spark 的 streaming
整体概述
一个例子
创建
|
|
连接
|
|
处理
|
|
写
|
|
开始执行
|
|
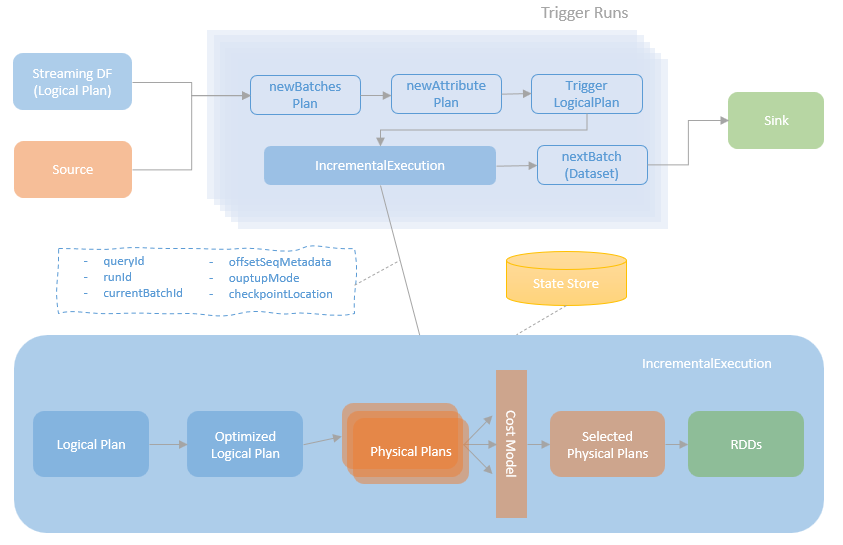
执行过程
- 通过 DataStreamReader 创建 source
- 执行转换操作,不断生成 DataFrame
- 执行写入,DataStreamWriter
- StreamingQueryManager 负责创建 StreamExecution 的实例
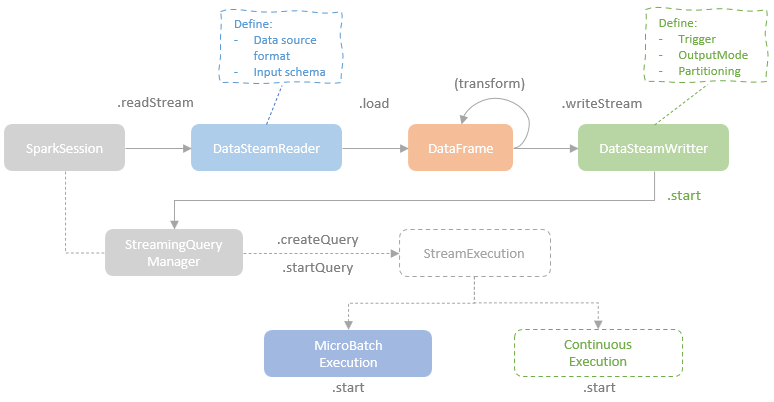
StreamExecution 的实现类
- MicroBatchExecution,实现精确一次,100ms 延迟
- ContinuousExecution,没有精确保障,1ms 延迟
启动的时候是调用 activeQueries 来触发的
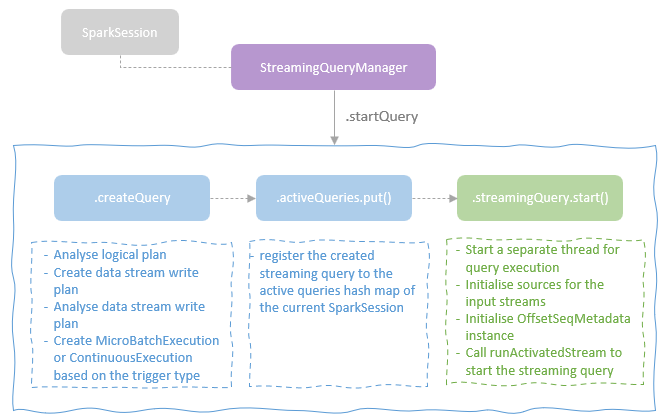
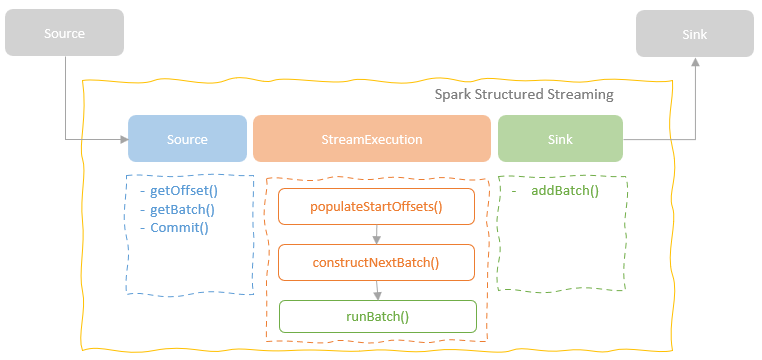
执行过程是通过读取 源端的一段数据,用 micro batch 来模拟的
也会触发 spark 的逻辑计划到物理计划的过程
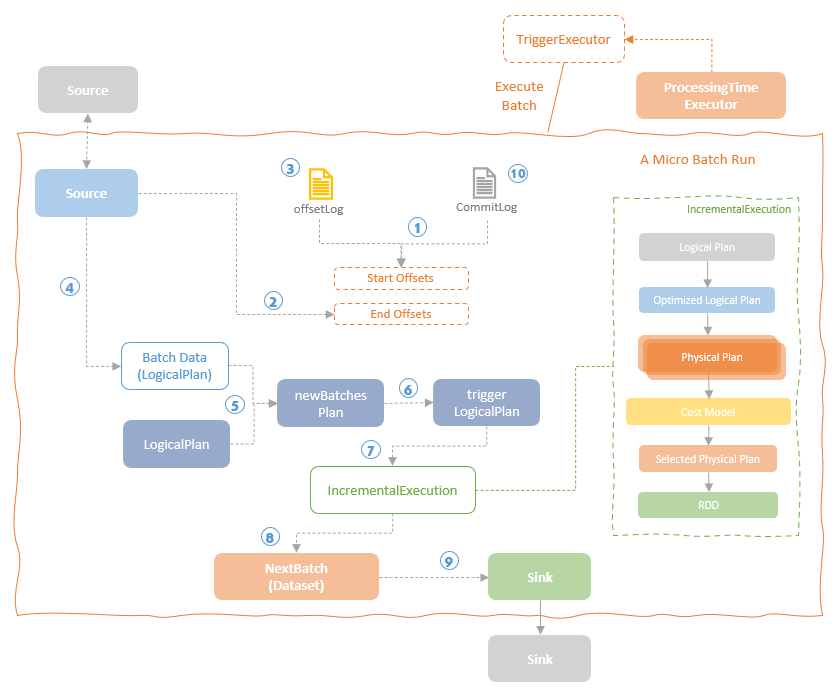
完整的执行过程
- 首先获取 start-offset,这是根据上一次执行完的 offset决定的,然后写 WAL
- 通过 commit log 保证事务性,同时确定 end offset
- 确定source是否有数据,然后构造一段数据
- 调用 getBatch 获取源端数据,此时不会真正触发执行
- 将plan 转为 newBatchesPlan,创建 triggerLogicalPlan
- 创建IncrementalExecution,开始做增量执行,类似普通spark任务也会有各种plan
- 写入 sink,记录 commit log
Source
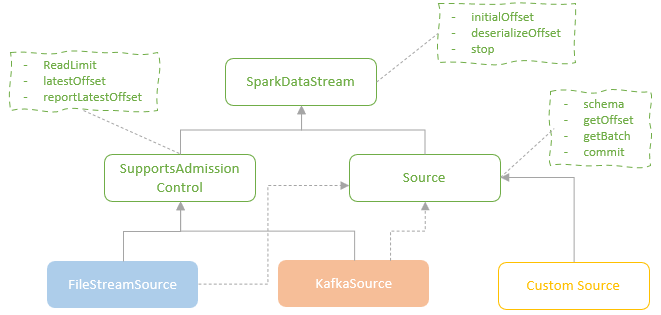
几个类
- SparkDataStream,是最高层的接口,表示一个输入流
- Source,表示输入源
- getOffset,表示最大可用的 offset
- last committed offset 和 the latest available offset,就可以确定一次要读取的一批数据
- 通过 getBatch 读取数据
- commit,表示已经处理完了,源端可以继续产生数据
- SupportsAdmissionControl,这个可以用来控制读取速率,做限流的
- FileStreamSource 和 KafkaSource 都支持限流
- 用文件写入时间作为 event time
- 支持类型:csv, test, json, Parquet, ORC
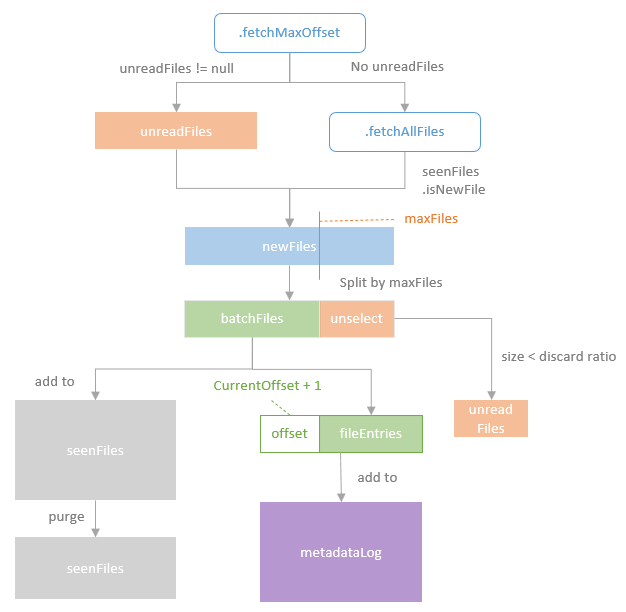
读取流程
- 通过 fetchMaxOffset 获取读取文件的 offset,此时会检查上一次是否有未读取的文件
- getBatch 通过元数据中包括的 start-offset 和 end-offset 来获取一批数据
- 如果有则读取上次的,没有就新抓取一批
- 如果新读取的文件内容 > maxFilesPerTrigger,则拆分成 2 部分
- 如果新拆分的第 2 部分 太小,则跟下一批一起处理
- 将 offser 记录到元数据中
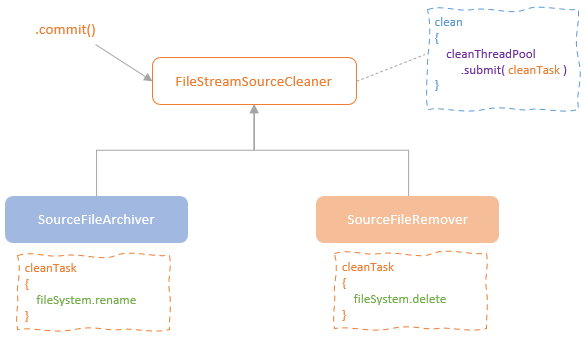
提交
- MicroBatchExecution 执行提交后,会通知source 端更新 offset
- FileStreamSource 定义了内部抽象类 FileStreamSourceCleaner 来完成清理动作
- 两个具体实现类:SourceFileArchiver(归档)、SourceFileRemover(清理)
- 都是在独立的线程中完成的
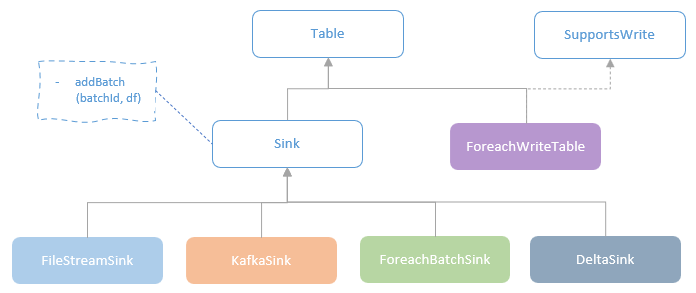
Sink
sink 的主要位置
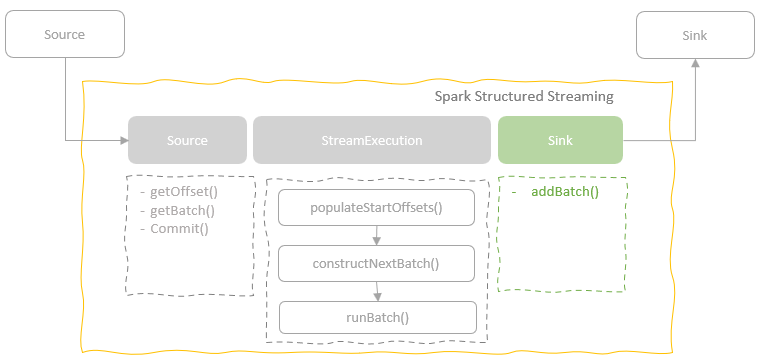
sink 介绍
- Sink 是一个 trait,每个子类都需要实现 addBatch
- addBatch 包括两个参数:batchId、DataFrame
- 通过 id 可以让外部系统来决定是覆盖还是丢弃,实现精确一次操作
实现类
- FileStreamSink,输出到 hadoop 兼容的文件系统,支持各种文件格式
- KafkaSink,输出到 Kafka
- DeltaSink,输出到 delta-lake 表格式
- ForeachBatchSink,ForeachWriteTable,这两个最灵活允许用户注入自定义的输出目标端
ForeachBatchSink
可以传入自定义的输出逻辑,这里是: batchWriter: (Dataset[T], Long)
|
|
在 DataStreamWriter#startInternal() 内,创建 ForeachBatchSink 实例
|
|
ForeachWriteTable & ForeachWriter
- ForeachBatchSink 是控制写一批数据
- 而这两个是可以控制 到 row 这个级别
三个需要实现的函数
- open – open connection for writing the current partition of data in the executor.
- process – when the ‘open’ method returns ‘true’, write a row to the connection.
- close – close the connection.
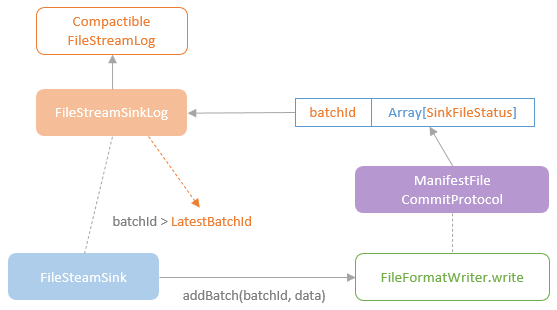
FileSystemSink
- 每个 micro batch 由 FileFormatWriter 负责写到每个独立的目录
- FileStreamSinkLog 负责记录写入成功的 列表信息
- ManifestFileCommitProtocal 记录了提交的信息
- 当写入成功后,将 pendingCommitFiles 增加到 FileStreamSinkLog
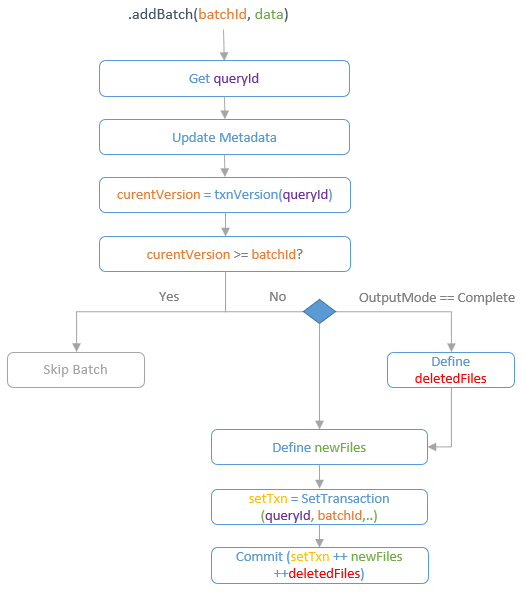
DeltaSink
- 这是是属于 delta-lake 项目里的,借助 delta-lake 的 transaction log 实现原子操作
- 通过 batchID 跟 txnVersion 比较,来判断是否忽略这个 batch
- DeltaSink 支持 Append、Complete 两种模式
- complete 通过删除所有文件来实现的,也就是 truncate + append 操作
- SetTransaction 将当前的 batchID 设置为事务 version,防止重复提交
IncrementalExecution
IncrementalExecution
- 继承自 QueryExecution,重用了spark的整个逻辑,包括分析,优化,执行逻辑计划等等
- 他内部维护了两个批之间的状态,用来实现增量的查询
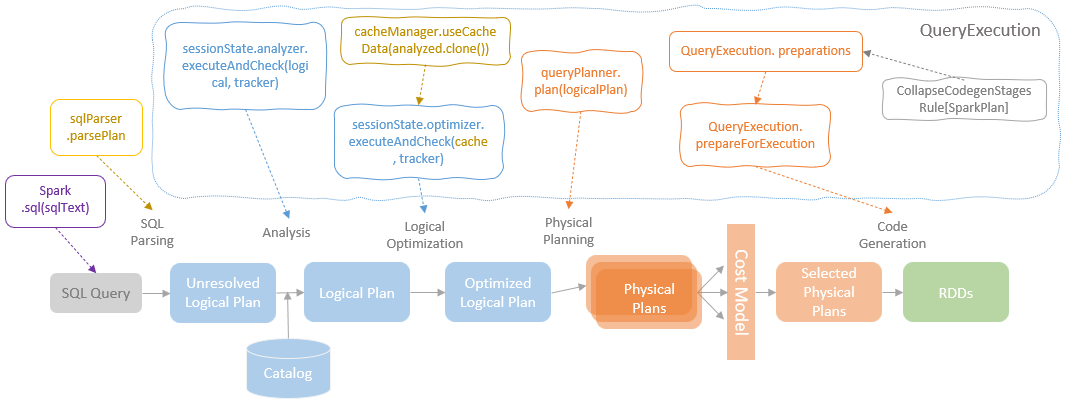
重用 QueryExecution
- 这里重用了spark 的通用逻辑
- 增量处理的时候,根据边界条件,和数据是否新达到了,每次都会生成一个新的 logical plan
- 这里会有元信息保存提交的offset 等位点信息
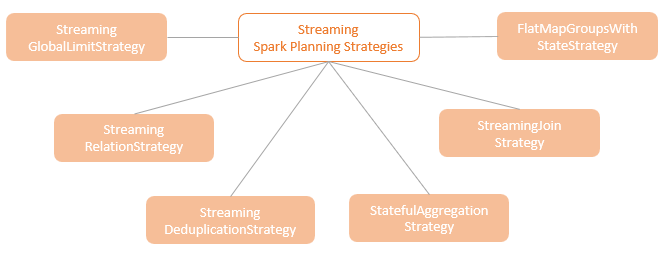
物理计划,当前有这么一些
- SpecialLimits
- JoinSelection
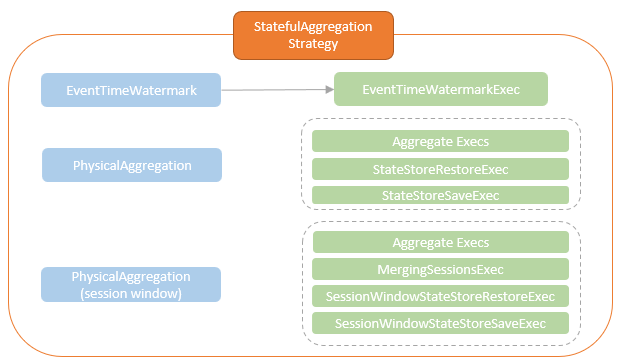
- StatefulAggregationStrategy
- StreamingGlobalLimitStrategy
- StreamingDeduplicationStrategy
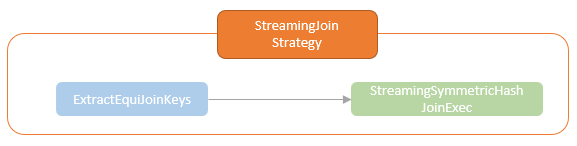
- StreamingJoinStrategy
- WindowGroupLimit
- InMemoryScans
- StreamingRelationStrategy
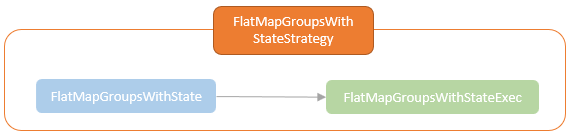
- FlatMapGroupsWithStateStrategy
- FlatMapGroupsInPandasWithStateStrategy
状态存储
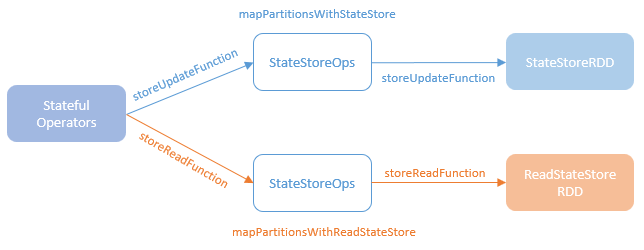
- mapPartitionsWithStateStore 创建 StateStoreRDD,执行物理写操作
- mapPartitionsWithReadStateStore 创建 ReadStateStoreRDD,执行读操作

Execution Preparation
- QueryExecution 会增插入一些必要的算子,如 sort,exchange 等
- IncrementalExecution 也会做一些准备操作
- 会记录 statefulOperatorId、nextStatefulOperationStateInfo
Stateful
有状态的记录
- 通过 StateStoreRDD,ReadStateStoreRDD 来写入、读取有状态数据
- 将有状态数据写入到 k-v 存储中
- 匿名函数会传递给 mapPartitionsWithStateStore、mapPartitionsWithReadStateStore
- 然后 mapPartitionsWithStateStore 创建 StateStoreRDD 更新状态,为每个 executor的每个分区创建 state store,调用匿名函数
- mapPartitionsWithReadStateStore 创建 ReadStateStoreRDD 做类似的工作,但是 state store 是只读的
StateStore
- StateStoreId 和 分区之间 1:1 做映射
- StateStoreId 是由:checkpointRootLocation, operatorId, partitionId, storeName 组成的
- state store 维护了一个 k-v对当做版本,每个版本表示一个操作状态点
- StateStore类封装了访问状态存储的方法
- StateStore的每个实例代表一个特定版本的统计数据,他们的实例由 StateStoreProvider 提供
- StateStoreProvider 会返回 getStore(version: Long),表示给定的版本
StateStoreProvider 的实现类
- HDFSBackedStateStoreProvider,使用 ConcurrentHashMap 作为第一阶段存储,第二阶段将数据保存到hdfs兼容格式中
- RocksDBStateStoreProvider,使用 RocksDB 来优化写入,避免 JVM内存开销
driver 和 executor
- StateStoreCoordinator 用 map 来记录每个 executor的位置
- StateStoreRDD 调用 driver,获取合适的 分区 locality 位置
- 每个 executor运行一个 StateStoreCoordinatorRef,用来跟 driver 的通讯,并告知 driver自己的活跃状态
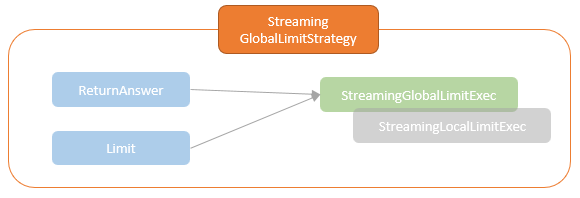
Limit
测试代码
|
|
打印的结果
|
|
解释
- 查询首先从 Rate 的source 流中生成 3个随机数每秒
- 首先执行 LocalLimit 操作然后是 GlobalLimit操作
- StreamingLocalLimitExec 从每个分区中取 limit条数据
- 假设有 10 个分区,每个分区取 5条,一共取 50条
- 这里会增加一个 Exchange操作,收集所有分区的数据,汇总成单个分区
- 之后读取所有 row并累计,如果超过了 limit 限制则后面的 row就不再返回了
- 当前的 micro-batch 完成后,将更新的 total row 写入到 state-store 中
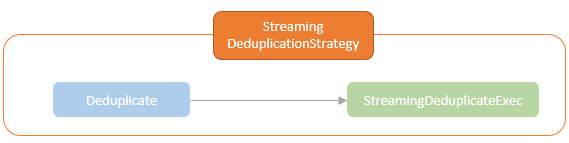
Duplicate
代码
|
|
打印结果:
|
|
解释
- 在这个流查询中,“key”值与现有行相同的行将被删除
- 这里做了 reshuffled 操作,相同的key 都会在一个分区内被操作
- 如果某个 key 在 state-store中说明之前处理过了,忽略即可
Aggregate
代码
|
|
打印的结果:
|
|
解释
- 从物理计划看,流的执行过程跟 batch 的逻辑很类似,只是多了 state-store
- 主要的不同是多了 StateStoreRestore、StateStoreSave 这些额外的操作
- StateStoreRestoreExec 从前面的 batch 中执行聚合操作
- 更新的聚合值会通过 StateStoreSave 写入到 state-store中
Stream-Stream Join
跟普通的 batch 方式 join不同,stream join 时,一端的 input data 可能已经到达了
但是另一端的数据可能还未达到,需要用 buffer 缓存这些临时数据
测试代码
|
|
打印结果:
|
|
解释
- 生成的物理计划为:StreamingSymmetricHashJoinExec
- EventTimeWatermark 增加到了两端,作为 水印的 filter
- 通过 HashClusteredDistribution,将两边的数据做 exchange,保证每个分区读到相同的key
- StreamingSymmetricHashJoinExec 执行前使用 StateStoreAwareZipPartitionsRDD 将两边的分区数据准备好
相比于普通的 join,stream join 有两点不同
- Use Symmetric Hash Join algorithm
- Join with buffered rows in state store
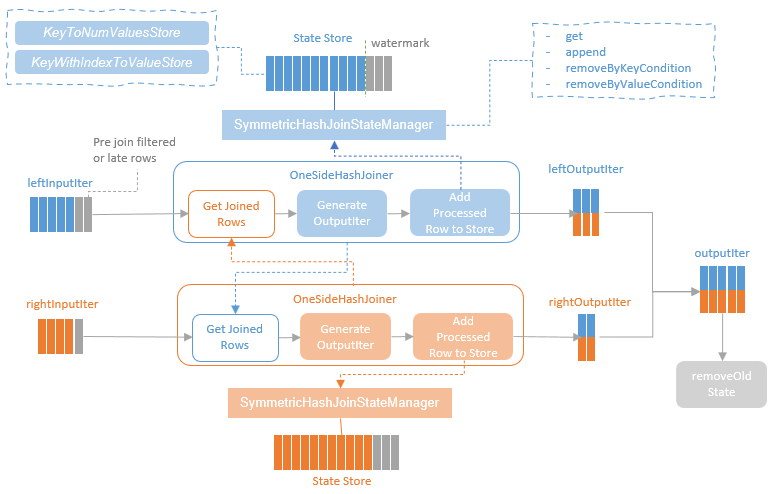
说明
- 普通的 hash join,是一端build hash,然后遍历另一端取出 row,跟hash-table里面的比较看是否匹配
- 由于两端的数据可能不是同一时间到达,不适合用普通 hash join 方式
- spark streaming 采用了 symmetric hash join algorithm
- 对于左右端,他们都会查找对方的 state-store 是否有匹配的key,也就是说,两端的 join 都有 build 和 probe行为
- 左右两端都用 OneSideHashJoiner,封装了consume input data 逻辑,使用对方的流状态作为输出
- 每个 OneSideHashJoiner 都维护了 SymmetricHashJoinStateManager,用来管理 state-store 状态

storeAndJoinWithOtherSide
- 这个是 StreamingSymmetricHashJoinExec 的核心逻辑,用来真实的执行 join操作
- left 端执行左边的 input数据;right 端执行 右边的input 数据
- 会通过水印标记,删除老的数据
- 提取输入行,使用 getJoinedRows 从对端 state-store中查询出匹配的 row
- 之后合并两端的数据输出,低于水印的 state row会被清除
- 除了 inner,也支持 left out,right out 等

StreamingSymmetricHashJoinExec 中的注释
- 这里会添加一些水印操作
- 如果 left 端水印超过指定的时间,就可以从 state-store 中删除
|
|
Session Window
Tumbling window、 Sliding window 这两种窗口的长度,session 起始时间都是归哪个的
而 session 窗口长度是不固定的,开始、结束时间也不固定,依赖于 input data
他将非空闲期间内的一些 session 分组到不同的窗口中
会话间隙内发生的任何事件都将合并到现有会话中
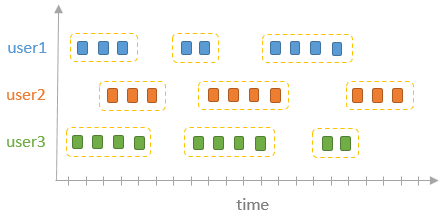
例子代码
|
|
打印结果:
|
|
session_window
- 第一个参数时 event timestamp column for windowing by time
- specifies the session gap duration which can be also viewed as timeout of the session
- spark 内部会定义 SessionWindow,
- analyzer 定义的 session windows是:
- [“start” = timestamp, “end” = timestamp + session gap].
物理计划
- 由 StatefulAggregationStrategy 负责调用 planStreamingAggregationForSession
- 生成对应的物理计划
执行过程
- Partial Aggregation 根据 key and session_window,对分区数据做分组
- Merging Sessions (optional),在 shuffle 之前先做一次merge,减少 shuffle 的数据量
- merge之前会插入一个 Sort算子
- Shuffle,相同 hash 的key会被分组到同一个分区,此时会去掉 session_window
- SessionWindowStateStoreRestore,从state-store中毒 session windows,将他们合并到当前的 micro-batch中,跟 mergingSessionExec 类似
- 另一个 MergingSessionExec 操作,从 input stream 和 state store 中合并,再计算聚合值
- SessionWindowStateStoreSave,将 session windwos 保存,为下一个 micro-batch 做准备
- Final Aggregation,最后输出结果
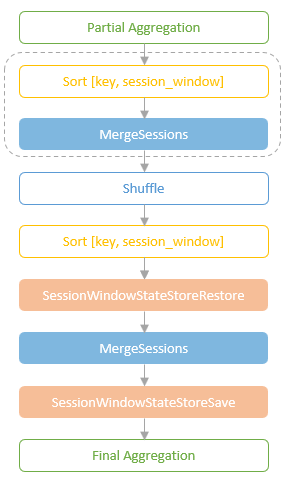
Merging Sessions
- 实现会话窗口的核心需求是决定哪些事件可以放置到会话窗口中,以及会话窗口何时结束。
- 开始时间是 input row达到了
- 结束时间是 [the event timestamp + the session gap duration]
- 也就是,新来的数据在这个窗口中,窗口就 expand,否则窗口就 close
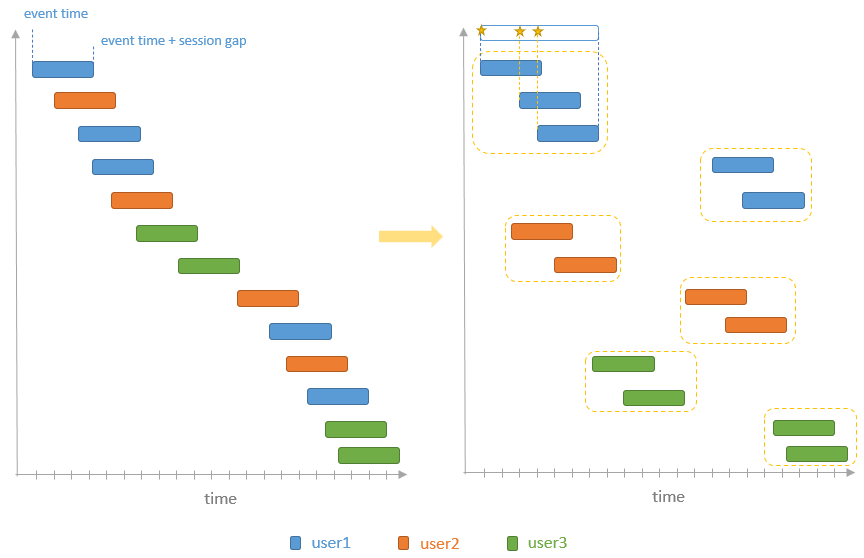
MergingSessionExec 物理算子的工作过程
- requiredChildOrdering,增加一个 Sort 算子
- 之后就可以按顺序一个一个处理了
- 当处理一行的时候,检查当前的key(session_windows) 是否在当前窗口中
- 如果不是,就另开启一个session 窗口
- 再检查 event timestamp 是否 > 当前 session end,如果是加入到当前窗口中,否则新启动一个窗口
|
|
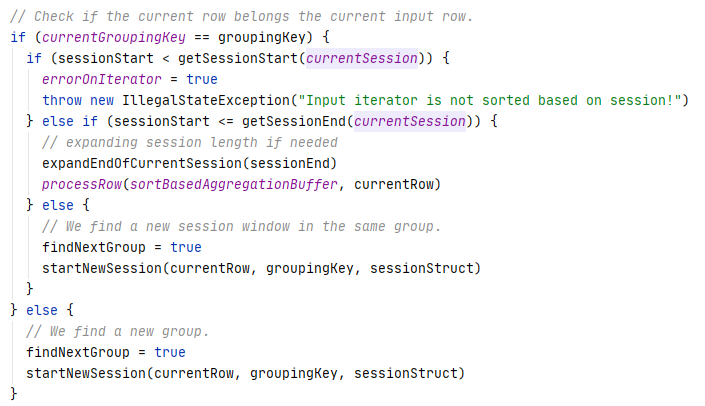
SessionWindowStateStoreRestoreExec
- 用于从状态存储中恢复会话窗口
- 根据 aggregate key 和 session windows,从当前 micro-batch 的排序中合并输入 row
- 真实的合并、排序操作定义在:MergingSortWithSessionWindowStateIterator
SessionWindowStateStoreSaveExec
- 一个物理算子
- 更新 state-store 中的 的状态
- 下图展示了 session windows 是如何存储在 state-store 中的
- 按照聚合key,用数组来存储 session-windows

参考
- Spark Structured Streaming Deep Dive (1) – Execution Flow
- Spark Structured Streaming Deep Dive (2) – Source
- Spark Custom Streaming Sources
- Spark Custom Streaming Sources
- Spark Structured Streaming Deep Dive (3) – Sink
- azure-event-hubs-spark
- Spark Structured Streaming Deep Dive (5) – IncrementalExecution
- Spark Structured Streaming Deep Dive (6) – Stateful Operations
- Stream-Stream Join
- Session Window