Gluten和相关依赖
Gluten
- 主页:https://oap-project.github.io/gluten/
- Gluten Intro Video at Data AI Summit 2022
- Gluten Intro Article at Medium.com
- Gluten Intro Article at Kyligence.io(in Chinese)
- Introducing Velox: An open source unified execution engine
github:https://github.com/oap-project/gluten
早期的 spark 主要的性能瓶颈在 I/O,随着这块的硬件性能提升,软件层面的优化也跟上了
慢慢的,性能瓶颈就不在是 磁盘I/O、网络I/O了
spark 在 2.0 之后采用了全阶段代码生成,之后通过性能 benchmark,已经没有多少能提升的地方了
而 C++ 的计算引擎中,出现了很多向量化计算引擎,这块的性能提升了很多,gluten 也就是想在这块发力的
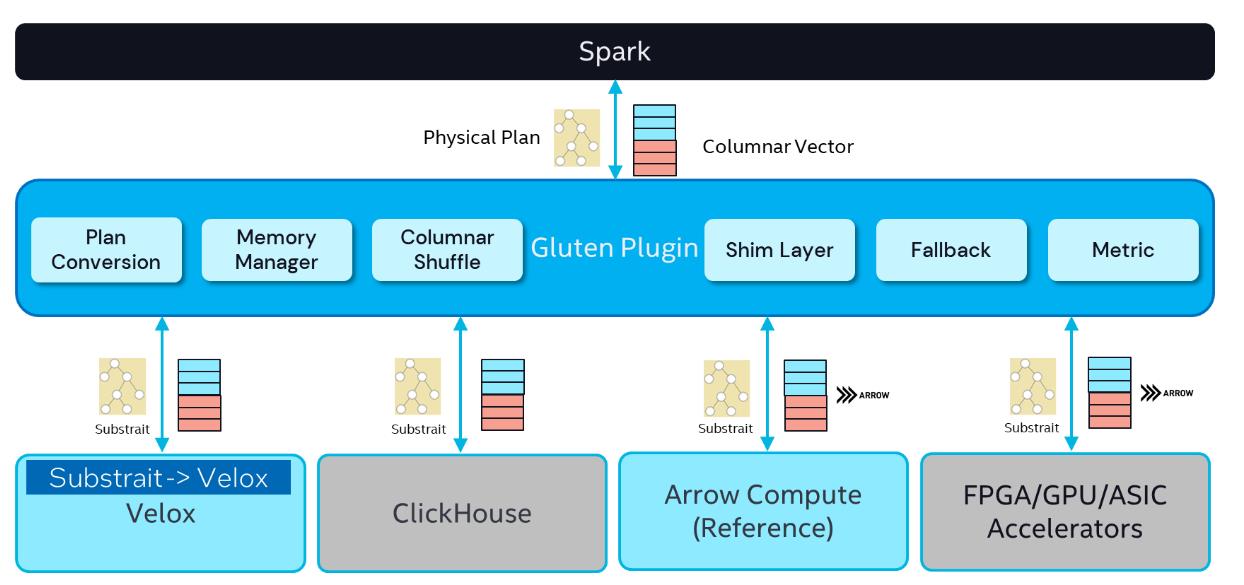
首先把spark 的物理计划翻译为 Substrait 计划,然后将其序列化,发送给 底层的执行引擎
目前支持 Vleox、ClickHouse
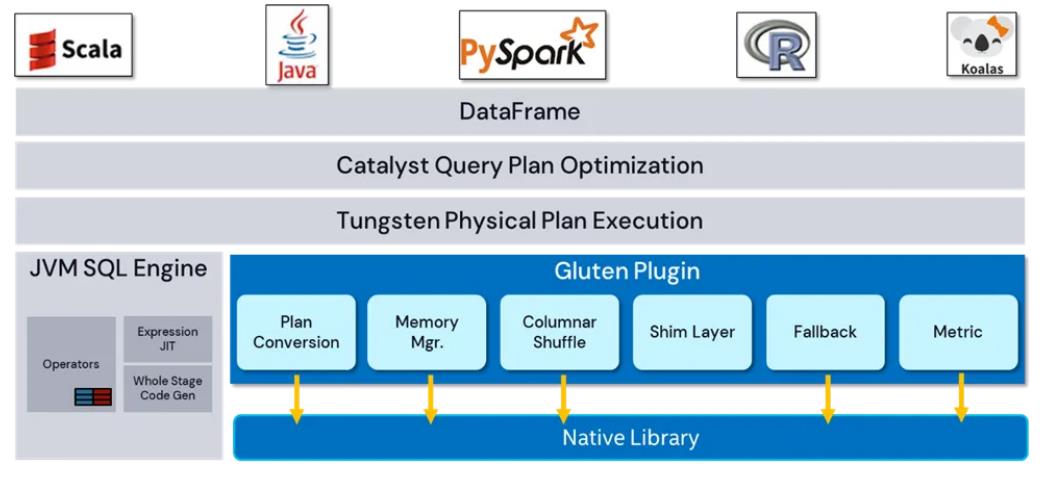
各个组件
- plan conversaion,转换物理计划
- memory manager,内存管理,默认向spark申请,不足会spill 到磁盘
- columnar shuffle,基于列的shuffler
- shim layer,可以集成多个spark版本
- fallback,如果底层不支持,则退回到原生spark执行
- metrics,可以集成到 spark-ui 中
各组件的另一个视角
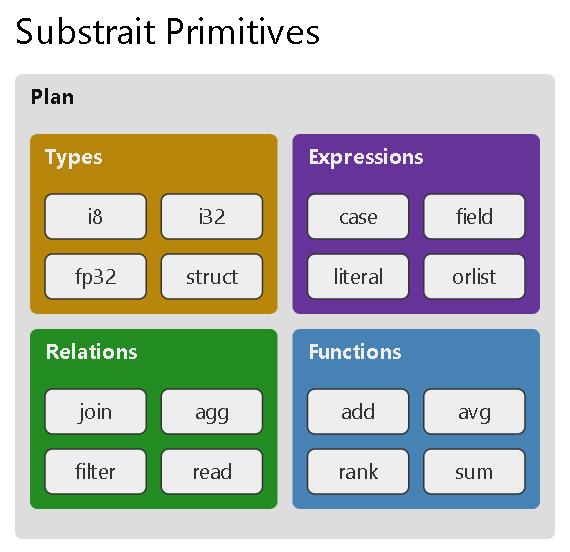
Substrait
demo,两个表:
|
|
查询的 SQL 如下:
|
|
基本类型
更详细的介绍,这里
- 简单类型
- 复杂类型,如结构体等
- 用户定义类型
表达式
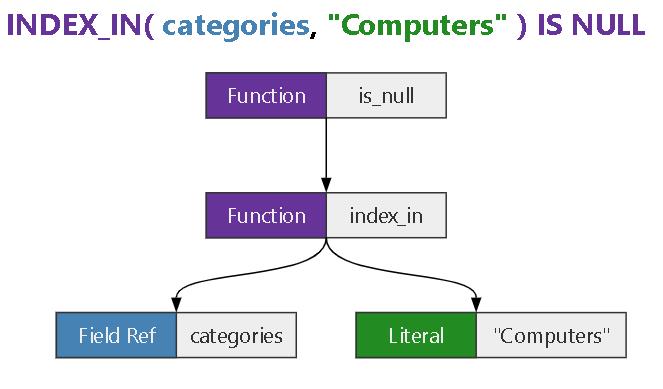
更详细介绍,这里
关系 和序列化
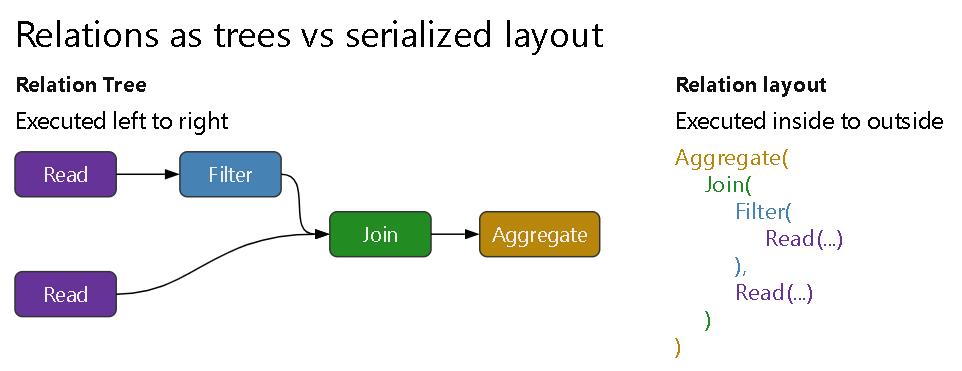
更详细介绍,relations
serialization
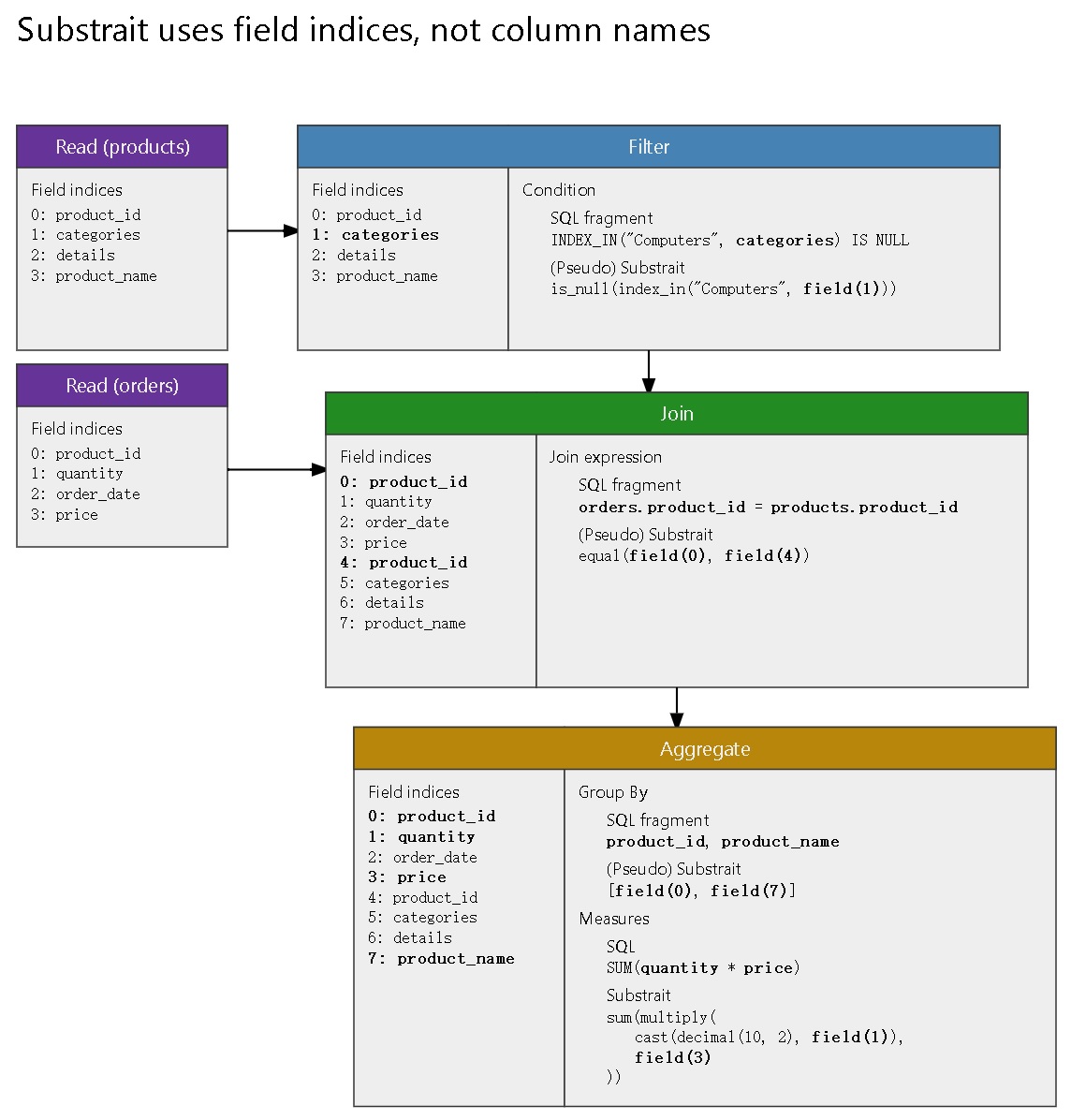
SQL 中的各字段引用,注意这里是做了引用,不是直接使用列名
其他: