为何Uber要将PostgreSQL迁到MySQL
背景
Uber早期的架构就是一个单体应用,用python写的,数据是存在PostgreSQL上的
之后为了跟随业务发展,改用了 微服务架构,并使用新的数据平台
现在使用的是 无模式 schemaless风格,在MySQL之上的一个数据共享层
这篇文章就介绍为何要将 PostgreSQL迁移到MySQL
PostgreSQL的架构
uber在使用过程中,发现PG的这么一些问题
- 低效的写架构
- 低效的数据复制
- 数据损坏问题
- MVCC支持度不好
- 升级到新版本很困难
下面就来讨论这些问题,探讨一下PG内部的数据存储格式,并对比一下MySQL的格式
这篇文章时间比较久了,用的还是 PG9.3版本的,不过总体来说大的架构基本没怎么变
磁盘格式
一个关系数据库需要提供如下功能:
- 增、删、改的能力
- schema变更的能力
- 多个事务并发执行下的事务视图,也就是MVCC实现
首先来看PG是如何存储数据的
PG存储的数据是不可变的,一个不可变的行叫做 tuple
tuple有唯一的标识符,叫做 ctid,相当于磁盘位置的,也就是物理位置的偏移量
|
|
假设有这么一张表:
|
|
表的数据如下,都是一些历史著名数学家
| id | first | last | birth_year |
|---|---|---|---|
| 1 | Blaise | Pascal | 1623 |
| 2 | Gottfried | Leibniz | 1646 |
| 3 | Emmy | Noether | 1882 |
| 4 | Muhammad | al-Khwārizmī | 780 |
| 5 | Alan | Turing | 1912 |
| 6 | Srinivasa | Ramanujan | 1887 |
| 7 | Ada | Lovelace | 1815 |
| 8 | Henri | Poincaré | 1854 |
而这个表在实际存储的时候,内部会有 ctid 字段,所以看起来就像是这样的:
| ctid | id | first | last | birth_year |
|---|---|---|---|---|
| A | 1 | Blaise | Pascal | 1623 |
| B | 2 | Gottfried | Leibniz | 1646 |
| C | 3 | Emmy | Noether | 1882 |
| D | 4 | Muhammad | al-Khwārizmī | 780 |
| E | 5 | Alan | Turing | 1912 |
| F | 6 | Srinivasa | Ramanujan | 1887 |
| G | 7 | Ada | Lovelace | 1815 |
| H | 8 | Henri | Poincaré | 1854 |
而主键的物理布局大概就是这样:
|id| ctid|
| – | – |
|1 | A
|2 |B|
|3 |C|
|4 |D|
|5 |E|
|6 |F|
|7 |G|
|8 |H|
另外两个 二级索引的物理布局像这样:
主键索引的顺序跟 ctid的顺序正好一致
而 二级索引的顺序,跟 citd的顺就不一致了
| first | last | ctid |
|---|---|---|
| Ada | Lovelace | G |
| Alan | Turing | E |
| Blaise | Pascal | A |
| Emmy | Noether | C |
| Gottfried | Leibniz | B |
| Henri | Poincaré | H |
| Muhammad | al-Khwārizmī | D |
| Srinivasa | Ramanujan | F |
| birth_year | ctid |
|---|---|
| 780 | D |
| 1623 | A |
| 1646 | B |
| 1815 | G |
| 1854 | H |
| 1887 | F |
| 1882 | C |
| 1912 | E |
假设我们要更新Muhammad al-Khwārizmī的出生年份,按照之前说的,PG的tuple都是不可变的
所以这里的更新是新增一行,新的行的 prev指向前一个版本
这里的 pre 是PG的一个内部字段
| ctid | prev | id | first | last | birth_year |
|---|---|---|---|---|---|
| A | null | 1 | Blaise | Pascal | 1623 |
| B | null | 2 | Gottfried | Leibniz | 1646 |
| C | null | 3 | Emmy | Noether | 1882 |
| D | null | 4 | Muhammad | al-Khwārizmī | 780 |
| I | D | 4 | Muhammad | al-Khwārizmī | 770 |
这里就多了I,它的前一个版本指向D
而这种情况下,实际是两个 二级索引也不是 update,而是又新增了一行
| first | last | ctid |
|---|---|---|
| Muhammad | al-Khwārizmī | D |
| Muhammad | al-Khwārizmī | I |
| birth_year | ctid |
|---|---|
| 770 | I |
| 780 | D |
PG 需要确定哪个版本是最新的,在执行事务时,也需要确定 哪些版本可以被事务看到
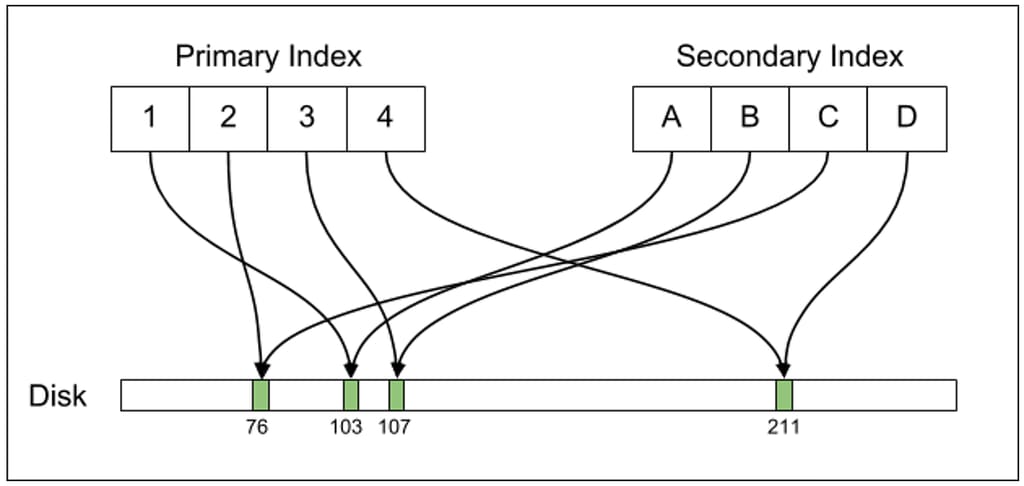
从上图中可以看到,PG的主索引、二级索引 都是直接指向了 物理磁盘的 ctid,也就是指向了实际的物理布局
而当 一个tuple的位置变更时,主索引、二级索引也需要跟着改变
复制
PG 使用WAL来保证事务的原子性,如果开启了流复制,则会将一台机器的变更发送到另一台
即使没有开启流复制,WAL也会自动开启,因为这是保证事务ACID语义的
当数据库崩溃再启动时,会首先读取WAL的内容
然后将WAL的内容,跟磁盘上的数据内容作比较,如果两者不一致,则以WAL的为准,将WAL的内容反应到磁盘上
如果出现了事务未提交,则需要回滚,将WAL的数据反向变更做回滚
流复制是将数据复制到 副本中,这样副本就可以实现只读事务了
WAL是物理级别的操作,它记录了磁盘具体位置的偏移量,就像 ctid 那样
如果在 主副本 -> 从副本 同步的时候,突然暂停,那么会发现主副本和从副本的字节是一一匹配的
如果 rsync 也可以修复副本数据
PostgreSQL的问题
写放大
由于PG的行是不可变的,更新时通过新增实现的
那么当更新al-Khwārizmī的出身年份时,虽然只更新了小部分内容,但会导致很多的物理层写入
一次更新会引发四次更新
- 写一个新行tuple到表空间
- 主索引增加一条记录
- 二级索引(first,last)增加一条记录
- 二级索引birth_year 增加一条记录
注意,(2)、(3) 实际并没有更新,但主键索引还是多了一条操作,二级索引的(first,last)也多了一条操作
如果二级索引(first,last)内容比较长,这会导致很多冗余的内容
尤其是当索引比较多的时候,一次更新带来的开销很大
复制
由于WAL是物理层操作,所以写放到在复制层也有影响
一次更新操作之后,会导致四次WAL复制,这些复制就从一个节点传播到了其他节点
在单机房内可能不是什么问题,因为带宽很高,机房内的带宽也都是免费的
但是跨机房,跨城市同步就会出现问题
Uber原先的机房在西海岸,现在为了容灾考虑,在东海岸增加了一个数据中心,于是就需要跨城市拷贝
这种跨城市之间的拷贝,不光带宽价格高,而且速度也很慢
此外Uber也用WAL作了归档处理,这是为了方便做副本上线,做快照处理的
但是WAL跨城市复制效率很低,而带宽不够快,跟不上WAL的写入速度
数据损坏
这是触发了 PG的一个bug
因为这个bug,一些本应该被标记为 非活跃的记录,却没有标记成功
当执行这个SQL时
|
|
这会出现两条记录,一个是原始的 780CE,一个是更新后的 770CE
如果查询时带了 ctid,则会看到他们的 物理偏移量不同
这个损坏的数据,在所有的副本上出现了,所以Uber的人也不知道到底影响面试多少
他们只能用代码来做防御
不同的副本表现也不一样
比如有的副本是 X行不对,Y行是新的;而有的副本则是Y行旧的,X行是新的
虽然这种影响这是少数几行,但因为 索引引用的也是物理偏移量,所以实际影响范围非常大
B+树会定期做 reblance,这样的话,会完全改变树的结构,这就好像一个子树移动到了新的位置
如果一个错误的数据被移动了,那么可能会导致树的大部分变得完全无效
虽然后续PG修复了这个问题,但是Uber团队仍然担心,因为这种问题是发生在物理层这个级别的
万一哪天又搞出一个bug,这样会导致整个数据库都出现问题,修复也会非常麻烦
复制MVCC
PG并么有真正的支持MVCC
如果流复制时有一个事务,这个事务影响了这一行,而流需要复制这行
就会导致阻塞,直到这个事务完成
如果事务很长,则会导致主副本和从副本之间有很大的延迟
而如果一个事务阻塞了WAL一段时间,则PG会kill掉这个事务
这种设计意味着,从副本通常会落后主副本几秒钟,而且事务很容易被kill掉
PostgreSQL升级
由于复制是物理级别的,所以更新很难
如果主副本是9.2的,那么从副本就不能是9.3或者其他版本
一般来说升级步骤如下:
- 关闭主副本
- 在主节点上运行
pg_upgrade,原地更新数据,这可能要几个小时 - 启动master
- 启动一个master快照,需要从master拷贝数据,这也需要几个小时
- 清除副本,并将新快照从主副本恢复到从副本
- 将所有的从副本应用到复制层级,并等待从副本追赶上主副本
随着Uber数据量变大,这种升级就变得很难了
虽然也有一个基于逻辑层的复制pglogical,但一致没有合并到主线
MySQL架构
InnoDB的磁盘存储
完整的讨论磁盘布局,MVCC太多了,我们的焦点集中在跟PG的对比
InnoDB也支持MVCC,并支持可变数据
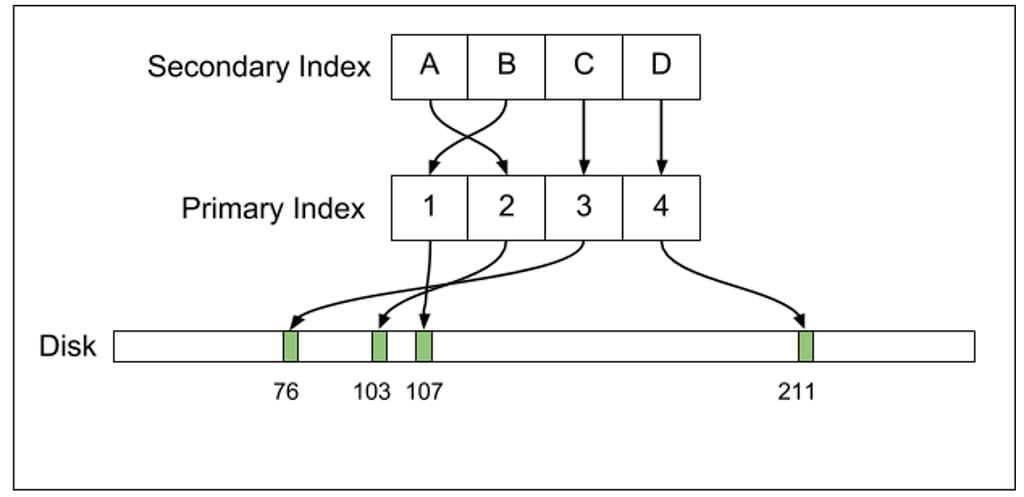
MySQL的二级索引并不是直接指向物理磁盘的,它指向了主索引
所以它的二级索引布局是这样的:
| first | last | id (primary key) |
|---|---|---|
| Ada | Lovelace | 7 |
| Alan | Turing | 5 |
| Blaise | Pascal | 1 |
| Emmy | Noether | 3 |
| Gottfried | Leibniz | 2 |
| Henri | Poincaré | 8 |
| Muhammad | al-Khwārizmī | 4 |
| Srinivasa | Ramanujan | 6 |
mysql的二级索引需要查找两次
- 首先根据二级索引找到主索引
- 再根据主索引定位到具体值
这种设置相比PG在查询方面就是劣势,不过它的好处也很明显,数据更新只需要修改对应的索引
MySQL是原地更新的,如果需要支持MVCC,MySQL会拷贝 旧行的到特殊的 回滚段中操作
假设要更新al-Khwārizmī’s的出生年份,只需要原地更新对应的行,以及年份的二级索引
主索引不需要变更,(first,last)也不需要变更
如果有大量的索引,就可以节省很多开销
这种设计也让 vacuum 、压缩变得更有效,他们只在回滚段中,而PG需要做全表扫描
MySQL的物理布局如下,二级索引 -> 主索引,如果记录发生物理变动,只需要改变主索引
复制
mysql有不同的复制模式
如下:
- 基于statement的复制,就是复制一个语句,如
UPDATE users SET birth_year=770 WHERE id = 4 - 行复制
- 混合复制
statement复制,只需要复制少量的逻辑语句即可,但是需要副本执行很多物理层的工作
而 行复制,是基于物理层的,跟PG类似
mysql中只有主索引是指向磁盘偏移量的,这点很重要
比如一个具体的复制,如将行 X从 t_1 变为 t_2
mysql只需要做逻辑变更,副本可以根据这些信息自动推断,更改索引
由于是逻辑复制,所以副本是真正的MVCC,因此在副本上读请求不会阻塞流更新
PG的流复制包含了磁盘物理变更,所以PG的副本在读时,会跟应用WAL变更冲突,无法实现MVCC
同时,这是逻辑层复制,所以即使出现问题、bug,也不会像PG那样影响很大
物理层错误之后,B+ 做了平衡,会影响整个数据库
由于是逻辑复制,所以可以在不同版本的mysql之间之间做复制
因为存储层的格式变动不会影响到逻辑层
对mysql升级一般是一个一个的来,升级所有副本,然后将其中一个变成主副本,升级的时候可以平滑完成不用中断业务
MySQL的其他优势
PG的Buffer Pool
- PG大量使用了操作系统的page cache
- 比如,实际部署的PG实例有768G内存,但真正的驻留内存只有25G,剩下的都是page cache
- 由于不是驻留内存访问这些数据需要通过 lseek、read 系统调用,增加了上下文切换开销
- 那个时候PG还没有优化,这两个系统调用可以合并成一个 pread
MySQL的Buffer Pool优势
- 用户态的LRU,这样就可以实现一些自定义的操作,比如大量的scan可以绕过缓存
- 避免了上下文切换,不会出现TLB miss 这种情况
MySQL连接
- 使用的是线程模式,开销更小
- 可以很轻松的扩展到1W个链接
PG的连接
- 进程模式,这样会导致启动、切换的开销很高
- 另外进程间通讯使用的是 System V IPC,而不是轻量级的 futex,后者通常没有什么竞争
- 除了内存、IPC开销,PG对并发支持也很差,当内存足够时,PG的并发也就几百
- 解决此问题的办法是用连接池:pgbouncer,不过出现了一些bug,打开了更多的连接
结论
Uber早期的时候,PG确实工作的很好,不过随着Uber规模的扩大,PG的问题就出现了
现在只有一些遗留的PG实现,其他的存储包括:
- 基于Mysql之上的无模式层
- 基于Cassandra的NoSQL
关于 无模式的介绍