数据开发工程师的工作内容(meta)
文章来源:
从一个宽泛的视角,介绍了 facebook 的 data engineers 使用的一些技术工具和框架
The data warehouse
内部使用了 ORC的一个fork,对读做了优化,链接
facebook 的数仓规模是 EB 级别的,所以一个数据中心放不下,需要跨几个机房存储
他们使用了 namespace 这个概念,混合了逻辑和物理位置
而一个表 就确定属于某个 namespace 的,这样一个 namespace 下的查询就不会跨机房了
但如果要跨 namespace 查询,就需要将 A 表拷贝,或者 B 表拷贝到对应的机房
每个表都按照 ds 分区,也就是 YYYY-MM-DD 分区的,一般是数据产生的时间,也有其他方式分区的
数据一般保留 90天,超过了就 归档,或者删除
数据如何写入数仓的
- 通过 data workflows 和管道写入的,data workflows
- 服务端和客户端拿到日志
- 生产环境图数据日的每日快照
Data discovery, data catalog
facebook 内部有一个叫 iData 的检查平台,是基于 web 的
开发人员可以根据 table 等关键字做搜索,检查平台为基于多个指标,如
- 数据新鲜度
- 文档
- 下游使用数量,ad hoc queries, other pipelines or dashboards
可以查找表的列类型,表的所有者
其他一些数据资产维度,比如 上游、下游的依赖等等
Presto and Spark: Querying the warehouse
主要是用 presto、spark 做查询
内部维护了一个分支,做了一些定制化修改,也会定期合并开源分支,同时也会提交修改到开源
所以内部使用主要就是基于spark、presto 方言写的 sql
一些复杂的逻辑会用 java、scala、python 来实现
data engineer, data scientist, software engineer
presto 主要是做 adhoc 查询,spark主要是复杂的 join 查询
一般 presto 会查询 几十亿行的数据,大概几秒,如果有聚会、join 需要几分钟
Scuba: Real-time analytics
facebook 内部的一个实时分析框架,用来分析日志的趋势
facebook 每天会产生 几百P 的数据,用户行为,代码变更,这个框架就用来实时分析这种变化,并提供开发人员展示
Scuba 的数据来自于客户端、或者服务端的 log
Scuba 可以通过 web UI 查询,类似于 Kibana,这样就不用写程序了,一般是生成 过去 5分钟的趋势报告
或者通过一种 SQL 方言查询
最后数据会写入到 hive
Daiquery & Bento: Query and analysis notebooks
data engineers 每天都会使用的工具之一
基于 web 的方式,可以查询任何数据源
- warehouse (either through Presto or Spark)
- Scuba
- 其他任何源
查询结果会以表格的方式展示,当然也可以 用其他形式展示
Daiquery 不支持其他复杂的查询
对此可以使用 Bento,这是 Jupyter 的内部实现,可以用 python 或者 R 做查询
很多 data scientists 用这个做机器学习、或者数据分析
Unidash: Dashboarding
类似于 Apache Superset、Tableau
比如工程师可以在 Daiquery 写查询,创建图表,然后导入 dashboard 中
而每次查询,再加载这个效率太低了
这里可以用 预聚会来加速,facebook 内部维护了一个 presto 改进的实现 RaptorX,有 10倍加速
这是通过缓存了通用的数据来加速的
RaptorX: Building a 10X Faster Presto
dashboard 可以通过 web 接口创建,也可以通过 python 来创建
Software development
内部使用了 高度定制化的 Visual Studio Code 作为 IDE,包括了一堆内置的插件,由专门的 team 维护
内部使用 Mercurial 的 fork版本作为源码控制,现在已经将其开源了
Sapling: Source control that’s user-friendly and scalable
采用的是 monorepo 代码管理方式
- 所有的 pipelines 和内部工具 都在一个仓库
- 日志定义,配置对象 在其他两个仓库
工程师会开发 pipelines,用来创建重要的数据集,之后通过分析工具或者 dashboard 来做查询,提供决策支撑
这些内部的基础设置工具,也会提交到 公司基础设置部门
Writing pipelines
数据流水线基本都是用 sql 写的,然后包装进 python 代码里面,再编排和调度
内部使用的调度框架是:Dataswarm,基于 AirFlow 做的修改
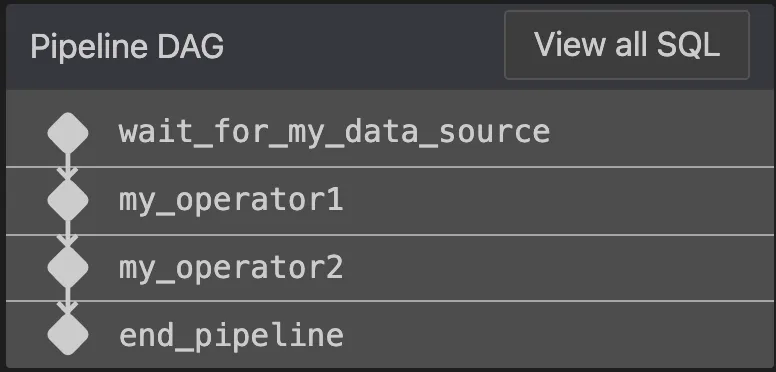
流水线是基于算子的,也就是 DAG 图
Dataswarm 中的大多数子算包括
- WaitFor operators,等待某个其他操作
- Query operators,运行查询,基于 presto、或者spark
- Data quality operators,对插入的数据做自动校验
- Data transfer operators,数据转换
- Miscellaneous operators,如发送 email,聊天通知,调用 API,执行脚本等
代码定义的流水线类似这样:


内部的 VSCode扩展,在保存或者计算 DAG 时,会执行这些 流水线逻辑
如果 SQL 有问题,自定义的扩展会提示
也运行工程师 基于真实数据调度一个测试用例,并将结果写到临时表中
UPM: Advanced pipeline features
一个内部的 统一 sql 前端
可以做的事情
- 相当于是 spark + presto 方言
- 语法分析,判断sql 是否合法
- 做一些 sql 校验
- 根据 select 中的列,可以检查出上下游的 血缘关系
比如,可以自动推断 所有的 WaitFors 依赖
Enabling static analysis of SQL queries at Meta

工程师通过 DAG 来检查 UPM 推断的依赖是否正确
Analytics Libraries
除了 UPM,还有其他一些库,用来创建复杂的pipelines
这些管道手动创建比较难
Analytics and Product-Market Fit
产生的一个 摘要风格的表

这个表包含了三个维度列
- product
- country
- has_log_session
以及两个聚合列
- total_session_time_minutes
- total_distinct_users_hll
HyperLogLog in Presto: A significantly faster way to handle cardinality estimation
Monitoring & operations
相当于 Dataswarm UI,一个基于 web 的界面
用来监控 pipeline 的,这个工具叫:CDM (Central Data Manager)
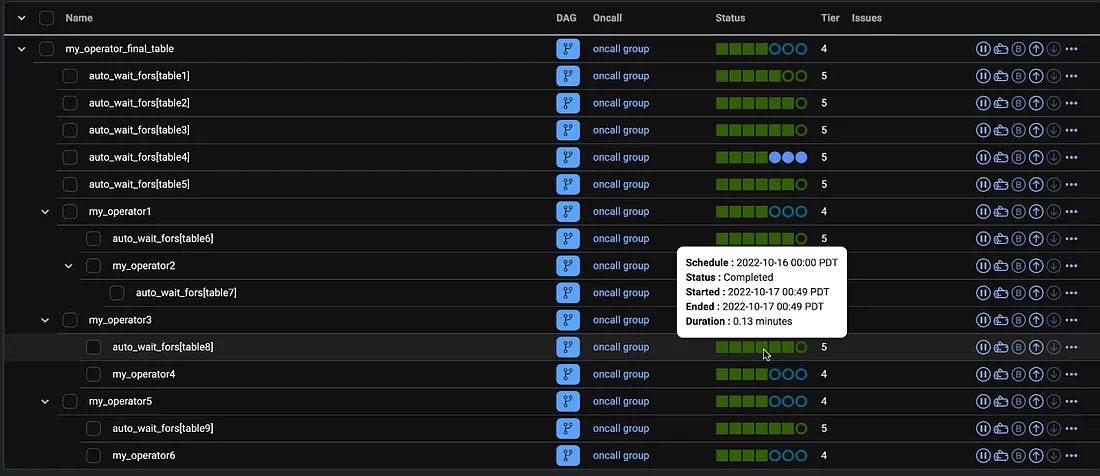
有点类似 Airflow 的 Tree View,除此之外还包括:
- 快速识别失败的 task,并找到对应的 log
- 定义和运行回填
- 导航到上游依赖
- 识别上游阻塞,递归的导航上游依赖,自动的找到 root,发现阻塞原因
- 如果不满足 SLA,则启动通知报警
- 设置监控数据质量检查
- 监控动态任务和历史性能
Conclusion
本文主要介绍了 数据工程师 所用的一些工具
一些 数据工程师主要工作是 创建 pipelines,创建 dashboards
另一些则专注于 日志、开发新的分析工具、专注于 ML 的 工作负载管理
这里没有覆盖的 工具
- 管理度量、试验方面的工具
- 试验测试平台
- 来用导出,展示试验的工具
- 私有工具
- 用来管理 ML 的特殊工具
- 用来理解 度量变化的 工具
未来的进一步工作包括
- 扩大隐私感知基础设置
- 减少查询的成本
- 减少存储的数据量
- 让 data engineers 管理大型管理更容易
- 减少 data engineers 重复的工作,让他们更专注产品