TPCx-HS优化总结
背景介绍
TPCx-HS是TPC组织提供的性能测试基准工具 (http://www.tpc.org/tpcx-hs/default.asp),主要目标是评估Hadoop集群的性能和可扩展性。
通过模拟大规模数据处理场景,测试集群在不同负载下的实际性能,包括吞吐量、响应时间、资源利用率等指标。
测试结果可以为用户提供有关Hadoop集群的性能和可扩展性方面的参考数据,以帮助用户做出更好的决策。
TPCx-HS本质上是Hadoop的TeraSort benchmark,通过对TB级数据进行排序,来测试HDFS和MapReduce框架对大规模数据的处理性能。
TPCx HS由以下三个任务组成:
- HSGen:生成大量用于排序的数据并存储于HDFS,数据量可以选择1TB~10000TB,典型测试数据量为1TB、3TB、10TB、30TB
- HSSort:从HDFS上读取TeraGen生成的数据,用MapReduce框架进行排序,并将排序结果结果存储在HDFS中。
- HValidate:排序结果验证,负责对HSSort的排序结果文件进行正确性校验,确认所有数据都按排序键正确排序。
TPCx-HS提供标准测试工具和脚本,仅允许配置执行引擎(MR/Spark)、数据量大小等少量参数。整个测试流程需要按顺序完成两轮(Run1/Run2)完整测试,每轮测试都需要按顺序执行三个任务。两轮测试完成,取较低成绩为最终测试结果。
优化思路
机器配置
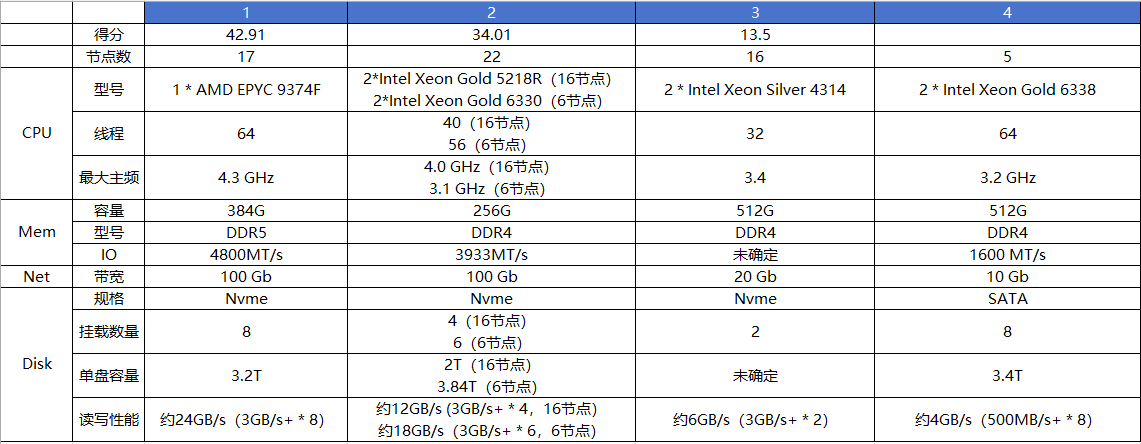
通过对TPCx-HS现有1TB榜单前两两名,以及准备参与的两个企业的硬件配置做一个比较
整体流程分析
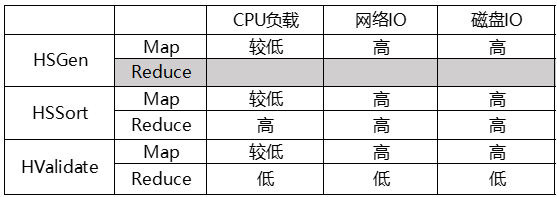
通过对TPCx-HS的流程代码分析,及实际测试,对不同测试阶段的资源占用进行如下分析。可以看出在不同任务阶段,对系统资源要求有所差异,评测结果受硬件性能影响很大。因此需要分别从CPU、网络、磁盘对整个测试系统进行有针对性的优化。
针对此次测试做的主要优化
- Spark编译适配JDK22,可以用到 ZGC(优化三个阶段的整体吞吐量)
- 优化批量写入(优化HSGen和HSSort的磁盘I/O)
- 编译scala将排序部分做成并行化(优化HSSort部分)
- 调整Spark参数(优化三个阶段的执行速度)
一共5台机器,每台机器的角色如下 | 机器编号 |namenode | datanode | Spark-master | Spark-slaver | | – | – | – | – | – | | 10 |Y | y | | Y | | 11 | | Y | Y | Y | | 12 | | Y | | Y | | 13 | | Y | | Y | | 14 | | Y | | Y |
不需要大数据平台组件,全部手动安装,不需要高可用
每个datanode使用 8块盘,读写速度约为 4G/s
检查网络、磁盘,内存读写
|
|
scp 传输检查各节点之间的网络传输速度,确保各个节点网络都正常
|
|
整体目标
- 尽可能让每个节点处理的任务量相差不大
- 尽可能让每个节点的资源,如CPU、内存、I/O等都处理满负荷状态
- 磁盘和网络配比约为 10:7,或者10:8,低于或者高于这个值,可能会出现硬件瓶颈
- 内存尽量多,可以启动更多executor,也可以用于更多的文件系统缓存
- CPU也尽可能多,用于排序的并行计算
Spark版本升级
评测脚本是基于Spark 2.x + Scala
2.11.x编译的,所以此次选用的Spark版本为2.4.8
该版本的Spark从官网获取的信息,以及实际测试只支持JDK 1.8,因此需要使用高版本JDK重新编译
在实际中,我们选择了OpenJDK最新版本JDK 22,因为Spark2.x版本使用的部分JVM函数与新版本JDK不兼容,所以整个编译过程需要根据错误信息进行修改
增加批量写入功能
TPCx-HS代码中,HSGen和HSSort有两个类
- HSOutputFormat
- HadoopHSOutputFormat
分别实现了HadoopRecordWriter接口的write方法
该方法最终会被Spark调用,将数据写入HDFS文件。调用链示意图见下
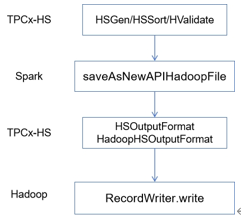
该方法每被调用一次,则写入一行数据,尽管有IO Cache保证写盘效率,但1T测试数据有100亿行,需要调用Java虚函数100亿次
因此需要为Hadoop/Spark以及TPCx-HS增加BatchWrite能力
Hadoop主要增加新接口
|
|
Spark主要增加以下方法
|
|
TPCx-HS需要增加BatchWrite调用,并实现接口BatchWrite接口
|
|
排序优化
创建三个自定义的类
- MyArrays,拷贝自java.util.Arrays,增加一些自定义的函数
- MyTimSort,拷贝自java.util.TimSort
- MyArraysParallelSortHelpers,拷贝自java.util. ArraysParallelSortHelpers
MyArrays中增加的函数为:
|
|
类似这样的函数还有三个,其内容跟原生的类似,只是增加了一个参数,这样就可以设置自定义的并行度了
由于这几个类不依赖任何第三方库,直接用 javac编译,jar命令打成mysort.jar包即可
将mysort.jar 放到$JAVA_HOME/jar/lib/ext 目录下
下载scala源码,代码checkout到 2.11.x,https://github.com/scala/scala/tree/2.11.x
修改 src/library/scala/collection下的 SeqLike.scala,修改sorted函数
|
|
根据环境变量 com_my_sort_nums 判断,是否需要调用 MyArrays类
Scala源码编译命令
|
|
最后结果在 $scala_home/build/pack 目录下,包含bin,lib目录
将spark/jars目录下的 scala-library-2.11.12.jar删除,将bulic/pack/lib 目录下的 scala-library.jar 拷贝过去,将mysort.jar也拷贝过去
使用方式,在spark-defaults.conf 中增加一段:
|
|
通过环境变量设置上即可
Spark参数优化
主要的调整参数
- 修改序列化实现类
- Shuffle写数据到内存上
- Shuffle数据压缩、内存buffer,写盘buffer、线程数、队列大小
- 数据本地性等待时间
- map输出缓冲区大小、reduce端读取缓冲区大小
- 计算内存大小
- 任务并行度
spark-defaults.conf 主要参数调整
|
|
测试工具的 Benchmark_Parameters.sh主要参数
|
|
OS层面优化
需要注意的是,从应用到的系统层,越往下调优的效果可能就越小,系统层面的调整可能不会产生很大影响
调整的参数
内存
- 关闭swap
磁盘
- 关闭XFS的CRC校验
- 关闭XFS的atime
- 对XFS做碎片整理
网络
- 增加TCP的读、写buffer
- 增加TCP的窗口大小
|
|
调整完之后,可以通过 dstat,iostat,vmstat,iftop等命令持续观察效果
单机版本对比
原生
|
|
优化后
|
|
优化后单节点利用率基本满了
参考
- Spark Configuration
- Spark Standalone Mode
- Tuning Spark
- swap space
- XFS
- xfs_info
- XFS file system
- XFS wikipedia
- Tune Operating System Performance
- Linux Performance Analysis in 60,000 Milliseconds
- TCP/IP tuning
- Tuning the Operating System and Platform
- Linux Tune Network Stack (Buffers Size) To Increase Networking Performance
- Tuning the network performance
- Scala github
- Sample FIO Commands for Block Volume Performance Tests on Linux-based Instances
- IO Plumbing tests with FIO
JVM优化
GC调优
通过 GC 日志,或者是 jstat 等命令,找到 GC 的次数,总执行时间,如果 GC 不是瓶颈那么调优的意义就不大了,这部分可以跳过。
如果观察到 GC 有一定的影响,则可以通过参数调优,减少 GC 的时间
可以先记录 GC日志,执行几次,然后用工具分析GC日志,分析工具可以使用在线的 GCeasy
对于服务端,可以用的 GC 算法包括:
- Throughput GC
- CMS
- G1
- ZGC
- Shenandoah
CMS 和 Throughput 自身有一定的缺陷,如果是 JDK 8 可以使用 G1
如果是 JKD11 或者跟高版本,则可以尝试用 ZGC
Shenandoah 跟 ZGC的设计目标一样,都是10ms以内的暂停时间,从目前发展势头看 ZGC更好,特别是 JDK21 ZGC 增加了分带GC又进一步提升了性能
G1调优
调优参数
| 序号 | JVM参数 | 功能解释 |
|---|---|---|
| 1 | -XX:MaxGCPauseMillis | 200,暂停时间 ms |
| 2 | -Xmx |
最大内存,最小内存设置一样 |
| 3 | -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc: |
记录日志,实际运行时关闭 |
| 4 | -XX:MaxMetaspaceSize | 增加元数据空间大小 |
| 5 | -XX:+UseStringDeduplication | 消除重复的 String |
| 6 | -XX:ParallelGCThreads | 设置为核数大小,STW 时并行 GC的线程数 |
| 7 | -XX:ConcGCThreads | 并行GC 线程,CPU核多可以调整 1/5 |
| 8 | -XX:InitiatingHeapOccupancyPercent | 触发 GC 的阈值,默认 45,内存大时,可适当调大 |
| 9 | -XX:+AlwaysPreTouch | 启动的时候分配物理内存页 |
| 10 | -Xbatch -XX:-TieredCompilation | 开启 C2 编译 |
G1调优的注意点
- 不要出现FGC,这相当于是 CMS的并发回收失败,变成SerialGC
- 吞吐量和暂停时间需要做权限,暂停时间短整体吞吐量可能会下降,反之吞吐量提高暂停时间可能会增加
下图吞吐量为 94.613%,暂停时间基本控制还可以
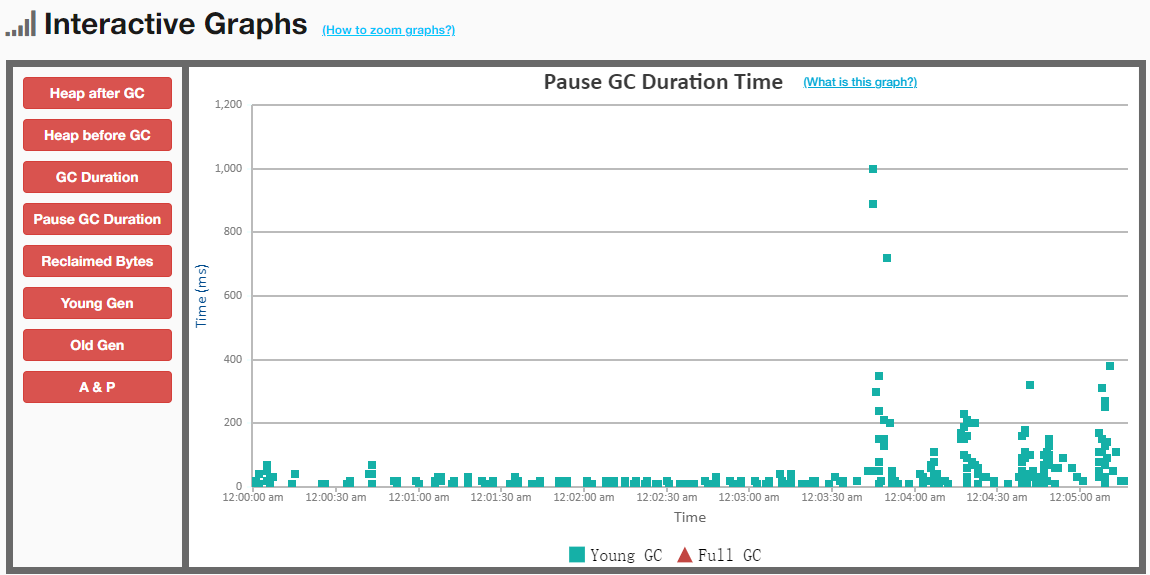
下图的吞吐量为 97.113%,但暂停时间提高了
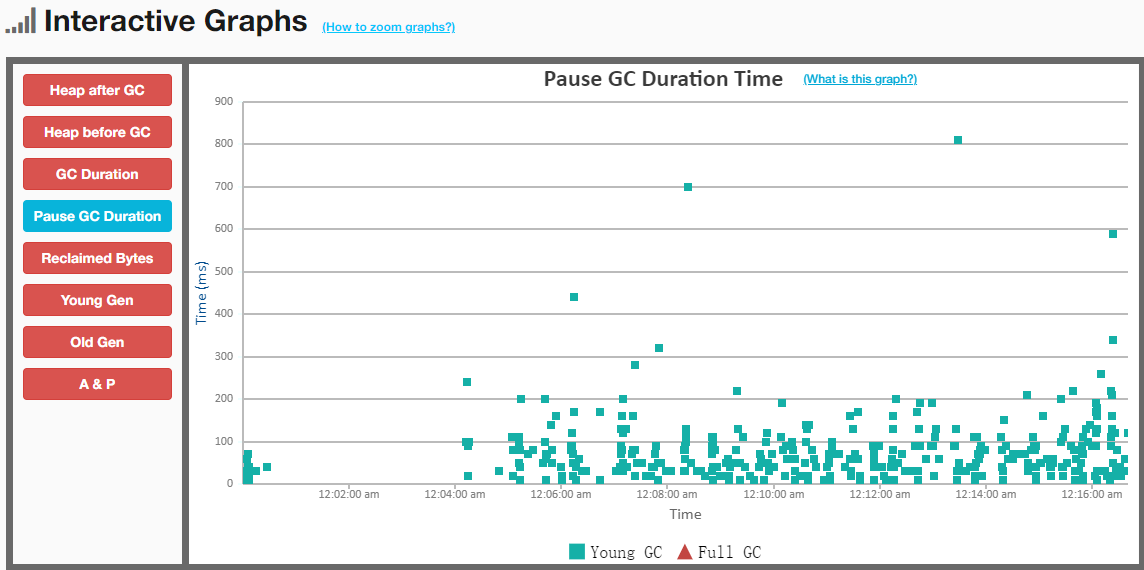
ZGC调优
调优参数
| 序号 | JVM参数 | 功能解释 |
|---|---|---|
| 1 | -XX:+UseZGC -XX:+ZGenerational | 启用 ZGC 的分带功能 |
| 2 | -Xmx |
最大内存,最小内存设置一样 |
| 3 | -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc: |
记录日志,实际运行时关闭 |
| 4 | -XX:-ZUncommit | 未使用的内存不归还给 OS,关闭对低延迟更有利 |
| 5 | -XX:MaxMetaspaceSize | 增加元数据空间大小 |
| 6 | -XX:+UseStringDeduplication | 消除重复的 String |
| 7 | -Xbatch -XX:-TieredCompilation | 开启 C2 编译 |
| 8 | -XX:+UseLargePages | 开启 大page支持 |
| 9 | -XX:+UseTransparentHugePages | 支持透明大page |
| 10 | -XX:+AlwaysPreTouch | 启动的时候分配物理内存页 |
JDK 21 增加了分带GC功能,从暂停时间、CPU开销都进一步降低了,同时也能动态的调整并行线程数,支持8M-16T内存,很多事情都可以自动完成,能调优的不多 注意点
- ZGC扫描的是根对象,需要注意根对象不能太多,如果一些框架分配了大量的对象,则可能导致ZGC扫描时间过长
- 吞吐量和暂时时间也要做平衡,如果吞吐量占用太多,可适当降低并行线程数
ZGC 无论是吞吐量、还是GC时间,比 G1 都有巨大的优势

采样分析
这里的思路是通过工具,连接到JVM内部,然后执行一段时间的采样,最后分析这些采样结果,也就是采样;另一种方式是字节码注入,跟踪一段函数的入参、出参等 采样的结果大致分为两类
- 通过 JFR采样整体指标,观察整个JVM在运行期间的问题
- 火焰图采样调用栈,分析整体函数时间占比
下图是通过JFR执行的一次采样
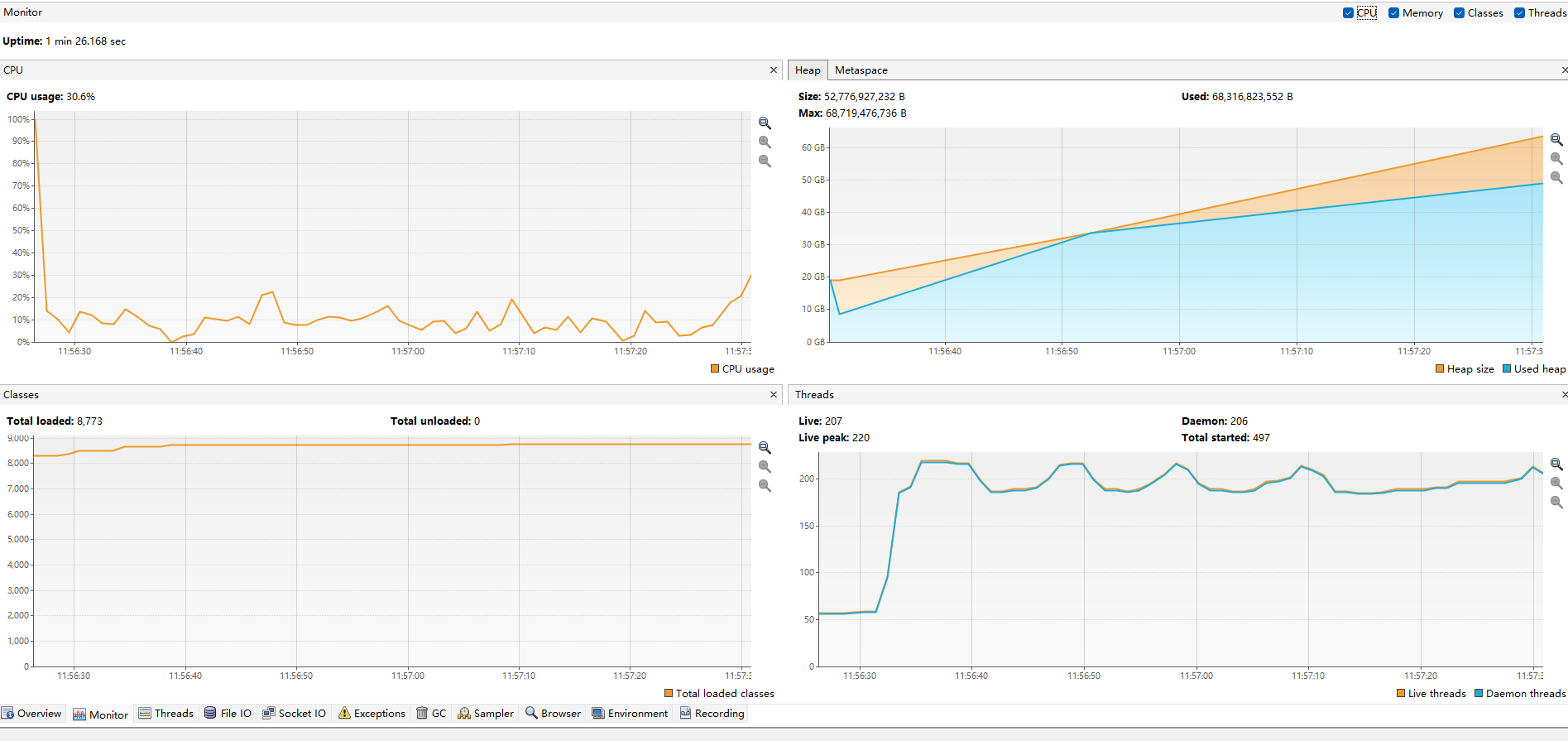
除了上图的系统数据外,还包括
- 线程运行状态分析
- 文件I/O,网络I/O
- 异常分析
- GC分析
- 调用栈执行时间
- CPU、内存执行采样分析
- 环境变量信息等
通过采样结果大致可以分析CPU还比较空闲,所以可以增加一些计算并行度,采样分析的目标是找到潜在的问题,然后再配合代码做一进步调整
除 JFR外,还可以通过开启 JMX,远程连接到 JVM进程内观察其实时运行状态,其展现形式基本跟 JFR采样的差不多,这里不再阐述
下图是对Spark执行排序过程的一个火焰图
- 绿色部分代表Java代码
- 蓝色部分代表第三方库代码
- 黄色部分代表JVM C++代码
- 橙色部分代表内核态C语言代码
- 红色代表用户态C语言代码
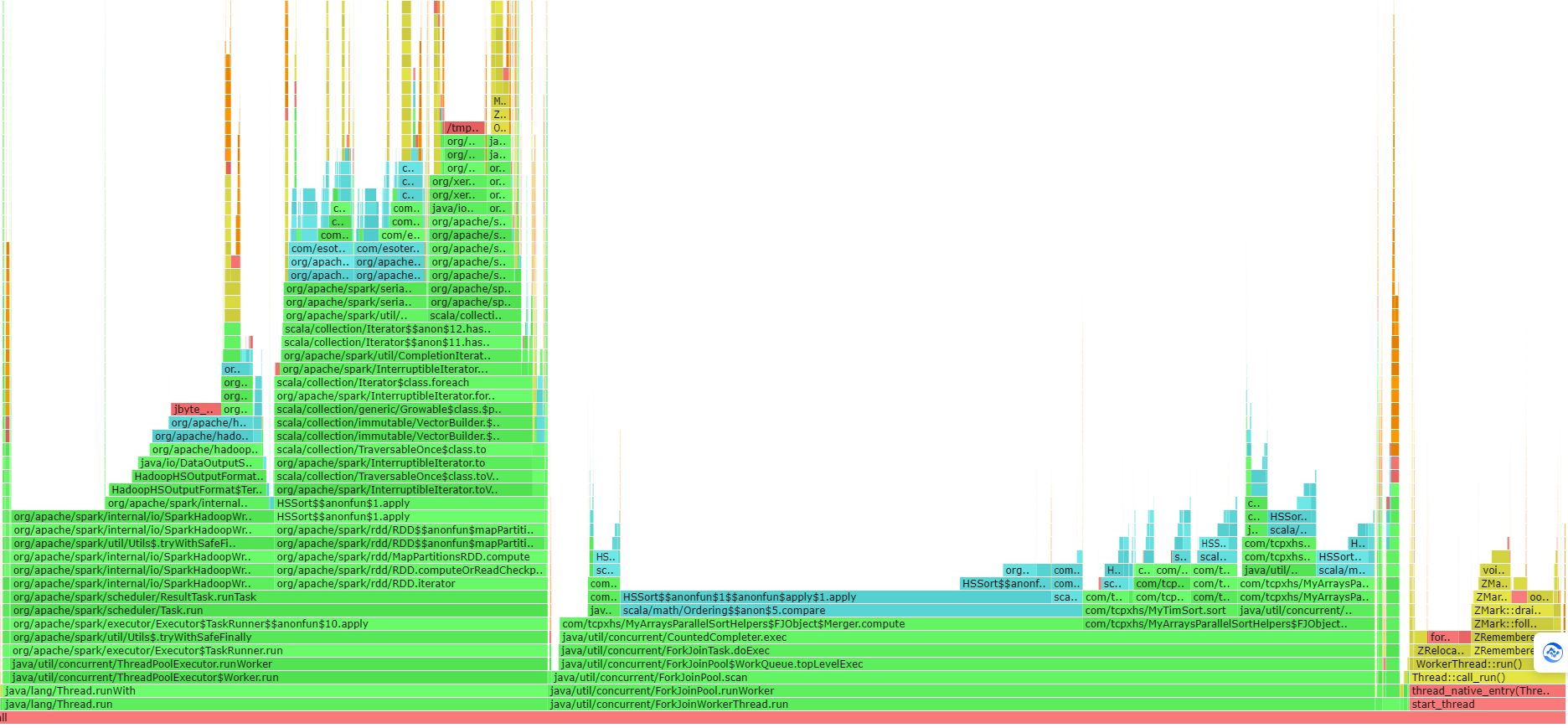
从上图中可以看到不同函数/功能的 总体占比
- ZGC占到了 15%,有点高了,需要适当降低并行GC 线程数
- Shuffle大约占了22%
- 排序部分大约占了 21%
- 迭代部分占了12
- Hadoop写部分占了12%
采样可以多执行几次,因为每次的执行可能会有些不同,多执行几次,大概就清楚某个功能模块的总体时间占比了,像上图的排序部分,它调用的是 JDK的单线程排序,这部分就可以优化
参考
- Garbage-First (G1) Garbage Collector
- OpenJDK ZGC
- Important G1 GC arguments
- Java ZGC algorithm Tuning
- GC easy
- ZGC: The Future of Low-Latency Garbage Collection Is Here(Slides)
- Concurrent thread-stack processing in the Z Garbage Collector(Slides)
- Shenandoah GC
- Shenandoah GC(Slides)
- Deep Dive into ZGC: A Modern Garbage Collector in OpenJDK
- Arthas
- JDK Mission Control
- Java Flight Recorder
- VisualVM
- Jprofiler
- jconsole
- Java® Development Kit Version 21 Tool Specifications
- async-profiler
一些优化思路记录
这里的一些优化思路在实际测试过程都不起效果,但有一些优化的思想可以在其他地方有效,比如gluten可以用在 TPC-H 中,预启动优化可以用于微服务
HDFS缓存
存储分层,冷数据放到归档盘中,热数据放到SSD中,最频繁访问的数据放到内存中,实现读、写加速
|
|
这里的[RAM_DISK]在HDFS 看来只是一个缓存层,之后会异步刷新到磁盘
分配 32G内存
|
|
集中缓存,每个datanode管理一些堆外内存,然后又namenode统一分配
通过cacheadmin 来指定缓存某个 hdfs路径
|
|
不起效果的原因
- 文件系统本身是有缓存的,通过free 等命令观察内存,会发现读写过程中cache部分是在不断增加的
- 当执行到校验部分时,需要从HDFS读取数据做校验,但dstat看此时并没有I/O,说明读的是文件系统缓存
- 因为读、写磁盘时本身就通过了缓存,再给HDFS额外加一层缓存,就没什么效果了
预启动优化
启动JVM虚拟机需要加载class,对class做校验,再生成内存格式,当类很多的时候,就需要很长时间加载
GraalVM是一个新的VM,其主要优化思想
- 将编译后的class文件,直接编译成目标平台的二进制文件,可以提升10-20倍的启动时间
- GraalVM在运行期优化方面做了很多工作,尤其是内联和逃逸分析,比原生的JDK有更好的优化效果
对比启动时间原生 JDK 22
|
|
编译成二进制后
|
|
JDK9 新增了 jatoc命令,用于将一个JVM运行期的内存格式dump出来,之后的JVM再启动时候就可以直接读取这个内存dump,从而加速启动
在之后的JDK中将这个命令废弃了,JDK13开始又将这个功能重新做了提案又开发出来了,目前这个功能用于微服务等小型应用的比较多,但没看到用于大型分布式项目的
不起效果的原因
- 将class文件编译成二进制只适合小型规模的项目,Spark有codegen和动态类加载无法这么编译
- GraalVM对于OpenJDK22,其优化效果不明显
- 类共享功能在OpenJDK22默认就打开了,而对于大型项目,目前看也没有这么用的
向量化
向量化的本质是利用了CPU的SIMD指令集,一条指令集可以执行多个任务,从而达到并行的效果
JVM本身对于向量化支持的比较弱,直到JDK21,关于向量化的API仍然在孵化过程中,在这个领域C++ 支持的是比较好的,C++可以调用更底层的系统库实现加速效果
一般Java的项目也都是将密集型的执行任务,交给底层的C++计算引擎完成
Spark在这个方向上有两个开源实现
- Blaze(rust 实现) +Apache Arrow DataFusion(rust实现)
- Gluten(C++实现) + facebook velox(C++实现)
Blaze 和 gluten只是一个转发层,真正的核心是DataFusion和velox,目前看这两个的成熟度差不多
但是转发层gluten比blaze要活跃很多,所以选择向量化最好是选gluten
Gluten实际对接的后端引擎有两个,velox和clickhouse,从官网支持力度和文档来看,gluten对velox的兼容度更好
Spark将其物理执行计划,转为Substrait执行计划,序列化为protobuf格式通过JNI交给C++层
C++层反序列化后,得到了Substrait执行计划,然后根据这个执行计划直接执行

Gluten官网提供了预编译好的jar包,但是不能使用,需要在centos8上重新编译
gluten 的组成和 依赖:
- arrow,apache 的开源项目,先要编译这个
- velox,facebook 的向量化引擎,依赖 arrow
- c++ 部分,依赖 velox,第三个编译
- java 部分,最后编译
编译环境
- GCC 11.2.1
- Cmake 3.16.9
- JDK 1.8
- Maven 3.8.5
编译的麻烦点在于Apache Arrow,以及velox,这两个都需要重新源码编译,尤其前者依赖了很多其他库,也都需要源码编译
而国内的网络限制需要手动下载,再修改cmake文件,将实际的https地址换成本地的http://localhost:9999 这样的地址
Gluten 的c++比较编译比较简单,java部分如果是新环境,需要从头下载非常多的依赖,光下载可能需要一天时间
不起效果的原因
-
文件格式定死了必须是行格式,使用向量化就需要行转列、列转行有很大开销
-
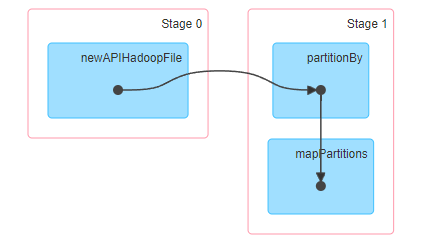
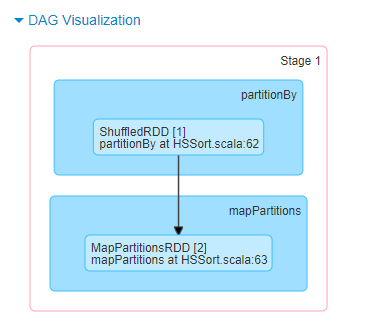
整个过程非常简单,排序就是读取数据,然后做排序,这里的算子很简单,调用的是scala的sortBy,见下图
-
由于调用的是高阶算子,无法转换成gluten的物理计划
-
测试过程是不允许修改jar包,所以只能使用2.x版本的Spark,gluten只能用于Spark3.2和3.3,实际是没法用于测试的
-
参考
HDFS cache
- Memory Storage Support in HDFS
- Centralized Cache Management in HDFS
- Archival Storage, SSD & Memory
- HDFS Disk Balancer
ahead-of-time compilation
- GraalVM
- OracleGraalVM
- GraalVM github
- Apache Spark—Lightning fast on GraalVM Enterprise
- GraalVM at Facebook
- CDS and AppCDS in Hotspot
- Class Data Sharing
- Improve Launch Times On Java 13 With Application Class-Data Sharing
- JEP 350: Dynamic CDS Archives
- JEP 341: Default CDS Archives
- JEP 310: Application Class-Data Sharing
- Ahead-of-time compilation wikipedia
gluten
- gluten github
- gluten
- Accelerate Spark SQL Queries with Gluten
- Introducing Velox: An open source unified execution engine
- velox
- velox github
- velox documentaion
- Velox: Meta’s Unified Execution Engine
- Xsimd
- Xsimd github
- Substrait
- Substrait github
- Apache Arrow documentation
- Apache Arrow github
- Intel® Intrinsics Guide
- Advanced Vector Extensions wikipedia
- jdk.incubator.vector API
- Java 18: Vector API — Do we get free speed-up?
- JEP 448: Vector API (Sixth Incubator)
- The jmod Command
- x86-simd-sort
- SIMD accelerated sorting in Java - how it works and why it was 3x faster
- A Novel Hybrid Quicksort Algorithm Vectorized using AVX-512 on Intel Skylake
- Java Programming Tutorial Java Native Interface (JNI)
- Photon: A Fast Query Engine for Lakehouse Systems
- blaze github
- Apache Arrow DataFusion