设计
总体概述
首先要增加几张表
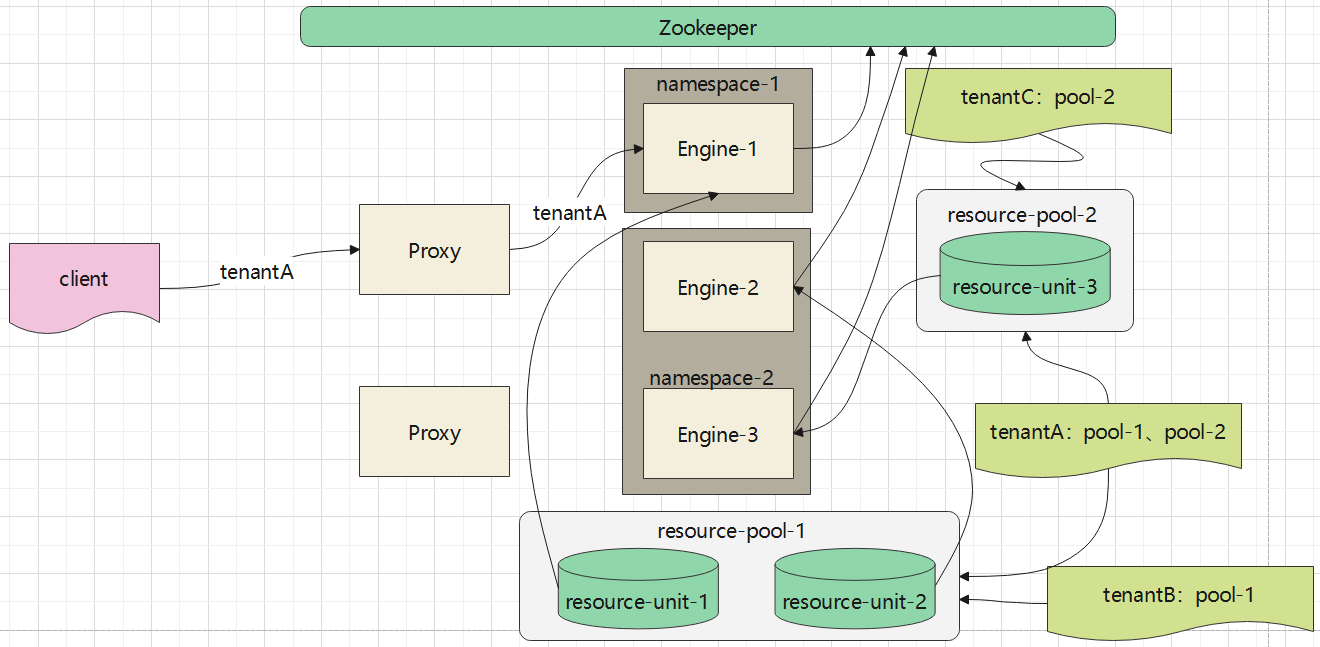
当一个请求交给proxy后
- proxy 会拿到当前请求的用户信息,然后去 租户资源、资源池表中,找到合适的资源池,也就是k8s的namespace
- 之后,再选择一个合适的 engine
- 如果没有合适的engine,或者 namespace下是空的,则创建一个对应的 engine
- 这个 engine的配置信息就是从资源池表中获取的
每个 proxy都是无状态的,请求会随机的落到一台 proxy上
proxy会从 Zookeeper上找到一堆 engine列表
proxy根据 用户信息,将请求转发到 对应的 namespace下
这个namespace下可能有多个engine,用户可以配置一些选择策略,选择合适的engine
目前没有用户端的选择策略,根据负载选择一个合适的engine
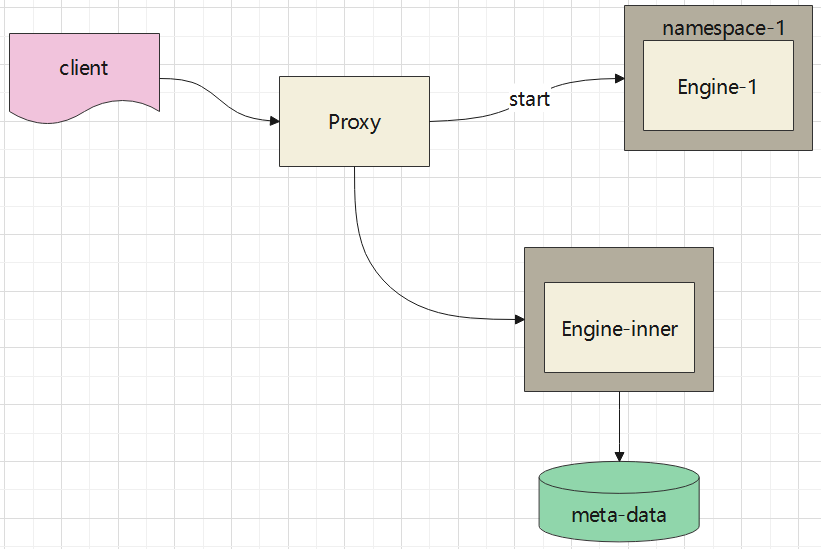
proxy处理时候的特殊情况
proxy可以拿到所有 namespace,所有engine信息
然后根据 租户的信息,选择一个具体的 engine
表中也定义了 租户->资源的关系,而proxy只是转发层,但此时需要读取数据库,所以就矛盾了
目前有这么几种方案
- 内部engine
- proxy+local-session
- 将元数据做成独立服务
内部engine
- 每个engine是根据 表中的配置来创建的
- 但是这种特殊场景下,是请求先到某个engine上,然后engine去元数据库中查配置,所以这种engine的配置就需要提前定义了
- 根据application配置中的定义,创建对应的engine
这种设计的优缺点
- 好处是:设计相当对简单,比较清晰,如果想增加高可用,可以配置2套内部engine
- 坏处是:请求多走了一层、另外内部engine也需要一点点资源,会造成一点点浪费
proxy+local-session
- master-proxy单独起一个local-spark-session,用来读取元数据表
- 读取到后元数据后,对外提供 API,其他普通proxy读取master的API,获取具体内存
这种设计的优缺点
- 好处是:不怎么占用资源
- 坏处是:对于普通proxy还是会多走一层、如果master-proxy挂了,会选主然后创建spark-session,会有一段时间请求不可用
- master和内部的engine(local-session)是强绑定的,而 内部engine就不存在这种问题
元数据独立服务
- 将元数据做成独立的服务,所有的应用都去请求这个元数据服务
- 元数据服务可以是单个engine(local-session),也可以是用engine+executor组合
这种设计的优缺点
- 好处是:结构上比较清晰
- 坏处是:部署复杂度增加很多、每个请求都需要多走一层、浪费了一些资源
对比上述三种方案
- 都会多走一层,所以多走一层是不可避免的,如果加上缓存,差不多就是一次网络I/O时间,大概能控制到10ms以内
- 独立元数据会造成部署复杂度增加,proxy+local-session会有单节问题,相对来说内部engine更好一些
Zookeeper路径
之前的是这样的:
1
|
/my_app/my_project/engine/172.16.10.98
|
现在变为:
1
2
3
4
|
/my_app/my_project/engine/namespace-1/172.16.10.1
/my_app/my_project/engine/namespace-1/172.16.10.2
/my_app/my_project/engine/namespace-2/172.16.10.11
/my_app/my_project/engine/namespace-2/172.16.10.12
|
session 路径
1
2
|
/my_app/my_project/sessin/tenant-1
/my_app/my_project/sessin/tenant-2
|
内容为:
1
2
3
4
5
6
|
{
"pool-1":"engine-ip",
"pool-2":"engine-ip",
"选择策略":"none",
"session类型"
}
|
租户session
将用户的session类型保存到zookeeper上
比如:
1
2
3
|
/my_app/junge-ha/session/tenant-1
/my_app/junge-ha/session/tenant-2
/my_app/junge-ha/session/tenant-3
|
每个 znode 路径表示一个租户信息
内容可以指定为session的类型
当前支持的类型:
- 一次性,请求来了创建一个engine,执行完后删除此engine(需要考虑SQL失败后engine销毁问题)
- 租户级别,一个租户的多个请求共享一个engine(默认)
- 应用级别,一个应用内的多个租户共享一个engine
kyuubi的session是这么定义的
- 单连接的,一个连接一个session,连接执行结束引擎结束,同一个用户的多个连接之间不共享
- 用户级别,一个用户的多个请求可以共享一个引擎
- 组级别, 一个组内的多个用户可以共享一个引擎
- server,全局共享级别
总体来说跟 kyuubi 比较像
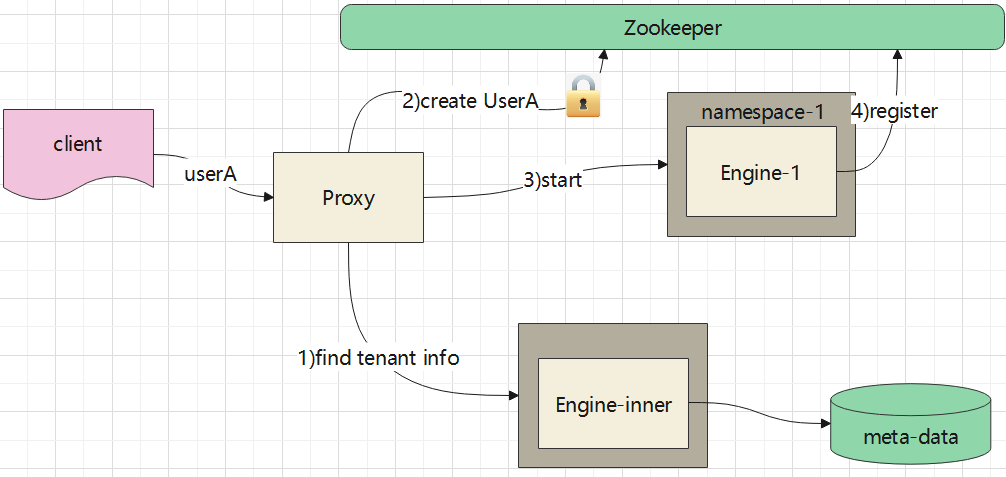
单连接session
执行过程如下:
- 当请求落到某个proxy时,proxy会首先去 内部engine查找这个 用户的资源信息
- 根据用户信息,去Zookeeper上查找对应的节点,如果是一次性的,会注册一个节点(分布式锁)
- 根据对应的资源信息,去启动engine(将engine分配到某个namespace下,并分配指定的资源)
- engine将自身注册到Zookeeper上
这里还有一些细节没有画出来,比如当 engine执行完返回后,server突然挂掉了,engine的回收问题
engine自身有一个session计数,当计数为0, 并且超时后,会将自己杀掉
这样proxy就不用管engine销毁问题了
这里可以做个优化,proxy不需要再去 zookeeper上创建 engine信息了,反正都是一次性的
proxy把必要的信息,通过 ENV 方式传递过去就可以了,之后engine自己注册到zookeeper上
等请求执行完后,自己销毁
用户级别session
跟单连接方式类似
- 请求落到某个proxy,proxy去内部engine查询这个用户的资源信息
- proxy去zookeeper上查找是否有对应的engine信息,没有就创建一个
- 根据获取到的engine信息,去连接对应的engine,发出请求
- 第二次来请求时,继续从zookeeper上获取信息,此时engine是启动的(如果engine那边没有超时自己销毁),就重用这个engine
资源池级别session
跟用户级别类似
- 请求落到某个proxy上,proxy去内部engine查询这个用户的资源信息
- proxy去zookeeper上查找,找不到就创建engine
- 连接engine,执行请求
- 后面的请求可以继续复用这个engine
三种方式的执行过程如下,创建engine时,需要有分布式锁
资源选择
proxy 拿到 用户资源表后,根据预定义的 选择策略,从 多个资源池中选择一个
对应的,从多个资源池中,选择一个资源单元,并创建若干个资源单元
目前还没想好具体的选择策略,可以简单一点
- 多个资源池的话,就随机、或者按照权重固定分配一个
- 多个资源单元的话,就按照负载选择一个
proxy是一直存在的,除非用户手动选择关闭,或者扩缩容
engine会根据超时时间自动关闭
engine也没有master,都是对等的engine,如果要维持 最大、最小数量,也可以用分布式锁实现
多个engine抢锁,然后统计出当前engine数量,大于 min,那么就将自己销毁,后面engine抢到锁之后继续判断
直到engine数量等于 min
如果 engine数量为 min时,可能会宕机挂掉一些,此时就无法创建了
等待下次proxy访问时,如果发现数量不满足,就继续创建 engine
事务问题
假设有一个用户A,这个用户相关的信息会出现在至少这些表中:
当删除用户 A后,要将上述三张表中的 A用户这条记录全部删掉
这是一个事务操作
但是目前 delta-lake 还不支持多表事务,所有同时删除 三个表的某个数据时,可能会存在事务不一致的问题
目前想到的解决办法是
- 以一个表为准,比如用户基本表
- 当这个基础表的数据是可以保证事务的
- 基础表的数据如果删除后,出现宕机了,那么后面需要有定时任务负责清理其他表数据
细节补充
1、预启动问题
2、engine的session计数问题
3、创建engine后的k8s监听线程
4、内嵌Zookeeper
预启动
- 需要一个master
- 定期扫描 用户资源表,然后创建出对应的engine
- 创建过程也是需要分布式锁,这个过程跟普通proxy创建engine是类似的
engine的计数问题
- jdbc请求每来一个,就++, 每次结束就–
- 同理,API请求也需要记录
k8s的监听线程
- proxy每次往 k8s上提交engine时候,就会创建一个监听线程
- proxy可能会有很多这种线程,考虑将这种线程去掉
内嵌Zookeeper
来自Kyuubi社区的回答
在写设计文档时,发现一些细节无法自圆其说,于是翻看了Kyuubi的代码,还找到了Kyuubi的社区群,咨询了一些问题
- 问题:session为单连接的情况下,server启动了一个engine,之后engine执行完返回了,此时server突然挂了,怎么回收这个engine呢
- 回答:engine 有 session 计数,当 session 为 0 后,经过 idle timeout 会自杀
- 问题:如果设置了用户级别session,在业务量比较低的时段,engine能自动回收吗
- 问题:第一次请求时需要先创建engine,会有等待时间,有配置能支持预启动engine吗
- 问题:如果某个用户关联了多个engine,那么server是根据什么策略将请求落到 某个具体engine上的
- 问题:kyuubi的server可以启动多个,这些server之间是对等的吗,还是有一个server-master?
- 问题:请求落到kuyybi的server层后,如果没有合适的engine,则会启动一个engine,如果每次请求落到不同的server上,server发现都不满足条件,需要启动engine,这样的话每个server都可以启动engine,是不会就乱了,这块是怎么管理的呢?
- 回答:创建 engine 时,会在 zk 上加个分布式锁
语法
概览
新增三张表,都在 information_schema库下面
三个表为:
三个表的关系:
资源单元
资源单元可以理解为 一个spark集群,定义了 driver的cpu和内存配置,executor的cpu和内存配置,以及executor数量
资源单元是一个静态配置,告诉 用户、管理员,现在有了这么一个 大小的集群,后面如果有请求的话,就按照这个配置来,启动对应配置、对应大小的集群
1
2
3
4
5
6
7
8
9
10
|
create table resources_unit(
string name, -- 资源单元名称
string driver_cores, -- driver的 CPU 核数
string driver_memory, -- driver的 内存数量
string executor_cores. -- executor的 CPU核数
string executor_memory, -- executor的 内存数量
string executor_min, -- executor最小数量
string executor_max, -- executor最大数量
string properties -- 扩展属性
)
|
| name |
driver_cores |
driver_memory |
executor_cores |
executor_memory |
executor_min |
executor_max |
properties |
| 资源单元名称 |
driver的CPU核数 |
driver的内存数量 |
executor的CPU核数 |
executor的内存数量 |
executor最小数量 |
executor最大数量 |
扩展属性 |
创建语法
扩展属性 with properties 是可选的
1
2
3
4
5
6
|
CREATE RESOURCE UNIT uc_1 DRIVER_CORES 1 DRIVER_MEMORY '2G' EXECUTOR_CORES 2 EXECUTOR_MEMORY '2G' EXECUTOR_MIN 1 EXECUTOR_MAX 10
WITH PROPERTIES (
'a1' = 'xxx1',
'a2' = 'xxx2',
'hello' = 'test'
);
|

创建支持 IF NOT EXIST,当目标资源存在时,会忽略 不会报错
1
|
CREATE RESOURCE UNIT IF NOT EXIST uc_1 DRIVER_CORES 1 DRIVER_MEMORY '2G' EXECUTOR_CORES 2 EXECUTOR_MEMORY '2G' EXECUTOR_MIN 1 EXECUTOR_MAX 10;
|
逗号是可选的,可以加也可以不加
1
2
3
4
5
6
|
CREATE RESOURCE UNIT uc_1 DRIVER_CORES 1, DRIVER_MEMORY '2G', EXECUTOR_CORES 2, EXECUTOR_MEMORY '2G', EXECUTOR_MIN 1, EXECUTOR_MAX 10
WITH PROPERTIES (
'a1' = 'xxx1',
'a2' = 'xxx2',
'hello' = 'test'
);
|
修改语法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
ALTER RESOURCE UNIT uc_1 DRIVER_CORES 1 DRIVER_MEMORY '2G' EXECUTOR_CORES 2 EXECUTOR_MEMORY '2G' EXECUTOR_MIN 1 EXECUTOR_MAX 10
WITH PROPERTIES (
'a1' = 'xxx1',
'a2' = 'xxx2',
'hello' = 'test'
);
# 可以设置其中一个参数
ALTER RESOURCE UNIT uc_1 DRIVER_CORES 1
# 也可以设置多个
ALTER RESOURCE UNIT uc_1 DRIVER_CORES 1 EXECUTOR_CORES 2
# 可以只设置扩展属性
ALTER RESOURCE UNIT uc_1
WITH PROPERTIES (
'a1' = 'xxx1',
'a2' = 'xxx2',
'hello' = 'test'
);
|
逗号是可选的
1
2
3
4
5
6
|
ALTER RESOURCE UNIT uc_1, DRIVER_CORES 1, DRIVER_MEMORY '2G', EXECUTOR_CORES 2, EXECUTOR_MEMORY '2G' ,EXECUTOR_MIN 1, EXECUTOR_MAX 10
WITH PROPERTIES (
'a1' = 'xxx1',
'a2' = 'xxx2',
'hello' = 'test'
);
|
删除语法
1
|
REMOVE RESOURCE UNIT uc_1
|
查询语法
1
2
|
SHOW RESOURCE UNIT uc_1;
SHOW RESOURCE UNIT -- 查询全部
|
t_1 是标识符,不需要带 ’ 引号
DRIVER_CPU、DRIVER_MEMORY、EXECUTOR_CPU、EXECUTOR_MEMORY、EXECUTOR_MIN、EXECUTOR_MAX
创建时,这6个值都是必填的,顺序可以任意
修改时,这个6个参数可以选择修改的其中 任意一个或者多个,顺序可以任意
其中 CPU的值范围是 [1, 2147483647]
内存是字符串,必须是整数开头,整数范围是 [1, 2147483647],必须以 ‘G’、‘g’、‘M’、’m’ 结尾
最大、最小数量必须是整数,范围是 [1, 2147483647]
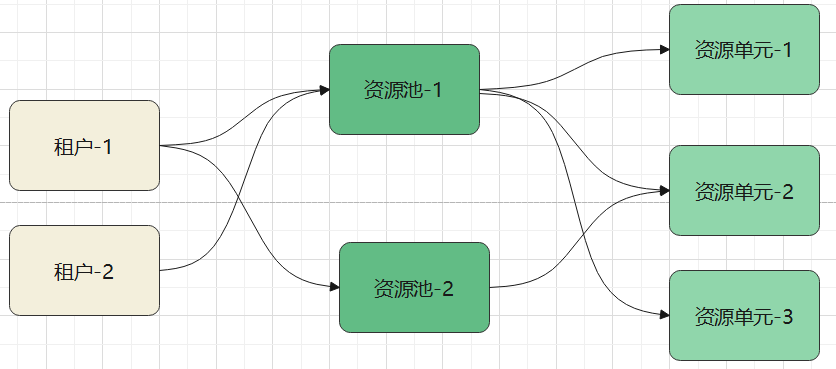
资源池
资源池映射到 k8s中的一个namespace
其中包含了若干个 spark小集群,每个小集群的具体配置、节点数量,是定义在资源单元中的
资源池中的 params 参数,包含了三个参数
- 资源单元名称,也就是使用哪个预定义的 小集群
- min, 也就是要启动 最少 个这样的小集群
- max, 也就是 最多 启动多少个这样的小集群
1
2
3
4
5
6
|
create table resources_pool(
string name, -- 资源池名称
string namespace, -- 对应的 k8s namespace
string params, -- 资源单元参数列表
string properties --扩展属性,先留着为 空字符,待以后扩展
)
|
| name |
namespace_name |
params |
properties |
| 资源池名称 |
对应的K8S的namespace名称 |
关联的资源单元参数列表 |
扩展属性,先留着为空 |
params 内容:
{
"unitName": "uc_1",
"min": "1",
"max": "10"
},
{
"unitName": "uc_2",
"min": "2",
"max": "3"
},
{
"unitName": "uc_3",
"min": "1",
"max": "2"
}
]
创建语法
1
2
3
4
5
6
7
|
CREATE RESOURCE POOL rp_1 'namespace_1' (UNIT 'uc_1' UNIT_MAX 10 UNIT_MIN 1),
(UNIT 'uc_2' UNIT_MIN 2 UNIT_MAX 3), (UNIT 'uc_3' UNIT_MAX 2 UNIT_MIN 1)
WITH PROPERTIES (
'a1' = 'xxx1',
'a2' = 'xxx2',
'hello' = 'test'
);
|

创建支持IF NOT EXIST语法,当目标资源存在时,忽略,不会报错
1
2
|
CREATE RESOURCE POOL IF NOT EXIST rp_1 'namespace_1' (UNIT 'uc_1' UNIT_MAX 10 UNIT_MIN 1),
(UNIT 'uc_2' UNIT_MIN 2 UNIT_MAX 3), (UNIT 'uc_3' UNIT_MAX 2 UNIT_MIN 1) ;
|
逗号是可选的
1
2
3
4
5
6
7
|
CREATE RESOURCE POOL rp_1, 'namespace_1', (UNIT 'uc_1', UNIT_MAX 10, UNIT_MIN 1),
(UNIT 'uc_2', UNIT_MIN 2, UNIT_MAX 3), (UNIT 'uc_3', UNIT_MAX 2 UNIT_MIN 1) ,
WITH PROPERTIES (
'a1' = 'xxx1',
'a2' = 'xxx2',
'hello' = 'test'
);
|
更新语法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
ALTER RESOURCE POOL rp_1 'namespace_2' (REMOVE UNIT 'uc_1'),
(ADD UNIT 'uc_12', UNIT_MIN 2, UNIT_MAX 3)
WITH PROPERTIES (
'a1' = 'xxx1',
'a2' = 'xxx2',
'hello' = 'test'
);
# 可以只更新 namespace
ALTER RESOURCE POOL rp_1 'namespace_2';
# 可以只更新资源单元部分
ALTER RESOURCE POOL rp_1 (REMOVE UNIT 'uc_1'),
(ADD UNIT 'uc_12', UNIT_MIN 2, UNIT_MAX 3)
# 可以只更新扩展属性
ALTER RESOURCE POOL rp_1
WITH PROPERTIES (
'a1' = 'xxx1',
'a2' = 'xxx2',
'hello' = 'test'
);
|
删除语法
1
|
REMOVE RESOURCE POOL rp_1
|
查询语法
1
2
|
SHOW RESOURCE POOL rp_1
SHOW RESOURCE POOL --查询全部
|
创建、更新中的 (UNIT ‘uc_1’ UNIT_MAX 10 UNIT_MIN 1) 可以有多个
UNIT ‘uc_1’ 表示之前创建好的资源单元名称,这个参数必须先开头
UNIT_MAX 表示最大资源单元数量,UNIT_MIN 表示最小资源单元数量,这两个参数顺序任意
创建、修改资源池时,关联的资源单元必须存在
逗号是可选的
1
2
3
4
5
6
7
|
ALTER RESOURCE POOL rp_1, 'namespace_2', (REMOVE UNIT 'uc_1'),
(ADD UNIT 'uc_12', UNIT_MIN 2, UNIT_MAX 3),
WITH PROPERTIES (
'a1' = 'xxx1',
'a2' = 'xxx2',
'hello' = 'test'
);
|
租户
租户的session类型:
- once_session,一次性session,没来一个请求,就创建一个对应的集群,对应ETL任务
- user_session,一个租户内的多个请求,公用这个session
- global_session,多个租户公用一个session
1
2
3
4
5
6
7
|
create table tenant_info(
string name, -- 租户名称
string resources, -- 对应的 资源池名称列表
string session_type, -- session类型,枚举类型:一次性、会话级别、全局共享
string strategy, -- 选择策略,选择一个具体的资源池,默认为随机选择(如果关联了多个资源池)
string properties -- 自定义租户的一些扩展属性,如不同租户有不同的root_path,可以定义在这里
)
|
| name |
resource |
session_typ |
strategy |
properties |
| 租户名称 |
关联的资源池名称列表 |
session类型 |
选择策略 |
扩展属性 |
创建语法
1
2
3
4
5
6
|
CREATE RESOURCE TENANT t_1 (POOL 'rp_1'), (POOL 'rp_2') TYPE 'user_session' STRATEGY 'my strategy'
WITH PROPERTIES (
'a1' = 'xxx1',
'a2' = 'xxx2',
'hello' = 'test'
);
|

创建语法支持IF NOT EXIST,当目标资源存在时,会忽略不会报错
1
|
CREATE RESOURCE TENANT IF NOT EXIST t_1 (POOL 'rp_1'), (POOL 'rp_2') TYPE 'user_session' STRATEGY 'my strategy';
|
逗号是可选的
1
2
3
4
5
6
|
CREATE RESOURCE TENANT t_1, (POOL 'rp_1'), (POOL 'rp_2'), TYPE 'user_session' ,STRATEGY 'my strategy',
WITH PROPERTIES (
'a1' = 'xxx1',
'a2' = 'xxx2',
'hello' = 'test'
);
|
修改语法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
ALTER RESOURCE TENANT t_1 (ADD POOL 'rp_1') TYPE 'global_session' STRATEGY 'my strategy'
WITH PROPERTIES (
'a1' = 'xxx1',
'a2' = 'xxx2',
'hello' = 'test'
);
# 可以只更新资源池部分
ALTER RESOURCE TENANT t_1 (ADD POOL 'rp_1'),(REMOVE POOL 'rp_2');
# 可以只更新session类型、策略部分
ALTER RESOURCE TENANT t_1 TYPE 'global_session';
ALTER RESOURCE TENANT t_1 STRATEGY 'my strategy'
# 可以只更新扩展属性部分
ALTER RESOURCE TENANT t_1
WITH PROPERTIES (
'a1' = 'xxx1',
'a2' = 'xxx2',
'hello' = 'test'
);
|
逗号是可选的
1
2
3
4
5
6
|
ALTER RESOURCE TENANT t_1, (ADD POOL 'rp_1') ,TYPE 'global_session', STRATEGY 'my strategy',
WITH PROPERTIES (
'a1' = 'xxx1',
'a2' = 'xxx2',
'hello' = 'test'
);
|
删除语法
1
|
REMOVE RESOURCE TENANT t_1
|
查询语法
1
2
|
SHOW RESOURCE TENANT t_1
SHOW RESOURCE TENANT --查询全部
|
t_1 是标识符,不能写成 ’t_1’
创建、更新时,对应的 资源池名称必须存在
session策略,选择策略 的内容目前不做校验
将租户关联的资源池、资源单元信息展示出来
1
|
SHOW RESOURCE TENANT t_1 WITH POOL AND UNIT
|
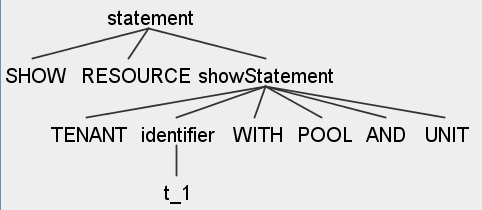
将租户关联的资源池 信息展示出来
1
|
SHOW RESOURCE TENANT t_1 WITH POOL
|
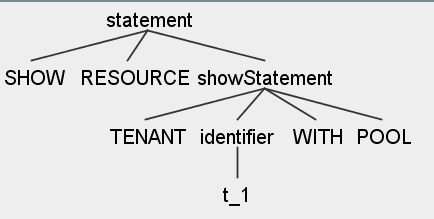
场景
1、一个ETL任务和普通任务 配置
- 普通任务就是默认的会话级别
- ETL的会话为一次性的
- ETL任务可以跟 普通任务放到一个资源池里面,也可以分开放
- 普通任务晚上不支持,资源超时自动回收,这样晚上跑ETL任务可以获取更多资源
2、多个ETL任务配置
- 仍然是配置租户session为一次性的
- 多个ETL任务的执行 跟一个ETL类似,跑完资源自动回收
- 如果多个ETL任务很占资源,可以给 租户配置两个或多个资源池
- 多个ETL任务,就会均匀的分配到不同的资源池
3、不想配置资源池、租户之类的
- 提供一个默认资源池
- 某租户如果找不到合适的资源池,就将转到这个默认资源池
- 相当于所有人公用一个大的资源池
4、调整资源单元
- 调整资源单元会影响到资源池,也会影响到其他租户
- 可以单独配置一个资源单元,新建一个资源池,将这个租户关联到新建的资源池上
5、调整资源池
6、显示现在有哪些资源单元,资源池占用量是多少
7、多个租户,每个租户都有若干普通任务和ETL任务
- 配置每个租户对应一个资源池,不干扰
- 也可以配置几个租户公用一个资源池
8、一个租户有大查询,也有小查询
- 创建两个资源单元,对应大小任务,放到一个或者两个资源池中
- 大小查询分别转到不同资源池
- 前端proxy层,目前还没有这种转发功能,目前可能就是随机转发
9、资源池调度控制问题
- 比如控制某个资源池,能调度 A类资源单元10个, B类资源单元5个
- 可以通过k8s标签的方式调度
- 这块暂不实现,增加一个空的字段,作为扩展
10、不同租户的元数据库分开
- 现在所有租户公用一个元数据库,没法分开
- 这块暂不实现,增加一个扩展字段,后续有类似需求可以放在扩展里面
语法文件
ANTLR 的 g4 文件内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
|
grammar ResourceSqlBase;
@members {
/**
* Verify whether current token is a valid decimal token (which contains dot).
* Returns true if the character that follows the token is not a digit or letter or underscore.
*
* For example:
* For char stream "2.3", "2." is not a valid decimal token, because it is followed by digit '3'.
* For char stream "2.3_", "2.3" is not a valid decimal token, because it is followed by '_'.
* For char stream "2.3W", "2.3" is not a valid decimal token, because it is followed by 'W'.
* For char stream "12.0D 34.E2+0.12 " 12.0D is a valid decimal token because it is folllowed
* by a space. 34.E2 is a valid decimal token because it is followed by symbol '+'
* which is not a digit or letter or underscore.
*/
public boolean isValidDecimal() {
int nextChar = _input.LA(1);
if (nextChar >= 'A' && nextChar <= 'Z' || nextChar >= '0' && nextChar <= '9' ||
nextChar == '_') {
return false;
} else {
return true;
}
}
}
tokens {
DELIMITER
}
singleStatement
: statement ';'* EOF
;
statement
: CREATE RESOURCE createStatement #create
| ALTER RESOURCE alterStatement #alter
| SHOW RESOURCE showStatement #show
| REMOVE RESOURCE removeStatement #remove
| SHOW ENGINES tenant=identifier #showEngines
| SHOW ENGINES POOL tenant=identifier pool=identifier #showEnginesPool
| SHOW ENGINES UNIT tenant=identifier pool=identifier unit=identifier #showEnginesUnit
| START ENGINE tenant=identifier pool=identifier unit=identifier #startEngine
| RESTART ENGINE pool=identifier name=STRING #restartEngine
| STOP ENGINE pool=identifier name=STRING #stopEngine
| (DESCRIBE | DESC) ENGINE pool=identifier name=STRING #descEngine
;
createStatement
: UNIT ifNotExist? name=identifier COMMA? unitOptions COMMA? withProperties? #createResourceUnit
| POOL ifNotExist? name=identifier COMMA? namespaceClause COMMA? poolClause COMMA? withProperties? #createResourcePool
| TENANT ifNotExist? name=identifier COMMA? poolListClause COMMA? tenantInfos COMMA? withProperties? #createTenant
;
alterStatement
: UNIT name=identifier COMMA? alterUnitOptions? COMMA? withProperties? #alterResourceUnit
| POOL name=identifier COMMA? namespaceClause? COMMA? alterPoolClause? COMMA? withProperties? #alterResourcePool
| TENANT name=identifier COMMA? alterPoolListClause? COMMA? tenantInfos? COMMA? withProperties? #alterTenant
;
showStatement
: UNIT (name=identifier (FOR POOL)? )? #showResourceUnit
| POOL (name=identifier (FOR TENANT)? )? #showResourcePool
| TENANT (name=identifier (WITH POOL (AND UNIT)? )? )? #showTenant
;
removeStatement
: UNIT name=identifier #removeUnit
| POOL name=identifier #removePool
| TENANT name=identifier #removeTenant
;
unitOptions
: unitOption (COMMA? unitOption)* #resourceUnitOptions
;
alterUnitOptions
: unitOption (COMMA? unitOption)* #alterResourceUnitOptions
;
unitOption
: DRIVER_CORES driverCpu=INTEGER_VALUE #driverCpuOption
| DRIVER_MEMORY driverMemory=STRING #driverMemoryOption
| EXECUTOR_CORES executorCpu=INTEGER_VALUE #executorCpuOption
| EXECUTOR_MEMORY executorMemory=STRING #executorMemoryOption
| EXECUTOR_MIN executorMin=INTEGER_VALUE #executorMin
| EXECUTOR_MAX executorMax=INTEGER_VALUE #executorMax
;
namespaceClause
: namespace=STRING #resourcePoolNamespace
;
poolClause
: '(' poolOptions ')' (COMMA '(' poolOptions ')')* #createResourcePoolOptions
;
poolOptions
: (UNIT name=STRING COMMA? poolOption COMMA? poolOption) #createResourcePoolOption
;
alterPoolClause
: '(' alterPoolOptions ')' (COMMA '(' alterPoolOptions ')')* #alterResourcePoolOptions
;
alterPoolOptions
: (ADD UNIT name=STRING COMMA? poolOption COMMA? poolOption) #addResourcePoolOption
| (REMOVE UNIT name=STRING) #removeResourcePoolOption
;
poolOption
: UNIT_MIN min=INTEGER_VALUE #resourcePoolOptionMin
| UNIT_MAX max=INTEGER_VALUE #resourcePoolOptionMax
;
poolListClause
: '(' poolListOption ')' (COMMA '(' poolListOption ')')* #createResourceTenantPoolList
;
poolListOption
: (POOL name=STRING) #createResourceTenantPoolOption
;
alterPoolListClause
: '(' alterPoolListOption ')' (COMMA '(' alterPoolListOption ')')* #alterResourceTenantPoolList
;
alterPoolListOption
: (ADD POOL name=STRING) #addResourceTenantPoolOption
| (REMOVE POOL name=STRING) #removeResourceTenantPoolOption
;
tenantInfos
: tenantInfo (COMMA ?tenantInfo)? #resourceTenantInfos
;
tenantInfo
: TYPE infoType=STRING #resourceTenantType
| STRATEGY infoStrategy=STRING #resourceTenantStrategy
;
identifier
: IDENTIFIER #unquotedIdentifier
| quotedIdentifier #quotedIdentifierAlternative
;
quotedIdentifier
: BACKQUOTED_IDENTIFIER
;
withProperties
: WITH PROPERTIES '(' withProperty (COMMA withProperty)* ')'
;
withProperty
: STRING '=' STRING
;
ifNotExist
: IF NOT EXIST
;
// key word
CREATE: 'CREATE';
ALTER: 'ALTER';
SHOW: 'SHOW';
REMOVE: 'REMOVE';
RESOURCE: 'RESOURCE';
UNIT: 'UNIT';
POOL: 'POOL';
TENANT: 'TENANT';
DRIVER_CORES: 'DRIVER_CORES';
DRIVER_MEMORY: 'DRIVER_MEMORY';
EXECUTOR_CORES: 'EXECUTOR_CORES';
EXECUTOR_MEMORY: 'EXECUTOR_MEMORY';
UNIT_MIN: 'UNIT_MIN';
UNIT_MAX: 'UNIT_MAX';
LEFT_PAREN: '(';
RIGHT_PAREN: ')';
POOL_LIST: 'POOL_LIST';
WITH: 'WITH';
AND: 'AND';
EXECUTOR_MIN: 'EXECUTOR_MIN';
EXECUTOR_MAX: 'EXECUTOR_MAX';
PROPERTIES: 'PROPERTIES';
TYPE: 'TYPE';
STRATEGY: 'STRATEGY';
ADD: 'ADD';
IF: 'IF';
NOT: 'NOT';
EXIST: 'EXIST';
COMMA: ',';
ENGINE: 'ENGINE';
ENGINES: 'ENGINES';
START: 'START';
RESTART: 'RESTART';
STOP: 'STOP';
DESCRIBE: 'DESCRIBE';
DESC: 'DESC';
EXECUTORS: 'EXECUTORS';
FOR: 'FOR';
STRING
: '\'' ( ~('\''|'\\') | ('\\' .) )* '\''
| '"' ( ~('"'|'\\') | ('\\' .) )* '"'
;
DOUBLEQUOTED_STRING
:'"' ( ~('"'|'\\') | ('\\' .) )* '"'
;
BIGINT_LITERAL
: DIGIT+ 'L'
;
SMALLINT_LITERAL
: DIGIT+ 'S'
;
TINYINT_LITERAL
: DIGIT+ 'Y'
;
INTEGER_VALUE
: DIGIT+
;
DECIMAL_VALUE
: DIGIT+ EXPONENT
| DECIMAL_DIGITS EXPONENT? {isValidDecimal()}?
;
DOUBLE_LITERAL
: DIGIT+ EXPONENT? 'D'
| DECIMAL_DIGITS EXPONENT? 'D' {isValidDecimal()}?
;
BIGDECIMAL_LITERAL
: DIGIT+ EXPONENT? 'BD'
| DECIMAL_DIGITS EXPONENT? 'BD' {isValidDecimal()}?
;
IDENTIFIER
: (LETTER | DIGIT | '_')+
;
BACKQUOTED_IDENTIFIER
: '`' ( ~'`' | '``' )* '`'
;
fragment DECIMAL_DIGITS
: DIGIT+ '.' DIGIT*
| '.' DIGIT+
;
fragment EXPONENT
: 'E' [+-]? DIGIT+
;
fragment DIGIT
: [0-9]
;
fragment LETTER
: [A-Za-z]
;
SIMPLE_COMMENT
: '--' ~[\r\n]* '\r'? '\n'? -> channel(HIDDEN)
;
BRACKETED_COMMENT
: '/*' .*? '*/' -> channel(HIDDEN)
;
WS : [ \r\n\t]+ -> channel(HIDDEN)
;
// Catch-all for anything we can't recognize.
// We use this to be able to ignore and recover all the text
// when splitting statements with DelimiterLexer
UNRECOGNIZED
: .
;
|