数据摄取:架构和模式
Overview
本质上来说,data ingestion 就是把运营平面的数据,同步到 分析平面中,这样就可以解锁 分析平面的所有能力了
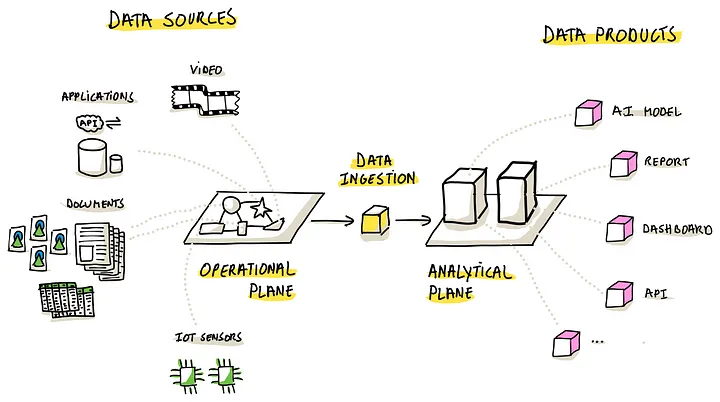
企业的分析平台需要对 各种数据源做分析,因此选择合适的 data ingestion 策略就很重要
这个 data ingestion 必须覆盖各种场景
- 比如标准的应用,CRM、ERP、金融系统等
- 非结构的数据,如 IoT传感器
- 还有 API,各种文档、图片、视频等
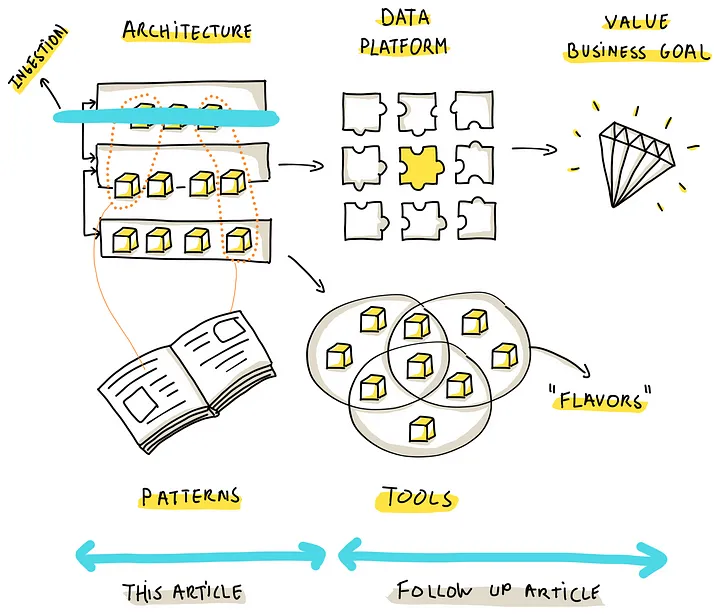
其中,数据平台由各种架构模式、各种工具组成,他们在其中扮演重要的功能、有效性的角色
本文介绍架构范式,指导选择合适的数据摄取策略,并指出其背后的本质
Pattern
Pattern 1: Unified Data Repository
这种模式就是 一个数据库,同时处理 OLTP、OLAP 数据
好处是简单,消除了数据同步的需要
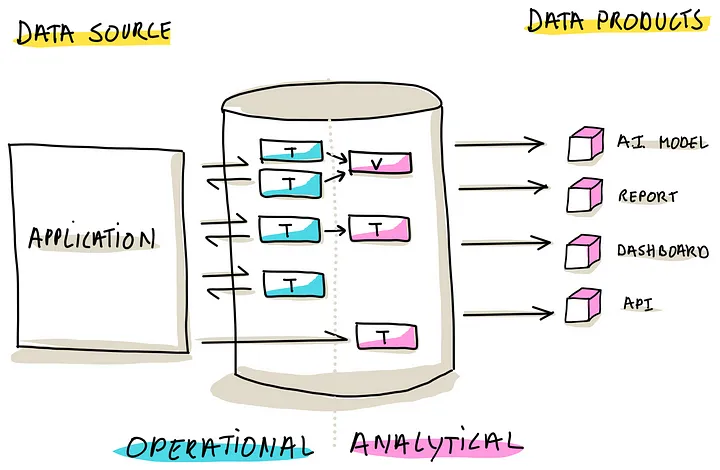
这种方式又分为两种 子模式
- Virtualization,在 OLTP 表之上建立视图,为 OLAP 使用
- Duplication and Transformation,在原 OLTP 表之上,建立物化视图,或者复制一份表,供 OLAP 使用
这种模式的限制
- Data Integration Challenges,因为是一个数据库来管理 OLAP、OLTP,如果数据源种类很多,就不好处理,需要跨数据源查询,带来复杂度
- Potential for System Interference,OLTP、OLAP 同时使用导致相关干扰
- Performance Trade-offs,OLTP 的场景跟 OLAP 复杂查询的场景不同,很难同时兼顾优化两个场景
- Tightly Coupled,导致 OLTP 和 OLAP 层的紧耦合,降低了灵活性
这种模式,适合数据集不大的场景,或者数据源种类较少的场景
Pattern 2: Data Virtualization
这种模式利用了特殊的软件,在多个底层的源之上,建立了数据虚拟层
也就是通过一个中间件整合底层的数据,做汇总后返回给 分析层
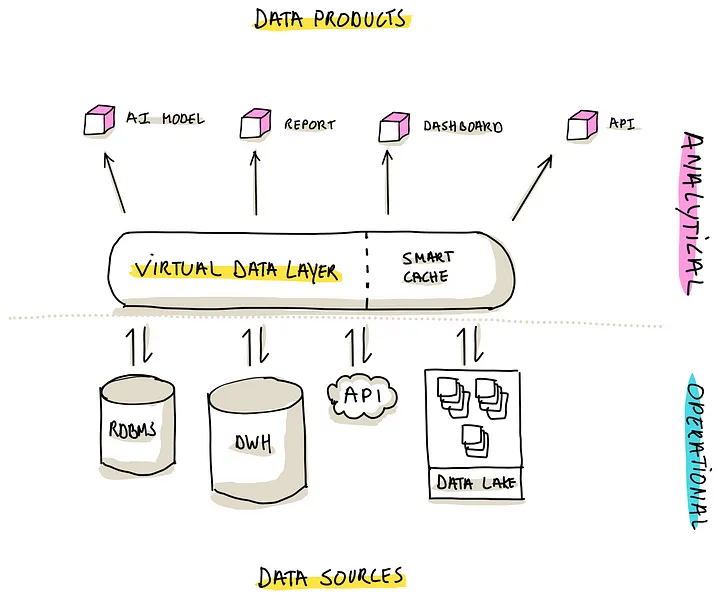
这种模式的好处
- Near-Real-Time Data Access,因为没有物理数据,访问的都是原始数据集,所以能提供 近实时的查询
- Intelligent Caching,通过整合了 cache,可以对底层系统的影响最小,也能提升性能
这种模式的限制
- Source System Limitations,如果底层系统对特定查询没有优化,则会影响到上层的访问
- Network Overhead,可能需要跨多个机房做跨数据源查询,有一定的延迟
- Historical Data Tracking,由于不存物理数据,没有做历史分离,也就是 time travel
使用这种模式时,需要详细的测试 底层基础设置,了解其限制和能力,这样才能更好的整合、优化这种模式
Pattern 3: ETL
这种就是标准的 ETL,Extract,Transform,Load 操作
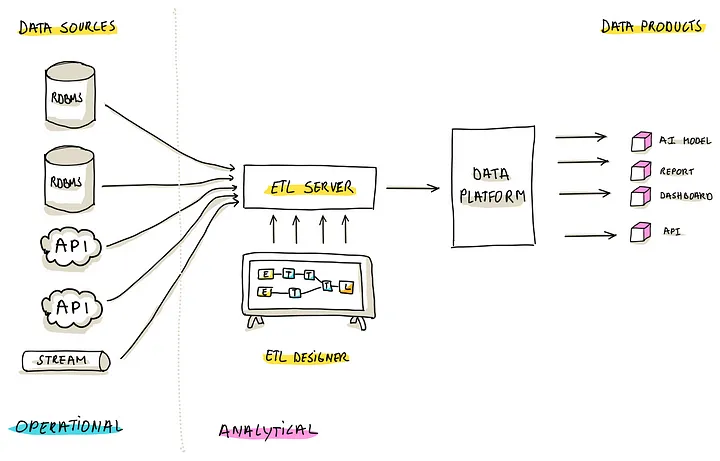
现在有很多这种 ETL 工具,还有直观的图形界面,方便用户观察细节
用户还可以通过脚本、SQL 来直接操作
这种管道方式的好处
- Centralized Logic,不光利用了数据摄取的能力,同时将数据塑造成满足 分析场景的模式
- User-Friendly Design,可视化的 ETL可以让不同技能的用户都能参与进来
Pattern 4: ELT
类似于 ETL,但是有些不同
- EL,首先直接 提取、加载操作,而转换操作直接在目标数据平台上完成,但不是立即转换的
- T,随后才发生的操作,这个操作是独立的,可以跟 EL 操作隔离开
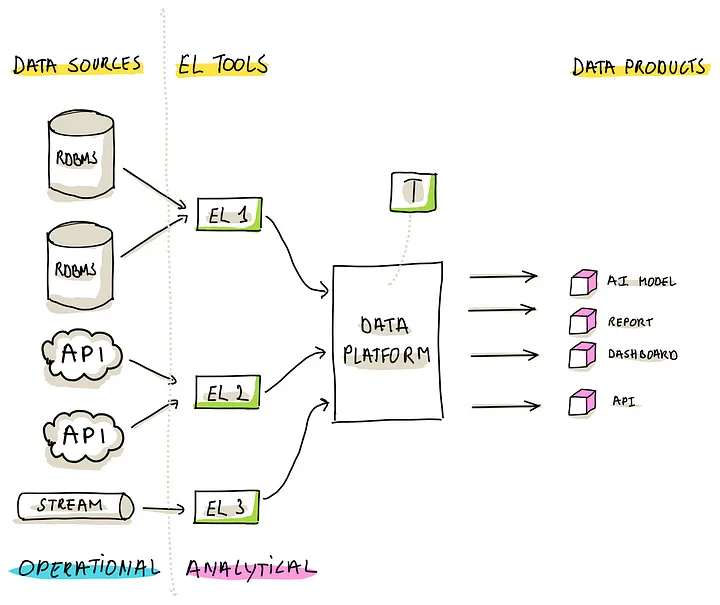
这种模式解决了 ETL 的几个问题
- Enhanced Flexibility,由于将 转换操作单独拿出来了,所以增强了灵活性,可以为不同的数据类型、转换标准选择不同的工具
- Aligned Performance,利用了数据平台的计算能力,可以做并行处理
- Improved Scalability,有助于选择自动化,可伸缩性方面的工具
这个模式的缺点
- Governance of Multiple Tools,使用不同的工具做 EL、T,需要严格的治理来管理许可、定价、更新周期和支持结构
- Orchestration Challenges,需要一个更好的工具来支持编排,基于 DAG 来确保转换发生在 EL 之后
Emerging Patterns
Push (vs Pull)
传统的模式是 pull 的方式,也就是 分析平台主动的从运营平台 拉取数据
而 push 模式,是运行平台将数据 push 到分析平台,只要源端发生了 create、read、update、delete CRUD 操作
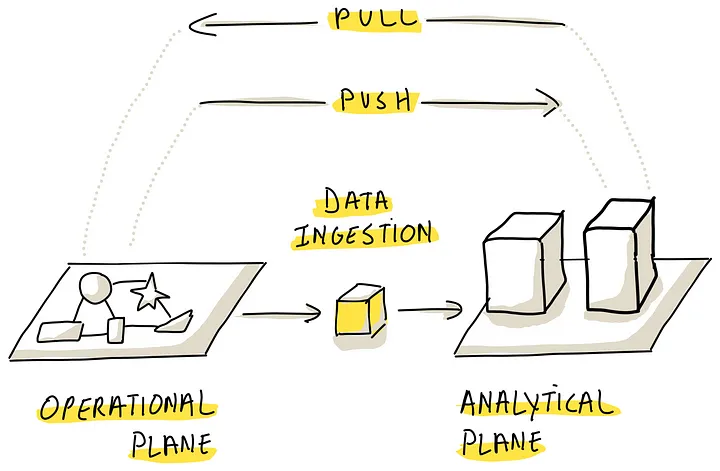
这种模式下主要用于流系统,但不止于此,运营平面需要额外的组件来扩展这个功能,或者在运营平板新增一些功能
这样就使得 分析平面只需要考虑 转换问题,而不需要考虑数据摄取管道相关的事情
这种方式的缺点
- Requirement for a dedicated application development team,需要额外的团队来完成这些任务
- Handling Push Failures,pull失败了只要重试即可,但是push失败了 分析平面感知不到,需要设计高可用,高并发的 push流系统
这种模式下,需要组织有很高的软件开发成熟度,否则需要跟其他方案配合使用
Stream Processing
流处理系统,适合大数据量、低延迟的系统,如金融交易、实时分析和物联网监控
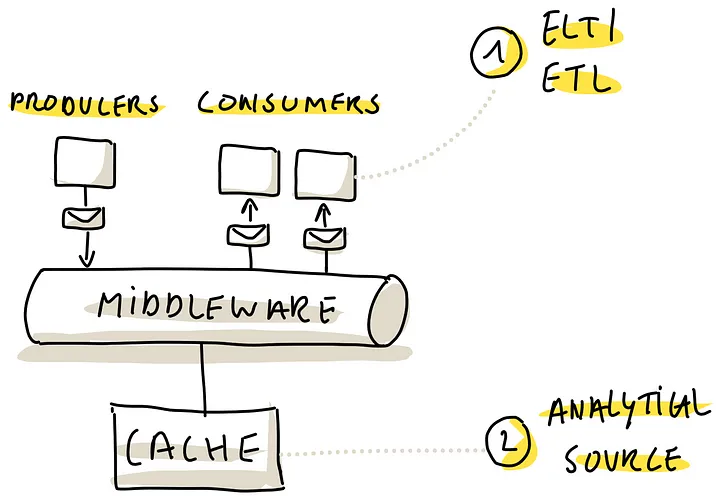
有两个好处
- Adapting ELT (or even ETL) for Streaming,可以提取实时的事件,并加载到分析平台
- Leveraging Streaming Caches,利用流cache作为一个数据源,相当于共享数据存储的变体,但要注意静态数据cache问题
Kappa、Lambda 则是统一两个世界的架构
Conclusions
提供了 5 种模式
- Unified Data Repository,最简单,但是限制了伸缩性
- Data Virtualization,提供了实时的能力,但限制了性能
- ETL,独立了两个平台的能力,但是也有性能瓶颈,僵化、不灵活
- ELT,很灵活,伸缩性很好,但是需要额外的编排
- 新兴的流处理模式,提供了实时性,提供了动态的方式获取数据