对 O数据库 CDC 的一些改动
原始版本只支持单节点,改动目标
- 能读取 RAC 共享存储的文件
- 能支持 RAC 多节点
代理节点
读取 ASM
改动后的架构如下:
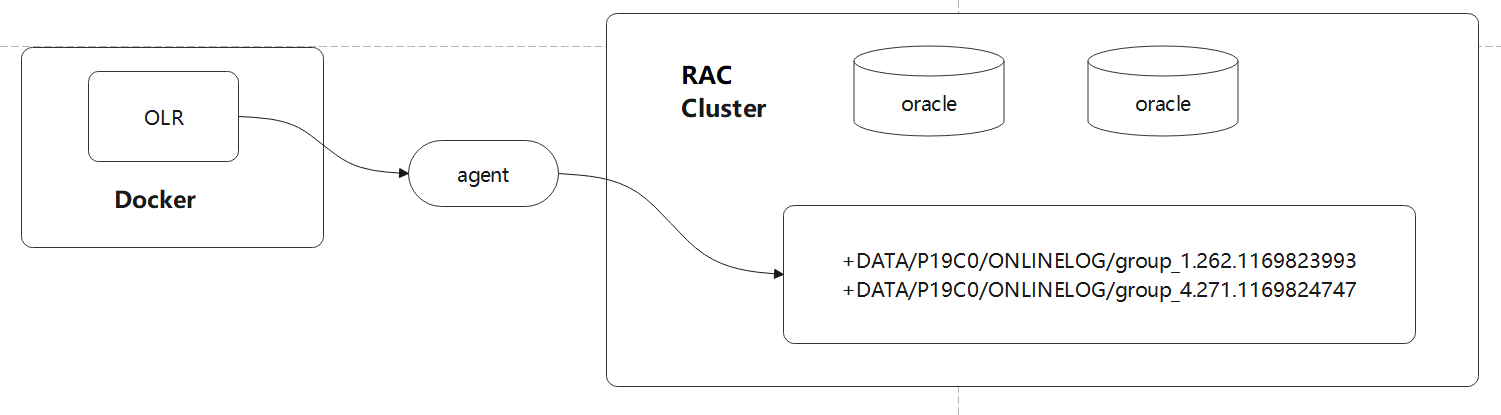
由于数据是 shared-disk 架构,redo log 是放在共享存储上的,OLR 默认是读本地磁盘,这样会导致根本拿不到 redo log
曾尝试过使用
- ftp,oracle对外暴露的是简化版的 ftp,不支持 offset功能,没法使用
- http,需要 basic 认证,但不知道用户名/密码,无法登录
当前选用的是调用 Oracle 自带的存储过程,来读取指定的文件
需要这几个参数
- 文件的路径路径
- 文件的 offset
- 读取的数量
存储过程正好可以满足这些要求,但是 C++ 无法连接 ASM 实例,只能用 C++ 调用 Java,Java再调用存储过程读取数据返回给 OLR
增加了一个代理节点,用 Java 实现的
这个代理可以放在任意位置,跟 OLR放在一起,或者放到RAC集群节点上,或者其他节点上都可以,只要能跟 ASM实例网络通讯即可
在 java 中使用了 4个存储过程
- dbms_diskgroup.getfileattr,获取文件属性
- dbms_diskgroup.open,打开文件
- dbms_diskgroup.read,读取文件
- dbms_diskgroup.close,关闭文件
需要注意的是,这个存储过程无法读取 redo log 的第 1 个块,所以第一个块是认为拼接出来的
好在第一块里面也没有什么太多的内容
|
|
对于第1个块,OLR 使用了4个地方
- 判断 是否为控制块,这里就硬编码就可以了
- block 的大小,当前固定为 512,后面可以做成可配置化的
- big endian or little endian,根据 7A,7B,7C,7D 的正序、逆序决定
- 一个debug参数,暂时没用
redo log的大小不是从数据块中解析的,而是直接获取文件大小,返回的
普通代理节点
普通代理节点架构如下:

普通代理节点,也是用 Java 实现的,增加普通代理节点的好处是部署成本降低了
因为 OLR 使用 C++编写的,客户环境直接运行可能都无法启动,所以必须用 Docker部署
而客户环的 数据库节点可能不允许装 Docker、或者因为操作系统版本限制,无法装 Docker
那么替代的方式:
- 在一个独立的节点上部署 Docker,运行 OLR
- 在数据库节点上运行代理,代理直接读取本地磁盘文件,返回
|
|
普通代理,读取 ASM 都是用 libcurl 实现的
普通代理的优化
- 构造函数、析构函数都是用了:std::call_once,来做 libcurl 的全局初始化,全局销毁
- redoOpen 的时候做线程级别初始化; redoClose 时做线程级别销毁,这两个都是不需要加锁,线程独立的
- redoRead 的时候正常读取,由于已经做了 TCP初始化,这里用 tcpdump 看,只有 push包、ack包
一些连接超时参数
- http 请求超时时间
- http 读取超时时间
- http 失败重试次数
- http 失败重试间隔时间
- trace 级别 log 增加 http 请求
未来的进一步优化:
- 减少 HTTP响应头,请求头大小;由于返回的内容都是二进制的,没有什么特殊需要处理的,但如果都是
0,可以考虑做一下压缩 - 基于 TCP 之上的 二进制协议,包括对 响应内容再做压缩等
- 使用 UDP,但需要增加额外的 CRC 校验,重试机制等
多个活跃节点
多主改造方式
改造,支持 多个 RAC 主节点
这里的架构是:
- 多个活跃的 主 RAC节点
- 可能有多个 备 RAC节点
- 一个 非 RAC的备节点,OLR连接到这个备节点
改造后的架构:
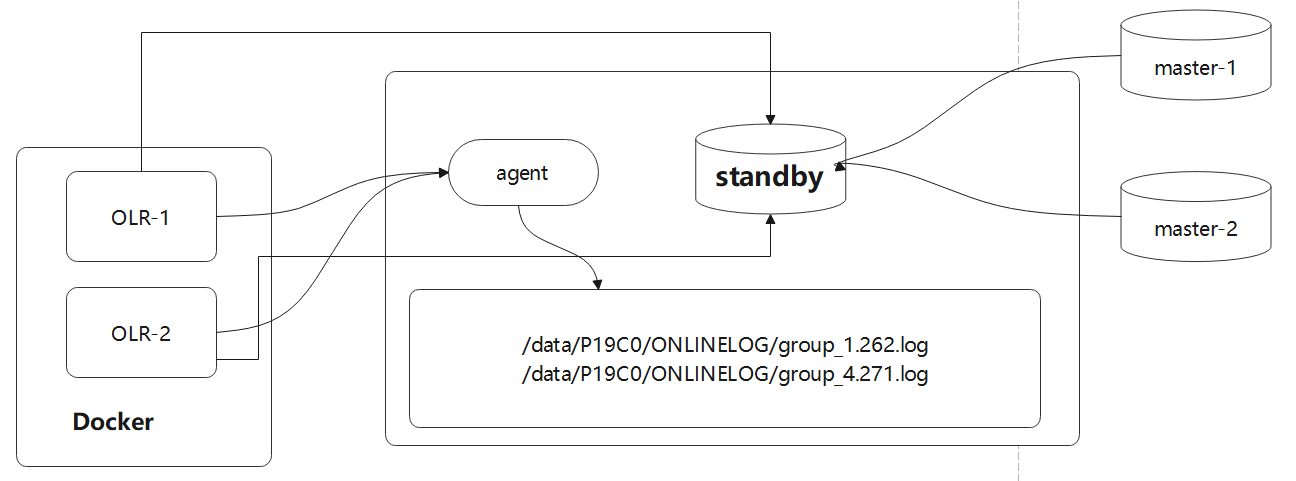
这里有2个主节点,所以启动了两个 OLR 进程,如果有 N 个主节点,就启动 N 个 OLR进程
查询 活跃 redo 的 SQL:
|
|
上述 SQL 跟原始的方式比较类似,差别在于增加了THREAD# 这个字段,用这个字段来区分这个 redo log 是哪个RAC主节点生成的
这里是 非 RAC 的备库,所以跟 RAC 还有些不同,这里就直接拿了THREAD# 字段就可以做区分了,如果是 RAC 实例
- V\$LOG,根据主库的 V\$LOG表的 thread字段,找到 THREAD 表
- V\$THREAD,根据 thread id,去 instance 表中,找到实例名称
- V\$INSTANCE,根据实例名,定位具体的实例信息
三张表
查询归档日志的 SQL:
|
|
类似的,也是增加了THREAD# 字段,来判断当前的 归档日志是哪个 RAC 主节点产生的
一些细节
两个 RAC 主节点是完全独立的,他们的sequence编号是单调递增,也是互不干扰的
从下面表格可以看到,两个活跃的主节点,其sequence 正好完全一致了
|
|
| SEQUENCE# | MEMBER | GROUP# | THREAD# | STATUS |
|---|---|---|---|---|
| 2,445 | /oradata/fast_recovery_area/ORCLCDC/onlinelog/o1_mf_1_m7033168_.log | 1 | 1 | ACTIVE |
| 2,445 | /oradata/ORCLCDC/onlinelog/o1_mf_1_m703306d_.log | 1 | 1 | ACTIVE |
| 2,445 | /oradata/fast_recovery_area/ORCLCDC/onlinelog/o1_mf_7_m7033o4s_.log | 7 | 2 | ACTIVE |
| 2,445 | /oradata/ORCLCDC/onlinelog/o1_mf_7_m7033n7z_.log | 7 | 2 | ACTIVE |
OLR 的代码中,对于归档日志的判断:
|
|
如果当前的 sequence 比归档大,说明之前处理过了,忽略即可
如果比当前小,说明出现空洞了
比如 online为 100时,切换了,online就变为 101,产生归档 100,再切换就变成
online 102,归档 100,101
如果在 100 的时挂了重启,那么会先读 100,再读 101
因为 Oracle 的一些并发处理机制,主库可能会先将 101 同步到备库,所以必须等到 100到来,并处理完后,才能继续处理 101
其他改动
日志轮转
- 增加 spdlog 依赖,作为 日志轮转
- 主要修改 Ctx.cpp,将各种日志的级别(默认写控制台),转为用 spdlog 实现
减少重复日志
- 假设 t1 时刻写入了 checkpoint
- t2 时刻进程挂了,然后再重启
- 此时会将 t1 – t2 时刻的数据,再推送一遍,导致重复
- 减少 checkpoint 的频率(默认600秒)
- 进程关闭时写一次 checkpoint
- 写入到 kafka 后,消费者通过 scn 号来去重
高可用
- checkpoint(元数据也在checkpoint中)写入到 redis中
- 多个 OLR实例共享 redis 中的checkpoint
- OLR-1-master,OLR-1-bak_1,OLR-1_bak_2 。。。
- 任何时刻只有一个 OLR 进程是活跃的
- 通过定期写 redis(NX原子)写入来实现的,只有一个节点能写入成功,然后不停的更新
- 超时后,其他进程感知到,再争抢写入,变成活跃节点,读 checkpoint
时间戳问题
- 修改时间戳问题,少了 8小时
- 修改 ISO 8601 字符串格式化问题,小了 8小时
- 修改 Ctx.cpp 的 epochToIso8601、valuesToEpoch 两个函数
- 使用 std 标准库的日期、以及格式化来实现的
增加主进程
- 主进程读取数据库,确定当前的 RAC 主节点数量
- 启动对应的 子进程,每个子进程就是一个 OLR 进程
丢数据问题
- 在查询 SYS.V_$ARCHIVED_LOG 表时,原始逻辑强制增加了一段: AND IS_RECOVERY_DEST_FILE = ‘YES’
- 有些归档日志可能不是来自快速恢复区,即这个字段值为 NO,导致查不到,会丢数据
- 如果定期删除归档日志,也会导致丢数据,或者出现各种奇怪的问题
- 一些归档日志来自 path A,一些来自 path B,而 path B 这个路径无法读取到,也会出现问题