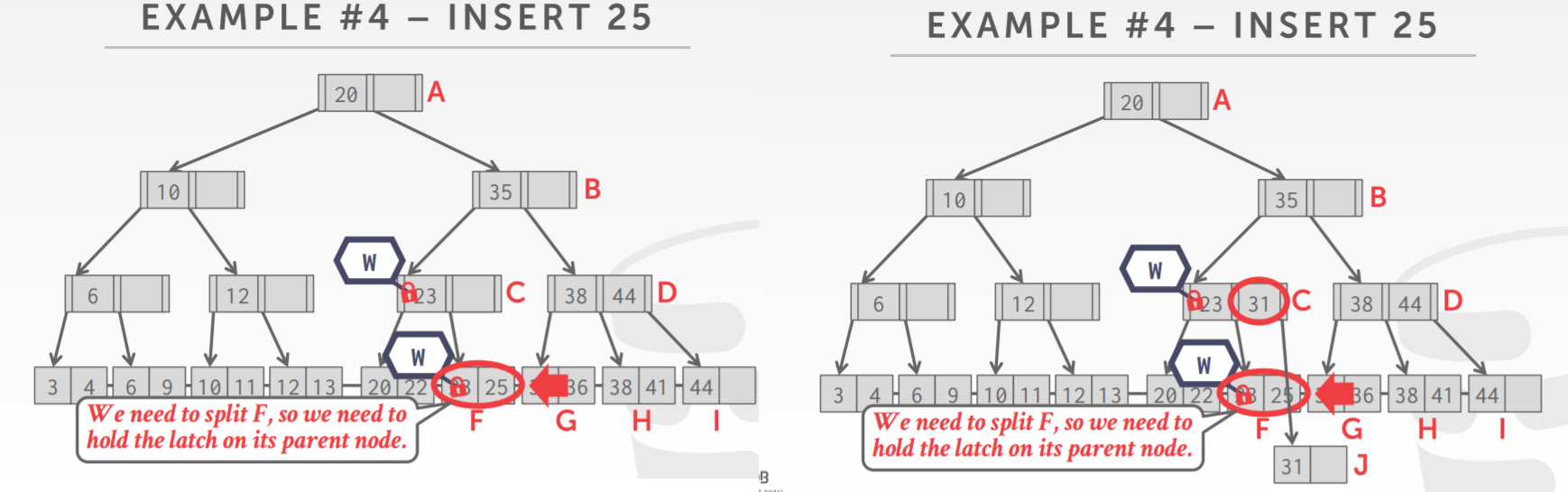
B+ 树的并发优化
- insert、delete操作,每次都是从root开始,都需要一个对root做写锁
- 并发情况下,效率会很低的
- 大多数情况下并不会发生 split、merge
- 先使用 读锁乐观的执行,如果出错,则使用悲观方式重新执行一次
- 对于 search,跟之前的一样
- 对于insert/delete,先找到页节点,对其枷锁
- 如果页节点 不是安全的,释放所有latch,按照之前的模式重新来一遍
- 这种方式假设只是 页节点需要修改,如果不是那么前面的 R latch就浪费了
相关文章
- No nuances, just buggy code (was: related to Spinlock implementation and the Linux Scheduler)
- Concurrency of operations on B-trees
- CMU-15445LAB2:实现一个支持并发操作的B+树
- 并发b+树协议.
- PostgreSQL B+树索引—并发控制
- Online B-Tree merging
Sorting + Aggregations
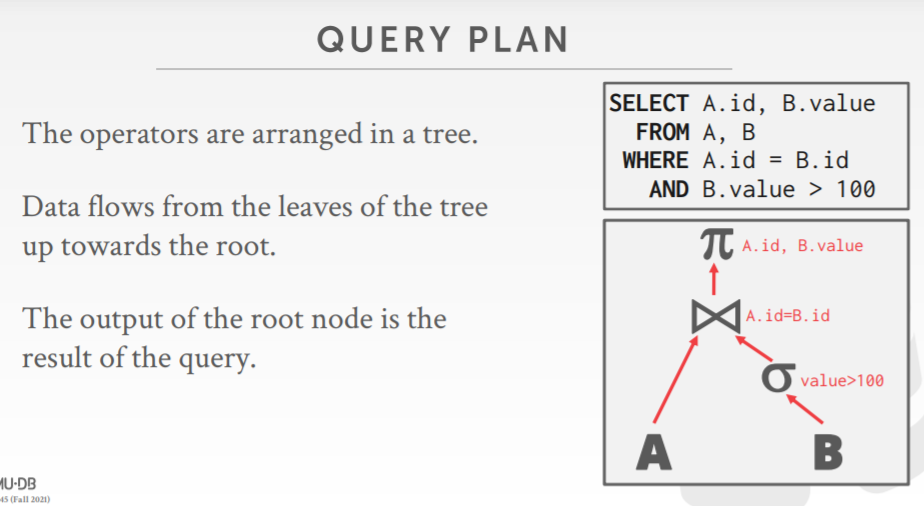
一个查询计划的例子
为什么需要排序
- 关系模型SQL是未排序的
- 指定的语句 order by需要排序
- 支持去重的 DISTINCT
- 需要批量排序后导入
- 聚合 group by
外排序
- 不能假设内存足够
- 使用分治合并的方式
- 两路归并需要3个 buffer pool page,两个输入页,一个输出页
- 即使有更多的buffer pool page,可能也不会更有效,因为工作都阻塞在I/O上了
- 优化方式,使用 double buffer
- 当系统正在处理当前一轮时,在后台预先抓取下一个轮并放入第二个buffer中
两路归并的例子
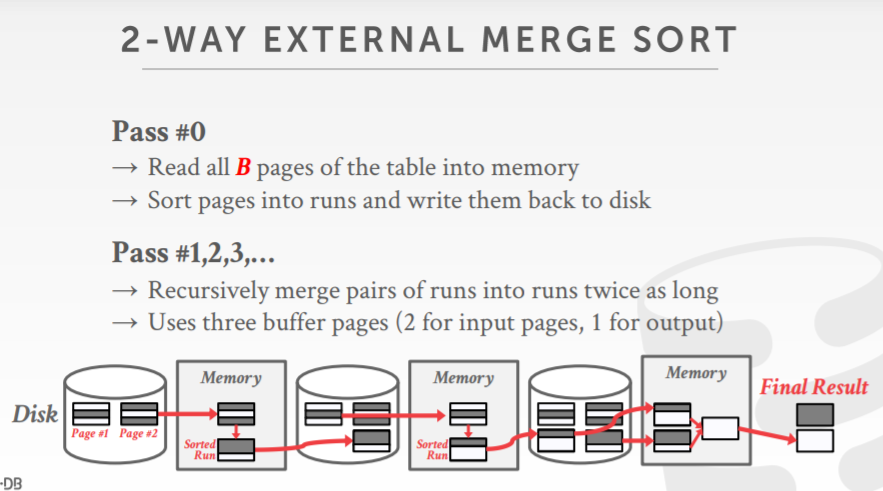
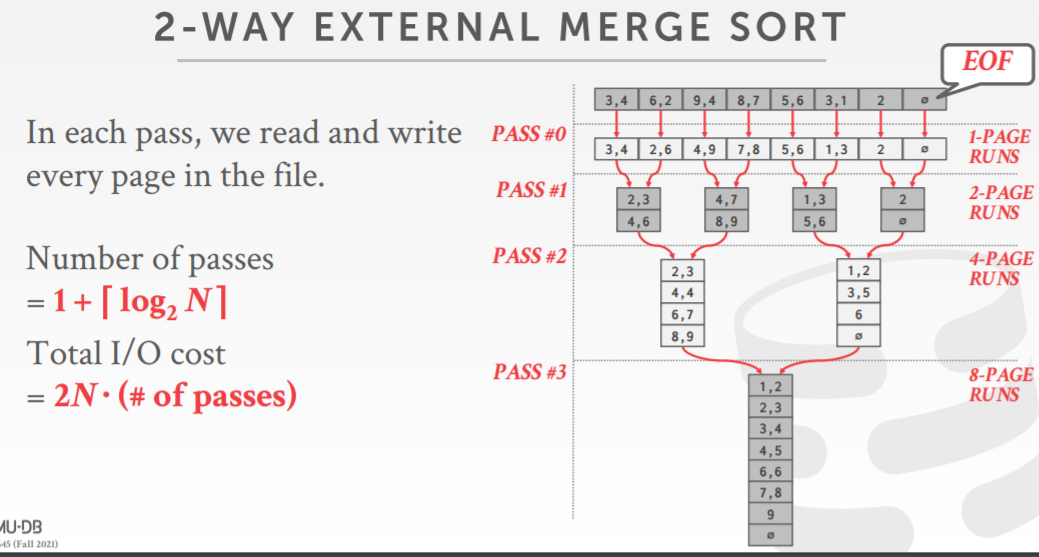
108个pages,5个buffer pool执行的例子

使用B+树索引加速排序
- 聚集索引,通过索引找到最左边的 page,然后顺序往后遍历即可,比外部排序要高效很多
- 非聚集索引,需要回表,效率就低很多了
aggreation
Collapse values for a single attribute from multiple tuples into a single scalar value.
aggreation的两种实现
- sorting
- hashing
以下SQL,通过sorting来执行
|
|
执行过程图:
- 先filter,过滤数据
- 再去掉多余的列
- 排序,然后再去重

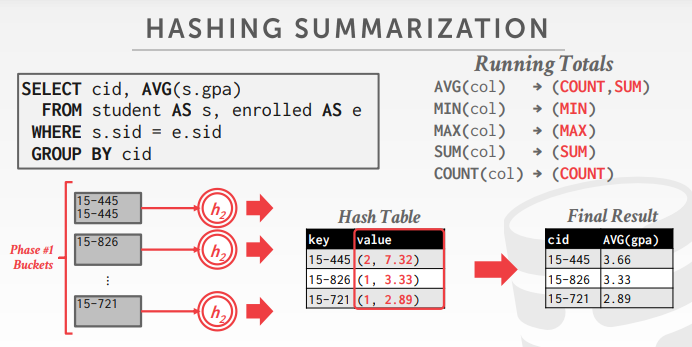
用hash替代排序
- distinct,只需要去重,其实不用排序
- group by,只需要分组,也不用排序
- 如果临时的hash table能放入内存,则很容易,否则需要溢出到磁盘
- 分区,根据key将数据放入不同的分区,然后写回到磁盘
- 根据每个分区,建立内存的hash表,然后计算聚合
- rehash阶段,存储一个 (GroupKey→RunningVal)
- 如果匹配了 group by key,则更新 runingVal内容,否则新建一个(GroupKey→RunningVal)
阶段一,partition的例子,根据 h1 哈希函数,做分区

阶段二,rehash例子,根据 h2 哈希函数,做计算
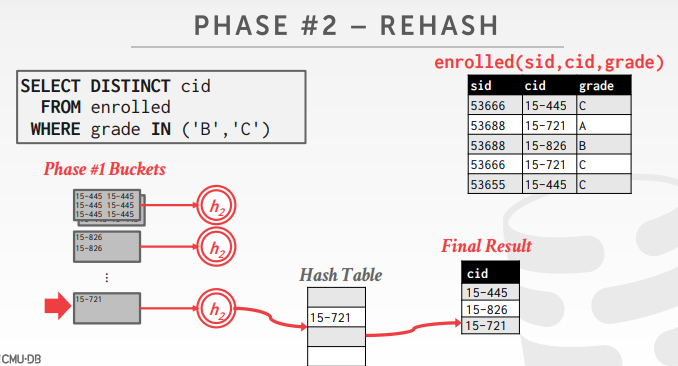
一个例子的总结
|
|
先根据 h1 函数建立分区,然后遍历分区,对每个分区执行 h2函数,key是 cid,value是 (个数,分数总和), 最后执行 (分数综合/个数) 即可求出平均值
Joins Algorithms
join算法有很多优化,但没有哪个算法适用所有场景
join的花费分析标准

join类型
- nested loop join
- simple/stupid
- block
- index
- sort-merge join
- hash join
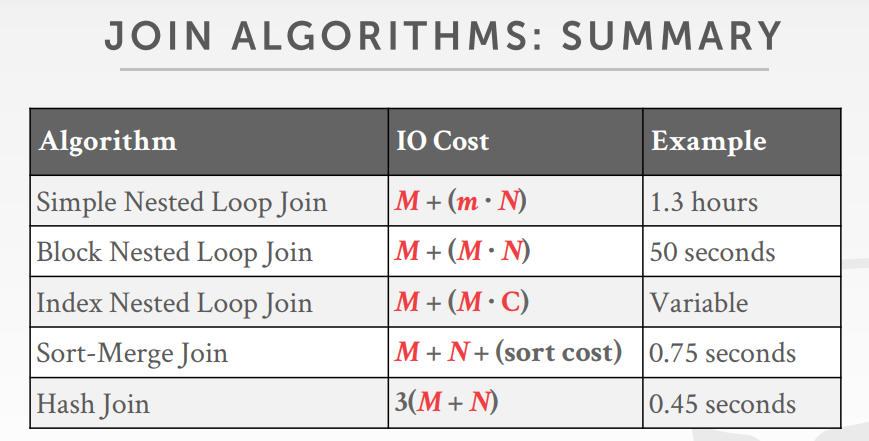
simple nested loop join的问题
- 外层M 个页,m tuples;内层 N个页,n tuples
- cost: M + (m * N)

block nested loop join是一次刦一个page,这样总的I/O就比simple要少很多
cost: M + (M * N)
|
|
如果有 B 个buffer,那么 B - 2个用于扫描外表,1个扫描内表,一个输出
cost:M + ((M/B-2) * N)
如果内层足够大,B > M + 2?
cost:M + N = 1000 +500 = 1500 IOs,每次I/O 0.1ms,总时间为 0.15秒

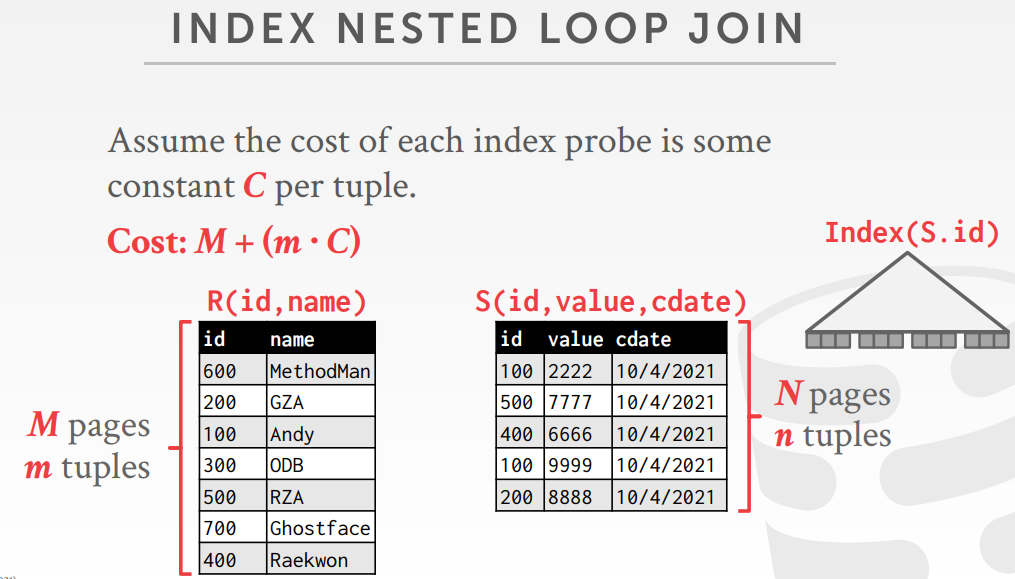
index nested loop join
|
|
nested loop join总结
- 让小表当做外部表
- 尽可能让外部表全放入内存中
- loop遍历内部表尽可能使用索引
- 三种算法:simple/stupid、block、index
- 目前讨论的都是两路join,也有多路join,同时多个表做关联,但这个方式只是出现在理论中
sort-merge join
- 先排序,按照 join 的key排序,使用外部排序
- 在合并,使用双指针迭代,必要时可能需要回溯
- Sort Cost (R): 2M ∙ (1 + logB-1[M / B])
- Sort Cost (S): 2N ∙ (1 + ⌈ logB-1[N / B])
- Merge Cost: (M + N)
- Total Cost: Sort + Merge
- 最坏的情况是,两个关系的所有元组的join属性包含相同值
- Cost: (M ∙ N) + (sort cost)
- 当join之前,两个表中的一个或者两个已经有序了,这时效率就比较高了
- 输入端关系可以通过显示的排序算子,or by scanning the relation using an index on the join key

sort-merge join算法:
|
|
join hash
- 如果基于 i 做分区,那么 R tuple 肯定属于 Ri,S tuple 属于Si
- 因此,Ri 只需要跟 Si 比较即可
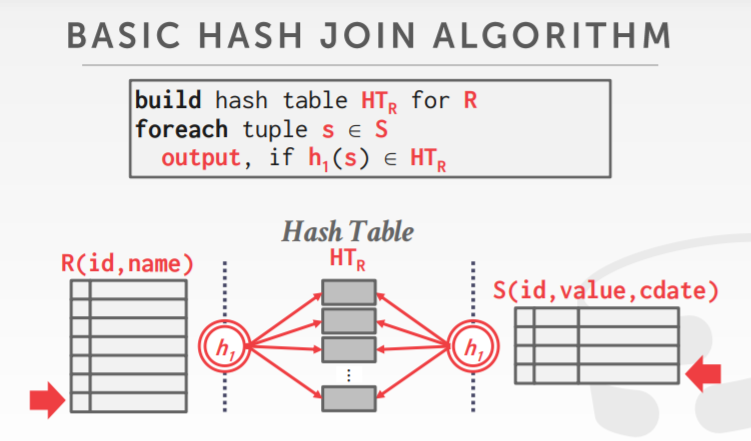
- 首先基于外表建立一个hash表,使用 h1 函数对join属性做hash
- 用h1 函数扫描内部表,查看是否有hash 表的值能跟其匹配
- hash表的key是查询的join条件
- Depends on what the operators above the join in the query plan expect as its input.
hash table values
- full tuple,避免在匹配的时检索外部表,需要更多的内存
- tupe identifier
- Could be to either the base tables or the intermediate output from child operators in the query plan.
- 探测阶段可以使用 bloom filter优化
- sideways information passing
bloom filter cost analysis

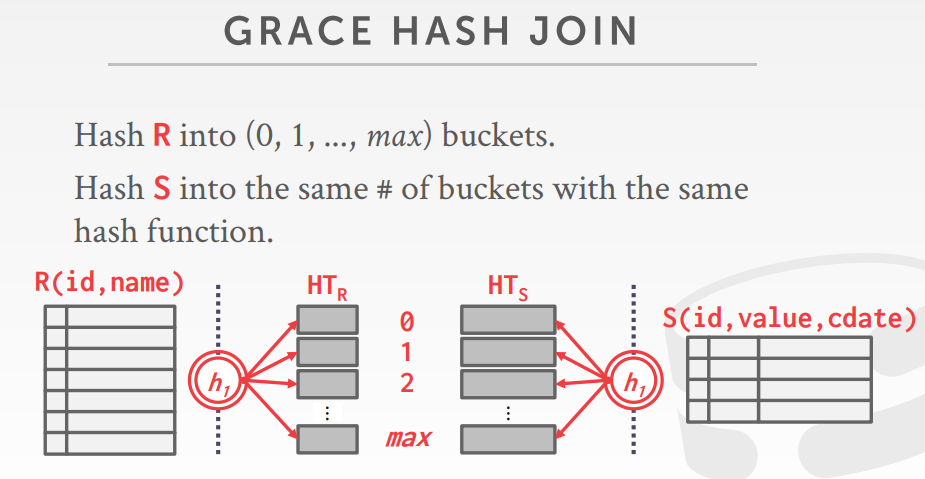
grace hash join
- 当内存不足放下整个hash 表时,可以采用这种方式
- 将连接跳上的两个表通过hash,打散到分区中
- 比较每个表对应分区的tuples
grace hash join比较 对应的两个分区
|
|
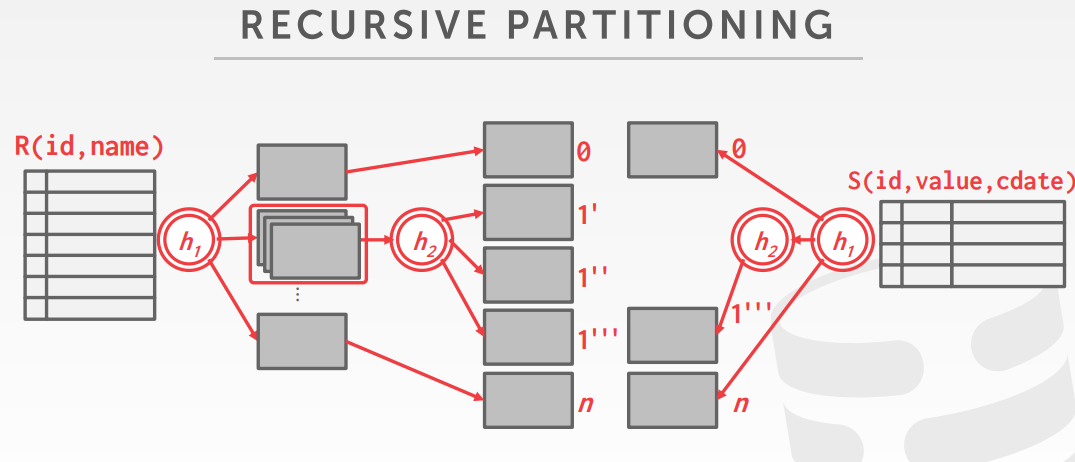
如果分区无法放入内存,则用 h2函数,继续递归的对这个分区再分区
如下,对 S 表的分区1,因为跟R的分区1 层级匹配,则也执行h2函数,跟R1.1’,R1.1’’,R1.1’’’ 匹配
grace hash join
- cost: 3(M + N)
- partitioning phase: 2(M + N)
- probing phase: M + N

如果DBMS知道外部表的大小,可以使用静态hash,这样就省去了额外的build、probe操作
如果不知道表大小,则必须使用动态hash,或者允许页溢出
hash算法总结
相关文章