Spark的 数据分布
分区相关的
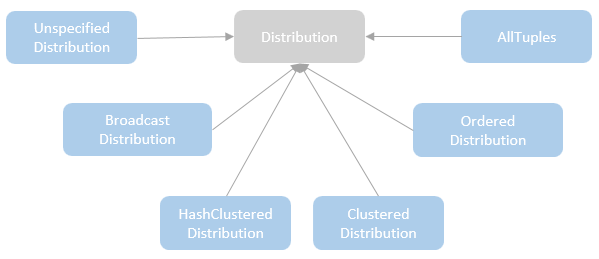
Distribution 类的继承关系
图片来源 -> 这里
主要的类
- UnspecifiedDistribution – represents the case that no specific requirements for the distribution. All the partitioning types mentioned later can satisfy this distribution.
- AllTuples – represents the distribution that only has a single partition.
- BroadcastDistribution – represents the case that the entire dataset is broadcasted to every node.
- ClusteredDistribution – represents the distribution that the rows sharing the same values for the clustering expression are co-located in the same partition.
- HashClusteredDistribution – represents the distribution that the rows are clustered according to the hash of the given expressions. Because the hash function, is defined in the HashPartitioning, therefore, HashClusteredDistribution can only be satisfied with the HashPartitioning.
- OrderedDistribution – represents the distribution that the rows are ordered across partitions and not necessarily within a partition.
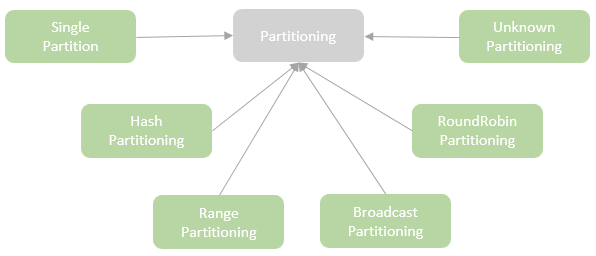
Partitioning 类的继承关系
主要的关系
- SinglePartition – represents a single partition (numPartitions == 1) which satisfies all the distributions apart from BroadcastDistribution as long as the condition for the requiredNumPartitions is met.
- RoundRobinPartitioning – mainly used for implementing the Dataframe.repartition method, which represents a partitioning where rows are distributed evenly across partitions in a round-robin fashion.
- HashPartitioning – represents a partitioning where rows are split across partitions based on the hash of expressions. The hashPartitioning can satisfy the ClusteredDistribution and HashClusteredDistribution.
- RangePartitioning – represents a partitioning where rows are split across partitions based on a total ordering of the dataset, which implies all the rows of a partition have to be larger than any row in the partitions ordered in front of the partition.
- BroadcastPartitioning – represents a partitioning where rows are collected from the nodes in the cluster and then all the collected rows are broadcasted to each node. BroadcastPartitioning can only satisfy the BroadcastDistribution.
Partitioner 类表示用什么方式做数据分区
例子
按照 hash 做分区
|
|
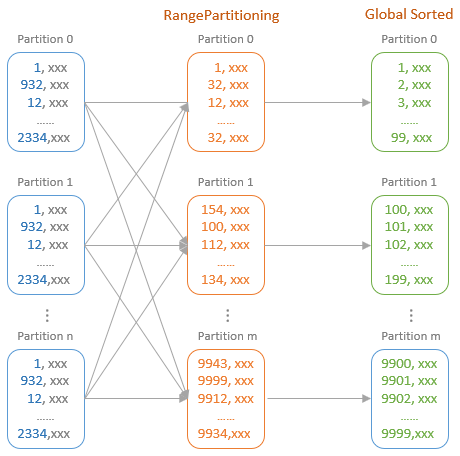
按照 range 做分区
|
|
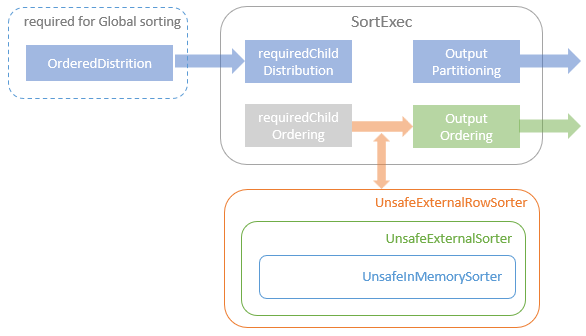
排序物理算子
SortExec#doExecute 代码:
|
|
内容比较简单,创建一个排序器,然后对子节点的数据做排序
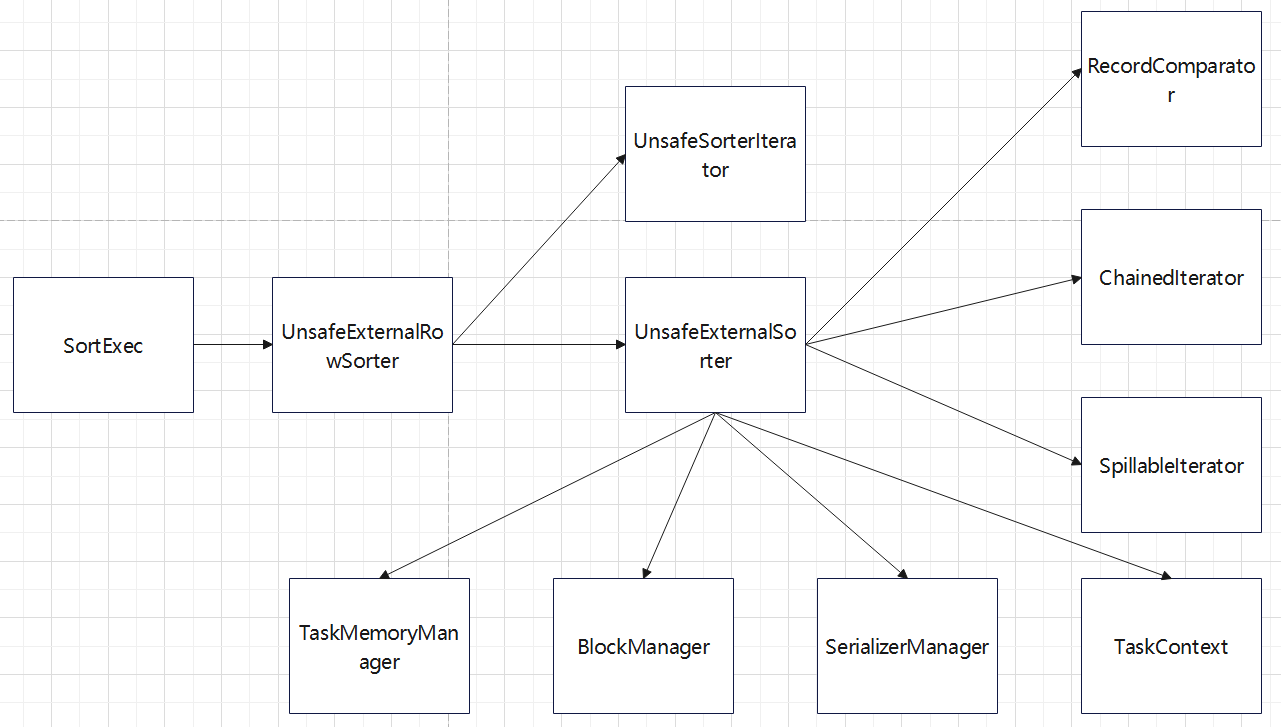
SortExec 依赖的其他类
排序时会有内存阈值判断,超过了会溢出到磁盘
图片来源 -> 这里
细说排序细节
以 SortMergeJoin 来说,首先它需要数据分布,以及排序
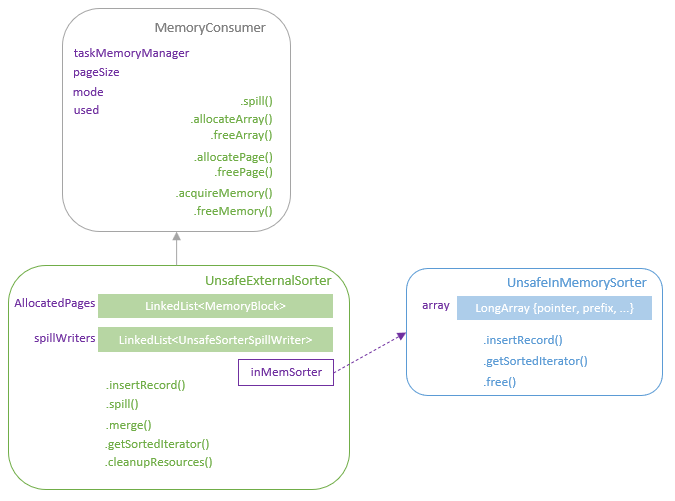
Sort 底层是借用下面两个操作实现
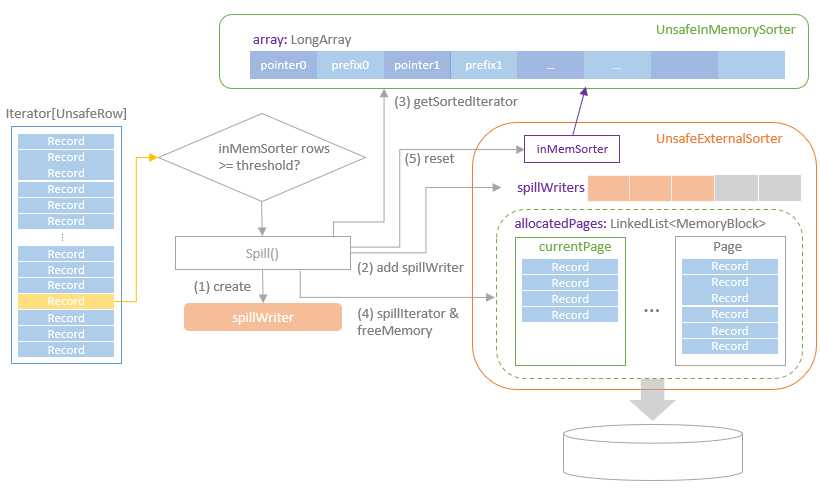
- UnsafeExternalSorter
UnsafeExternalSorter 的组成
- 包含了一个 linked list,用来分配内存页
- spill writer,会free 内存写到磁盘
- UnsafeInMemorySorter 会持有一个 LongArray数组
- UnsafeExternalSorter 提供了插入数据,返回迭代器的接口
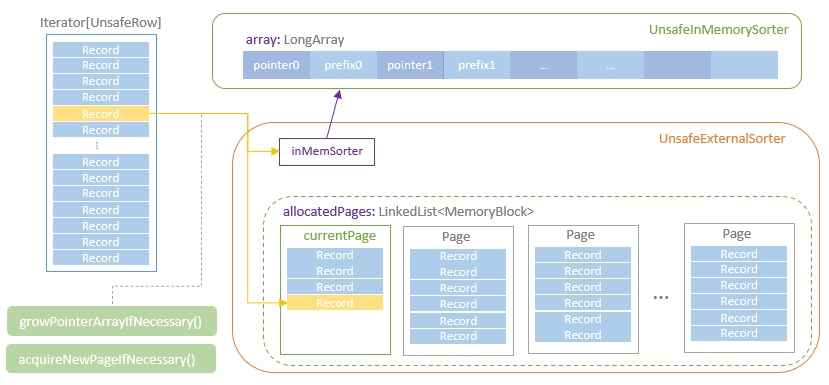
如下
- 首先会迭代分区中的记录,将器插入到 UnsafeExternalSorter
- 这又会插入到 UnsafeInMemorySorter
- 插入到内存数组时,会检查页是否足够,是否有足够的内存,是否要spill 等
- 这里使用了前缀比较,主要是避免 cache miss
当内存不足时,会 spill 到磁盘
- 首先创建 判断如果超过内存阈值,就需要写入到磁盘了
- 创建 UnsafeSorterSpillWriter 实例,也就是 spillWriter
- spillWriter 获取内存页中的指针,拿到数据,写入到磁盘
- 之后清空内存中的page
spill file按照下列格式存储
|
|
getSortedIterator
- 外排序或者内存排序都会返回一个迭代器
- 如果是数字,用的是 radix sort,一般情况就是 封装了 JDK 的 tim sort
- 如果有spill 则,调用外排序,还会用归并的动作
|
|
Shuffle操作
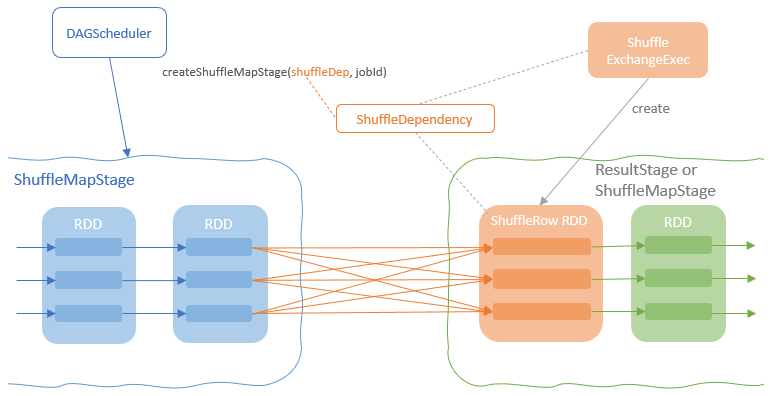
ShuffleExchangeExec 操作
- 准备 ShuffleDependency,根据父节点所需要的分区schema,对子节点的输出做分区
- 添加 ShuffleRowRDD,并将准备好的 ShuffleDependency指定为这个RDD 的依赖项
- DAGScheduler 发现了ShuffleRowRDD的依赖后,创建ShuffleMapStage,保证 row rdd,并为ShuffleDependency中定义的shuffle操作生成数据
ShuffleExchangeExec
- 提供的prepareShuffleDependency方法封装了用于根据预期的输出分区定义ShuffleDependency的逻辑
- 也就是 输入的 RDD中每一行应该放到哪个分区中
- 为输入 RDD每一行创建一个k-v对,k是目标分区id,value是原始记录
- ShuffleMapStage 包装上游RDD,输出shuffle
- ShuffleMapStage 由 每个 Executor 中的 ShuffleMapTasks执行
- 每个ShuffleMapStage 调用写操作输出shuffle
- ShuffleDependency 从shuffle manager 那里读取数据,拿到MapStauts 状态
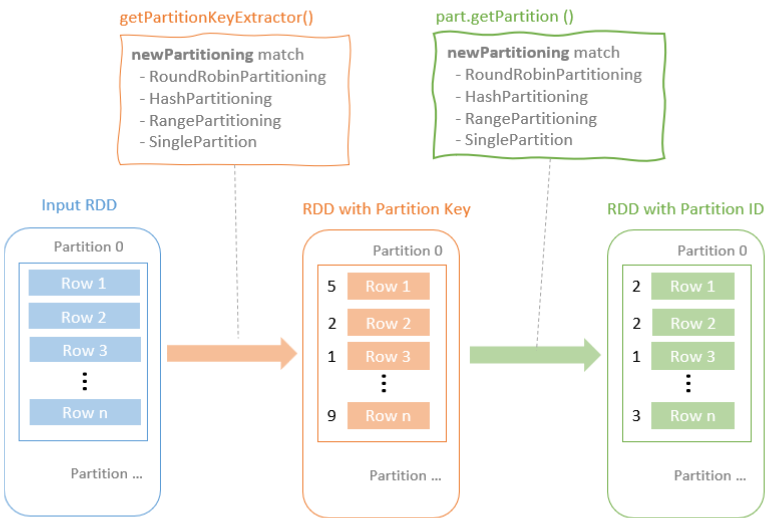
根据分区生成key 是根据不同的分区目标来做的
- RoundRobinPartitioning
- HashPartitioning
- RangePartitioning
- SinglePartition
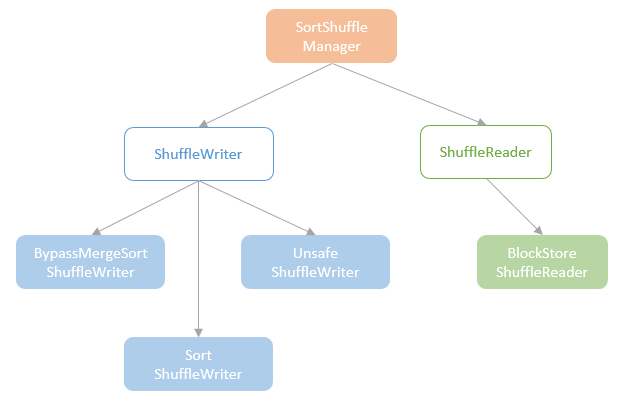
shffule 的管理 类之间的关系
- ShuffleManager 的唯一实现类SortShuffleManager
- ShuffleWriter 包含了三个实现类
- ShuffleReader只有一个实现类 BlockStoreShuffleReader
- BypassMergeSortShuffleWriter 不做排序,适合分区较少场景
- UnsafeShuffleWriter,使用Tungsten 做分区排序
- SortShuffleWriter,不满足一些阈值条件,则使用这个
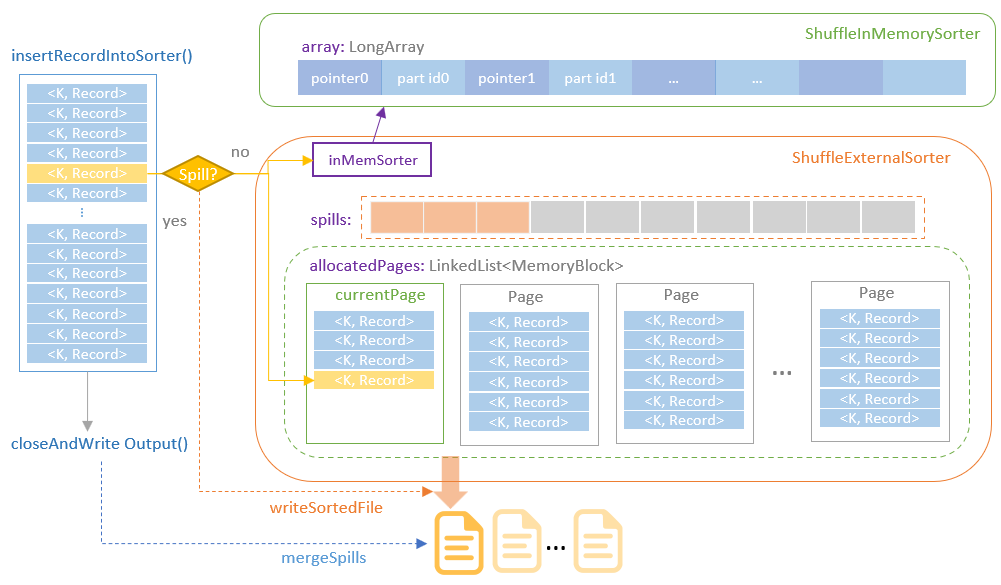
UnsafeShuffleWriter
- 其工作原理,跟 UnsafeExternalSorter 类似
- 包含了基于内存排序:ShuffleInMemorySorter,内部用 LongArray 指向了 分区-id,value 对
- 当<partition id, row> 插入时,首先检查内存是否足够,分配内存页
- 如果内存不足则 spill 到磁盘,再做归并排序
- 写入的信息也包含一些元信息,如分区长度,block id,等
- 写入完后,为每个分区id,增加一个 index,方便 reader快速定位
BlockStoreShuffleReader
- shuffle reader的唯一实现类
- 当每个shuffule写操作完成后,会注册 ShuffleMapTask 到 driver
- 对于reader 端,会抓取到这些信息,并交给BlockStoreShuffleReader MapOutputTrackerMaster
- 于是会初始化一个真正的 fech实例,然后从 map 端读取数据