资源隔离修改配置动态加载
需求
基于资源隔离这个大功能的基础之上,增加的一个小功能
当修改 租户、资源池、资源单元时 能做到动态更新配置,不需要用户手动操作
因为在实际的场景中,用户可能也没权限,也不方便去操作 k8 集群,所以需要提供一种方式,能让用户修改完配置后,实现配置自动更新
虽然只是一个 子功能,但是比 资源隔离本身可能还要复杂,牵涉到 多个组件
- k8s
- zookeeper
- proxy,proxy-master,engine
而且需要考虑到很多异常的情况
- 如节点宕机
- 写元数据、写 ZK节点是非原子性的,如何保证冥等性,或者事务补偿
- 如何将元数据中的信息,跟 k8s 中的 pod 做快速对比
设计
总体架构
总体架构如下:
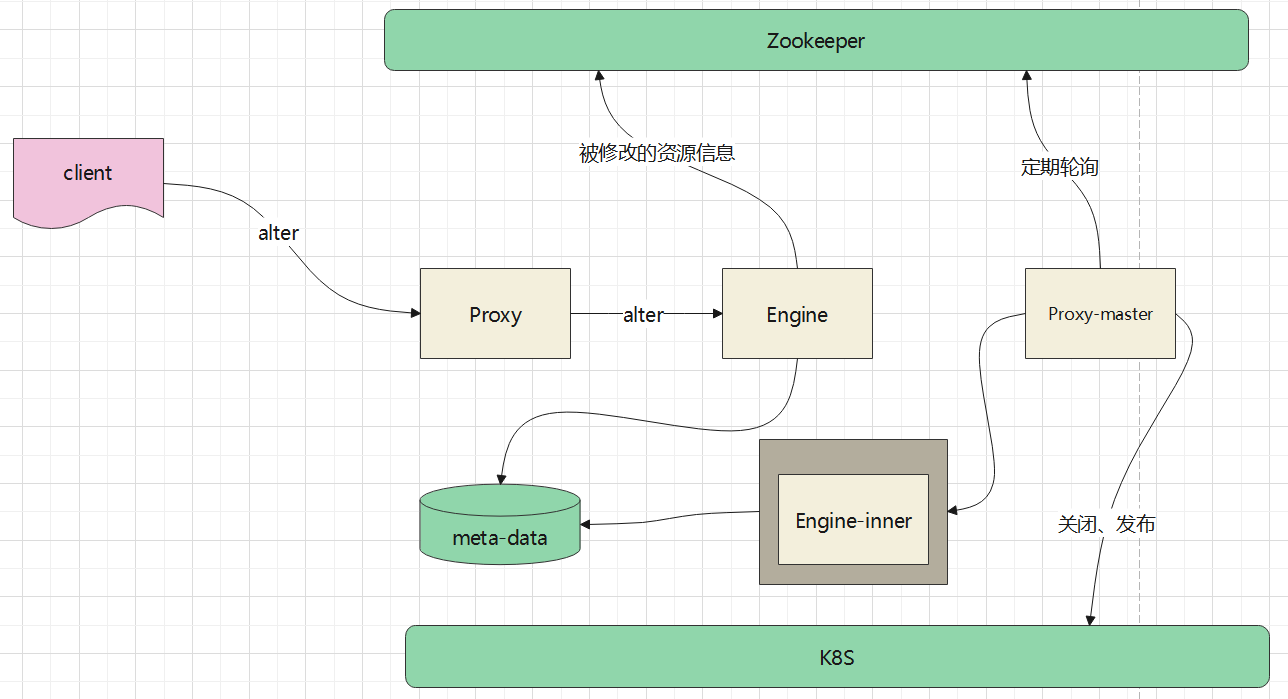
用户执行了更新资源的请求后,由 proxy交给某个engine,engine负责更新元数据库
之后,将新增的信息注册到 ZK 上,由于engine可能会宕机,所以这里注册的 ZK节点,需要是持久性的节点
proxy-master会定期轮询 ZK(也可以做到基于通知的方式更实时的处理),当发现有更新时,获取这些更新信息
比如
- ZK上的信息是更新了资源单元 uc_1 的完整信息,这个相当于是旧的信息
- master请求 engine-inner,找到 uc_1 的最新信息,并通过反查的方式,获取 资源单元关联的资源池,租户信息
- 根据 根据查询得到的 资源单元、资源池、租户,去 k8s 上查找对应的 pod
- 根据 pod 对比 元数据库中最新查到的配置
- 如果有变更则 删除对应的 pod,创建新的 pod
- 最后删除掉 ZK 路径,完成这次动态变更
新增语法
|
|
反查信息
|
|
master连接engine
由于proxy只是一个代理,没有计算能力,proxy-master也是一样的
而proxy-master在 处理动态更新的时候,需要查询元数据信息
获取一些反查信息,这时候,master 需要连接 eninge,通过engine来返回对应的信息
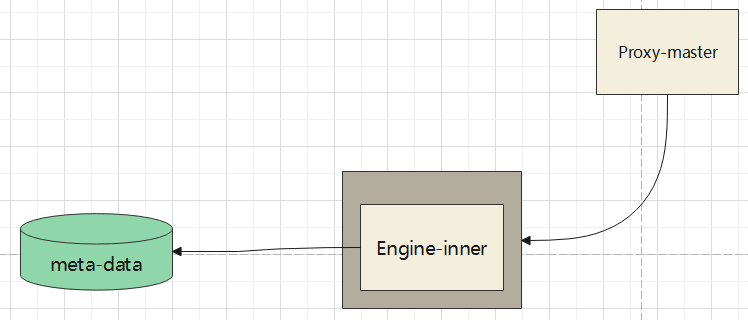
这里会出现 thrift协议,非 open-session情况下的,首次连接 engine问题
- 当客户端执行 创建 jdbc连接时,会触发到 proxy,然后proxy 会发送 open-session请求给engine
- 之后 proxy跟engine就建立了连接
- 因为是用户主动发送的请求,所以proxy是能拿到用户名/密码的
- 但这里是在非 JDBC主动请求的情况下,就没有用户名/密码了,所以需要预置一套密码
- 这种情况,只对于 simple情况下才有影响
- 如果是 SASL,kerberos,proxy -> engien,使用的是 SASL,加密协议但是无密码,所以不用校验
目前 simple 的方式还没有特殊处理
更新资源的实现细节
以更新一个 租户为例
- 假设原租户关联了 rp_1, rp_2
- rp1 管理了 uc_1,uc_2
- rp_2 关联了 uc_3
更新后
- 租户关联了 rp_1,rp_3
- rp_1 关联了uc_1,uc_2 不动
- rp_3 关联了 uc_4
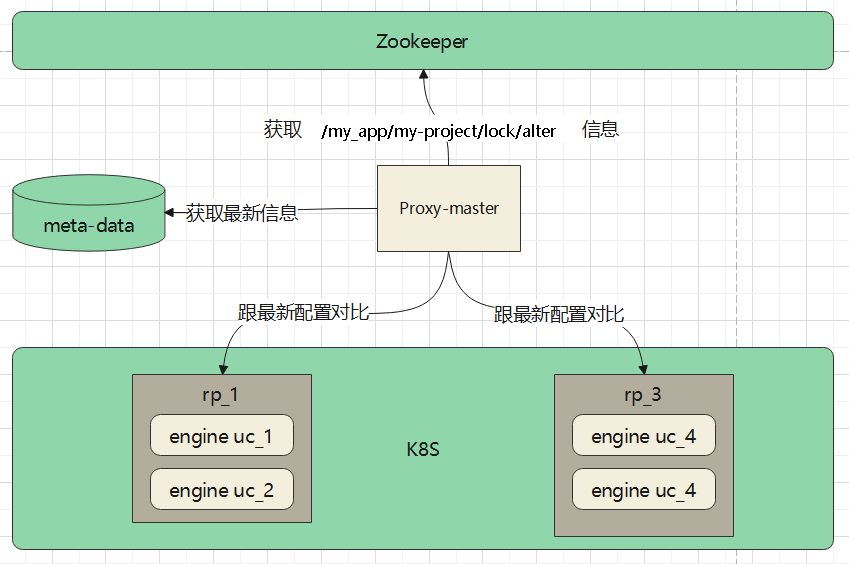
engine更新完后,将 原租户的信息挂到 ZK 上
master 定期读取 ZK 上的路径
- 从 ZK 上获取到了 t_1 信息
- 然后从数据库中获取最新的 t_1 信息
- 获取到 t_1 关联的 资源池 rp1,去 rp_1 下检查,看 rp_1 下面的 engine是否满足 uc_1,uc_2 的配置,如果缺失需要新启动
- 去rp_3 下检查,对应的 engine是否满足 uc_4 的配置,没有缺失需要启动
- 再去老的 rp_2下面检查,这时候不应该有 t_1 的的engine了,如果有需要将其关闭
发布engine的三种方式
发布engine,调用的命令是 START ENGINE t_1 rp_1 uc_1
将一个 engine 发布到指定的 资源池,也就是 k8s 的namespace 下,并根据 uc_1 的配置创建 engine
这里跟之前不同的是
- 之前发布 engine,都是 proxy发布的
- 而这次是需要执行SQL命令,所以实际发布者是 engine
- 也就是 engine,发布 engine
engine 发布 engine目前有三种方式
- 基于线程的方式,这需要将 spark.kubernetes.submission.waitAppCompletion=true,false则发不完线程退出,导致当前engien关联的executor也会退出,原因还不清楚
- 基于线程的发布,就是套用了之前的逻辑,完全不动,但是需要将上述配置开启,开启的坏处是,每次发布一个engine都会出现一个监控线程,长期下来这是不合适的
- 使用进程的发布方式,在 engine内,新启动一个进程,然后用这个进程来调用SparkSubmit 发布新的engine,这样就不会有上述问题了
- 带来的副作用是,新进程相当于一个新的JVM,也会占用额外内存,弄不好会超过 pod资源限制,可能会导致 pod 出现 OOM
- 基于 proxy-master来发布,engine 如果接受到发布的命令,则将这个命令注册到 ZK 上,然后就不管了,可以正常返回
- 之后proxy-master拿到 ZK 上的信息,去发布 engine,proxy-master发布 engine就是套用了之前的逻辑
目前使用的是第三种方式
基于pod标签对比更新
从数据库中新获取的 资源,需要跟老的,已经发布的 pod 做对比
比如,原先的 资源单元配置是:driver 1C1G,executor 2C2G,min:1,max:2,以及一堆的扩展属性
pod会将这些信息,做成标签,比如
- 记录 unit_name=uc_1
- 资源单元配置 unit_configs=1_1G_2_2G 表示 driver 1C1G,executor 2C2G
- 扩展属性unit_properties,这个比较长,不适合直接放进去,这里对扩展属性内容做了 MD5 编码
Name: my-app-aba01288bd33e1ff-driver
Namespace: my-namespace
Priority: 0
PriorityClassName: <none>
Node: 10.111.40.111/10.111.40.111
Start Time: .........
Labels: name=my-app
namespace=my-namespace
pool_name=rp_2
spark-app-name=my-app
spark-app-selector=spark-8032fb14ef9148cb978de4031f064fe5
spark-role=driver
spark-version=3.3.3
tenant_name=t_1
unit_configs=1_2G_2_2G
unit_name=uc_3
unit_properties=99914b932bd37a50b983c5e7c90ae93b
通过这种方式,就可以使用 租户名称的标签、资源池名称标签、资源单元名称,然后就可以定位到具体的 engine 了
同时因为有标签过滤,查询的性能也会很快
如果 master 通过 标签对比,发现 已有的 pod 跟数据库最新的配置是一样的,说明 这个pod已经被启动了,可能是之前 master宕机了,那么直接忽略就可以了
如果发现有缺失的,比如需要 3个这样的engine,实际只发现了 2个,那么就将剩余的 1个 再创建起来就可以了
异常处理
master是通过分布式锁确定的,所以proxy-master只会有一个
如果一个master宕机了,那么就会出现选举,如果配置了两个proxy,剩下的那个proxy就会变成master
如果只有一个proxy,等k8s自动启动了新 proxy后,这个proxy会继续作为master
master会定期遍历 ZK 路径下 /my-app/ny-project/lock/alter 这样的节点
这个节点只有一个,而且是持久节点,除非主动删除不会自己消失
master 异常处理
- 当 master 根据 alter节点的信息,发现要创建 3个 pod,但是创建完 1个后,就宕机了
- 新master接管后继续获取到这个 alter节点,然后通过元数据库的最新信息,和 pod标签对比,发现需要再创建 2个pod,于是继续处理
- 当处理完剩下的 2个pod后,新master又宕机了
- 第二个 master接管后,拿到 alter节点的信息,然后对比 最新数据和 pod 的标签,发现都一样,于是什么都不做
- 第二个master 删除 ZK 上的 alter 节点,本次动态更新结束
engine修改资源异常处理
- 由于只有一个 alter节点,当 修改了一个资源后,再次修改时,创建对应的 alter节点会失败,只有等master处理完后才能继续修改
- engine 先将 alter的信息注册到 ZK 上,然后再更新元数据库,假设更新元数据之前就宕机了
- master 获取到了 alter节点信息,再获取最新的元数据信息(没有修改过),然后跟 pod做对比
- 发现没有任何修改,于是删除这个 alter节点,本次动态更新结束(相当于什么都没更新)
优雅重启
普通重启就是 先启动一个pod,然后再立马删除一个 pod
这种做法不太优雅,会导致之前的任务处理失败
更优雅的方式
- 将 engine 对应的 ZK 节点删除
- 删除 ZK 节点后,因为新请求会首先检查 ZK,现在没有了,所以新请求就不会转发给这个engine了
- 当前的 engine监听自己的 ZK 节点,当发生变化时,如被删除,则触发一个监听检查
- 这个监听检查会定期检查当前是否还有 运行的任务,如果有继续等待
- 如果没有,就将自己杀掉