卡内基梅隆的数据库课程-5
课程地址
https://15445.courses.cs.cmu.edu/fall2021/schedule.html
Introduction to Distributed Databases
并行 VS 分布式
- 并行数据库
- 每个节点在物理上都比较近
- 节点之间的通讯是高速LAN
- 通讯花费比较小
- 分布式DMBS
- 节点的物理位置比较远
- 节点通讯走公网
- 节点的通讯开销不能忽略
分布式DB
- 使用单节点介绍的技术,现在来支持分布式环境中的事务和查询执行
- 优化、查询几乎
- 并发控制
- 日志、恢复
- 分布式的架构指明,哪些共享资源可以被CPU直接访问
- 这影响了CPU之间的彼此协调,以及他们在数据库的什么地方检查/存储对象
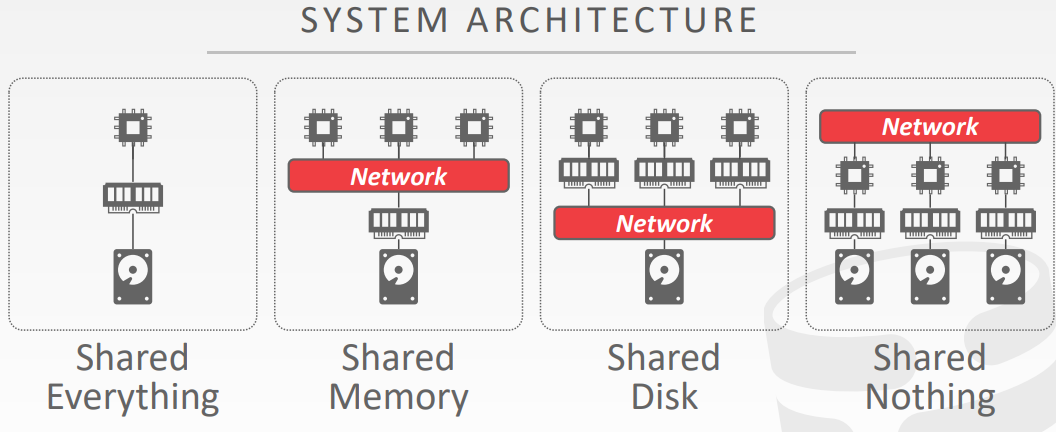
分布式数据库的架构
- shared everything
- shared memory
- CPU通过内部连接访问共享的内存地址
- 每个CPU都有所有内存数据结构的全局视图
- 每个处理器上的DBMS实例,知道其他实例
- 没什么实际的DBMS用这种架构,只有HPC high performace computing 是这种架构
- shared disk
- 每个CPU通过内部连接访问单个逻辑磁盘,每个CPU都有他们自己的私有内存
- 对于存储层来说,计算层的扩容是独立的
- 必须在CPU之间发送消息,让他们学习到其他节点的状态
- shared nothing
- 每个DBMS实例都有它自己的CPU、内存、磁盘
- 节点之间通讯只能通过网络
- 扩容比较困难、确保一致性比较难、性能和效率比较高


早期的分布式数据库
- MUFFIN – UC Berkeley (1979)
- SDD-1 – CCA (1979)
- System R* – IBM Research (1984)
- Gamma – Univ. of Wisconsin (1986)
- NonStop SQL – Tandem (1987)

设计问题
- 应用如何找到数据?
- 如果再分布式数据中执行查询?
- Push query to data.
- Pull data to query.
- DBMS如何确保正确性?
同质节点 VS 非同质节点
- Approach #1: Homogenous Nodes
- 集群中的每个节点都执行相同的任务集合,尽管数据分区不同
- 使配置和故障转移更容易
- Approach #2: Heterogenous Nodes
- 节点被分配特殊任务
- 允许一个物理节点承载专用任务的多个虚拟节点
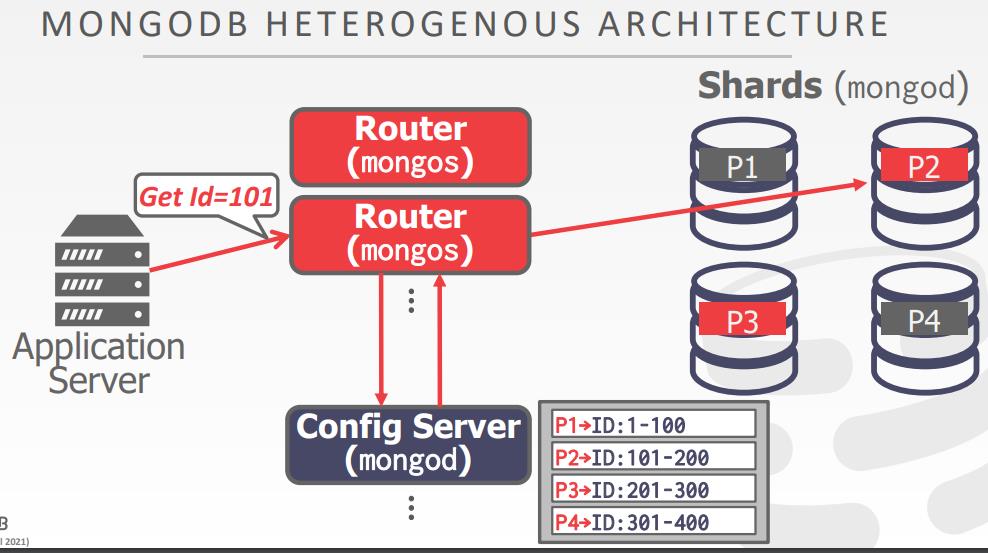
数据的透明性
- 用户不需要知道数据的的物理分布,表如何被分区、复制
- 一个查询可以工作于单个节点的DB,同样也可以运用于分布式DB
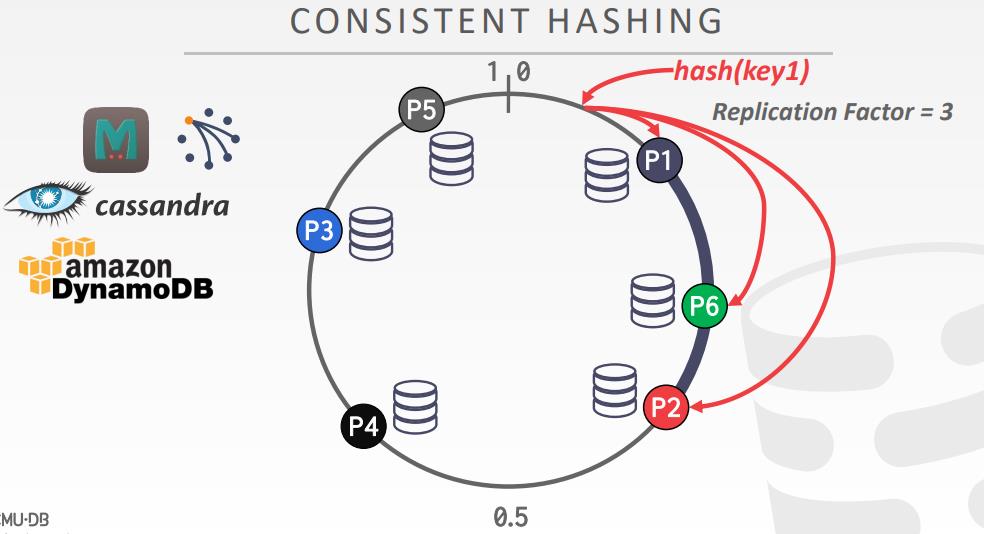
数据分区
- NoSQL通常叫 sharding
- 每个节点执行一个查询片段,然后再做合并
- naive表分区,每个节点都有全量的数据
- 水平分区,表的tuple包含不想交的集合
- 选择按大小、负载、使用平均量划分数据库的列
- 物理分区,shared nothing;逻辑分区 shared disk
- hash分区,range分区
一致性hash,以及Replication Factor
单节点 vs 分布式
- 单节点的事务只需要访问一个分区
- DBMS不需要协调其他节点上的并发事务
- 分布式事务需要访问一个或多个分区
- 需要很大的协调开销
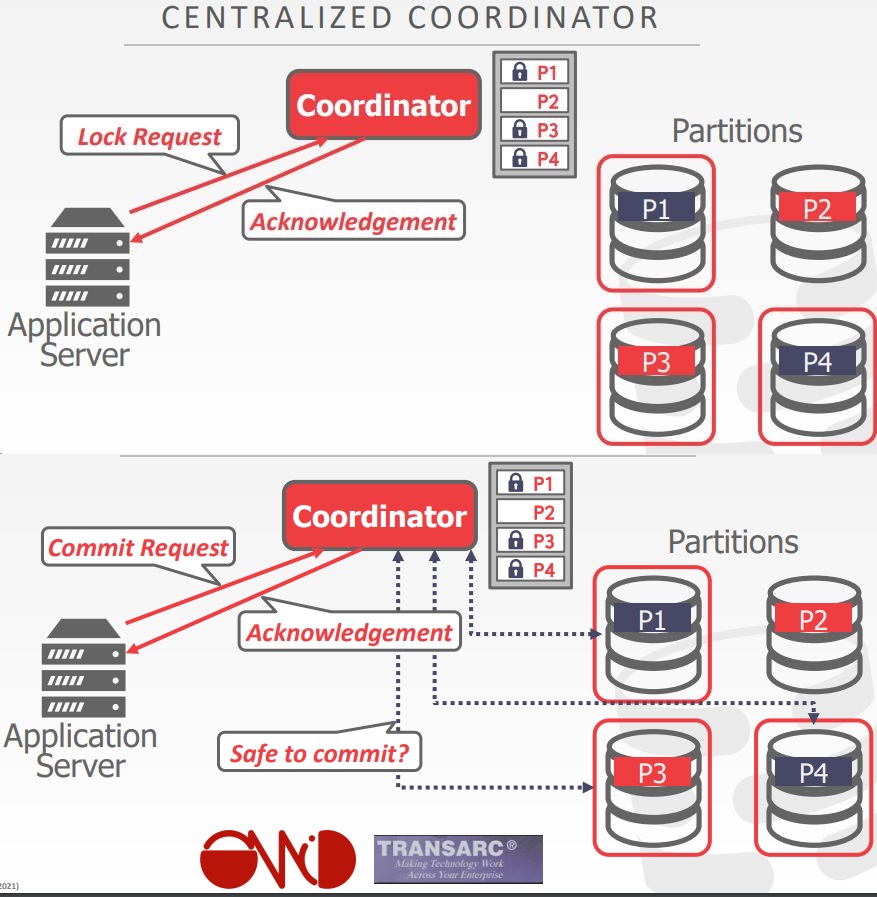
事务协调
- 如果DBMS支持多个操作,以及分布式事务,就必须要一种方式协调他们执行
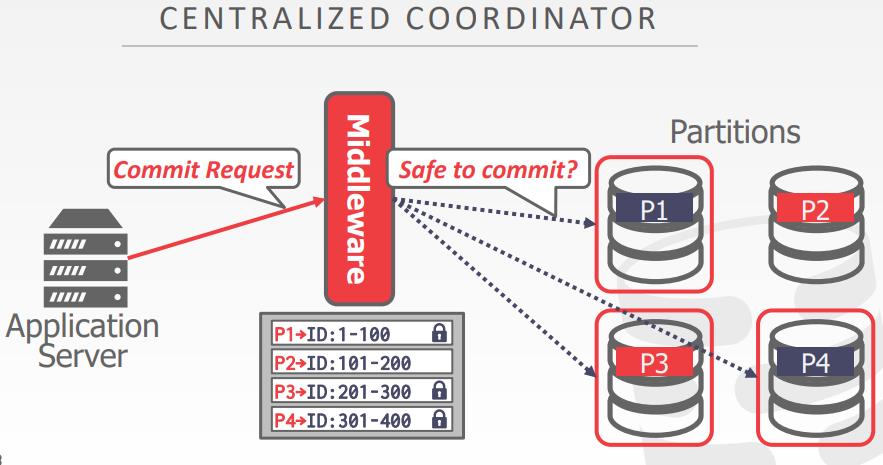
- 中心化的方式
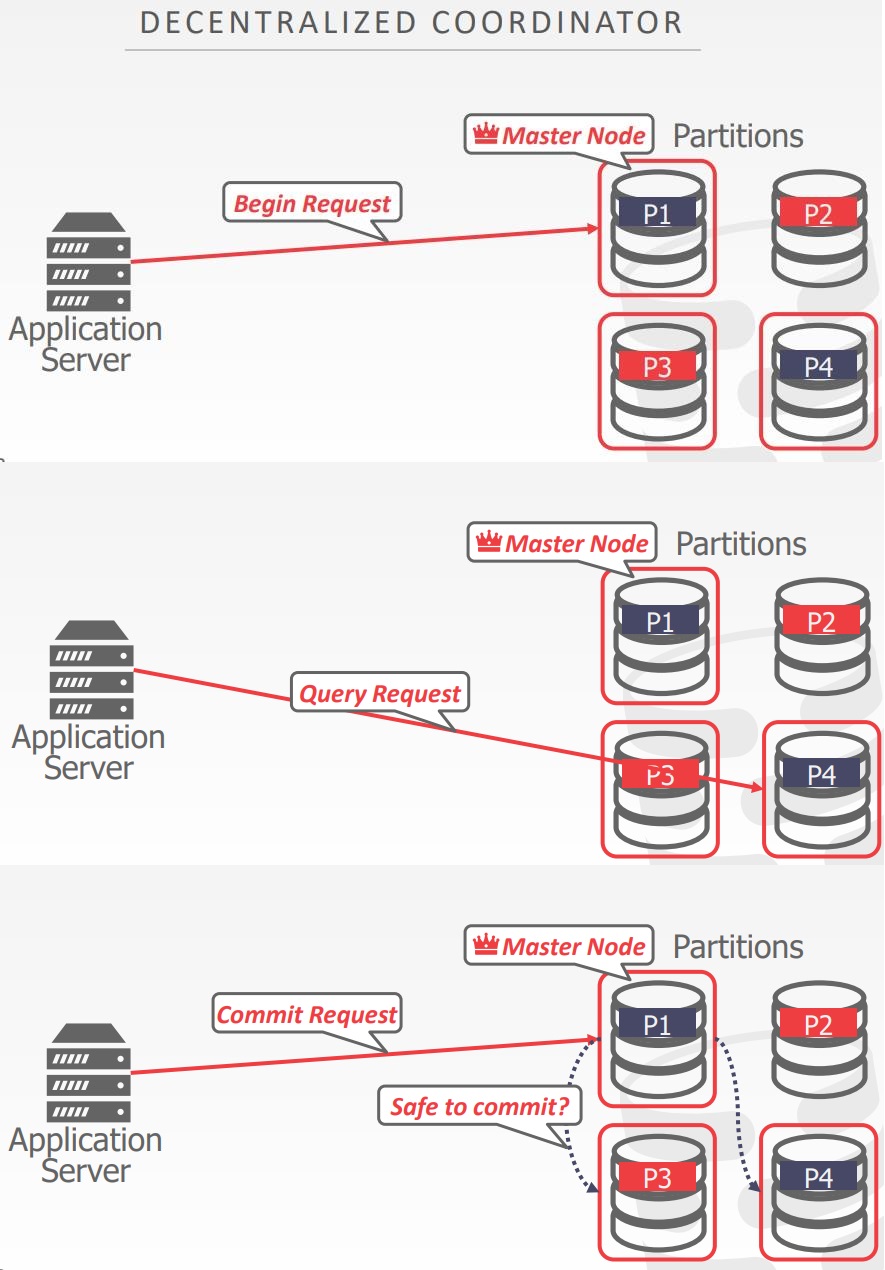
- 去中心化的方式
- TP monitor对于DBMS是一个中心化协调的例子
- 开发于1970-1980年代,提供终端和大型机之间的事务
- ATM、航空公司预定
- 现在的数据库也支持这个功能
分布式并发控制
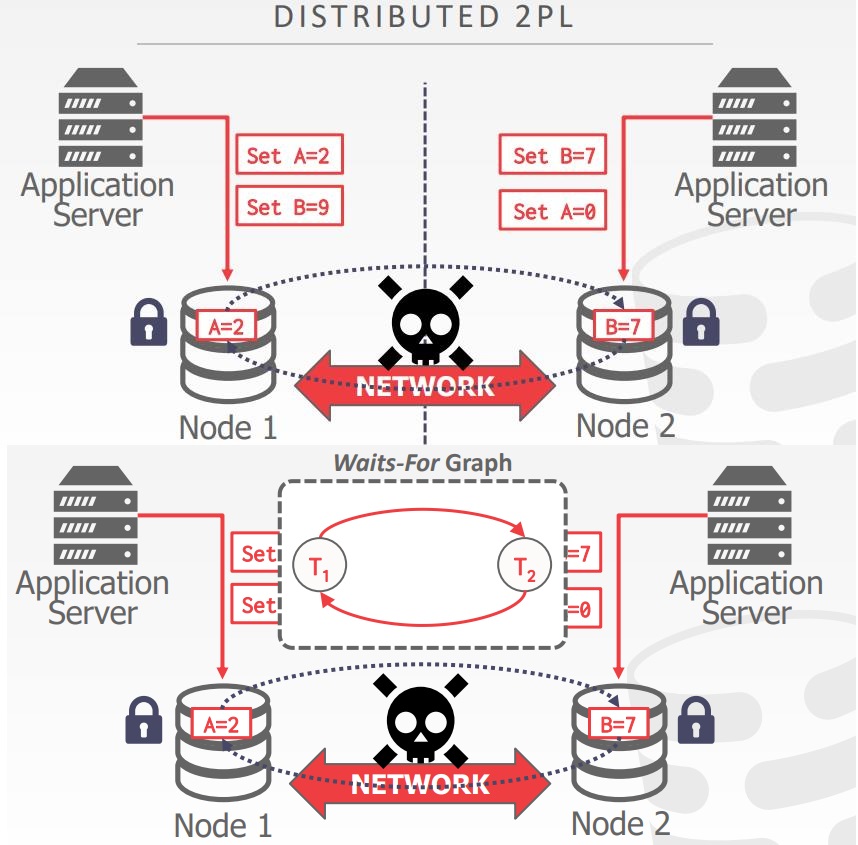
- 允许多个事务跨多个节点并发执行
- 很多单个DBMS的协议需要做修改
- 实现起来很难
- 复制、网络通讯开销、节点失败、时钟倾斜
相关文章
Distributed OLTP Database Systems
OLTP vs OLAP
- On-line Transaction Processing (OLTP):
- Short-lived read/write txns.
- Small footprint.
- Repetitive operations
- On-line Analytical Processing (OLAP):
- Long-running, read-only queries.
- Complex joins.
- Exploratory queries.
问题
We have not discussed how to ensure that all nodes agree to commit a txn and then to make sure it does commit if we decide that it should.
- What happens if a node fails?
- What happens if our messages show up late?
- What happens if we don’t wait for every node to agree?
重要的假定
- 假设所有的节点都是良好的,并且都是相同的管理域
- 如果节点没有失败,那么让其提交事务,最后肯定会提交的
- 如果不相信分布式DB中的其他节点,需要对事务使用 拜占庭容错协议,区块链
原子提交协议
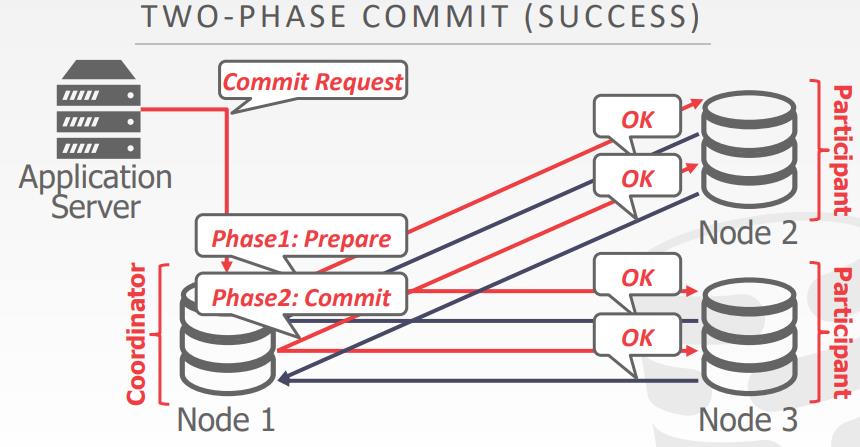
- 当多个节点完成时,DBMS需要询问多个节点是否可以安全提交
- Two-Phase Commit
- Three-Phase Commit (not used)
- Paxos
- Raft
- ZAB (Apache Zookeeper)
- Viewstamped Replication
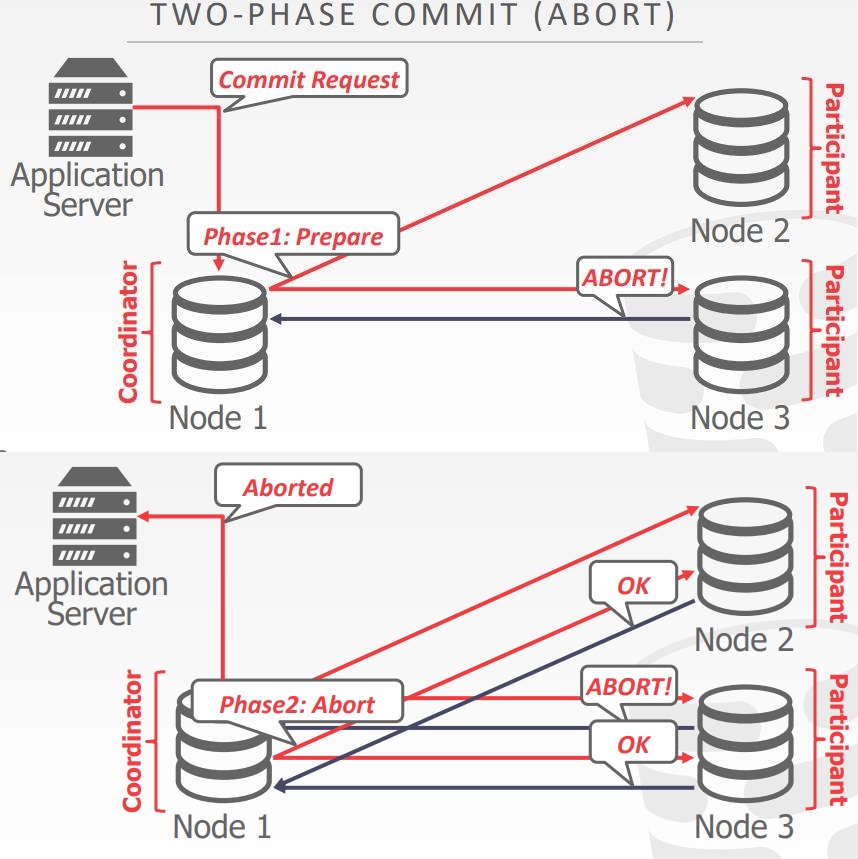
2PC
- 每个节点记录每个阶段的结果,到非易失性存储日志中
- What happens if coordinator crashes?
- Participants must decide what to do.
- What happens if participant crashes?
- Coordinator assumes that it responded with an abort if it hasn’t sent an acknowledgement yet
2PC的优化
- Early Prepare Voting
- 如果发送的请求到远端的一个节点,这个节点时最后一个执行的节点;该节点还将用查询结果返回它们对准备阶段的投票
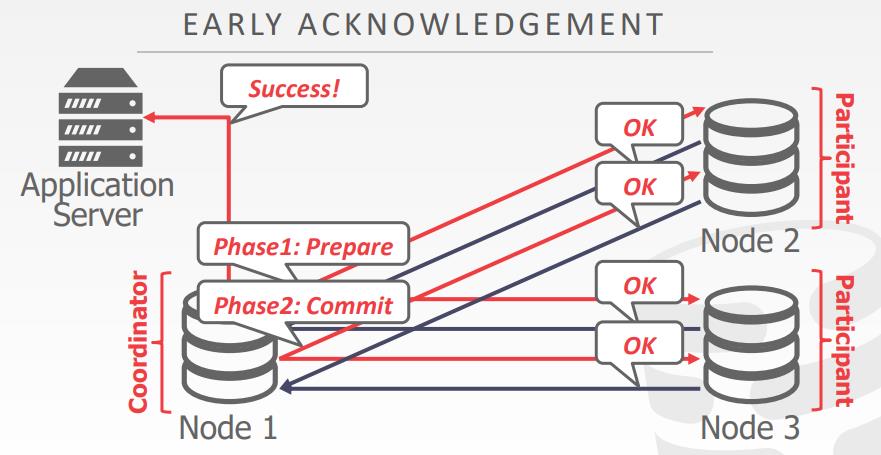
- Early Acknowledgement After Prepare
- 如果所有节点投票提交事务,协调节点可以响应客户端确认,在事务提交阶段之前就可以响应这个请求
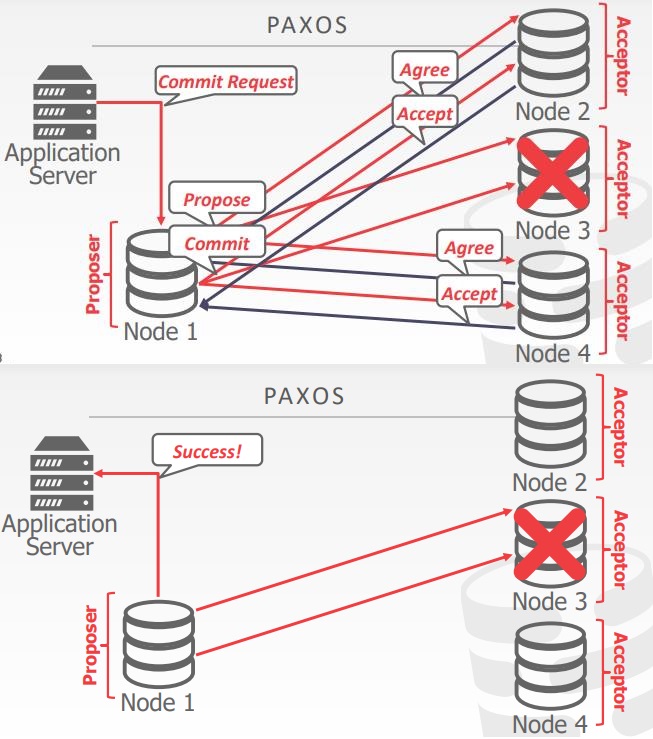
PAXOS
- 共识算法,一个协调提案一个结果,提交或者终止,参与者投票是否结果可以成功
- 如果大多数参与是活跃的,则不会阻塞,可以证明有最小化的消息延迟
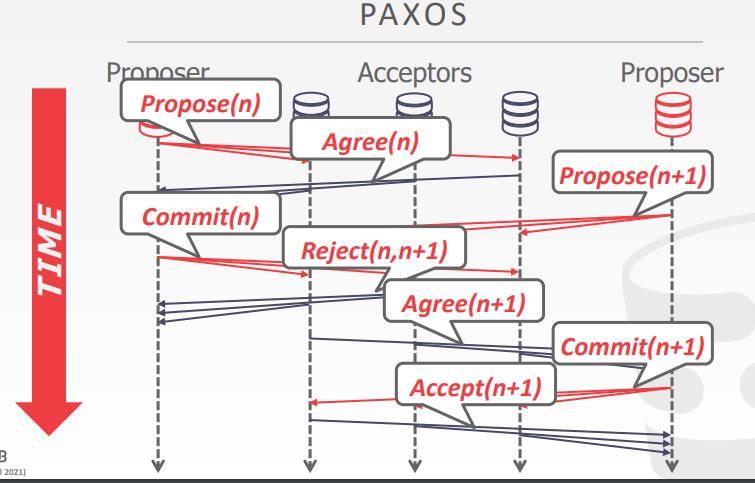
multi-paxos
- 如果系统选举了单个leader来处理提案,那么可以跳过准备阶段
- 当失败时,返回到full paxos
- 系统定期更新谁是新的leader
- 节点在leader选举期间必须交互日志条目,确保每个节点都是最新的
2PC vs PAXOS
- Two-Phase Commit
- 在请求阶段如果协调节点收到消息后挂了,则必须阻塞,直到协调阶段恢复
- paxos
- 如果多数派存活则不会阻塞,只要足够长的时间没有故障
复制
- DBMS必须跨冗余节点复制数据,以提高可用性
- 设计决策
- Replica Configuration
- Propagation Scheme
- Propagation Timing
- Update Method
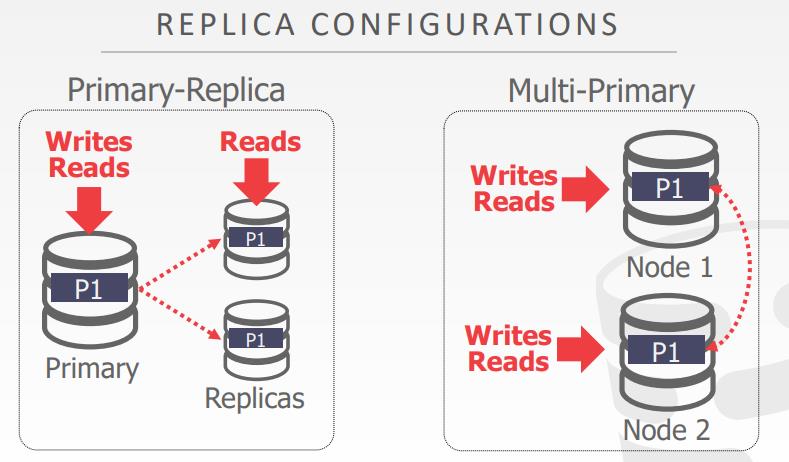
复制配置
- Approach #1: Primary-Replica
- 所有的更新由主节点处理
- 主节点传播更新到副本,不用使用原子提交协议
- 只读事务可以访问副本
- 如果主副本挂了,必须选举出一个新主节点
- Approach #2: Multi-Primary
- 事务可以更新任何副本
- 副本之间必须使用原子提交协议同步更新
K-safety
- 是一个阈值,用于决定复制数据库的失败容错性
- K 表示每个数据 使用可用的副本数量
- 如果副本数量低于这个阈值,DBMS则停止执行,并将自己下线
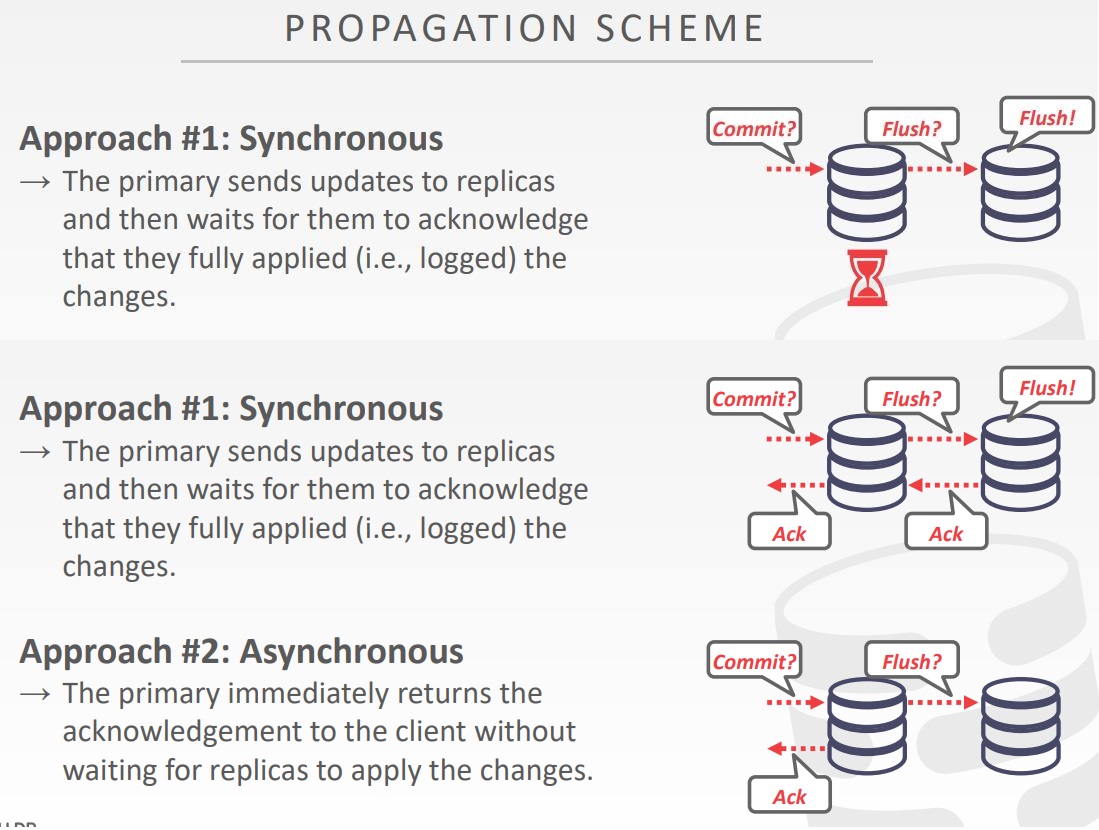
传播的模式
- 当一个事务提交到复制数据库,DBMS决定,在响应客户端之前,是否要等待事务变更传播到其他节点上
- 传播级别
- Synchronous (Strong Consistency)
- Asynchronous (Eventual Consistency)
传播时机
- Approach #1: Continuous
- 生成日志消息的时候,就立刻发送他们
- 也需要发送commit、abort消息
- Approach #2: On Commit
- 在事务提交的时候,才发送日志消息
- 对于终止的事务,不需要在发送日志消息了
- 假设事务日志可以完全装入内存
主动 vs 被动
- Approach #1: Active-Active
- 每个副本上的事务执行是独立的
- 事务执行后需要检查,是否每个副本上执行的事务是一致的
- Approach #2: Active-Passive
- 每个事务在单个位置执行,并传播到其他副本
- 可以执行物理、或者逻辑复制
- 不等同于 Primary-replica vs. multi-Primary
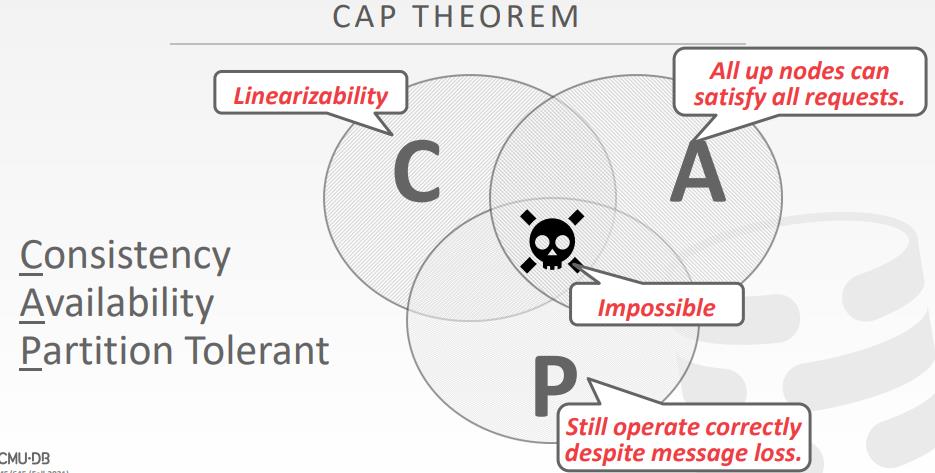
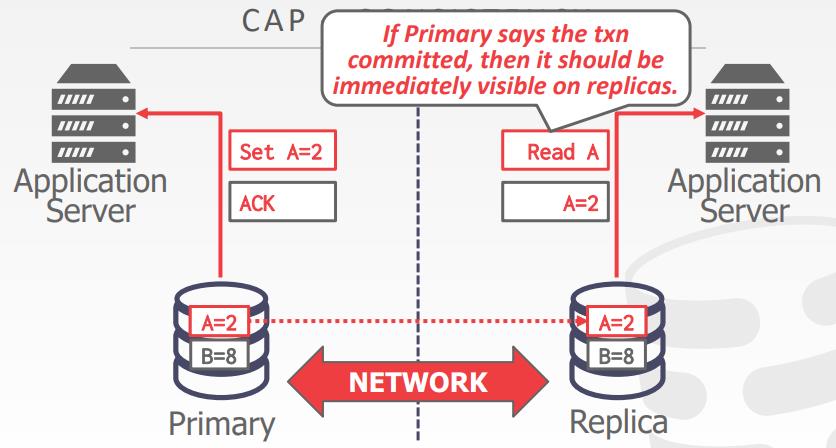
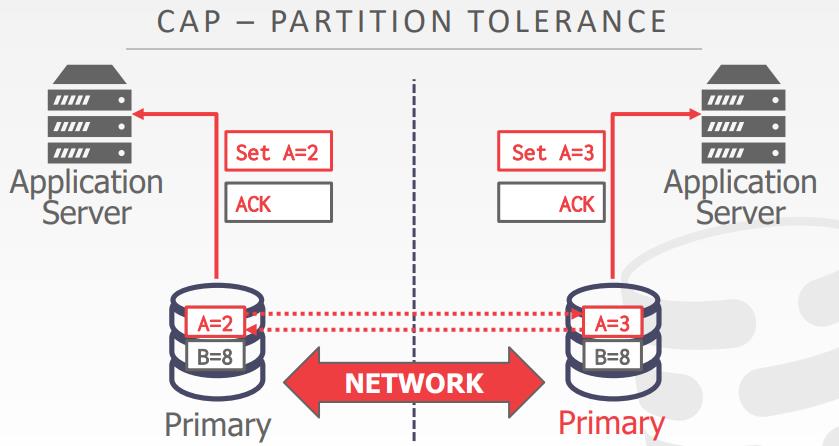
CAP理论
- Eric Brewer在2002年提出的,对于一个分布式系统,只能满足两个
- Consistent
- Always Available
- Network Partition Tolerant
- CAP如何处理失败决定了他们支持CAPDINGLI D 哪些元素
- Traditional/NewSQL DBMSs
- 停止变更操作,直到多数派节点能连通
- NoSQL DBMSs
- 节点重新连通之后,提供恢复冲突的机制
CAP consistency
CAP availability
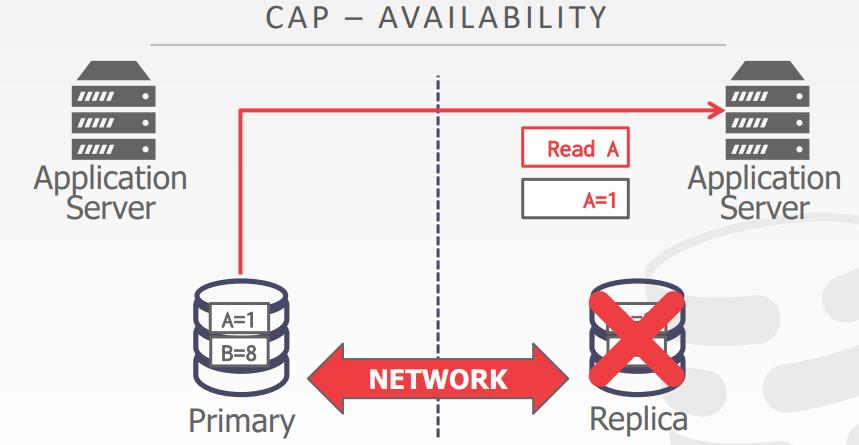
CAP partition tolerance
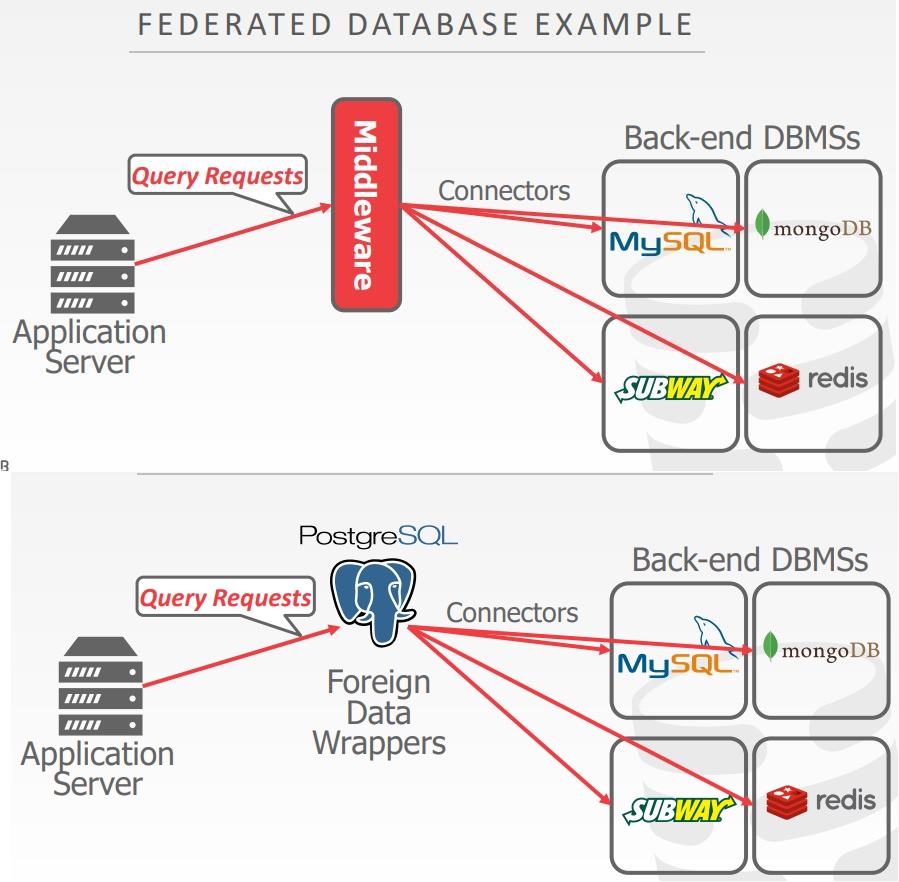
federated database
- 假设分布式系统中允许的所有节点都是相同的DBMS软件
- 但是企业经常在应用中使用不同的DBMS
- 需要单个接口访问不同数据库
- 将多个DMBS连接到一起,变成单个逻辑系统的分布式架构
- 一个查询可以访问任何地方的数据
- 很困难,没人能做的很好
- 不同的数据模型、查询语言、限制
- 没有简单的方式优化查询
- 大量的数据复制
结论
- 假设我们的分布式数据库中的所有节点都是友好的
- 对于 blockchain这样的数据库,每个节点都是敌对的,必须使用不同协议来提交事务
相关文章
Distributed OLAP Database Systems
分叉的系统
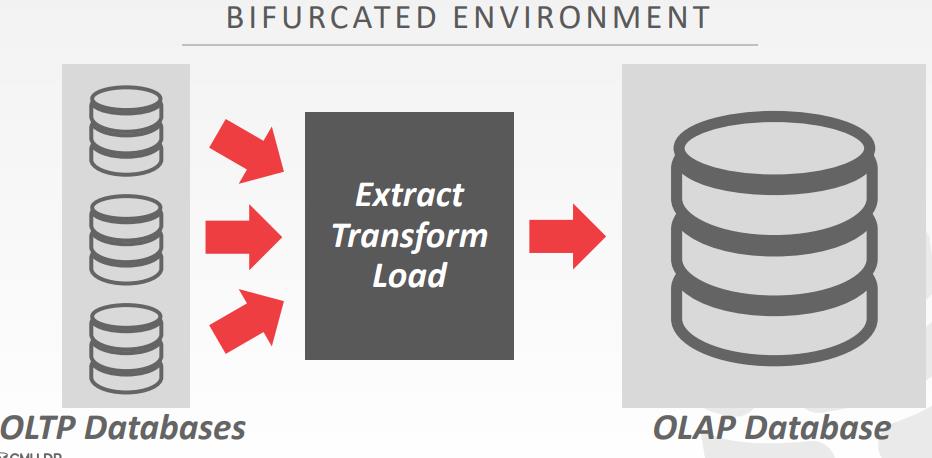
支持的系统
- 服务于管理,、操作、组织规划级别的应用,可以通过分析历史数据,帮助人们对未来问题做决策
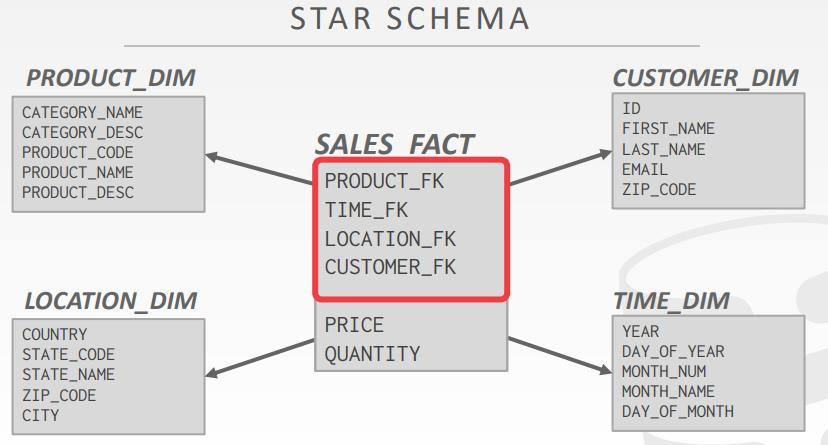
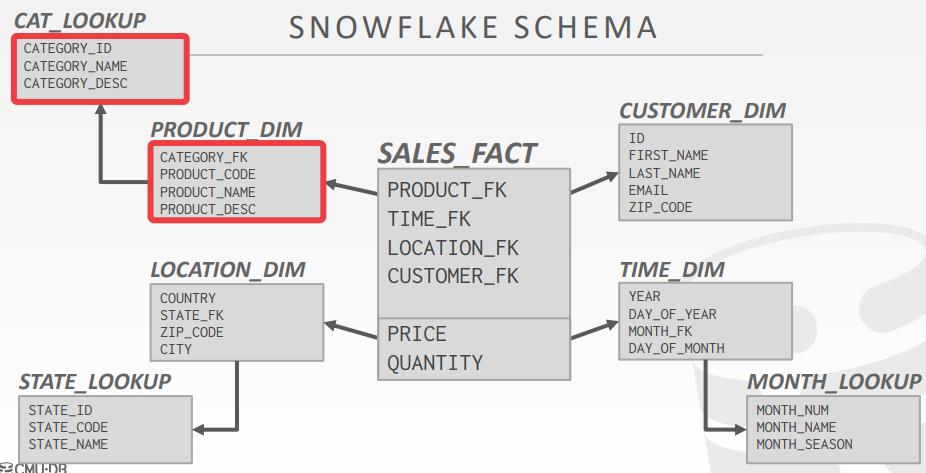
- Star Schema vs. Snowflake Schema
- Issue #1: Normalization
- 雪花模型的存储空间更少
- 非规范化的模型可能会违反一致性、完整性
- Issue #2: Query Complexity
- 雪花模型需要更多的join来得到数据
- 使用星型模型模式查询会更快
push VS pull
- Approach #1: Push Query to Data
- 发送查询,或者一部分查询到包含数据的节点
- 在数据端执行尽可能多的执行和filter,然后通过网络返回
- Approach #2: Pull Data to Query
- 将数据带到正在处理查询的节点
观察到的
- 从远程的数据源收到数据的节点,可以将其缓存到buffer pool中
- 允许DBMS支持中间结果 > 总内存数量
- 重启后,临时的page不会持久化
- 如果一个节点在执行期间挂了,对于一个长任务的OLAP查询会怎样?
- 对于 shared-nothing设计的分布式OLAP数据库来说,它假设执行期间,节点不会失败
- 如果执行期间节点失败,那么整个查询就失败了
- DBMS可以在执行期间获取查询中间结果快照,以便在节点失败时恢复
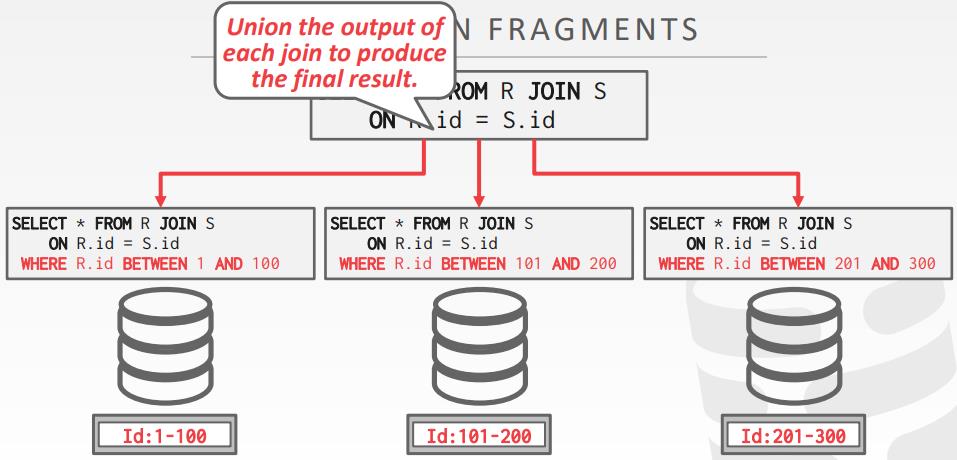
查询计划片段
- Approach #1: Physical Operators
- 生成单个查询计划,并将其分解为指定分区的片段
- 大多数系统都是这种方式
- Approach #2: SQL
- 重写原始查询到分区特定的查询
- 允许每个节点的本地优化
- 目前只有 SingleStore、Vitess 是这种实现
分布式join算法
- 分布式join的效率依赖于
- 一种方式是将整个表放到单个节点上,然后执行join
- 但这样就失去了分布式DB的并行性
- 跨网络传输的代价很高
- 表R 和 S的 join,DBMS需要在相同的节点上得到合适的tuple
- 一旦数据在节点上,就执行相同的join算法,这些join算法就是之前介绍的哪些
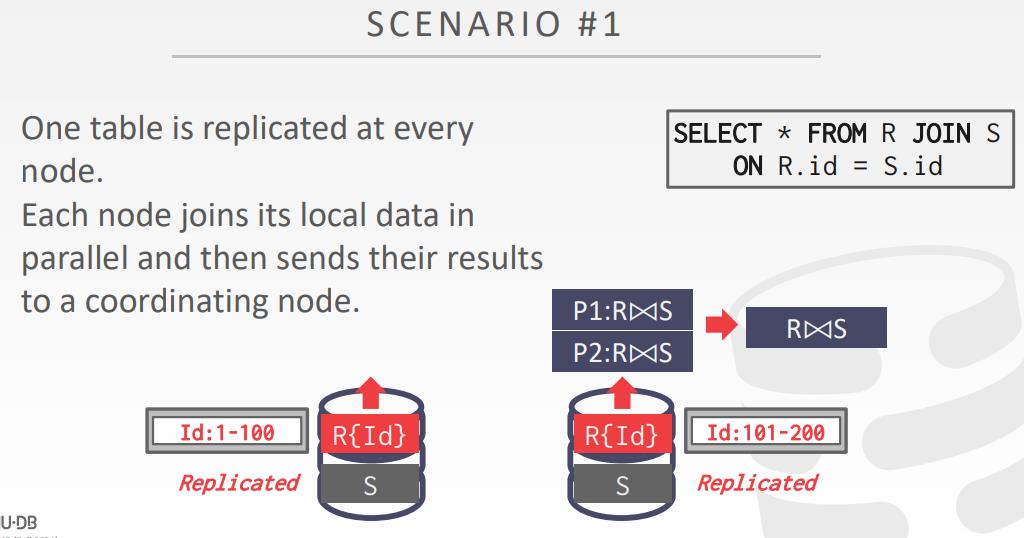
场景1
- 一个表被复制到每个节点
- 每个节点在它的本地数据上并行的执行join,并将结果发送到协调节点
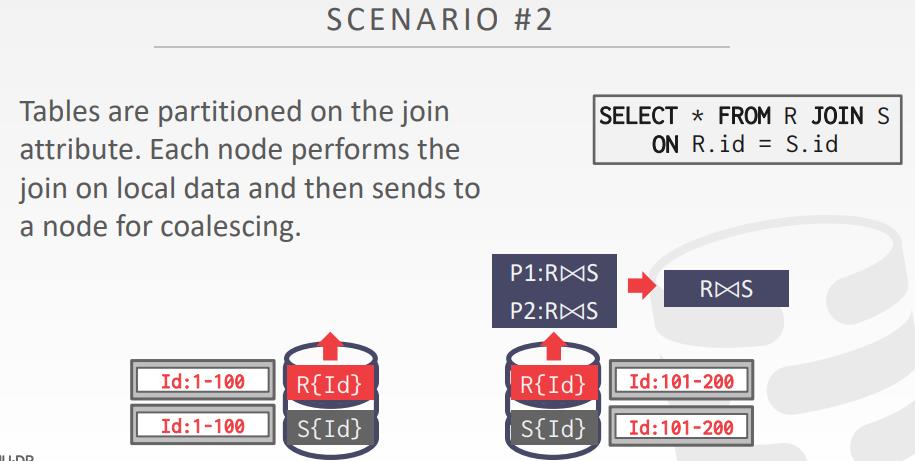
场景2
- 表以join属性做分区
- 每个节点在其本地数据上执行join,然后发送结果到协调节点上
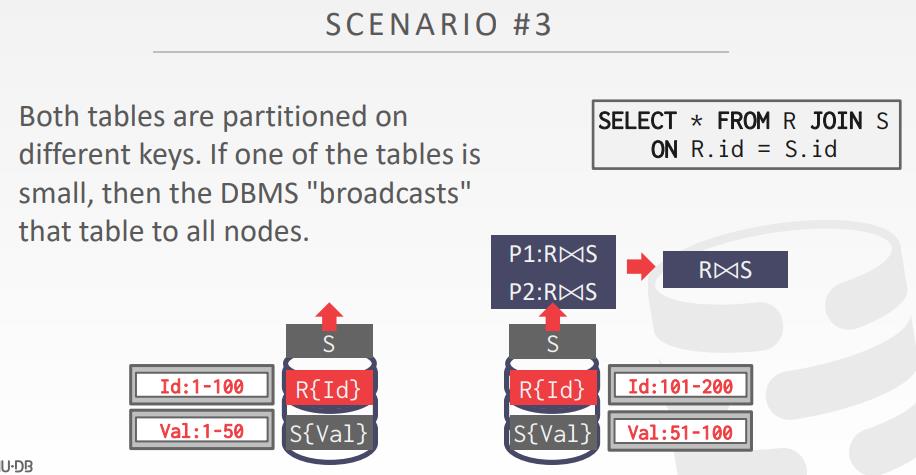
场景3
- 两个表以不同的key分区
- 如果一个表是小表,则将其广播到所有节点上
场景4
- 两个表都不是以join 的key分区的
- 需要跨节点shuffle,然后拷贝他们再join

semi-join
- join结果中如果只包含左表的列,分布式DB使用 semi-join最小化数据发送量(join期间)
- 有点类似projection下推
- 有一些数据库支持 semi-join
- 否则就用 exist 语法

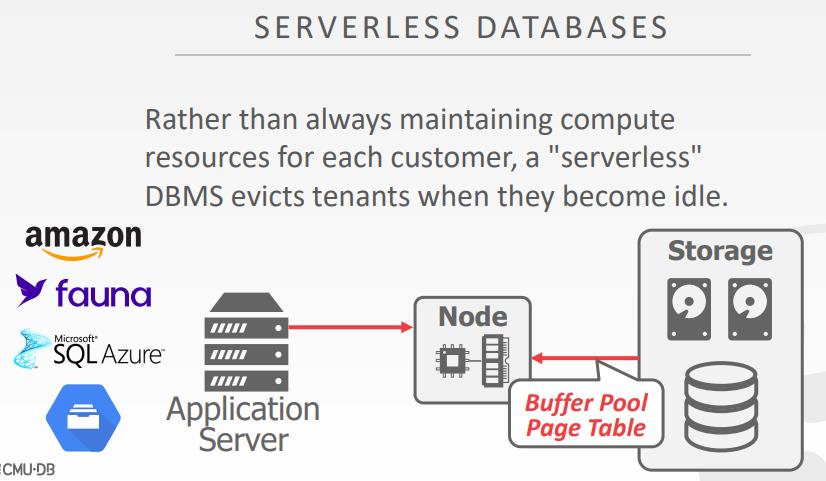
云系统
- 厂商提供了 database-as-a-service DBaaS服务,提供了管理DBMS的环境
- 新的系统开始漠河 shared-nothing 和 shared-disk之间的边界
- 你可以从 S3拷贝数据到计算层之前,做一些filter操作
- Approach #1: Managed DBMSs
- 没有对DBMS做大改动,让其知道运行在云环境中
- 大多数厂商都是这么做的
- Approach #2: Cloud-Native DBMS
- 系统设计主要是运行在云环境中
- 通常基于shared-disk架构
- 如:Snowflake, Google BigQuery, Amazon Redshift, Microsoft SQL Azure
- 无服务的数据库,在用户不使用的情况下,可以主动驱逐租户,节省价格
分解组件
- System Catalogs
- HCatalog, Google Data Catalog, Amazon Glue Data Catalog
- Node Management
- Kubernetes, Apache YARN, Cloud Vendor Tools
- Query Optimizers
- Greenplum Orca, Apache Calcite
统一的格式
- 大多数DBMS都提供了他们专有的磁盘的二进制格式文件
- 想要在不同系统之间共享文件,就只能将其转为一个通用的格式
- CSV、JSON、XML
- 开源的二进制格式,可以跨系统访问

各种OLAP系统
- 云厂商的
- Amazon redshift、snowflake、SQL Azure、Oracle
- 专有的
- Clickhose、presto、splice、greenplum、vertica、oracle exadata、teradata

相关文章
- SingleStore
- Vitess
- AWS Glue tables
- Kubernetes
- Apache YARN
- Greenplum Orca
- Apache Calcite
- BusTub page
- Apache Pqrquet
- Apache ORC
- Apache CarbonData
- Apache Iceberg
- HDF5
- Apache Arrow