背景
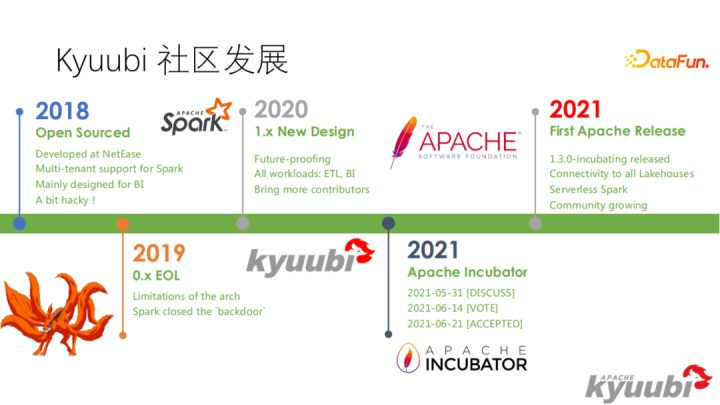
Kyuubi 最早在2018年从网易魔改的内部 Spark 分支中独立出来并开源
2021年成为Apache的孵化项目
spark thrift 只是一个单点,虽然官方也出了主备的解决方案,但基本还是单点
在此基础上,kyuubi对其做了扩充,支持的功能如下
- 高可用
- 多租户
- 支持YARN、Mesos、kubernets、Standalone
- 统一入口,方便使用

kyuubi 的目标是提供一个 高可用、多租户的入口
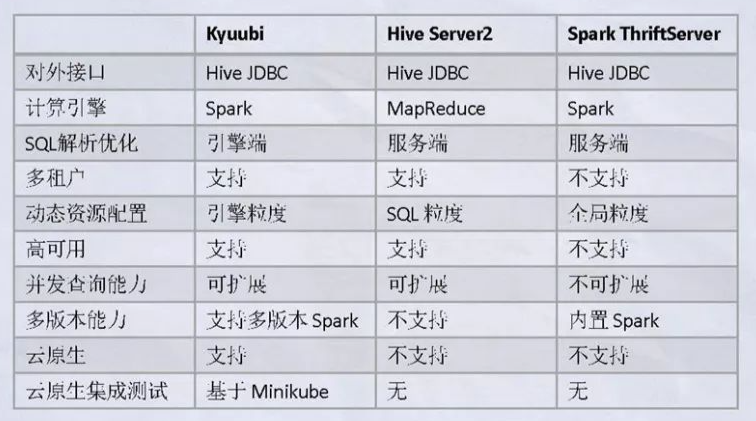
上图是官方的,比较老了,实际支持的引擎包括:
和Spark、hive的对比
架构
高可用
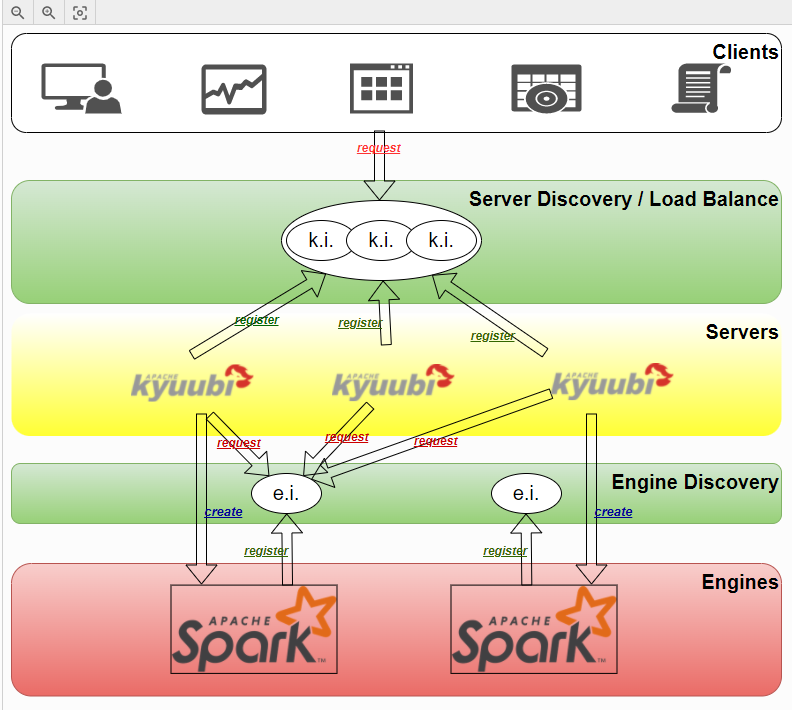
上图很重要,基本上说清了 kyuubi 要做的事情
由于spark thrift只是单个入口点,所以要扩展成多个,那么就要有一个服务发现的功能,这里是借助 Zookeeper完成的
整体上分三层
- client
- 支持Hive2协议、mysql、REST API
- hive驱动被改写过,在连接kyuubi之前,需要从ZK上找到可用的服务
- 通过ZK,客户端就实现了负载均衡的能力
- server
- 可以理解为一个代理层,接受客户端的请求并转发
- server启动后会将自己注册到ZK上
- server本身提供了mysql协议的服务、REST服务、hive-rpc服务
- engine
- 引擎层相当于spark的driver,在启动的时候会将自己注册到ZK上
- 引擎层本身也提供了一个RPC入口,等待server层的连接
- 引擎层本身没有做什么修改,就是执行SQL并返回结果
 上图是三层之间的调用关系
上图是三层之间的调用关系
server层、engine层会将自己注册到ZK上
而 SparkSQLEngine instance1 相当于一个集群入口
同理 instance2、instance3也相当于是一个入口,一共有3个入口
server层可以根据不同的需求,负载情况,等选择一个入口,发送SQL执行
session管理
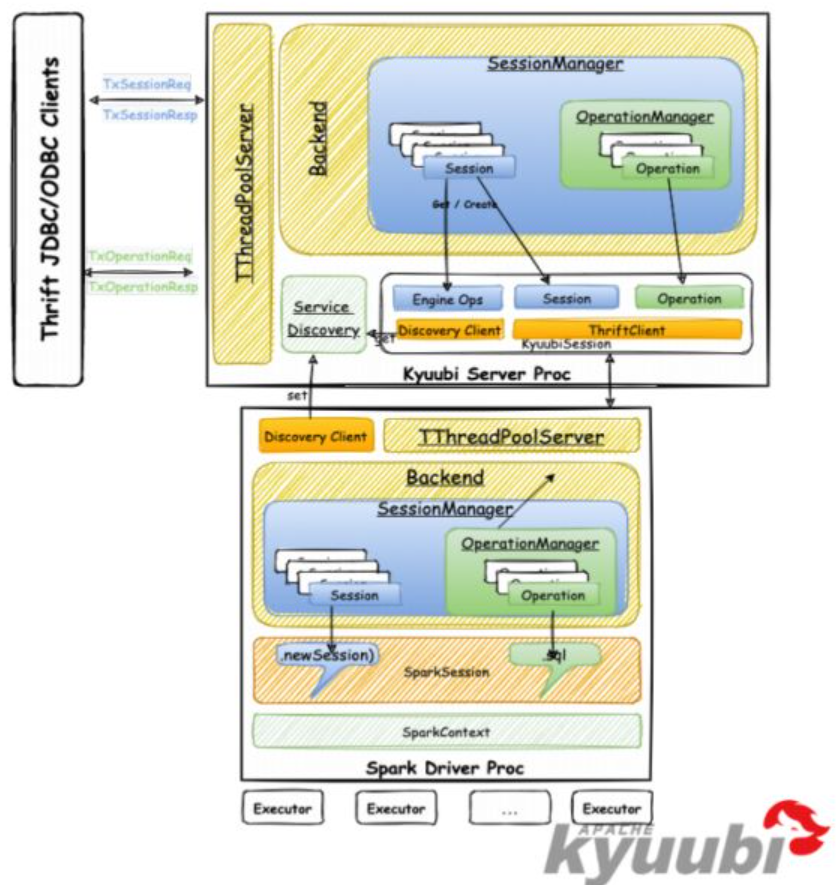
解释上图
- 上图的上半部分是 kyuubi的server,它接受用户的请求,然后由 session manager创建一个session
- 这个session中包含了客户端的各种操作信息,以及附加的一些信息
- 下半部分是kyuubi的engine部分,它也有一个session manager,它创建的是spark session
- server和engine都有TThreadPoolServer,说明这两层是通过thrift进行交互的
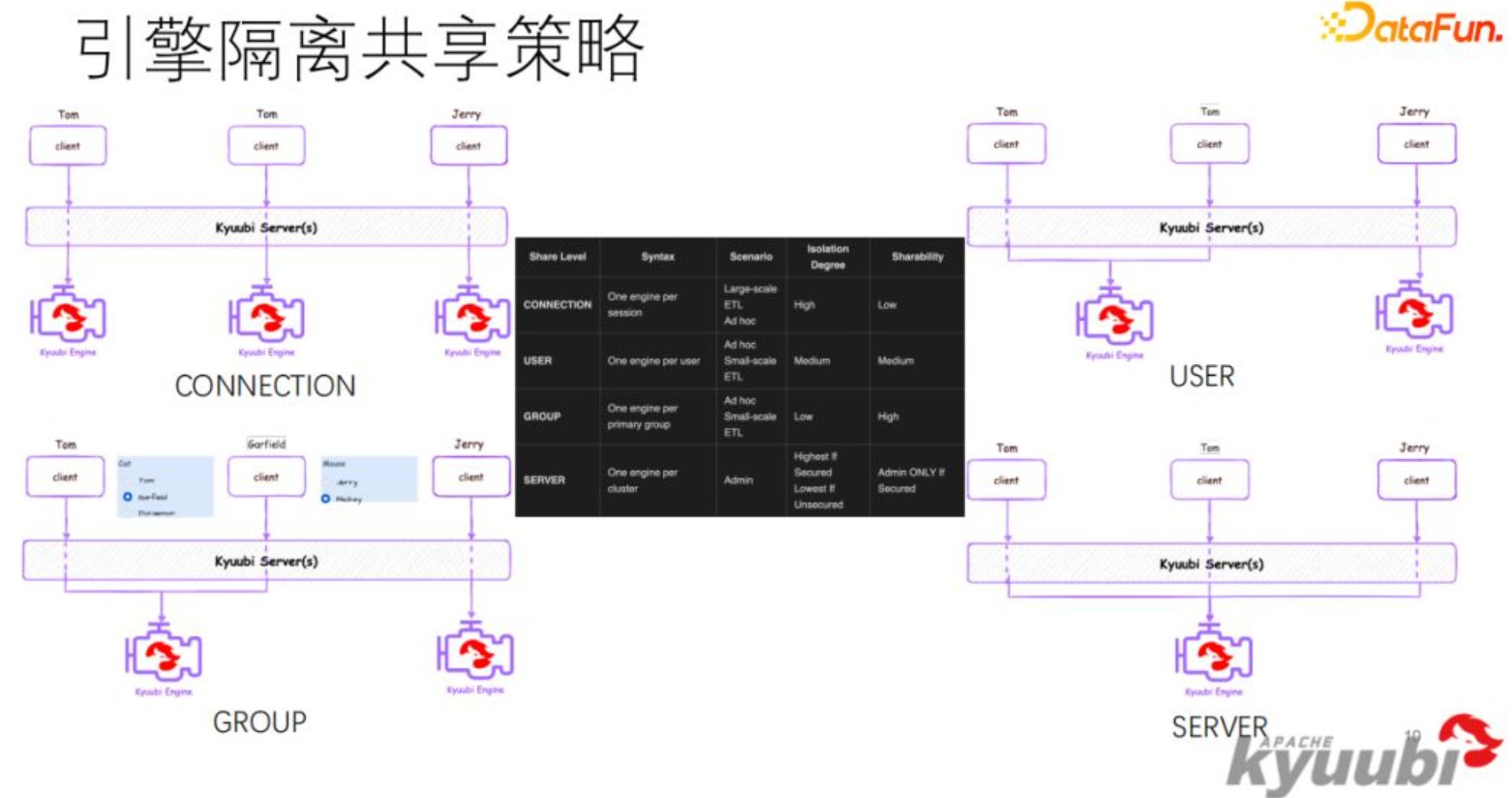 session分为这么几种
session分为这么几种
- 单连接的,一个连接一个session,连接执行结束引擎结束,同一个用户的多个连接之间不共享
- 用户级别,一个用户的多个请求可以共享一个引擎
- 组级别, 一个组内的多个用户可以共享一个引擎
- server,全局共享级别
其他
其他一些功能
- 可以部署在 k8s上
- 支持多种认证方式
- 提供了各种监控参数,方面用JConsole、VisualVM 等工具查看
- 使用了
[Metrics](https://metrics.dropwizard.io/)这个工具,可以暴露自身的监控指标,方便其他工具采集
实现细节
部署执行
从官网下载一个 kyuubi 进入bin目录,可以执行运行启动(仅限linux环境)
部署一个 kyubbi后,进程中的主要线程如下(去掉了JVM自身的线程):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
KyuubiTBinaryFrontendHandler-Pool: Thread-31
KyuubiTBinaryFrontendHandler-Pool: Thread-30
KyuubiTBinaryFrontendHandler-Pool: Thread-29
"KyuubiTBinaryFrontend: Thread-24" #24 prio=5 os_prio=0 cpu=5.85ms elapsed=79361.68s tid=0x00007fe786711000 nid=0x6a8f runnable [0x00007fe70bcfb000]
java.lang.Thread.State: RUNNABLE
at java.net.PlainSocketImpl.socketAccept(Native Method)
at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:409)
at java.net.ServerSocket.implAccept(ServerSocket.java:560)
at java.net.ServerSocket.accept(ServerSocket.java:528)
at org.apache.thrift.transport.TServerSocket.acceptImpl(TServerSocket.java:129)
at org.apache.thrift.transport.TServerSocket.acceptImpl(TServerSocket.java:35)
at org.apache.thrift.transport.TServerTransport.accept(TServerTransport.java:60)
at org.apache.thrift.server.TThreadPoolServer.serve(TThreadPoolServer.java:162)
at org.apache.kyuubi.service.TBinaryFrontendService.$anonfun$run$2(TBinaryFrontendService.scala:100)
at org.apache.kyuubi.service.TBinaryFrontendService.$anonfun$run$2$adapted(TBinaryFrontendService.scala:100)
at org.apache.kyuubi.service.TBinaryFrontendService$$Lambda$242/82985674.apply(Unknown Source)
at scala.Option.foreach(Option.scala:407)
at org.apache.kyuubi.service.TBinaryFrontendService.run(TBinaryFrontendService.scala:100)
at java.lang.Thread.run(Thread.java:750)
KyuubiSessionManager-timeout-checker
Curator-Framework-0
main-EventThread ZK客户端
main-SendThread(my-server-1101:2181) ZK客户端
Curator-ConnectionStateManager-0
org.apache.hadoop.fs.FileSystem$Statistics$StatisticsDataReferenceCleaner
Timer-0 不清楚做什么用的
ProcessThread(sid:0 cport:2181) ZK相关,接受请求的
SyncThread:0 ZK相关
SessionTracker ZK相关
NIOServerCxn.Factory:my-server-1101/10.201.81.222:2181 ZK 相关,select线程
|
主要线程
- 依赖了 Zookeeper,以及ZK的工具 Curator 相关的线程
- KyuubiTBinaryFrontend是 接收线程
- KyuubiTBinaryFrontendHandler-Pool 是工作线程
- 还有一个session 的超时检查线程
可以在本地启动一个 beeline 连接
1
|
beeline -u 'jdbc:hive2://10.201.81.222:10009' -n 【你的账号】
|
引擎执行
上面那段 beeline执行会抛错异常,不过可以看到 引擎启动、执行的一些细节
抛出异常
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
Caused by: java.io.IOException: Cannot run program "/data1/kyuubi/apache-kyuubi-1.5.2-incubating-bin/bin/bin/spark-submit" (in directory "/data1/kyuubi/apache-kyuubi-1.5.2-incubating-bin/work/anonymous"): e rror=2, No such file or directory
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1048) ~[?:1.8.0_322]
at org.apache.kyuubi.engine.ProcBuilder.start(ProcBuilder.scala:143) ~[kyuubi-server_2.12-1.5.2-incubating.jar:1.5.2-incubating]
at org.apache.kyuubi.engine.ProcBuilder.start$(ProcBuilder.scala:142) ~[kyuubi-server_2.12-1.5.2-incubating.jar:1.5.2-incubating]
at org.apache.kyuubi.engine.spark.SparkProcessBuilder.start(SparkProcessBuilder.scala:39) ~[kyuubi-server_2.12-1.5.2-incubating.jar:1.5.2-incubating]
at org.apache.kyuubi.engine.EngineRef.$anonfun$create$1(EngineRef.scala:239) ~[kyuubi-server_2.12-1.5.2-incubating.jar:1.5.2-incubating]
at org.apache.kyuubi.engine.EngineRef.tryWithLock(EngineRef.scala:192) ~[kyuubi-server_2.12-1.5.2-incubating.jar:1.5.2-incubating]
at org.apache.kyuubi.engine.EngineRef.create(EngineRef.scala:206) ~[kyuubi-server_2.12-1.5.2-incubating.jar:1.5.2-incubating]
at org.apache.kyuubi.engine.EngineRef.$anonfun$getOrCreate$1(EngineRef.scala:282) ~[kyuubi-server_2.12-1.5.2-incubating.jar:1.5.2-incubating]
at scala.Option.getOrElse(Option.scala:189) ~[scala-library-2.12.15.jar:?]
at org.apache.kyuubi.engine.EngineRef.getOrCreate(EngineRef.scala:282) ~[kyuubi-server_2.12-1.5.2-incubating.jar:1.5.2-incubating]
at org.apache.kyuubi.session.KyuubiSessionImpl.$anonfun$openEngineSession$1(KyuubiSessionImpl.scala:98) ~[kyuubi-server_2.12-1.5.2-incubating.jar:1.5.2-incubating]
at org.apache.kyuubi.session.KyuubiSessionImpl.$anonfun$openEngineSession$1$adapted(KyuubiSessionImpl.scala:97) ~[kyuubi-server_2.12-1.5.2-incubating.jar:1.5.2-incubating]
at org.apache.kyuubi.ha.client.ZooKeeperClientProvider$.withZkClient(ZooKeeperClientProvider.scala:104) ~[kyuubi-ha_2.12-1.5.2-incubating.jar:1.5.2-incubating]
at org.apache.kyuubi.session.KyuubiSessionImpl.openEngineSession(KyuubiSessionImpl.scala:97) ~[kyuubi-server_2.12-1.5.2-incubating.jar:1.5.2-incubating]
at org.apache.kyuubi.operation.LaunchEngine.$anonfun$runInternal$1(LaunchEngine.scala:51) ~[kyuubi-server_2.12-1.5.2-incubating.jar:1.5.2-incubating]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_322]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_322]
|
通过 spark-submit的方式,启动一个新进程
1
2
3
4
5
6
7
8
9
10
11
12
13
|
org.apache.kyuubi.engine.EngineRef: Launching engine:
/data1/kyuubi/apache-kyuubi-1.5.2-incubating-bin/bin/bin/spark-submit \
--class org.apache.kyuubi.engine.spark.SparkSQLEngine \
--conf spark.hive.server2.thrift.resultset.default.fetch.size=1000 \
--conf spark.kyuubi.ha.zookeeper.quorum=-server-11976:2181 \
--conf spark.kyuubi.client.ip=10.136.78.78 \
--conf spark.kyuubi.engine.submit.time=1656659668857 \
--conf spark.app.name=kyuubi_USER_SPARK_SQL_你的账号_default_3672b136-3b40-4452-b20d-96b6f5aeeac6 \
--conf spark.kyuubi.ha.engine.ref.id=3672b136-3b40-4452-b20d-96b6f5aeeac6 \
--conf spark.kyuubi.ha.zookeeper.auth.type=NONE \
--conf spark.yarn.tags=KYUUBI \
--conf spark.kyuubi.ha.zookeeper.namespace=/kyuubi_1.5.2-incubating_USER_SPARK_SQL/你的账号/default \
--proxy-user 你的账号 /data1/kyuubi/apache-kyuubi-1.5.2-incubating-bin/externals/engines/spark/kyuubi-spark-sql-engine_2.12-1.5.2-incubating.jar
|
ZK存储的信息
通过命令行连接到 kyuubi注册的ZK
1
2
3
|
# ZK上的节点信息
ls /
[kyuubi, kyuubi_USER, zookeeper]
|
/kyuubi 路径下的信息
1
2
3
4
5
|
ls /kyuubi
[serviceUri=my-server-1101:10009;version=1.5.2-incubating;sequence=0000000000]
[zk: 10.201.81.222:2181(CONNECTED) 7] get /kyuubi/serviceUri=my-server-1101:10009;version=1.5.2-incubating;sequence=0000000000
my-server-1101:10009
|
还有一个 kyuubi_USER的路径
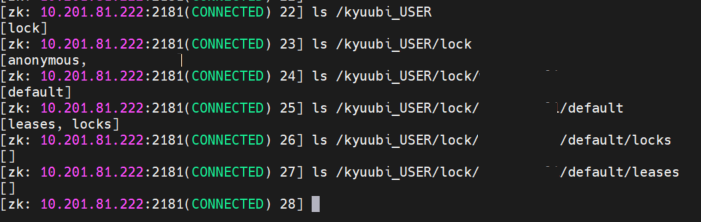 这个路径可能 对应的是用户级别的session
这个路径可能 对应的是用户级别的session
再往下是 lock 路径
然后是 用户,每次连接过来的用户,都会在 ZK 上有一个对应的路径信息
用户后面的路径是 default,应该是 查询的数据库
最下面的两个是
租约信息
锁信息
代码实现细节
session相关的定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
object ShareLevel extends Enumeration {
type ShareLevel = Value
val
/**
* In this level, An APP will not be shared and used only for a single session
*/
CONNECTION,
/*
* DEFAULT level, An APP will be shared for all sessions created by a user
*/
USER,
/**
* In this level, An APP will be shared for all sessions created by a user's default group
*/
GROUP,
/**
* In this level, All sessions from one or more Kyuubi server's will share one single APP
*/
SERVER = Valu
|
支持的引擎类型
1
2
3
4
5
|
object EngineType extends Enumeration {
type EngineType = Value
val SPARK_SQL, FLINK_SQL, TRINO, HIVE_SQL = Value
}
|
操作状态、操作类型
1
2
3
4
5
6
7
|
// 操作状态
val INITIALIZED, PENDING, RUNNING, COMPILED, FINISHED, TIMEOUT, CANCELED, CLOSED, ERROR, UNKNOWN =
Value
// 操作类型
val UNKNOWN_OPERATION, EXECUTE_STATEMENT, GET_TYPE_INFO, GET_CATALOGS, GET_SCHEMAS, GET_TABLES,
GET_TABLE_TYPES, GET_COLUMNS, GET_FUNCTIONS = Value
|
类的继承关系
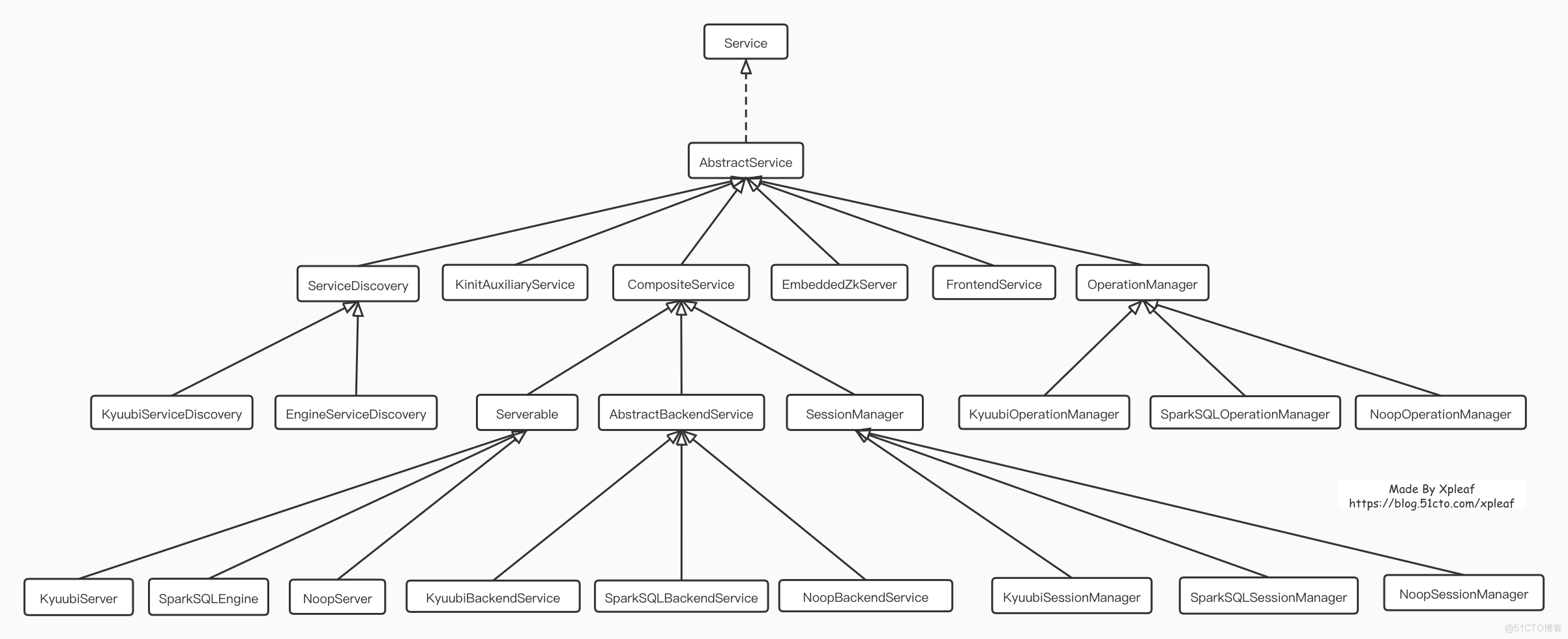
详细的代码实现细节,参考这篇文章 -> 【网易Spark Kyuubi核心架构设计与源码实现剖析】
这篇文章讲的比较细了,server层、引擎层的启动,到执行基本都说清楚了
实现kyuubi的功能
按照功能分解
- 增加一个工具类封装ZK的api,可以读/写ZK的一些节点
- 增加一个代理层,实现 client -> 代理 -> 自定义hive-server(engine-server) 这一条请求执行链路
- 基于ZK工具类,增加一个session 管理功能,每来一个请求,就可以在ZK上创建一个节点,并设置session类型
整合这些功能
- 代理将自身注册到ZK上,引擎层将自己注册到ZK上
- 修改客户端,可以通过ZK发现代理
- 基于ZK的方式,完成 client -> proxy -> engine-server
- 在此基础上,增加session管理功能
其他
- proxy -> custom hive-server 这条路线,可以不用kerberos认证,改用Sasl方式
- 部署多台proxy,engine-server测试效果
- 本地测试仍然可以用 client -> engine-server的方式,不需要ZK,方便调试测试
- 异步查询
参考