高可用设计
背景
由于 spark自带的thrift本身只是一个单点,虽然可以通过ZK部署主备,但运行时仍然只有一个节点接收外部请求,很容易成为瓶颈
为此,我们参考了网易的 kyuubi,给其增加了高可用能力,可以将各种不同的节点都部署成多个,解决单点、以及计算瓶颈的问题
设计概览
整体架构
总体的架构如下:
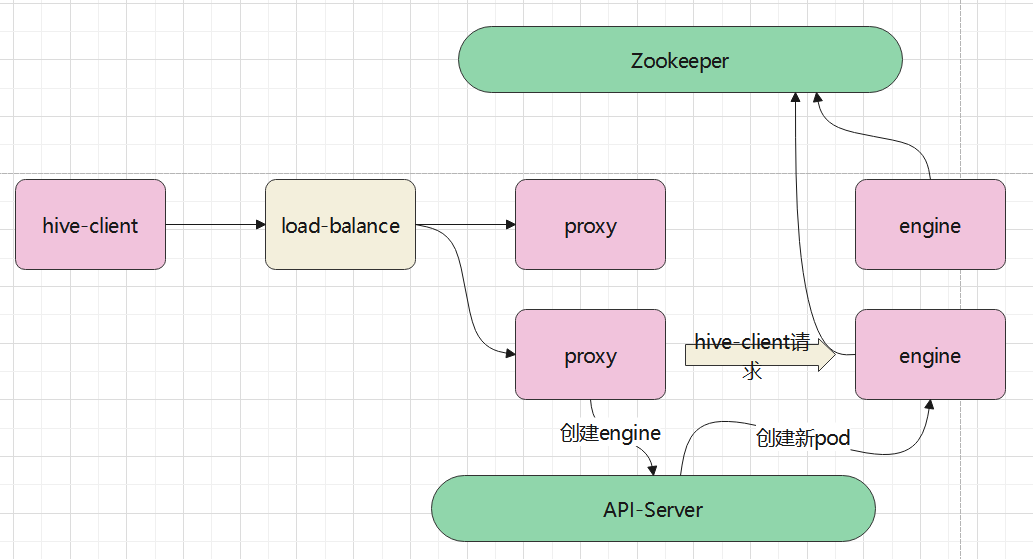
对上述名词做一个解释:
- hive-client,这个就是原生的hive jdbc程序,通过一个统一的IP、域名来访问扩展spar-driver
- load-balance,由k8s提供的一个负载均衡服务,它将请求转发到一个具体的 proxy
- proxy,这个角色有点特殊,它即是服务端,也是客户端,
- 对于 hive-client来说,他是客户端,接收请求
- 对于 engine 来说,它又是客户端,将hive-client的请求转发给 engine
- hive-client -> proxy, 以及 proxy -> engine,使用的都是统一套 hive thrift协议
- engine,这个类似之前的扩展spar-driver服务端
- 它也相当于一个 spark-driver
- 之前扩展spar-driver的hive-server端接收hive-client请求,执行SQL并返回
- 现在这个 engine,就等同于之前的扩展spar-driver hive-server
- engine 会将自身注册到 Zookeeper上,包括engine节点的 IP和port
- proxy 接收到 hive-client的请求后,会通过Zookeeper查找一堆 engine列表,然后选择一个合适的,再创建一个连接,跟engine通讯
- 如果proxy没有找到合适的,或者 engine列表为空,则通过k8s的api-server动态启动一个engine
一个更完整的调用关系:
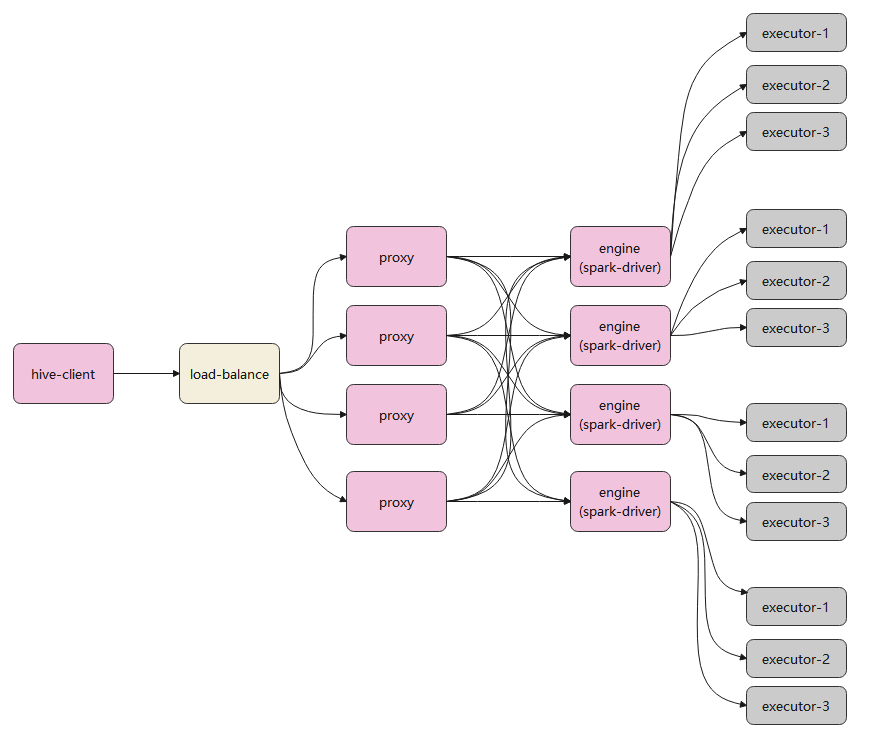
从上图可以看到,proxy 和 engine是多对多的关系
- load-balance请求请求转发给一个具体的proxy后,这个proxy会选择一个合适的engine进行连接
- 每个engine,相当于一个spark-dirver
- 上图中,相当于有 4个 spark集群
动态启动
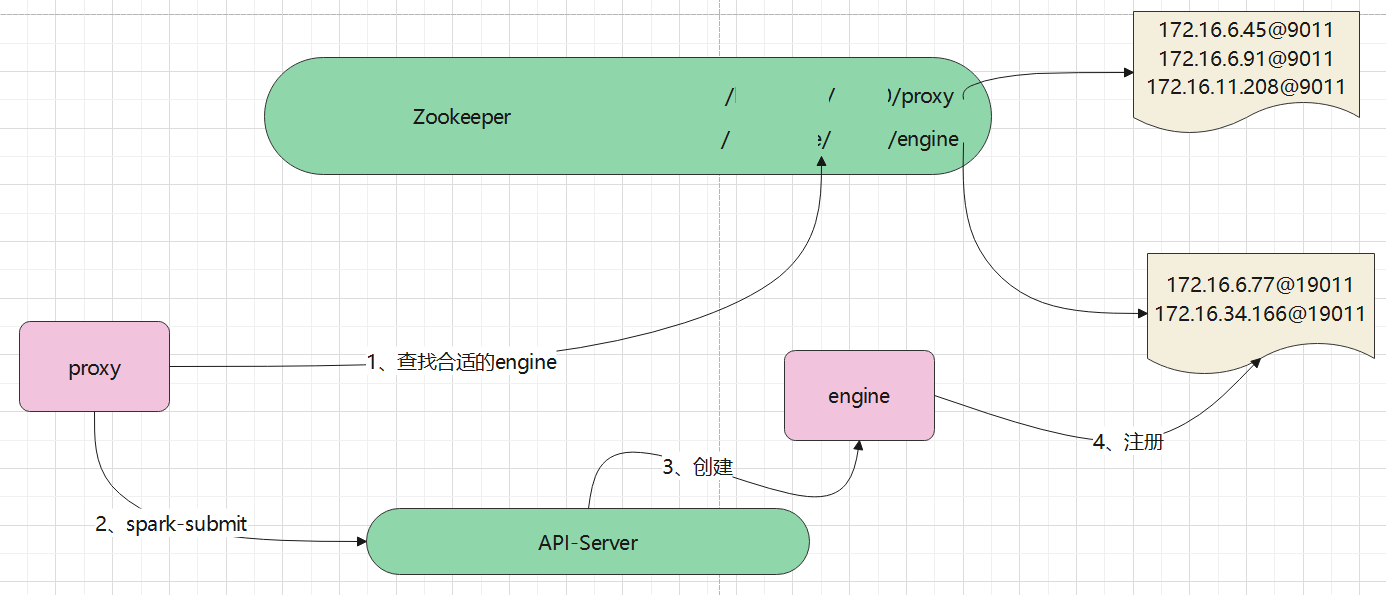
上述的执行流程是:
- proxy首先从
/扩展spar-driver/xxx/engine找一个合适的engine - 如果没有合适的,则通过spark-submit,调用api-server,动态启动一个engine
- api-server负责创建一个新的pod,也就是新的engine
- 新的engine将自己注册到 zookeeper上
- proxy感知到zookeeper的变化,获取到刚刚注册的engine,跟这个engine建立通讯
所有的节点都部署在k8s上(zookeeper也可以单独部署)
当客户端的请求到proxy之后,proxy会在zookeeper的 /扩展spar-driver/xxx/engine这个路径上,查找可用的engine
这个查找过程,本身可以扩展出很多东西:
- engine定时的将自身的负载信息回报到zookeeper上,proxy根据负载情况选择一个合适的engine
- proxy缓存engine的列表,等下次请求来了,就不用再访问zookeeper了
- 对于上述缓存方案,还需要增加一些定时清理,去除无效的engine等逻辑
- 如果engine少于固定的数量,比如5个或者10个,则再动态启动一批
目前的逻辑比较简单,就是看目前的 engine列表数量是否 小于一个阈值,如果不是,则随机选择一个engine
否则就动态创建一批 engine
engine的动态创建过程
执行过程:
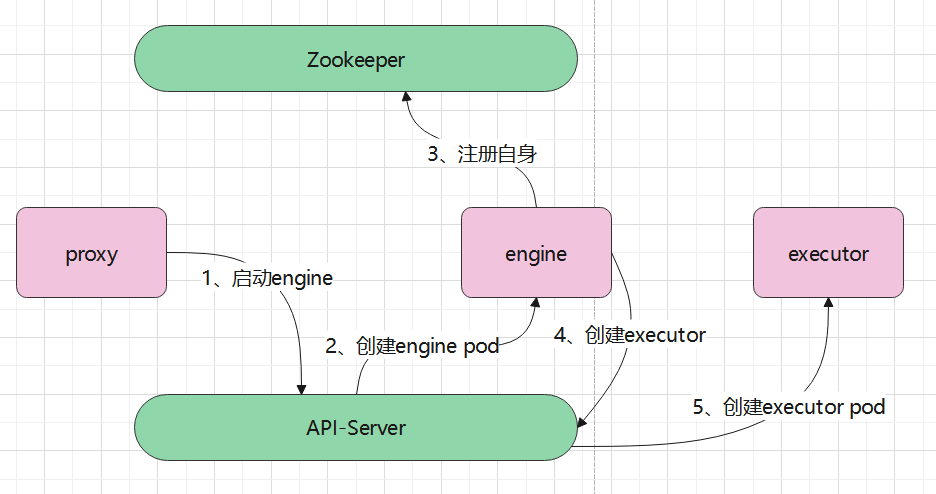
1、proxy通过api-server动态启动engine
2、api-server创建新pod,也就是engine
3、engine将自身注册到zookeeper上
4、engine再创建executor,这里也是通过api-server创建的
5、api-server创建一个新的pod executor
proxy 创建engine时,是通过 env的方式,将spark的参数传递给engine的
这样engine在启动的时候,通过env就可以拿到对应的参数了
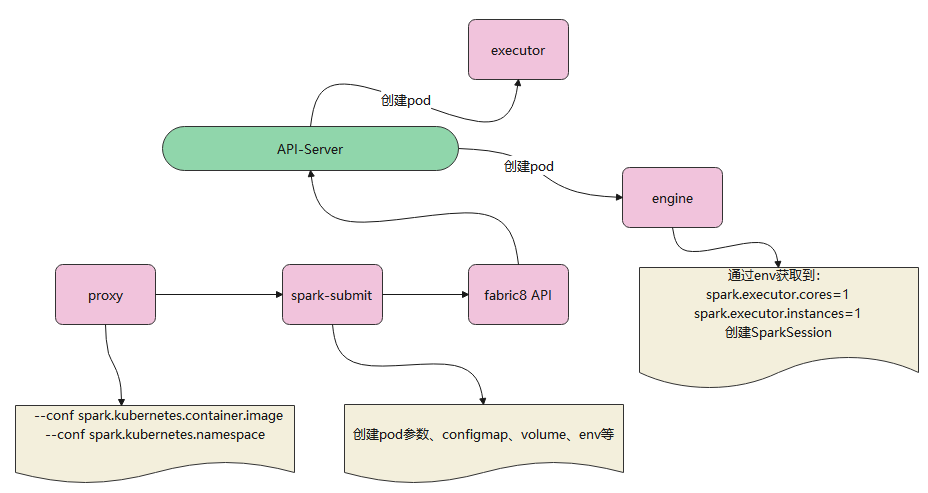
如上,proxy会调用 spark-submit程序,来启动一个新pod
1、proxy 会将一堆自定义的 –conf 参数传递给spark-submit
2、spark-submit根据这些参数,创建pod参数、configmap参数、volume、传递env等等
3、最终是调用 fabric8 API将请求发给 api-server的
4、api-server收到请求后,创建出新的pod,也就是engine
5、proxy调用spark-submit时,传递了一堆参数,其中包含了 env相关的,这些参数最终由api-server收到传递给engine
6、engine通过 env就可以获取到proxy传递过来的指定,执行一些更动态的逻辑
不同的安全连接方式
proxy,engine可以使用不同的连接方式
- 客户端 到 proxy,可以采用kerboers方式,这跟之前的连接方式一样
- proxy 到 engine,可以采用 SASL方式,因为客户端到proxy已经验证一次了,后面没必要再验证了,而SASL本身也是加密的

基于负载的选择
继承 SparkListener,实现
- onJobStart
- onJobEnd
- onExecutorAdded
- onExecutorRemoved
等节点变化,job变化时候,变更Zookeeper下的 固定节点
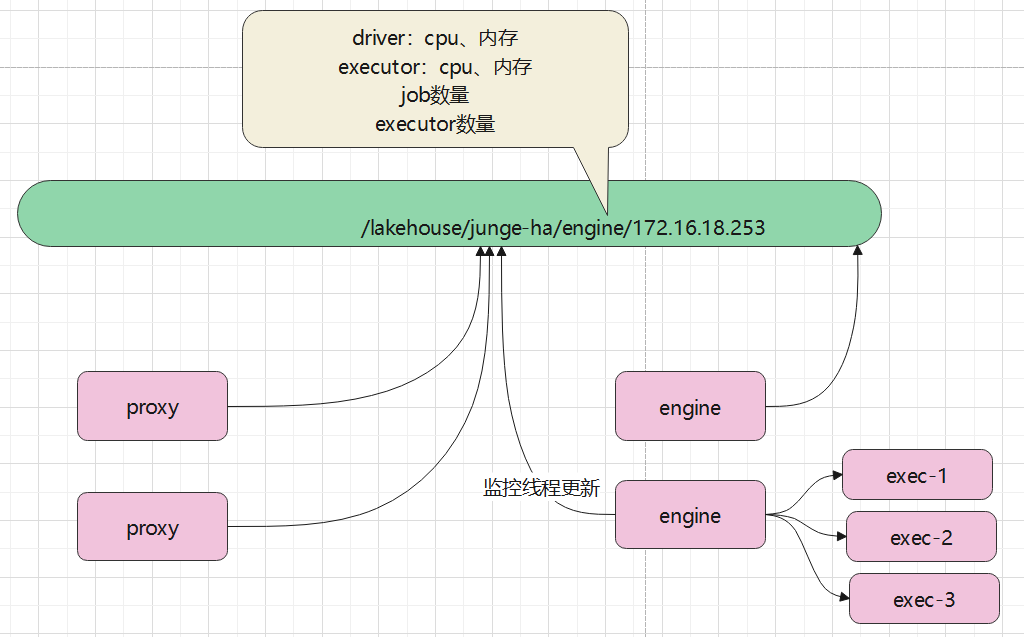
/扩展spar-driver/my-test/engine/172.16.18.99 这个znode 节点中存储的信息为:
{
"execCount": 11,
"jobCount": 1024,
"driver": {
"cores": 2,
"mem": "2G"
},
"executor": {
"cores": 2,
"mem": "4G"
}
}
当新增一个executor,或者新job出现时,更新 /扩展spar-driver/my-test/engine/172.16.18.99
跟这个任务相关的有三个线程:
- spark的listener线程,当job、executor变化时触发自定义的逻辑,然后将事件发到队列中
- engine节点的监听线程立刻从 阻塞队列中获取事件,将事件更新到 Zookeeper上
- proxy的监听节点定期监听Zookeeper的engine列表,然后选择一个负载最低的放入缓存中,待后续请求使用
负载计算公式:
|
|
举个例子:
集群1
driver:1C2G,executor:2C4G,executor数量109个,job数量33个
(1 + 2 + 109 * (2 + 4)) / 33.0
结果为 19.909集群2
driver: 1C2G,executor:2C4G,executor数量为46个,job数量为25个
(1 + 2 + 46 * ( 2 + 4)) / 25.0
结果为 11.16
综合看集群1的分数更高,所以选择集群 1
现在已经有一个1分钟的定时逻辑,会获取zk 上的engine列表
proxy统计出这个路径下的engine,计算出executor的数量 * 内存,executor数量 * CPU
以及job数量,计算出一个负载最低的engine,然后选择出这个engine,以提供给下次请求使用
如果proxy是基于事件监听的方式,获取到的统计就非常实时了,但是每次有job新增、销毁都会触发 N个proxy重新计算,也要考虑大集群的消耗问题
当然也可以支持两种
- 基于1分钟(可以配置)的定期检查
- 基于事件通知的实时方式