Apache Iceberg is an open table format for huge analytic datasets.
Iceberg adds tables to compute engines including Spark, Trino, PrestoDB, Flink, Hive and Impala
using a high-performance table format that works just like a SQL table.
Basic Use
一些特性:
- Schema evolution supports add, drop, update, or rename, and has no side-effects
- Hidden partitioning prevents user mistakes that cause silently incorrect results or extremely slow queries
- Partition layout evolution can update the layout of a table as data volume or query patterns change
- Time travel enables reproducible queries that use exactly the same table snapshot, or lets users easily examine changes
- Version rollback allows users to quickly correct problems by resetting tables to a good state
目前支持的计算引擎
- Spark
- Flink
- Hive
- Trino
- ClickHouse
- Presto
- Dremio
- Starrocks
- Amazon Athena
- Amazone EMR
- Impala
- Doris
Table
Branching and Tagging
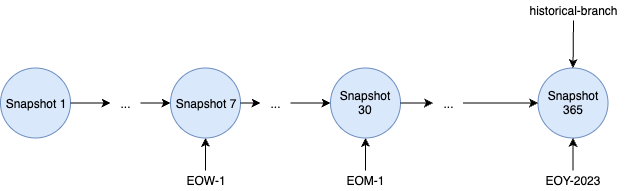
版本,time travel 等都是通过 元数据实现的,每次变更就是一个快照,支持快照过期策略,也就是快照的生命周期策略
iceberg 还提供了更丰富的功能,可以给这个快照 打 branch、tag,这样他们的生命周期,也就是过期策略 就独立了
支持 branch、tag 的快照管理
1
2
3
4
5
6
7
8
9
10
11
|
-- Create a tag for the first end of week snapshot. Retain the snapshot for a week
ALTER TABLE prod.db.table CREATE TAG `EOW-01` AS OF VERSION 7 RETAIN 7 DAYS;
-- Create a tag for the first end of month snapshot. Retain the snapshot for 6 months
ALTER TABLE prod.db.table CREATE TAG `EOM-01` AS OF VERSION 30 RETAIN 180 DAYS;
-- Create a tag for the end of the year and retain it forever.
ALTER TABLE prod.db.table CREATE TAG `EOY-2023` AS OF VERSION 365;
-- Create a branch "test-branch" which will be retained for 7 days along with the latest 2 snapshots
ALTER TABLE prod.db.table CREATE BRANCH `test-branch` RETAIN 7 DAYS WITH SNAPSHOT RETENTION 2 SNAPSHOTS;
|
Audit Branch
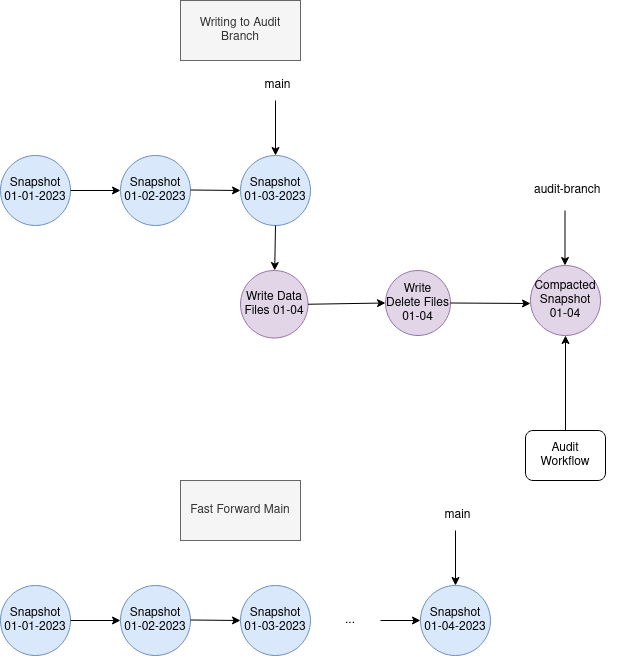
设置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
ALTER TABLE db.table SET TBLPROPERTIES (
'write.wap.enabled'='true'
);
-- Create audit-branch starting from snapshot 3, which will be written to and retained for 1 week.
ALTER TABLE db.table CREATE BRANCH `audit-branch` AS OF VERSION 3 RETAIN 7 DAYS;
-- WAP Branch write
SET spark.wap.branch = audit-branch
INSERT INTO prod.db.table VALUES (3, 'c');
-- After validation, the main branch can be fastForward to the head of audit-branch to update the main table state.
CALL catalog_name.system.fast_forward('prod.db.table', 'main', 'audit-branch');
-- The branch reference will be removed when expireSnapshots is run 1 week later.
|
Configuration
链接
Evolution
Schema evolution
- Add – add a new column to the table or to a nested struct
- Drop – remove an existing column from the table or a nested struct
- Rename – rename an existing column or field in a nested struct
- Update – widen the type of a column, struct field, map key, map value, or list element
- Reorder – change the order of columns or fields in a nested struct
Iceberg schema updates are metadata changes, so no data files need to be rewritten to perform the update.
Iceberg guarantees that schema evolution changes are independent and free of side-effects, without rewriting files:
- Added columns never read existing values from another column.
- Dropping a column or field does not change the values in any other column.
- Updating a column or field does not change values in any other column.
- Changing the order of columns or fields in a struct does not change the values associated with a column or field name.
Iceberg uses unique IDs to track each column in a table. When you add a column, it is assigned a new ID so existing data is never used by mistake.
支持分区演化
- 老的分区格式保持不变,新的分区格式变了,新数据写入到新分区后按照新格式
- 自动适配,SQL 不需要更改,通过元数据来实现的
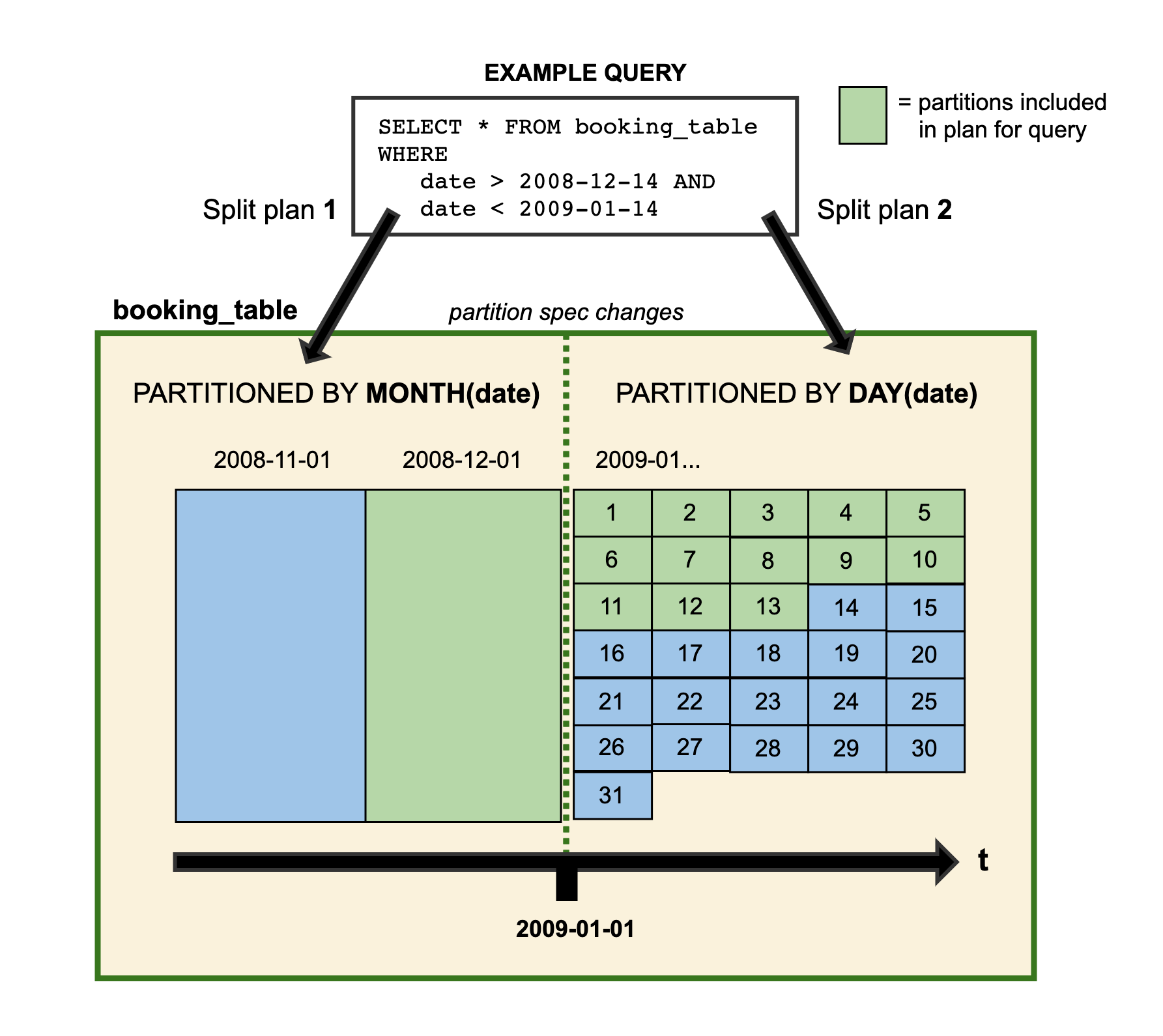
Sort order evolution
可以通过 API 修改排序顺序
1
2
3
4
5
|
Table sampleTable = ...;
sampleTable.replaceSortOrder()
.asc("id", NullOrder.NULLS_LAST)
.dec("category", NullOrder.NULL_FIRST)
.commit();
|
老版本的保持不动,新写入的会自动适配
Maintenance
Expire Snapshots
1
2
3
4
5
6
|
// This example expires snapshots that are older than 1 day:
Table table = ...
long tsToExpire = System.currentTimeMillis() - (1000 * 60 * 60 * 24); // 1 day
table.expireSnapshots()
.expireOlderThan(tsToExpire)
.commit();
|
以及
1
2
3
4
5
6
|
Table table = ...
SparkActions
.get()
.expireSnapshots(table)
.expireOlderThan(tsToExpire)
.execute();
|
Remove old metadata files
- write.metadata.delete-after-commit.enabled
- write.metadata.previous-versions-max
删除孤儿文件,比如任务执行时候后留下的
1
2
3
4
5
|
Table table = ...
SparkActions
.get()
.deleteOrphanFiles(table)
.execute();
|
小文件压缩,对于流场景需要
1
2
3
4
5
6
7
|
Table table = ...
SparkActions
.get()
.rewriteDataFiles(table)
.filter(Expressions.equal("date", "2020-08-18"))
.option("target-file-size-bytes", Long.toString(500 * 1024 * 1024)) // 500 MB
.execute();
|
重写元数据文件
1
2
3
4
5
6
|
Table table = ...
SparkActions
.get()
.rewriteManifests(table)
.rewriteIf(file -> file.length() < 10 * 1024 * 1024) // 10 MB
.execute();
|
metrics 类型
可用的 metrics
- LoggingMetricsReporter
- RESTMetricsReporter
- custom Metrics Reporter
自定义的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public class InMemoryMetricsReporter implements MetricsReporter {
private List<MetricsReport> metricsReports = Lists.newArrayList();
@Override
public void report(MetricsReport report) {
metricsReports.add(report);
}
public List<MetricsReport> reports() {
return metricsReports;
}
}
|
注册
1
2
3
4
5
6
7
8
9
|
TableScan tableScan =
table
.newScan()
.metricsReporter(customReporterOne)
.metricsReporter(customReporterTwo);
try (CloseableIterable<FileScanTask> fileScanTasks = tableScan.planFiles()) {
// ...
}
|
可以自动处理分区列
支持分区演化
plan 是单节点的,好处是
- Lower latency SQL queries – by eliminating a distributed scan to plan a distributed scan
- Access from any client – stand-alone processes can read data directly from Iceberg tables
两级的 manifest
- Manifest files store a list of data files, along each data file's partition data and column-level stats
- manifest list stores the snapshot's list of manifests, along with the range of values for each partition field
- Metadata files Defines the table, and tracks manifest lists, current and previous snapshots, schemas, and partition schemes.

首先通过分区的range,读取 manifest list,这样就可以找到 manifest files
之后,读取每个 manifest files,获取数据
manifest list 相当于一个高层的索引
而 manifest file 也包含了 列的统计信息,通过 lower & upper bounds 的谓词 skip,可以过滤掉很多数据,加速查询
Reliability
Hive 的问题
- 元数据用的是数据库,存储系统用的是分布式系统,两套系统,可能会导致不一致
- 大量分区 scan 的时候压力会很大,list分区,对文件系统是 O(N) 的操作
iceberg 的设计
- Serializable isolation: All table changes occur in a linear history of atomic table updates
- Reliable reads: Readers always use a consistent snapshot of the table without holding a lock
- Version history and rollback: Table snapshots are kept as history and tables can roll back if a job produces bad data
- Safe file-level operations. By supporting atomic changes, Iceberg enables new use cases, like safely compacting small files and safely appending late data to tables
可以解决的问题
- O(1) RPCs to plan: Instead of listing O(n) directories in a table to plan a job, reading a snapshot requires O(1) RPC calls
- Distributed planning: File pruning and predicate push-down is distributed to jobs, removing the metastore as a bottleneck
- Finer granularity partitioning: Distributed planning and O(1) RPC calls remove the current barriers to finer-grained partitioning
Concurrent write operations
- 用的是 OCC
- 提交的时候,swap metadata file
- 如果失败了,则重试
- 也可以使用 append 方式,这样写入的时候就不会有失败了
支持重命名,底层支持任何对象存储,不需要 list 操作
Schemas
支持下面类型
| Type |
Description |
Notes |
| boolean |
True or false |
|
| int |
32-bit signed integers |
Can promote to long |
| long |
64-bit signed integers |
|
| float |
32-bit IEEE 754 floating point |
Can promote to double |
| double |
64-bit IEEE 754 floating point |
|
| decimal(P,S) |
Fixed-point decimal; precision P, scale S |
Scale is fixed and precision must be 38 or less |
| date |
Calendar date without timezone or time |
|
| time |
Time of day without date, timezone |
Stored as microseconds |
| timestamp |
Timestamp without timezone |
Stored as microseconds |
| timestamptz |
Timestamp with timezone |
Stored as microseconds |
| string |
Arbitrary-length character sequences |
Encoded with UTF-8 |
| fixed(L) |
Fixed-length byte array of length L |
|
| binary |
Arbitrary-length byte array |
|
| struct<…> |
A record with named fields of any data type |
|
| list |
A list with elements of any data type |
|
| map<K, V> |
A map with keys and values of any data type |
|
Spark
API
一些例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
def xx(): Unit = {
val spark = SparkSession.builder
.master("local")
.appName("Iceberg spark example")
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.config("spark.sql.catalog.local", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.local.type", "hadoop")
.config("spark.sql.catalog.local.warehouse", "iceberg_warehouse")
.getOrCreate
spark.sql("create database iceberg_db");
spark.sql("CREATE TABLE local.iceberg_db.table (id bigint, data string) USING iceberg\n");
spark.sql("INSERT INTO local.iceberg_db.table VALUES (1, 'a'), (2, 'b'), (3, 'c')");
spark.sql(
"""
| CREATE TABLE if not exist local.iceberg_db.wokao(id int, name string) using iceberg
|""".stripMargin)
spark.sql(
"""
|INSERT INTO local.iceberg_db.wokao
|VALUES (1, 'wokao111'), (2, 'wokao222'), (3, 'wokao333')
|""".stripMargin)
val result = spark.sql(
"""
| select * from local.iceberg_db.wokao
|""".stripMargin)
result.show()
spark.sql(
"""
| SELECT count(1) as count, data
|FROM local.iceberg_db.table
|GROUP BY data;
|""".stripMargin).show()
spark.sql(
"""
| SELECT * FROM local.iceberg_db.wokao.snapshots;
|""".stripMargin).show()
}
val df = spark.table("local.db.table")
df.count()
|
打印结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
+---+--------+
| id| name|
+---+--------+
| 1|wokao111|
| 2|wokao222|
| 3|wokao333|
+---+--------+
+-----+----+
|count|data|
+-----+----+
| 1| a|
| 1| b|
| 1| c|
+-----+----+
+--------------------+-------------------+---------+---------+--------------------+--------------------+
| committed_at| snapshot_id|parent_id|operation| manifest_list| summary|
+--------------------+-------------------+---------+---------+--------------------+--------------------+
|2024-02-24 11:52:...|1288202450499236155| null| append|iceberg_warehouse...|{spark.app.id -> ...|
+--------------------+-------------------+---------+---------+--------------------+--------------------+
|
Spark Configuration
hive 的
1
2
3
4
|
spark.sql.catalog.hive_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hive_prod.type = hive
spark.sql.catalog.hive_prod.uri = thrift://metastore-host:port
# omit uri to use the same URI as Spark: hive.metastore.uris in hive-site.xml
|
rest
1
2
3
|
spark.sql.catalog.rest_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.rest_prod.type = rest
spark.sql.catalog.rest_prod.uri = http://localhost:8080
|
hadoop
1
2
3
|
spark.sql.catalog.hadoop_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hadoop_prod.type = hadoop
spark.sql.catalog.hadoop_prod.warehouse = hdfs://nn:8020/warehouse/path
|
自定义的
1
2
3
|
spark.sql.catalog.custom_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.custom_prod.catalog-impl = com.my.custom.CatalogImpl
spark.sql.catalog.custom_prod.my-additional-catalog-config = my-value
|
读和写
1
2
3
4
5
6
7
8
9
10
|
// time travel
spark.read
.option("snapshot-id", 10963874102873L)
.table("catalog.db.table")
// write with Avro instead of Parquet
df.write
.option("write-format", "avro")
.option("snapshot-property.key", "value")
.insertInto("catalog.db.table")
|
CommitMetadata
1
2
3
4
5
6
7
8
9
10
|
import org.apache.iceberg.spark.CommitMetadata;
Map<String, String> properties = Maps.newHashMap();
properties.put("property_key", "property_value");
CommitMetadata.withCommitProperties(properties,
() -> {
spark.sql("DELETE FROM " + tableName + " where id = 1");
return 0;
},
RuntimeException.class)
|
Spark DDL
一些例子
1
2
3
4
|
CREATE TABLE prod.db.sample (
id bigint COMMENT 'unique id',
data string)
USING iceberg;
|
设置分区
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
CREATE TABLE prod.db.sample (
id bigint,
data string,
category string)
USING iceberg
PARTITIONED BY (category);
CREATE TABLE prod.db.sample (
id bigint,
data string,
category string,
ts timestamp)
USING iceberg
PARTITIONED BY (bucket(16, id), days(ts), category);
|
其他一些建表方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
CREATE TABLE prod.db.sample
USING iceberg
AS SELECT ...
CREATE TABLE prod.db.sample
USING iceberg
PARTITIONED BY (part)
TBLPROPERTIES ('key'='value')
AS SELECT ...
REPLACE TABLE prod.db.sample
USING iceberg
AS SELECT ...
REPLACE TABLE prod.db.sample
USING iceberg
PARTITIONED BY (part)
TBLPROPERTIES ('key'='value')
AS SELECT ...
CREATE OR REPLACE TABLE prod.db.sample
USING iceberg
AS SELECT ...
|
Iceberg has full ALTER TABLE support in Spark 3, including:
- Renaming a table
- Setting or removing table properties
- Adding, deleting, and renaming columns
- Adding, deleting, and renaming nested fields
- Reordering top-level columns and nested struct fields
- Widening the type of int, float, and decimal fields
- Making required columns optional
branch、tag
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
-- CREATE audit-branch at current snapshot with default retention.
ALTER TABLE prod.db.sample CREATE BRANCH `audit-branch`
-- CREATE audit-branch at current snapshot with default retention if it doesn't exist.
ALTER TABLE prod.db.sample CREATE BRANCH IF NOT EXISTS `audit-branch`
-- CREATE audit-branch at current snapshot with default retention or REPLACE it if it already exists.
ALTER TABLE prod.db.sample CREATE OR REPLACE BRANCH `audit-branch`
-- CREATE audit-branch at snapshot 1234 with default retention.
ALTER TABLE prod.db.sample CREATE BRANCH `audit-branch`
AS OF VERSION 1234
-- CREATE audit-branch at snapshot 1234, retain audit-branch for 31 days, and retain the latest 31 days.
-- The latest 3 snapshot snapshots, and 2 days worth of snapshots.
ALTER TABLE prod.db.sample CREATE BRANCH `audit-branch`
AS OF VERSION 1234 RETAIN 30 DAYS
WITH SNAPSHOT RETENTION 3 SNAPSHOTS 2 DAYS
|
Spark Procedures
一些例子
1
2
3
|
CALL catalog_name.system.procedure_name(arg_name_2 => arg_2, arg_name_1 => arg_1);
CALL catalog_name.system.procedure_name(arg_1, arg_2, ... arg_n);
|
Roll back table db.sample to snapshot ID 1:
1
|
CALL catalog_name.system.rollback_to_snapshot('db.sample', 1);
|
Set the current snapshot for db.sample to 1:
1
2
3
|
CALL catalog_name.system.set_current_snapshot('db.sample', 1);
CALL catalog_name.system.set_current_snapshot(table => 'db.sample', tag => 's1');
|
expire_snapshots
1
2
3
|
CALL hive_prod.system.expire_snapshots('db.sample', TIMESTAMP '2021-06-30 00:00:00.000', 100);
CALL hive_prod.system.expire_snapshots(table => 'db.sample', snapshot_ids => ARRAY(123));
|
rewrite_manifests
1
2
3
|
CALL catalog_name.system.rewrite_manifests('db.sample');
CALL catalog_name.system.rewrite_manifests('db.sample', false);
|
Table migration
1
2
3
4
5
6
7
|
CALL catalog_name.system.snapshot('db.sample', 'db.snap');
CALL catalog_name.system.snapshot('db.sample', 'db.snap', '/tmp/temptable/');
CALL catalog_name.system.migrate('spark_catalog.db.sample', map('foo', 'bar'));
CALL catalog_name.system.migrate('db.sample');
|
Metadata information
1
2
|
CALL spark_catalog.system.ancestors_of('db.tbl', 1);
CALL spark_catalog.system.ancestors_of(snapshot_id => 1, table => 'db.tbl')
|
Change Data Capture
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
CALL spark_catalog.system.create_changelog_view(
table => 'db.tbl',
options => map('start-snapshot-id','1','end-snapshot-id', '2')
);
CALL spark_catalog.system.create_changelog_view(
table => 'db.tbl',
options => map('start-timestamp','1678335750489','end-timestamp', '1678992105265'),
changelog_view => 'my_changelog_view'
);
CALL spark_catalog.system.create_changelog_view(
table => 'db.tbl',
options => map('start-snapshot-id','1','end-snapshot-id', '2'),
identifier_columns => array('id', 'name')
)
SELECT * FROM tbl_changes;
SELECT * FROM tbl_changes where _change_type = 'INSERT' AND id = 3 ORDER BY _change_ordinal;
|
Queries
For example, to read from the files metadata table for prod.db.table:
1
|
SELECT * FROM prod.db.table.files;
|
Time travel
1
2
3
4
5
6
7
8
9
10
11
|
-- time travel to October 26, 1986 at 01:21:00
SELECT * FROM prod.db.table TIMESTAMP AS OF '1986-10-26 01:21:00';
-- time travel to snapshot with id 10963874102873L
SELECT * FROM prod.db.table VERSION AS OF 10963874102873;
-- time travel to the head snapshot of audit-branch
SELECT * FROM prod.db.table VERSION AS OF 'audit-branch';
-- time travel to the snapshot referenced by the tag historical-snapshot
SELECT * FROM prod.db.table VERSION AS OF 'historical-snapshot';
|
DataFrame
1
2
3
4
5
6
7
8
9
10
11
|
// time travel to October 26, 1986 at 01:21:00
spark.read
.option("as-of-timestamp", "499162860000")
.format("iceberg")
.load("path/to/table")
// time travel to snapshot with ID 10963874102873L
spark.read
.option("snapshot-id", 10963874102873L)
.format("iceberg")
.load("path/to/table")
|
Incremental read
1
2
3
4
5
6
|
// get the data added after start-snapshot-id (10963874102873L) until end-snapshot-id (63874143573109L)
spark.read()
.format("iceberg")
.option("start-snapshot-id", "10963874102873")
.option("end-snapshot-id", "63874143573109")
.load("path/to/table")
|
Inspecting tables
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
SELECT * FROM prod.db.table.history;
+--------------------+-------------------+---------+-------------------+
| made_current_at| snapshot_id|parent_id|is_current_ancestor|
+--------------------+-------------------+---------+-------------------+
|2024-02-24 11:52:...|1288202450499236155| null| true|
+--------------------+-------------------+---------+-------------------+
SELECT * from prod.db.table.metadata_log_entries;
SELECT * FROM prod.db.table.snapshots;
select
h.made_current_at,
s.operation,
h.snapshot_id,
h.is_current_ancestor,
s.summary['spark.app.id']
from prod.db.table.history h
join prod.db.table.snapshots s
on h.snapshot_id = s.snapshot_id
order by made_current_at;
SELECT * FROM prod.db.table.entries;
|
Files
1
2
3
4
5
6
|
SELECT * FROM prod.db.table.files
+-------+--------------------+-----------+------------+------------------+------------------+----------------+-----------------+----------------+--------------------+--------------------+------------+-------------+------------+-------------+
|content| file_path|file_format|record_count|file_size_in_bytes| column_sizes| value_counts|null_value_counts|nan_value_counts| lower_bounds| upper_bounds|key_metadata|split_offsets|equality_ids|sort_order_id|
+-------+--------------------+-----------+------------+------------------+------------------+----------------+-----------------+----------------+--------------------+--------------------+------------+-------------+------------+-------------+
| 0|iceberg_warehouse...| PARQUET| 3| 666|{1 -> 52, 2 -> 65}|{1 -> 3, 2 -> 3}| {1 -> 0, 2 -> 0}| {}|{1 -> � , 2 -> ...|{1 -> � , 2 -> ...| null| [4]| null| 0|
+-------+--------------------+-----------+------------+------------------+------------------+----------------+-----------------+----------------+--------------------+--------------------+------------+-------------+------------+-------------+
|
Manifests
SELECT * FROM prod.db.table.manifests;
Partitions
1
|
SELECT * FROM prod.db.table.partitions;
|
Positional Delete Files
1
|
SELECT * from prod.db.table.position_deletes;
|
All Data Files
1
2
3
4
5
6
7
8
9
10
|
SELECT * FROM prod.db.table.all_data_files;
+-------+--------------------+-----------+------------+------------------+------------------+----------------+-----------------+----------------+--------------------+--------------------+------------+-------------+------------+-------------+
|content| file_path|file_format|record_count|file_size_in_bytes| column_sizes| value_counts|null_value_counts|nan_value_counts| lower_bounds| upper_bounds|key_metadata|split_offsets|equality_ids|sort_order_id|
+-------+--------------------+-----------+------------+------------------+------------------+----------------+-----------------+----------------+--------------------+--------------------+------------+-------------+------------+-------------+
| 0|iceberg_warehouse...| PARQUET| 3| 666|{1 -> 52, 2 -> 65}|{1 -> 3, 2 -> 3}| {1 -> 0, 2 -> 0}| {}|{1 -> � , 2 -> ...|{1 -> � , 2 -> ...| null| [4]| null| 0|
+-------+--------------------+-----------+------------+------------------+------------------+----------------+-----------------+----------------+--------------------+--------------------+------------+-------------+------------+-------------+
SELECT * FROM prod.db.table.all_delete_files;
SELECT * FROM prod.db.table.all_entries;
|
All Manifests
1
2
3
4
5
6
|
SELECT * FROM prod.db.table.all_manifests;
+--------------------+------+-----------------+-------------------+----------------------+-------------------------+------------------------+-------------------+
| path|length|partition_spec_id| added_snapshot_id|added_data_files_count|existing_data_files_count|deleted_data_files_count|partition_summaries|
+--------------------+------+-----------------+-------------------+----------------------+-------------------------+------------------------+-------------------+
|iceberg_warehouse...| 5781| 0|1288202450499236155| 1| 0| 0| []|
+--------------------+------+-----------------+-------------------+----------------------+-------------------------+------------------------+-------------------+
|
References
1
|
SELECT * FROM prod.db.table.refs;
|
Structured Streaming
Streaming Reads
1
2
3
4
|
val df = spark.readStream
.format("iceberg")
.option("stream-from-timestamp", Long.toString(streamStartTimestamp))
.load("database.table_name")
|
Streaming Writes
1
2
3
4
5
6
|
data.writeStream
.format("iceberg")
.outputMode("append")
.trigger(Trigger.ProcessingTime(1, TimeUnit.MINUTES))
.option("checkpointLocation", checkpointPath)
.toTable("database.table_name")
|
In the case of the directory-based Hadoop catalog:
1
2
3
4
5
6
7
|
data.writeStream
.format("iceberg")
.outputMode("append")
.trigger(Trigger.ProcessingTime(1, TimeUnit.MINUTES))
.option("path", "hdfs://nn:8020/path/to/table")
.option("checkpointLocation", checkpointPath)
.start()
|
Iceberg supports append and complete output modes:
- append: appends the rows of every micro-batch to the table
- complete: replaces the table contents every micro-batch
Partitioned table
1
2
3
4
5
6
7
|
data.writeStream
.format("iceberg")
.outputMode("append")
.trigger(Trigger.ProcessingTime(1, TimeUnit.MINUTES))
.option("fanout-enabled", "true")
.option("checkpointLocation", checkpointPath)
.toTable("database.table_name")
|
Hive
With Hive version 4.0.0-alpha-2 and above, the Iceberg integration when using HiveCatalog supports the following additional features:
- Altering a table with expiring snapshots.
- Create a table like an existing table (CTLT table)
- Support adding parquet compression type via Table properties Compression types
- Altering a table metadata location
- Supporting table rollback
- Honors sort orders on existing tables when writing a table Sort orders specification
With Hive version 4.0.0-alpha-1 and above, the Iceberg integration when using HiveCatalog supports the following additional features
- Creating an Iceberg identity-partitioned table
- Creating an Iceberg table with any partition spec, including the various transforms supported by Iceberg
- Creating a table from an existing table (CTAS table)
- Altering a table while keeping Iceberg and Hive schemas in sync
- Altering the partition schema (updating columns)
- Altering the partition schema by specifying partition transforms
- Truncating a table
- Migrating tables in Avro, Parquet, or ORC (Non-ACID) format to Iceberg
- Reading the schema of a table
- Querying Iceberg metadata tables
- Time travel applications
- Inserting into a table (INSERT INTO)
- Inserting data overwriting existing data (INSERT OVERWRITE)
指定Catalog类型HiveCatalog
1
2
3
4
|
set iceberg.catalog.iceberg_hive.type=hive;
set iceberg.catalog.iceberg_hive.url=thrift://hadoop1:9083;
set iceberg.catalog.iceberg_hive.clients=10;
set iceberg.catalog.iceberg_hive.warehouse=hdfs://hadoop1:8020/warehouse/iceberg-hive;
|
建表
1
2
3
4
5
|
CREATE TABLE iceberg_test2 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
TBLPROPERTIES('iceberg.catalog'='iceberg_hive');
INSERT INTO iceberg_test2 values(1);
|
指定Catalog类型HadoopCatalog
1
2
|
set iceberg.catalog.iceberg_hadoop.type=hadoop;
set iceberg.catalog.iceberg_hadoop.warehouse=hdfs://hadoop1:8020/warehouse/iceberg-hadoop
|
建表
1
2
3
4
|
CREATE TABLE iceberg_test3 (i int)
STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://hadoop1:8020/warehouse/iceberg-hadoop/default/iceberg_test3'
TBLPROPERTIES('iceberg.catalog'='iceberg_hadoop');
|
hive 读取 hbase 上的表
1
2
3
4
5
6
7
8
9
10
11
12
13
|
CREATE EXTERNAL TABLE hive_hbase_table_example(
key int,
value string
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" = ":key,cf:value"
)
TBLPROPERTIES (
"hbase.table.name" = "hbase_table_name",
"hbase.mapred.output.outputtable" = "hbase_table_name"
);
|
Flink
API
建 catalog,建库等
1
2
3
4
5
6
7
8
9
10
11
12
13
|
CREATE CATALOG hive_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://localhost:9083',
'clients'='5',
'property-version'='1',
'warehouse'='hdfs://nn:8020/warehouse/path'
);
CREATE TABLE `hive_catalog`.`default`.`sample` (
id BIGINT COMMENT 'unique id',
data STRING
);
|
写入
1
2
|
INSERT INTO `hive_catalog`.`default`.`sample` VALUES (1, 'a');
INSERT INTO `hive_catalog`.`default`.`sample` SELECT id, data from other_kafka_table;
|
API
1
2
3
4
5
6
7
8
9
10
11
|
StreamExecutionEnvironment env = ...;
DataStream<RowData> input = ... ;
Configuration hadoopConf = new Configuration();
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://nn:8020/warehouse/path", hadoopConf);
FlinkSink.forRowData(input)
.tableLoader(tableLoader)
.append();
env.execute("Test Iceberg DataStream");
|
读取
1
2
3
4
5
6
7
8
9
10
11
12
|
-- Submit the flink job in streaming mode for current session.
SET execution.runtime-mode = streaming;
-- Enable this switch because streaming read SQL will provide few job options in flink SQL hint options.
SET table.dynamic-table-options.enabled=true;
-- Read all the records from the iceberg current snapshot, and then read incremental data starting from that snapshot.
SELECT * FROM `hive_catalog`.`default`.`sample` /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/ ;
-- Read all incremental data starting from the snapshot-id '3821550127947089987' (records from this snapshot will be excluded).
SELECT * FROM `hive_catalog`.`default`.`sample` /*+ OPTIONS('streaming'='true',
'monitor-interval'='1s', 'start-snapshot-id'='3821550127947089987')*/ ;
|
Flink Connector
connector 方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='hive_prod',
'uri'='thrift://localhost:9083',
'warehouse'='hdfs://nn:8020/path/to/warehouse'
);
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='hive_prod',
'catalog-database'='hive_db',
'catalog-table'='hive_iceberg_table',
'uri'='thrift://localhost:9083',
'warehouse'='hdfs://nn:8020/path/to/warehouse'
);
|
hadoop catalog
1
2
3
4
5
6
7
8
9
|
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='hadoop_prod',
'catalog-type'='hadoop',
'warehouse'='hdfs://nn:8020/path/to/warehouse'
);
|
rest catalog
1
2
3
4
5
|
CREATE CATALOG rest_catalog WITH (
'type'='iceberg',
'catalog-type'='rest',
'uri'='https://localhost/'
);
|
自定义的 catalog
1
2
3
4
5
6
7
8
9
10
11
|
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='custom_prod',
'catalog-impl'='com.my.custom.CatalogImpl',
-- More table properties for the customized catalog
'my-additional-catalog-config'='my-value',
...
);
|
完整的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='hive_prod',
'uri'='thrift://localhost:9083',
'warehouse'='file:///path/to/warehouse'
);
INSERT INTO flink_table VALUES (1, 'AAA'), (2, 'BBB'), (3, 'CCC');
SET execution.result-mode=tableau;
SELECT * FROM flink_table;
+----+------+
| id | data |
+----+------+
| 1 | AAA |
| 2 | BBB |
| 3 | CCC |
+----+------+
3 rows in set
|
DDL Queries
主键和分区
1
2
3
4
5
6
7
8
9
10
11
12
|
CREATE TABLE `hive_catalog`.`default`.`sample` (
id BIGINT COMMENT 'unique id',
data STRING NOT NULL,
PRIMARY KEY(`id`) NOT ENFORCED
) WITH ('format-version'='2');
CREATE TABLE `hive_catalog`.`default`.`sample` (
id BIGINT COMMENT 'unique id',
data STRING NOT NULL
)
PARTITIONED BY (data)
WITH ('format-version'='2');
|
查询
1
2
3
4
5
|
-- Execute the flink job in streaming mode for current session context
SET execution.runtime-mode = streaming;
-- Execute the flink job in batch mode for current session context
SET execution.runtime-mode = batch;
|
批量读
1
2
3
|
-- Execute the flink job in batch mode for current session context
SET execution.runtime-mode = batch;
SELECT * FROM sample;
|
批量读 API
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://nn:8020/warehouse/path");
DataStream<RowData> batch = FlinkSource.forRowData()
.env(env)
.tableLoader(tableLoader)
.streaming(false)
.build();
// Print all records to stdout.
batch.print();
// Submit and execute this batch read job.
env.execute("Test Iceberg Batch Read");
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://nn:8020/warehouse/path");
IcebergSource<RowData> source = IcebergSource.forRowData()
.tableLoader(tableLoader)
.assignerFactory(new SimpleSplitAssignerFactory())
.build();
DataStream<RowData> batch = env.fromSource(
source,
WatermarkStrategy.noWatermarks(),
"My Iceberg Source",
TypeInformation.of(RowData.class));
// Print all records to stdout.
batch.print();
// Submit and execute this batch read job.
env.execute("Test Iceberg Batch Read");
|
流式读
1
2
3
4
5
6
7
8
9
10
11
|
-- Submit the flink job in streaming mode for current session.
SET execution.runtime-mode = streaming;
-- Enable this switch because streaming read SQL will provide few job options in flink SQL hint options.
SET table.dynamic-table-options.enabled=true;
-- Read all the records from the iceberg current snapshot, and then read incremental data starting from that snapshot.
SELECT * FROM sample /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/ ;
-- Read all incremental data starting from the snapshot-id '3821550127947089987' (records from this snapshot will be excluded).
SELECT * FROM sample /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s', 'start-snapshot-id'='3821550127947089987')*/ ;
|
流式读 API
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://nn:8020/warehouse/path");
DataStream<RowData> stream = FlinkSource.forRowData()
.env(env)
.tableLoader(tableLoader)
.streaming(true)
.startSnapshotId(3821550127947089987L)
.build();
// Print all records to stdout.
stream.print();
// Submit and execute this streaming read job.
env.execute("Test Iceberg Streaming Read");
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://nn:8020/warehouse/path");
IcebergSource source = IcebergSource.forRowData()
.tableLoader(tableLoader)
.assignerFactory(new SimpleSplitAssignerFactory())
.streaming(true)
.streamingStartingStrategy(StreamingStartingStrategy.INCREMENTAL_FROM_LATEST_SNAPSHOT)
.monitorInterval(Duration.ofSeconds(60))
.build();
DataStream<RowData> stream = env.fromSource(
source,
WatermarkStrategy.noWatermarks(),
"My Iceberg Source",
TypeInformation.of(RowData.class));
// Print all records to stdout.
stream.print();
// Submit and execute this streaming read job.
env.execute("Test Iceberg Streaming Read");
|
Roadmap
General
- Multi-table transaction support
- Views Support
- Change Data Capture (CDC) Support
- Snapshot tagging and branching
- Inline file compaction
- Delete File compaction
- Z-ordering / Space-filling curves
- Support UPSERT
Clients
- Add the Iceberg Python Client
- Add the Iceberg Rust Client
- Add the Iceberg Go Client
Spec V2
- Views Spec
- DSv2 streaming improvements
- Secondary indexes
Spec V3
- Encryption
- Relative paths
- Default field values
Reference