大数据采集
主要的一些大数据采集工具
日志和各种数据源采集
- Flume
- Fluentd
- Logstash、FileBeat
离线数据采集
- Datax
- Sqoop
实时采集
- Canal
- Maxwell
一些商用、过时的
- Scribe
对比
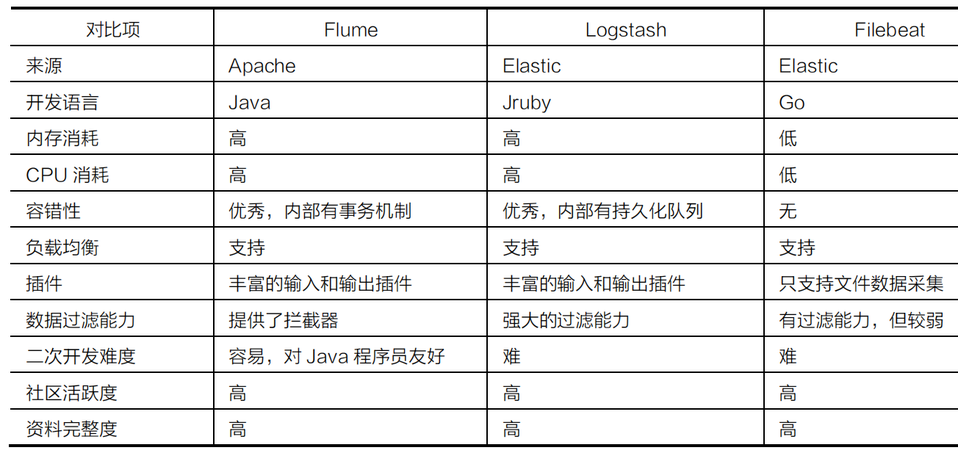
Flume vs Fluentd vs FileBeat
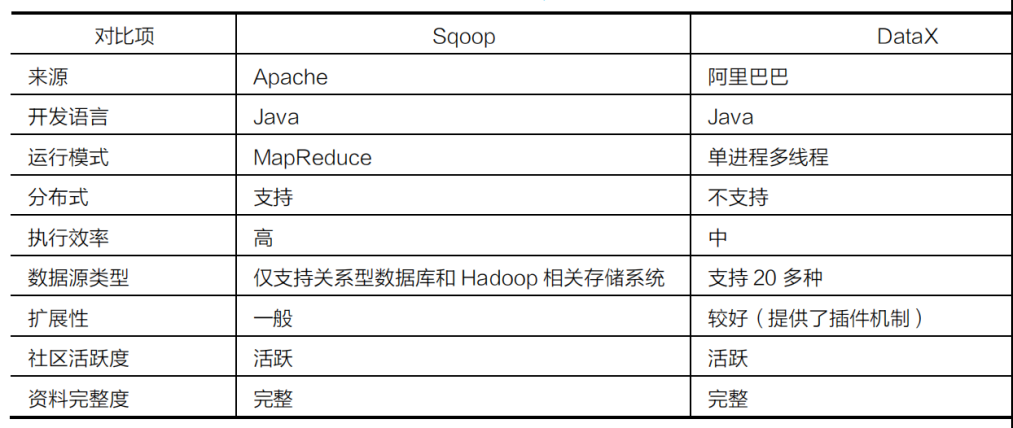
Datax vs Sqoop
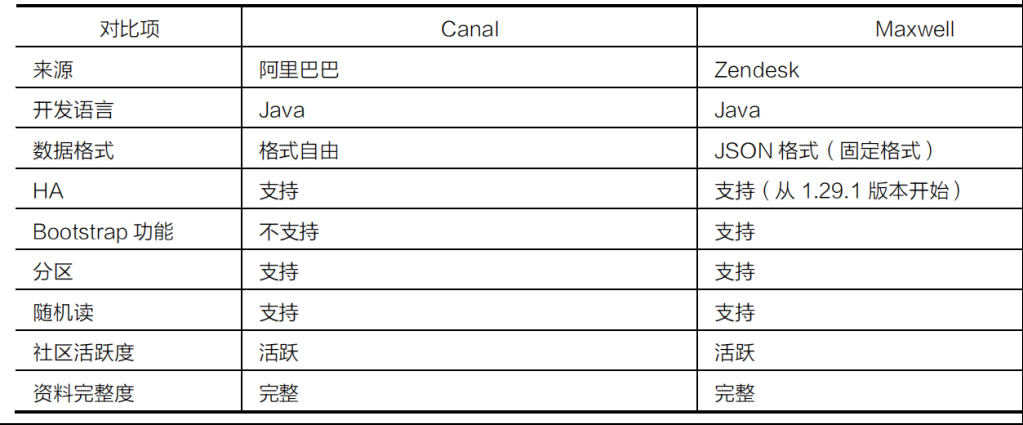
Canal vs Maxwell
Flume
整体介绍
Java 开发的
Flume是一个分布式,可靠且可用的系统,用于有效地收集,聚合大量日志数据并将其从许多不同的源移动到集中式数据存储中
Flume的使用不仅限于日志数据聚合。由于数据源是可定制的,因此Flume可用于传输大量事件数据
包括但不限于网络流量数据,社交媒体生成的数据,电子邮件消息以及几乎所有可能的数据源
Flume提供了三种级别的可靠性保障,从强到弱依次分别为
- end-to-end:收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送
- Store on failure:这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送
- Best effort:数据发送到接收方后,不会进行确认
Flume以agent为最小的独立运行单位。一个agent就是一个JVM。它是一个完整的数据收集工具,含有三个核心组件
- source
- channel
- sink
通过这些组件, Event 可以从一个地方流向另一个地方
一个例子,从网络接收事件,打印到控制台上
|
|
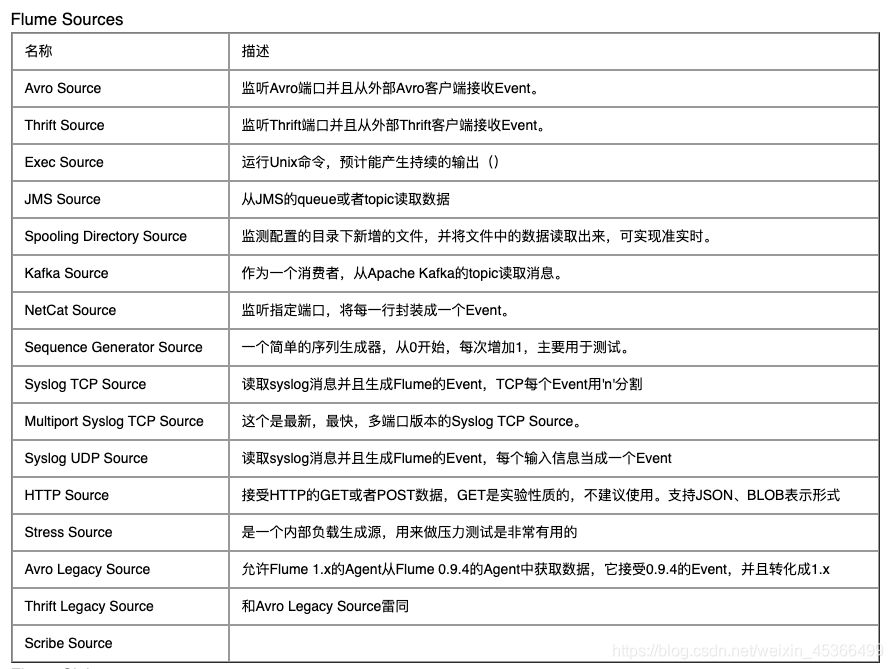
source类型
Channel类型:

Sink类型:
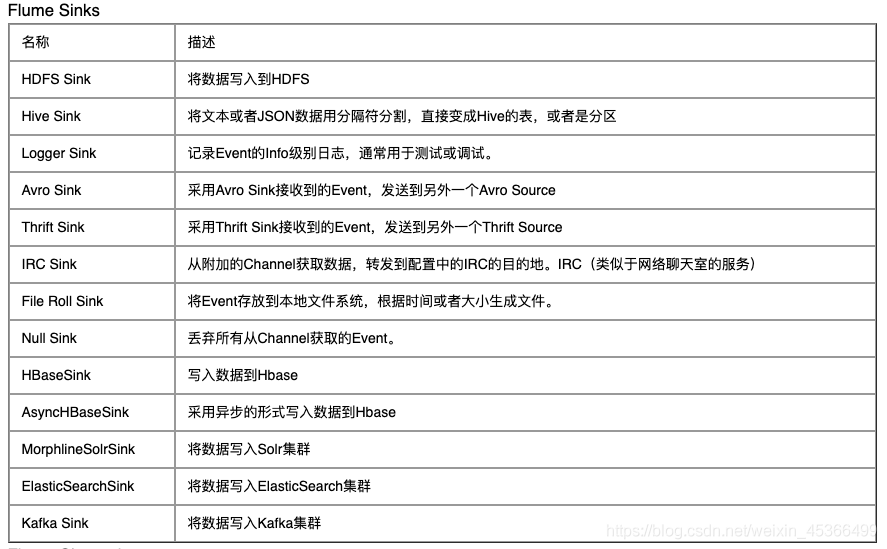
Flume Channel Selectors
- Replicating Channel Selector
- Load Balancing Channel Selector
- Multiplexing Channel Selector
- Custom Channel Selector
Flume Sink Processors,可以分组多个sink
- Failover Sink Processor
- Load balancing Sink Processor
- Custom Sink Processor
Event Serializers
- Body Text Serializer
- “Flume Event” Avro Event Serializer
- Avro Event Serializer
Flume Interceptors,可以像责任链一样串联,选择和丢弃 event,还可以配置正则
- Timestamp Interceptor
- Host Interceptor
- Static Interceptor
- Remove Header Interceptor
- UUID Interceptor
interceptor 类型:
使用场景
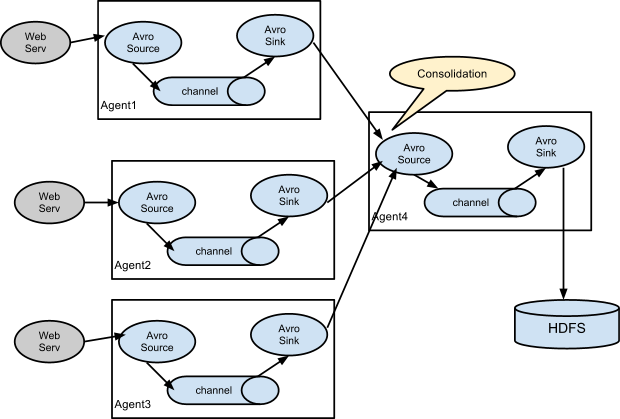
多个agent顺序连接

多Agent的复杂流
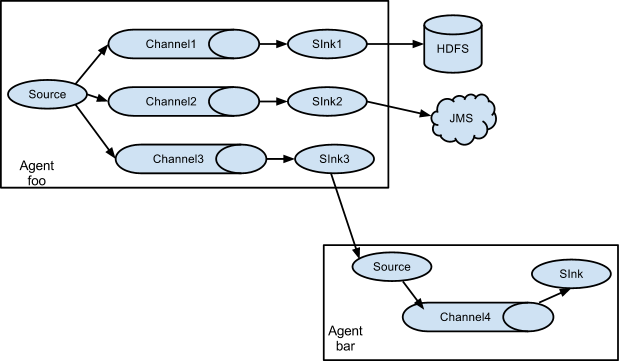
多路复用流
监控
- JMX Reporting
- Ganglia Reporting
- JSON Reporting
- Custom Reporting¶
Flume 的 At-least-once 保证的实现基础是建立了自身的 Transaction 机制
Flume 的 Transaction 有 4 个生命周期函数,分别是 start、 commit、 rollback 和 close
- 当 Source 往 Channel 批量投递事件时首先调用 start 开启事务,批量 put 完事件后通过 commit 来提交事务
- 如果 commit 异常则 rollback ,然后 close 事务,最后 Source 将刚才提交的一批消息事件向源服务 ack(比如 kafka 提交新的 offset )
- Sink 消费 Channel 也是相同的模式,唯一的区别就是 Sink 需要在向目标源完成写入之后才对事务进行 commit
- 两个组件的相同做法都是只有向下游成功投递了消息才会向上游 ack,从而保证了数据能 At-least-once 向下投递
性能调优
- 事务 batch 指的是合理设置 batch 配置
- Channel 的 capacity 大小
参考
Fluentd
整体介绍
ruby 开发的
跟 flume 很类似

Fluentd的Input/Buffer/Output非常类似于Flume的Source/Channel/Sink
- Input,负责接收数据或者主动抓取数据。支持syslog,http,file tail等。
- Buffer,负责数据获取的性能和可靠性,也有文件或内存等不同类型的Buffer可以配置。
- Output,负责输出数据到目的地例如文件,AWS S3或者其它的Fluentd
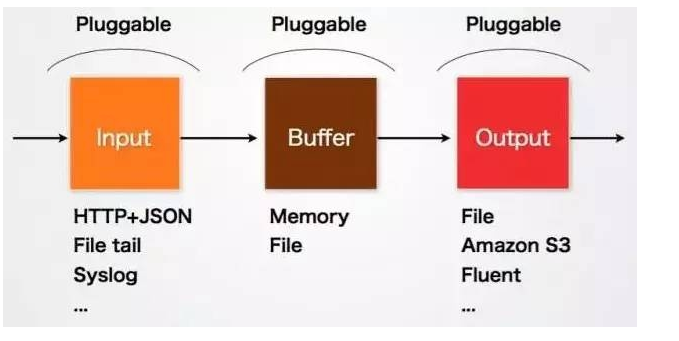
Fluentd vs. Logstash
- fluentd 比 logstash 更省资源
- 更轻量级的 fluent-bid 对应 filebeat,作为部署在结点上的日志收集器
- fluentd 有更多强大、开放的插件数量和社区
配置文件的核心是各种命令块(directives),每一种命令都是为了完成某种处理
命令与命令之间还可以组成串联关系,以 pipline 的形式流式的处理和分发日志
命令的主要组成部分有:
- source,类似于 flume 的source
- filter,类似于 interceptor
- match,类似于 sink
- label,将任务分组
- error,处理异常,用 system 修改运行参数
一个例子
|
|
Fluentd 支持 9 种类型的插件:
- Input:事件流入口;
- Parser:修改 Input 插件中事件格式,用于 Source;
- Filter: 修改事件流,用于 Filter;
- Output:输出插件,用于 Match;
- Formatter:修改 Output 插件中事件流的格式,用于 Match;
- Buffer:在 Output 插件中指定 buffer,用于 Match;
- Storage:将插件状态存入内存或数据库,可用于 Source、Filter 和 Match,需要插件支持 storage 命令。
- Service Discovery
- Metrics
任何消息传递系统,都需要考虑消息递交语义(delivery semantics)
- At most once:最多传递一次,有可能会丢消息,但是不会重复;
- At least once:最少传递一次,不会丢消息,但是可能重复;
- Exactly once:确切的只传递一次,需要多次确认消息状态,会极大的牺牲性能。
一个日志收集系统由两个角色组成:
- log forwarders:负责日志采集和转发;
- log aggregators:负责日志收集和汇总处理
- fluentd 可以扮演上述两个角色(或者由 fluent-bit 扮演 forwarders 角色),为了保证高可用, 对 aggregators 做多点备份

监控
- prometheus
- Datadog
- REST API
参考
Sqoop
架构
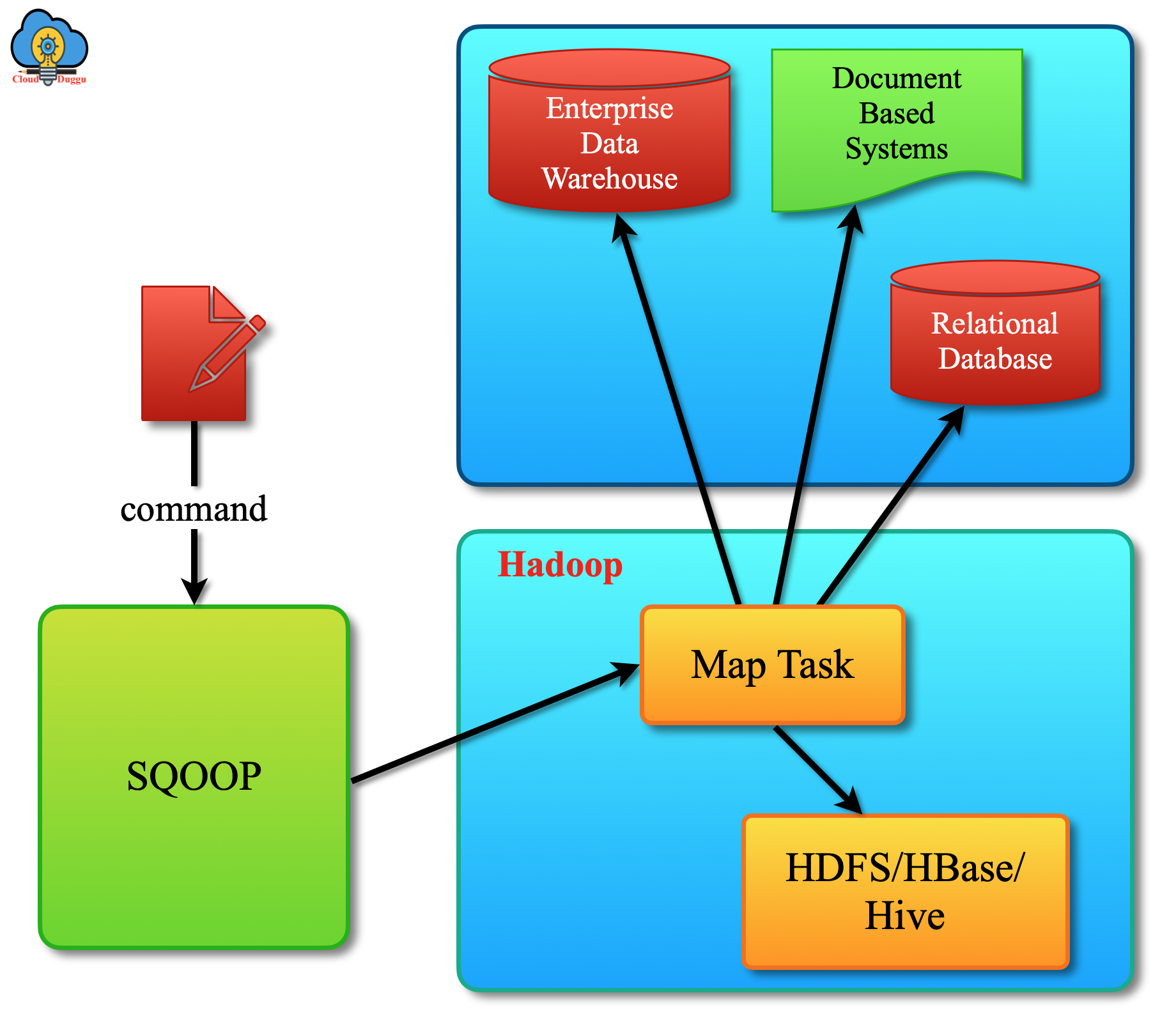
数据的导入导出:
- Import:数据导入。RDBMS—–>Hadoop
- Export:数据导出。Hadoop—->RDBMS
参考
Datax
一个 DataX 的bug
- 原生的 hdfsreader 读取超大 orc 文件有 bug
- orc 的读 api 会把大文件分片成多份,默认大于 256MB 会分片,而 datax 仅读取了第一个分片
- 修改为读取所有分片解决问题。因为 256MB 足够大,这个问题很少出现很隐蔽
参考
- 官网
- 将 DataX 执行结果通过钉钉上报
- 开源遇上华为云——DataX for HuaweiCloud OBS
- 使用 DataX 同步 MaxCompute 数据到 TableStore(原 OTS)优化指南
SeaTunnel
参考