bustub数据库
地址
https://15445.courses.cs.cmu.edu/fall2022/assignments.html
环境搭建
卡耐基梅隆数据库课程,还附带了一个实现环境,算是这门课的亮点
一款教学性质的数据库:bustub
虽然是教学性质的,不过有些 Lab 还是比较有意思,比如完整的实现 一颗B+树,这就很有挑战了
另外还有并发控制,查询执行的各种算子,基本上做完这个迷你数据库之后,对整个数据库的运行原理,应该是很清晰了。
一些信息
环境
- 我用的是
ubuntu 20.x - 编译器是
GCC 9.4.0 - 使用的是 Windows,然后装了 vs-code
- 本地装了一个虚拟机,装了 ubuntu,这样就可以远程开发了
我做的是 2022 年的课程,而最新的代码是 2023 年的,直接用最新的代码跑 2022 年的是没法弄的
很多代码,测试用例都对不上了,所以要找到 2022 年的提交,然后在对应的时间点上 打个分支,从那个分支上开始做
5个 Lab
- C++ Primer,这个不算是真正的实验,只是检查 C++ 的语法,使用什么的是否达标
- Buffer Pool Manager,需要做一个 可扩展的hash表、一个 LRU-k 缓存,以及将前两者整合起来,变成 buffer pool
- B+Tree Index,实现 B+ 树的 点查询、范围查询、插入、删除、以及并发控制
- Query Execution,实现scan、insert、delete、index-scan、agg、nested-loop-join、nested-index-join、sort、limit、topN、以及几个优化算法
- Concurrency Control,实现锁管理、死锁检测、并发的查询执行
编译命令:
|
|
buffer pool
参考了 这篇博客
Extendible Hash Table
由一个 directory 和多个 bucket 组成
- directory,存放指向 bucket 的指针,是一个数组,用于寻找 key 对应 value 所在的 bucket
- bucket,存放 value,是一个链表。一个 bucket 可以至多存放指定数量的 value
Extendible Hash Table 与 Chained Hash Table 最大的区别是,Extendible Hash 中,不同的指针可以指向同一个 bucket,而 Chained Hash 中每个指针对应一个 bucket
发生冲突时,Chained Hash 简单地将新的 value 追加到其 key 对应 bucket 链表的最后,也就是说 Chained Hash 的 bucket 没有容量上限。而 Extendible Hash 中,如果 bucket 到达容量上限,则对桶会进行一次 split 操作
假设 bucket = 2,现在已经有0、1两个值了,再插入就要 split了
- global depth++
- directory 容量翻倍
- 创建一个新的 bucket
- 重新安排指针
- 重新分配 KV 对
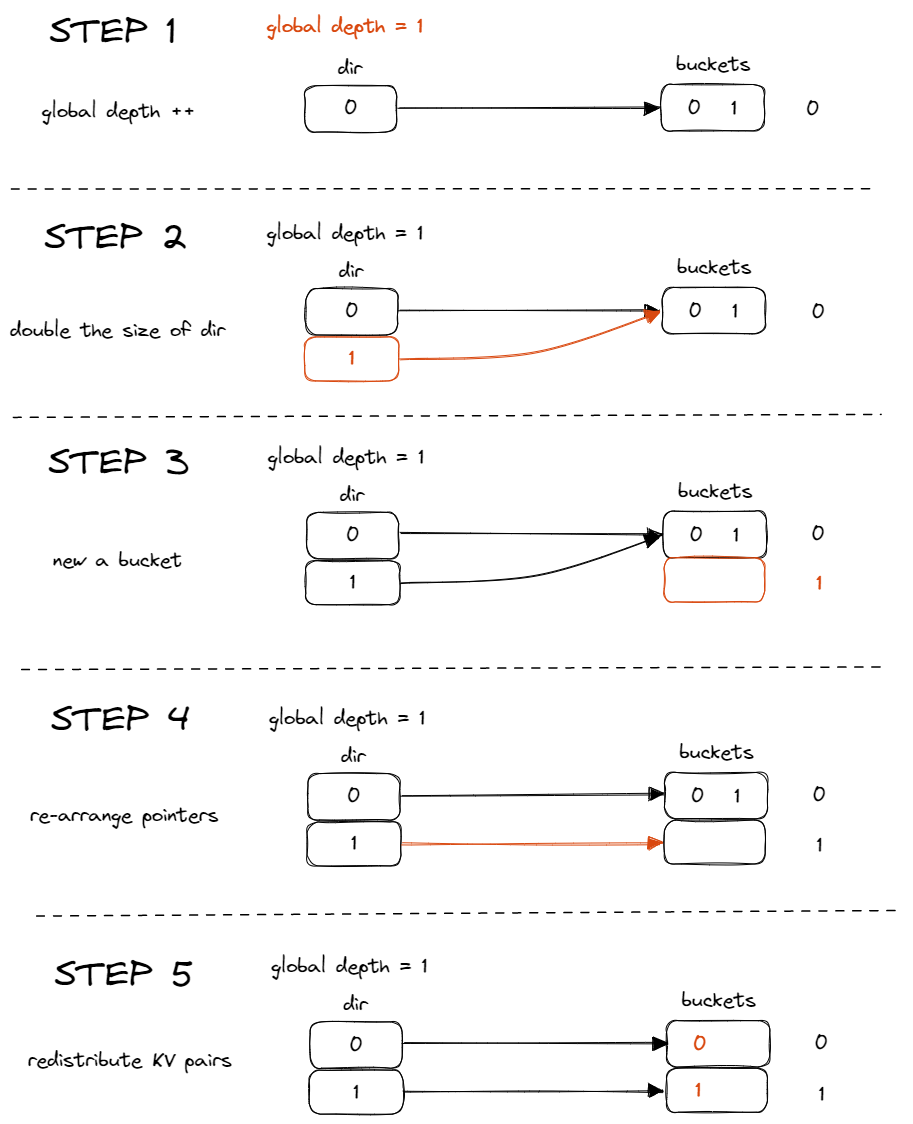
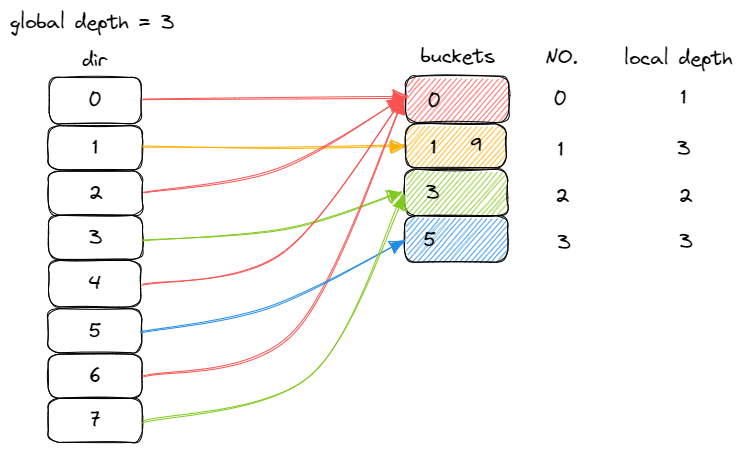
这里还需要引入一个 local的 depth,只要发生分裂,local-depth++
全局扩容时,容量翻倍,directory 中的指针,比如原先是0、1、2、3,扩容后就多了4、5、6、7
如果观察 其二进制
|
|
会发现,4、5、6、7其 低位部分,正好对应了 0、1、2、3
所以扩容时,直接将原先 directory 的指针复制一遍就行了
然后再将 value 插入对应的位置
扩容后,可能会有多个 directory指向同一个 bucket
LRU-k
- 在 LRU-K 中,我们需要记录 page 最近 K 次被引用的时间
- 假如 list 中所有 page 都被引用了大于等于 K 次,则比较最近第 K 次被引用的时间,驱逐最早的
- 假如 list 中存在引用次数少于 K 次的 page,则将这些 page 挑选出来,用普通的 LRU 来比较这些 page 第一次被引用的时间,驱逐最早的
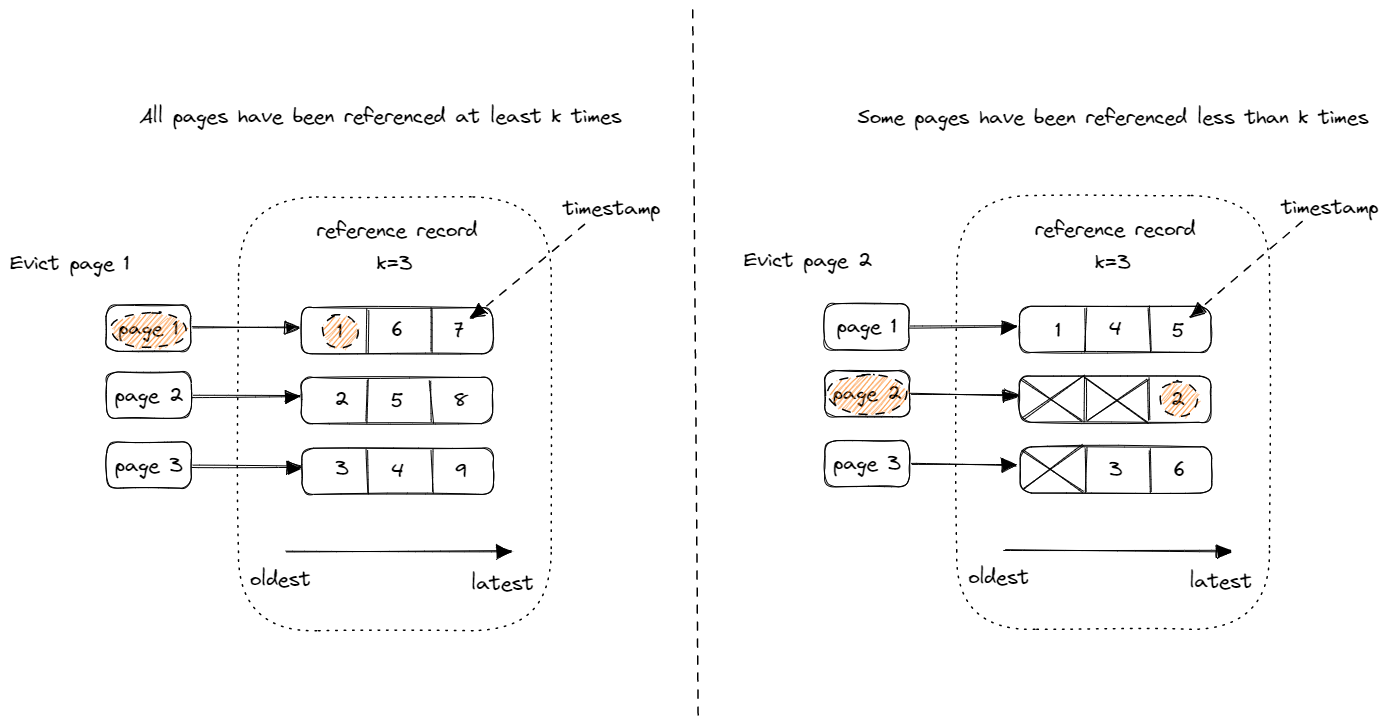
另外还需要注意一点,LRU-K Replacer 中的 page 有一个 evictable 属性,当一个 page 的 evicitable 为 false 时,上述算法跳过此 page 即可
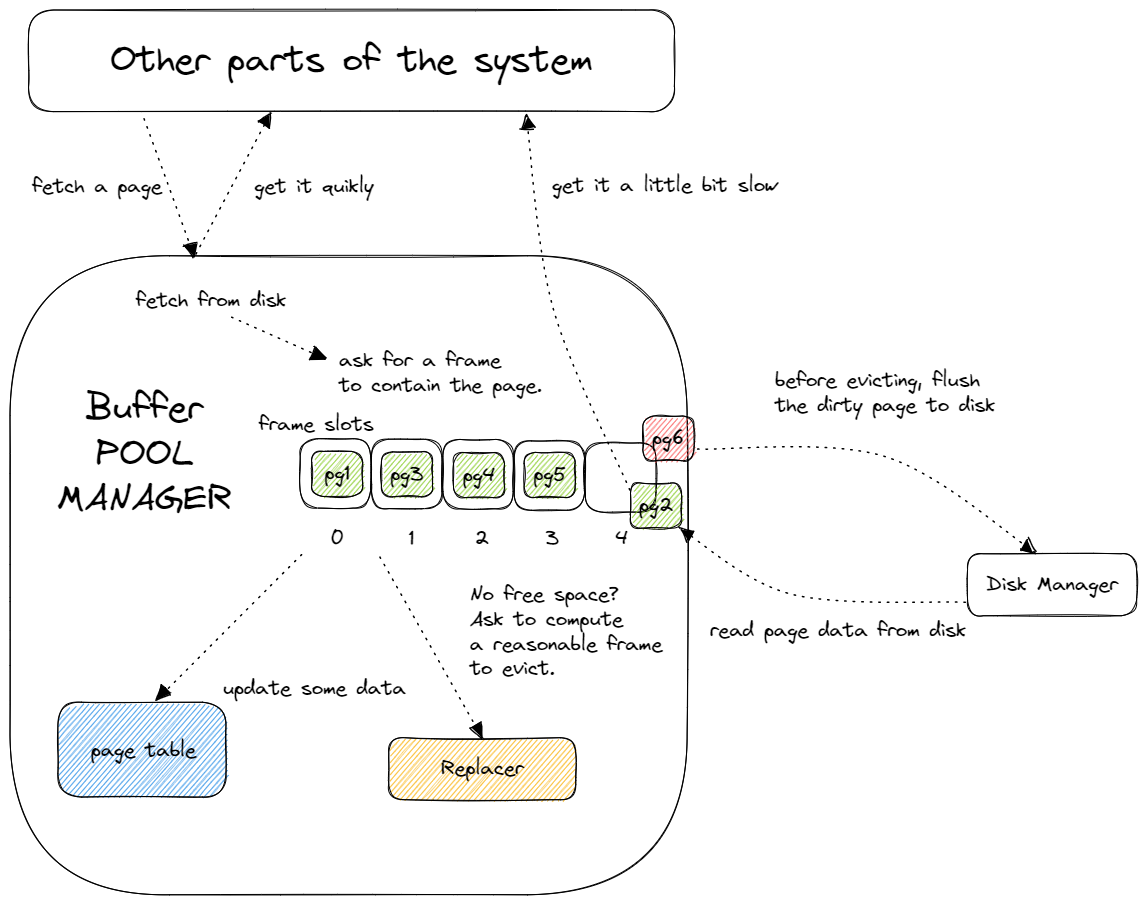
Buffer Pool Manager
几个重要的变量
- pages:buffer pool 中缓存 pages 的指针数组
- disk_manager:框架提供,可以用来读取 disk 上指定 page id 的 page 数据,或者向 disk 上给定 page id 对应的 page 里写入数据
- page_table:刚才实现的 Extendible Hash Table,用来将 page id 映射到 frame id,即 page 在 buffer pool 中的位置
- replacer:刚才实现的 LRU-K Replacer,在需要驱逐 page 腾出空间时,告诉我们应该驱逐哪个 page
- free_list:空闲的 frame 列表
NewPage
- 如果所有page都是 unevictable,返回
- 如果 buffer pool中有空闲的,创建一个空的 page在 frame 中
- 如果 buffer pool中没有空闲的 frame,但有可以驱逐的page,调用 LRU-k 的替换策略
- 获取可以驱逐的 page的frame_id,将frame中的page驱逐,并创建新的page放在此frame中
- 如果驱逐的frame是脏的,则将page写入disk,并清空frame数据;非脏页就直接清空,再删除 LRU-k中的引用
- 放置新的page后,LRU-k中的frame设置驱逐为false
整体结构如下:
B+树
task-1
这里包含几个核心类
- B+Tree Parent Page,这是父类
- B+Tree Internal Page,内部节点
- B+Tree Leaf Page,叶子节点
利用 flexible array 的特性来自动填充 page data 4KB 减掉 header 24byte 后剩余的内存。剩下的这些内存用来存放 KV 对
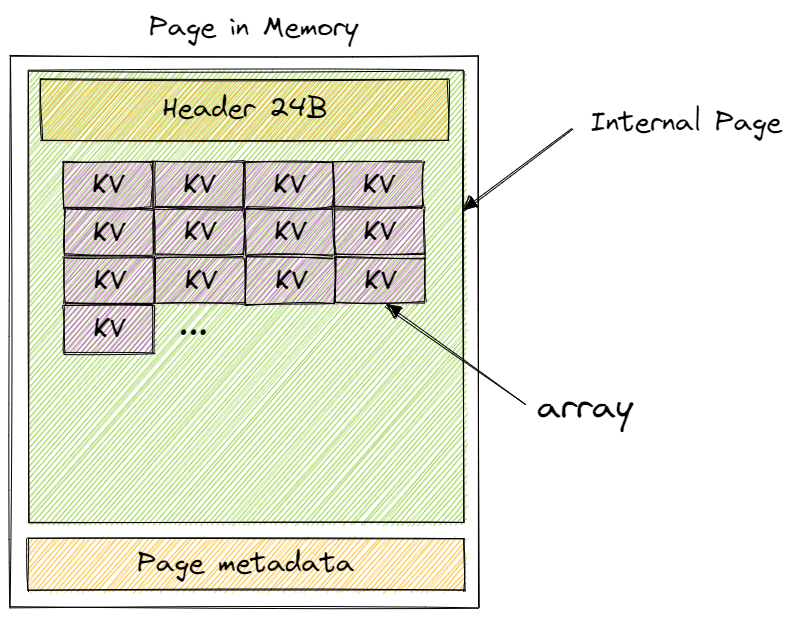
internal page 中,第一个 key,默认为空
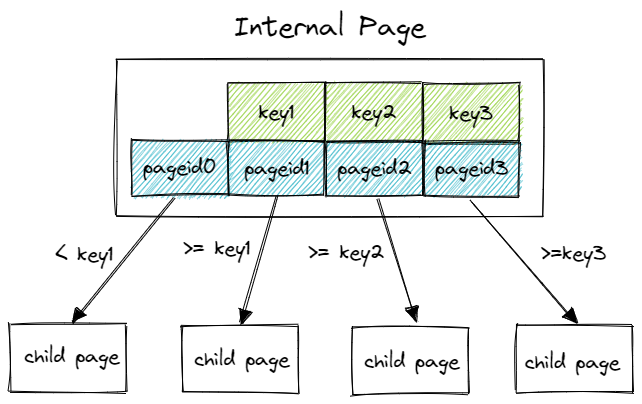
key 就是数据的key,value是 子节点的page_id
除了 第一个 key是 < key1 这种比较方式,后面的都是 >=
task-2
查找
- 这个直接递归找就行了,后面插入、删除也会复用这个功能
- 封装成一个 Findleaf 函数
- 由于叶节点数据是有序的,可以用 二分
- 获取的时候,使用 buffer pool的 fetch-page,使用完后,需要将这个 page,unpin掉
插入
- 新建一个空的page
- 将原page的一半 move 到新page中
- 更新原page 和新page的 next_page_id
- 获取 parent-page,将用于区分原page和新page的 key插入父节点中
- 更新parent-page所有子节点的父节点指针
- 由于会递归的分裂,需要字底向上不断递归执行
删除
- 找到叶子节点数据,删除
- 检查左右兄弟节点(必须是同一个父节点的),是否有空闲的,如果有则从兄弟节点偷一个
- 左边偷的时候偷最右边的,插入当前第一个(用当前key更新父节点);右边偷第一个,插入当前最后一个(用右边节点key更新父节点)
- 如果是中间节点偷,偷左边(父节点key下移到当前,左节点最右key移动到当前),偷右边(父节点key下移到右节点,右节点最左key移到当前)
- 否则跟兄弟节点合并,这里可以做个统一,做兄弟-当前合并(当前节点数据move到左节点),当前节点-右节点合并(右节点move到当前)
- 再递归的从父节点中删除key
task-3
对叶子节点做迭代
当迭代到末尾时检查当前的 next_page_id 是否为空,不空则要获取下一个page,继续迭代
由于是从上往下先获取到某个叶子节点,然后从左到右节点的,理论上会跟 插入、删除产生冲突,出现死锁
不过这块 课程说可以不用处理
task-4 锁流程
- 先锁住 parent page,
- 再锁住 child page,
- 假设 child page 是安全的,则释放 parent page 的锁
- 安全指当前 page 在当前操作下一定不会发生 split/steal/merge
- 同时,安全对不同操作的定义是不同的
- Search 时,任何节点都安全
- Insert 时,判断 max size
- Delete 时,判断 min size
- 这里需要将遍历的page都放到 deque中,如果当前节点时安全的,则一次性释放所有的page锁
查询执行
官网给出的整体架构

内置了一些 mock 表
|
|
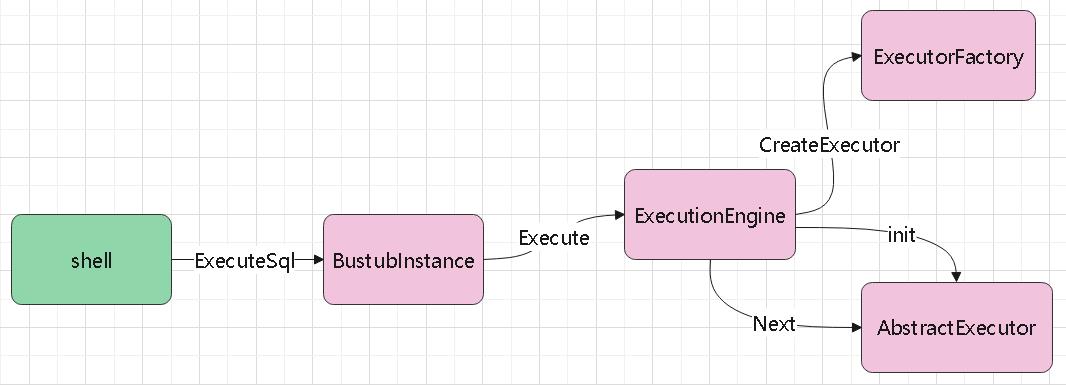
单个SQL的执行过程
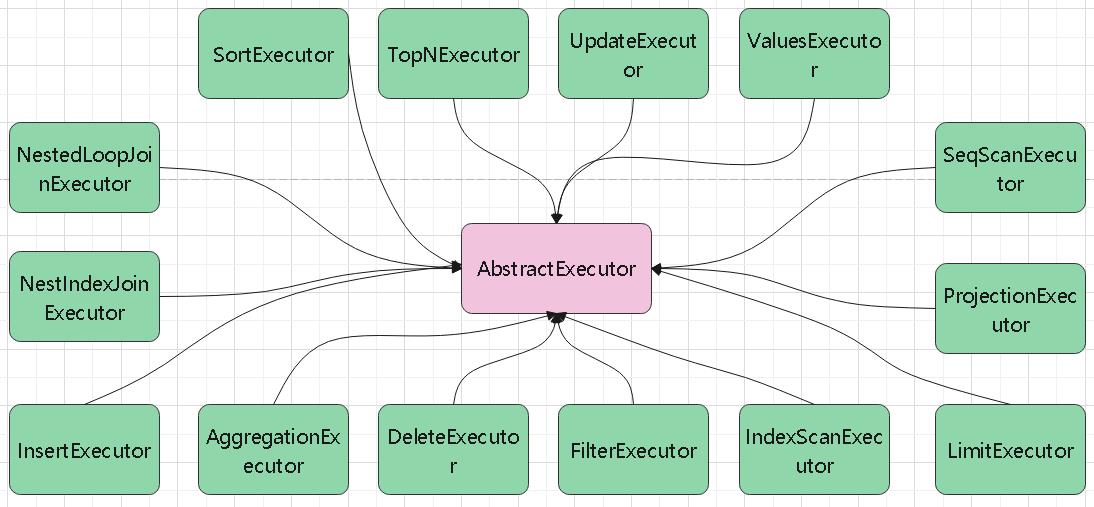
目前支持的算子:
explain
|
|
P3 支持 SQL,可以用 SQL来执行,并检查结果
|
|
seq_scan_executor
这个没有 child,就是叶子节点,直接扫描 table 就行了
insert_executor
这个有一个 子节点 是 values_executor,也就是 insert 时可以带多个 VALUES
先拿到 一个 values,然后返回,再调用 table 插入到表中
之后再更新 索引
delete_executor
这个下面会跟一个 FilterExecutor,如果有 where 条件的话
再往下就是 SeqScanExecutor,这个就是叶子节点了
所以执行过程是,先 scan然后返回,filter判断是否满足条件,满足的话返回tuple,delete算子将这个 tuple插入到表中
最后再更新 索引
index_scan_executor
下面这个 SQL 经过优化后,会变成 index scan
|
|
这个就是 扫描 B+树 索引,拿到 RID,然后去 table-heap 里面查找对应的值
aggregation_executor
对于这种SQL
|
|
- 其group by是:colA、colB
- 聚合字段是:colC、colD、colA
- 聚合规则为:max、min、count
比如有这么一张表
| – | – |
|---|---|
| a1 | x1 |
| a1 | x2 |
| a1 | x3 |
| a2 | x1 |
| a2 | y1 |
| a3 | x3 |
| a1 | y2 |
a1:x1、x2、x3
a2:x1、y1
a3:x3、y2
对于上面的SQL
- 在 init阶段,从子节点返回tuple,封装key 和value
- 以(colA、colB)作为map的key
- value是(colC、colD、colA),也是一个联合的value
- 然后将 (colA、colB)对应的value,(colC、colD、colA)做聚合处理
- value[0]累加max(colC),value[1]累加min(colD),value[2]累加count(colA)
nested_loop_join_executor
比如这个SQL,当然优化后会变成 hash-join
|
|
- 调用左子树,拿到结果,拿到 tuple,再 for 遍历右边,再拿一个tuple
- 对比两个tuple是否相等
- 如果相等,则将左表、右表的value封装成tuple返回
- 如果不等,并且join类型是 LEFT,则返回左表的value,右表对应的设置为空
- 需要注意保存 left、right的遍历位置
nested_index_join_executor
下面这个 SQL 优化后就变成这样:
|
|
- 根据查询计划,创建出 左表,以及右表的 index
- 遍历左表,获取一个 value,然后 B+树(右表的)扫描这个 value
- 如果返回的 rid不为空,就拿这个 rid 去 table-heap中查询
- 并将 左、右表返回的 value 封装为tuple返回
- 如果右表的rid返回空,join类型为LEFT,只返回左表的tuple,右表的全部设置空
sort
SQL如下
|
|
- 可以在
init的时候,将整个子节点全部加载到内存中 - 然后用
std::sort做排序,然后一个for循环处理所有的order by列表 - 在
std::sort的lambda中,按照字段顺序做 asc、desc - 在 next中,只需要遍历获取值就可以了
limit
SQL
|
|
- init的时候只需要初始化子节点
- next的时候设置一个 count,然后获取子节点再 count++
- 当 count 达到 limit的数量时,返回false
topN
比如 sort + limit 就会被优化为 topN
|
|
- init的时候直接把子节点的数据读进来,排序的方式跟 order by类似
- 根据 asc、desc做排序,需要使用
std::priority_queue,然后自定义一个排序规则 - 排序规则跟 order by的类似,priority_queue 保持住 limit个元素
- next 阶段就直接从迭代器中获取
- 为了实现 topN,还需要实现一个优化规则,当检查到 plan是 limit(做一个cast转换),并且子节点是order by(做一个cast转换)
- 就将 limit和order by 的 plan信息取出,创建出新的 topN plan,topN plan的子节点指向 order by的子节点
- 还需用递归,处理多种 limit+order by的情况
优化
Query 1: Where’s the Index?
- 优化规则,将 NLJ 转换为 HJ
- 检查当前的
plan为NLJ,并检查 谓词是 等值判断 - 将左右节点取出,转换为
HJ - hash join的执行,init 部分,将左表取出,放到 hash 表中
- next时,去probe右表的内容,检查是否匹配,hash-join的前提是必须是 等值的
- join reorder,根据
EstimatedCardinality调整顺序,不过这个函数都是 mock的数据,只能用于mock表 - NLJAsIndexJoin 的规则是左表有index,右表是table/mock-table,这里也可以优化一下,反过来也成立
Query 2: Too Many Joins!
- NLJ套NLJ,左节点必须也是NLJ,同时左节点的两个节点,以及右节点必须有一个是scan
Query 3: The Mad Data Scientist
- 列裁剪,两个project的node做合并,以上面的为准
- project套agg时,将agg中多余的express去掉
并发控制
task 1
- 表锁的申请和释放
- 行锁的申请和释放
LockTable 执行流程
- txn状态检查
- READ_UNCOMMITTED,只允许X、IX锁,并且只能在GROWING阶段
- READ_COMMITTED,允许所有的锁,只有IS、S锁允许出现在SHRINKING阶段
- REPEATABLE_READ,允许所有的锁,所有锁只能出现在GROWING阶段,不允许出现在SHRINKING阶段
- 获取锁
- 根据 oid 从table_map中找到request_queue
- 如果队列不存在 则创建一个,锁住队列,释放table_lock_map
- 检查锁升级
- 请求队列中 tid 等于当前事务id
- 不允许多个并发对相同资源升级锁
- 判断 锁更新模式的兼容性
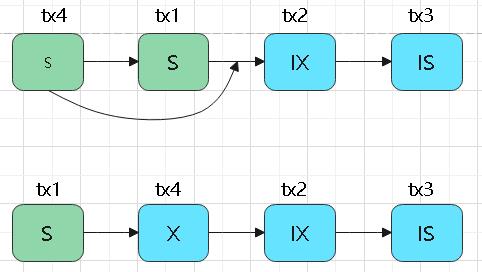
- 兼容性:IS -> [S, X, IX, SIX]、S -> [X, SIX]、IX -> [X, SIX]、SIX -> [X]
- 从原队列中删除LockRequest,创建一个新的锁升级后的LockRequest,找到第一个没有获得锁的 LockRequest,插在它前面
- 获得锁授权,即检查S、X、IS、IX、SIX的彼此兼容性,不兼容则用 std::condition_variable 等待
- 如果唤醒后发现是 aborted状态则返回(死锁检查时,某个事务会终止,醒来后需要判断)
- 否则将锁升级置空,设置granted,插入到事务记录中,并唤醒此队列上的其他线程(非X模式下)
- 锁请求入队列
- 先插入到队列尾部,之后跟锁升级情况类似
- 锁授权,兼容性检查,不满足则等待
- 满足则唤醒队列中其他线程(非X模式下),返回返回
table_lock_map_ 的结构如下:
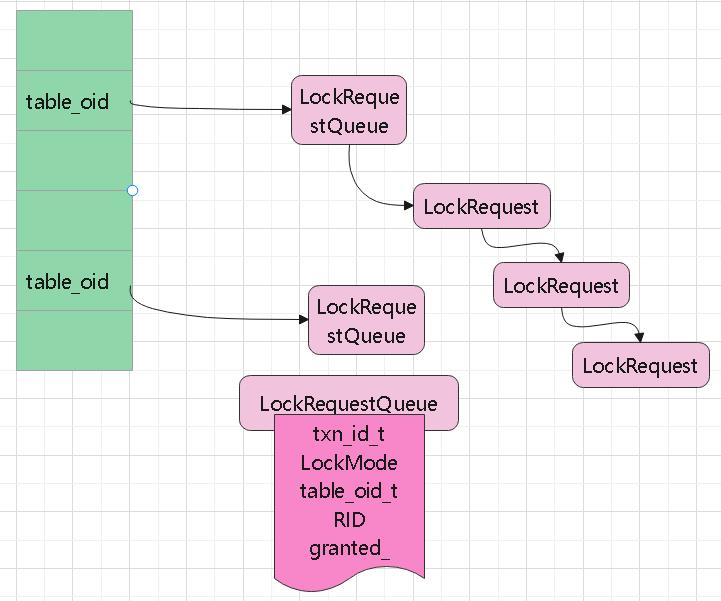
锁升级:
更新事务的加锁集合
|
|
LockRow 执行流程
总体上跟 LockTable差不多,但有些不同点
- IS、IX、SIX这几种不支持行锁
- 锁的GROWING、SHRINKING检查都是一样的
- 如果锁模式为 X,检查对应的表锁中是否存在 X、IX、SIX
- 只有跟 LockTable差不多,获取队列(为空则创建),检查锁升级,锁升级兼容性检查,
- 同上,再从队列中删除,创建新的升级锁插入到合适位置,然后锁授权检查,不兼容则wait
- 否则,插入队列,锁授权检查,不兼容wait,兼容则唤醒队列其他线程(非X模式下),并返回
UnlockTable
相关LockTable要简单很多
- 首先检查 table_lock_map_ 是否有对应的表 oid,没有则终止
- 检查事务关联的 S的row_set、X的row_set是否已经被释放,没有则终止
- 获取对应的 队列,遍历队列,如果事务是granted_ ,则从队列中删除,唤醒其他线程
- 更新事务状态,如果是 READ_UNCOMMITTED && X模式、READ_COMMITTED && X模式、 REPEATABLE_READ && (S || X 模式)
- 且当前事务非 commit、或者非 aborted,设置状态为SHRINKING
- 从事务管理的集合中删除LockRequest
- 如果队列中没找到,则抛出异常 ATTEMPTED_UNLOCK_BUT_NO_LOCK_HELD
UnlockRow的总体流程跟 UnlockTable类似
task 2
触发的入口是RunCycleDetection函数,这个函数在后台定期运行
事务1 -> 事务2 的关系,放到 waits_for_中,几个重要的变量
|
|
同时也将 事务1、事务2的 tid 保存起来
流程
- 遍历table_lock_map_,获取table_oid_t对应的队列,遍历队列
- 如果队列中的granted_为true,则假如到 granted_set中
- 否则加入到等待图中,也就是调用 AddEdge,并将事务id放到 txn_set_中
- 对于 row_lock_map_ 也按照同样逻辑走一遍
- 调用 HasCycle,判断是否有死锁,这里需要while判断
- 如果有死锁,则将这个事务终止,从waits_for_中删除,并调用 RemoveEdge,删除图中的边
- 调用table_lock_map_的cv唤醒table上的等待线程(如果有的话),同理唤醒row上的等待线程
HasCycle流程
- 遍历 txn_set_,然后调用 DFS不断检查每个事务id
- DFS中将其加入到 active_set_ 中
- 从waits_for_中找到这个事务id 指向的下一个节点集合
- 对这个集合做排序
- 下一个节点不为空,并且存在于活跃事务中,说明出现环了,返回
- 否则继续做深度遍历
- DFS遍历完没有发现环,返回 false
- 如果发现了环,则从活跃事务集合中,找到max,也就是最新的那个
- 之后RunCycleDetection中就使用这个事务id,打破循环
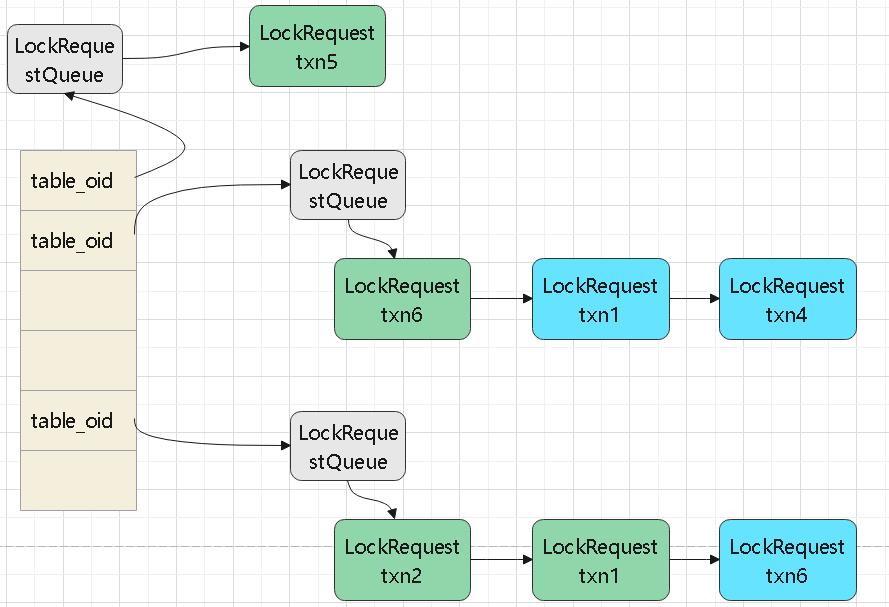
table_lock_map_ 中的队列,以及事务的依赖
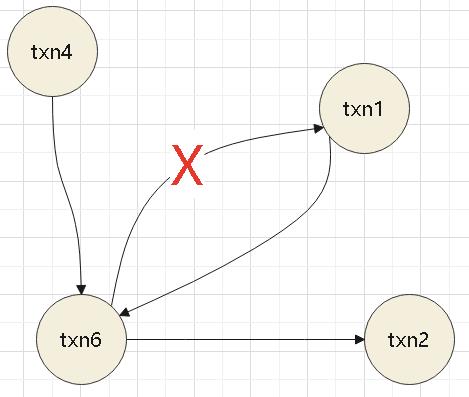
这里 txn6同时等待 t1、t2
t6同时被 t1、t4等待
所以 t6 和 t1之间出现环,t6最新所以要终止
task 3
SeqScanExecutor
- init的时候,非 READ_UNCOMMITTED模式,要锁住表,用 IS 模式
- next时,如果结束了,对于READ_COMMITTED要释放所有行所,再释放表锁,REPEATABLE_READ不用管会统一释放
- next时,非READ_UNCOMMITTED模式下,锁住行
InsertExecutor
- init时,使用 IX模式,锁住表
- next时候,获取子节点的tuple,插入table-heap中,然后执行 X模式的行所,将这个记录插入到tuple关联的所有index中
DeleteExecutor
- 跟插入基本一样,init时用 IX锁住表
- next时候拿到子节点的tuple,锁住行,删除table-heap中的行,再更新tuple关联的所有index
优化部分参考 这里