Query Acceleratio
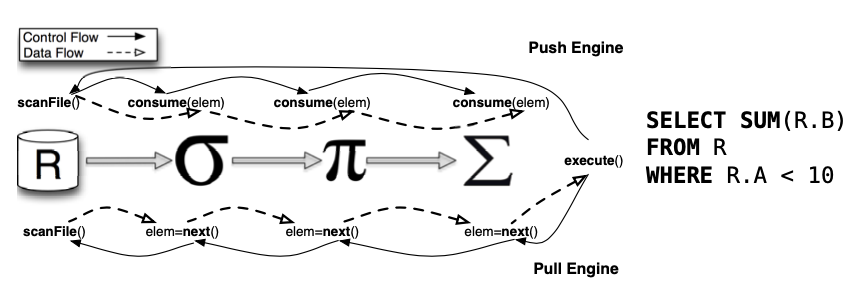
Pipeline Execution Engine
对原先的 火山模型的增强,更合适现代 CPU
优点
- 从pull 变成 push 数据
- 阻塞的算子变成异步的
- 执行的线程可控
参数
1
2
3
4
5
|
-- 开启
set enable_pipeline_engine = true;
-- 设置并行度
set parallel_pipeline_task_num = 0;
|
Nereids-the Brand New Planner
新增了一套 优化算法
- RBO,这里可能类似 Spark 的模式匹配规则,可以适配更复杂的查询
- CBO,使用了 cascades 框架
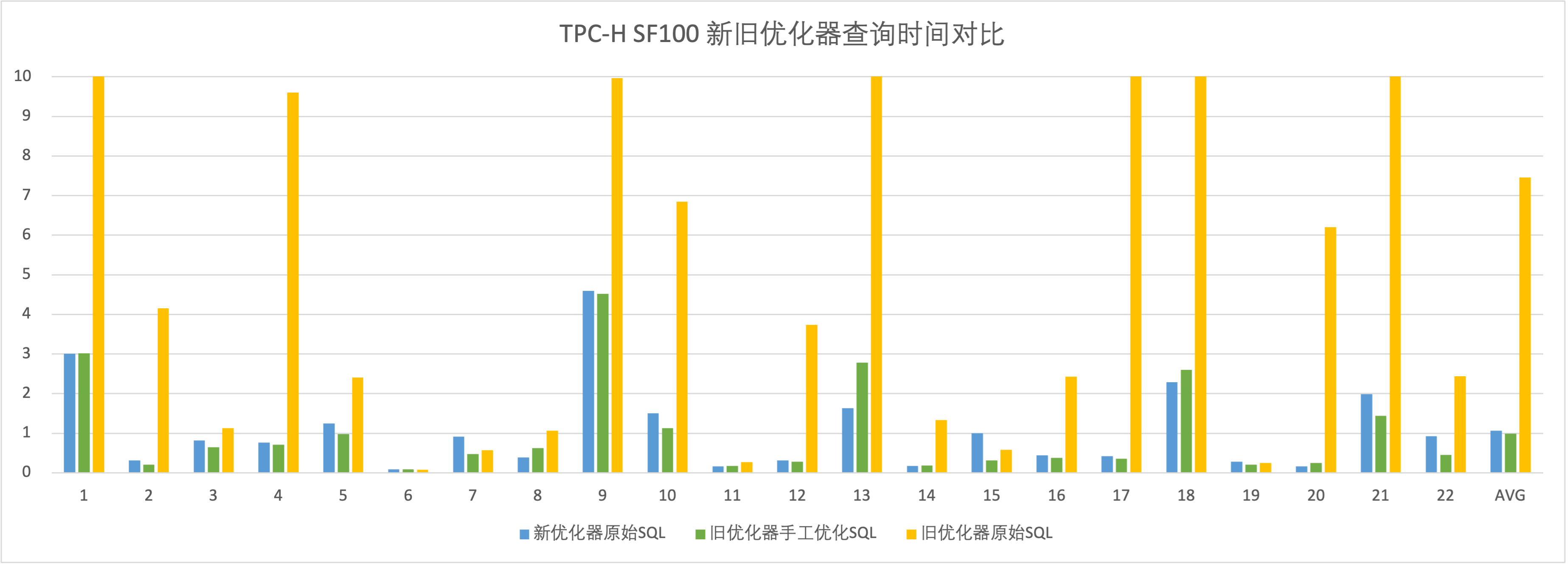
新老优化器对比
调整
1
2
3
4
5
|
-- 开启
SET enable_nereids_planner=true;
-- fall back 到老的优化器
SET enable_fallback_to_original_planner=true;
|
High-Concurrency Point Query
doris 默认是列存的,但是对于 点查询就不好了,尤其是列很多的情况下
doris 也支持行存,键表的时候可以指定
1
|
"store_row_column" = "true"
|
一个例子,这里使用了 Merge-On-Write 策略
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
CREATE TABLE `tbl_point_query` (
`key` int(11) NULL,
`v1` decimal(27, 9) NULL,
`v2` varchar(30) NULL,
`v3` varchar(30) NULL,
`v4` date NULL,
`v5` datetime NULL,
`v6` float NULL,
`v7` datev2 NULL
) ENGINE=OLAP
UNIQUE KEY(`key`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`key)` BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"enable_unique_key_merge_on_write" = "true",
|
使用 PreparedStatement 加速查询,只支持单表等值 where 条件
1
2
3
4
5
6
7
8
9
10
|
url = jdbc:mysql://127.0.0.1:9030/ycsb?useServerPrepStmts=true
// use `?` for placement holders, readStatement should be reused
PreparedStatement readStatement = conn.prepareStatement("select * from tbl_point_query where key = ?");
...
readStatement.setInt(1234);
ResultSet resultSet = readStatement.executeQuery();
...
readStatement.setInt(1235);
resultSet = readStatement.executeQuery();
...
|
默认的 cache 是针对 列的,也有另外的针对行的 cache
- disable_storage_row_cache
- row_cache_mem_limit
Materialized View
是 Rollup 的超集
一个物化视图可以匹配多个查询,在一个表上创建多个物化视图不推荐
支持的聚合函数
- SUM, MIN, MAX (Version 0.12)
- COUNT, BITMAP_UNION, HLL_UNION (Version 0.13)
doris 自动维护 基表,物化视图之间的一致性
当 insert 到基表后,自动插入到 物化视图,这是一个同步操作,更新完物化视图后,才算 insert 成功
创建表和 物化视图
1
2
3
4
5
6
7
8
9
10
11
12
13
|
create table duplicate_table(
k1 int null,
k2 int null,
k3 bigint null,
k4 bigint null
)
duplicate key (k1,k2,k3,k4)
distributed BY hash(k4) buckets 3
properties("replication_num" = "1");
create materialized view k1_k2 as
select k2, k1 from duplicate_table;
|
查看
1
2
3
4
5
6
7
8
9
10
11
12
|
desc duplicate_table all;
+-----------------+---------------+-------+--------+--------------+------+------+---------+-------+---------+------------+-------------+
| IndexName | IndexKeysType | Field | Type | InternalType | Null | Key | Default | Extra | Visible | DefineExpr | WhereClause |
+-----------------+---------------+-------+--------+--------------+------+------+---------+-------+---------+------------+-------------+
| duplicate_table | DUP_KEYS | k1 | INT | INT | Yes | true | NULL | | true | | |
| | | k2 | INT | INT | Yes | true | NULL | | true | | |
| | | k3 | BIGINT | BIGINT | Yes | true | NULL | | true | | |
| | | k4 | BIGINT | BIGINT | Yes | true | NULL | | true | | |
| | | | | | | | | | | | |
| k1_k2 | DUP_KEYS | mv_k2 | INT | INT | Yes | true | NULL | | true | `k2` | |
| | | mv_k1 | INT | INT | Yes | true | NULL | | true | `k1` | |
+-----------------+---------------+-------+--------+--------------+------+------+---------+-------+---------+------------+-------------+
|
The use of materialized views is generally divided into the following steps:
- Create a materialized view
- Asynchronously check whether the materialized view has been constructed
- Query and automatically match materialized views
限制
- delete 的列不在物化视图中,则需要手动维护
- 单个表不能有太多物化视图,如果有10个会严重影响 import 速度,相当于要导入 10个表
- Unique Key model,只能更改列的顺序,不能执行聚合
- 有些查询重写,可能会导致 物化视图 命中失败
Statistics
Currently, the following information is collected for each column:
| Information |
Description |
| row_count |
Total number of rows |
| data_size |
Total data size |
| avg_size_byte |
Average length of values |
| ndv |
Number of distinct values |
| min |
Minimum value |
| max |
Maximum value |
| null_count |
Number of null values |
手动收集
1
2
3
|
ANALYZE < TABLE | DATABASE table_name | db_name >
[ (column_name [, ...]) ]
[ [ WITH SYNC ] [ WITH SAMPLE PERCENT | ROWS ] ];
|
采样 10%
1
|
ANALYZE TABLE lineitem WITH SAMPLE PERCENT 10;
|
收集 100,000 rows
1
|
ANALYZE TABLE lineitem WITH SAMPLE ROWS 100000;
|
show语法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
SHOW [AUTO] ANALYZE < table_name | job_id >
[ WHERE [ STATE = [ "PENDING" | "RUNNING" | "FINISHED" | "FAILED" ] ] ];
show analyze 245073\G;
*************************** 1. row ***************************
job_id: 245073
catalog_name: internal
db_name: default_cluster:tpch
tbl_name: lineitem
col_name: [l_returnflag,l_receiptdate,l_tax,l_shipmode,l_suppkey,l_shipdate,\
l_commitdate,l_partkey,l_orderkey,l_quantity,l_linestatus,l_comment,\
l_extendedprice,l_linenumber,l_discount,l_shipinstruct]
job_type: MANUAL
analysis_type: FUNDAMENTALS
message:
last_exec_time_in_ms: 2023-11-07 11:00:52
state: FINISHED
progress: 16 Finished | 0 Failed | 0 In Progress | 16 Total
schedule_type: ONCE
|
查看列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
SHOW COLUMN [cached] STATS table_name [ (column_name [, ...]) ];
show column stats lineitem(l_tax)\G;
*************************** 1. row ***************************
column_name: l_tax
count: 6001215.0
ndv: 9.0
num_null: 0.0
data_size: 4.800972E7
avg_size_byte: 8.0
min: 0.00
max: 0.08
method: FULL
type: FUNDAMENTALS
trigger: MANUAL
query_times: 0
updated_time: 2023-11-07 11:00:46
|
session级别的配置
- auto_analyze_start_time
- auto_analyze_end_time
- enable_auto_analyze
- huge_table_default_sample_rows
- huge_table_lower_bound_size_in_bytes
- huge_table_auto_analyze_interval_in_millis
- table_stats_health_threshold
- analyze_timeout
- auto_analyze_table_width_threshold
fe 配置
- analyze_record_limit
- stats_cache_size
- statistics_simultaneously_running_task_num
- statistics_sql_mem_limit_in_bytes
Join Optimization
Bucket Shuffle Join
详细设计在 这个 issues
现有的两个 join,执行 A join B:
- Broadcast Join,需要将 B 发送到 三个 A 的node 上,网络开销 3B,内存开销 3B
- Shuffle Join,网络开销 A + B,内存开销 B
Bucket Shuffle Join 原理
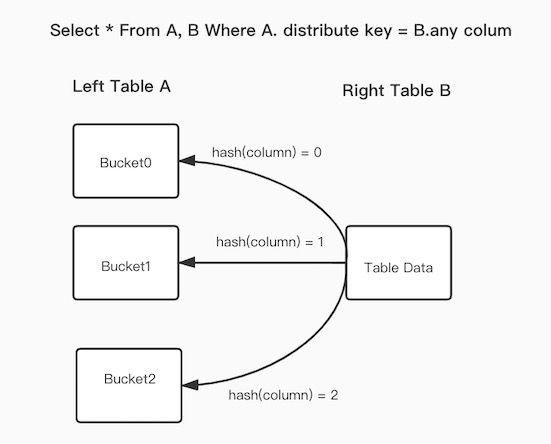 执行过程
执行过程
- 首先计算出 左表 A 的所有列分布,计算出 hash值
- 将 hash值和分布情况发送到 B节点
- B 节点做拆分,将数据拆分后发送到 A 的三个 node 上
- 总发送的数据量就是 B,如果 node 节点多,则发送的数据量大幅降低
例子
1
2
3
|
-- 开启
set enable_bucket_shuffle_join = true;
select * from test join [shuffle] baseall on test.k1 = baseall.k1;
|
1
2
3
4
5
6
7
8
9
|
| 2:HASH JOIN
|
| | join op: INNER JOIN (BUCKET_SHUFFLE)
|
| | hash predicates:
|
| | colocate: false, reason: table not in the same group
|
| | equal join conjunct: `test`.`k1` = `baseall`.`k1`
|
The join type indicates that the join method to be used is:BUCKET_SHUFFLE
使用原则
- 对用户透明
- join 条件必须是 等值的
- 左表的 列类型,必须跟 右表的列类型一致,因为要计算 hash 用的
- 只能用于 doris 自己的表
- 分区表时,只能确保左表时单分区,所以要 where 条件尽可能做分区裁剪
- 如果左表是 colocate 表,数据分布规则是确定的,则 bucket shuffle join 效果会更好
Colocation Join
详细设计在 这个 issue
将 partition 再分成若干个 buckets,确保 buckets Mth 落在一个确定的 node上
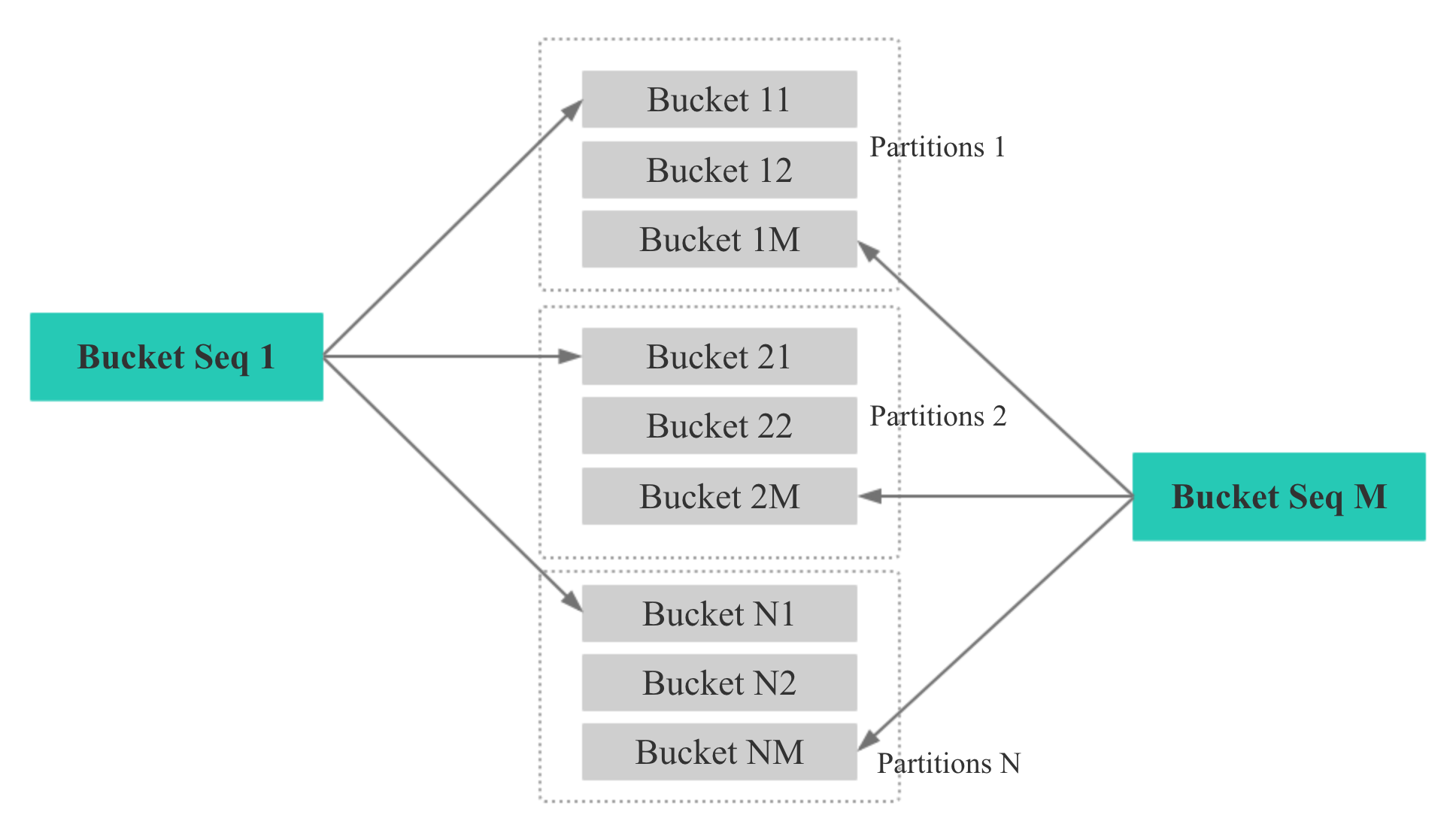
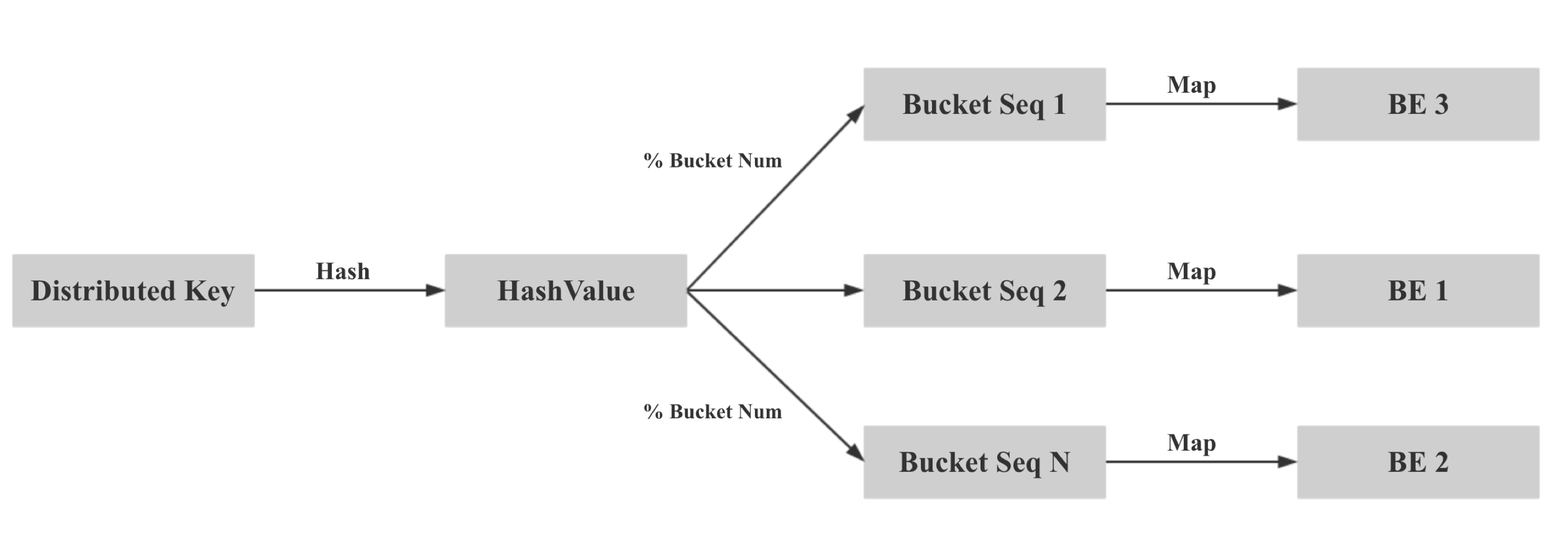
然后按照一定的映射规则,将 distributed key 做 hash 计算,落到某个固定的 buckets seq 上
这里实际是 mod bucket num 做的,然后再将 bucket seq 映射到某个固定的 node 上
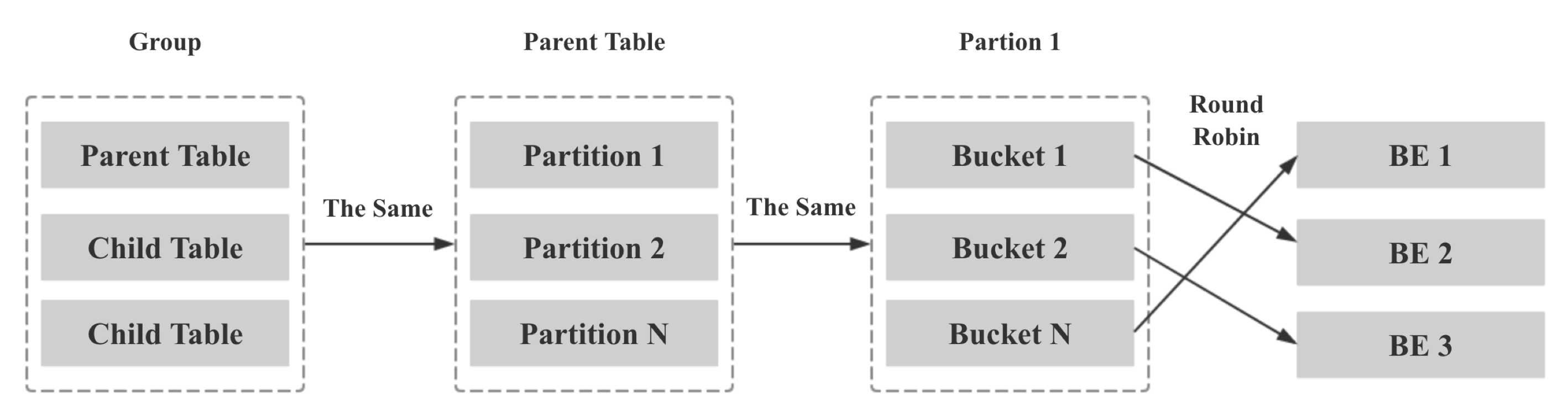
将 bucket seq 映射到 某个 固定 node,是根据 roudn robin 做的
这里还有 parent table,child table,目前已经没有了,早起的设计跟最终实现有些些不同
创建表
1
2
3
4
5
6
7
|
CREATE TABLE tbl (k1 int, v1 int sum)
DISTRIBUTED BY HASH(k1)
BUCKETS 8
PROPERTIES(
"colocate_with" = "group1",
"replication_num" = "1"
);
|
查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
SHOW PROC '/colocation_group';
+-----------------+----------------+----------+------------+-------------------------+----------+----------+----------+
| GroupId | GroupName | TableIds | BucketsNum | ReplicaAllocation | DistCols | IsStable | ErrorMsg |
+-----------------+----------------+----------+------------+-------------------------+----------+----------+----------+
| 1345111.1346358 | 1345111_group1 | 1346340 | 8 | tag.location.default: 1 | int(11) | true | |
+-----------------+----------------+----------+------------+-------------------------+----------+----------+----------+
SHOW PROC '/colocation_group/1345111.1346358';
+-------------+--------------------------+
| BucketIndex | {"location" : "default"} |
+-------------+--------------------------+
| 0 | 1346034 |
| 1 | 1346034 |
| 2 | 1346034 |
| 3 | 1346034 |
| 4 | 1346034 |
| 5 | 1346034 |
| 6 | 1346034 |
| 7 | 1346034 |
+-------------+--------------------------+
|
如果 colocate 节点发生变化,节点宕机等等,Stable 属性就变成 false,join 的时候会退化为 普通 join
创建两个表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
CREATE TABLE `tbl1` (
`k1` date NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` int(11) SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
PARTITION BY RANGE(`k1`)
(
PARTITION p1 VALUES LESS THAN ('2019-05-31'),
PARTITION p2 VALUES LESS THAN ('2019-06-30')
)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1",
"replication_num" = "1"
);
CREATE TABLE `tbl2` (
`k1` datetime NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` double SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1",
"replication_num" = "1"
);
|
查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
DESC SELECT * FROM tbl1 INNER JOIN tbl2 ON (tbl1.k2 = tbl2.k2);
+------------------------------------------------------------------------------------------------------+
| Explain String |
+------------------------------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| k1[#12] |
| k2[#13] |
| v1[#14] |
| k1[#15] |
| k2[#16] |
| v1[#17] |
| PARTITION: UNPARTITIONED |
| |
| VRESULT SINK |
| |
| 3:VEXCHANGE |
| offset: 0 |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: k2[#4] |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 03 |
| UNPARTITIONED |
| |
| 2:VHASH JOIN |
| | join op: INNER JOIN(COLOCATE[])[] |
| | equal join conjunct: k2[#4] = k2[#1] |
| | runtime filters: RF000[in_or_bloom] <- k2[#1](1/1/1048576) |
| | cardinality=1 |
| | vec output tuple id: 3 |
| | vIntermediate tuple ids: 2 |
| | hash output slot ids: 0 1 2 3 4 5 |
| | |
| |----0:VOlapScanNode |
| | TABLE: default_cluster:demo.tbl2(tbl2), PREAGGREGATION: OFF. Reason: No aggregate on scan. |
| | partitions=0/1, tablets=0/0, tabletList= |
| | cardinality=1, avgRowSize=0.0, numNodes=1 |
| | pushAggOp=NONE |
| | |
| 1:VOlapScanNode |
| TABLE: default_cluster:demo.tbl1(tbl1), PREAGGREGATION: OFF. Reason: No aggregate on scan. |
| runtime filters: RF000[in_or_bloom] -> k2[#4] |
| partitions=0/2, tablets=0/0, tabletList= |
| cardinality=1, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
+------------------------------------------------------------------------------------------------------+
|
join 部分显示:join op: INNER JOIN(COLOCATE[])[]
使用到了 colocate join 了
如果没有用到,则可能会显示 BROADCAST 等信息
同时显示 colocate join 失败的原因,如:colocate: false, reason: group is not stable
一些 fe 参数
- disable_colocate_relocate
- disable_colocate_balance
- disable_colocate_join
- use_new_tablet_scheduler
还可以通过 API(需要认证),展示 colocate 配置,Stable、UnStable,等
Runtime Filter
就是一种运行期的 filter,可以让 大表 扫描出更少的数据,这样 join 的效率更高
1
2
3
4
5
6
7
8
9
|
| > HashJoinNode <
| | |
| | 6000 | 2000
| | |
| OlapScanNode OlapScanNode
| ^ ^
| | 100000 | 2000
| T1 T2
|
|
甚至可以将 filter 下推到数据源层
1
2
3
4
5
6
7
8
9
|
| > HashJoinNode <
| | |
| | 6000 | 2000
| | |
| OlapScanNode OlapScanNode
| ^ ^
| | 6000 | 2000
| T1 T2
|
|
使用
1
2
3
4
5
|
CREATE TABLE test (t1 INT) DISTRIBUTED BY HASH (t1) BUCKETS 2 PROPERTIES("replication_num" = "1");
INSERT INTO test VALUES (1), (2), (3), (4);
CREATE TABLE test2 (t2 INT) DISTRIBUTED BY HASH (t2) BUCKETS 2 PROPERTIES("replication_num" = "1");
INSERT INTO test2 VALUES (3), (4), (5);
|
查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
EXPLAIN SELECT t1 FROM test JOIN test2 where test.t1 = test2.t2;
+-------------------------------------------------------------------+
| Explain String |
+-------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| t1[#4] |
| PARTITION: UNPARTITIONED |
| |
| VRESULT SINK |
| |
| 4:VEXCHANGE |
| offset: 0 |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: t1[#1] |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 04 |
| UNPARTITIONED |
| |
| 3:VHASH JOIN |
| | join op: INNER JOIN(BUCKET_SHUFFLE)[] |
| | equal join conjunct: t1[#1] = t2[#0] |
| | runtime filters: RF000[in_or_bloom] <- t2[#0](-1/0/2097152) |
| | cardinality=1 |
| | vec output tuple id: 3 |
| | vIntermediate tuple ids: 2 |
| | hash output slot ids: 1 |
| | |
| |----1:VEXCHANGE |
| | offset: 0 |
| | |
| 2:VOlapScanNode |
| TABLE: default_cluster:demo.test(test), PREAGGREGATION: ON |
| runtime filters: RF000[in_or_bloom] -> t1[#1] |
| partitions=1/1, tablets=2/2, tabletList=1346417,1346419 |
| cardinality=1, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
| |
| PLAN FRAGMENT 2 |
| |
| PARTITION: HASH_PARTITIONED: t2[#0] |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 01 |
| BUCKET_SHFFULE_HASH_PARTITIONED: t2[#0] |
| |
| 0:VOlapScanNode |
| TABLE: default_cluster:demo.test2(test2), PREAGGREGATION: ON |
| partitions=1/1, tablets=2/2, tabletList=1346425,1346427 |
| cardinality=1, avgRowSize=0.0, numNodes=1 |
| pushAggOp=NONE |
+-------------------------------------------------------------------+
|
限制
- 支持 in,min,max,bloom filter
- 只支持等值条件
Doris Join Optimization Principle
支持两种 hash
- Hash Join
- Nest Loop Join.
Shuffle way
-
BroadCast Join,支持 hash 和 nest loop,类似于spark 的 BHJ,BNLP
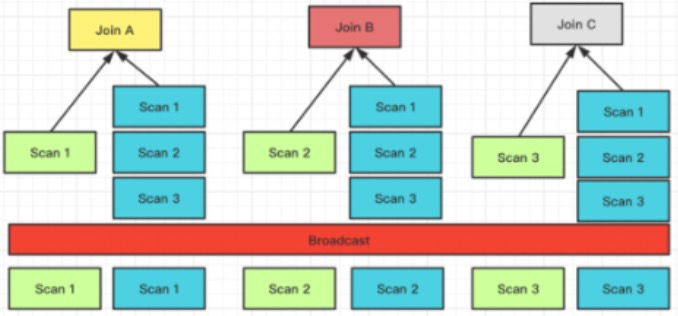
-
Shuffle Join,只支持 hash,类似于 spark 的 SHJ
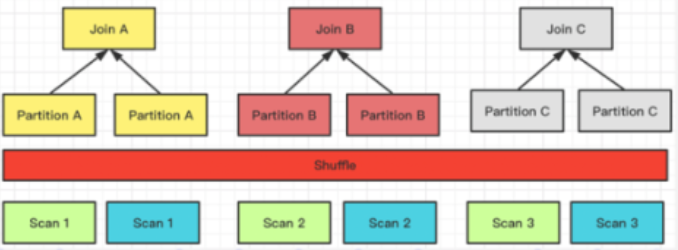
-
Bucket Shuffle Join,B 将数据拆分,将对应部分发送到不同节点上
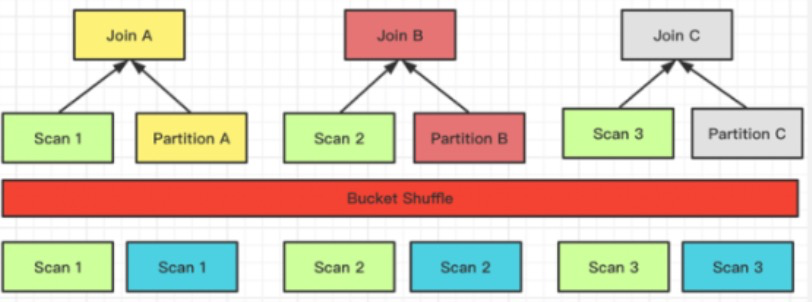
-
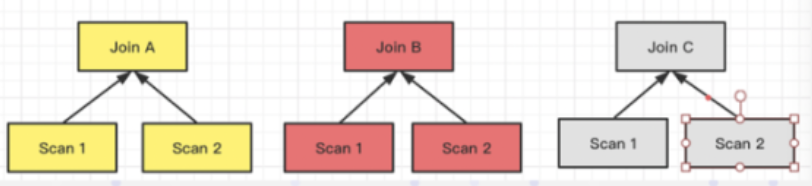
Colocation,两个表的数据完全按照预定的分布,没有网络开销
| Shuffle Mode |
Network Overhead |
Physical Operators |
Applicable Scenarios |
| BroadCast |
N * T(R) |
Hash Join / Nest Loop Join |
Universal |
| Shuffle |
T(S) + T(R) |
Hash Join |
General |
| Bucket Shuffle |
T(R) |
Hash Join |
There are distributed columns in the left table in the join condition, and the left table is executed as a single partition |
| Colocate |
0 |
Hash Join |
There are distributed columns in the left table in the join condition, and the left and right tables belong to the same Colocate Group |
Runtime Filter Type
- In
- min,max
- Bloom Filter
Join Reader,当前支持的 join reoder 规则
- 大表 join 小表,中间结果尽可能小
- 将带条件的 join 表往前放
- hash join 的优先级比 nest loop join 更高
Doris Join tuning method
- 利用 profile,这里有非常详细的执行信息
- 了解 jion 的机制
- 使用session变量更改行为
- 检查 查询计划
Optimization case practice
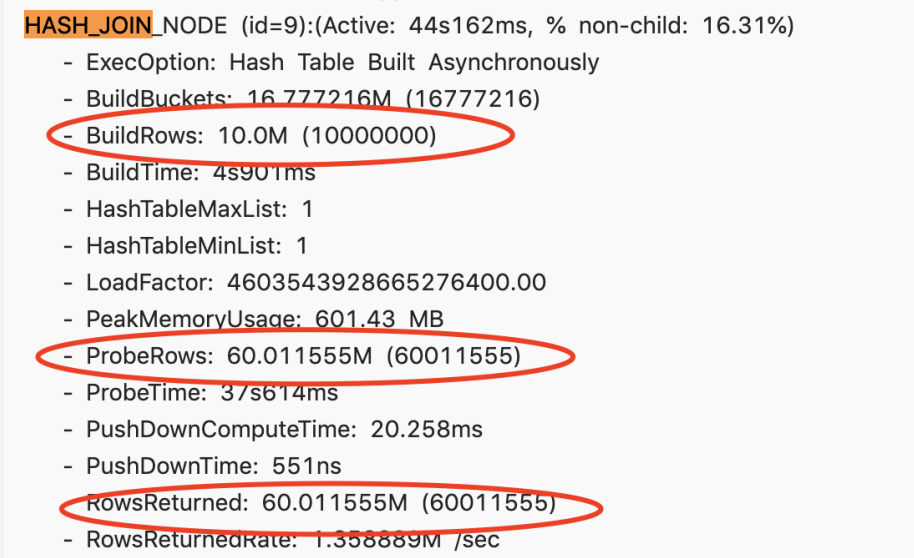
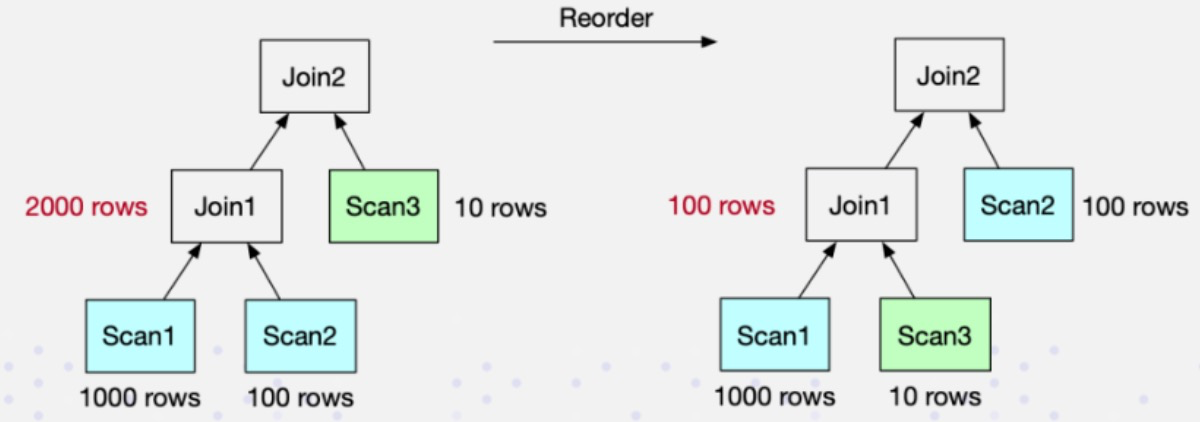
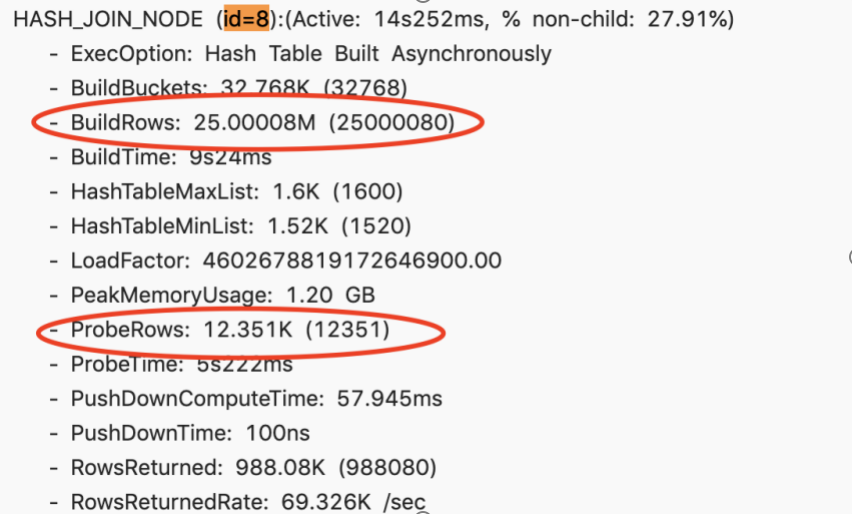
- case 1
四个表的 join,检查 profile,build rows 左表太大,probe rows 右表太小
调整 join order
1
|
set enable_cost_based_join_reorder = true
|
之后就好很多了
1
2
3
4
5
6
7
8
9
10
|
select 100.00 * sum (case
when P_type like 'PROMOS'
then 1 extendedprice * (1 - 1 discount)
else 0
end ) / sum(1 extendedprice * (1 - 1 discount)) as promo revenue
from lineitem, part
where
1_partkey = p_partkey
and 1_shipdate >= date '1997-06-01'
and 1 shipdate < date '1997-06-01' + interval '1' month
|
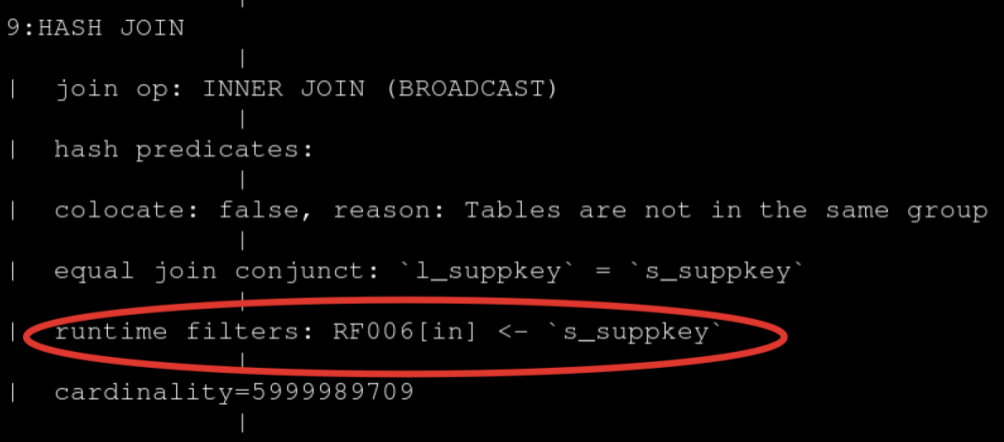
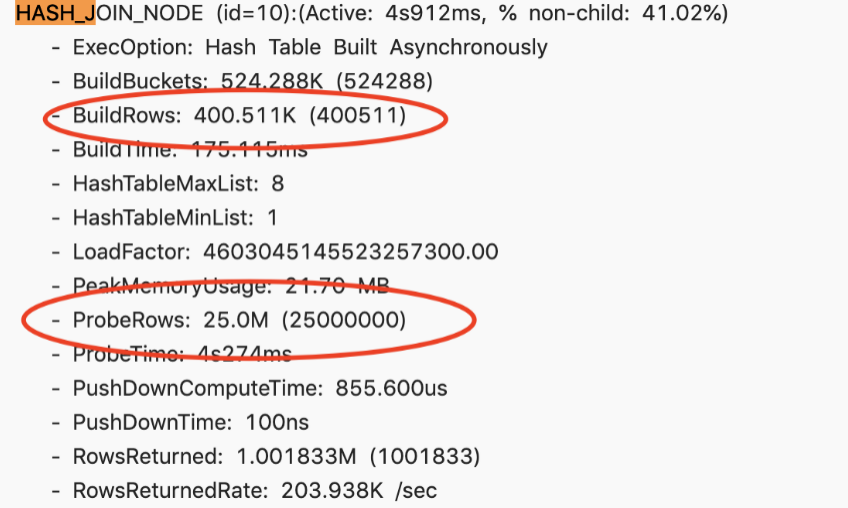
左表很小,因为经过了两次 filter过滤,但是却选择了 大表做为 build
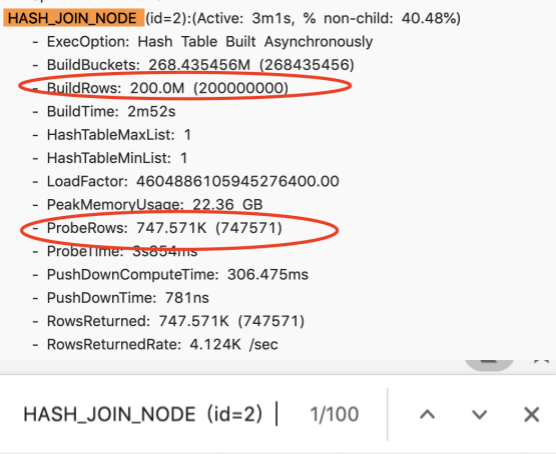
这是因为 doris 还没有足够的信息,收集这些统计数据,导致错误的 join order
可以手动调整,将上 join hint,使用 shuffle 方式,这样就能提升很多
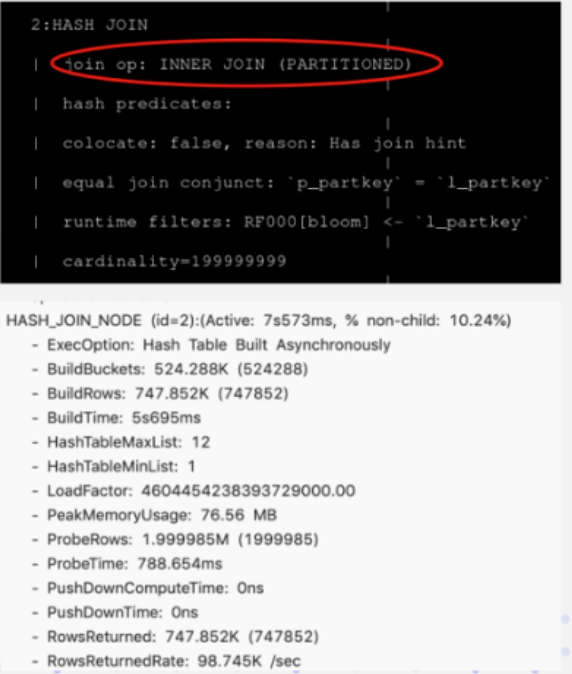
Doris Join optimization suggestion
- 选择简单类型做join,匹配的类型要相等,避免cast
- 选择 key 列作为 join 条件,这对延迟物化也有效果
- 两个大表做 join,选择 Co-location 方式,这样就避免了网络开销,因为大表join 的网络开销会很大
- Runtime Filter 在高选择率时效果非常好,但可能会有副作用,需要根据场景细粒度调整 sql
- 多表 join 的时候,确保左表时大表,右表 build 表是小表,hash 的效果比 nest loop好,必要时可以用 hint 调整
Lakehouse
Multi-catalog
Multi-catalog Overview
让doris 可以做数据湖分析,联邦查询
之前是两层结构,database -> table,现在是三层结构
catalog -> database -> table
目前支持的数据源
- Apache Hive
- Apache Iceberg
- Apache Hudi
- Elasticsearch
- JDBC
- Apache Paimon(Incubating)
基本命令
1
2
3
|
SHOW CATALOGS
SWITCH internal;
SWITCH hive_catalog;
|
创建 hive 外部 catalog
1
2
3
4
|
CREATE CATALOG hive PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://172.21.0.1:7004'
);
|
元数据刷新,支持
- hive: Hive MetaStore
- es: Elasticsearch
- jdbc: standard interface for database access (JDBC)
1
2
3
4
5
6
|
-- Set the catalog refresh interval to 20 seconds
CREATE CATALOG es PROPERTIES (
"type"="es",
"hosts"="http://127.0.0.1:9200",
"metadata_refresh_interval_sec"="20"
);
|
也支持 ranger 做鉴权
Hive
Iceberg, Hudi 也用 hive metasotre作为元数据层,所以兼容 hive metastore 的系统也可以被访问到
配置 ha
1
2
3
4
5
6
7
8
9
10
|
CREATE CATALOG hive PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://172.0.0.1:9083',
'hadoop.username' = 'hive',
'dfs.nameservices'='your-nameservice',
'dfs.ha.namenodes.your-nameservice'='nn1,nn2',
'dfs.namenode.rpc-address.your-nameservice.nn1'='172.21.0.2:8088',
'dfs.namenode.rpc-address.your-nameservice.nn2'='172.21.0.3:8088',
'dfs.client.failover.proxy.provider.your-nameservice'='org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider'
);
|
HA 和 kerberos
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
CREATE CATALOG hive PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://172.0.0.1:9083',
'hive.metastore.sasl.enabled' = 'true',
'hive.metastore.kerberos.principal' = 'your-hms-principal',
'dfs.nameservices'='your-nameservice',
'dfs.ha.namenodes.your-nameservice'='nn1,nn2',
'dfs.namenode.rpc-address.your-nameservice.nn1'='172.21.0.2:8088',
'dfs.namenode.rpc-address.your-nameservice.nn2'='172.21.0.3:8088',
'dfs.client.failover.proxy.provider.your-nameservice'='org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider',
'hadoop.security.authentication' = 'kerberos',
'hadoop.kerberos.keytab' = '/your-keytab-filepath/your.keytab',
'hadoop.kerberos.principal' = '[email protected]',
'yarn.resourcemanager.principal' = 'your-rm-principal'
);
|
支持其他的文件系统包括
- VIEWFS
- JuiceFS
- S3
- OSS
- OBS
- COS
- Glue
For Hive Catalog, 4 types of metadata are cached in Doris:
- Table structure: cache table column information, etc.
- Partition value: Cache the partition value information of all partitions of a table.
- Partition information: Cache the information of each partition, such as partition data format, partition storage location, partition value, etc.
- File information: Cache the file information corresponding to each partition, such as file path location, etc.
当节点宕机后,会再次获取 hive 拿到元数据,默认 cache 失效为 10分钟
1
2
3
4
5
|
CREATE CATALOG hive PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://172.0.0.1:9083',
'file.meta.cache.ttl-second' = '60'
);
|
手动刷新,指定的库,指定的表
1
2
3
|
REFRESH CATALOG ctl1 PROPERTIES("invalid_cache" = "true");
REFRESH DATABASE [ctl.]db1 PROPERTIES("invalid_cache" = "true");
REFRESH TABLE [ctl.][db.]tbl1;
|
周期刷新
1
2
3
4
5
|
CREATE CATALOG hive PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://172.0.0.1:9083',
'metadata_refresh_interval_sec' = '600'
);
|
整合 rangeer,增加一些配置
1
2
|
"access_controller.properties.ranger.service.name" = "hive",
"access_controller.class" = "org.apache.doris.catalog.authorizer.RangerHiveAccessControllerFactory",
|
Copy the configuration files ranger-hive-audit.xml, ranger-hive-security.xml, and ranger-policymgr-ssl.xml under the HMS conf directory to the FE conf directory
放到 conf 目录中,重启 fe
Best Practices
- Create user user1 on the ranger side and authorize the query permission of db1.table1.col1
- Create role role1 on the ranger side and authorize the query permission of db1.table1.col2
- Create a user user1 with the same name in doris, user1 will directly have the query authority of db1.table1.col1
- Create role1 with the same name in doris, and assign role1 to user1, user1 will have the query authority of db1.table1.col1 and col2 at the same time
JDBC
创建 mysql 的
1
2
3
4
5
6
7
8
|
CREATE CATALOG jdbc_mysql PROPERTIES (
"type"="jdbc",
"user"="root",
"password"="123456",
"jdbc_url" = "jdbc:mysql://127.0.0.1:3306/demo",
"driver_url" = "mysql-connector-java-5.1.47.jar",
"driver_class" = "com.mysql.jdbc.Driver"
)
|
查询`
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
show catalogs;
+-----------+-------------+----------+-----------+-------------------------+---------------------+------------------------+
| CatalogId | CatalogName | Type | IsCurrent | CreateTime | LastUpdateTime | Comment |
+-----------+-------------+----------+-----------+-------------------------+---------------------+------------------------+
| 0 | internal | internal | | UNRECORDED | NULL | Doris internal catalog |
| 1346433 | jdbc_mysql | jdbc | yes | 2024-01-05 09:37:58.788 | 2024-01-05 09:38:13 | |
+-----------+-------------+----------+-----------+-------------------------+---------------------+------------------------+
SELECT * FROM jdbc_mysql.hello.t1 LIMIT 10;
+------+-------+
| id | sname |
+------+-------+
| 1 | aaa |
| 2 | bbb |
| 3 | ccc |
| 4 | ddd |
+------+-------+
|
支持的 JDBC 类型
- MySQL
- PostgreSQL
- Oracle
- SQLServer
- Doris
- Clickhouse
- SAP HANA
- Trino
- Presto
- OceanBase
查询
1
2
3
|
SHOW TABLES FROM <catalog_name>.<database_name>;
SHOW TABLES FROM <database_name>;
SHOW TABLES;
|
File Analysis
支持文件格式自动推断
1
2
3
4
5
6
7
|
DESC FUNCTION s3 (
"URI" = "http://127.0.0.1:9312/test2/test.snappy.parquet",
"s3.access_key"= "ak",
"s3.secret_key" = "sk",
"format" = "parquet",
"use_path_style"="true"
);
|
File Cache
开启
1
2
|
SET enable_file_cache = true;
SET GLOBAL enable_file_cache = true;
|
当 be 从远端读数据时,会将文件拆分放入 block 中,后续请求就直接命中缓存
相关配置在conf/be.conf
通过 profile 检查是否被缓存了
1
2
3
4
5
6
7
8
|
- FileCache:
- IOHitCacheNum: 552
- IOTotalNum: 835
- ReadFromFileCacheBytes: 19.98 MB
- ReadFromWriteCacheBytes: 0.00
- ReadTotalBytes: 29.52 MB
- WriteInFileCacheBytes: 915.77 MB
- WriteInFileCacheNum: 283
|
External Table Statistics
用于收集外部表的统计信息
1
2
3
4
5
6
|
ANALYZE TABLE sample_table;
+--------------+-------------------------+--------------+---------------+---------+
| Catalog_Name | DB_Name | Table_Name | Columns | Job_Id |
+--------------+-------------------------+--------------+---------------+---------+
| hive | default_cluster:default | sample_table | [name,id,age] | 1346450 |
+--------------+-------------------------+--------------+---------------+---------+
|
展示结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
show analyze 1346450\G
*************************** 1. row ***************************
job_id: 1346450
catalog_name: hive
db_name: default_cluster:default
tbl_name: sample_table
col_name: [name,id,age]
job_type: MANUAL
analysis_type: FUNDAMENTALS
message:
last_exec_time_in_ms: 2024-01-05 21:27:16
state: FINISHED
progress: 4 Finished/0 Failed/0 In Progress/4 Total
schedule_type: ONCE
1 row in set (0.00 sec)
SHOW ANALYZE TASK STATUS 1346450;
+---------+---------------+---------+------------------------+-----------------+----------+
| task_id | col_name | message | last_state_change_time | time_cost_in_ms | state |
+---------+---------------+---------+------------------------+-----------------+----------+
| 1346451 | name | | 2024-01-05 21:27:16 | 115 | FINISHED |
| 1346452 | id | | 2024-01-05 21:27:16 | 115 | FINISHED |
| 1346453 | age | | 2024-01-05 21:27:16 | 115 | FINISHED |
| 1346454 | TableRowCount | | 2024-01-05 21:27:16 | 77 | FINISHED |
+---------+---------------+---------+------------------------+-----------------+----------+
|
收集 mysql 的
1
|
ANALYZE TABLE jdbc_mysql.hello.t1;
|
周期性的收集
1
|
analyze table hive.tpch100.orders with period 86400;
|
显示所有的状态
终止
1
2
|
KILL ANALYZE [job_id]
DROP ANALYZE JOB [JOB_ID]
|
还可以修改和删除
1
2
|
DROP STATS hive.tpch100.orders
DROP STATS hive.tpch100.orders (o_orderkey, o_orderdate)
|
当初次查询的时候,统计信息模块会收集外部表的 statistic 信息
如果外部表不支持列等信息统计,则会大致评估,这会影响精准度
编译
1
2
|
cd doris
BUILD_FS_BENCHMARK=ON ./build.sh --be
|
例子
1
2
3
4
5
6
7
|
sh run-fs-benchmark.sh \
--conf= configuration file \
--fs_type= file system \
--operation= operations on the file system \
--file_size= file size \
--threads= the number of threads \
--iterations= the number of iterations
|
执行 hdfs 的
1
2
3
4
5
6
7
|
sh run-fs-benchmark.sh \
--conf=hdfs.conf \
--fs_type=hdfs \
--operation=create_write \
--file_size=1024000 \
--threads=3 \
--iterations=5
|
对象存储
1
2
3
4
5
6
|
sh bin/run-fs-benchmark.sh \
--conf=s3.conf \
--fs_type=s3 \
--operation=single_read \
--threads=1 \
--iterations=1
|
Ecosystem
Spark Doris Connector
Spark Doris Connector can support reading data stored in Doris and writing data to Doris through Spark.
Github: https://github.com/apache/doris-spark-connector
概述
- Support reading data from Doris.
- Support Spark DataFrame batch/stream writing data to Doris
- You can map the Doris table to DataFrame or RDD, it is recommended to use DataFrame.
- Support the completion of data filtering on the Doris side to reduce the amount of data transmission.
例子
1
2
3
4
5
6
7
8
9
10
11
12
|
CREATE
TEMPORARY VIEW spark_doris
USING doris
OPTIONS(
"table.identifier"="$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME",
"fenodes"="$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT",
"user"="$YOUR_DORIS_USERNAME",
"password"="$YOUR_DORIS_PASSWORD"
);
SELECT *
FROM spark_doris;
|
data frame
1
2
3
4
5
6
7
8
|
val dorisSparkDF = spark.read.format("doris")
.option("doris.table.identifier", "$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME")
.option("doris.fenodes", "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT")
.option("user", "$YOUR_DORIS_USERNAME")
.option("password", "$YOUR_DORIS_PASSWORD")
.load()
dorisSparkDF.show(5)
|
RDD
1
2
3
4
5
6
7
8
9
10
11
12
|
import org.apache.doris.spark._
val dorisSparkRDD = sc.dorisRDD(
tableIdentifier = Some("$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME"),
cfg = Some(Map(
"doris.fenodes" -> "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT",
"doris.request.auth.user" -> "$YOUR_DORIS_USERNAME",
"doris.request.auth.password" -> "$YOUR_DORIS_PASSWORD"
))
)
dorisSparkRDD.collect()
|
插入
1
2
3
4
5
6
7
|
INSERT INTO spark_doris
VALUES ("VALUE1", "VALUE2", ...);
-- or
INSERT INTO spark_doris
SELECT *
FROM YOUR_TABLE
|
也支持 streaming
Other Connector
flink https://github.com/apache/doris-flink-connector
DataX Doriswriter
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id","order_code","line_code","remark","unit_no","unit_name","price"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://localhost:3306/demo"],
"table": ["employees_1"]
}
],
"username": "root",
"password": "xxxxx",
"where": ""
}
},
"writer": {
"name": "doriswriter",
"parameter": {
"loadUrl": ["127.0.0.1:8030"],
"loadProps": {
},
"column": ["id","order_code","line_code","remark","unit_no","unit_name","price"],
"username": "root",
"password": "xxxxxx",
"postSql": ["select count(1) from all_employees_info"],
"preSql": [],
"flushInterval":30000,
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:9030/demo",
"selectedDatabase": "demo",
"table": ["all_employees_info"]
}
],
"loadProps": {
"format": "json",
"strip_outer_array":"true",
"line_delimiter": "\\x02"
}
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
|
Seatunnel Doris Sink
Kyuubi,将 JDBC 作为引擎接入后,可以作为 Kyuubi 的后端
Logstash Doris Output Plugin
Beats Doris Output Plugin(ES)
Plugin Development Manual
跟 UDF 不一样,这个不参与 sql 计算的
插件结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# plugin .zip
auditodemo.zip:
-plugin.properties
-auditdemo.jar
-xxx.config
-data/
-test_data/
# plugin local directory
auditodemo/:
-plugin.properties
-auditdemo.jar
-xxx.config
-data/
-test_data/
|
plugin.properties 内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
### required:
#
# the plugin name
name = audit_plugin_demo
#
# the plugin type
type = AUDIT
#
# simple summary of the plugin
description = just for test
#
# Doris's version, like: 0.11.0
version = 0.11.0
### FE-Plugin optional:
#
# version of java the code is built against
# use the command "java -version" value, like 1.8.0, 9.0.1, 13.0.4
java.version = 1.8.31
#
# the name of the class to load, fully-qualified.
classname = AuditPluginDemo
### BE-Plugin optional:
# the name of the so to load
soName = example.so
|
安装
1
|
install plugin from "/home/users/doris/auditloader.zip";
|
查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
show plugins\G
*************************** 1. row ***************************
Name: auditloader
Type: AUDIT
Description: load audit log to olap load, and user can view the statistic of queries
Version: 0.12.0
JavaVersion: 1.8.31
ClassName: AuditLoaderPlugin
SoName: NULL
Sources: /home/users/doris/auditloader.zip
Status: INSTALLED
Properties: {}
*************************** 2. row ***************************
Name: AuditLogBuilder
Type: AUDIT
Description: builtin audit logger
Version: 0.12.0
JavaVersion: 1.8.31
ClassName: org.apache.doris.qe.AuditLogBuilder
SoName: NULL
Sources: Builtin
Status: INSTALLED
Properties: {}
2 rows in set (0.00 sec)
|
这里 提供了一些插件的例子
CloudCanal Data Import
官网,文档介绍
目前支持 30+ 数据库
有非常好的可视化界面
DBT Doris Adapter
dbt官网
DBT(Data Build Tool) is a component that focuses on doing T (Transform) in ELT (extraction, loading, transformation)
- the “transformation data” link The dbt-doris adapter is developed based on dbt-core 1.5.0 and relies
on the mysql-connector-python driver to convert data to doris.
UDF
Remote User Defined Function Service
通过 protobuf 传递消息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
CREATE FUNCTION rpc_add_two(INT,INT) RETURNS INT PROPERTIES (
"SYMBOL"="add_int_two",
"OBJECT_FILE"="127.0.0.1:9114",
"TYPE"="RPC"
);
CREATE FUNCTION rpc_add_one(INT) RETURNS INT PROPERTIES (
"SYMBOL"="add_int_one",
"OBJECT_FILE"="127.0.0.1:9114",
"TYPE"="RPC"
);
CREATE FUNCTION rpc_add_string(varchar(30)) RETURNS varchar(30) PROPERTIES (
"SYMBOL"="add_string",
"OBJECT_FILE"="127.0.0.1:9114",
"TYPE"="RPC"
);
|
使用
1
2
3
4
5
6
|
select rpc_add_string('doris');
+-------------------------+
| rpc_add_string('doris') |
+-------------------------+
| doris_rpc_test |
+-------------------------+
|
日志中显示的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
INFO: fnCall request=function_name: "add_string"
args {
type {
id: STRING
}
has_null: false
string_value: "doris"
}
INFO: fnCall res=result {
type {
id: STRING
}
has_null: false
string_value: "doris_rpc_test"
}
status {
status_code: 0
}
|
Java UDF
这个代码比较简单,没有任何 doris 相关的类,就是纯的 JDK 相关逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
package org.apache.doris.udf.demo;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException;
public class SimpleDemo {
//Need an inner class to store data
/*required*/
public static class State {
/*some variables if you need */
public int sum = 0;
}
/*required*/
public State create() {
/* here could do some init work if needed */
return new State();
}
/*required*/
public void destroy(State state) {
/* here could do some destroy work if needed */
}
/*Not Required*/
public void reset(State state) {
/*if you want this udaf function can work with window function.*/
/*Must impl this, it will be reset to init state after calculate every window frame*/
state.sum = 0;
}
/*required*/
//first argument is State, then other types your input
public void add(State state, Integer val) throws Exception {
/* here doing update work when input data*/
if (val != null) {
state.sum += val;
}
}
/*required*/
public void serialize(State state, DataOutputStream out) {
/* serialize some data into buffer */
try {
out.writeInt(state.sum);
} catch (Exception e) {
/* Do not throw exceptions */
log.info(e.getMessage());
}
}
/*required*/
public void deserialize(State state, DataInputStream in) {
/* deserialize get data from buffer before you put */
int val = 0;
try {
val = in.readInt();
} catch (Exception e) {
/* Do not throw exceptions */
log.info(e.getMessage());
}
state.sum = val;
}
/*required*/
public void merge(State state, State rhs) throws Exception {
/* merge data from state */
state.sum += rhs.sum;
}
/*required*/
//return Type you defined
public Integer getValue(State state) throws Exception {
/* return finally result */
return state.sum;
}
}
|
创建 一个函数
1
2
3
4
5
6
|
CREATE AGGREGATE FUNCTION simple_sum(INT) RETURNS INT PROPERTIES (
"file"="file:///pathTo/java-udaf.jar",
"symbol"="org.apache.doris.udf.demo.SimpleDemo",
"always_nullable"="true",
"type"="JAVA_UDF"
);
|
使用
1
2
3
4
5
6
|
select simple_sum(t1) from test;
+----------------+
| simple_sum(t1) |
+----------------+
| 10 |
+----------------+
|
UDF 是和数据库绑定的,而内置函数是全局的
Native User Defined Function
这个要麻烦不少,还要写 cmake 文件,这里
SQL Manual
SQL Functions
内置的函数
- Array Functions
- Date Functions
- Gis Functions
- String Functions
- Struct Functions
- Combinators
- Aggregate Functions
- Bitmap Functions
- Bitwise Functions
- Conditional Functions
- JSON Functions
- Hash Functions
- HLL Functions
- Numeric Functions
- Encryption Functions
- Table Functions
- Window Functions
- IP Functions
- Vector Distance Functions
- CAST
- DIGITAL_MASKING
表函数的一个例子
1
2
3
4
5
6
7
8
9
10
11
|
select * from local(
-> "file_path" = "log/be.out",
-> "backend_id" = "1346034",
-> "format" = "csv")
-> where c1 like "%start_time%" limit 10;
+------------------------------------------+
| c1 |
+------------------------------------------+
| start time: Thu Dec 28 11:15:19 CST 2023 |
| start time: Fri Dec 29 11:11:35 CST 2023 |
+------------------------------------------+
|
显示 fe、be 的函数
1
2
3
4
5
6
7
|
select * from frontends()\G
desc function frontends();
select * from backends()\G
desc function backends();
select * from catalogs();
|
数字掩码
1
2
3
4
5
6
|
select digital_masking(13812345678);
+--------------------------------------------------+
| digital_masking(cast(13812345678 as VARCHAR(*))) |
+--------------------------------------------------+
| 138****5678 |
+--------------------------------------------------+
|
SQL Reference
Cluster management
- ALTER-SYSTEM-ADD-FOLLOWER
- ALTER-SYSTEM-ADD-OBSERVER
- ALTER-SYSTEM-ADD-BACKEND
- ALTER-SYSTEM-ADD-BROKER
- 以及相关的modify、drop 操作
Account Management
- CREATE-ROLE
- CREATE-USER
- ALTER-USER
- SET-PASSWORD
- SET-PROPERTY
- LDAP
- GRANT
- REVOKE
- DROP-ROLE
- DROP-USER
Database Administration
- ADMIN-SHOW-CONFIG
- ADMIN-SET-CONFIG
- SET-VARIABLE
- INSTALL-PLUGIN
- ADMIN-SET-REPLICA-STATUS
- ADMIN-SET-REPLICA-VERSION
- ADMIN-SET-PARTITION-VERSION
- ADMIN-SET-TABLE-STATUS
- ADMIN-SHOW-REPLICA-DISTRIBUTION
- ADMIN-SHOW-REPLICA-STATUS
- ADMIN-REPAIR-TABLE
- KILL
- ADMIN-REBALANCE-DISK
Data Types
- BOOLEAN
- TINYINT
- SMALLINT
- INT
- BIGINT
- LARGEINT
- FLOAT
- DOUBLE
- DECIMAL
- DATE
- DATETIME
- CHAR
- VARCHAR
- STRING
- HLL (HyperLogLog)
- BITMAP
- QUANTILE_STATE
- ARRAY
- MAP
- STRUCT
- JSON
- AGG_STATE
DDL
- Create:catalog,database,table,index,external-table,view,materialized-view,function
- Alter:file,policy,resource,workload-group,sql-block-rule,encrypt-key
- Drop
- Backup and Restore
DML
- Load
- Manipulation,CURD
- outfile
SHOW
- CREATE CATALOG
- CREATE DATABASE
- CREATE ENCRYPTKEY
- CREATE EXTERNAL TABLE
- CREATE FILE
- CREATE FUNCTION
- CREATE INDEX
- CREATE MATERIALIZED VIEW
- CREATE POLICY
- CREATE REPOSITORY
- CREATE RESOURCE
- CREATE ROLE
- CREATE ROUTINE LOAD
- CREATE SQL BLOCK RULE
- CREATE SYNC JOB
- CREATE TABLE
- CREATE TABLE AS SELECT
- CREATE TABLE LIKE
- CREATE USER
- CREATE VIEW
- CREATE WORKLOAD GROUP
- SHOW CREATE CATALOG
- SHOW CREATE DATABASE
- SHOW CREATE FUNCTION
- SHOW CREATE LOAD
- SHOW CREATE REPOSITORY
- SHOW CREATE ROUTINE LOAD
- SHOW CREATE TABLE
Utility
- HELP
- USE
- DESCRIBE
- SWITCH
- REFRESH
- SYNC
- CLEAN-QUERY-STATS
Admin Manual
cluster management
Overview of the upgrade process
- Metadata backup
- Turn off the cluster copy repair and balance function
- Compatibility testing
- Upgrade BE
- Upgrade FE
- Turn on the cluster replica repair and balance function
通过 ALTER SYSTEM,add、或者 delete 节点
loadbalance
1
|
jdbc:mysql:loadbalance://[host:port],[host:port].../[database][?propertyName1][=propertyValue1][&propertyName2][=propertyValue
|
ProxySQL
ProxySQL is a flexible and powerful MySQL proxy layer.
It is a MySQL middleware that can be actually used in a production environment.
It can realize read-write separation, support Query routing function, support dynamic designation of a certain SQL for cache,
support dynamic loading configuration, failure Switching and some SQL filtering functions.
Data Admin
backup 步骤
- Snapshot and snapshot upload
- Metadata preparation and upload
- Dynamic Partition Table Description
Data Restore,通过命令从 远端存储恢复
- Create the corresponding metadata locally
- Local snapshot
- Download snapshot
- Effective snapshot
Drop Recovery
也有相关的命令
Other Manager
统计信息
- SHOW QUERY PROFILE
- SHOW LOAD PROFILE
然后可以查看各种执行算子,通过算子来分析执行情况,这里
SQL 拦截,类似黑名单机制
1
2
3
4
5
6
7
|
CREATE SQL_BLOCK_RULE test_rule
PROPERTIES(
"sql"="select \\* from order_analysis",
"global"="false",
"enable"="true",
"sqlHash"=""
)
|
安全通讯
- TLS certificate
- FE SSL certificate
Maintenance and Monitor
Monitor Metrics
- 包括自身节点信息,主机信息,JVM信息等
- FE Process monitoring
- FE JVM metrics
- BE Process metrics
- BE Machine metrics
磁盘管理,两个水位
- High Watermark
- Flood Stage,比上面的更高,表示磁盘快不够了
Data replica management
- Tablet: The logical fragmentation of a Doris table, where a table has multiple fragments.
- Replica: A sliced copy, defaulting to three copies of a slice.
- Healthy Replica: A healthy copy that survives at Backend and has a complete version.
- Tablet Checker (TC): A resident background thread that scans all Tablets regularly, checks the status of these Tablets, and decides whether to send them to Tablet Scheduler based on the results.
- Tablet Scheduler (TS): A resident background thread that handles Tablets sent by Tablet Checker that need to be repaired. At the same time, cluster replica balancing will be carried out.
- Tablet SchedCtx (TSC): is a tablet encapsulation. When TC chooses a tablet, it encapsulates it as a TSC and sends it to TS.
- Storage Medium: Storage medium. Doris supports specifying different storage media for partition granularity, including SSD and HDD. The replica scheduling strategy is also scheduled for different storage media.
1
2
3
4
5
6
7
8
9
10
|
+--------+ +-----------+
| Meta | | Backends |
+---^----+ +------^----+
| | | 3. Send clone tasks
1. Check tablets | | |
+--------v------+ +-----------------+
| TabletChecker +--------> TabletScheduler |
+---------------+ +-----------------+
2. Waiting to be scheduled
|
监控和报警,支持整合 prometheus
TABLETS 查看
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
show tablets from test\G
*************************** 1. row ***************************
TabletId: 1346417
ReplicaId: 1346418
BackendId: 1346034
SchemaHash: 1990704458
Version: 2
LstSuccessVersion: 2
LstFailedVersion: -1
LstFailedTime: NULL
LocalDataSize: 218
RemoteDataSize: 0
RowCount: 1
State: NORMAL
LstConsistencyCheckTime: NULL
CheckVersion: -1
VersionCount: 2
QueryHits: 0
PathHash: -2566916266841741493
MetaUrl: http://192.168.1.2:8040/api/meta/header/1346417
CompactionStatus: http://192.168.1.2:8040/api/compaction/show?tablet_id=1346417
CooldownReplicaId: -1
CooldownMetaId:
*************************** 2. row ***************************
TabletId: 1346419
ReplicaId: 1346420
BackendId: 1346034
SchemaHash: 1990704458
Version: 2
LstSuccessVersion: 2
LstFailedVersion: -1
LstFailedTime: NULL
LocalDataSize: 219
RemoteDataSize: 0
RowCount: 3
State: NORMAL
LstConsistencyCheckTime: NULL
CheckVersion: -1
VersionCount: 2
QueryHits: 0
PathHash: -2566916266841741493
MetaUrl: http://192.168.1.2:8040/api/meta/header/1346419
CompactionStatus: http://192.168.1.2:8040/api/compaction/show?tablet_id=1346419
CooldownReplicaId: -1
CooldownMetaId:
2 rows in set (0.00 sec)
|
根据 ID 查看
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
show tablet 1346417\G
*************************** 1. row ***************************
DbName: default_cluster:demo
TableName: test
PartitionName: test
IndexName: test
DbId: 1345111
TableId: 1346415
PartitionId: 1346414
IndexId: 1346416
IsSync: true
Order: 0
QueryHits: 0
DetailCmd: SHOW PROC '/dbs/1345111/1346415/partitions/1346414/1346416/1346417';
|
meta-tool 工具
1
|
./lib/meta_tool --root_path=/path/to/storage --operation=load_meta --json_meta_path=/path/to/10017.hdr.json
|
配置自动启动,如
1
2
|
systemctl enable doris-fe
systemctl enable doris-be
|
HTTP-API
BE 的 web-UI 有 memory tracker 信息
Metadata Operations and Maintenance
Metadata Design Document
StarRocks
来自 StarRocks 官网的文档记录
核心功能
- FE 和 BE 架构,多个 FE对等,都可以接收请求
- 元数据存在 Berkeley DB 中,存在 FE 中,每个 FE 存全量
- 基于 paxos 协议实现选主功能,包括 Leader、Follower、Observer
- 前缀索引、列级索引、预先聚合、bloom filter、bitmap 索引、zone map 索引
- 数据分布:Round-Robin、range、list、hash,数据压缩
数据管理
- 对比传统Scatter-Gather 框架模式只有一个汇总点,这里可以有多个汇总点,并行度更高
- 实时更新的列存,merge-on-read、copy-on-write、delta-store、delete-and-insert
- 数据湖支持,物化视图
- catalog,默认可以自己管理数据,external catalog:hive、delta-lake、ice-berg、hudi、JDBC catalog
- 工具集成,BI类的:Hex、Querybook、 superset、tableau、工具:DataGrip、DBeaver
- 各种导入导出,导入:MySQL、Flink导入、Spark导入、流导入、insert语句、kakfa;export关键字,spark、flink导出
查询加速
- Cascades 风格的CBO 优化器;手动采集、自动采集、全量采集、直方图
- 前缀索引、列级索引、预先聚合、bloom filter、bitmap 索引、zone map 索引
- 数据分布:Round-Robin、range、list、hash,数据压缩
- 同步物化视图、异步物化视图
- HyperLogLog去重、bitmap去重,查询缓存
- Colocate Join,创建 Colocation Group(CG),同一个CG内按照相同的分区分桶规则,这样可以本地join
- Bucked shffle join,只shuffle 小表的部分数据到不同的分片
集群管理和其他
- K8S支持,缩容、扩容
- 报警监控、备份,审计日志
- 内部的 information_schema 库
- 权限认证管理,创建用户、用户组、角色、权限
- 资源隔离、查询队列、内存管理、黑名单,这些都有自定义的SQL
- 查询计划,有点类似 impala,Query Profile
- 集群管理命令、AUTO_INCREMENT
- 函数:日期、字符串、聚合、array、bitmap、json、map、binary、加密、正则、条件、百分位、标量、工具、地理位置
Reference