Apache Iceberg Tables 的读写和查询管理
原文
https://www.dremio.com/blog/the-life-of-a-read-query-for-apache-iceberg-tables/
Apache Iceberg 101
存储层的结构如下:
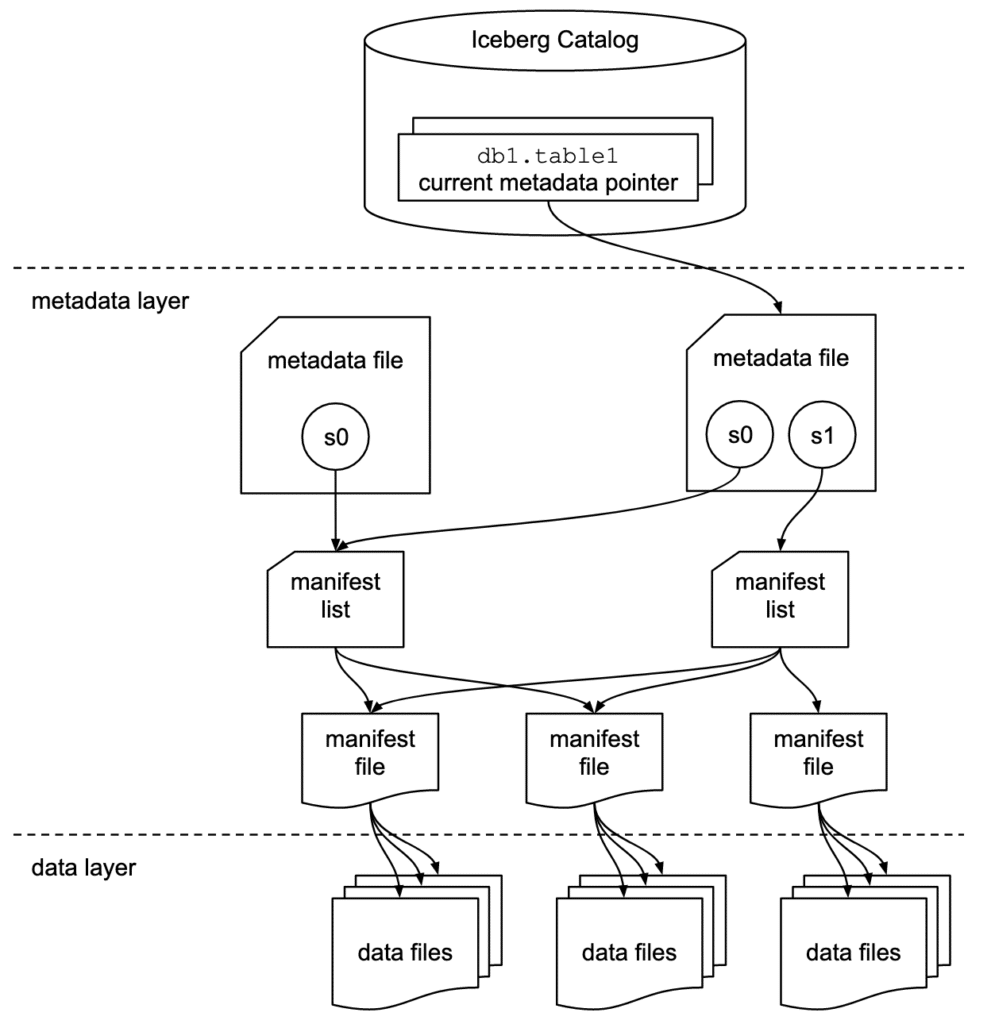
Data Layer
- Data files – Parquet or ORC 的存储格式,真实数据放这里
- Delete files – 被认为是删除的数据
Metadata Layer
- Manifest files – 一个快照的子集,这些文件用于追踪这些子集中独立的数据文件,以及进一步的元数据裁剪
- Manifest lists – 定义一个表的快照,列出构成这个快照的所有 manifest文件,以及进一步裁剪的元数据
- Metadata files – 定义表,跟踪 manifest lists,当前以及前一个快照,schemas,以及 分区 schemas
The Catalog
- 这个指定当前的元数据文件,可以提供类似数据库的事务保证,以及元数据存储功能
官网的描述信息
How a Query Engine Processes the Query
基于order表的查询,表结构
|
|
查询语句
|
|
Metadata Qeruy
查询首先被提交到 engine,然后被解析,engine 需要知道这个表的元数据,才能做plan
查询元数据,四个步骤执行过程如下:
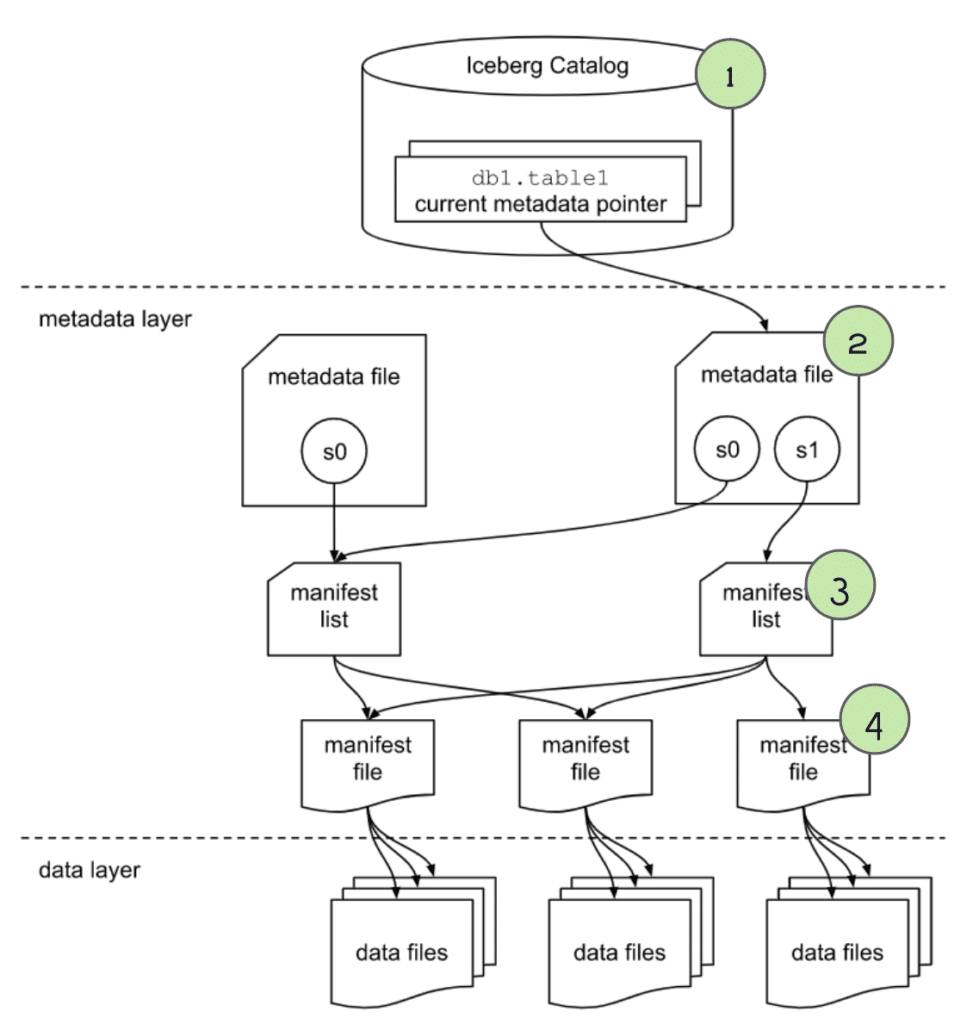
第一步,获取 catalog,根据 catalog 获取 orders 表的当前元数据文件
第二步,通过 order 表的最新的元数据,可以
- 拿到表的 schema
- 表的分区信息,之后在 plan 中可以做裁剪
- 当前快照的 “manifest list” 可以知道 需要再进一步扫描哪些文件

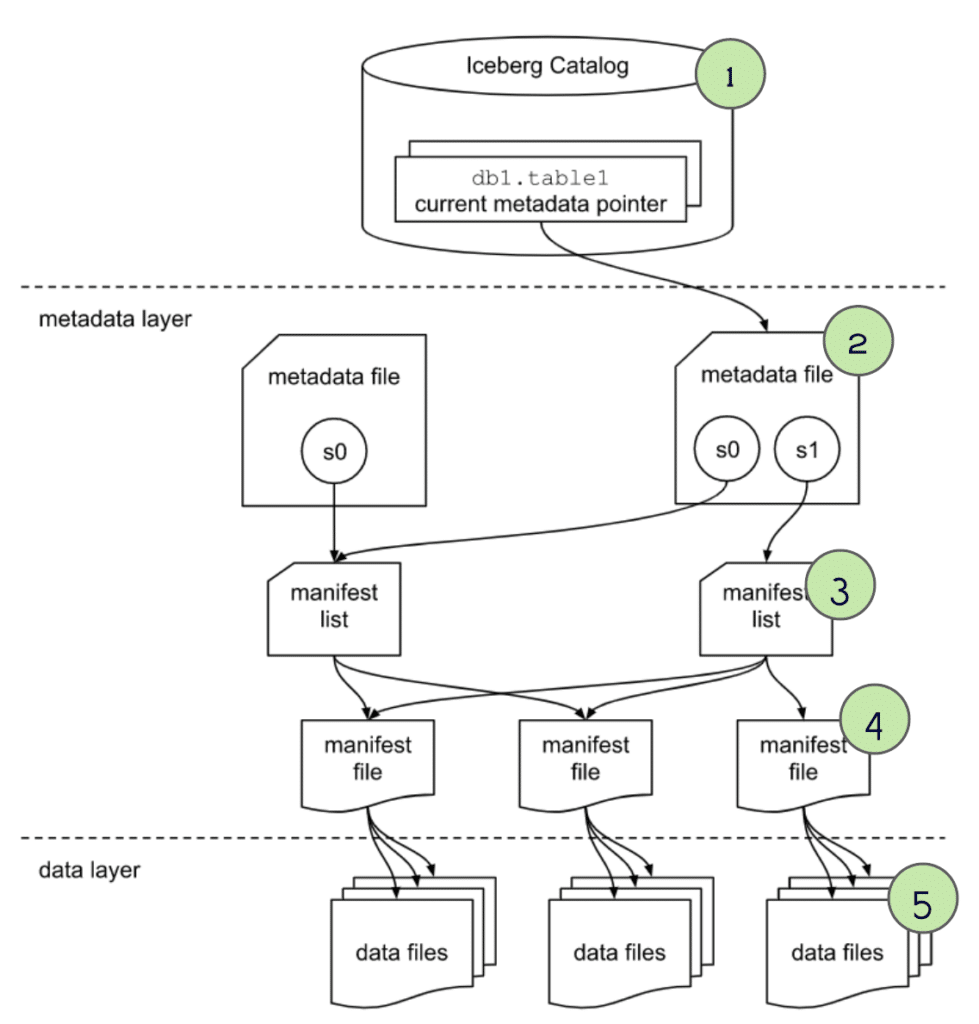
第三步,通过 manifest list 文件,我们可以再进一步
- partition-spec-id,可以拿到分区的 schema信息,当前的 order 只有一个分区
- 每个分区还包含了一些统计信息,通过 lower 和 upper 边界,可以可以确定 是否要跳过这个分区
- 当后面拿到 manifest file 时候还可以再做进一步的 skip

第四步,根据每个 manifest file 文件,可以继续做裁剪,然后获取每个文件对应的 data
- schema-id, partition-id 包含的就是数据文件信息
- 内容的类型,比如可以跳过 delete类型的数据
- 列中包含了 value内容、唯一值、lower、upper信息,可以做裁剪

Performing the Scan and Returning the Results
经过上面几次 裁剪后,真正要扫描的数据文件就很少了
parquet 文件本身也包含 min/max信息,还可以继续在文件级别继续 裁剪
Time Travel
查询前一个版本的信息
|
|
这里使用了 TIMESTAMP AS OF ,用做 time travel 用的
完整的执行过程如下:
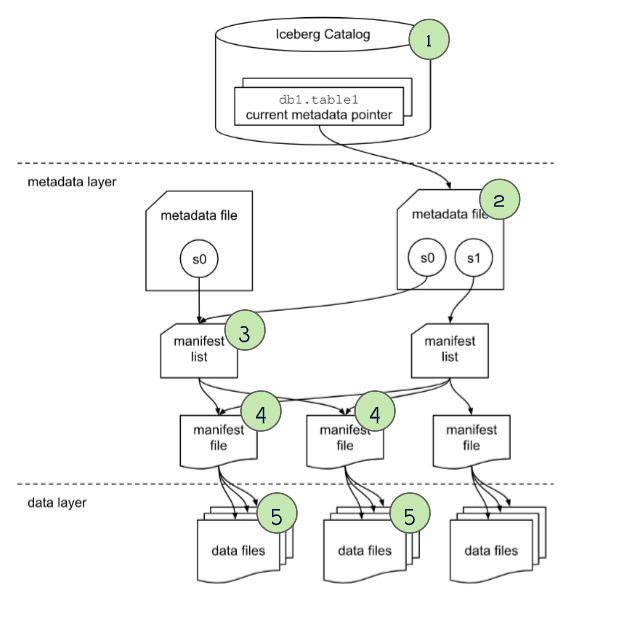
通过最新的 快照,可以:
- 通过比较快照 id,或者 快照的 timestamp,找到 AS OF 之前的快照
- 获取这个表的 schema
- 获取查询分区,用于裁剪,以及目标快照的 manifest list

跟普查查询类似,找到 manifest list 文件
- 通过 partition-spec-id,可以知道分区信息
- 分解分区的统计信息,lower 和 upper做进一步裁剪
- 在这里可以 skip 大量不需要的分区

对于 manifest files
- schema-id、partition-id 对应于数据文件
- 跳过 delete 类型的文件
- 根据 统计信息,如 lower、upper,做裁剪

接下来就是 scan 数据文件,因为前面已经 skip 了大量的文件,此时需要扫描的文件就少很多了
parquet文件本身也可以做谓词下推,进一步减少读取的数量
整个过程,其实跟普通的读取差不多
How a Query Engine Processes the Write
Insert
查询语句
|
|
执行过程
- 查询被提交到 engine,解析,之后查询引擎开始解析
- 获取 catalog,拿到 schema,尽管只是append,但要确认两件事
- 确保满足表的 schema,以及哪些字段不能为 null
- 获取表的分区,确定如何组织写入的数据
- 写入数据
- 因为是 insert,所以不会对已有文件造成影响,只要写入新文件即可
- 写入时根据表的分区 schema信息做写入
- 如果设置了排序顺序,并且engine 也支持,则写入也会按照指定要求写入
- 写入元数据
- 写入每个 manifest file 文件,每个文件包含了数据文件的具体路径,每个列的统计信息等
- 将本地快照中新增的 manifest file,已经存在的 manifest file,一起写入到 新的 manifest list 中
- 在这个 manifest list中,包含了所有 manifest file 的路径,以及每个文件的信息,如每个分区的 lower和upper等
- 创建一个 metadata file用来汇总表信息,包含文件路径,以及 manifest list 信息等
- 提交
- engine 再一次获取 catalog,以确保在写入的同时,没有新的快照出现
- 这是为了防止并发写入冲突
- 当出现冲突时第一个写入成功,后面的写入者会重试 3 或者 4,直到成功或者 重试失败退出
- 读取的时候总是拿到最新的快照,所以并发写入还没有提交时不会有影响
Delete
语句
|
|
执行过程
- 发送请求到 engine,准备解析
- 获取 catalog拿到最新的 metadata file
- 根据表的分区信息,确定如何写入数据
- 获取当前的 序列ID,事务序列ID, 假设在完成之前没有其他的写入冲突,利用了 OCC 机制
- 写文件
- 写策略取决于表的删除策略:“copy-on-write” (COW) or “merge-on-read” (MOR)
如果是 copy-on-write
- 通过元数据,识别出哪些文件包含删除的数据
- 完整的读取这些文件,确定删除的内容
- 写一个新文件替换这个快照中的文件,新文件中不包含被删除的内容
如果是 merge-on-write 避免了重写数据文件,但包含了墓碑的删除数据文件,读取时需要进一步处理,包含两种删除
- Position deletes
- Equality deletes
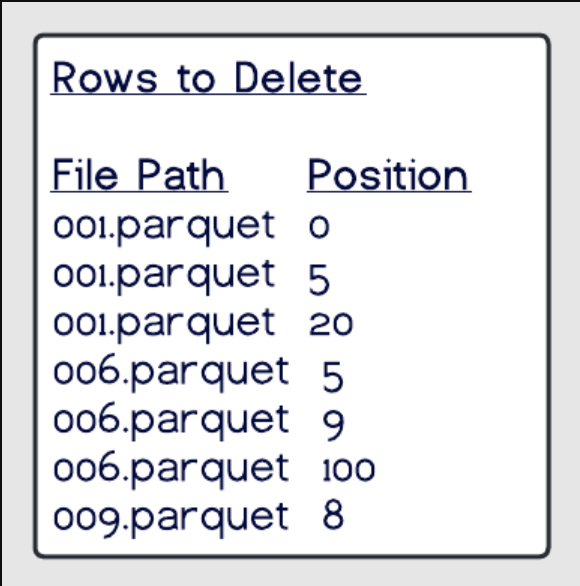
Position deletes
- 通过扫描元数据,确定哪些文件被删除
- 通过扫描数据文件,确定要删除的记录位置
- 在分区中写一个删除类型的文件,记录了哪些记录是按位置从 哪些文件中删除的
Equality deletes
- 不需要扫描任何文件,只需要写一个删除类型的文件,列出哪些行中的值要被删除
- 在读取时,根据删除类型文件和分区中的数据记录做重建,这个操作代价很高

原始的文件仍然被保留,当后续读取时,会根据 删除类型文件,旧文件做合并处理
- 写元数据文件
- 开始写入 manifest file,每个文件包含 数据文件的路径,以及文件的 列统计信息,lower和upper等
- 将新的 和存在的 manifest files文件一起当做一个快照,写入到 manifest list 中
- 在新的 mainfest list中包含所有 manifest file 的路径,以及统计信息,如增加了多少数据,lower、upper等
- 再写入 metadata file,记录表的汇总信息,包括manifest list的路径和相信信息
- 提交记录
- 再次获取 catalog,同时确保在写入时候,没有出现新的快照
- 同样也是为了预防并发冲突的,失败会继续重试
- 读取总是拿到最新的快照,正在写入的不会影响读取
Upsert/Merge
语句
|
|
执行过程
- 解析查询,准备建立查询计划
- 检查 catalog
- 校验表的 schema,确认非空字段,获取分析信息
- 获取当前的 序列ID,事务序列ID,使用 OCC 做并发控制
- 写数据文件
- 同时从源、目标读取数据文件放入内存中,然后做匹配,比如根据 id 做比较,
- copy-on-write,只要匹配更新任何一行,整个文件都需要读取,重写
- merge-on-read,生成新的更新/删除/插入 数据文件,读取时会忽略旧的文件,只有更新的数据在内存中,占用内存会减少
- 如果 WHEN MATCHED 匹配,则做更新,则做插入操作
- 写元数据
- 跟之前的一样,写入 manifest files,以及数据文件路径、统计信息
- 当前快照中已经存在的 manifest file,跟新的一起,写入到 manifest list中,以及manifest file 的路径和统计信息
- 写入metadata file汇总表信息,包含 manifest list路径和信息等
- 提交
- 再次获取 catalog信息,确保这段时间没有写冲突,如果有冲突则继续重试
- 利用了OCC 做并发控制,快照隔离级别,串行化隔离级别,来确保 ACID 事务
Reference
- The Life of a Write Query for Apache Iceberg Tables
- Maintaining Iceberg Tables – Compaction, Expiring Snapshots, and More
- How Z-Ordering in Apache Iceberg Helps Improve Performance
- What Is Apache Iceberg? Features & Benefits
- Lakehouse Trifecta — Delta Lake, Apache Iceberg & Apache Hudi
- Iceberg Table Spec
- Youtub: CHUG Talks: Introduction to Apache Iceberg
- Row-Level Changes on the Lakehouse: Copy-On-Write vs. Merge-On-Read in Apache Iceberg
- Optimistic concurrency control
- How Netflix uses eBPF flow logs at scale for network insight