某O 数据库的 CDC 工作原理
整体结构
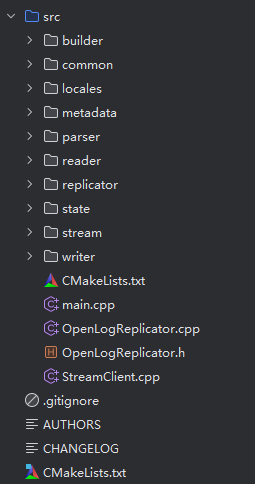
包结构
- builder,创建消息,消息队列,消息内容
- common,异常,表达式,系统表,metric 等
- locales,国际化相关
- metadata,元数据
- parser,核心的解析部分
- reader,读取部分,只有从文件系统读这个实现
- replicator,包含连接Oracle 的一些操作,处理离线,在线的数据
- state,状态检查点
- stream,流相关实现类,如写网络,zeromq
- writer,写入部分,包括写kafka,写文件,写流
会创建这么几个线程
- Reader
- Writer
- Replicator
- Checkpoint
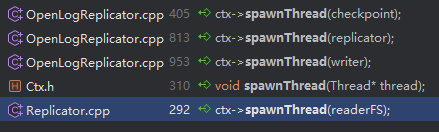
这里使用的是 pthread 这种较低级别的 API,而不是 c++11 的api
主要的解析入口是在 OpenLogReplicator#run 中
几个线程之间的关系
- 由 OpenLogReplicator 负责读取配置文件,创建对应的 reader,writer,checkpoint 等类
- 然后用 pthread 来创建对应的线程
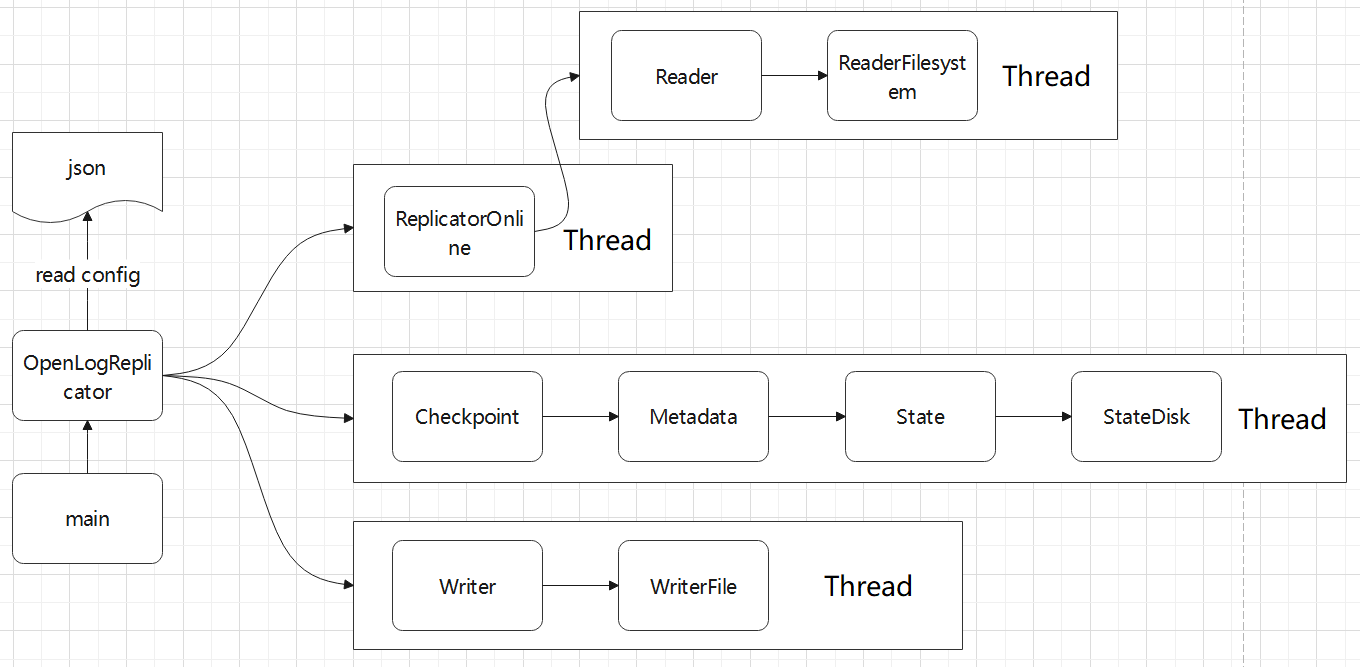
replicator 以及相关的依赖
实际依赖要比下图复杂很多,不少都是相互依赖,这里简化了很多
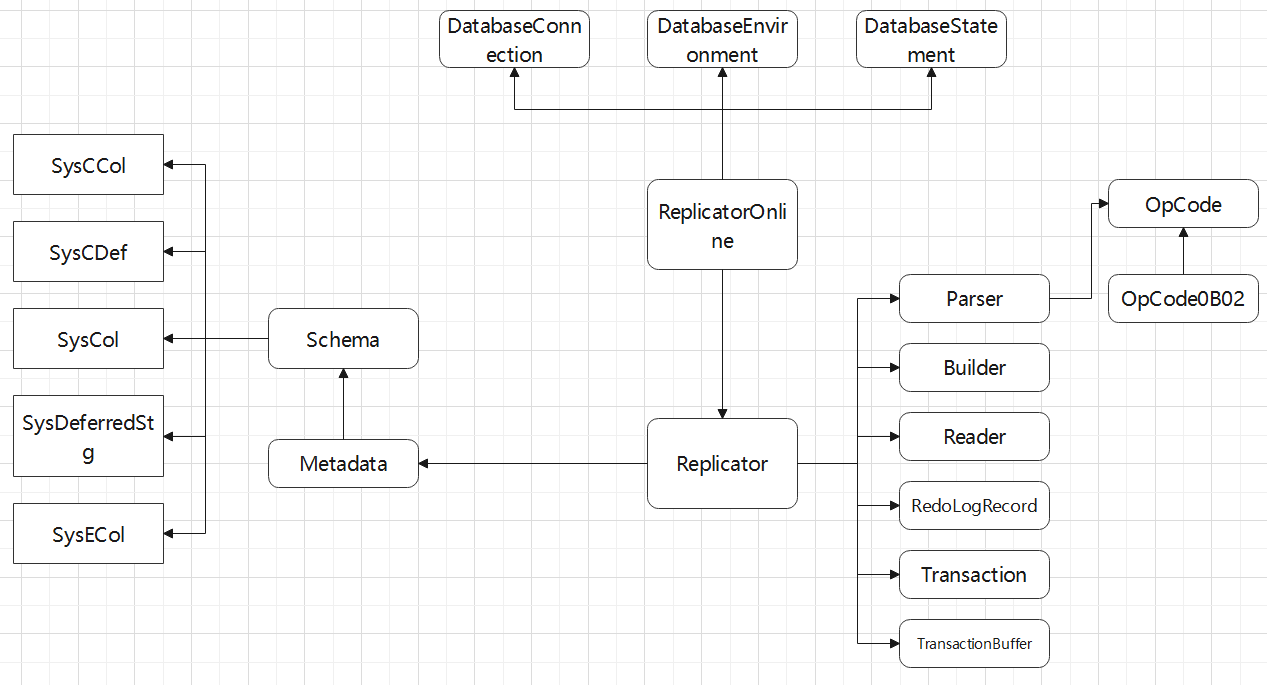
Schema 关联的类很多,都是系统表的一些封装
OpCode 实现类,对应的就是具体的操作,如 insert,update等等,这里的实现类非常多
扩展点
Replicator 和 Builder 相关的类图
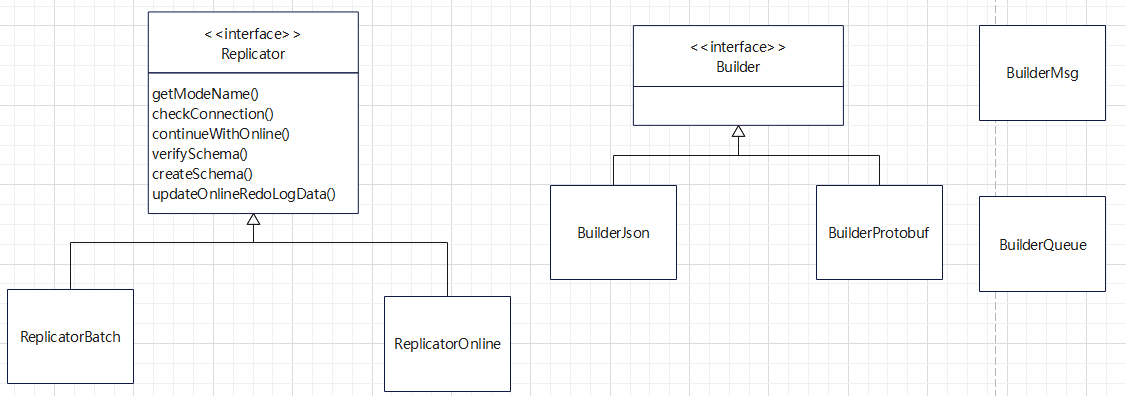
Builder 部分的两个实现类
- BuilderJson
- BuilderProtobuf
父类需要扩展的函数
|
|
子类是对这些列,以及数据做一些组装,比如组装成 json 格式
读 和 写 相关的类图
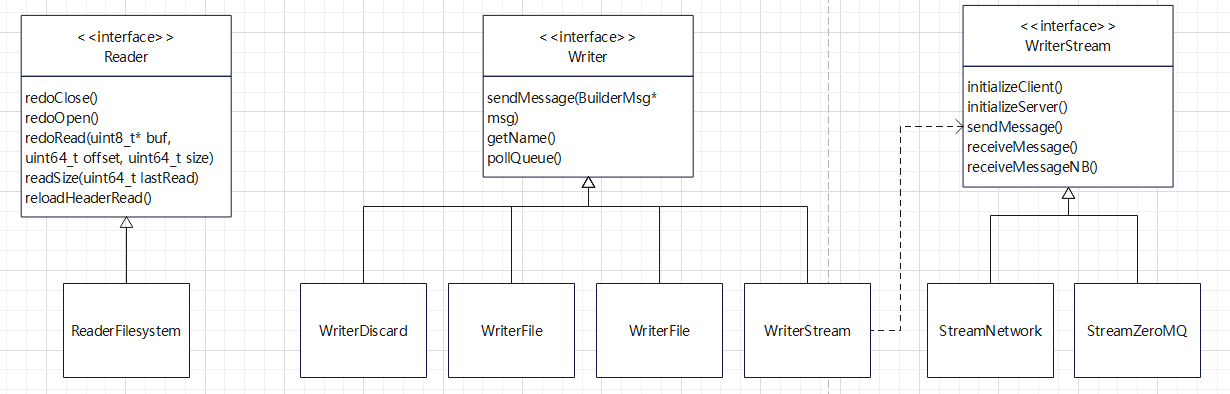
读目前只有一个实现类,从文件系统读取
写有很多
- 写文件
- 直接丢弃
- 写 kafka
- 调用写流接口,写网络、写 zeroMQ
监控扩展点
- 监控相关的是 common/metrics/Metrics.h
- 这里定义了非常多的 metrics 相关函数
- 实现类是 MetricsPrometheus
监控相关的扩展内容
- 读相关的
- 写相关的
- build 数据内容相关
- parse 相关
状态扩展点
- State 这个类,定义了状态相关的函数
- 目前只有一个实现类 StateDisk,将状态写入到磁盘
解析部分
Metadata 的依赖
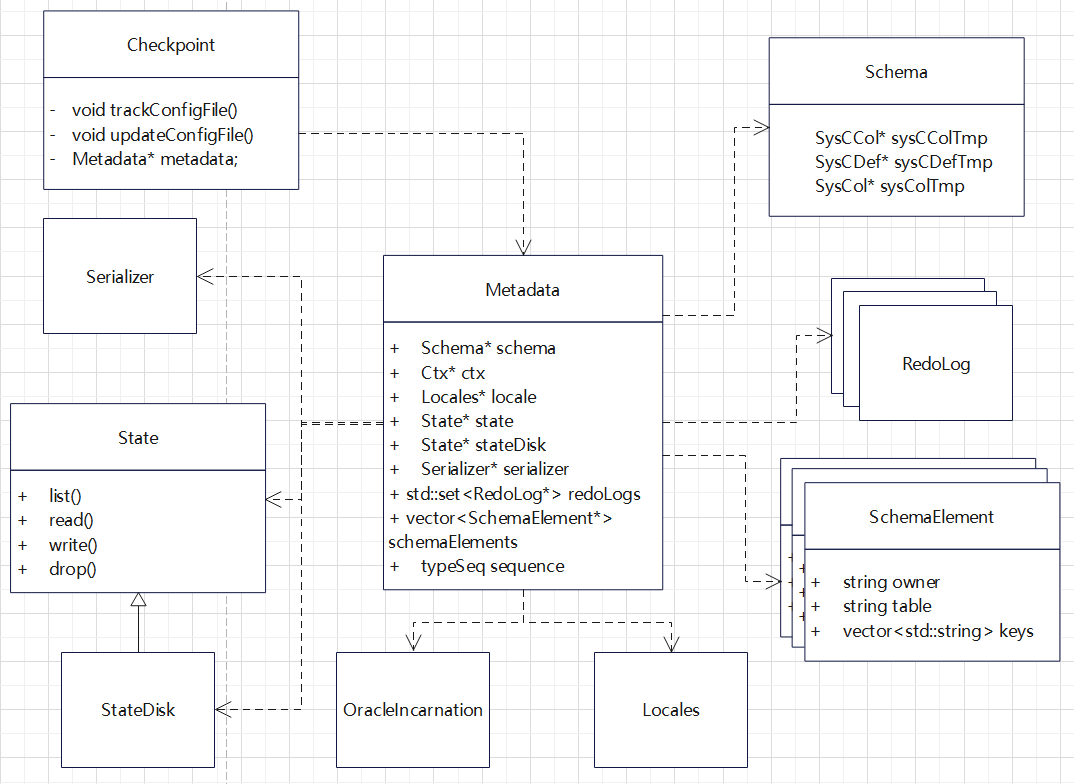
Schema 类关联的类(对表的封装)
|
|
Reader 类的四状态
|
|
默认是 sleep 状态,会由 Replicator,Parser 来更新这些状态,然后 Reader 继续后面的读取操作
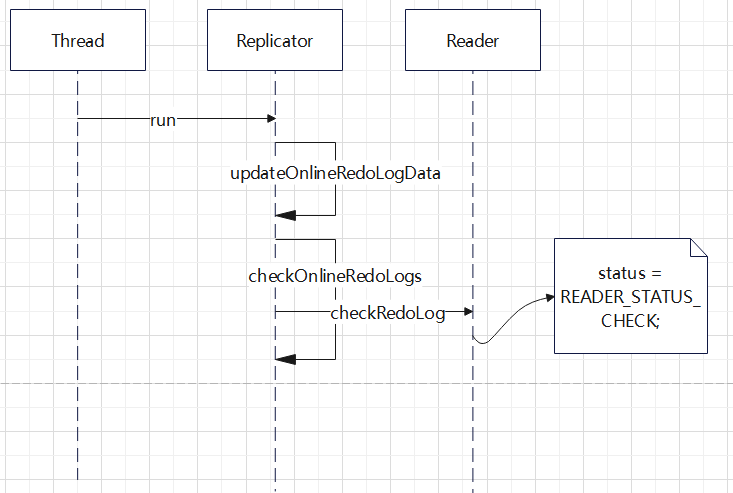
READER_STATUS_CHECK 更新触发逻辑
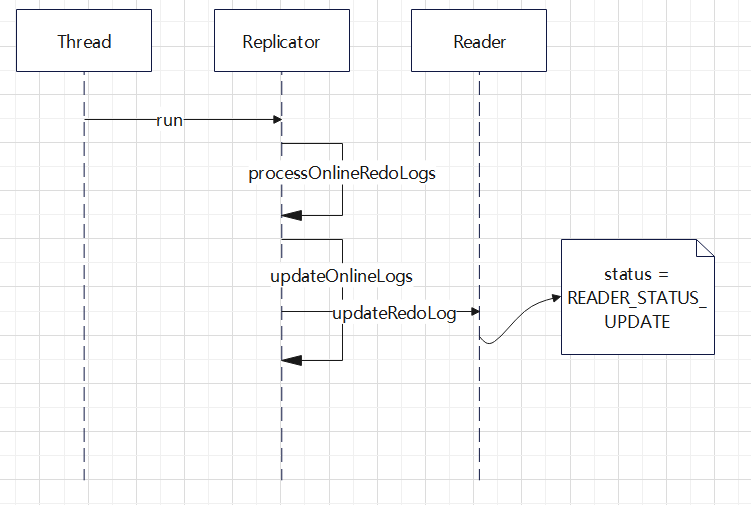
READER_STATUS_UPDATE 更新触发逻辑
READER_STATUS_READ 更新逻辑
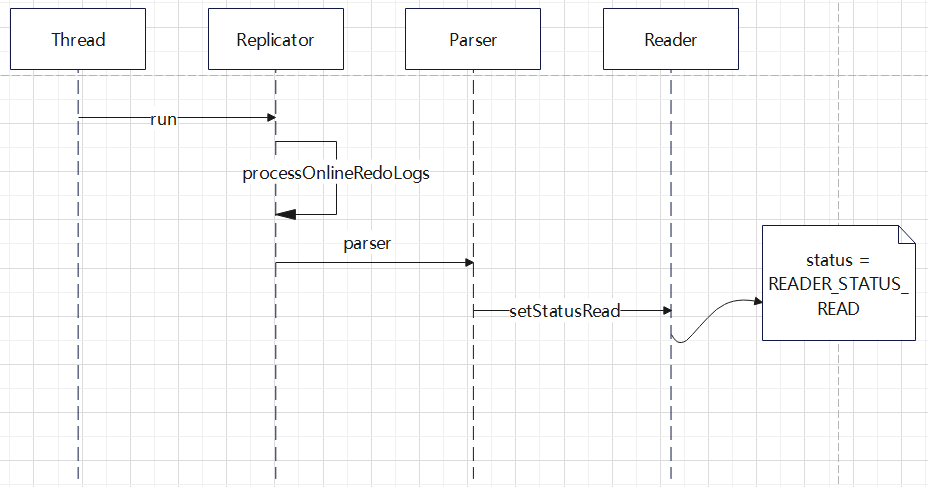
以上三种状态都是由 Replicator 线程触发的,这里一个独立的唯一线程,负责更新每个读取线程的逻辑
另外 Replicator 线程在更新 Reader 类时,也可能会 wait,这可能是考虑到了 CPU 空转问题
Replicator wait后,再由 Reader 线程负责唤醒
整个多线程条件变量,包含
- 一个主线程,Replicator
- 多个读取线程 Reader
- 三个条件变量:condBufferFull、condReaderSleeping、condParserSleeping
读取的 状态机
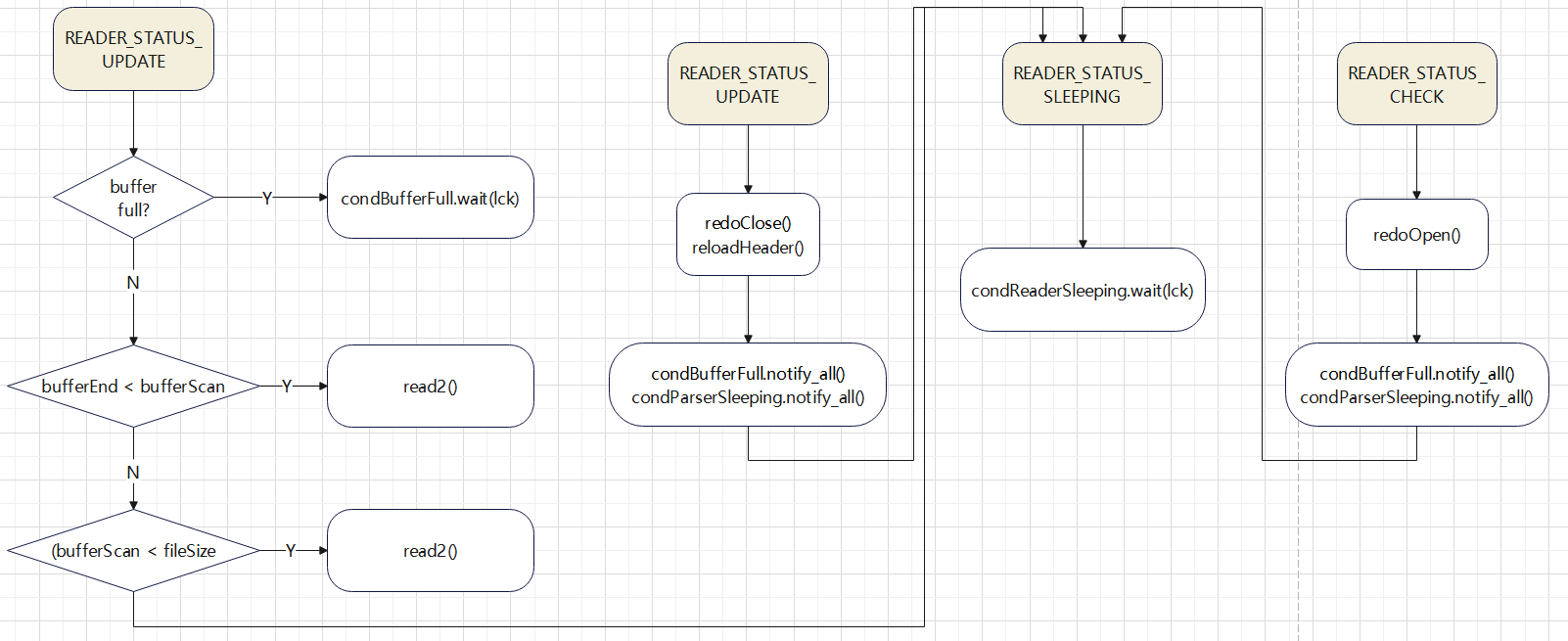
解释
- 一开始读线程是 READER_STATUS_SLEEPING 状态,先 wait
- 由 Replicator线程负责更新线程状态,READER_STATUS_UPDATE 会关闭文件、流,重新读取
- READER_STATUS_CHECK 则是从头开始解析 redo log
- READER_STATUS_UPDATE,是真正的往后开始读取redo log文件,这个状态是由 Parser来更新的
- 读取时还判断了 buffer是否满了,以及特殊情况的 read2(),一般走的是 read1() 逻辑
而 Parser#parser()执行的前提是, Replicator 线程判断满足一个条件
以下是在 Replicator#processOnlineRedoLogs() 中执行的
其实后面的 判断肯定会满足,因为拿到的 getNumBlocks()很大,是2**31个,获取文件大小不是从 redo log中解析的,是调用paxos API获取的
所以真正成立的条件是onlineRedo->reader->getSequence() == metadata->sequence
|
|
多个读线程、replicator线程、写线程之间的 条件变量交互关系
checkpoint 线程好像没有特别的唤醒机制,是自己wait 一段时间后醒来的
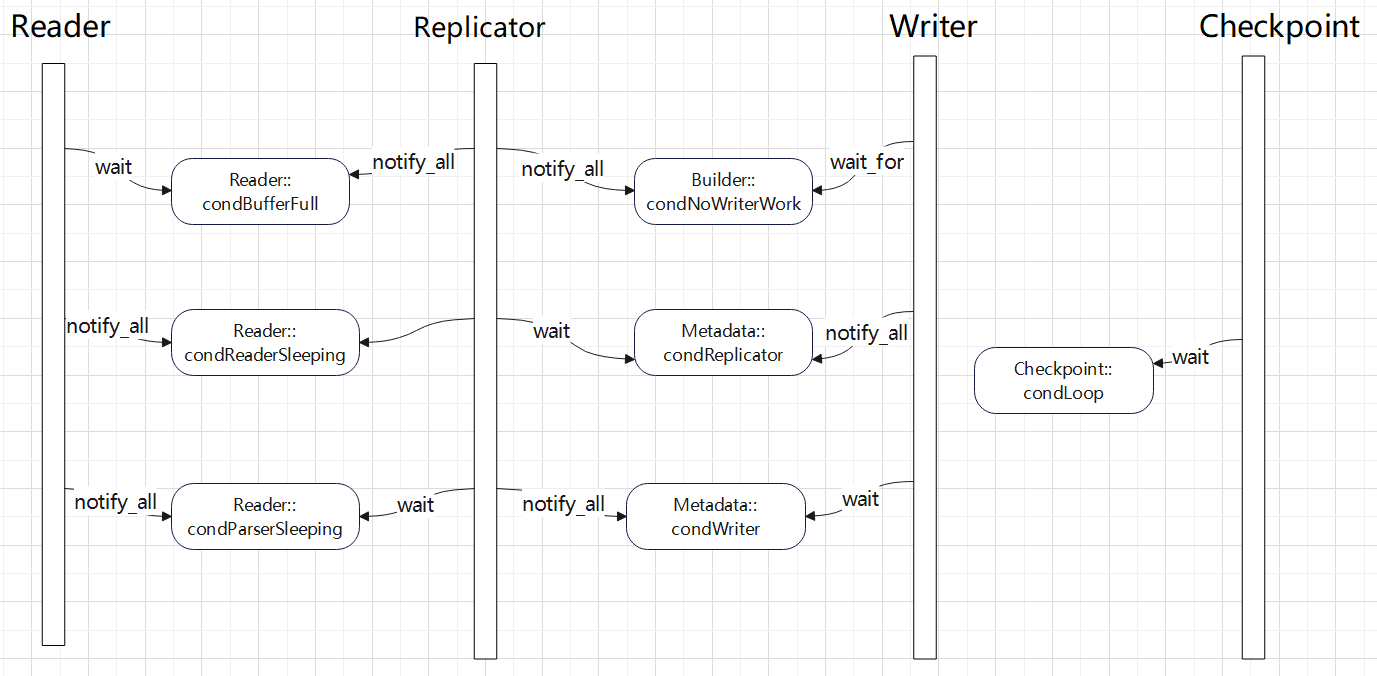
解析文件
redo log 的一些重要信息,看起来是直接从 redo log 中获取的
在Paser#pase()中
|
|
一次插入的解析的过程
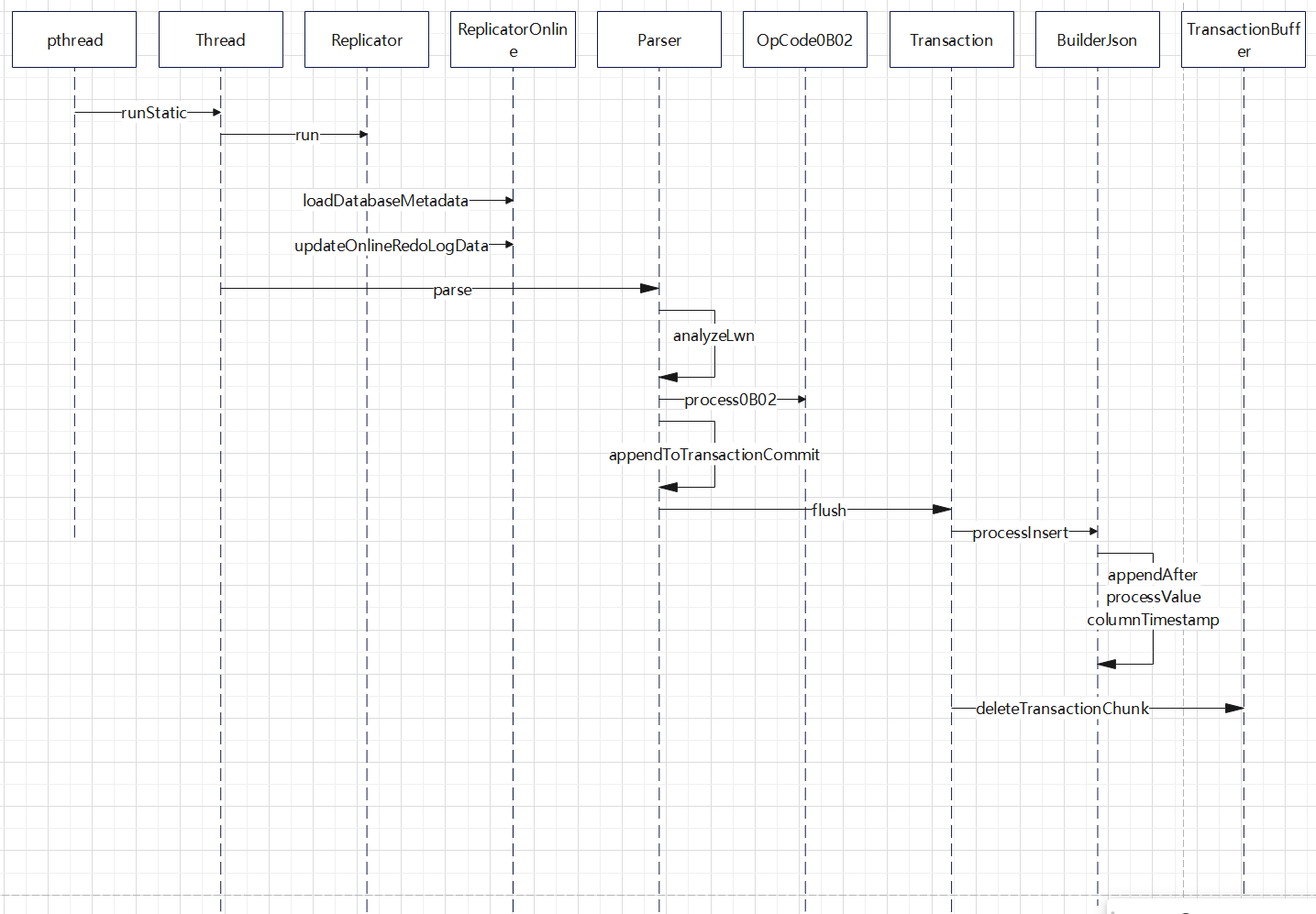
解释
- 首先pthread调用到自定义的线程类,执行Replicator#run
- 之后,调用 online的解析逻辑,加载元数据,获取sequence信息等等
- 拿到一个具体的redo log文件后,交给Parser类去做具体的解析
- Parser 类中解析出一个数据单元 lwn,然后 case判断这个是哪种类型
- 如果是单条插入,就交给 OpCode0B02做处理,解析插入逻辑
- 解析完后放入到内存中,如果出现提交,则调用 Transaction做flush
- 这里会将插入的二进制按照一条一条数据,对于每一列根据不同的类型来做处理,比如这里是处理了 timestamp类型
- 之后会生成一个完整的 JsonBuild,然后触发一个写通知,由 另外一个写线程将 build 中的内容输出到目标中
- 事务处理完后,删除对应的内存块