FlumeJava: Easy, Efficient Data-Parallel Pipelines
Introduction
MapReduce是一个开创性的好东西,大大简化了并行处理的编写,之后就出现了各种开源的相似产品
MR简要回顾
- map阶段,读取文件中的数据,多个文件被当做一个逻辑输入文件,然后调用mapper函数,产出0或多个键值对,并将结果落盘
- shuffle阶段,读取mapper的文件,按照key做分组排序,并将结果再次落盘
- reducer,读取key和管理的value集合,调用reducer函数,产生0到多个替换value的结果
- 还有一些优化如map阶段的可选combiner自定义函数,可以提前聚合
- sharder函数,可以选择哪个reducer机器来接受指定的key
但是MR太底层了,真实情况是需要多个MR组合起来使用的,也就是像流水线那样处理一个真实的场景,但是MR没这个功能
于是只能手动编写多个MR,还要维护、管理他们之间的管理,处理前后依赖,还要删除中间数据等等,非常麻烦
之后谷歌就搞出了 FlumeJava这个东西,这个其实一个库,底层还是基于MapReduce 的,但在上面做了很多创新
FlumeJava就是一堆不可变的并行集合,支持各种并行处理操作,在不同的数据类型之上提供了一个统一的抽象层和执行策略
FlumeJava会推迟执行,会优化执行计划,实际就是对底层的MR的执行做优化,比如根据数据量大小选择是远程MR,还是本地loop
这种优化效果可以达到手动的效果,跟一个有经验的MR程序员写出来的程序差不多,但是开发难度要低很多
另外FlumeJava会管理各种MR产生的中间结果
总的来说,FlumeJava像一个承上启下的框架,基于M-R做了很多优化,而这些优化对后面的系统有很大的启发
- 比如,增加了很多基本的算子,通过这些基本算子,又可以组合成多种复杂的功能
- 底层还是基于M-R的,但上层是Java,而这些Java代码又可以跟普通的逻辑代码混合在一起,开发效率提高了很多
- 增加了延迟执行,生成DAG,然后对DAG做优化
其实从这几点看,后面出现的Spark、Flink都是类似的思路
The FlumeJava Library
先看下目标,FlumeJava的目标是
- 提供一个接近于用户逻辑计算的构造
- 提供一个抽象层,可以使用户远离低层级的物理细节,如输入输出格式,存储格式等
- 也避免了map中的各种逻辑算计分区等等
Core Abstractions
FlumeJava的核心类
- PCollection,是一个T类型,不可变的bag集合,可以是排序的队列,也可以是无序的;它从文件中创建,保持在内存中
- 另一个核心类是PTable<K,V>,他是PCollection<Pair<K,V»的子类
下面是一个例子
|
|
上面例子中,读文本文件,并编码为UTF-8,或者读二进制文件,编码为DocInfo.class
FlumeJava定义了一堆主要的数据并行操作,通过类似parallelDo(),将一个输入的PCollection,产生一个新的PCollection
参数为:DoFn<T, S>,表示输入为T,输出为类型为S
再来看一个例子:
|
|
lines.parallelDo 表示这个操作可以并行完成
collectionOf(strings()) 表示结果产出为 无序的stirng类型(有序的如:sequenceOf(elemEncoding ))
emitFn是一个回调函数,会将结果放入PCollection中
FlumeJava定义了一堆 DoFn、MapFn、FilterFn
parallelDo()可以在map和reduce端使用
第二个例子是 group by的,它将多个PTable<K,V>类型的map,映射到一个唯一的PTable<K,Collection> map,每个key都是未排序的,所有的值都是原生的java集合
下面就是计算 URL 到 映射到他们的文档集合,这个就是MR的shuffle阶段
|
|
第三个例子是 combine,类似于mapper阶段的聚合,以及reducer
|
|
第四个主要元素是 flatten(),它将传入的list返回为单个 PCollection
不过他并非真正的创建,而是返回一个逻辑视图
最终可以通过PCollections,将结果写入到磁盘
|
|
因为 PCollections 只是一个普通的Java对象,所以它可以跟其他Java代码一起整合使用
于是可以写出下面这样的代码:
|
|
Derived Operations
比如 count()操作,它将 PCollection 导出为 a PTable<T, Integer>
所以代码可以简化为:
|
|
还有 join,他把 PTable<K, V1> 和 PTable<K, V2> 转换成了:PTable<K,Tuple2<Collection, Collection»
统一的table中的key包含了 table1、table2中出现的key对应的value
join的实现如下:
- 应用parallelDo() 到每个输入的 PTable<K, Vi>,转换为PTable<K,TaggedUnion2<V1,V2»
- 使用flatten()组合表
- 用groupByKey()打平table,产生出:PTable<K, Collection<TaggedUnion2<V1,V2»>
- 将 parallelDo() 应用到被key分组的表,转换每个 Collection<TaggedUnion2<V1,V2» 到Collection的type和Collection.
最后一个实用的操作是:top()
Deferred Evaluation
FlumeJava中的操作都是推迟执行的,这样可以方便优化
每个PCollection对象都表示一个推迟的也就是还没计算,或者是已经物化的状态
当调用parallelDo()时,只是创建了延迟的对象,并返回一个PCollection指向它
FlumeJava可以用 DAG表示延迟的PCllection和操作
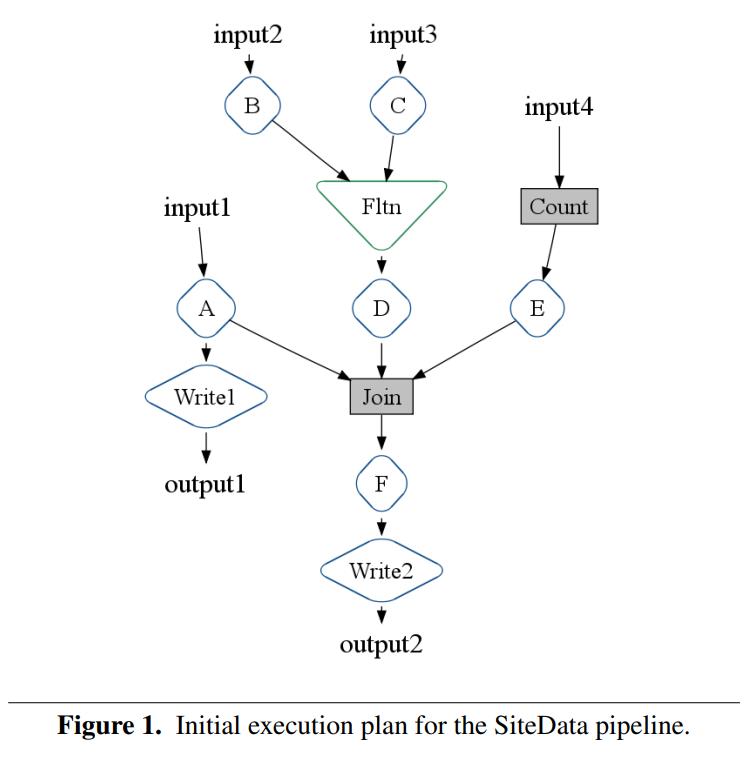
下图展示了一个执行计划
输入2经过B 和 输入3经过C,他们两的通过flatten整合到一起交给D
输入4计算count,交给E
之后A、D、E做join,然后交给F
最终,输出A和F的结果
真实的操作是通过 FlumeJava.run() 触发的,会变成优化的逻辑计划
当一个PCllection被评估,会转成内存数据结构,或者引用到一个中间的临时文件
当执行计划后续不再引用这些中间文件时,FlumeJava会自动的删除这些文件
PObjects
在PCllection执行期间,或者执行之后,提供了一种获取其值的方式,也就是 PObject
比如下面这个例子,调用asSequentialCollection获取一PObject<Collection>,执行FlumeJava#run之后,就可以获取运行结果了
|
|
下面这个例子是 combine(),通过这种方式可以计算sum,或者max
|
|
另一个例子
|
|
再来看一个例子,PObject还可以作为参数传递给PCllection
当POjbect被计算出来后,用户的自定义代码就可以获取这个值了
|
|
此外PObject还可以封装List,也就是将多个值内嵌到PObject中
通过上述代码,我们可以看到 PObject就可以提取流水线中的各种值,也可以被继续包装传给流水线
Optimizer
就是把用户构建的、模块化的FlumeJava执行计划,变成高效的执行计划,然后转换成独立的图
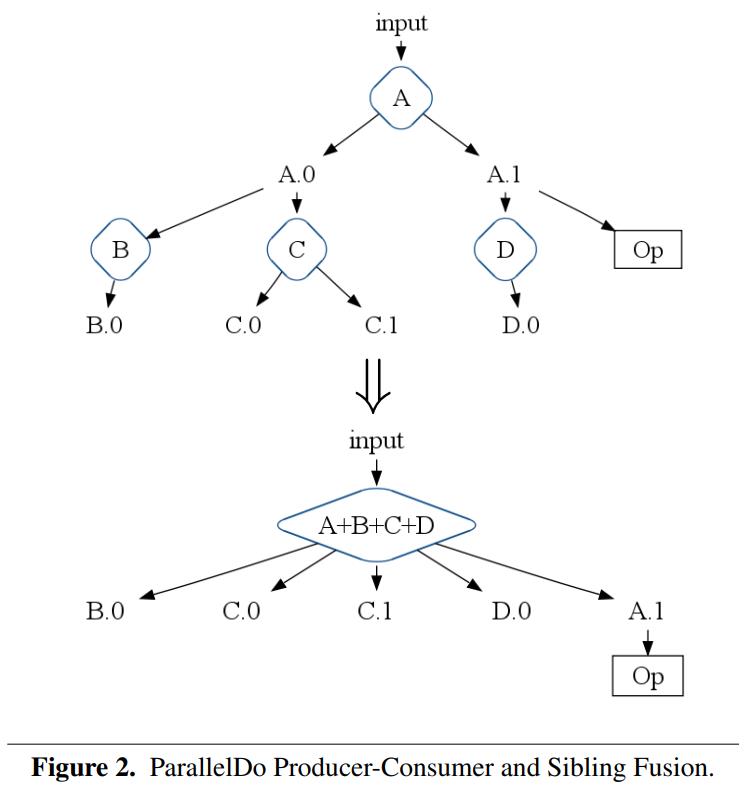
ParallelDo Fusion
这里包含了两种
- produce-consumer,比如一个ParallelDo处理了函数f,其输出被当做另一个函数的输入,于是可以合并这两个节点
- sibling fusion,当多个算子读一个输入时,可以将他们融合为一个算子,合并后的算子产生多个输出
比如,可以将图2 做一些转换,A、B、C、D融合为A+B+C+D,此时A0就不再需要了
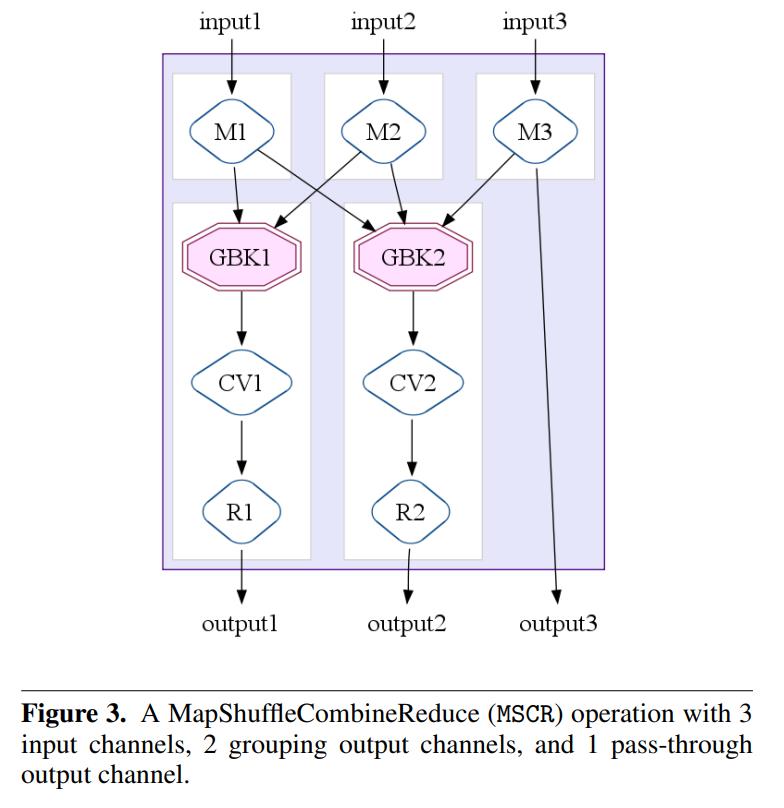
The MapShuffleCombineReduce (MSCR) Operation
这里的核心思想是将 ParallelDo, GroupByKey, CombineValues, 以及 Flatten 融入到 单个MapReduce中
为了弥补这些操作抽象层之间的差别,使用了 MapShuffleCombineReduce MSCR操作
MSCR使用了 M个输入,以及R个输出,输出可能包含可选的shuffle,可选的combine以及一个reduce
每个输入都会向一个或者多个输出通道发射
每个输出执行一个shuffle,或者可选的 combinVlaue,以及reduder
也可以将输入直接输出,也就是pass-through
MSCR本质上可以优化为单个M-R
图3中,包含3个输入,2个输出,这两个输出都执行了shuffle以及combinVlaue,以及一个 pass-through的输出
MSCR Fusion
它会往前推,找到合适的GroupByKey,再往后找到合适的CombineValues
把他们融合为一个大的 MSCR
比如对于图4,是把多个 groupby-key合并到一起了
在和里gbk1和gbk2是关联的,因为他们公用了M2的输出
同理,gbk2和gbk3也是关联的,他们公用了M4,所以把这三个gbk都融合进来
gbk2的输出融合给了cv2,而r2和r3也被融合进来了
还有一些额外的附加,比如gbk1的op1,以及m4的输出
最后变成了4个输入,5个输出
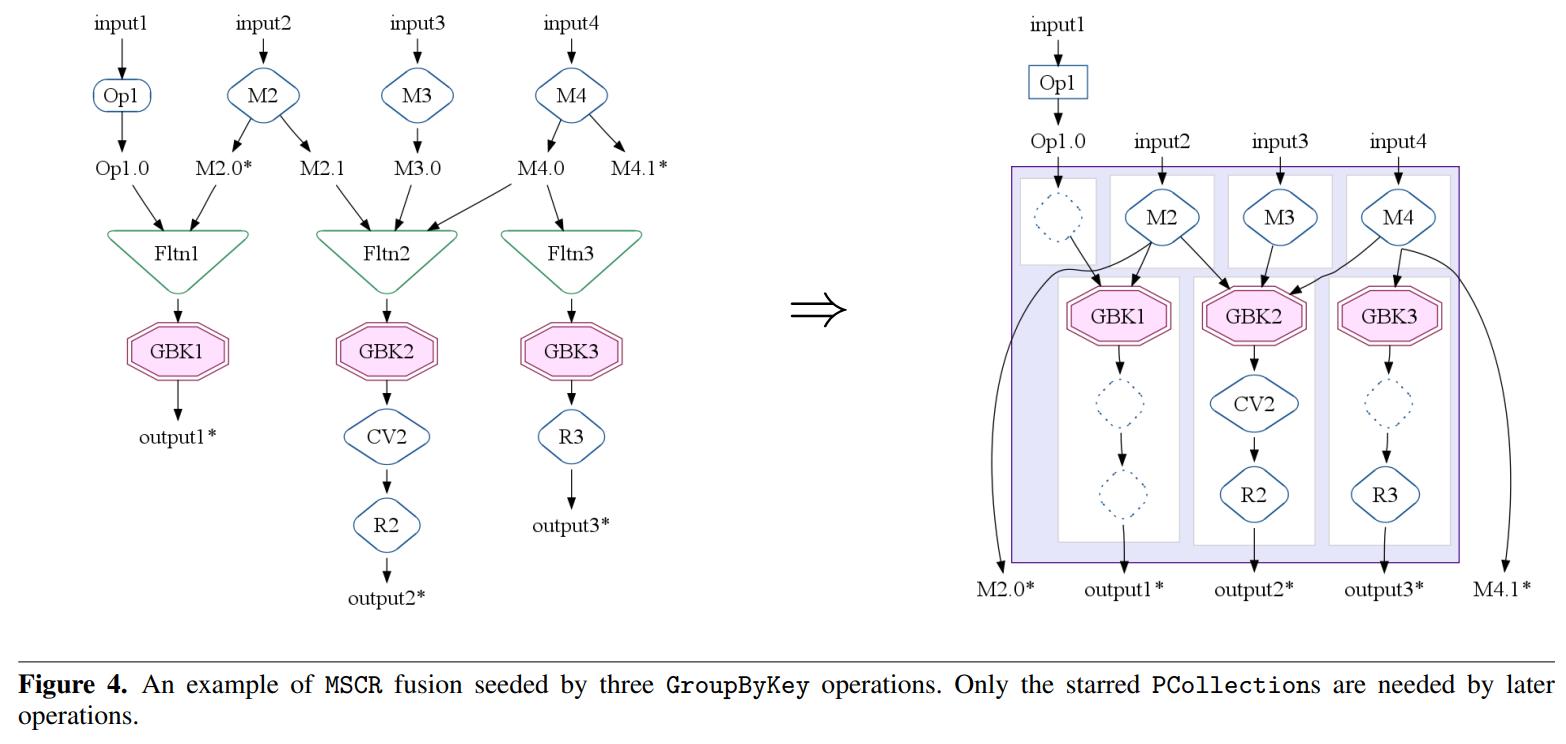
在所有GroupByKey操作都转换为MSCR操作,任何剩余的ParallelDo操作也被转换为普通的MSCR操作,使用包含ParallelDo的单个输入通道和单个直通输出通道。最终优化的执行计划只包含MSCR, Flatten、Operate操作
Overall Optimizer Strategy
执行一系列的优化,目标是产生尽可能少,尽可能高效的MSCR操作
- Sink Flattens,就是把 h(f(a) + g(b))h(f(a)) + h(g(b)),后面可以对(h ◦ f)(a)做融合,(这里+ 是Flatten)
- Lift CombineValues operations,进行部分combine计算,之后在局部的基础上在汇总
- Insert fusion blocks
- Fuse ParallelDos
- Fuse MSCRs
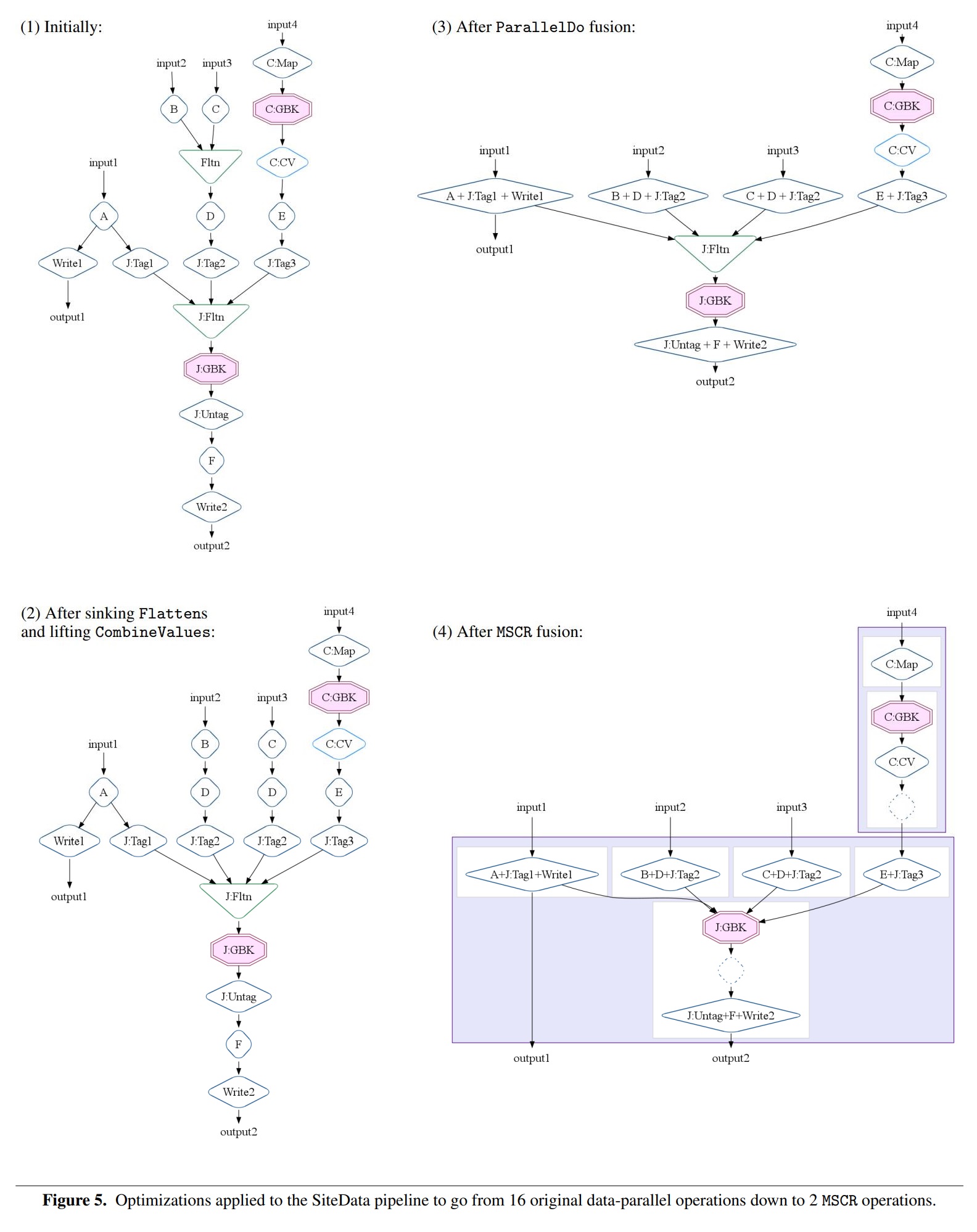
Example: SiteData
将16个源操作优化到2个MSCR操作
- 首先是: sinking Flattens、lifting CombineValues,把flatten下推到D
- 然后是ParallelDo,把各个兄弟节点融合
- MSCR操作之后,变成2个,把各种兄弟节点融合后的输出转为gbk
Executor
总结
- 优化完了之后,就直接交给M-R执行了
- 目前只支持批执行,未来考虑实现增量、流、连续执行
- 支持本地和远程运行,对于小数量的,直接用本地的方式执行
- 对于大数据量,可以自动的创建多个M-R任务,并行执行
- 未来考虑增加自动评估优化,根据数据量大小,负载情况做预估创建M-R
- 还提供了cache功能
- 提供日志,对于远端的M-R报错,本地也可以拿到远程出错信息,方便调试
Evaluation
2009年第一次发布,之后就在谷歌开始大规模使用了,优化效果非常好
一般来说可以把M-R的数量优化减少5倍,有的能优化到30倍
从优化效果看,对于小数据量、大数据量都有效果
下面是一个对比 ,每个版本需要的代码数量
| Benchmark | FlumeJava | MapReduce(Modular) | MapReduce(Hand-Opt) | Sawzall(Hand-Opt) |
|---|---|---|---|---|
| Ads Logs | 320 | 465 | 399 | 158 |
| IndexStats | 176 | 296 | 336 | - |
| Build Logs | 276 | 476 | 355 | - |
| SiteData | 465 | 653 | 625 | 261 |
对比优化后的效果 ,FlumeJava显示了优化前后的效果
| Benchmark | FlumeJava | MapReduce(Modular) | MapReduce(Hand-Opt) | Sawzall(Hand-Opt) |
|---|---|---|---|---|
| Ads Logs | 14 → 1 | 4 | 1 | 4 |
| IndexStats | 16 → 2 | 3 | 2 | - |
| Build Logs | 7 → 1 | 3 | 1 | - |
| SiteData | 12 → 2 | 5 | 2 | 6 |
每个测试的输入数据量:
| Benchmark | Input Size | Number of Machines |
|---|---|---|
| Ads Logs | 550 MB | 4 |
| IndexStats | 3.3 TB | 200 |
| Build Logs | 34 GB | 15 |
| SiteData | 1.3 TB | 200 |
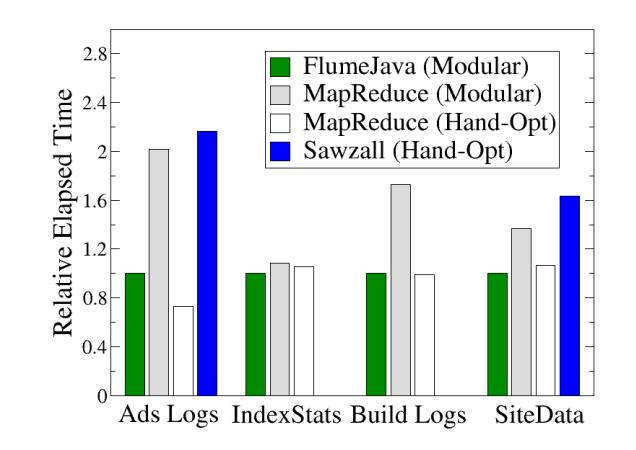
下面是基准测试的结果,时间越短越好,可以看到FluemJava跟手动优化的M-R差不多
Conclusion
相关系统
- MapReduce,这个不用说了
- Sawzall,基于M-R的DSL,有很大限制,比如不支持join
- Hadoop,仿造者
- Cascading,类似于FlumeJava,但需要用户手动构造DAG
- Pig,类SQL,还需要用代码表示数据流图算子之间的边
- Dryad,微软搞的,有点像Cascading又有点像FlumeJava,需要定义数据流转向,也有优化操作
- DryadLINQ,对linq的支持
- SCOPE,基于Dryad之上,支持SQL
- Map-Reduce-Merge,在M-R的基础上增加了merge,可以支持关系代数
FlumeJava的优化思想也借鉴了很多关系型DB的工作
不过没有索引,join也是hash-join