Presto在各大公司的应用
B站
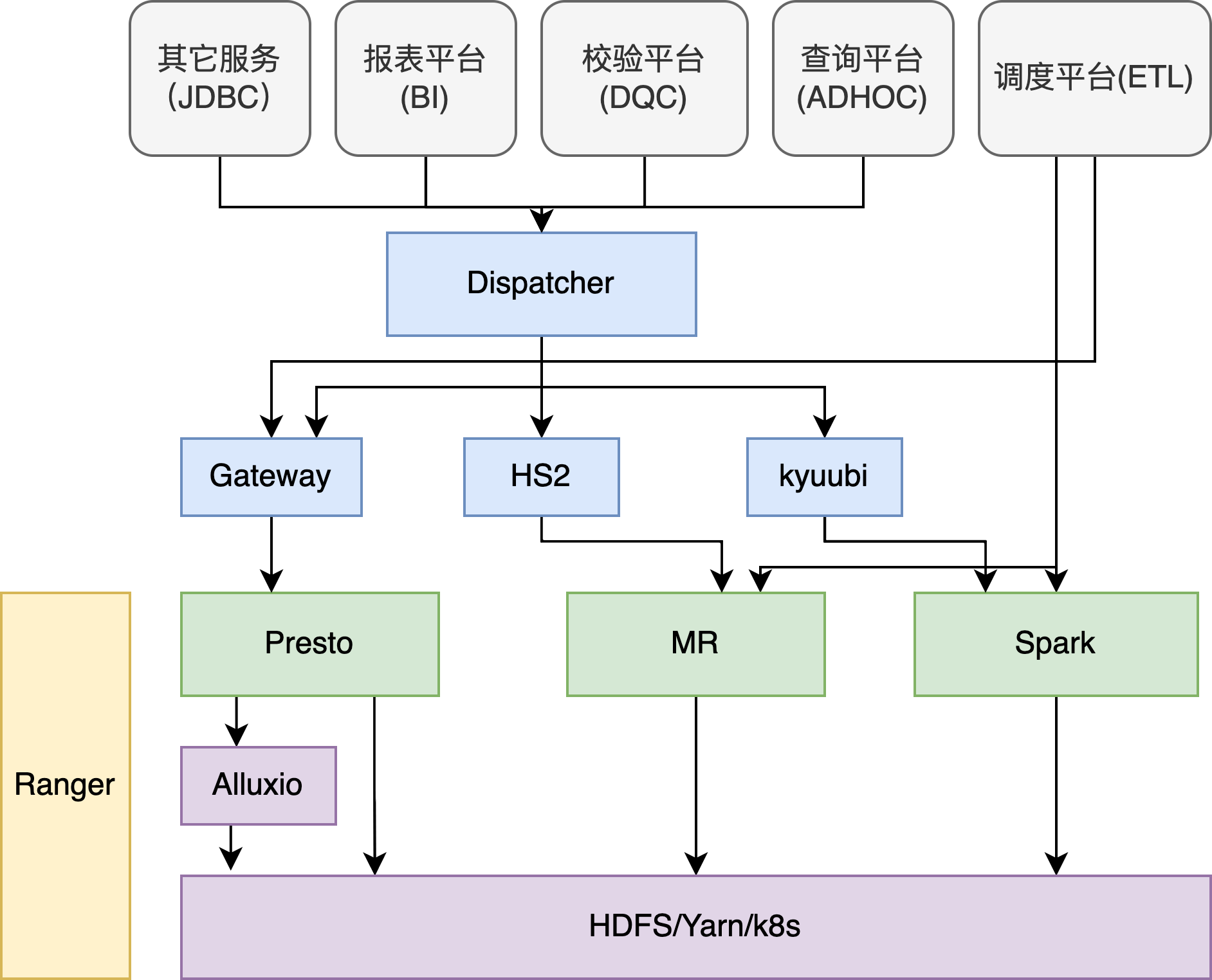
最前面有一层 dispatcher,使用了 Linkedin开源的coral 对语法做分析,转换
根据不同的 SQL 类型,转到不同的引擎
spark 用了 kyuubi 做了前端,实现多租户、高可用
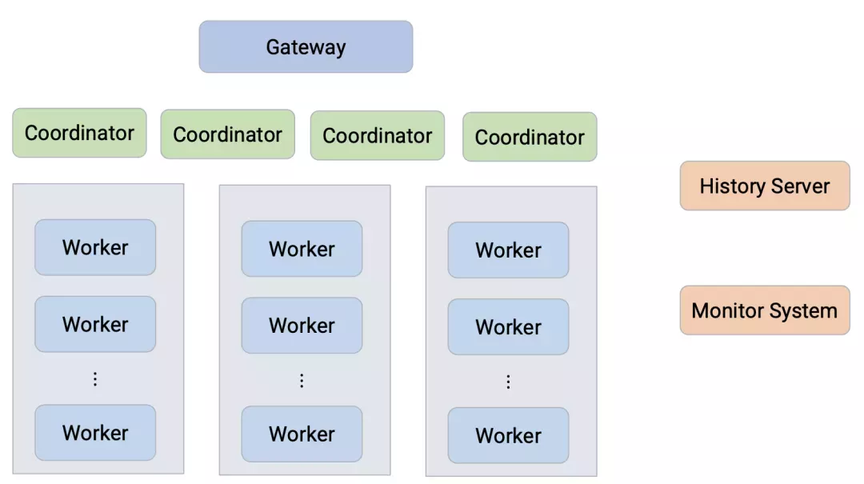
presto 也是类似,前面有一个 gateway,实现高可用
另外所有的引擎都接入了 ranger,做鉴权
改造点
- 所有的请求经过 gateway 到 presto
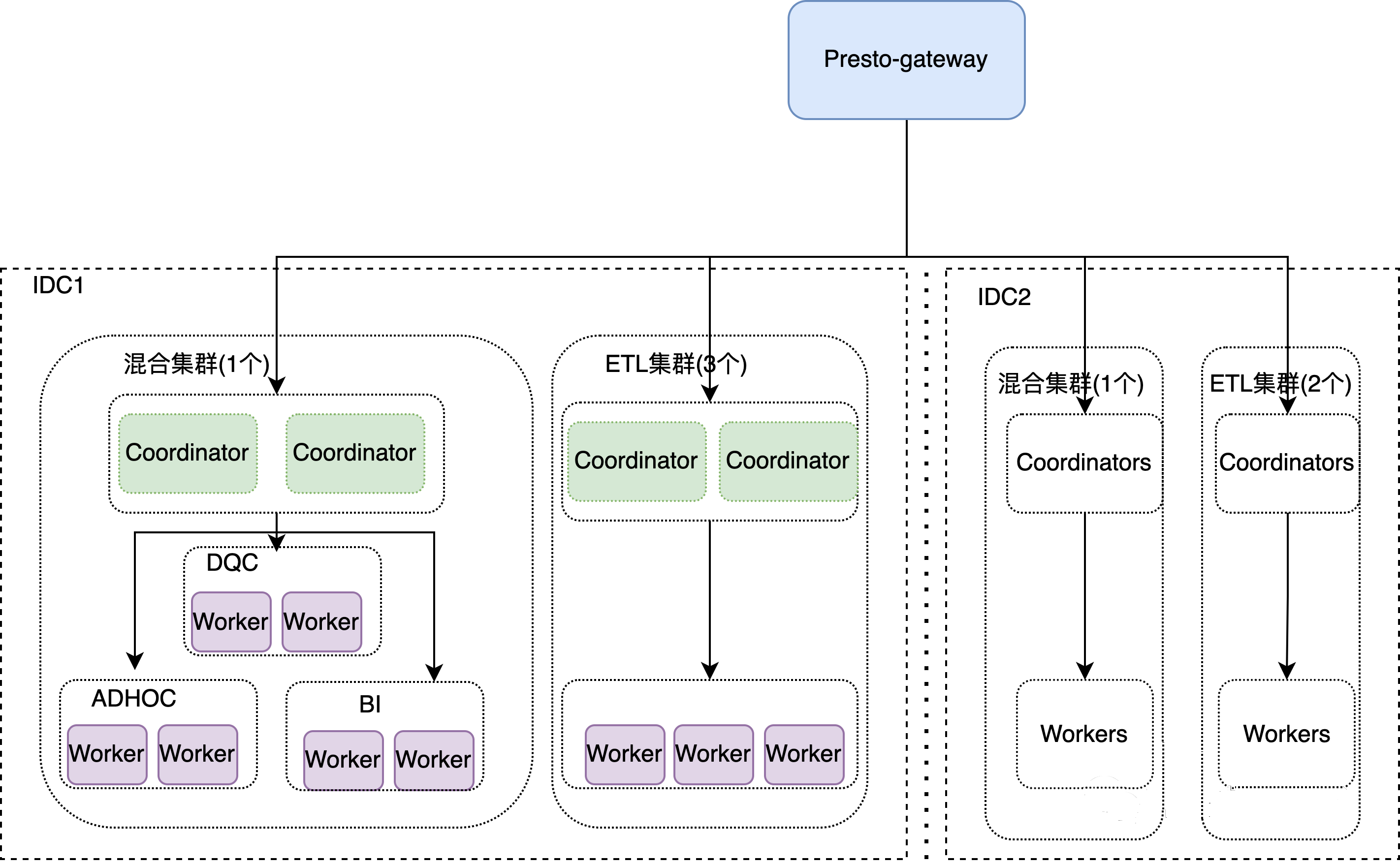
- 探测 coordinator 状态,根据作业ID 来选择机房调度
- 对 query 做解析,根据依赖的表和分区,选择合适的机房
- 探测 coordinator负载,内存、作业堵塞,来选择负载均衡
coordinator 多活改造
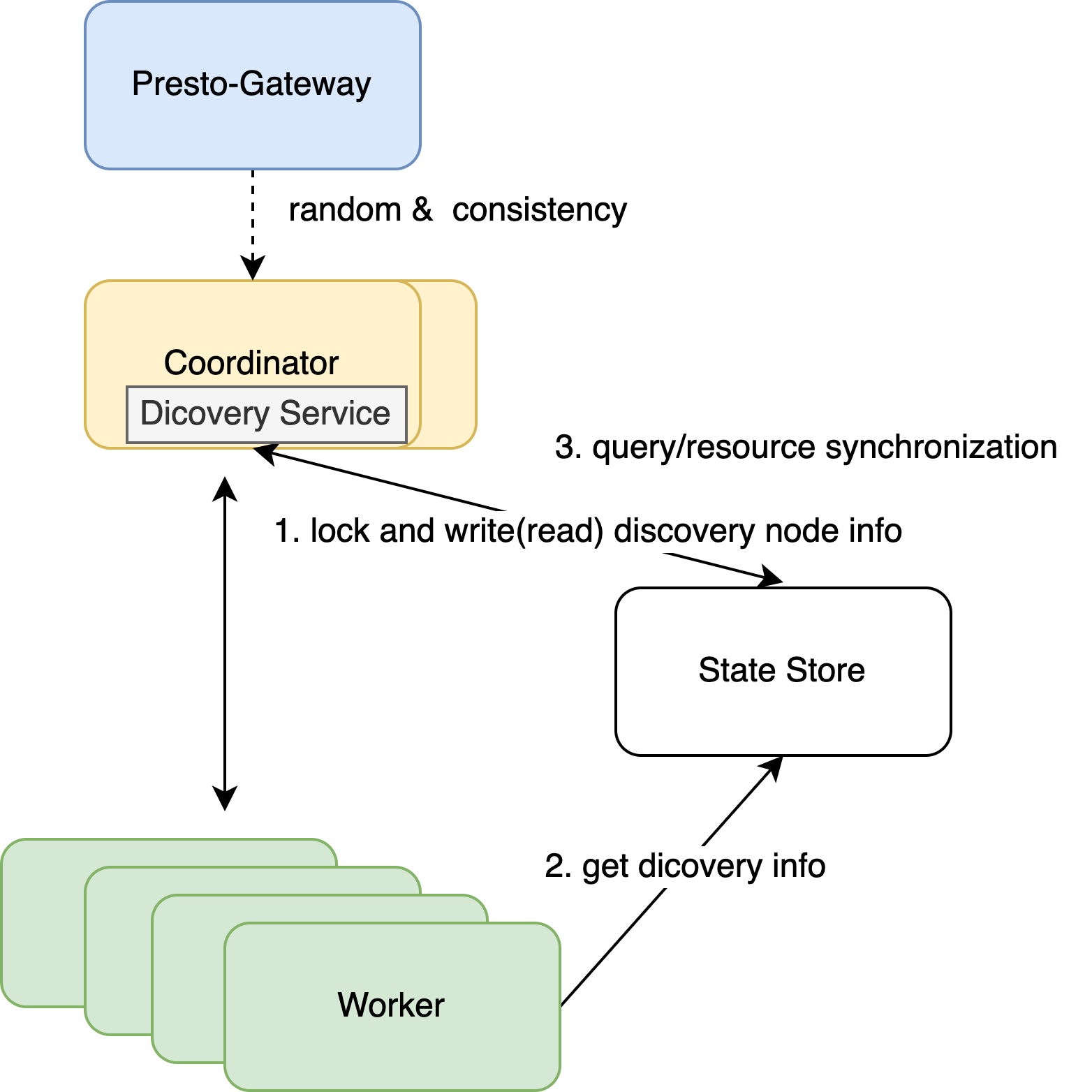
- 使用 redis作为持久注册
- coordinator 启动时注册分布式锁
- worker 读取 redis获取对应的 coordinator
- gateway 随机选择一个 coordinate,或者一直使用这个会话
稳定性方面
- 资源隔离方面,使用了 lable,根据已经配置好的lable,动态选择对应的集群
- 同样的请求第二次路由,就会找低负载的集群
- 另外有惩罚措施,会占用过大的请求,会将惩罚下发到所有worker节点
- gateway 会解析SQL,替换表达式提取通用 MD5特种,如果类似的请求出现,会做拦截,或者kill
- worker端根据 MBean,kill 掉超过一定比列的task
可用性方面
- spark/hive 语法兼容
- 隐式转换,hive UDF兼容,insert overwrite table
- 支持更多的数据源,多数据源联合查询
- HDFS上的jar,动态加载catalog
- Job History服务
- 监听发布系统kill -15信号,将自身状态改为非 activ,等完成任务再退出,实现无损发布
性能方面
- 增加 alluxio
- 开发cache invalidate服务,监听hive meta event,根据分区路径删除无效缓存
- 查询结果做 MD5提取,放到redis,如果有DDL事件,根据分区,做缓存失效处理
- 高版本的 Dynamic Partition Pruning,根据这种思路重现实现改造的
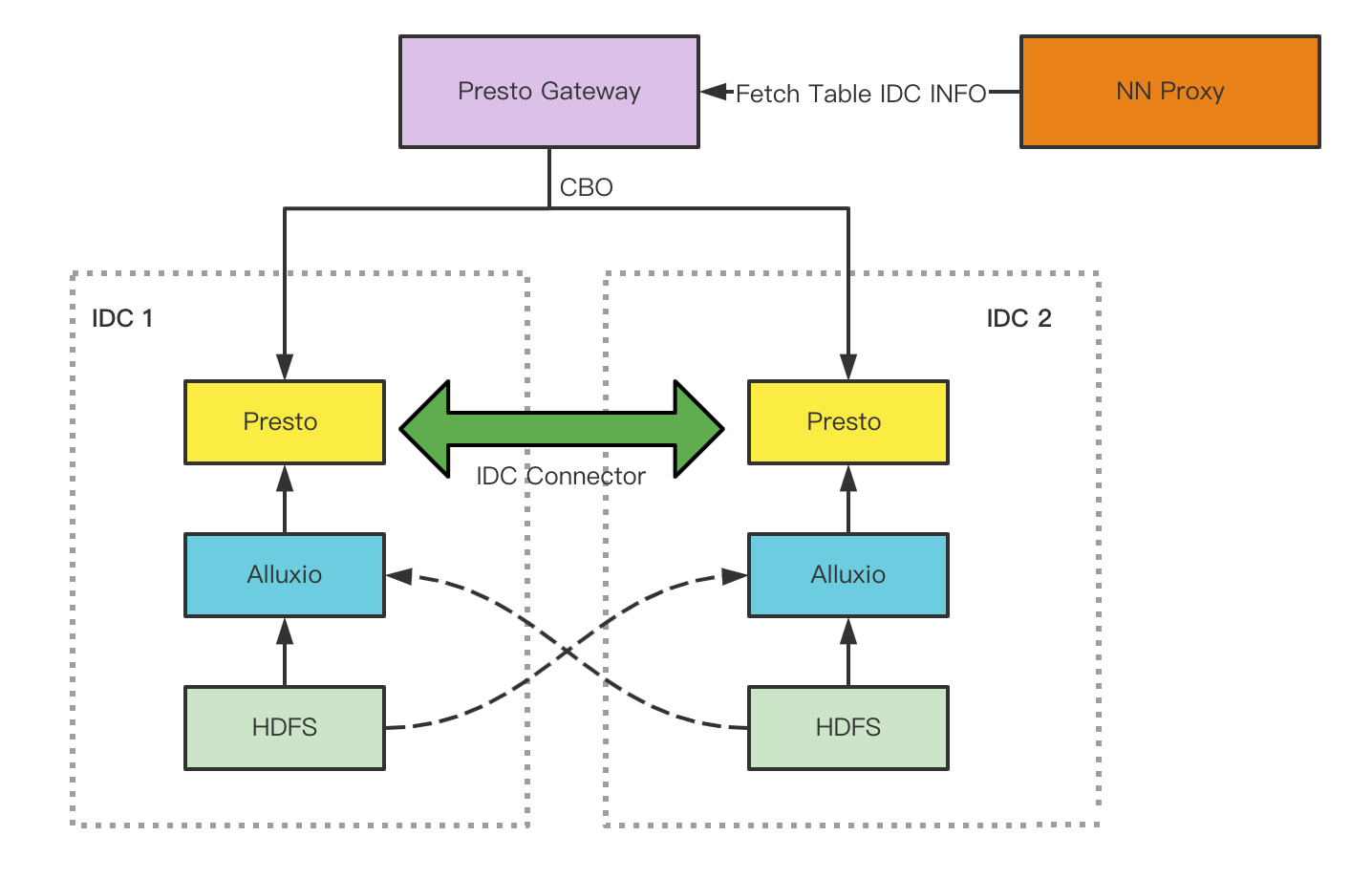
多机房架构
- 用户侧统一接入Presto gateway,每个机房部署独立 集群
- 访问单张表:调度到数据所在机房
- 多表在同一机房,作业路由到数据所在机房
- 多表在不同机房,路由到数据量较大的表所在机房,较小的表限流读
- 实现跨 IDC的计算下推
- 多表访问时,将子查询下推第二机房,再跟主机房合并
- 通过血缘关系找出跨机房热分区,提前预加载到缓存
字节跳动

参考
- 官网
- github
- PrestoCon Day 2022 youtub
- Presto 在 B 站的实践
- Presto 在字节跳动的内部实践与优化(实践篇)
- Presto 在字节跳动的内部实践与优化(优化篇)
- Presto实现原理和美团的使用实践
- Presto 在滴滴的探索与实践
- 一文看懂 VLDB 22 技术趋势及精选论文
- Presto:Meta十年数据分析之旅
- Speed Up Presto at Uber with Alluxio Local Cache
- Engineering Data Analytics with Presto and Apache Parquet at Uber
- Presto at Bytedance youtub
- Data Lake Analytics: Alibaba’s Federated Cloud Strategy
- Forecasting SQL query resource usage with machine learning