数据摄取:工具选择策略
原文
https://medium.com/the-modern-scientist/data-ingestion-part-2-tool-selection-strategy-07c6ca7aeddb
数据摄入工具,结合了 运营平面,分析平面,选择合适的工具很重要,不能很快的导入数据,分析就会失去价值
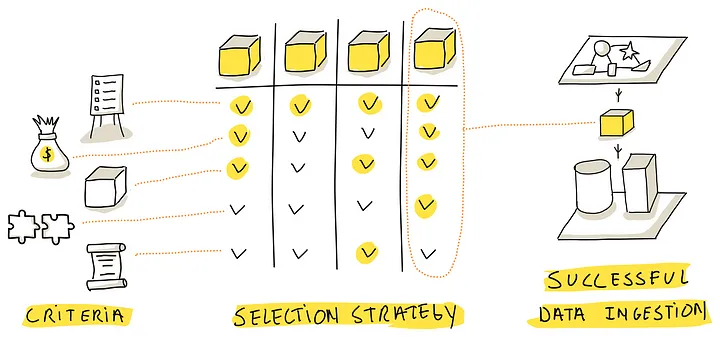
主要分为三个章节
- Tool Selection Criteria,套路需要的目标、供应商无关的标准,使企业组织数据,企业架构策略保持一致
- Ingestion Tool Flavors, 提供了各种可用工具的广泛讨论,讨论工业中最常用和最有效的方法
- Selection Strategy, 提出了一个系统的和迭代的方法来选择工具
Tool Selection Criteria
Strategic Criteria
(数据摄取工具必须与几个关键策略保持一致,包括数据、企业架构和IT策略。这些策略中通常列出的标准包括用户角色、体系结构考虑、维护和控制、避免供应商锁定、工具生态系统、简单性、操作计划、重用、购买或构建的决定,以及编排和监控的各个方面)
数据摄取工具策略,本质上的因素包括:数据、企业架构、IT战略 保持一致
- User Personas,识别用户角色,懂得和摄取工具的交互是关键,比如用户是熟练还是不熟练?是否提供一线支持,是否积极使用这些工具,这都影响了需要的工具的范围和复杂度
- Data Platform Architecture,数据平台的架构对工具选择的影响很大,如 ELT 需要选择多个不同的工具;或者为 ETL工具栈定义在特定的模块中
- Simplicity,从源 -> 目标使用的步骤越少越好,比如可以用一个工具来完成数据提取,实现简单性
- Vendor Lock-In,防止供应商锁定,一般来说“一个工具搞定所有”可能会被锁定,需要考虑退出的策略,以及影响
- Operational Plane Strategy,无论是流策略、使用SaaS产品,或者坚持本地的 RDBMS,每个都会导致不同的 选择策略
- Maintenance and Control Tradeoff,一些工具需要更多的维护,更新,升级,配置变更等单,但控制程度很高;而SaaS产品控制度很低,但维护成本降低了
- Monitoring and Orchestration,基于触发、或者调度,摄取工具也需要 编排和监控这些
- Reuse vs Buy vs Build,重用、采购、或者自己构建,这些需要符合整个公司的技术策略
- Tool Ecosystem,即使一个工具感觉不错,他可能价格不友好、或者缺乏成熟度、技术支持不够,这也带来一定风险,但特定工具可以解决特定场景也可以考虑
Pricing Criteria
各种 工具供应商提供了不同的定价策略,需要分析这些价格策略,懂得成本在不同场景下如何波动的
这些分析可以确保当前的需求,也能满足未来长远的需求
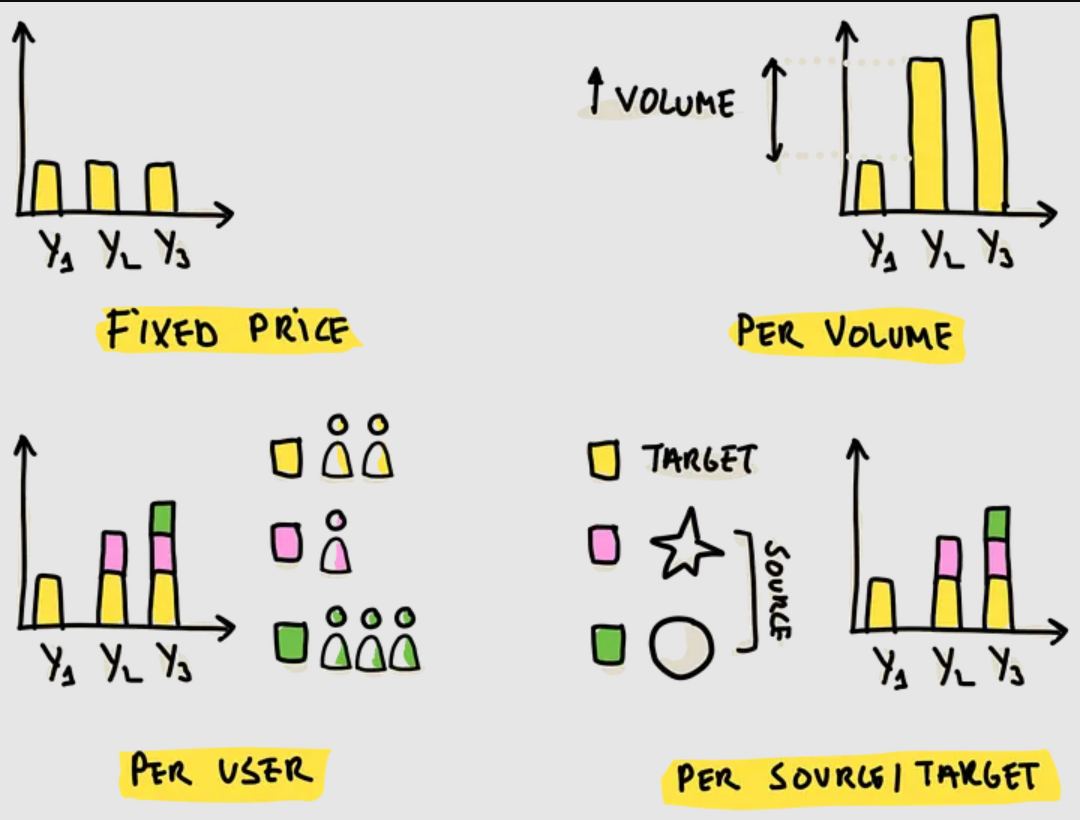
(数据摄取工具的价格策略,对当前和未来都很重要)
供应商的数据摄取工具价格策略
- Fixed Price,一些供应商使用了固定价格策略,无论规模和复杂程度,都可以事先预判
- Price per Ingested Data Volume,基于摄取的量来计费,一般是初始化免费,后面更新收费,或者是一段时间内更新主键的次数来收费
- Price per User,基于创建,修改数据摄取管道的用户量来收费,如果是在一个大企业内广泛使用,这个策略可能会受限
- Price per Source and Targe,广泛使用的策略,成本由每个数据源和 目标数据源的 CPU、内存、带宽等来计费的
- Price per Pipeline,基于配置了多少管道来定价,相比 源/目标定价,频繁重用管道时,可能使价格变很高
运行摄取工具,在云环境,会带来计算、存储成本,也会 间接提高价格
Functional Data Criteria
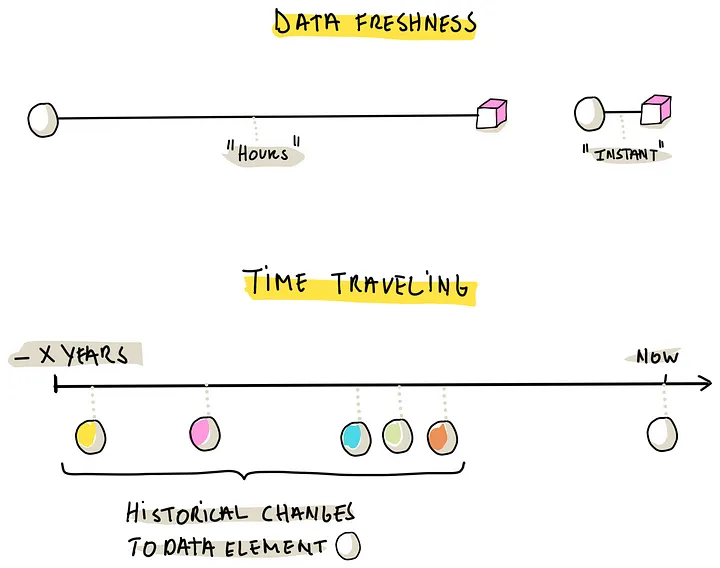
(数据更新需要实时,或者几小时更新一次,一些用例需要全面的历史数据,可以做 time travel回到以前的状态)
对数据摄取过程施加特定的功能性数据需求
- Data Freshness,分为每日更新,或者实时更新,他们的设计完全不同;选择这些策略不仅仅是数据摄取,还影响到整体策略和用户响应
- Time Traveling,对于某些场景是必须的,这就需要工具在开始之前捕获保存这些变更
- Data Volume,随着数据增长,工具应该能有效的处理,不会引起不必要的成本
- Data Variety,需要处理结构,非结构化数据
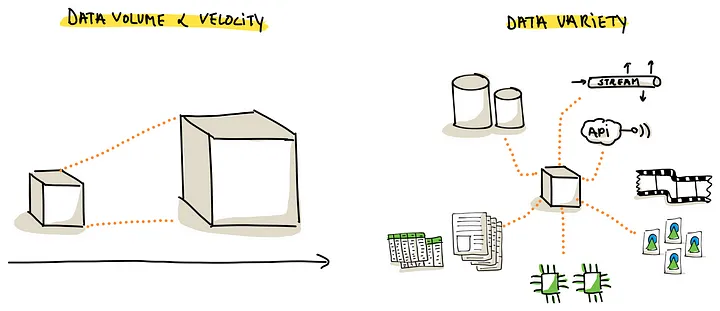
(大数据的关键“V”会显著影响数据摄取工具的选择。在这种选择中,音量、速度和多样性等因素发挥着关键作用)
理解这些数据功能需求,可以对其当前的工作,并适应未来的各种场景
Data Source and Target Criteria
数据源、目标的 标准也会影响 数据摄取工具
- Source Requirements,侧重于数据源的独特特性,如数据源支持的API 类型;流的协议,以及私有部署/云环境的不同;可能需要网关/中间件,这些细节规范很重要,决定了如何在数据源上 整合/执行
- Target Requirements,这里的重点是数据如何存储,如何管理;包括基于文件的数据湖、可扩展的数据仓库,以及传统的DBMS;每个存储都有特定的要求和功能,影响摄取工具的选择
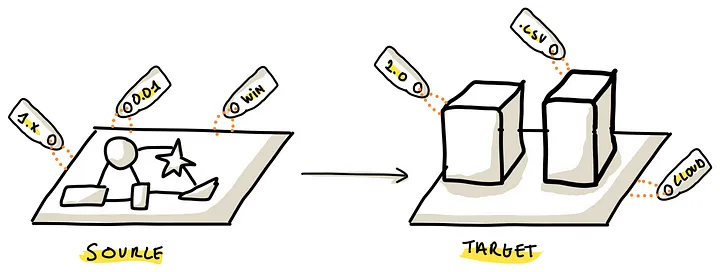
(源和目标的精确细节对于确定特定的数据摄取工具是否适合您的独特环境至关重要)
了解 源、目标数据源需求后,摄取工具不仅兼容现在的基础设施,也能有能力适配数据管理策略
Data Contract Criteria
在源、目标之间有效的转换,牵涉到:数据契约,也就是传输的数据格式
这依赖于数据源,包括各种类型,属性,DBMS中的列和数据类型,或者REST API,以及流数据
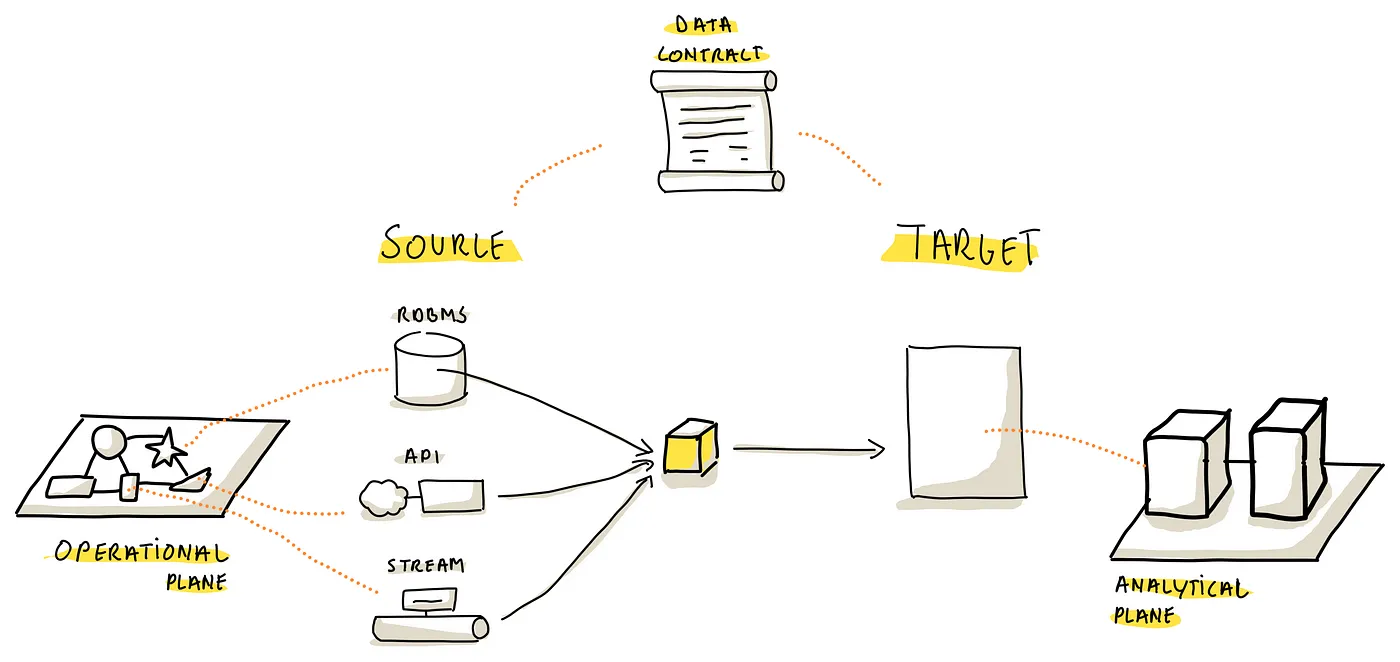
(隐式和显式数据契约构成了操作领域和分析领域之间的关键接口。数据摄取工具需要善于管理这些动态契约场景)
隐式和显式数据契约:
- Explicit Data Contract Definitions,这里的关键是是否可以跟包含显示定义的存储层整合,如果是,则需要管理和适配任何变化的能力,确保处理的一致性
- Resilience to Contract Changes,当契约失效、被意外更改时如何反馈?摄取过程是否停止,是否有回退或者通知机制?数据结构是否频繁变化?工具需要有处理中断和维护连续性的能力
了解这些对数据摄取工具的 鲁棒性,适配数据结构的能力很重要
Data Ingestion Tool Flavors
现在开始选择合适的工具
确保 跟 数据摄取工具建立一致标的标准
这里讨论 流行的摄取工具,每个类别都是独特的
Batch Loading Tools
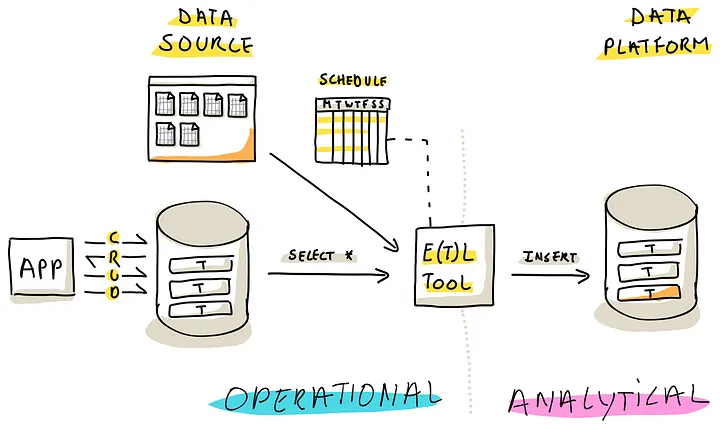
(批加载工具系统地从源检索数据并将其移动到指定的目的地)
批加载 需要周期性的调度,比如晚上,是 ETL、ELT 工具套件中的一员,一般来说包含两点
- Full Load,从源全量的导入数据到目标端
- Incremental Load,自上一次导入后的增量数据,一般需要主键、或者 时间戳来配合实现增量导入
批处理很简单,但也有缺点,会占用源系统大量的资源,也会影响系统性能,一般是在峰值较低的晚上进行,批处理可能会很长甚至几个小时
增量处理对源系统影响较小,可以做 5 - 10秒分钟一次来处理,但是依赖主键、时间戳,有些源系统可能不支持,影响其使用
Change Data Capturing (CDC) Tools
利用了数据库的 CDC 机制,可以实时的捕获变更,工具采用 ETL 处理 提取和加载,由数据平台负责转换
在各种复制方案中,基于 log 的复制最通用,CDC 工具访问数据库的 Write-Ahead Log WAL,这些log 记录了 CRUD 的变更,这样不需要对源系统做额外的操作
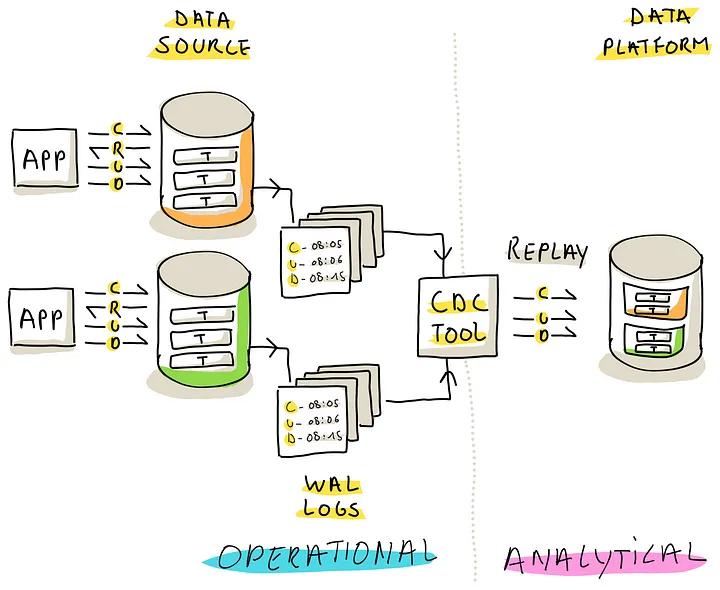
(基于cdc的摄取工具利用WAL日志将数据从源复制到目标)
为了更有效的利用 CDC,源系统一般需要持久化一段时间 WAL
一些高级的 CDC 工具,可以从一种格式转换到另外一种格式,如源系统 Oracle,转换到不同的目标系统 Delta Lake、Analytical Data WareHouse
需要注意的是,这些能力一般是为 数据库系统定制的,它们与其他数据源一起使用更多的是例外,而不是常态
Connector Based Tools
第三种数据摄取工具,通过 即插即用的:连接器 来运行
连接器用来从 源提取数据,加载到目标中,用户可以选择和集成这些组件到他们的摄取管道中
通过将复杂的细节封装在配置文件或用户友好界面中,简化了数据摄取的复杂性
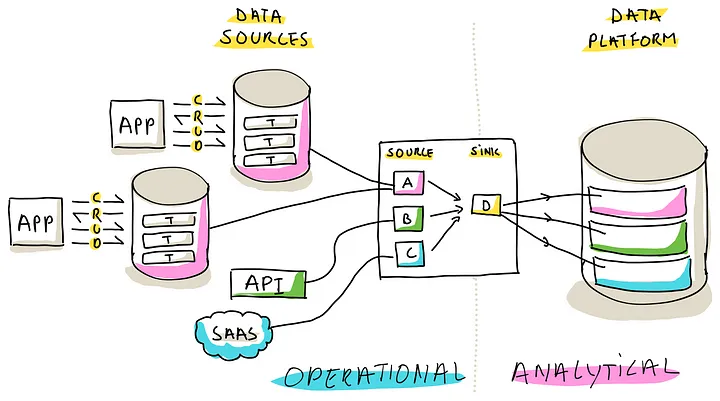
(基于连接器的工具可以通过将源连接器(用于提取)链接到目标连接器(用于加载)来设置摄取管道)
包括三种主要类型的 连接器
- Application Connectors,主要为 CRM, ERP, Payroll, Project Management 等产品设计的,基于API 提取方法,并根据每个应用做特殊定制
- Database Connectors,简化化了从数据库提取数据的过程,底层可能涉及 CDC 的流程,或标准批加载技术
- Generic Connectors,为通用目的设计的连接器,可以从 CSV加载,跟 REST、ODdata API交互,从 SFTP 提取数据
目标连接器可以 适配各种数据平台,跟 摄取管道无缝衔接,这些管道可以写到 数据仓库,数据湖,传统的 DBMS中
Code-Driven Data Ingestion
跟前面的 几个方式不同,这种是通过代码方式整合 摄取管道的,可能混合了代码和中间件
基于代码的方式有以下特点:
- High Level of Control,可以控制各个细节,可以高度定制,并实现不常见的类型,实现严格的 SLA
- Limited Vendor Lock-In,比专有工具提供的配置选项的方式,这种混合了编程语言和元数据的方式,可以最大程度防供应商锁定
- Automation Possibilities,可以基于源、目标,实现完全自动化的方式工作
- Build before Buy,跟使用成熟的方案比,从头开发需要更多的成本,而后续的维护成本更高
- Specific Personas,加入各种角色以及后期维护是个问题,需要很好的代码规范、文档、以及工程化的保障
Ingestion Tool Selection Strategy
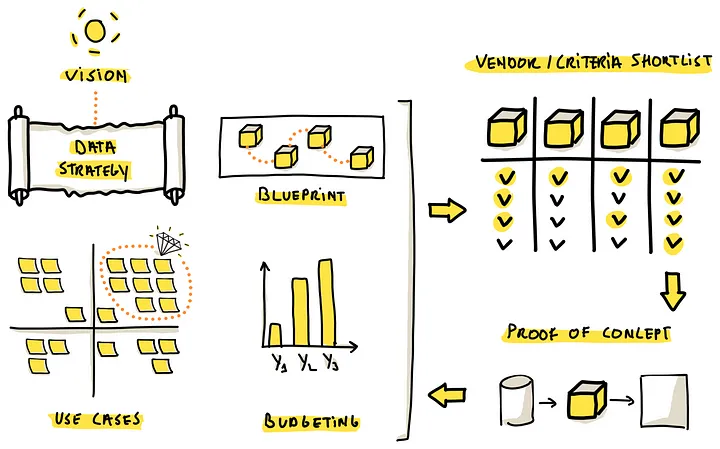
(一个系统的、迭代的策略对于创建一个基于无偏见的、供应商中立的选择标准的供应商候选名单是必不可少的)
选择一个合适的 数据摄取工具,是一个战略过程,应该迭代的进行并仔细考虑各种标准
要建立可持续的工具选择策略,可以从下面步骤开始:
- Define Data Product Use Cases,确定数据产品的用例和优先级,确定分析平面的特定数类型
- Develop a Preliminary Data Strategy,确定于组织数据处理相关的标准,是购买、简单VS复杂、避免供应商锁定,集中监控,工具的主要作用
- Sketch a Data Platform Architecture Blueprint,数据摄取工具只是数据平台体系的一部分,数据如何存储、如何编排、监控,将影响摄取工具的各种要求
- Budgeting,重要的是评估摄取处理的预算需求,考虑到企业的财政方式,可能涉及到年度预算,或者更详细的,基于收入的,以及首先的价格策略
有了这四个部分,就可以编制一个列表,根据需求进行定制,这个列表可以当做 供应商候选名单的基础;一旦有了这个列表就可以跟供应商联合,跟你的需求对齐
之后开始做 Proof of Concept POC,如果 poc失败,则继续从列表中找下一个供应商,poc 的结果可以作为选择工具的最终指导
主要这是一个迭代的过程,早起跟 供应商的交互可以 提炼出你的想法,POC 可以找到初始工作时忽略的需求
这个迭代方法确保了一个彻底、全面的方式,可以为企业提供一个非常合适的摄取工具
Conclusions
本文为选择合适的摄取工具作为数据平台的一部分,提供了一系列必须的标准
建议创建一个适合你企业指定需求和用例的,特定的策略
这种方法确保了对这些工具的供应商中立的观点,(第三部分)可能会介绍一些满足这些标准的市场研究
文章中介绍的标准不仅适用于数据摄取标准,对于数据平台的其他组件,如:存储方案、计算引擎、管道技术,也是适用的