文件同步
背景
Spark的 driver template,executor template,在跨 k8s 的 namespace 下,需要再搞一份
比如 executor需要这些
1
2
3
4
5
6
7
|
volumeMounts:
- mountPath: /tmp/krb5_conf
name: my_project-krb5-conf
- mountPath: /tmp/krb5_keytab
name: my_project-krb5-keytab
- mountPath: /my_project/resources/kerberos
name: keytab-config
|
driver的就更多了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
volumeMounts:
- mountPath: /tmp/krb5
name: kerberos-temp
- mountPath: /my_project/resources/kerberos
name: keytab-config
- mountPath: /tmp/executoe_template
name: my_project-executor-template
- mountPath: /my_project/resources
name: resource-config
- mountPath: /tmp/application-properties
name: my_project-app-properties
- mountPath: /my_project/resources/config
name: app-config
- mountPath: /tmp/scheduler-config
name: my_project-scheduler-config
- mountPath: /my_project/resources/scheduler-config
name: scheduler-config
- mountPath: /tmp/ranger
name: my_project-ranger-xml
|
在资源隔离场景下,使用了 k8s 的 namespace,由于 namespace是天然隔离的,所以 不同 namespace 中的 配置文件没法共用
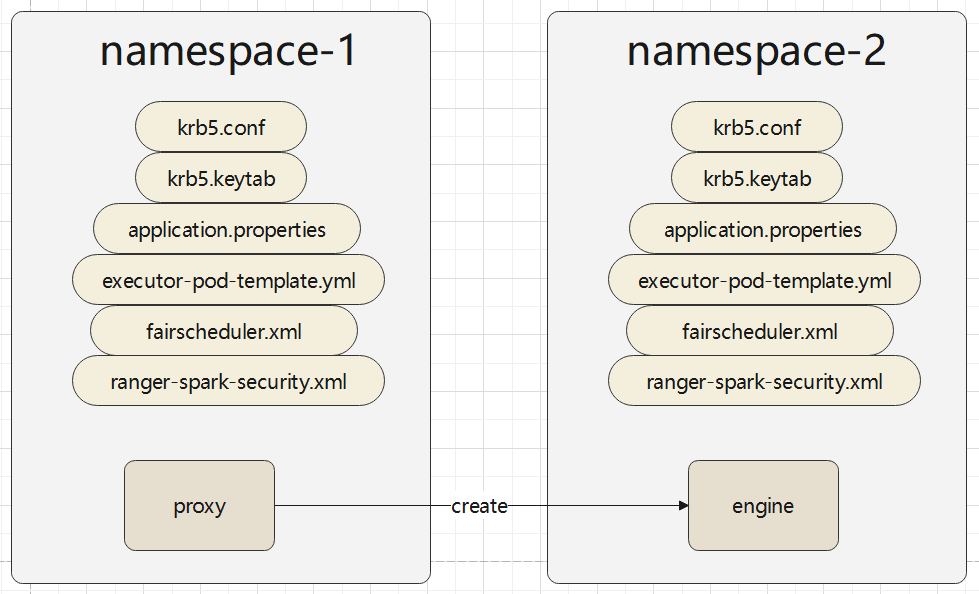
如上,本来有一个 namespace-1,下面有若干文件,这时候,基于 namespace 1 启动了一个新的 pod,是放在 namespace-2下的,但如果要正常使用这个 pod,就需要在 namespace 2 下把相关文件重新创建一遍
希望达成的效果
- proxy 创建 engine时,不需要再创建配置文件了,可以自动完成
- 跨 k8s 的 namespace 下创建 engine时,也不需要冗余手动创建配置文件了,可以自动完成
实现方案
目前想到了有这么一些方案
- 基于 ZK 同步配置文件
- 基于 minio 同步配置文件
- 基于 HDFS 同步配置文件
- 内置一个 http,其他 pod主动拉取
- pod 之间使用组播实现同步
- 基于环境变量同步
基于ZK、minio、HDFS的同步
这几种本质是差不多的,都是把配置文件放到一个外部组件中
这些依赖都有一些问题
- HDFS 是最麻烦的一个,因为使用 HDFS,得先有 krb5 文件,但此时还没有这个文件
- minio需要密码,可能需要通过 env 先传递过去
- zk 目前只需要 ip 和port可以直接获取,但如果环境要求必须用 kerberos 连接,那也不好搞了
基于 http同步,组播
proxy 自身启动一个 http 服务,然后 engine 主动去连接这个 http
但 proxy 如果宕机了,engine 就不知道去哪里获取了
使用组播的方式,大家都先加入一个组播,然后识别出各自的身份
这样即使proxy挂了,新的proxy如果能加入这个组,engine还是可以找到的
实现组播也有一些问题
- 所有的应用都是基于 k8s的,那就相当于每个应用一个组播,如何确保组播地址不冲突,相互不会干扰
- 几个proxy + 几百个engine时,如何平衡读取 proxy,以及很多细节需要处理
基于环境变量
这个比较简单,直接将配置文件的内容写到环境变量中
新 pod 启动后,直接读取环境变量的值,然后将值的内容 写入到指定的路径中
比如直接将 环境变量中的值,写入到 /my_project/resources/config/application.properties
之后的逻辑就按正常方式读取 application.properties 即可
实现细节
拉取配置文件(不管是基于ZK、或是ENV),这个动作本身的需要在正常逻辑启动之前执行
因为正常的逻辑需要读取配置文件,krb5等,如果拉取动作跟正常逻辑混在一起了,可能还没拉取就报错了
同时拉取这个动作,跟正常逻辑不应该耦合太紧,所以放到 init 容器里面做这些事情比较合适
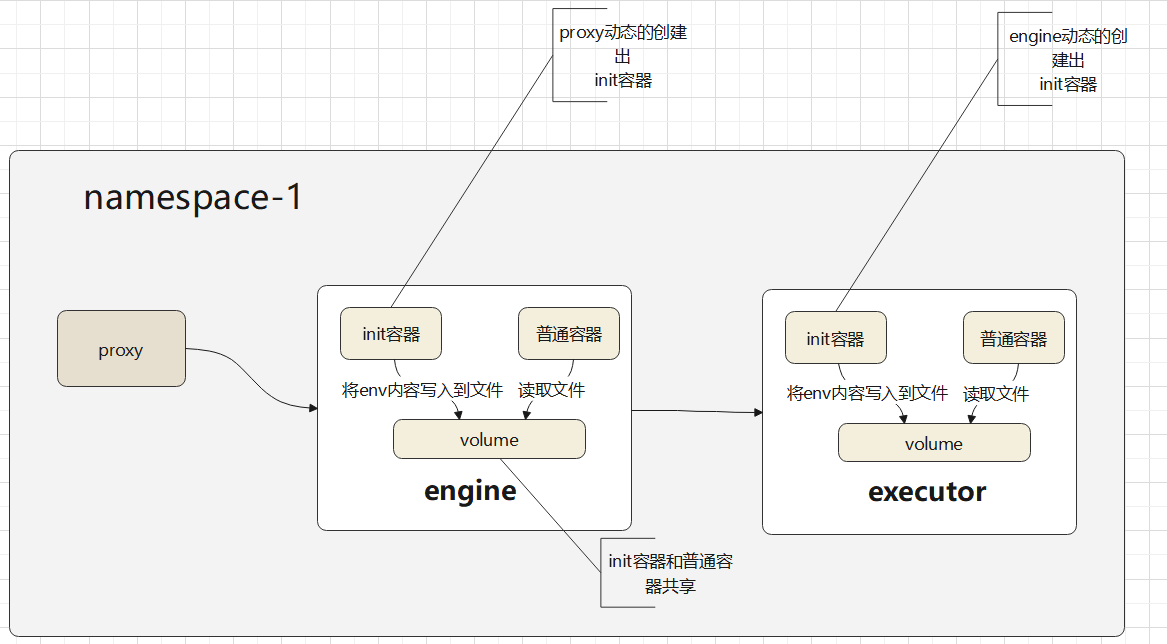
一个 namespace 内的拉取流程
- proxy 需要配置出 engine 的init 容器
- 之后再创建出一个 volume,这个 volume 跟 pod 生命周期一样即可,pod 销毁了配置文件也就没了
- proxy 读取本地,也就是容器内的配置文件,作为 env传递给 engine 的 init 容器
- init 容器读取解析出这些 env,保存到 共享的 volume 中
- engine 的正常逻辑继续正常,此时配置文件都被 init 容器正常放置好了,engine后续的逻辑不需动,正常执行
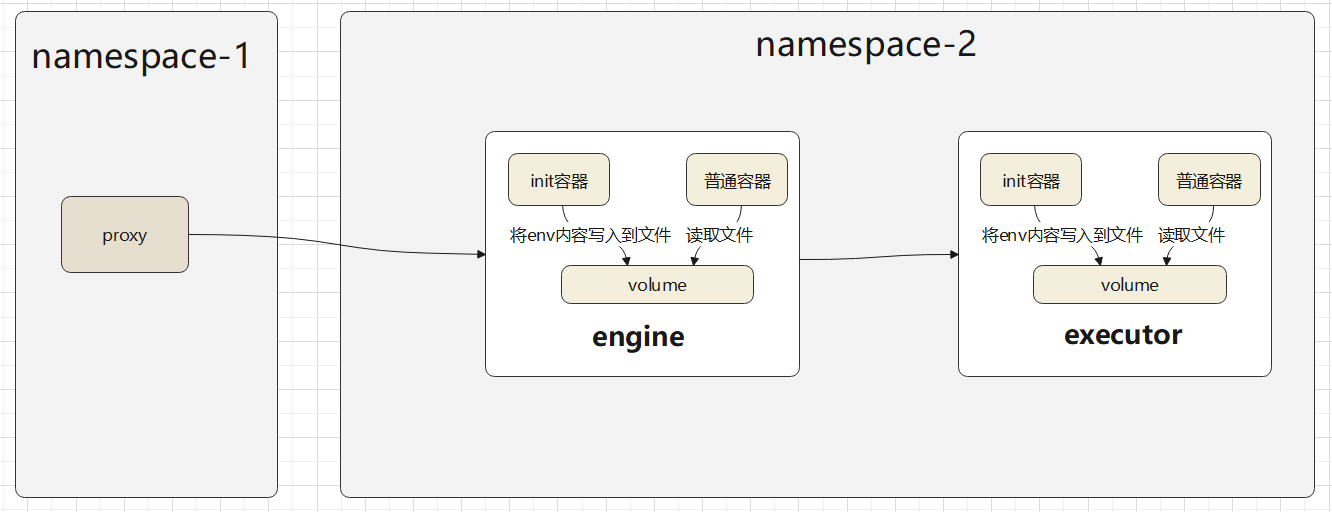
跨 namespace 的拉取流程
- 这个流程总体上跟 namespace内的 是差不多
- proxy 也是要创建出 init容器、volume,只是发布到 不同的namespace中
- 新namespace 下的 engine会继续创建出 executor,他们两个是在同一个 namespace 下的
- engine 也会创建出 executor 的 init 容器、volume
- 之后把 krb5的两个文件传递到 init 容器的 env中,init 读取写入到共享的 volume中
- 之后 executor 就可以读取到这些文件,后面走正常逻辑可
操作步骤
增加配置:
spark.kubernetes.driver.pod.featureSteps=org.apache.spark.server.k8s.extension.EngineSetup,org.apache.spark.server.k8s.extension.EngineNamespaceFeature
spark.kubernetes.executor.pod.featureSteps=org.apache.spark.server.k8s.extension.ExecutorSetup
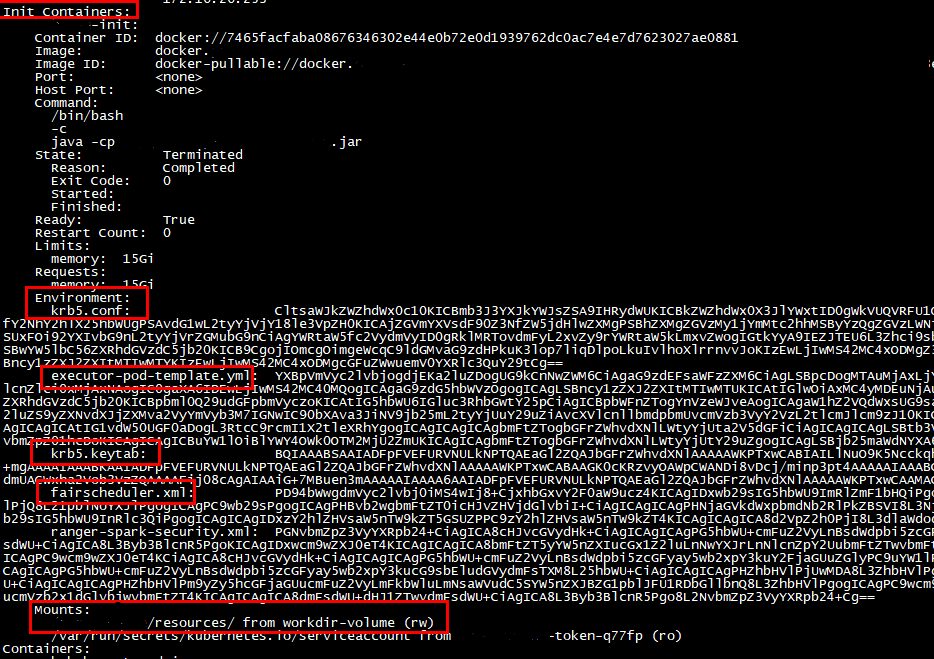
启动后,查看 pod 描述,会有一个 init 容器,这个是自动创建的
其中 cmd 命令是java -cp .:/xxxx.jar com.test.XXX
这个类是在 init容器中,启动一个拉取 ENV 的逻辑
env 的name 是文件名,value是文件内容的base64编码
然后是 mount,这个也是自动生成的
最后增加 host-aliase,proxy拿到自己的 host-aliase,然后直接设置到 engine 的pod 上
进入 engine pod,host 就被自动设置上了
镜像统一
背景
目前项目包含了两个镜像,一个 实际业务 镜像,一个是 sparkexecutor 镜像
在流水线部署 的时候,源码实际是被编译了两次
一次是编译打包生成 实际业务 镜像
一次是编译打包 将文件拷贝至 spark-executor 镜像
两次编译导致每次部署时间都很长
在实际项目部署时也需要管理两个镜像
因上述原因,现将 两个镜像 合二为一,统一成一个镜像
实现
将两个镜像合并为一个,大致有三种策略
- 将原基础镜像(OpenJDK11),跟 spark-executor镜像整合,变成新的基础镜像,项目编译代码后,将编译后的文件直接拷贝到整合的镜像中
- 原基础镜像不动,打包时,将spark-executor镜像中的内容拷贝到基础镜像中,将项目的编译后的文件也拷贝到基础镜像中
- 将原基础镜像的内容拷贝到 spark-executor镜像中,之后项目编译的文件也拷贝到 spark-executor中
第一种方式,后续Spark 升级的话维护起来会麻烦一点,好处是流水线打包速度会更快
第二种方式,维护起来会简单一些,基础镜像和spark-executor可以单独升级,但部署流水线会慢 2-3 分钟
第三种方式,spark-executor镜像使用的是ubuntu,有些工具不支持,另外还需要冗余的拷贝一份JDK
目前使用的是 第二种方式
镜像合并后,需要一种机制来判断,是启动 engine,还是 executor
目前的做法是,如果环境变量中不包含 MY_PROJECT_EXECUTOR,则认为当前角色是 engine,启动 engine
否则,启动 executor
当 engine启动 executor之前,会执行一个 k8s扩展,将 MY_PROJECT_EXECUTOR 变量设置进去,于是新 pod 启动时就认为自己是 executor
dockerfile
统一镜像后的dockerfile
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
# builder
FROM maven:3.6.3-openjdk-11-slim AS builder
COPY . .
COPY settings.xml $MAVEN_CONFIG/
WORKDIR /
RUN mvn clean package -Dmaven.test.skip=true
# 使用 Spark3.3.2 的镜像,后续升级的话,将这里的版本号修改一下即可
FROM spark:3.3.2-amd64 AS SPARK_IMAGE
# 基础镜像,包含 JDK11.0.16,以及一些方便排查的工具和命令
FROM base:OpenJDK-11.0.16_V1.0
ARG TARGET=/my_project-main/target
ARG MY_PROJECT=/my_project
ARG DEPENDENCY=/dependency
ARG SPARK_HOME=/opt/spark
ARG JAVA_HOME=/usr/local/openjdk-11.0.16+8-x64
ENV SPARK_HOME=$SPARK_HOME
ENV MY_PROJECT_DOCKER_IMAGE=my_project.container.image
ENV SPARK_CLASSPATH $SPARK_CLASSPATH:$SPARK_HOME/lib/*
# 将 Spark 镜像中的目录、相关文件、核心启动脚本拷贝到 基础镜像中
COPY --from=SPARK_IMAGE /opt/spark /opt/spark
COPY --from=SPARK_IMAGE /opt/decom.sh /opt
COPY --from=SPARK_IMAGE /opt/entrypoint.sh /opt
COPY --from=SPARK_IMAGE /usr/bin/tini /usr/bin
COPY --from=builder $DEPENDENCY/bootstrap.sh /opt
COPY --from=builder $TARGET/main-*.jar $MY_PROJECT/engine-main.jar
COPY --from=builder $TARGET/lib $MY_PROJECT/lib
COPY --from=builder $TARGET/lib $SPARK_HOME/lib
COPY --from=builder $TARGET/main-*.jar $SPARK_HOME/lib
COPY --from=builder $TARGET/resources/scheduler-config $MY_PROJECT/resources/scheduler-config
COPY --from=builder $TARGET/resources/custom-log4j2-json-layout.json $MY_PROJECT/resources/custom-log4j2-json-layout.json
COPY --from=builder $TARGET/resources/log4j2-spring.xml $MY_PROJECT/resources/log4j2-spring.xml
RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
echo 'Asia/Shanghai' > /etc/timezone && \
useradd -ms /bin/bash hive && \
chmod +x /opt/bootstrap.sh
EXPOSE 8011
EXPOSE 4040
EXPOSE 7078
EXPOSE 7079
WORKDIR /my_project
# 统一镜像后的核心启动脚本
# 如果环境变量中包含 MY_PROJECT_EXECUTOR,则脚本调用 executor 的启动逻辑
# 否则,调用启动 my_project 的启动逻辑
ENTRYPOINT [ "/opt/bootstrap.sh" ]
|
基础镜像 dockerfile
基于 JDK11 打的基础镜像dockerfile
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
# 基于 CentOS 7.4 基础上,创建新基础镜像
# 此基础镜像包含 OpenJDK 11.0.16,和 Spark-executor 镜像的 JDK 版本保持一致
# 并增加了一些排查工具和命令
FROM centos:centos7.4.1708
LABEL describe="MY_PROJECT base image(OpenJDK 11.0.16)"
RUN rm -f /etc/yum.repos.d/*
COPY My_project-Centos7-public.repo /etc/yum.repos.d/
COPY openjdk-11.0.16+8-x64 /usr/local/openjdk-11.0.16+8-x64
COPY arthas /arthas
RUN yum -y install krb5-devel krb5-workstation && \
yum -y install curl && \
yum -y install dstat && \
yum -y install traceroute && \
yum -y install wget && \
yum -y install lsof && \
yum -y install tcpdump && \
yum -y install net-tools && \
yum -y install sysstat && \
yum -y install telnet && \
yum -y install psmisc && \
echo "alias ll='ls -l'" >> /root/.bashrc && \
yum -y remove perl && \
rm -rf /var/cache/yum && \
touch /var/cache/yum
ENV PATH=${PATH}:/usr/local/openjdk-11.0.16+8-x64/bin
ENV TZ=Asia/Shanghai
ENV LANG zh_CN.UTF-8
|