卡内基梅隆的数据库课程-3
课程地址
https://15445.courses.cs.cmu.edu/fall2021/schedule.html
Concurrency Control Theory

动机:
- 避免并发时的条件竞争,lost updates,concurrency control
- 避免宕机造成的数据不一致 durability recovery
A transaction is the execution of a sequence of one or more operations (e.g., SQL queries) on a database to perform some higher-level function. We need formal correctness criteria to determine whether an interleaving is valid. DBMS是用户程序的抽象视图
定义
- A txn may carry out many operations on the data retrieved from the database
- The DBMS is only concerned about what data is read/written from/to the database.
- Changes to the “outside world” are beyond the scope of the DBMS.
正确性的标准:ACID
- Atomicity: All actions in the txn happen, or none happen,all or nothing
- Consistency: If each txn is consistent and the DB starts consistent, then it ends up consistent,it looks correct to me
- Isolation: Execution of one txn is isolated from that of other txns,as if alone
- Durability: If a txn commits, its effects persist, survive failures
原子性
- Commit after completing all its actions.
- Abort (or be aborted by the DBMS) after executing some actions.
- DBMS guarantees that txns are atomic.
- From user’s point of view: txn always either executes all its actions or executes no actions at all.
- 确保原子性的机制
- Logging,DBMS logs all actions so that it can undo the actions of aborted transactions.
- Maintain undo records both in memory and on disk
- Shadow Paging, Originally from System R
- DBMS makes copies of pages and txns make changes to those copies. Only when the txn commits is the page made visible to others
- 影子paging的实现:CouchDB、LMDB (OpenLDAP
一致性
- 这个实际上需要应用端来保证的,
- If the database is consistent before the transaction starts (running alone), it will also be consistent after.
- The “world” represented by the database is logically correct. All questions asked about the data are given logically correct answers
隔离性的概念很多,先说说持久性
- All the changes of committed transactions should be persistent.
- No torn updates.
- No changes from failed transactions
- The DBMS can use either logging or shadow paging to ensure that all changes are durable.
隔离性 isolation
- 用户提交的任务是交叉执行的,DB端仍然需要交叉运行,但在外面看来,好像每次只有一个在运行
- We need a way to interleave txns but still make it appear as if they ran one-at-a-time.
- A concurrency control protocol is how the DBMS decides the proper interleaving of operations from multiple transactions.
- Pessimistic: Don’t let problems arise in the first place.
- Optimistic: Assume conflicts are rare, deal with them after they happen.
- 无论A、B是以什么样的顺序执行,或者交叉执行的,都应该相当于 串行的方式执行这两个任务
Concurrency control is automatic
- System automatically inserts lock/unlock requests and schedules actions of different txns.
- Ensures that resulting execution is equivalent to executing the txns one after the other in some order.
A、B账户各有100元,并且要给两个账户增加6%的利息
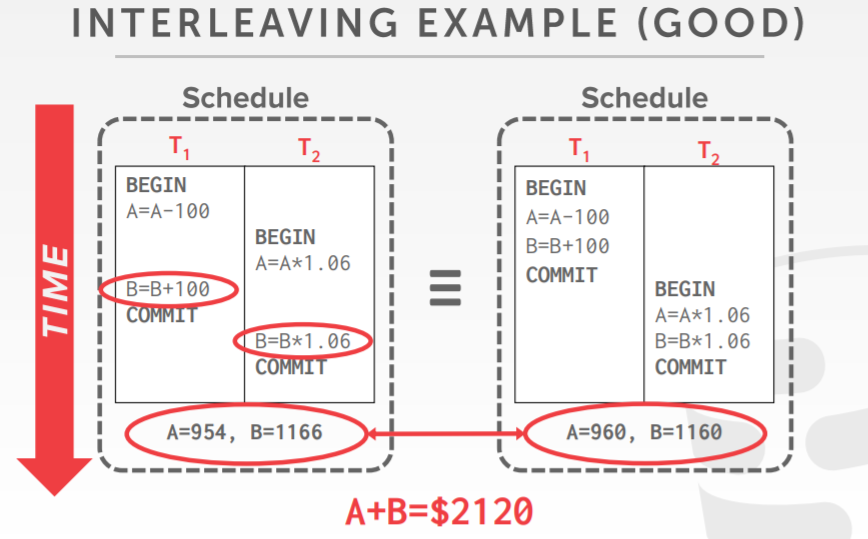

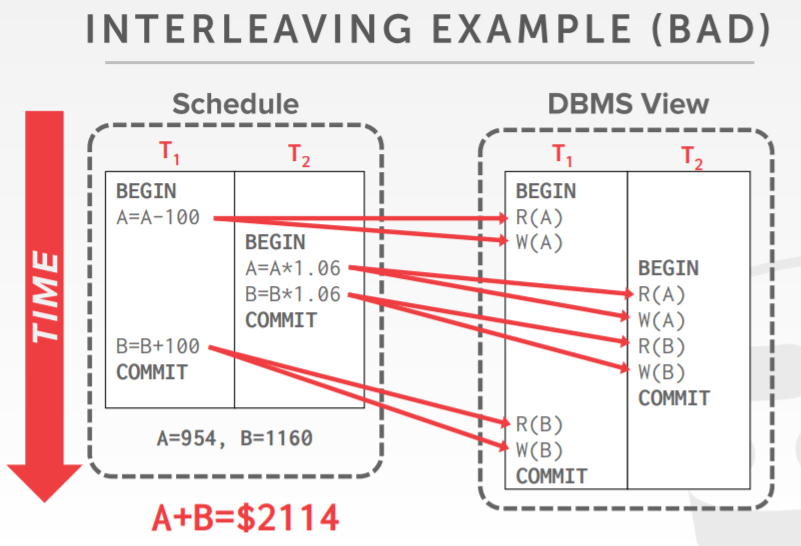
正确性
- How do we judge whether a schedule is correct?
- If the schedule is equivalent to some serial execution.
- 串行化调度
- A schedule that does not interleave the actions of different transactions.
- 等价的调度
- For any database state, the effect of executing the first schedule is identical to the effect of executing the second schedule.
- Doesn’t matter what the arithmetic operations are!
- 可串行化调度
- A schedule that is equivalent to some serial execution of the transactions
- If each transaction preserves consistency, every serializable schedule preserves consistency
- 可串行化 相比事务的启动时间、提交顺序,缺少了直观感觉,但是提供了调度的灵活性,即更好的并行化能力
冲突操作
- They are by different transactions
- They are on the same object and at least one of them is a write
- Read-Write Conflicts (R-W)
- Write-Read Conflicts (W-R)
- Write-Write Conflicts (W-W)
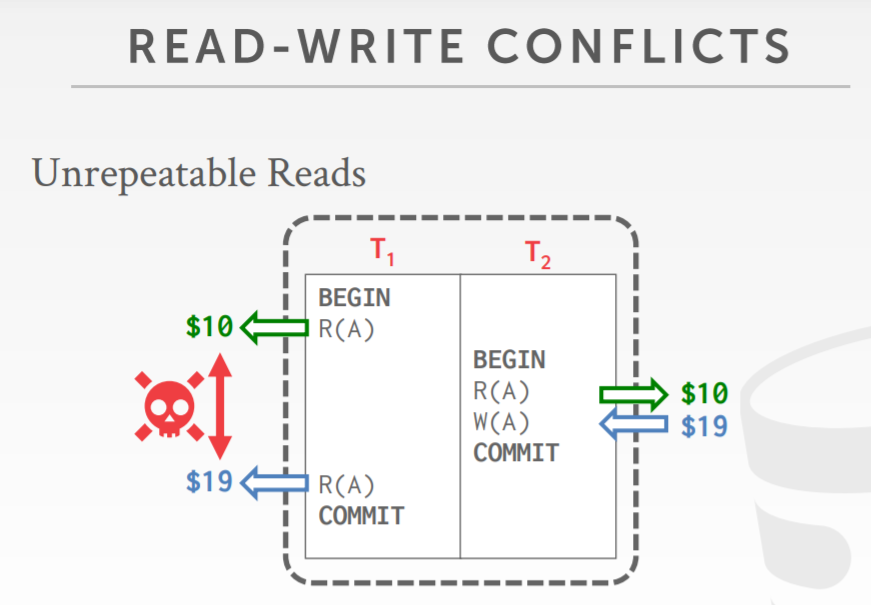
不可重复读,Unrepeatable Reads
读未提交,Reading Uncommitted Data (“Dirty Reads”)
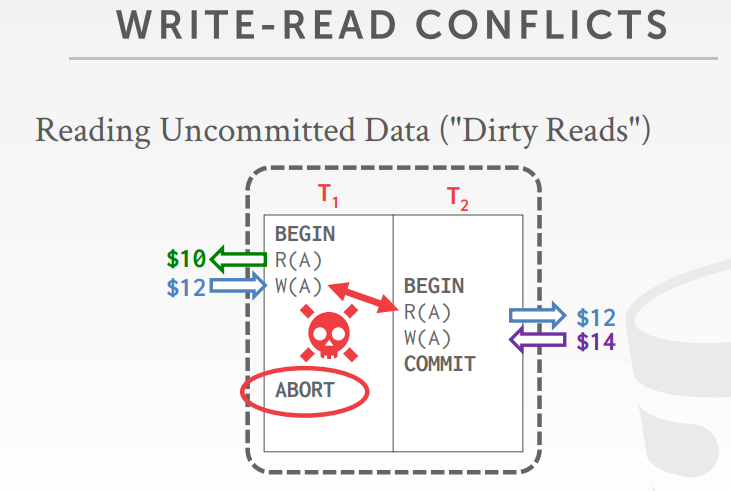
覆盖未提交的数据,Overwriting Uncommitted Data
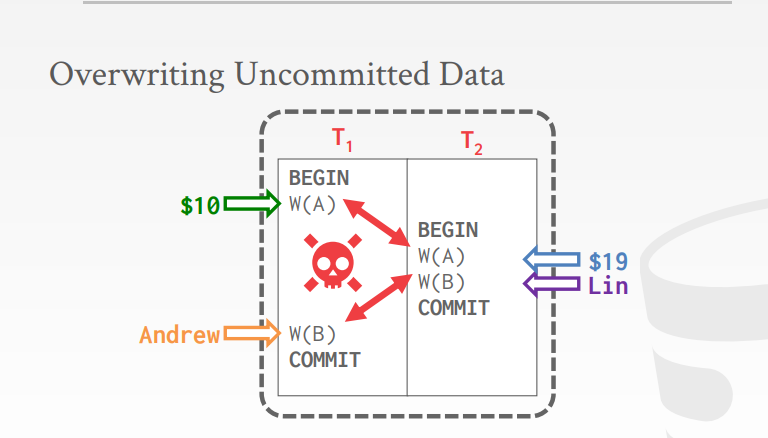
通过这些冲突,我们知道了串行化的调度意味着什么
- This is to check whether schedules are correct.
- This is not how to generate a correct schedule
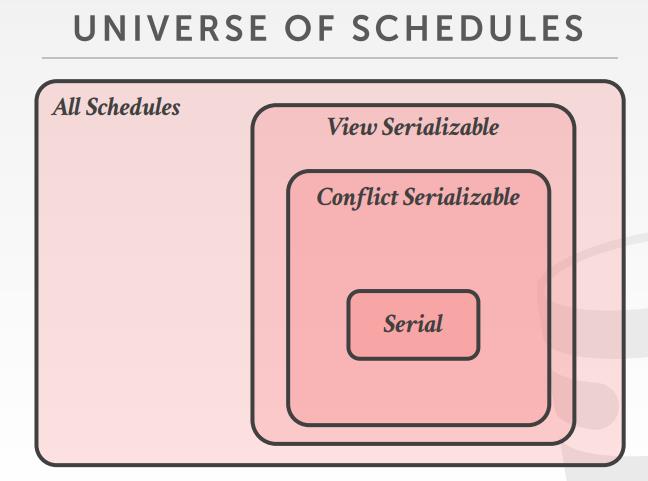
- Conflict Serializability,大多数数据库都支持
- View Serializability, 没有数据库能做到这一点
conflict serializable schedules
- 两个调度冲突
- 相同事务涉及了相同的操作
- Every pair of conflicting actions is ordered the same way.
- 如果交换不同事务的,连续的、非冲突的操作,将S转换为串行调度,那么S 就是 conflict serializable
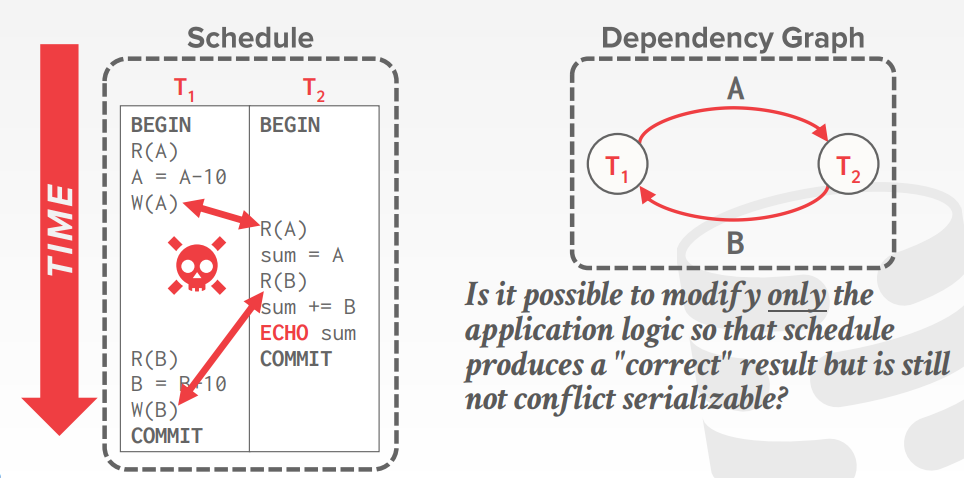
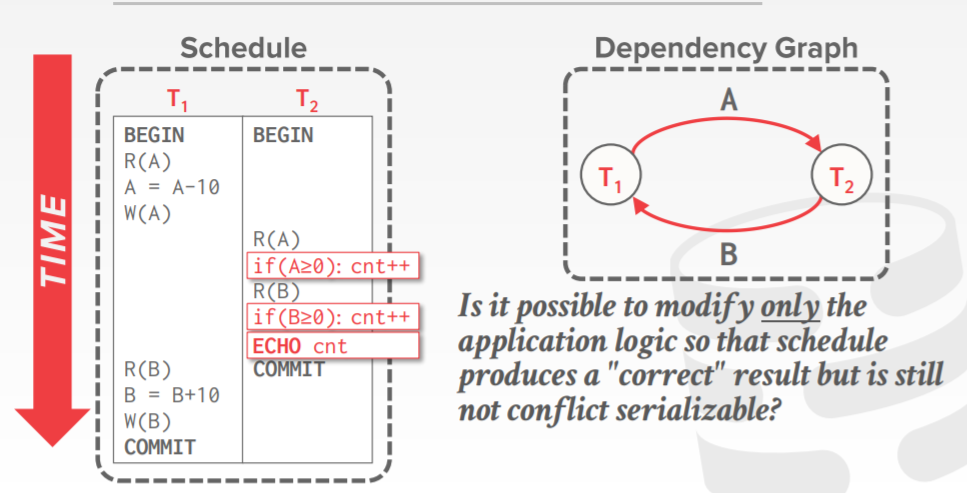
conflict serializablity intuition 例子

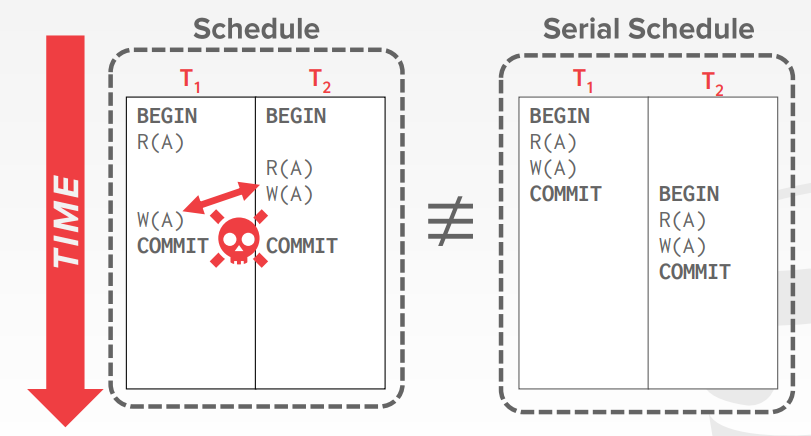
转换的方式,对于只有两个或者很少的事务,比较容易操作,但事务多了就不好弄了
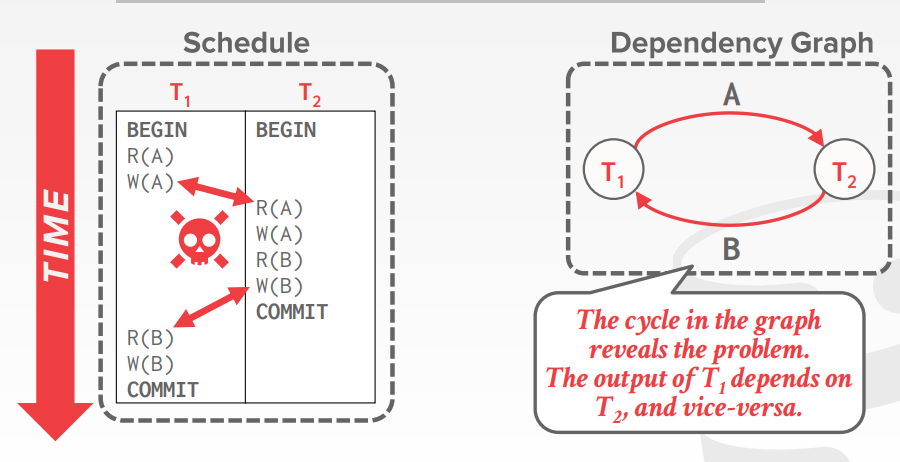
可以使用 依赖图,dependency graphs
- 边 Ti 到Tj,表示 Ti的一个操作Oi 跟 Tj的一个操作Oj 冲突
- Oi 在调度中,比Oj 更早出现
- 也叫 优先图,precedence graph
- 当依赖图中没有环,才能转换成 conflict serializable
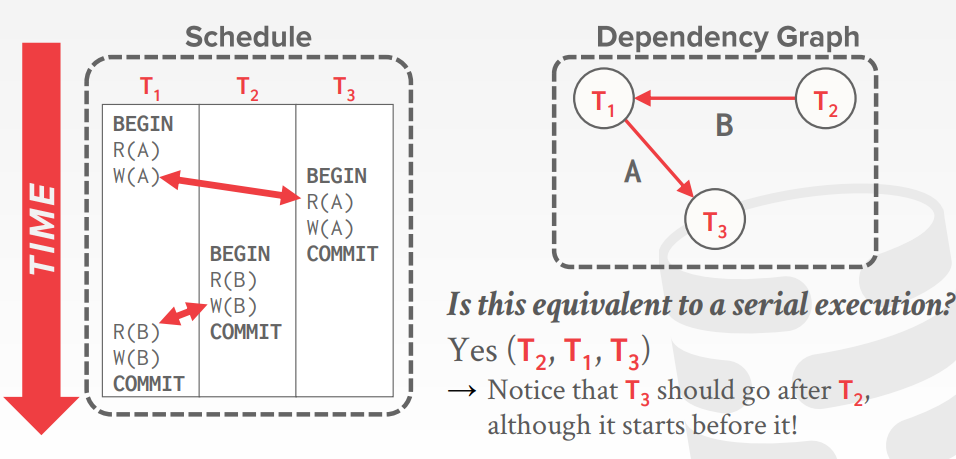
依赖图的例子
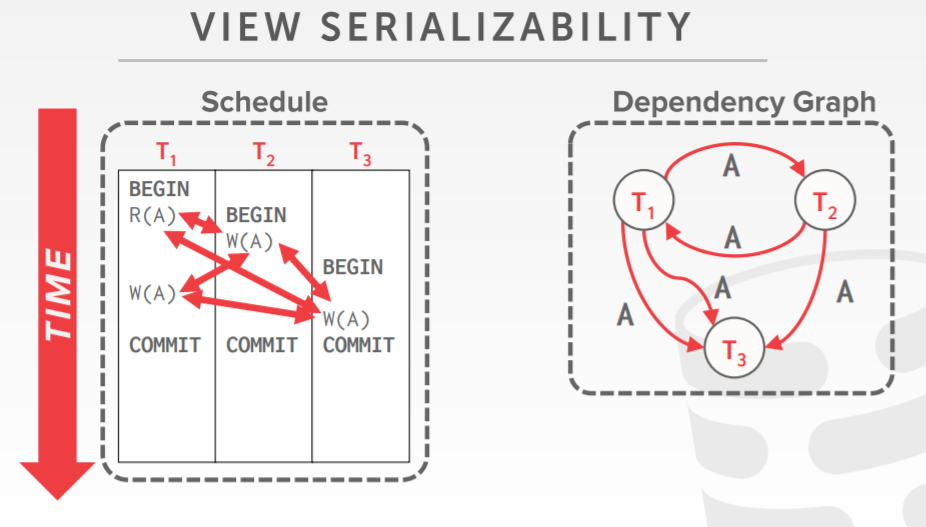
视图可串行化 view serializabilty
- 可串行性的另一个(较弱的)概念
- 当满足下面三个调度条件才认为 S1、S2是 视图等价的
- 如果T1 读了S1中的A 初始值,那么T1也需要读 S2中的A 初始值
- 如果T1读了 S1中 被T2写入的A值,那么T1也需要 读取 S2中由T2写入的A值
- 如果T1 在S1中写入了A的最终值,那么T1 需要在S2 中写入A的最终值
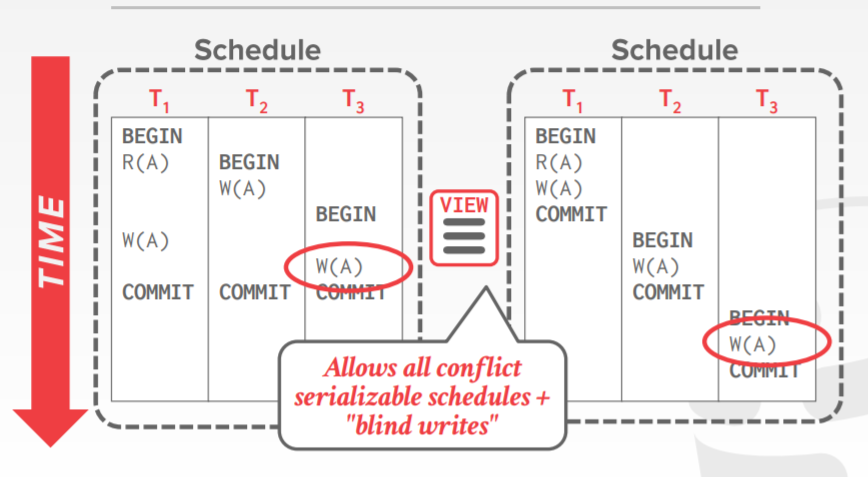
view serializability 允许比 conflict serializability 各方多的调度
但是难以有效的实施,NP完全问题
这两种调度,都不允许你所谓的 可序列化 调度
这是因为他们不懂得操作或者数据的意义
实际的系统会支持 conflict serializability,因为它可以有效的执行
为支持更多并发,一些特殊情况,需要在应用程序级别单独处理
两种 串行化方式总结
- Conflict Serializable
- 检验方式通过:swapping,或者是用 dependency graphs
- 任何数据库,宣称他们支持 serializable,实际使用的就是这种方式
- View Serializable,NP完全没问题,没法有效验证
相关文章
Two-Phase Locking Concurrency Control
Lock Types
我们需要保证所有的调度执行都是正确的(如串行化),而不用提前知道整个调度
用lock来来保护数据库对象
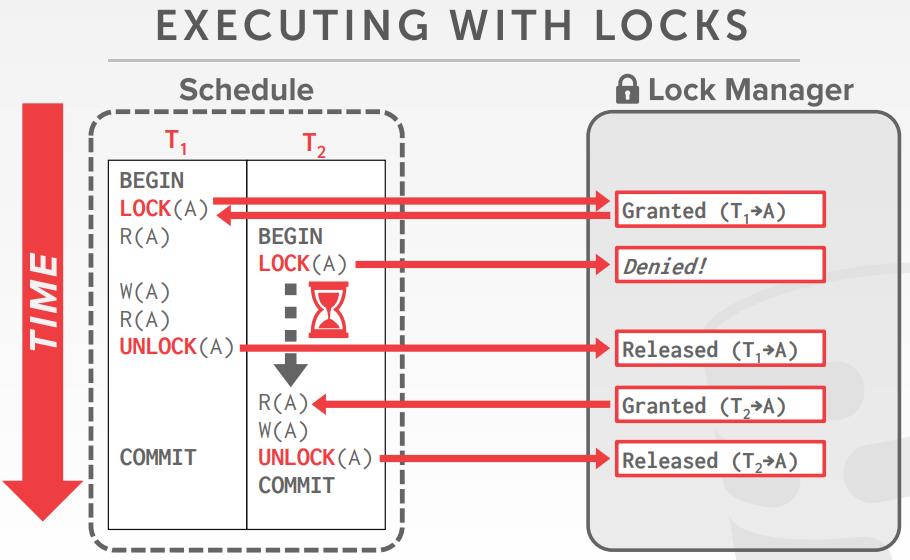
锁类型
- S-LOCK: Shared locks for reads.
- X-LOCK: Exclusive locks for writes.
lock vs latche
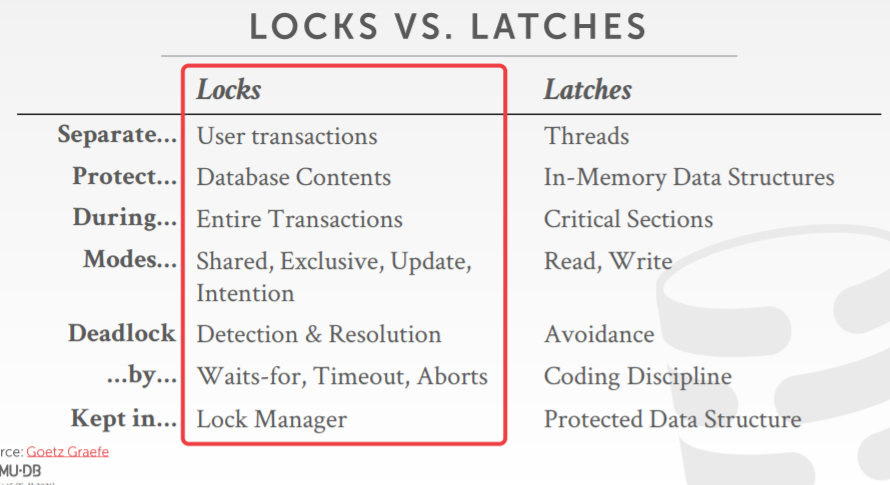
锁管理器负责分配,或者拒绝锁
It keeps track of what transactions hold what locks and what transactions are waiting to acquire any locks.
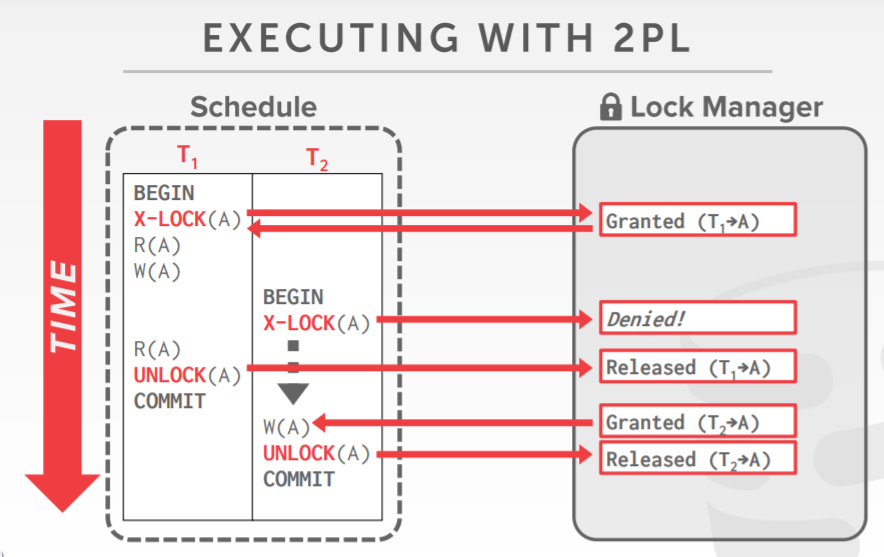
虽然采用锁,但并发交错执行时,还是会有问题,如下 T1先读了A,然后T2写了A(提交了事务),T1再写A,此时再读A,就是不可重复读
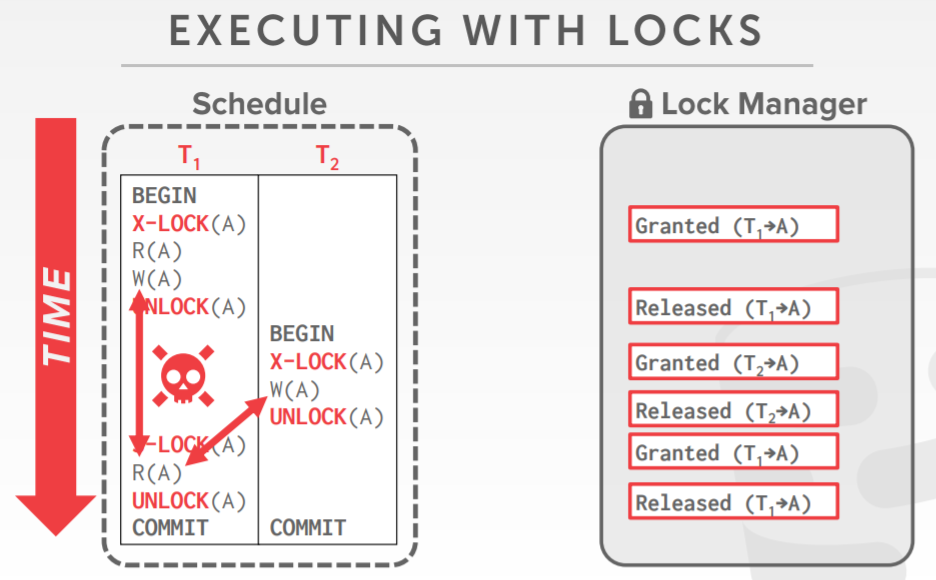
Two-Phase Locking
2PL
- 两阶段锁,是一种并发控制协议,决定事务是否可以访问数据库中的对象,以动态的方式访问
- 这个协议不需要提前知道所有的查询请求
- 分为两个阶段,Growing、Shrinking
- Growing阶段,每个事务都需要从DBMS的锁管理器那获取锁,锁管理器负责分配、拒绝锁请求
- Shrinking阶段,只允许释放之前获取的锁,不允许再申请新的锁
- 2PL可以保证conflict serializability,生成的优先图是无环的
- 2PL有一个问题,会导致 级联终止 cascading aborts
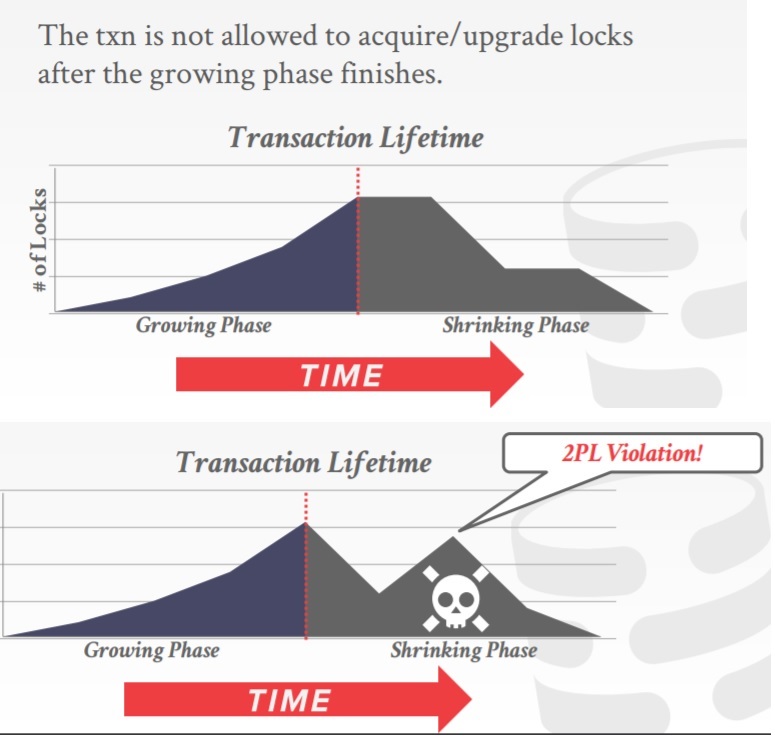
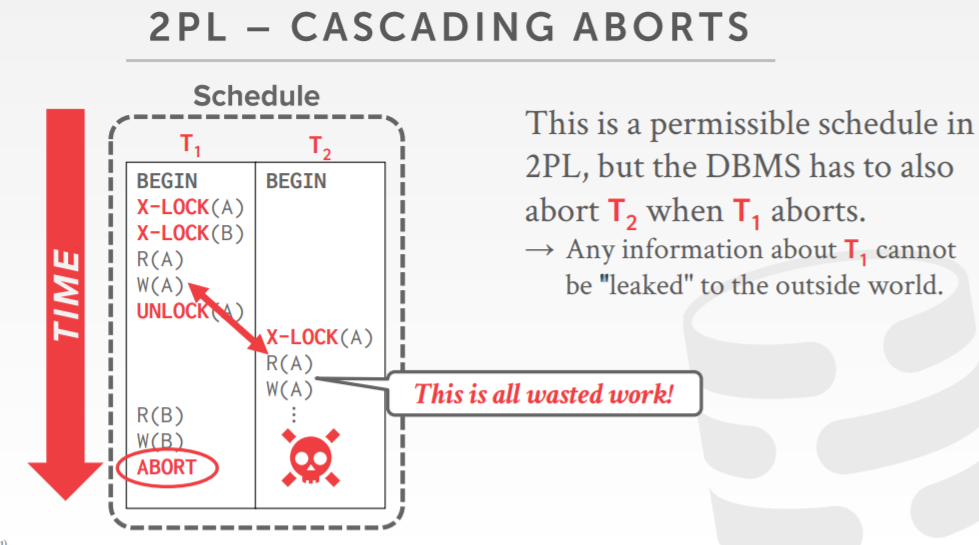
2PL的问题
- 一些调度是可以被序列化的,但2PL不允许
- 锁限制了并发
- May still have “dirty reads”.
- Solution: Strong Strict 2PL (aka Rigorous 2PL)
- May lead to deadlocks.
- Solution: Detection or Prevention
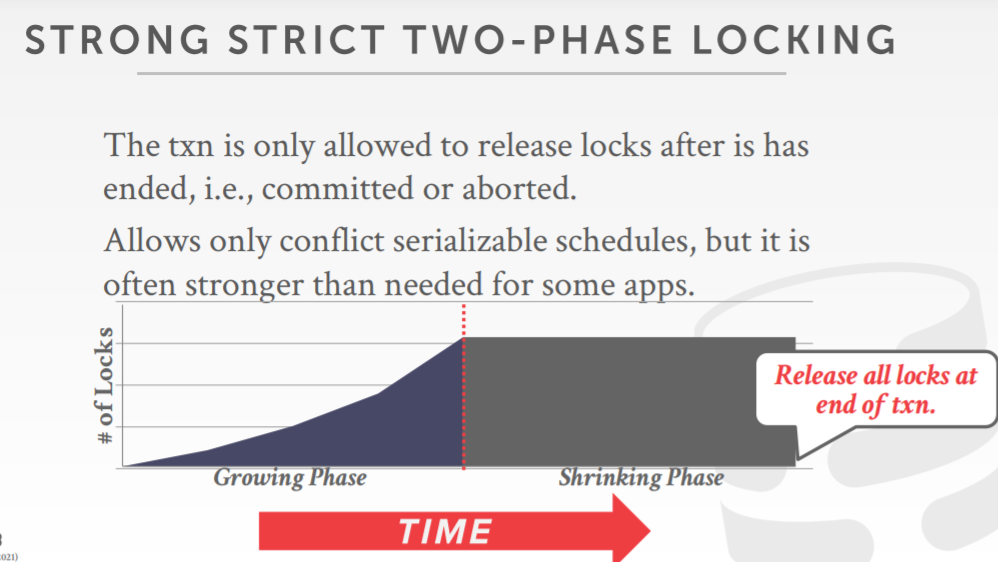
Strong Strict 2PL
- 只允许在commit或者abort的时候释放锁
- 只允许冲突序列化调度,但它通常比一些应用程序需要的更强
- 如果一个事务写了一个value后直到完成,没有其他事务读取,则这个调度是 严格的 strict
- 优势,不会引发级联终止
- 终止事务,可以通过恢复修改后的tuple原始值来取消
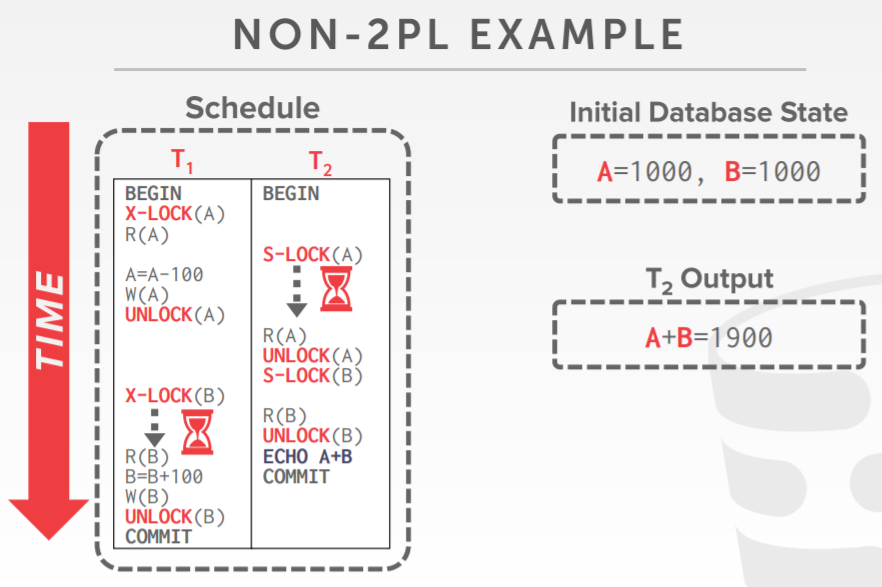
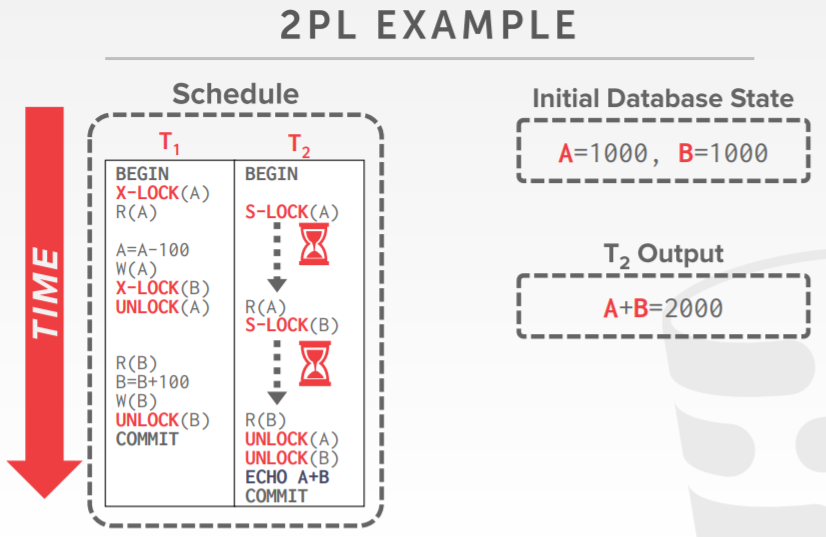
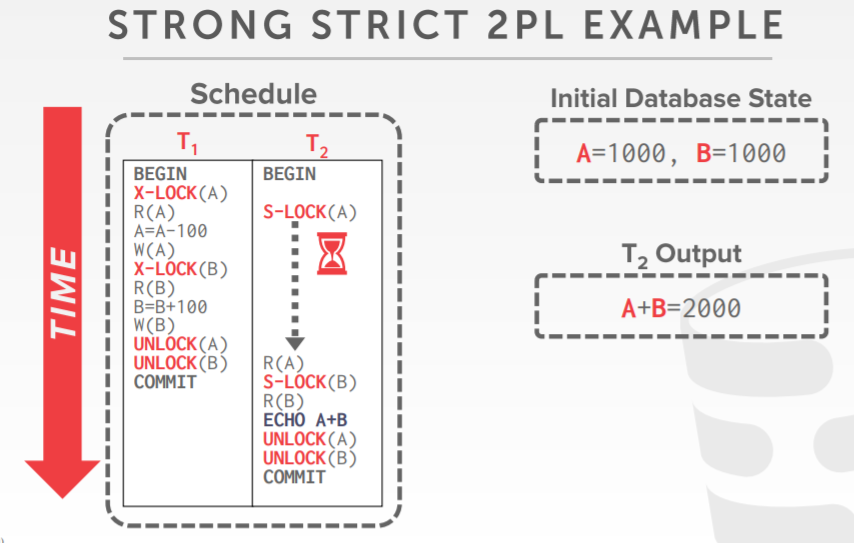
各种调度对比
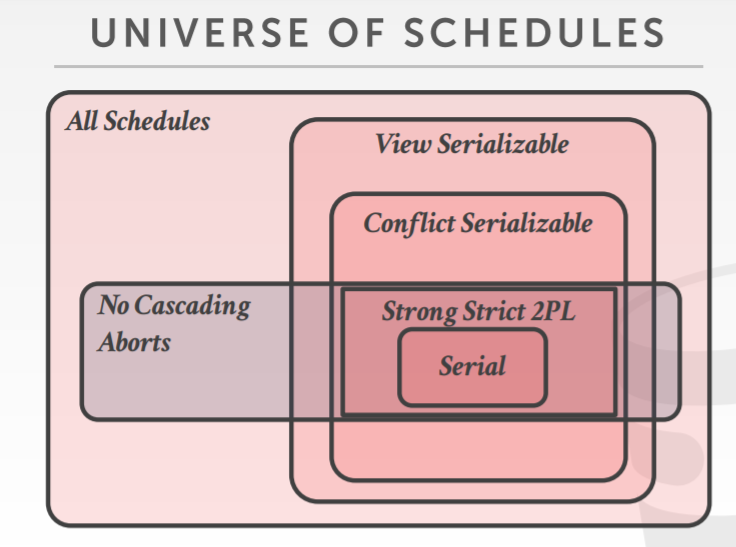
Deadlock Detection + Prevention
2PL的死锁问题
- A deadlock is a cycle of transactions waiting for locks to be released by each other
- Deadlock Detection
- Deadlock Prevention
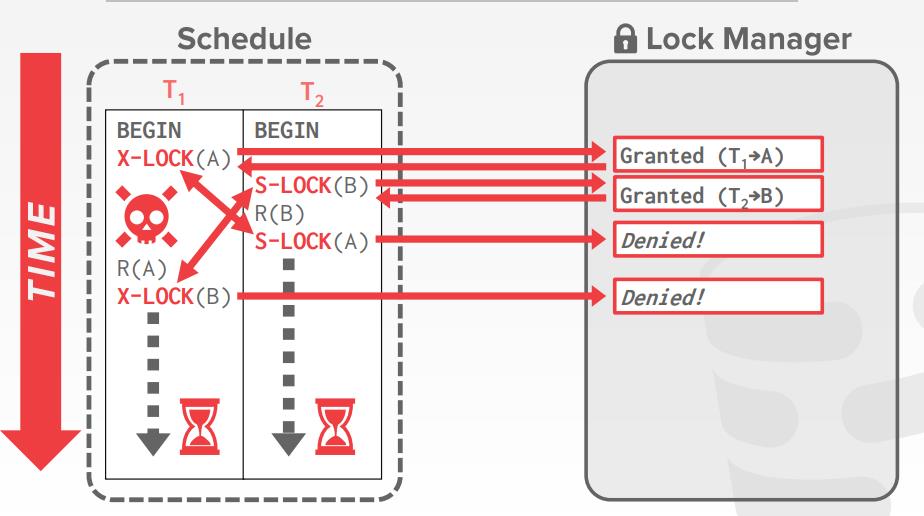
死锁的检测
- 创建一个等待图 waits-for graph ,跟踪每个事务等待获取的锁
- Node是事务
- edge边,如果Ti 等待 Tj释放锁,则:Ti -> Tj
- 系统周期性的检测等待图中的循环,然后决定如果打破这个循环
- 当检测到一个死锁后,可以选择一个victim 受害者事务,将其回滚来终止循环
- victim事务会被重启、或者终止(更通用),具体取决于如何调用
- 权衡:检测死锁的频率,在中断死锁前需要等待多久
- 选择一个victim事务有多种变量
- By age (lowest timestamp)
- By progress (least/most queries executed)
- By the # of items already locked
- By the # of txns that we have to rollback with it
- 还需要考虑到过去因为饥饿导致的重启次数
- DBMS还可以决定回滚的程度
- Approach #1: Completely
- Approach #2: Minimally
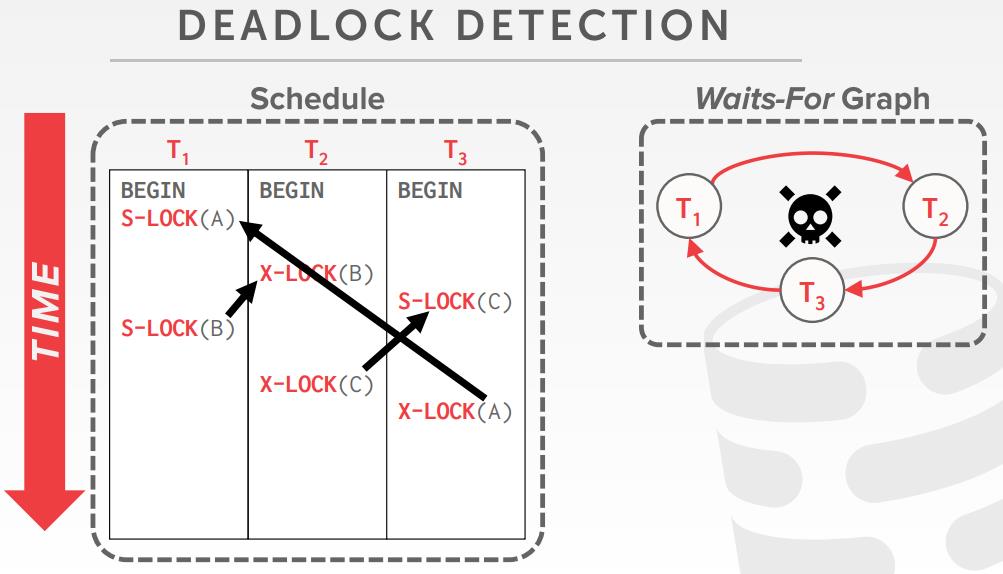
死锁的预防
- 当一个方事务尝试获取锁,而这个锁正被另一个事务持有,DBMS会kill他们中的一个,来预防死锁
- 这种方式不需要 等待图,或者检测算法
- 基于时间戳的方式,分配一个优先级,Older Timestamp = Higher Priority (e.g., T1 > T2
- Wait-Die (“Old Waits for Young”)
- 如果请求事务的优先级 > 持有事务,则请求事务等待;否则终止请求事务
- Wound-Wait (“Young Waits for Old”)
- 如果请求事务优先级 > 持有事务则持有事务终止或释放锁;否则请求事务等待
- 为什么这种方案可以预防死锁:等待锁时,只允许一种类型的方向
- 事务重启后,时间戳为原来的时间戳
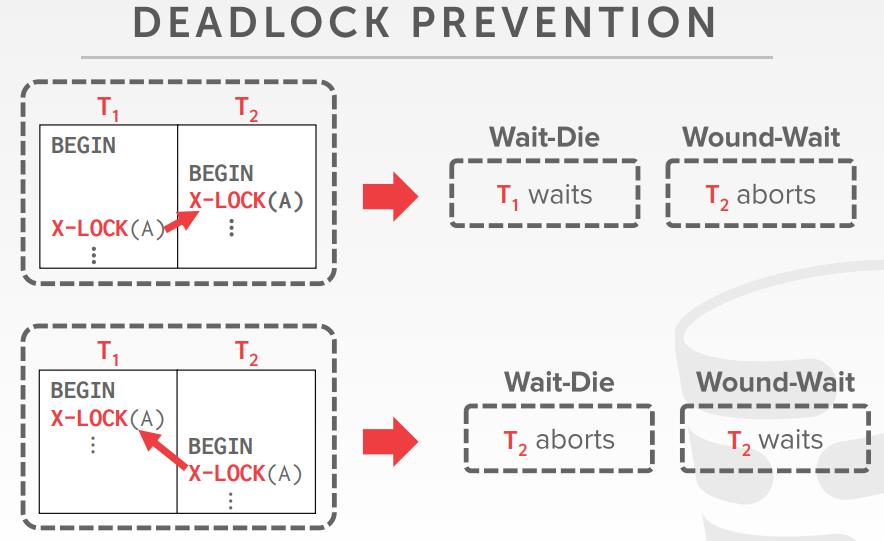
Hierarchical Locking
锁粒度 lock granularities
- 上面所有的例子,都是 数据库对象 -> 锁的一对一映射
- 如果要更新 10亿个tuples,则需要获取10亿个锁
- 即使锁可用的情况下,获取 lock 也比 latch 更昂贵
- 当 一个事务要获取锁时,DBMS会决定 锁的粒度(范围)
- Attribute? Tuple? Page? Table?
- 理想情况下,事务需要的锁的最少数量
- Trade-off between parallelism VS overhead
- Fewer Locks, Larger Granularity vs. More Locks, Smaller Granularity
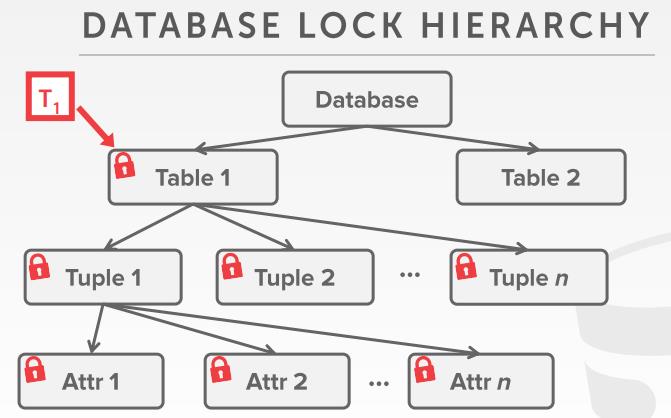
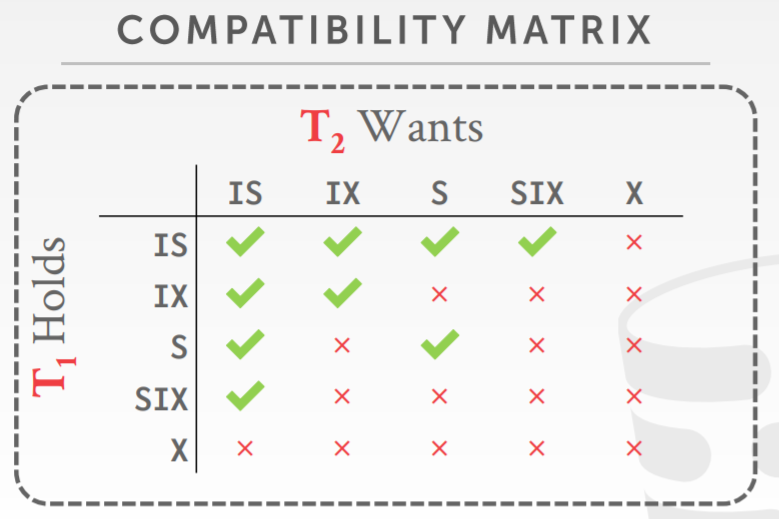
意向锁 intention lock
- 意向锁允许一个 更高的节点以 shared、exclusive 模式获取锁,而不用检查其后代节点
- 如果一个节点的锁是意向锁,则事务需要显示执行锁,在低级别节点上
- 意向共享锁Intention-Shared (IS),显示的用共享锁,lock较低级别
- 意向排斥锁Intention-Exclusive (IX),在低级别使用使用显示的排斥锁
- 共享意向排斥锁Shared+Intention-Exclusive (SIX)
- 以该节点为根的子树显示的锁定在共享模式,较低节点显示的锁定在排斥模式
- 每个事务在数据库层次结构的最高级别获得合适的锁
- 要在节点上获得S、IS锁,则事务至少要在父节点上持有IS锁
- 要在节点上获得X、IX、SIX锁,则事务至少要在父节点上持有IX锁
- 分层锁在实践中很有用,因为每个事务只需要获得几个锁
- 意向锁有助于提升并发
- 意向共享锁IS: 意图以更细的粒度获得S锁
- 意向排斥锁IX: 意图以更细的粒度获得X锁
- 共享意向排斥锁SIX:可以同时使用S、IX锁
- 当有太多低级别锁时,可以动态转为粗粒度锁,这也减少了 lock mananger的任务
- 通常不需要在事务中手动设置锁,有时可以向DBMS提示,来帮助改善并发性
- 对于重要的变更,可以显示的设置锁
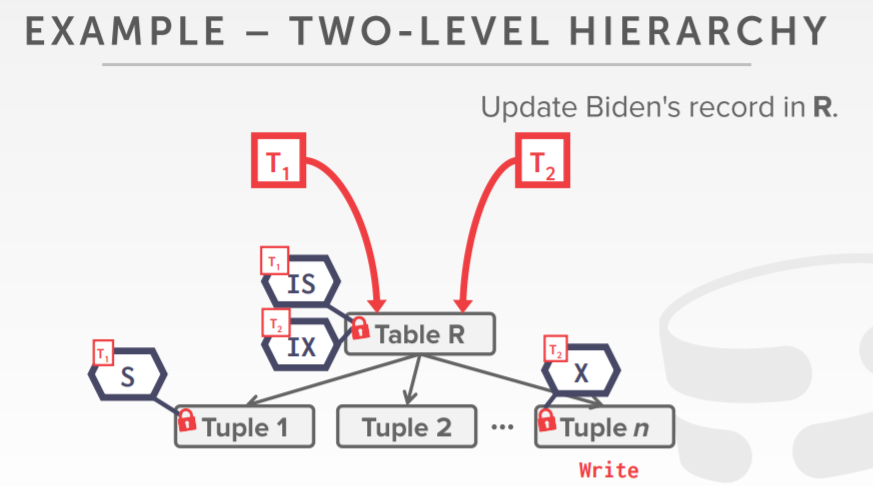
假设有两个事务,T1 要获取某个账户的信息;T2 要增加某个账户的1%
在页节点上,使用 排斥锁+共享锁
特殊的意向锁,使用在更高级别
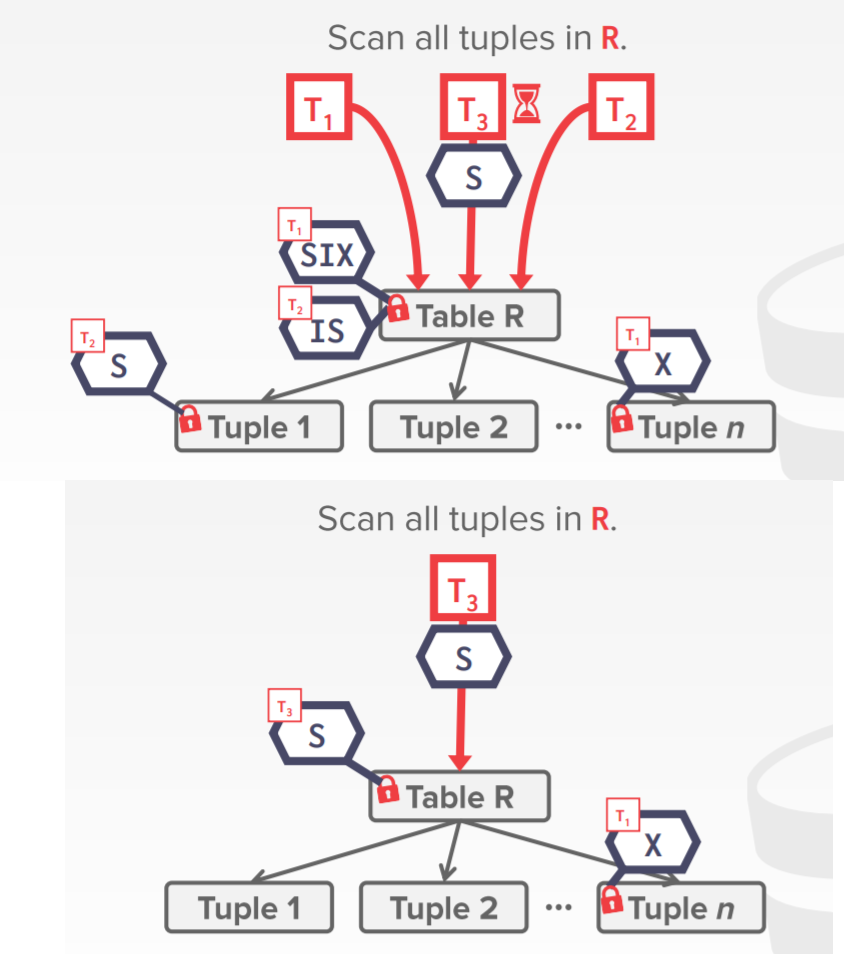
假设有三个事务;T1 scan R表并更新一些tuple;T2读R的单个tuple;T3scan all tuple in R
锁的SQL语句,这不是标准SQL的一部分,不同数据库的语法也不一样
Postgres/DB2/Oracle Modes: SHARE, EXCLUSIVE
MySQL Modes: READ, WRITE
|
|
select … for update 这种方式
|
|
相关文章
Timestamp Ordering Concurrency Control
Basic Timestamp Ordering (T/O) Protocol
使用 时间戳来决定 事务的序列化顺序
如果 TS(Ti) < TS(Tj),那么DBMS需要确保等价的执行串行调度 Ti 在 Tj之前
时间戳分配
- 每个事务都分配一个唯一的、单调递增的时间戳
- 给事务Ti分配时间戳TS(Ti)
- 在事务执行期间,不同的方案在不同的时间分配时间戳
- 多种实现策略
- System Clock.
- Logical Counter.
- Hybrid
basic T/O
- 2PL是悲观策略,T/O是乐观的
- 读写都不需要加锁
- 每个对象 X 都被标记最新的读/写成功的事务时间戳
- W-TS(X) – Write timestamp on X
- R-TS(X) – Read timestamp on X
- 如果事务从“未来”访问一个对象,则会终止、重启
T/O 读操作
|
|
T/O写
|
|
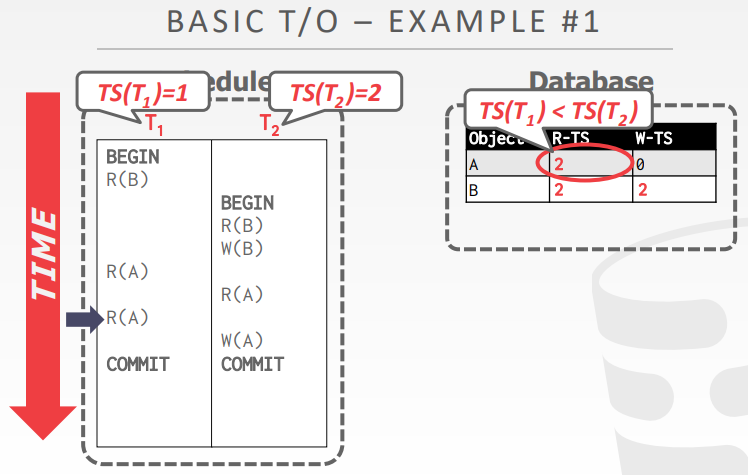
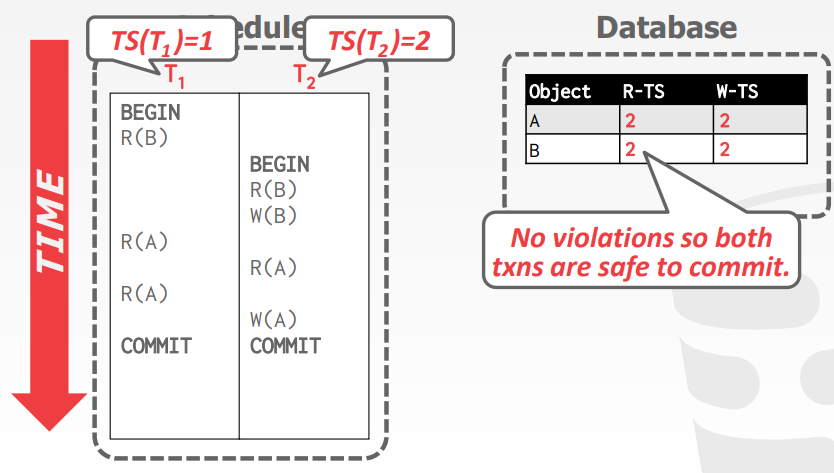
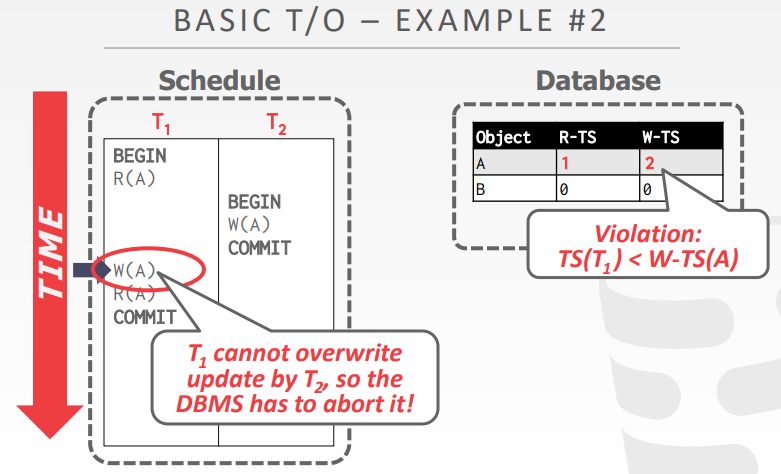
两个例子
- 第一个例子T1的时间戳是
1,T2是2 - 第一次读B时,R(B),R-TS(B)为1,之后T2也读了B,R-TS(B)为2
- 然后T2写B,W-TS(B)为2
- T1再读A,TS(T1) > W-TS(A),可以读取,最后T2的W(A)也满足条件
- 第二个事务 T1的R(A)后,R-TS(A)为1,T2 W(A)后 W-TS(A)为2
- T1再 W(A),此时 TS(T1) < W-TS(A) 违反条件
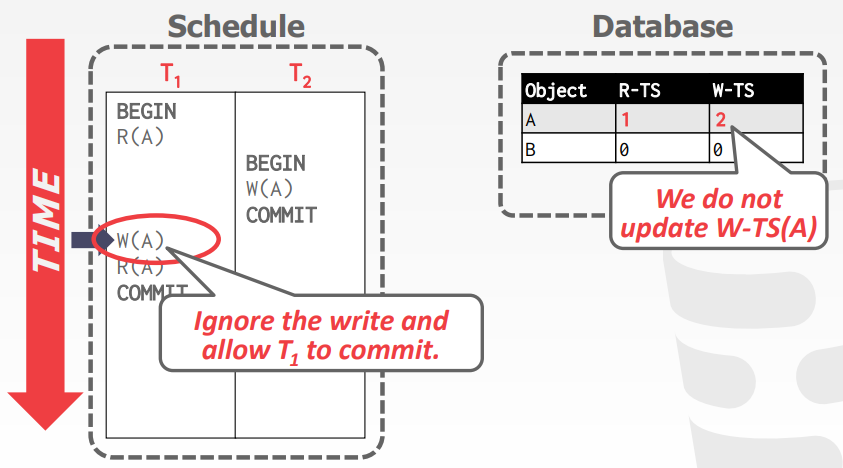
托马斯写规则,thomas write rule
|
|
使用 托马斯写规则后,原先失败,要重启的事务,现在可以继续了
如下,T1的W(A)违反了规则,可以直接忽略掉,继续执行R(A)再提交,不影响事务
BACIS T/O
- 生成的调度是 conflict serializable
- 如果不使用 thomas 写规则,则没有死锁,因为没有事务等待的情况
- 如果短事务造成冲突,则长事务可能会饥饿
- 允许不可恢复的调度
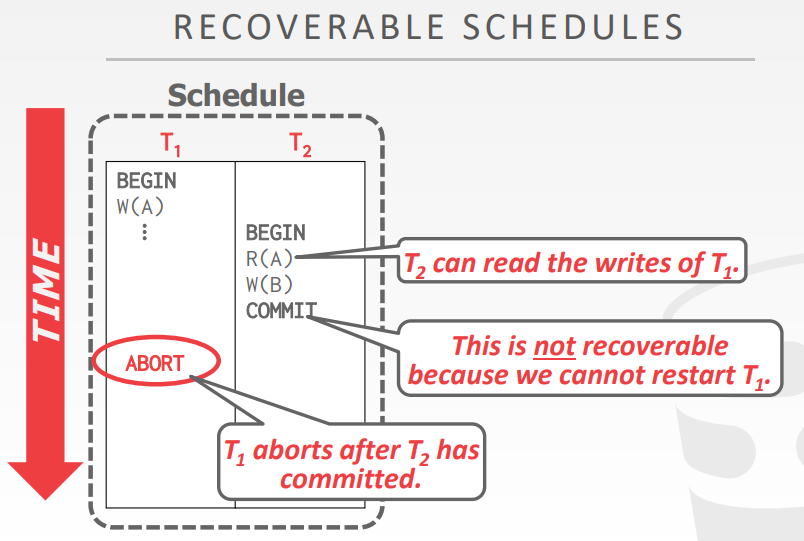
recoverable
- 如果事务是在 所有已读取的更改都提交后,才提交的,那么这个调度就是 可恢复的
- 否则,在宕机恢复重新存储的数据后,DBMS不能保证事务能读取
basic T/O的一些问题
- 拷贝数据到事务的工作空间,更新时间戳都有较高的开销
- 长时间运行的事务都可能会饥饿
- 一个事务可能会读取从不递增的事务
- 如果假设所有的事务冲突都很罕见,所有的事务执行都很短,那么强制事务等待获取锁会增加开销
- 更好的方式是采用无冲突的 优化方式
Optimistic Concurrency Control
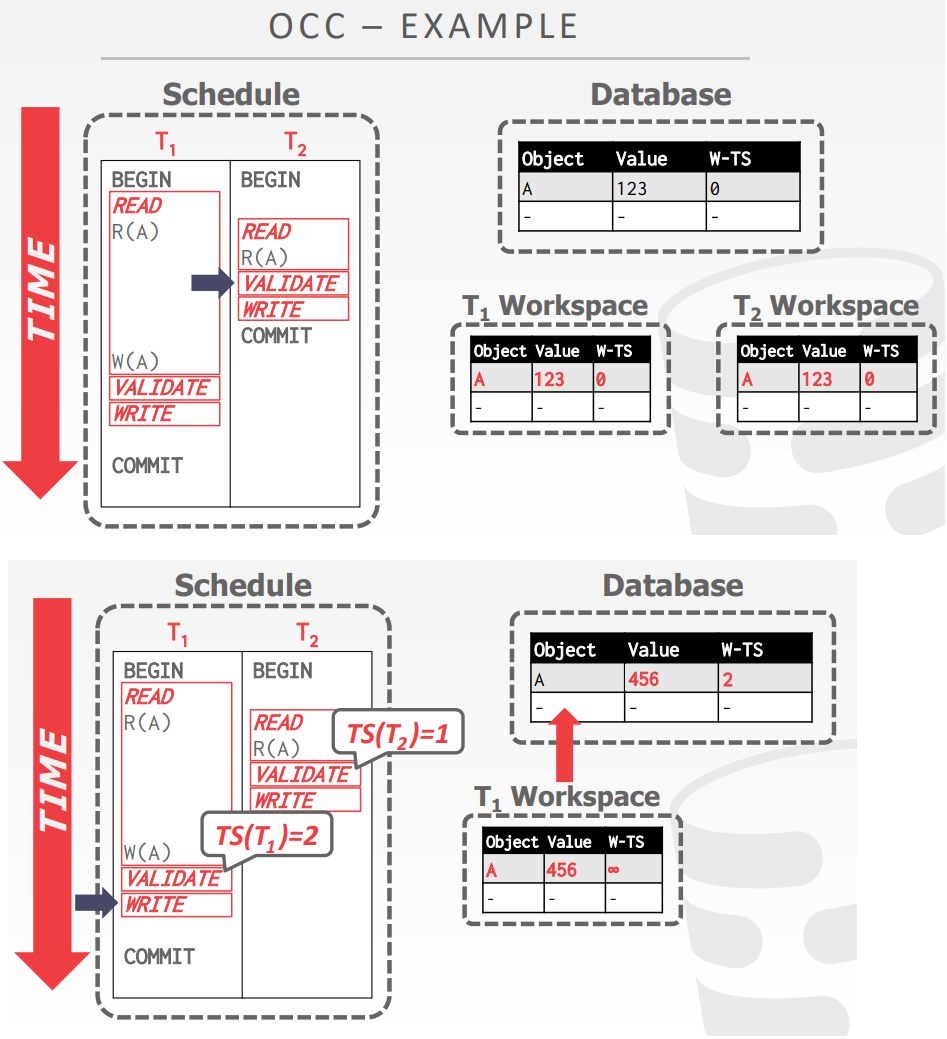
OCC总结
- DBMS为每个事务,创建一个私有的工作空间
- 任何读取对象都拷贝到工作空间中
- 修改也应用到工作空间中
- 当提交时,DBMS比较工作空间的写集合,是否跟其他事务有冲突
- 三个方面阶段
- Read Phase,跟事务的踪读/写集合,并将他们的写存储到私有空间中
- Validation Phase,当事务提交时,检查是否跟其他事务有冲突
- 当提交时,需要确保只允许串行化的调度
- 检查其他事务的RW、WW冲突,并确保冲突时一个方向的,如older -> younger
- 校验的两种方式:Backward Validation、Forward Validation
- Write Phase,如果校验成功,将工作空间中的私有更改应用到数据库;否则终止并重启事务
- DBMS将事务的写集合的更改传播到数据库中,并使其他事务可见
- 假设写阶段一次只能有一个事务
- 使用 wirte latch支持并发校验/写
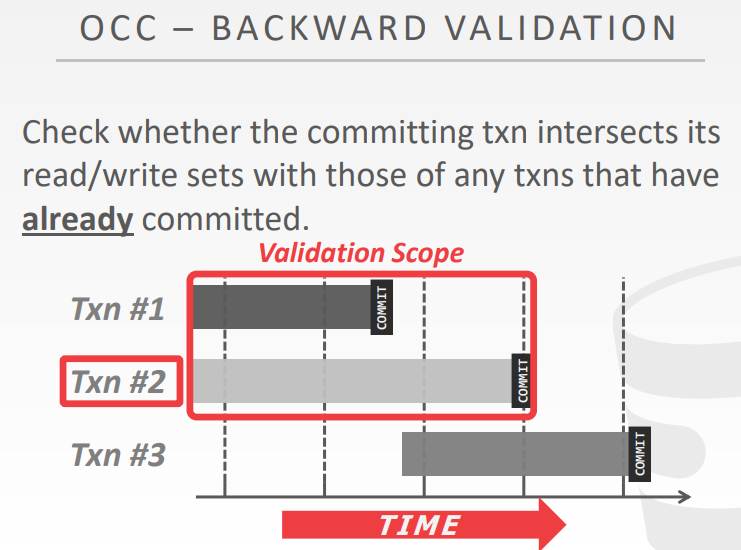
backward validation
检查当前提交的事务,跟任何之前提交的事务,其读/写集合 是否有相交
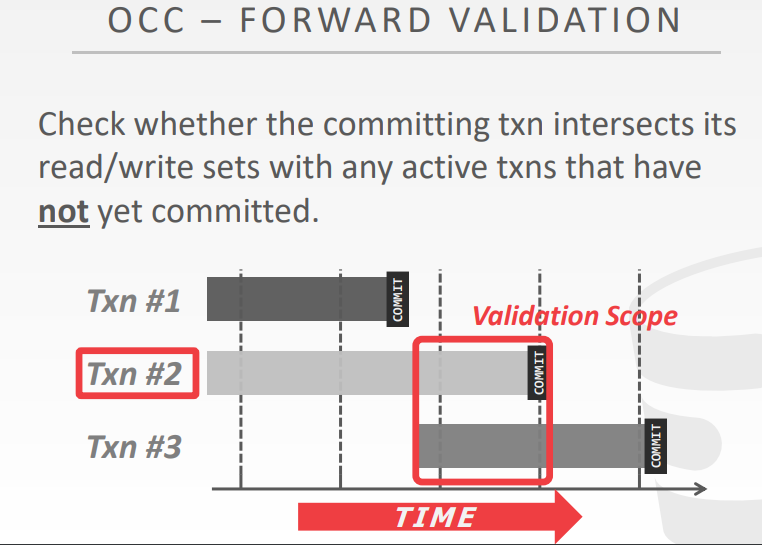
forward validation
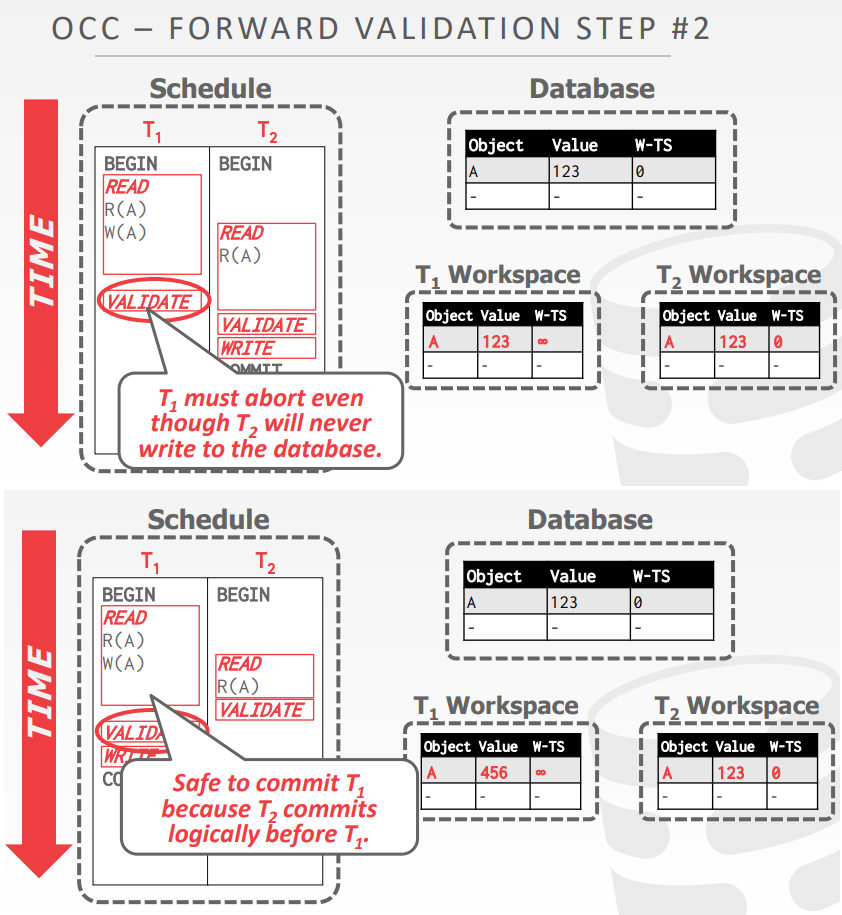
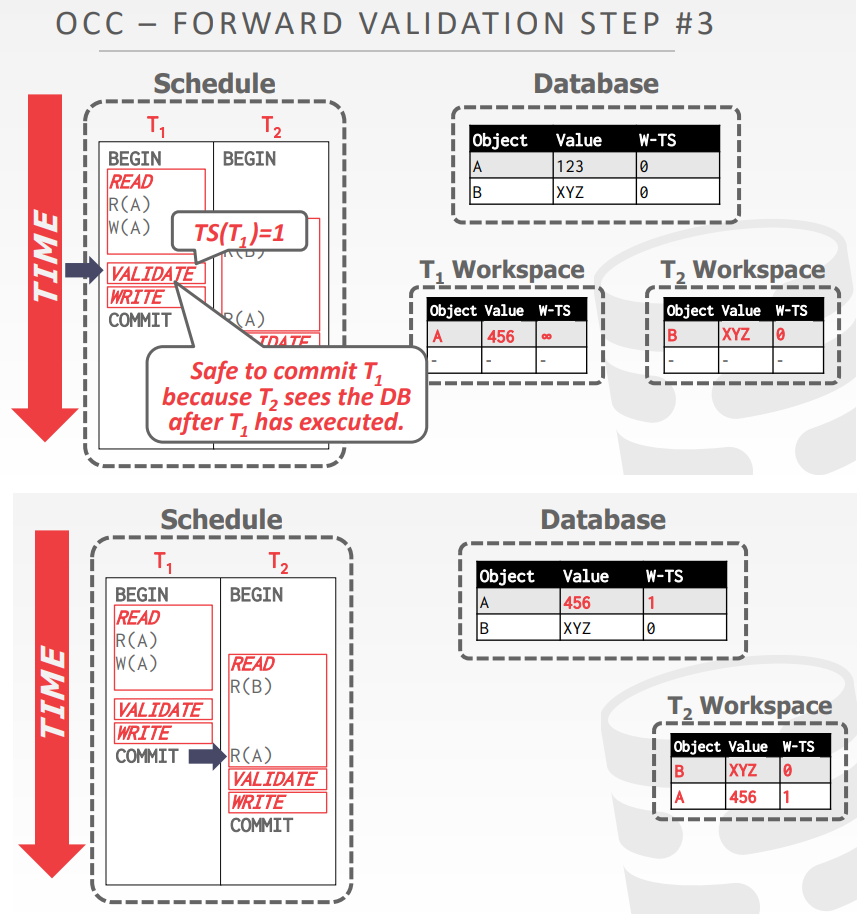
- 检查当前提交的事务,跟现有的活跃事务,其读/写集合 是否有相交
- 在校验阶段开始,给每个事务分配时间戳
- 检查提交事务和其他正在运行的事务的时间戳 顺序
- 如果 TS(Ti) < TS(Tj) 那么下面三种情况之一必须成立
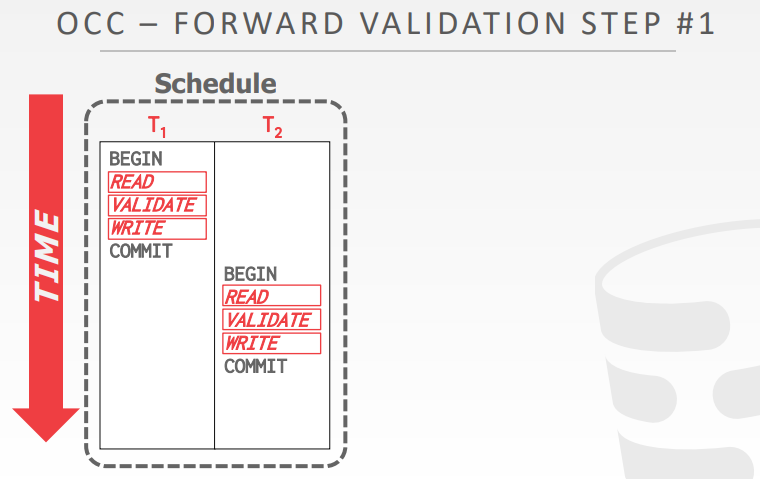
forward validation,如果 TS(Ti) < TS(Tj) 那么下面三种情况之一必须成立
- 第一种,Ti 的所有阶段都在Tj之前完成的
- 第二种,在Tj开始写阶段之前,Ti就完成了,并且Ti 不会写任何Tj要读的对象
- WriteSet(Ti) 和 ReadSet(Tj) 的交集为空
- 第三种,Ti的读阶段在 Tj的读阶段 之前完成,Ti没有写任何 Tj要读/写的对象
- WriteSet(Ti)和ReadSet(Tj)交集为空;WriteSet(Ti)和WriteSet(Tj)交集为空
OCC 总结
- 当并发冲突很低的时候,适合OCC
- 所有的事务都是只读的
- 事务访问的数据子集都是不想交的
- 如果数据库很大,负载没有倾斜,那么conflict可能性比较低,使用lock则是浪费
- 拷贝数据到本地会有很大开销
- 校验阶段,写阶段可能是瓶颈
- 终止比2PL开销更大,因为他们发生在事务执行之后
Isolation Levels
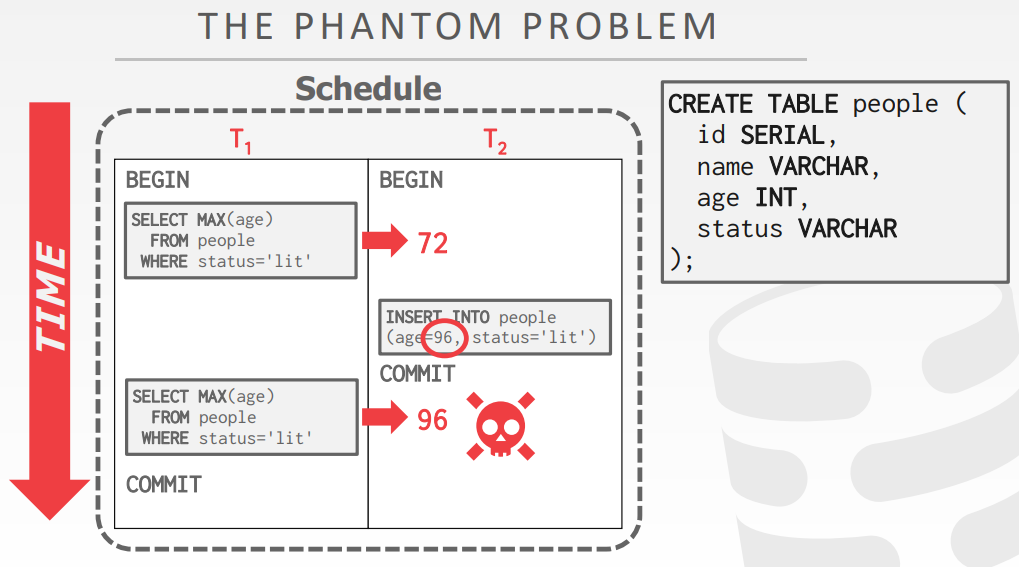
幻读问题
- T1 锁住的是已经存在的记录,而不是正在进行的记录
- 如果集合对象是固定的,读/写独立条目的conflict serializability才能保证可串行化
- 三种实现方式
- Approach #1: Re-Execute Scans
- DBMS跟踪事务执行的所有查询中的 WHERE 子句
- 必须为事务中的每个范围查询保留扫描的集合
- 提交后,只重新执行每个查询的扫描部分,并检查是否生成相同的结果
- 比如,运行update查询的scan,但不修改匹配的tuple
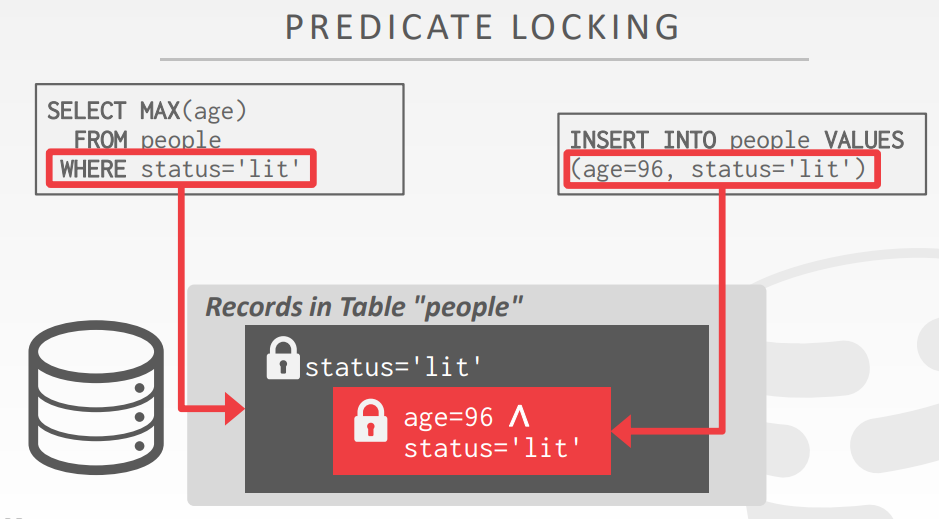
- Approach #2: Predicate Locking
- 提议的方案来自于System R
- 谓词上的共享锁,在SELECT 查询的where子句中;谓词的排斥锁在UPDATE、INSERT、DELETE的WHERE子句中
- 除了HyPer,没有在其他系统中实现过
- Approach #3: Index Locking
index locking
- 如果状态属性上有一个索引,那么事务可以用 status=‘lit’ 锁定包含数据的索引页
- 如果没有 status=‘lit’这个记录,事务必须锁定该数据条目所在的索引页(如果存在的话)
- 如果没有合适的索引,那么事务必须获得
- 在每个页上设置一个锁,防止一条变更语句 status=‘lit’
- 表本身的锁,用来预防 status=‘lit’被添加或者删除
隔离级别
- 可串行化很有用,因为它允许程序员忽略并发问题
- 但是它限制了并发的能力,降低了性能
- 我们需要更弱一些的并发级别,来提供伸缩性
- 控制一个事务,暴露给其他并发事务操作的程度
- 将事务暴露于未提交的更变为代价,提供更大的并发性
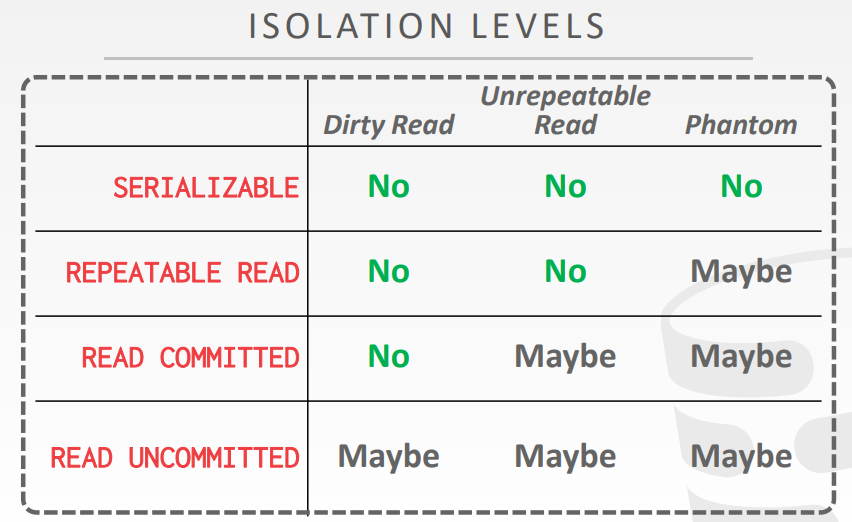
- Dirty Reads、Unrepeatable Reads、Phantom Reads
四种隔离级别
- SERIALIZABLE: No phantoms, all reads repeatable, no dirty reads.
- REPEATABLE READS: Phantoms may happen.
- READ COMMITTED: Phantoms and unrepeatable reads may happen.
- READ UNCOMMITTED: All of them may happen.
用2PL来实现各种隔离级别
- SERIALIZABLE: Obtain all locks first; plus index locks, plus strict 2PL.
- REPEATABLE READS: Same as above, but no index locks.
- READ COMMITTED: Same as above, but S locks are released immediately.
- READ UNCOMMITTED: Same as above but allows dirty reads (no S locks).
SQL-92 的隔离级别,不是所有数据库都支持的 SQL-92 访问模式
- Only two possible modes:
- READ WRITE (Default)
- READ ONLY
- Not all DBMSs will optimize execution if you set a txn to in READ ONLY mode.
|
|
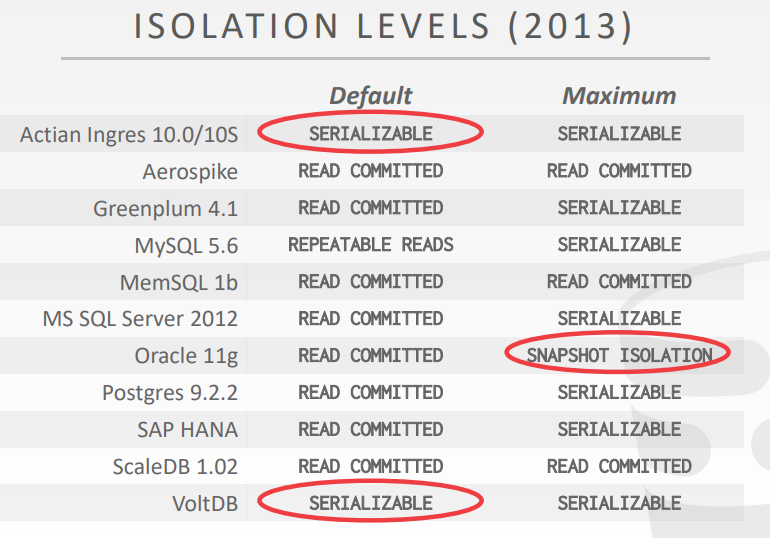
isolation levels 2013
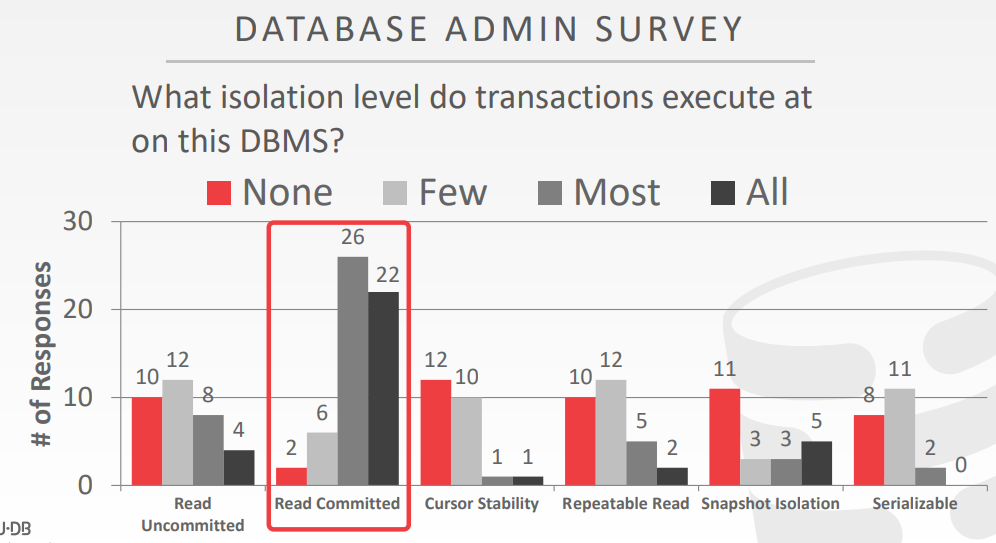
数据库管理员调查,在不同的事务隔离级别中,发生的比例是多少
相关文章
- On optimistic methods for concurrency control
- Thomas Write Rule
- precision locking,Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems
- HyPer(main-memory-based) – A Hybrid OLTP&OLAP High Performance DBMS
- When is “ACID” ACID? Rarely.
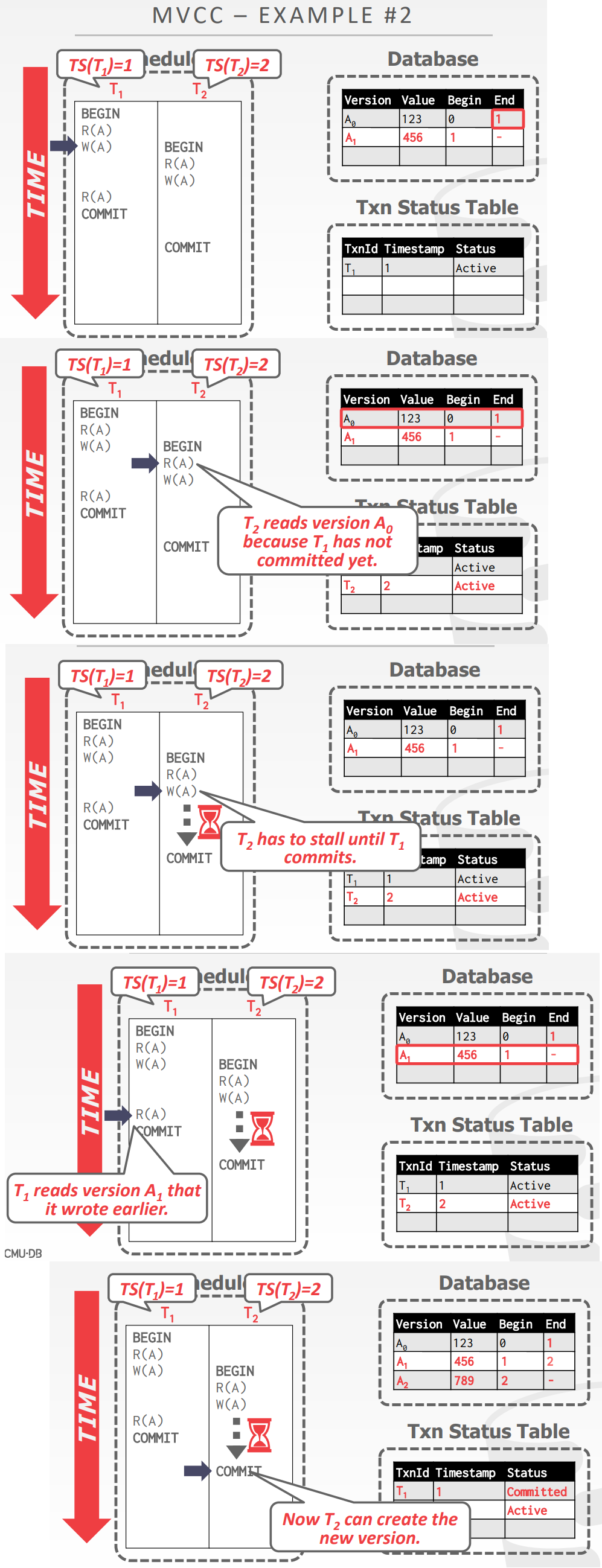
Multi-Version Concurrency Control
概述
- 对于数据库中的单个逻辑对象,维护多个物理版本
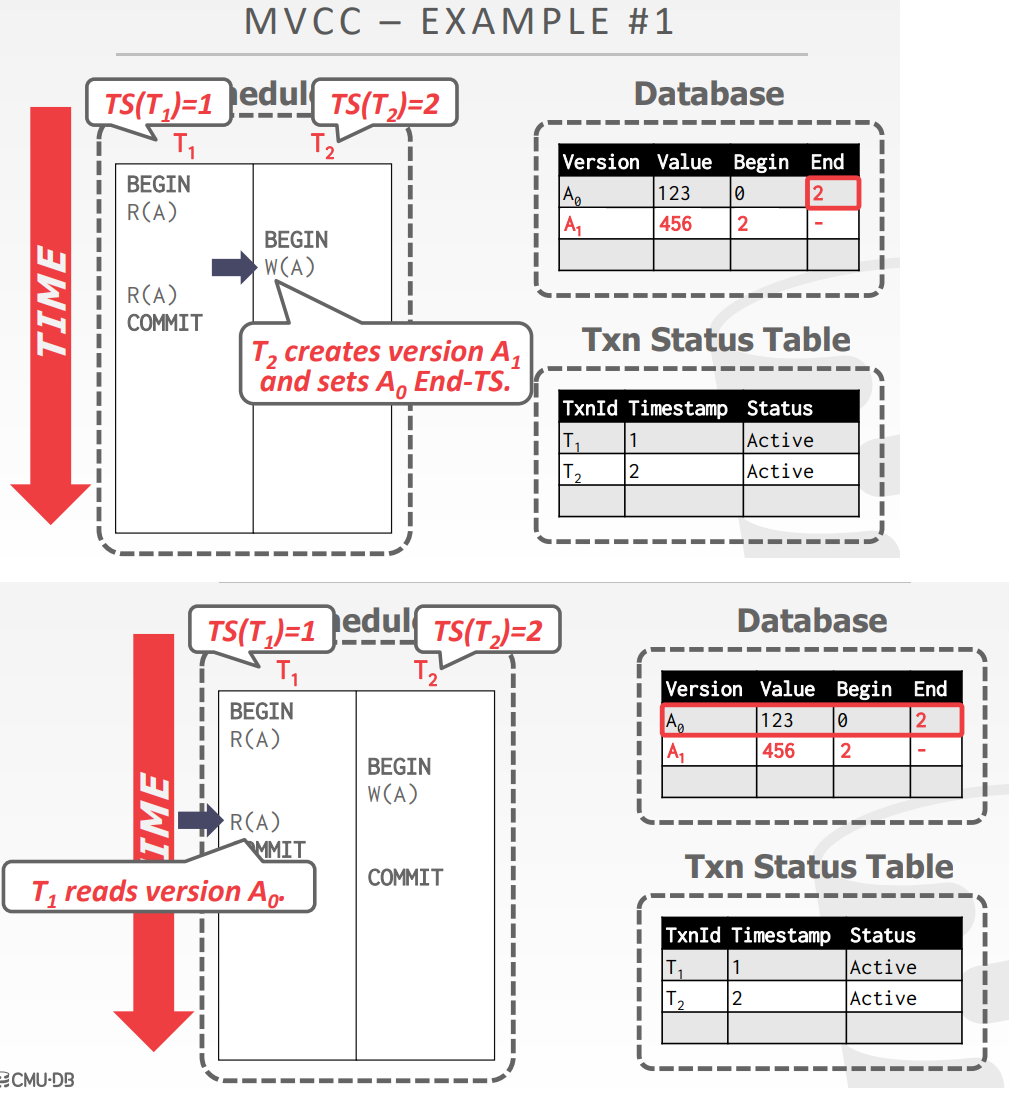
- 当事务写对象时,DBMS创建这个对象的新版本
- 读对象时,读取事务开始时对象的最新版本
- 来自于1979年MIT的博士论文
- 最早的实现是1980年早期的 Rdb/VMS(现在叫Oracle Rdb)、以及DEC 的InterBase(现在开源为Firebird)
- 这两篇文章都出自NuoDB联合创始人 Jim Starkey 之手
- 写不会阻塞读、读不会阻塞写
- 只读事务可以读取一致性快照,不需要lock,使用时间戳来决定可见性
- 支持 time-travel 查询
- MVCC不仅仅是一个并发控制协议,它完全影响了DBMS事务管理和数据库的方式

Concurrency Control Protocol
并发控制协议
- Approach #1: Timestamp Ordering
- 给事务分配一个方时间戳,来决定串行顺序
- Approach #2: Optimistic Concurrency Control
- 三阶段的协议,使用私有的工作空间存放新版本
- Approach #3: Two-Phase Locking
- 事务在读/写逻辑tuple时,在物理版本上获取合适的锁
Version Storage
version storage
- DBMS使用tuple的指针字段,为每个逻辑tuple创建版本链
- DBMS在运行时,可以找到特定事务的可见版本
- 索引总是指向链的头部
- 不同的存储模式决定,怎么/在哪里存储每个版本
- Approach #1: Append-Only Storage
- 新版本通过append的方式到相同的表空间
- Approach #2: Time-Travel Storage
- 老版本拷贝到独立的表空间
- Approach #3: Delta Storage
- 修改属性的原始值 被复制到一个独立的增量的表空间
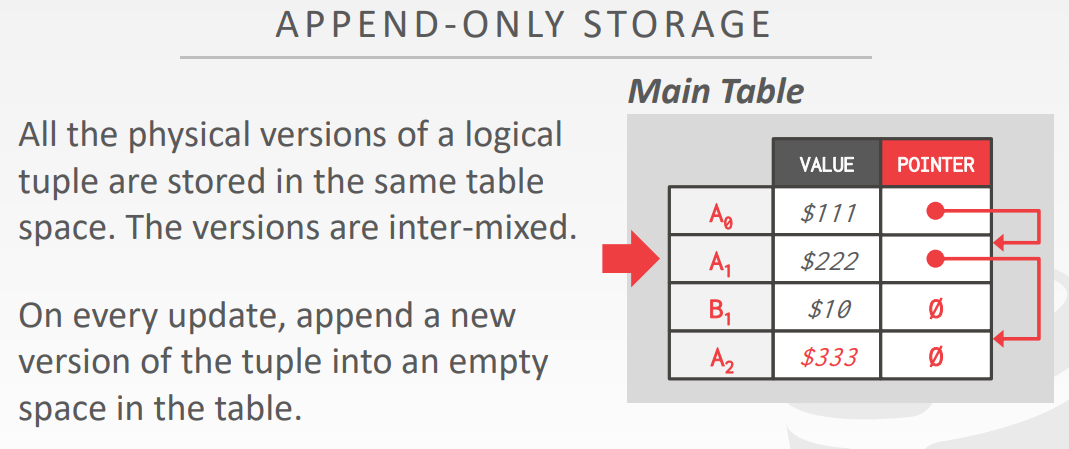
Append-Only Storage
- 所有逻辑tuple的物理版本,都存储到相同的表空间
- 这些版本是内部混合存储的
- 在每次更新时,追加一个新tuple版本到表中的空的空间中
- 下图是append存储方式,A0通过指针找到A1,A1通过指针找到A2
- 版本链的顺序
- Approach #1: Oldest-to-Newest (O2N)
- 追加新版本到链的末尾,必须通过遍历的方式查找
- Approach #2: Newest-to-Oldest (N2O)
- 不用遍历查找,但是每个新版本,都需要更新索引指针
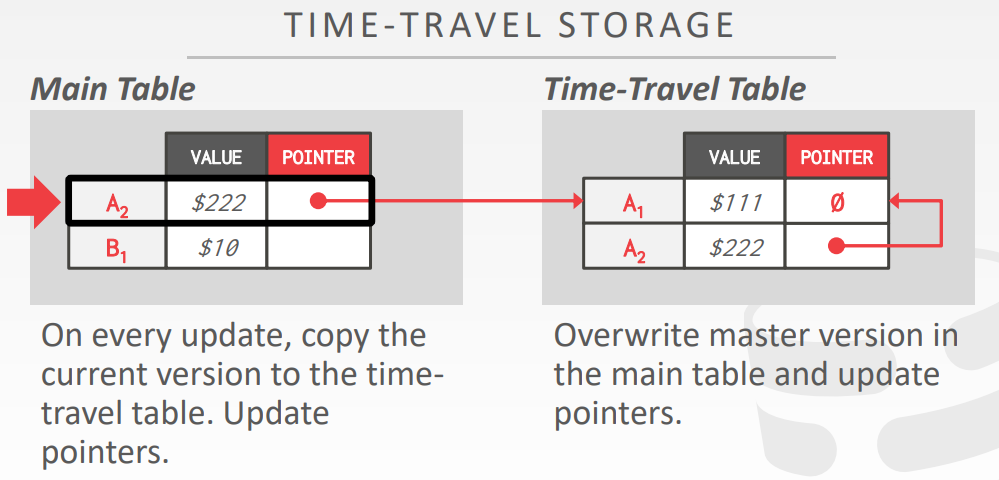
time-travel storage
- 对于每次更新,将当前版本拷贝到 时间旅行表中,并更新指针
- 覆盖主表中的主版本,并更新指针
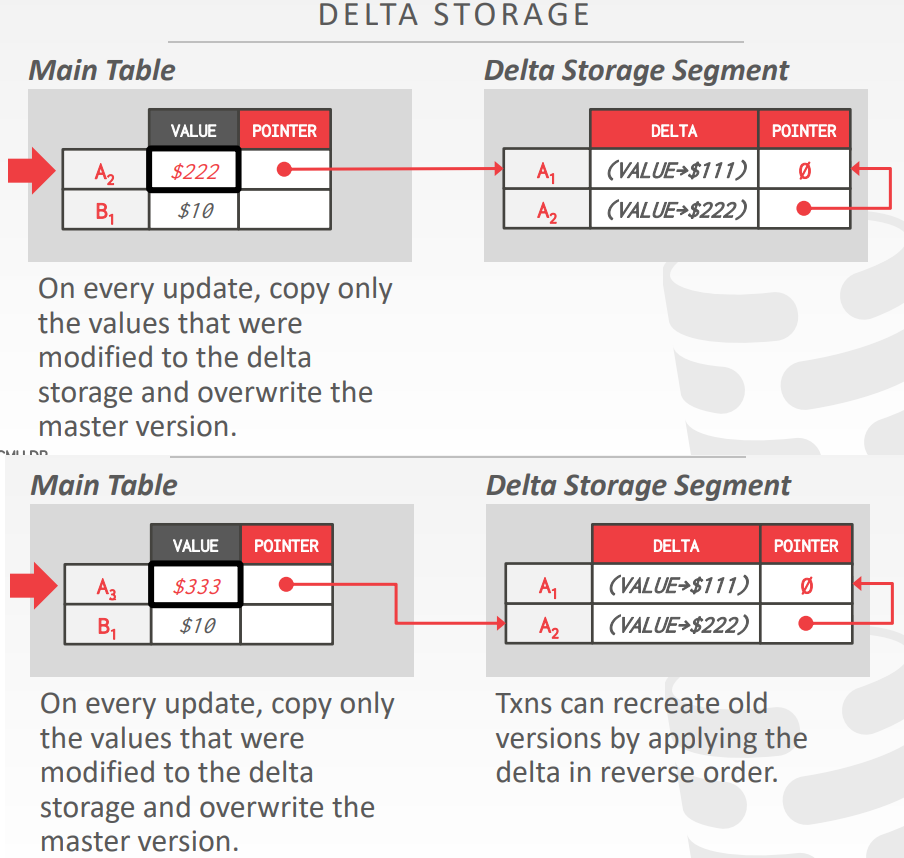
delta storage
- 对于每次更新,拷贝修改的值到 delta-storage,再覆盖主版本
- 事务可以通过反向应用增量来创建 旧版本
- 一开始主表的最新版本是A2,指向delta的A1,之后主表增加了A3,再更新指针 指向delta的A2
- 其指针变更过程有点像 time-travel
Garbage Collection
垃圾收集
- 随着时间推移,DBMS需要回收物理版本
- DBMS中没有活动的事务可以“看到”哪个版本(SI)
- 版本通过终止的事务创建
- 设计决策
- 怎样看到过期的版本
- 如何确定回收内存是安全的
- Approach #1: Tuple-level
- 通过直接检查tuple找到旧版本
- Background Vacuuming vs. Cooperative Cleaning
- Approach #2: Transaction-level
- 事务跟踪他们的旧版本,这样DBMS就不用scan tuple来决定可见性
tuple level的垃圾收集,backgroud vacuuming
- 独立的线程
- 周期性的扫描表,并查找可回收的版本,工作在另外一个存储中
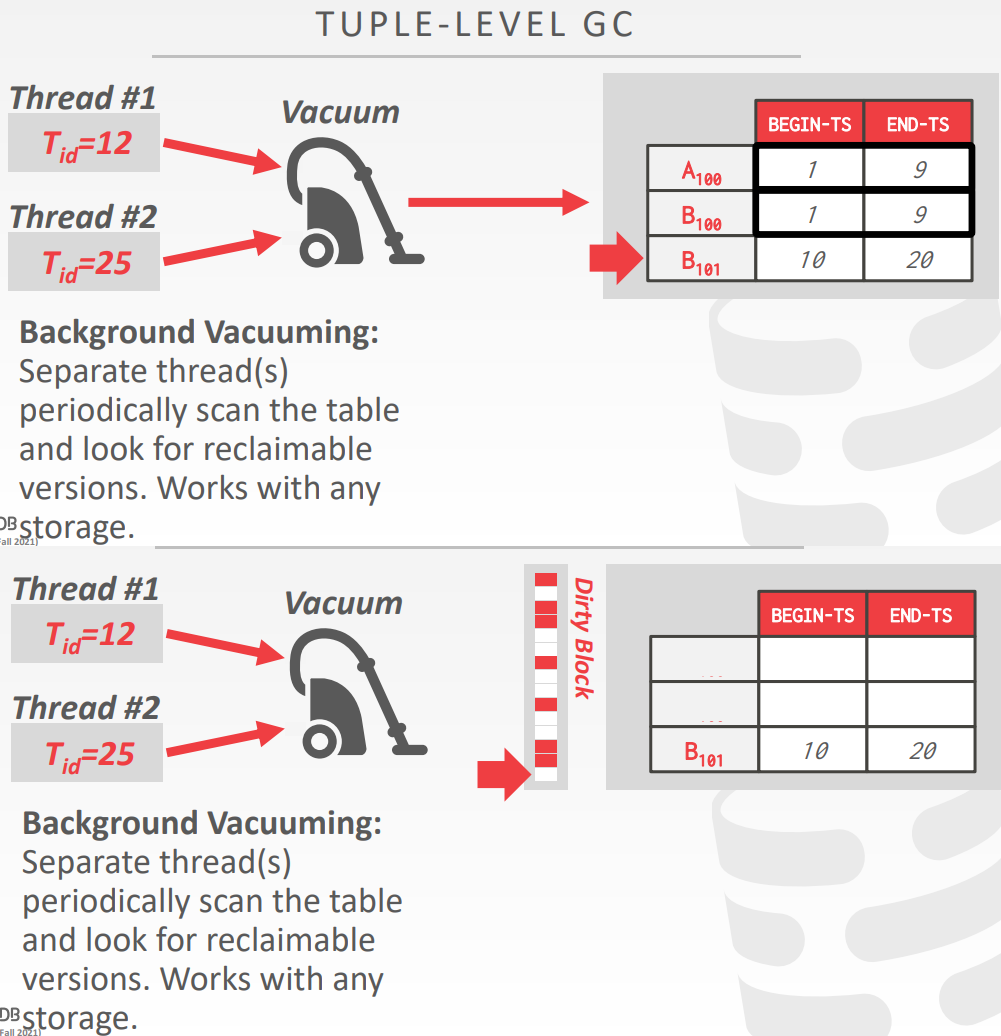
tuple level的垃圾收集,Cooperative
- 工作线程识别出可回收的版本,在遍历版本链时
- 这种方式能用于O2N,即older -> new这种模式下

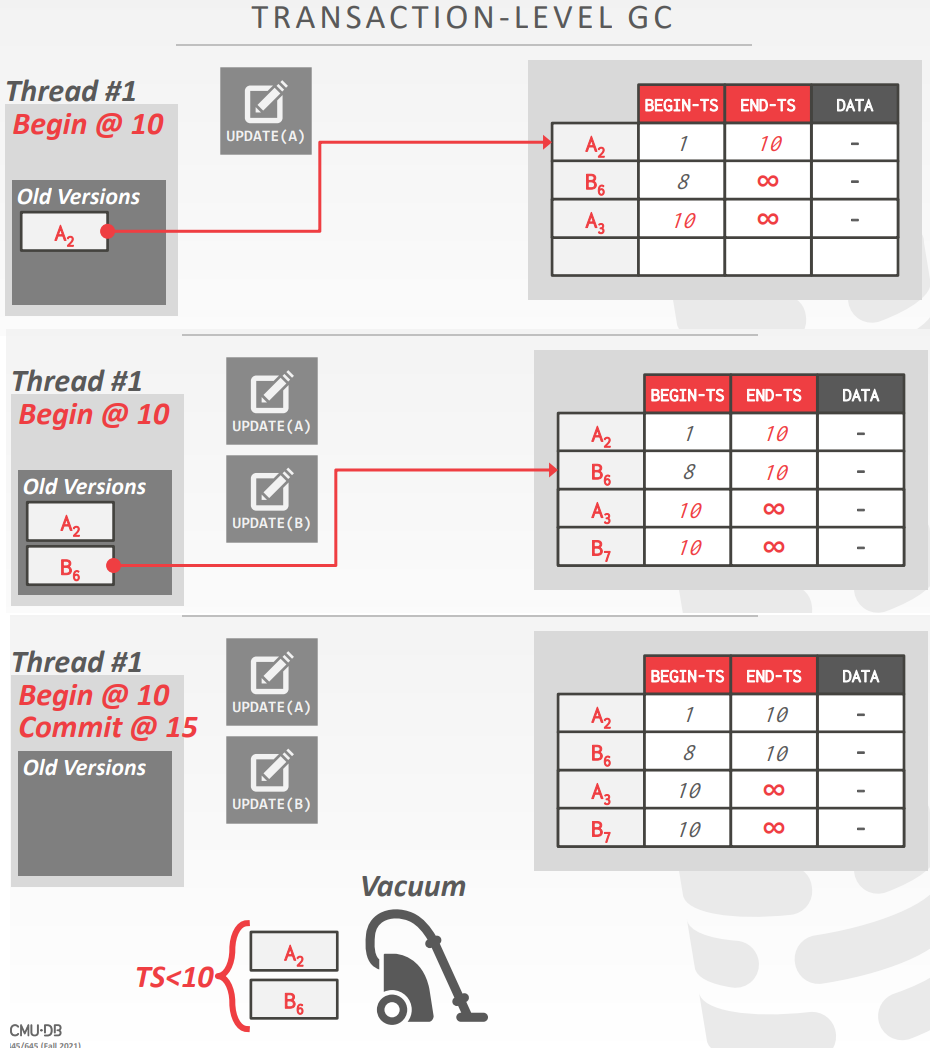
transaction level 垃圾收集
- 每个事务都跟踪它自己的 读/写集合
- 当所有的版本由最终事务创建后,DBMS决定其不再可见
- 需要多个线程足够块的回收内存
Index Management
索引管理
- 主键索引指向版本链的head
- DBMS更新主键索引的频率,取决于tuple更新时,是否创建新版本
- 如果事务更新了一个tuple的主键属性,那么这相当于 先delete,再insert
- 二级索引则更复杂
二级索引
- Approach #1: Logical Pointers
- 对每个tuple使用一个不改变的固定标识符
- 需要一个额外的间接层
- Primary Key vs. Tuple Id
- Approach #2: Physical Pointers
- 使用版本链头的物理地址
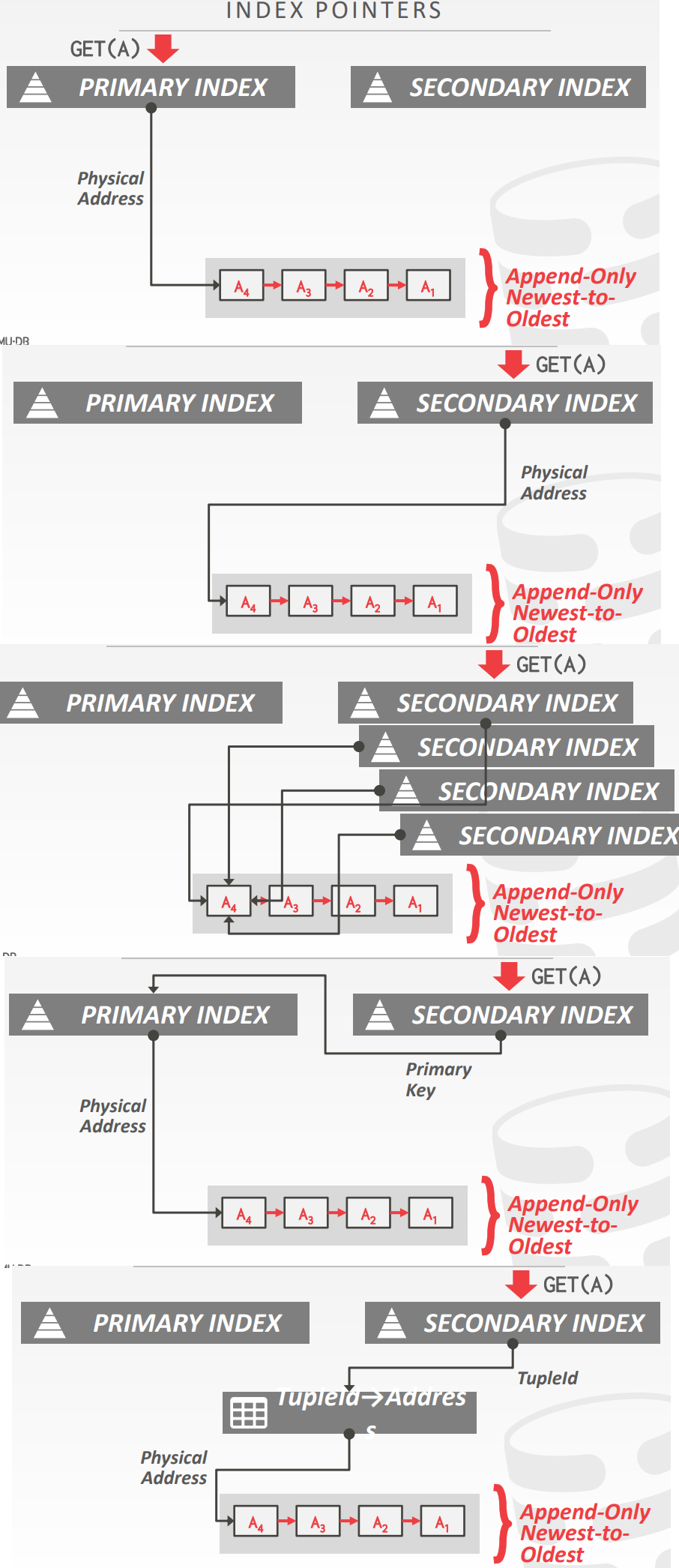
MVCC index
- 通常不适用他们的key存储tuple的版本信息
- 除了MySQL,索引组织表
- 每个索引必须支持不同快照的不同key
- 相同key可以指向不同快照中的不同逻辑tuple
- 每个索引的底层数据数据结构必须支持存储 非唯一key
- 使用额外的执行逻辑对pkey/unique index执行条件插入
- 自动的检测key是否存在,然后insert
- worker可以在一起获取中返回多个条目,然后必须跟随指针找到合适的物理版本
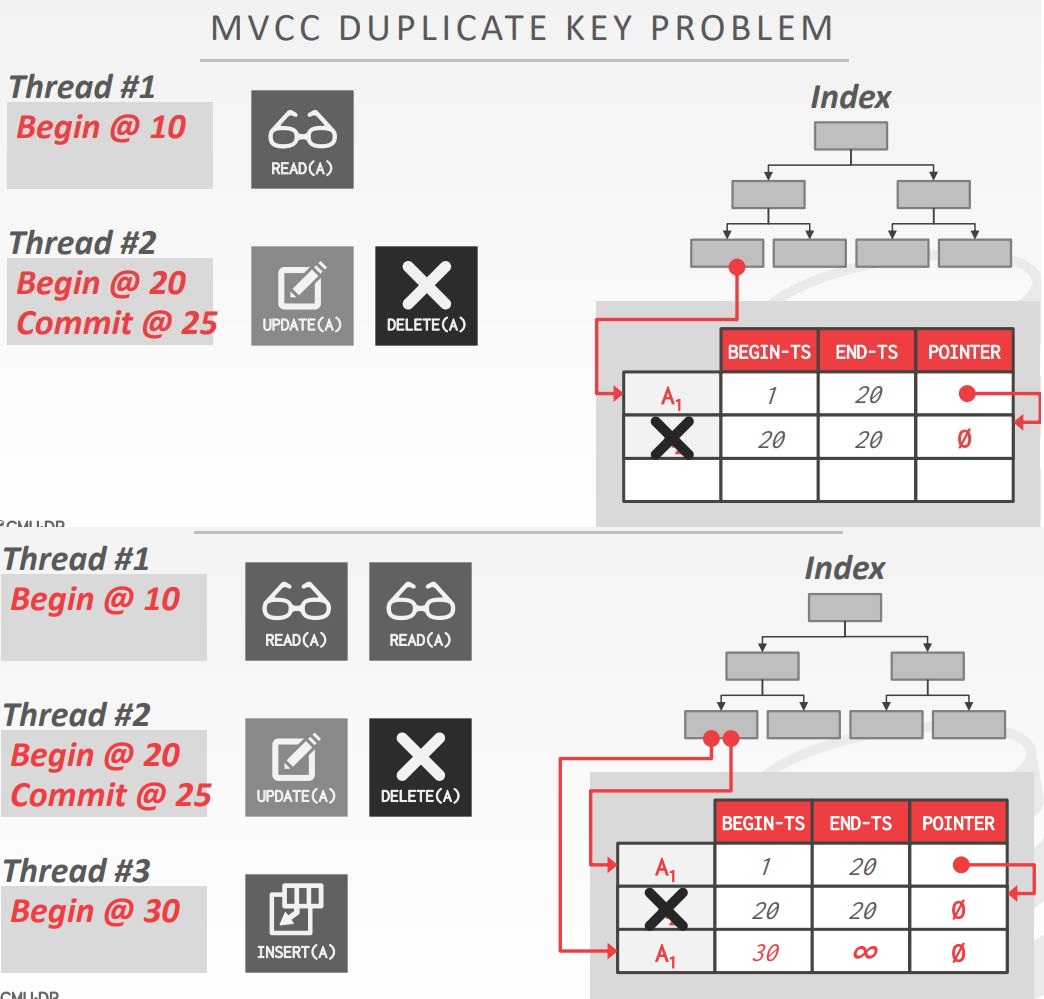
MVCC delete
删除概述
- 当逻辑删除tuple的所有版本不可见时,DBMS才物理删除tuple
- 如果一个tuple被删除,那么在最新版本之后不能有该元组的新版本
- 没有 写-写重复、first-write win
- 需要有一种方式来表示,tuple在某个时间点上被逻辑的删除
- Approach #1: Deleted Flag
- 维护一个flag指明,逻辑tuple在罪行物理版本之后被删除
- 可以放在tuple的 head中,或者单独的一个列中
- Approach #2: Tombstone Tuple
- 创建一个空的物理版本指明有一个逻辑tuple被删除了
- 为墓碑tuple使用一个单独的池,在版本链指针中使用一个特殊的bit pattern,以减少存储开销
各种数据库的 MVCC 实现总结
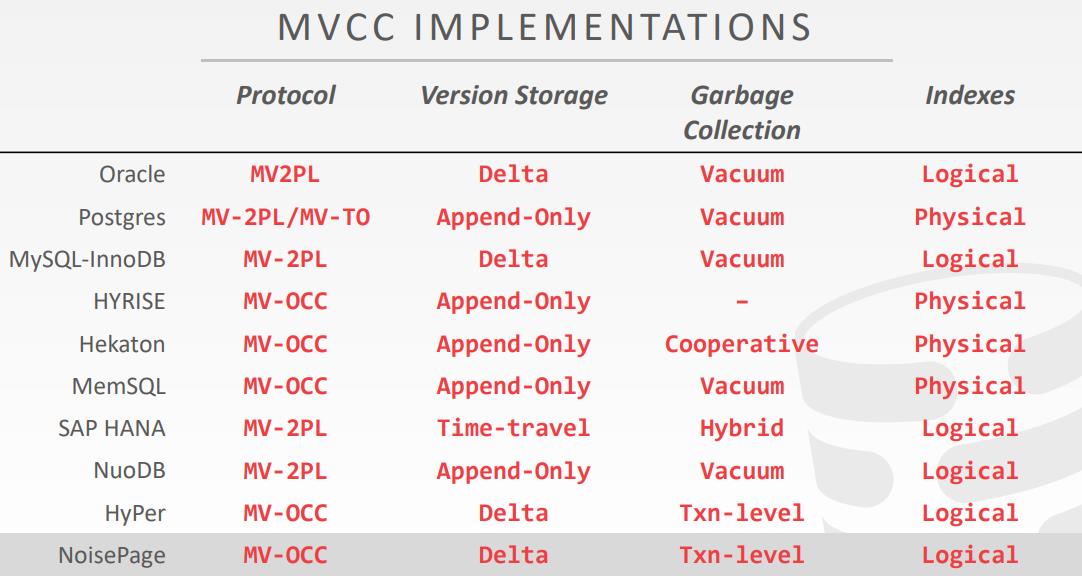
相关文章
- MVCC 1979年发布的最初协议
- Jim Starkey
- Oracle Rdb
- InterBase
- Firebird
- Why Uber Engineering Switched from Postgres to MySQL