深入数据库系统: Query Execution & Processing
背景
相关资料
论文总结
- MonetDB/X100: Hyper-Pipelining Query Execution
- Access Path Selection in Main-Memory Optimized Data Systems Should I Scan or Should I Probe
- Materialization Strategies in the Vertica Analytic Database: Lessons Learned
- Accelerating Analytics with Dynamic In-Memory Expressions
课程总结
整体架构
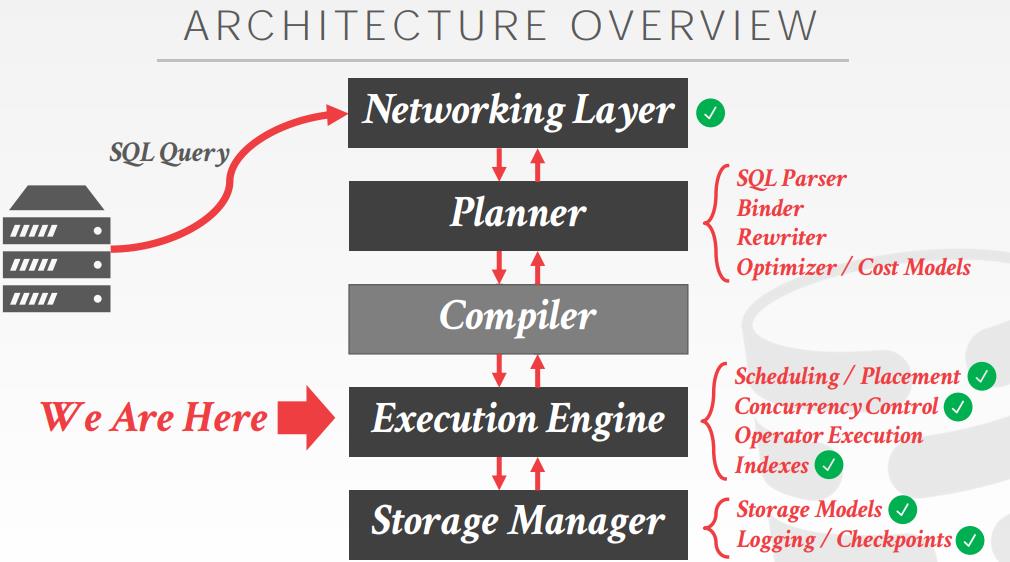
假设数据集已经全部放到内存中了
优化目标
- 减少指令的数量
- 减少每个指令的执行周期
- 并行执行
算子执行
- Query Plan Processing
- Scan Sharing
- Materialized Views
- Query Compilation
- Vectorized Operators
- Parallel Algorithms
- Application Logic Execution (UDFs)
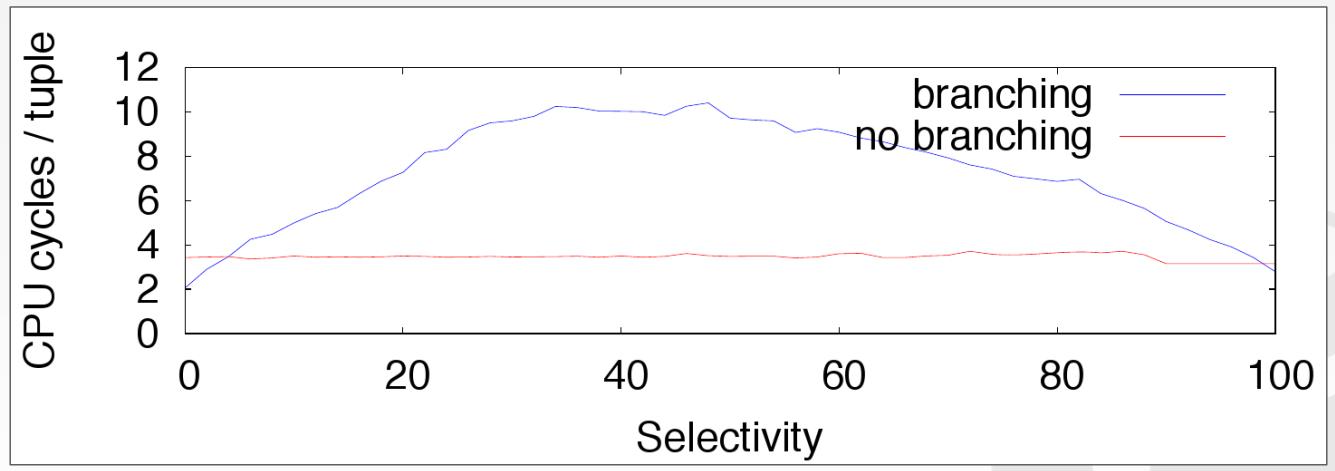
DBMS/CPU的问题
- 依赖,如果一个指令依赖另一个指令,则他们就无法在相同流水行并行
- 分支预测,为保持流水行繁忙CPU会冒险预测提前执行,但如果执行出错会将所有预测和执行的工作全部丢弃
- DMBS一般是顺序scan时执行filter操作,但是几乎不可能预测正确
Scalar (Branching)
|
|
Scalar (Branchless)
|
|
selection scans,如下:
处理模型
- Iterator Model(Volcano、Pipeline)
- Materialization Model
- Vectorized / Batch Model
支持 火山模型的系统
- SQLite
- mongoDB
- nuoDB
- Impala
- DB2
- Vertica
- SQLServer
- GreenPlum
- PostgreSQL
- Oracle
- MySQL
物化模型,对于小数量查询的 OLTP比较合适,OLAP不合适
- Teradata
- MonetDB
- VoletDB
- Hyrise
向量化查询
- 每次查询的数量,依赖于硬件、查询属性
- 对于OLAP很合适,可以减少每个算子的调用数量
- Presto
- Vectorwise
- snowflake
- Hyrise
- DuckDB
- SQLServer
- DB2
- Oracle
- Amazon redshift
- Cockroach Labs
查询处理的方向
- 自顶向下,根节点从子节点pull数据,tuple的传递方向是跟函数 调用一致的
- 字底向上,叶结点push数据到他们的父节点,允许在流水线中更紧密的控制cache/register
将单个查询并行化方式
- Intra-Operator,水平
- 所有独立的实例执执行相同的函数,基于不同的数据子集
- 然后增加一个exchange算子,整合所有的子节点数据
- Inter-Operator,垂直
- 算子之间有覆盖,以便将流水线数据从 一个节点 传递到另一个节点,而不用物化
- 从查询计划中的不同片段中,同时执行多个算子
- 仍然需要exchange操作,将中间结果片段做合并,也叫 pipelined parallelism.
- 两个算法不是排斥的,每个关系算子都有并行算法
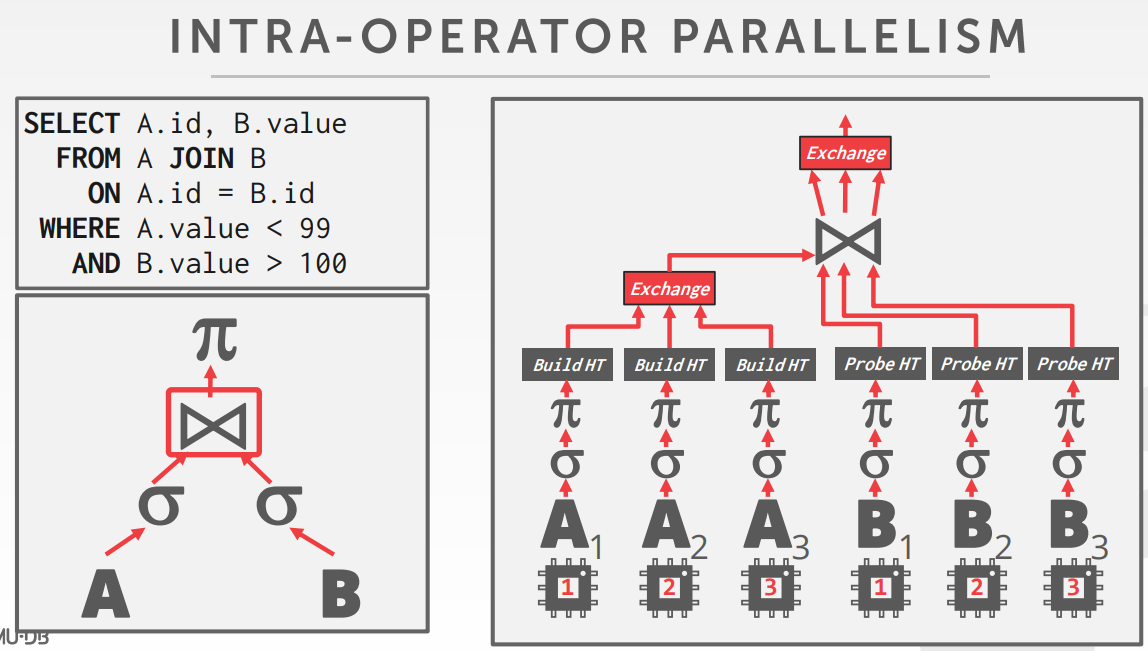
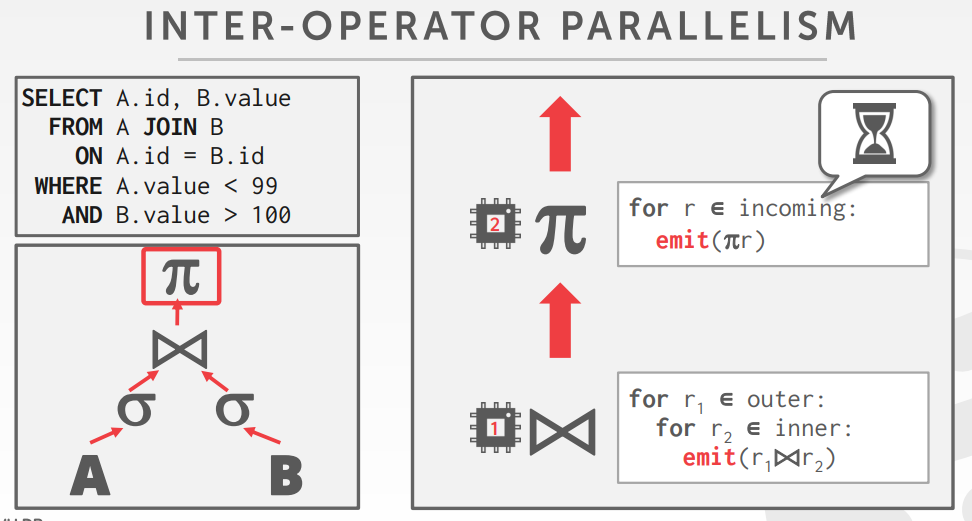
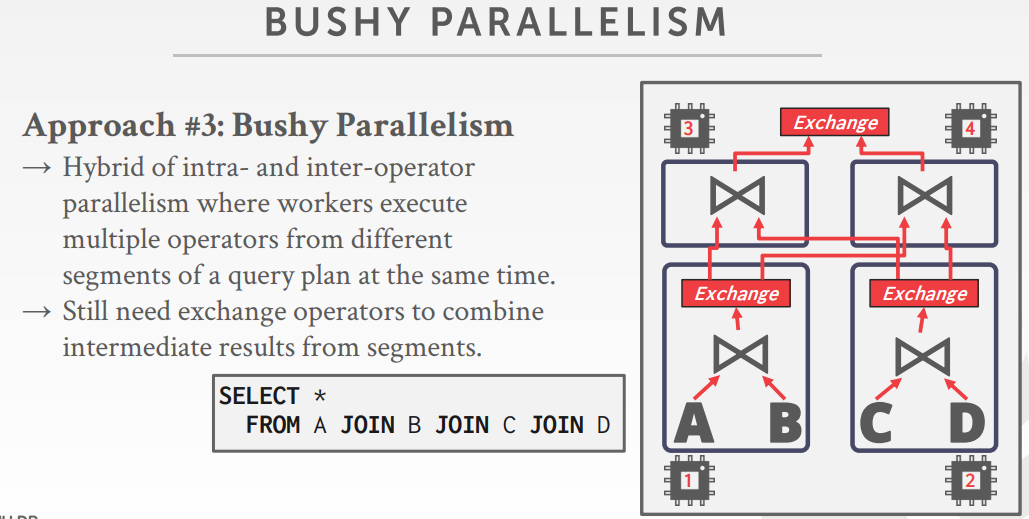
决定 查询计划的工作节点的数量依赖
- CPU核数
- 数据大小
- 算子的功能
worker 分配
- One Worker per Core,每个核分配一个线程
- sched_setaffinity
- Multiple Workers per Core
- 每个核一个线程池,允许CPU核可以充分利用(如果一个worker阻塞了)
任务的分配
- push,由一个中央的调度器来分配task到worker上,并监控他们的状态
- pull,worker从队列中获取下一个task,处理、然后返回再获取下一个
向量化、字底向上 的执行方式更适合 OLAP
对于现代CPU来说,最有效的方式 不是总产生最有效的执行策略
论文总结
MonetDB/X100: Hyper-Pipelining Query Execution
CIDR 2005
- 现代CPU的制作工艺缩小、芯片内的电路也在缩短、速度也就提高了
- 流水线的运作让CPU可以满负荷运作
- 但对于超长指令不友好(等前一个执行完),对分支也不友好
- 有的CPU如安腾,时钟频率不高但有很多并行流水线
- 有的CPU如奔腾,主频很高但并行流水线不多
- 循环流水线,打破分支预测行为,让指令充分并行化
- MySQL的测试结果,很多指令的执行周期很长,因为很多指令都在等待状态
- 其他一些商业数据库也有这个原因,这就是火山模型导致的
- 因为一次只执行一个加法,导致流水线出现等待,再加上调用的成本,又更高了
- MonetDB避免了火山模型,采用物化方式,其90%都是执行时间,但是物化拷贝又变成瓶颈
- 由于需要频繁的拷贝中间数据到内存中,所以内存带宽称为其瓶颈
- X100采用折中的方式,使用向量化操作一次一批
- X100如果持续调大size,中间结果就只能放到主存,退回成物化方式了
论文的贡献
- 研究发现很多数据库的 每秒指令周期都上不去
- 因为类似MySQL这样的火山模型其解释开销、分支预测,降低了CPU利用率
- MonetDB避免了火山模型,但物化方式会使内存带宽成为瓶颈
- 论文提出了采用批量的方式,平摊了火山模型的开销,也避免了物化方式的内存带宽瓶颈
实现和评估
- 现代主流的OLAP系统,很多都采用了论文中引入的向量化方式
- 使用TPC-H的Q1,没有join的复杂场景,聚合产生的结果可以用hash完成无需额外的I/O,并用gprof分析函数的调用时间
Materialization Strategies in the Vertica Analytic Database: Lessons Learned
ICDE 2013
- 列存系统查询时,通过物化方式将不同列糅合为一行,这种也叫tuple重建(物化)策略
- 包括两造,早期物化实现简单但性能不好;延迟物化,很难实现,但性能相对更好
- 早期物化分为:并行化(同时查两个列再拼接到一起)、流水线(直接去列中过滤数据),Vertica采用后者
- 延迟物化需要保持更多的信息,评估也很难,在join两边的数据无法放入内存时,还不如早期物化
- Vertica采用延迟物化,如果出错则退回早期物化
- Sideways Information Passing SIP是一系列技术集合,可用于改进join的性能
- 布隆join(类似半连接只是缓存了bloom方式),R和S属性存储起来,发生join时去查找并重建tuple
- 论文使用了 SIP+早期物化方式
- Vertica按投影存储,每个表包含一个超级投影(包含每个列的位置),投影可以分区、可以冗余复制
- 边信息传递,三个表达式会创建 4个filter,3个部分(fact.A1 IN(hash dim.B1),一个汇总
- SPI过滤器会尽可能下推,文中给出了 4个执行规则
- fact.FK = dim.PK AND dim.B = 5,通过对dim.B建立hash表,在扫描事实表时做min、max过滤
- 额外加速:谓词评估的顺序也很重(靠前的列压缩比更高),编码的影响
- 早期物化+SIP 比纯早期有很多提升,在很多场景中比延迟物化也有提升
论文的贡献
- 列存系统查询tuple重建时需要物化方式,早期物化实现简单性能查;延迟物化实现困难性能好
- 论文提出了早期物化+边信息传递,解决了延迟物化join溢出退化问题
- 通过对小表建立hash表,尽可能下推实现性能提升,总体能达到延迟物化的效果
实现和评估
- Vertica系统应该使用了这种方式
- 使用TPC-DS 直接评估早期、延迟、早期+SIP三种效果,但只给了9种场景,总体看早期+SIP比延迟略好,但场景略偏少了点
Access Path Selection in Main-Memory Optimized Data Systems Should I Scan or Should I Probe
SIGMOD 2017
- 对于主内存数据库来说,二级索引似乎并不重要,因为顺序扫描比索引更快
- 通过列存、向量化模型、数据压缩、并发下的共享scan
- 对现代分析系统是否还需要二级索引?如何做路径选择?
- 路径选择需要考虑很多参数,如:selelct算子、工作负载、数据布局、硬件特性、zone-map、压缩、B树等
- 内存中的共享scan的代价包括:数据移动、谓词评估、写入结果、单个查询开销、共享查询开销
- 内存中B+树二级索引代价:树的遍历、遍历叶节点、二级索引数据访问、写结果、结果排序、单个索引探测时间、并发索引访问
- 根据上述代价模型得出,如果选择因子很高适合scan,否则适合索引
- 访问路径的选择会很大程度影响最终查询性能,可能会称为优化器的一部分
- 从测试结果看,没有哪种访问路径策略是所有场景通吃的
- 即使在现代主内存系统中,二级索引仍然有用
- 小数据场景下scan更好,数据集变大index更有效
- 路径选择并不是一个固定的阈值,而是一个斜率,会受到选择性、硬件参数、系统设计、数据布局、并发的综合影响
论文的贡献
- 通过对主内存系统的scan和index分析和测试发现没有哪种 路径选择策略是所有场景通吃的
- 这两种路径选择策略都有适用的场景,受到选择性、硬件、数据布局、并发的综合影响
- 到底选择scan还是index的路径选择策略综合考量,路径选择可能会融入优化器,变成一个重要组成部分
实现和评估
- 不太清楚哪些系统使用了论文中的实现方式,这可能要对优化器和数据采用做很大重构了
- 对不同机器配置,分别测试了并发、选择性、数据布局场景综合考量,并给出了scan和index的热力图分布,测试场景比较充分
Accelerating Analytics with Dynamic In-Memory Expressions
VLDB 2016
- Oracle12发布了基于列的内存数据库,它是混合格式的,磁盘存储(buffer pool)是基于行的,分析内存是基于列的
- Oracle后续又推出了表达式优化,也是基于内存列格式的,对于列格式完全兼容
- 表达式中有数值计算,在数据量很多时计算成本就很高
- 优化:基表的预计算列、物化视图、预定义cube,这几种不太适合 ad-hoc场景,而且底层表变动后维护成本也高
- 通用子表达式消除,相当于对表达式做缓存,但对于并发场景不友好
- Oracle会区分根表达式、子表达式、还会创建隐式表达式,表达式会做规范化处理
- 表达式分为静态、动态,会存储到系统共享区域中
- 系统会根据时间维度维护两种统计快照,累计值(第一计算至今),当前值(最近24小时)
- 系统会根据权重对表达式做排名,识别出热表达式
- 虚拟列 表示一个、多个列表达式,不占用物理空间,然后将动态表达式 物化到内存中
- 由于底层布局都是一样的,所以分区、复制等容错对虚拟列也可以使用
- 一致性是通过undo log,SCN的闪回技术实现的
- SQL编译后悔识别出子表达式,检查这个DIME(Dynamic In-Memory Expressions)是否在内存中,根据代价计算是否要替换
论文的贡献
- Oracle首创的混合行(物理)+列(内存)格式,用于加速OLAP场景,而大表扫描的表达式计算仍然需要大量时间
- 通过额外模块识别、统计、记录这些表达式,通过undo log实现闪回的一致性读
- 本质上是一种语法树替换,识别子表达式后判断其是否被缓存了,再根据cost判断是否要替换这个子表达式
实现和评估
- Oracle12之后就实现了这种机制,对OLAP场景做进一步加速
- 对TCP-H、JSON、混合OLTP三个场景做了测试,基本考虑各种场景,测试覆盖面比较广
参考
- Renamed to Vectorwise and acquired by Actian in 2010
- Rebranded as Vector and Avalanche
- C++ attribute: likely, unlikely (since C++20)
- Bogdan Raducanu
- PostgreSQL Source Code
- Efficiently Compiling Efficient Query Plans for Modern Hardware
- Relaxed Operator Fusion for In-Memory Databases: Making Compilation, Vectorization, and Prefetching Work Together At Last
- sched_setaffinity(2) — Linux manual page
- Vertica数据库脱颖而出的15个特性
- Awesome Vertica
- Vertica数据库简介
- 超级方便的Linux自带性能分析工具!gprof介绍、安装、使用及实践
- C/C++性能测试工具—-gprof
- 关键字_restrict
- Access Path Selection in Main-Memory Optimized Data Systems: Should I Scan or Should I Probe? 知乎解读