分析和比较几种 LakeHouse 存储系统
论文
https://15721.courses.cs.cmu.edu/spring2023/papers/20-databricks/p92-jain.pdf
General Overview
提到了关于在对象存储之上,构建数据仓库的挑战
- 首先延迟很高
- 跟第一个类似,对象存储支持的范围很广,数据规模非常大,但是加载很慢
- 湖仓系统能够访问各种开放计算引擎,所以接口是开放的,跟普通数据库就不痛,所以对事物和ACID的设计就很有挑战
比如说有这么一些问题
How to coordinate transactions
- 有些系统是直接构建在 对象存储之上的
- 而有的是通过 hive-meastore构建的,这样延迟就降低了,但是扩展性也降低了
- 三个存储系统的事物隔离级别也不同,这也是一个 trade-off
Where to store metadata
- 这三个都是用了 zone map 和其他一些辅助数据结构,用于加速访问
- 这些信息放那里,三个存储则不一样
- 有的放对象存储中,有的放 事务log中,有的放到额外的服务中
How to query metadata
- delta-lake 和 hudi,用并行的job,也就是spark任务查询元数据
- 可以查询非常大的表,但增加了延迟
- iceberg将元数据处理放到单个节点的客户端库中
How to efficiently handle updates?
- 要支持随机更新,以及快速查询,而且是在对象存储之上的
- 不同的系统支持的优化策略不同
- copy-on-write,merge-on-write 两个策略
| Table Metadata | Transaction Atomicity | Isolation Levels |
|---|---|---|
| Delta Lake | Transaction Log + Metadata Checkpoints | Atomic Log Appends |
| Hudi | Transaction Log + Metadata Table | Table-Level Lock |
| Iceberg | Hierarchical Files | Table-Level |
lakehouse 系统跟传统的数仓不同之处
- 前者基于开放的格式,提供开放的接口
- 其他的引擎可以直接查询底层的数据,除了SQL,还可以支持机器学习等其他场景
lakehouse对数仓做了分解
- 存储管理
- 表元数据
- 事务管理,嵌入到多个引擎的客户端库中,每个引擎可以有他们自己的plan和执行方式
LakeHouse Sysem
Transaction Coordination
三个 系统都支持事务,但只支持单表事务,不支持多表
另外每种的实现方式也不同
三个都使用MVCC 实现事务
表中附带了一个元数据,当事务开始的时候会读这个元数据,获取这个表的快照
然后从快照中读取所需的数据,事务提交的时候会自动更新元数据
Delta-lake依赖底层的存储系统提供的原子操作,put-if-absent,如果底层的不支持,则外接一个DynamoDB
Hudi、iceberg 用 表锁来实现,依赖 Zookeeper、Hive MetaStore、DynamoDB
但是依赖 Hive MetaStore 也有问题,如果客户端和服务端的锁心跳超时了,可能会导致脏写
三者都用 OCC optimistic concurrency control 做隔离
通过不同的校验机制,通过实现不同的校验方式,来做到不同的隔离级别
Hudi、Iceberg,在写的时候会校验这个写的文件,如果某些 事务在当前事务之后开始,那么快照中就没有了
但这些事务提交了,导致当前事务写文件冲突,这两个系统会确保这个冲突不发生
这个是 OCC 的向前检查策略
Delta 也提供了类似的方式,对于其他事务的 Update、Merge、Delete 的读条件会检查,如果不在事务的快照中则无法提交
Dleta 提供了可选,对Select 条件也做检查,提供更高的隔离机制
两个 可串行化
- serializability:事务的结果跟事务执行顺序一样
- strict serializability:跟事务日志中出现的顺序一致
左边的是事务一致性,最高等级是:可串行化;右边是数据一致性,最高等级是:可线性化
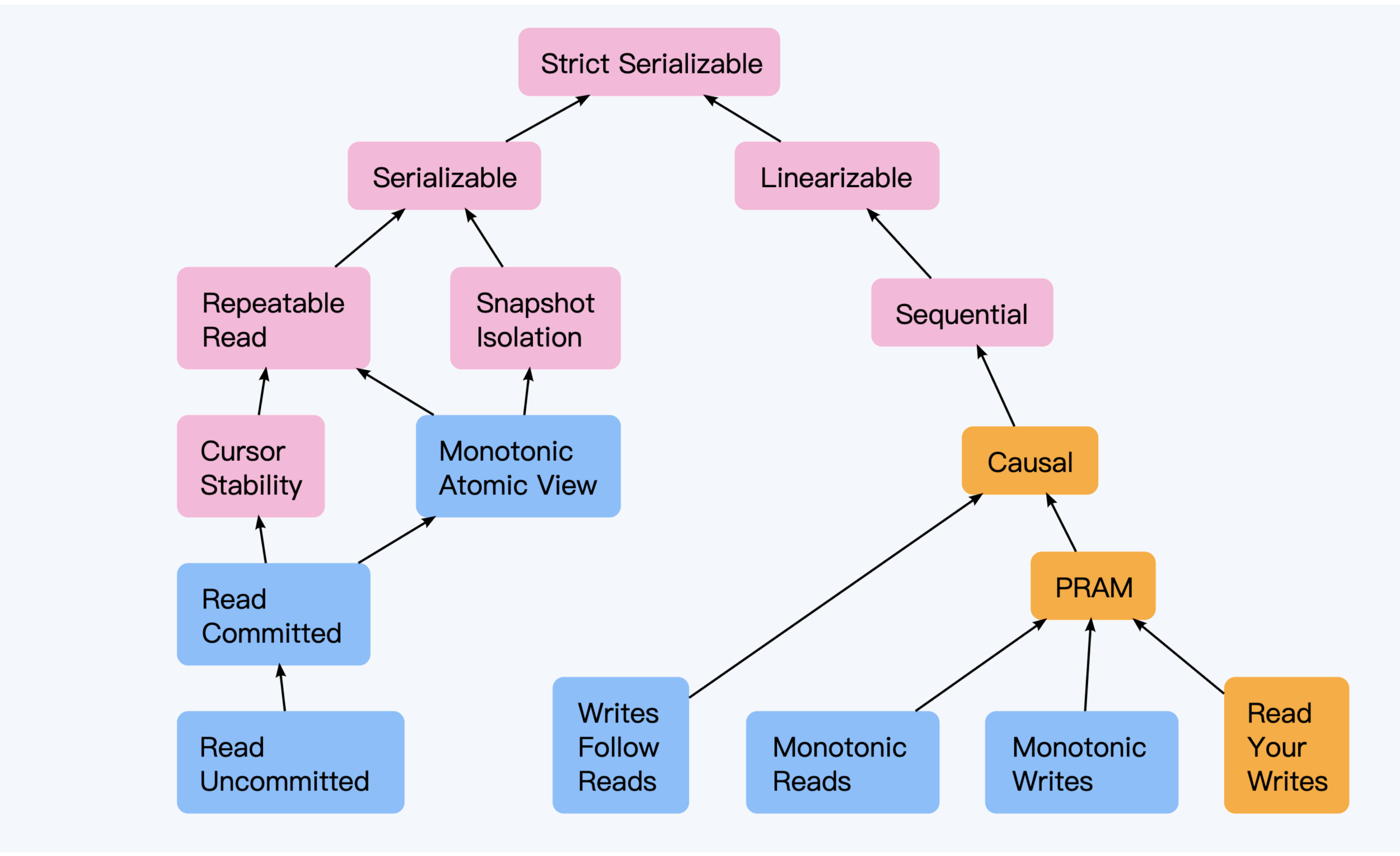
事务相关的
- Strict Serializable,t1,t2,t3三个事务,执行结果跟提交顺序一致,而且真实执行也是一致的,保证 t2 开始前能看到 t1 的结果
- Serializable,内部可能是交错的,只是执行结果保证跟串行方式一致
- Snapshot Isolation,使用 MVCC 实现,读写不冲突,预防了 non-repeatable
- Repeatable Read,跟 快照隔离类似,但用 lock 实现,读写冲突,并发降低了
- Cursor Stability,游标稳定,在读取一行的时候会锁住,这样其他更新就会等待,当游标移动到下一行释放锁
- Read Committed,预防了脏读
- Read Uncommitted,最低隔离级别,并发度是最高的
Metadata Management
元数据的读取速度 限制了正常查询的速度
如果元数据获取太慢,则正常查询也不可能快
S3 限制了每次查询 1000个返回,如果要查询 百万的话,需要几分钟,这样就太慢了
元数据存储格式
- 表格式
- 层次结构
Delta Lake 和 Hudi 使用了 表格式
- Hudi 将元数据存储到一个特殊的 表中
- Delta Lake,存储在 事务log中(结合了Parquet 和 JSON 格式)
事务不是直接写到表中的,而是写事务log,然后周期性的压缩 到这个表中(使用了 merge-on-read 策略)
Ice berg 使用了层次结构,元数据存储在清单文件的层次结构中,最底层的每个文件 存储了一系列文件的元数据
而更上层的则包含了下层的 聚合元数据
这种方式更像一个表索引
聚合查询所需的数据,使用了两个不同的策略
- Delta Lake,Hudi:batch job 方式扫描元数据表,找到查询计划中所匹配的所有文件
- Ice berg:使用了更上层文件作为索引,来最小化查询,使用了单节点方式
单节点的方式对于小查询来说效果更好,但是对于大表的分布式查询其伸缩性就不行了
未来,查询计划是否可以根据 CBO 来动态的选择这些策略,也是一个开放话题
Data Update Strategies
两个不同的更新策略
- Copy-On-Write (CoW),写入的数据 写到新文件中,带来写放大,但读没影响
- Merge-On-Read (MoR),将写入的行级别信息写到其他地方,等到读的时候再重建,读放大
CoW 会导致写放大,读没影响, 更适合读场景,三个系统都支持
MoR 会导致读放大,写影响很小,更适合写场景,Hudi、Ice Berg 也支持,Delta Lake 未来也会支持
MoR 的实现方式
- Iceberg,以及Delta(还未实现),采用墓碑的方式,用辅助的文件标记为墓碑,查询时通过辅助记录做过滤
- Hudi,将insert、update、delete的行格式写入Avro文件中,查询时再做重建
Benchmark
LHBench
https://github.com/lhbench/lhbench
load 和 查询,其中 load 来看的话, delta lake 跟 iceberg 差不多,但是hudi 要慢很多,几乎10倍
这是因为 hudi做了优化的 key upsert,但是对于 bulk load导入代价很高,因为有很耗时的 key 去重处理
查询速度 delta 是hudi 的 1.4倍,是 iceberg 的 1.7倍
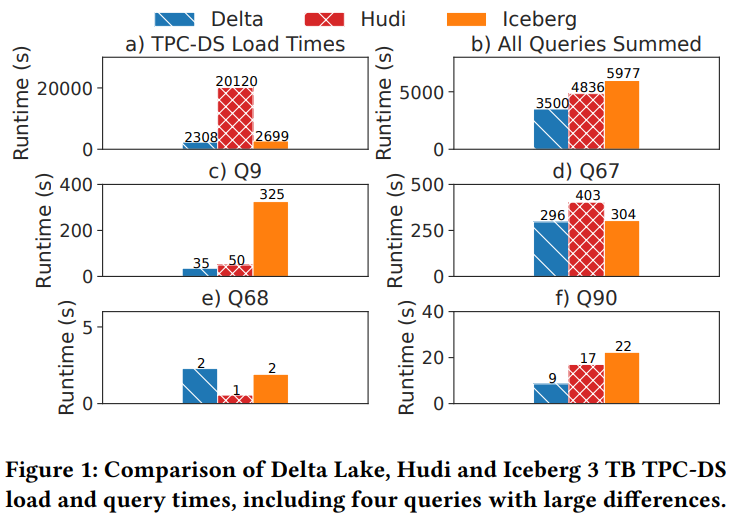
spark 生成的查询计划都是一样的,差别是读取的数据读取时间
对于 Q90,delta 是 6.5分钟、hudi 是 18.8分钟,iceberg 是18.6分钟
比如 delta 存储一个 128M 文件,而 hudi则是存储了 22个 8.3M文件,hudi更偏向小文件小查询,而 delta 则是大查询
for example, to read the Web Sales Table in Q90,
the executor must
read 2128 files (138 GB) in Delta Lake
but 18443 files (186 GB) in Hudi.
iceberg 读取总量跟 delta 差不多,但是它对支持 column drops、renames这些,导致需要一些自定义的parquet读取操作者
而不是原生spark的,导致变慢了
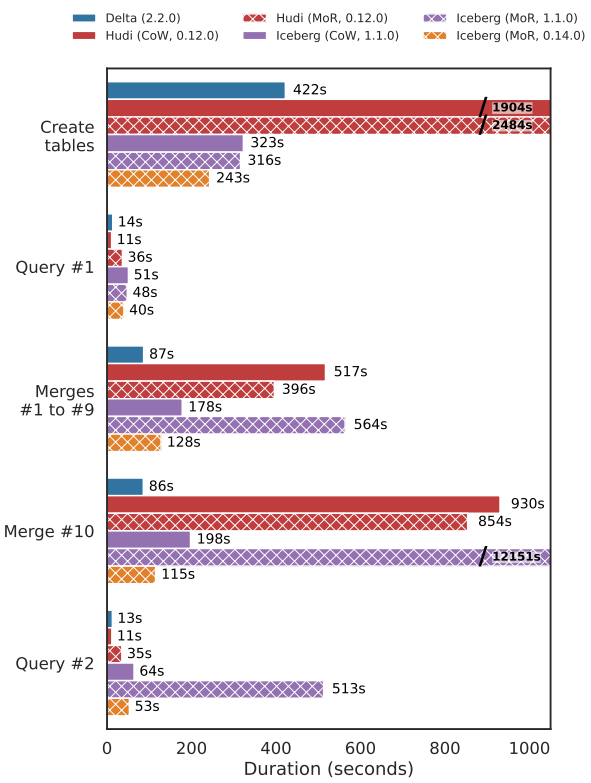
hudi 的 MoR 是 CoW 的 1.3倍,但是代价是 读取慢了 3.2倍
iceberg 的 MoR 是 CoW 的 1.4倍,但同样 读也变慢了
delta 只有CoW,但是做了一些优化,读取数据文件少,所以总体还不错
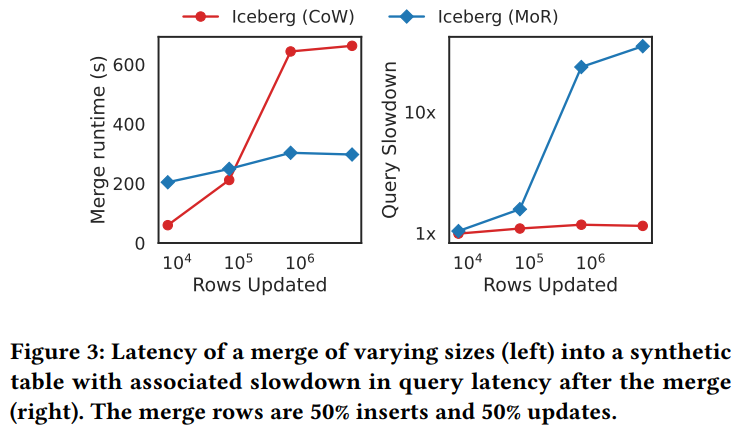
下面是 50%的insert + 50%的update 场景
iceberg 的 MoR 在不行数量增大的时候,MoR变化不大,但是 CoW 的开销,也就是写放大很严重,越来越慢
对于读取来说,MoR 性能下降的很厉害,比 CoW 超过10倍了
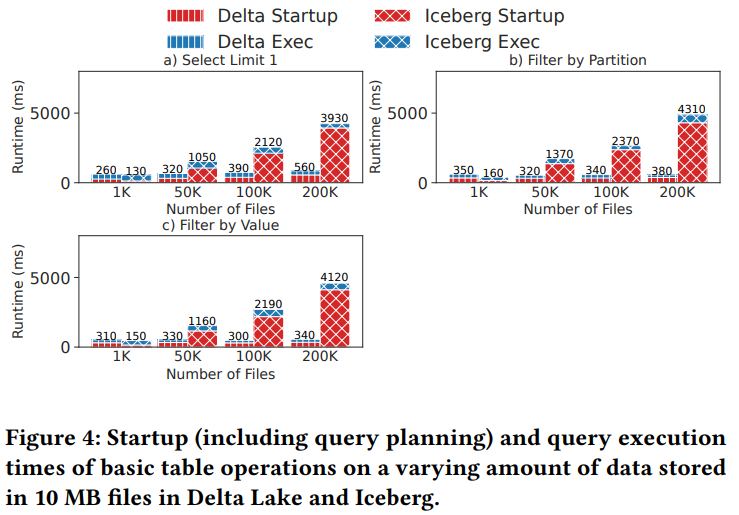
对比元数据访问的性能,生成各种各样大小的文件,从1K - 200K,以及 10G - 2T 不等
小文件的时候 iceberg 单节点效率不错,但随着表数据量增大,iceberg的启动时间就增加了很多
Open Questions
论文最后也提出了一些开放性问题
How can lakehouse systems best balance ingest latency and query latency
- 比如是否可将合并操作移除,也就是 MoR 做成异步的,这样就不影响更新了
- 另外系统是否可以基于此场景下,做自动的数据压缩策略
Can we use a cost model to intelligently choose between query lanning strategies
- 比如对于索引生成小的,高选择率的查询,使用单节点
- 而分布式 元数据查询使用大查询?
Can lakehouse systems efficiently support high write QPS under concurrency?
- 每次更新操作,都需要写入到底层对象存储的元数据中
- 对象存储延迟很高, > 50 ms,这样就限制了 QPS