Copy-On-Write vs Merge-On-Read in Apache Iceberg
Updating Tables on the Data Lake
更新、删除能力对于传统数据库是必须的,但对于数据仓库来说,他只是一个特殊的数据库,用于做分析处理
data lakes用于解决成本、扩展性的问题,用独立的技术来解决如存储,计算等问题,可扩展也可以通过对象存储来解决
计算引擎演化为主要处理读的计算
lake house则从传统的数据仓库,往数据湖方向走
而对于写密集型的场景,data lake 需要在计算、存储之间增加新的抽象,来实现 ACID 保证以及性能,这也是 数据湖表格式出现的原因
iceberg 就是存储和计算之间的表格式
iceberg提供了 ACID保障,v2表格式 可以在不可变数据删实现 update、delete,而不用重写整个文件
有两种方式可以实现 update、delete等特性
- copy-on-write (COW)
- merge-on-read (MOR).
没有一种通吃的方案,每个方案都是 trade-off,有他们合适的场景,主要考虑的是 读、写的延迟
这也不是 iceberg 特有的问题,对于其他场景,如 lambda 架构也会存在这些问题
CoW-Best for tables with frequent reads, infrequent writes/updates, or large batch updates
CoW,当要更新、删除 某一行、或者一批行时,会将数据文件复制一份
新版本中会包含更新的数据,删除的话,就做取反操作,将没被删除的数据重写一份
写入的速度依赖于要更新多少 数据文件(重写这些文件),在并发执行时也会导致冲突,出现更多的重试
如果要更新很多行,那么 CoW 倒是不错的选择,但如果更新的行也少,也需要重写整个文件,代价就比较高了
对于读来说,没有什么额外要做的事情,正常读就可以了,所以适合 读多写少的场景

| Summary of COW (Copy-On-Write) | |
|---|---|
| PROS | CONS |
| Fastest reads | Expensive writes |
| Good for infrequent updates/deletes | Bad for frequent updates/deletes |
MoR - Best for tables with frequent writes/updates
MoR 时,文件不需要重写,只需 将更改写入到新文件中,在读取的时候使,将这些变更 merge 到原始文件中,形成 新的状态
这种方式写入时很快,但也意味着 读的时候,需要做更多的事情
iceberg 是通过跟踪 update、delete的文件实现的
如果删除一行,就将其添加到删除文件中,读取时重建这些文件
如果是更新一行,delete 文件也会个跟踪这个 update,之后读取时会忽略掉旧的数据
而做了数据压缩之后,就跟 LSM 树格式一样,只会记录合并后的少量数据,更新前的数据就会被忽略
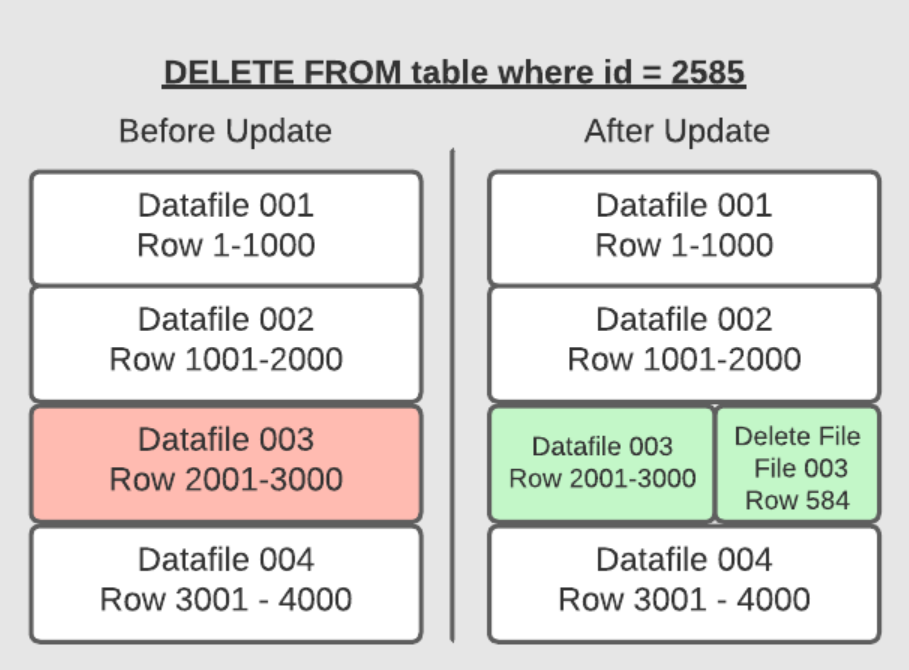
Position Deletes
在这个模式中,仍然需要读取记录文件,但不需要重写文件了
而是记录被删除文件记录中的位置
这个策略 很大程度上减少了update、delete的写时间,读的时候,merge 的成本也相对较低
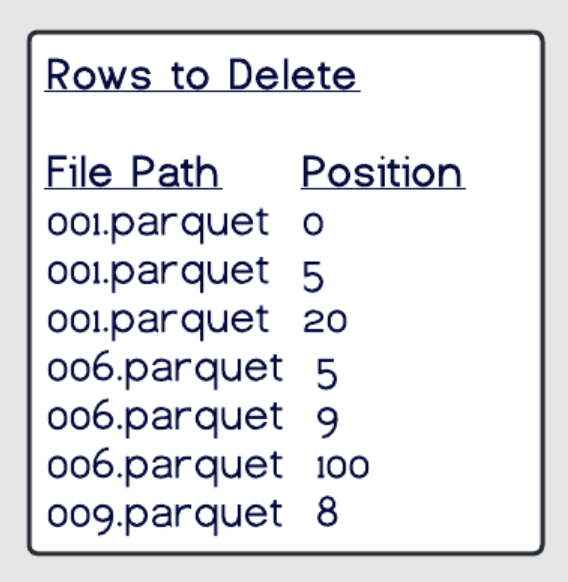
Equality Deletes
在写入的时候不需要读取任何文件,对于写时间可以进一步提升
在删除文件中记录 待删除/更新的 字段,以及值
这种策略在 更新的时候,比 Position Deletes要快很多
但是读取的代价很高,需要扫描所有的行,然后做重建

Minimizing the Read Costs
当执行压缩时,会写入新文件,这个文件根据 删除文件,旧文件做了合并重建,这样读取时就不需要做额外操作了
推荐定期执行 压缩,这样对读的的影响就降低了,同时也能保持高的写性能
Types of Delete Files Summary
| How it works | Pros | Cons | How to manage read costs | Good fit | |
|---|---|---|---|---|---|
| Position | Tracks file path and row position in file | Fast writes | Slower reads | Run compaction jobs regularly | Better forfrequent updates/deletes in which copy- on-write is not fast enough |
| Equality | Tracks query criteria for delete/update targets | Super-fast writes | Much slower reads | For when updates/deletes with position deletes is still not fast enough |
When to Use COW and When to Use MOR
选择 CoW、MoR/position、MoR/equality 取决于如何使用表
可以根据场景预测表的使用方式,如果选择不对,也可以简单调整策略
| Approach | Update/Delete Frequency | Insert Performance | Update/Delete Latency/Performance | Read Latency/Performance |
|---|---|---|---|---|
| Copy-On-Write | Infrequent updates/deletes | Same | Slowest | Fastest |
| Merge-On-Read Position Deletes | Frequent updates/deletes | Same | Fast | Fast |
| Merge-On-Read Equality Deletes | Frequent updates/deletes where position delete MOR is still not fast enough on the write sid | Same | Fastes | Slowest |
Configuring COW and MOR
COW 、MOR 不是非此即彼的选项,可以在表的配置中 独立的设置 delete、update、merge选项
|
|
可以使用 alter 修改
|
|
Further Optional Delete/Updates Fine-Tuning Strategies
几个注意点
- 分区字段一般包含在查询中,特别像时间戳这样的字段,可以加速查询
- 排序表字段一般也包含在分区字段中,如 timestamp
- 对单独的列做额外的元数据调整,可以用 write.metadata.metrics 对每个字段做细粒度调整
- 比如对于流写入,一般波动不会太大,可以禁用 check-ordering 设置,这样就不会检查写入数据的字段是否与表顺序相同,可以节省时间
|
|
Reference
- Apache Iceberg 101 – Your Guide to Learning Apache Iceberg Concepts and Practices
- Exploring the Architecture of Apache Iceberg, Delta Lake, and Apache Hudi
- Compaction in Apache Iceberg: Fine-Tuning Your Iceberg Table’s Data Files
- Deep Dive Into Configuring Your Apache Iceberg Catalog with Apache Spark
- Hadoop Modernization: A Framework for Success
- Apache Iceberg FAQ
- Multi-Table Transactions on the Lakehouse – Enabled by Dremio Arctic
- A Hands-On Look at the Structure of an Apache Iceberg Table
- New: Row-Level and Column-Level Access Controls
- Compaction in Apache Iceberg: Fine-Tuning Your Iceberg Table’s Data Files
- Table Format Partitioning Comparison: Apache Iceberg, Apache Hudi, and Delta Lake
- Migrating a Hive Table to an Iceberg Table Hands-on Tutorial
- Table Format Governance and Community Contributions: Apache Iceberg, Apache Hudi, and Delta Lake
- How We Got to Open Lakehouse
- Comparison of Data Lake Table Formats (Apache Iceberg, Apache Hudi and Delta Lake)
- How to Build a Modern, Cloud-Native Analytics Stack with GoodData and Dremio