Kafka架构
LinkedIn 最早做这套系统,就是为了解决服务之间的耦合问题,有了 kafka 就变成松耦合了
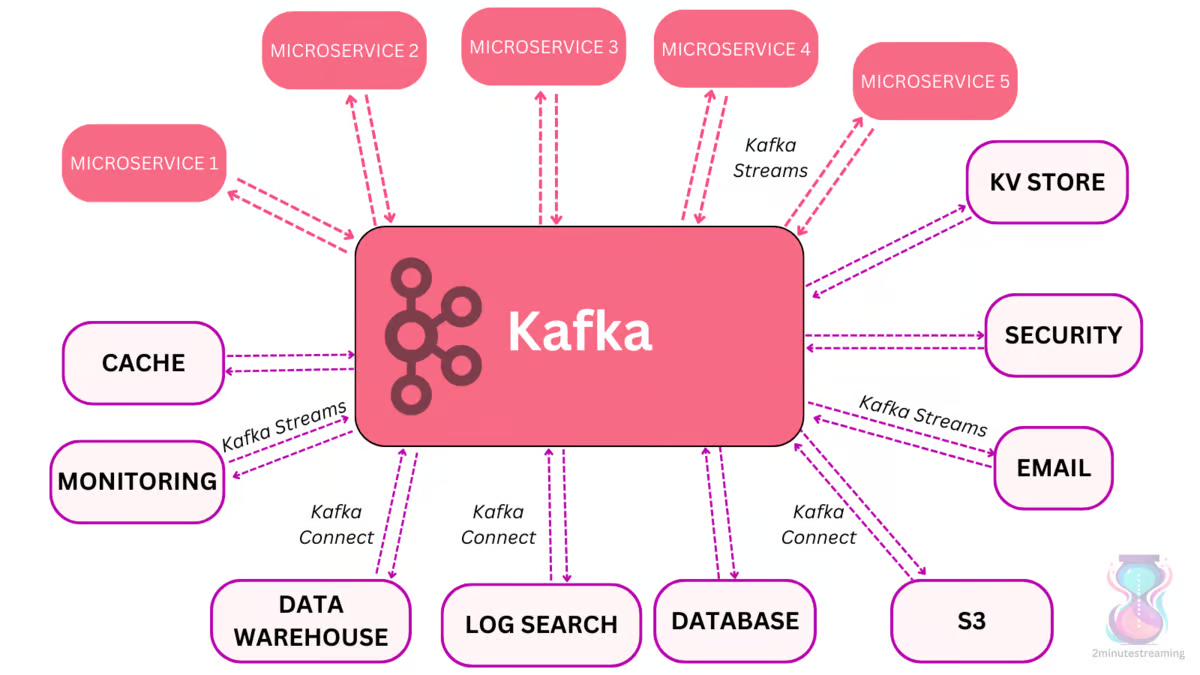
架构
架构
- producer,多个写入者
- broker,保存数据,内部分成多个 partition,partition 一主多从
- consumer,可以组成 cosumer group
- 一些节点元数据信息,保存在 ZK 上
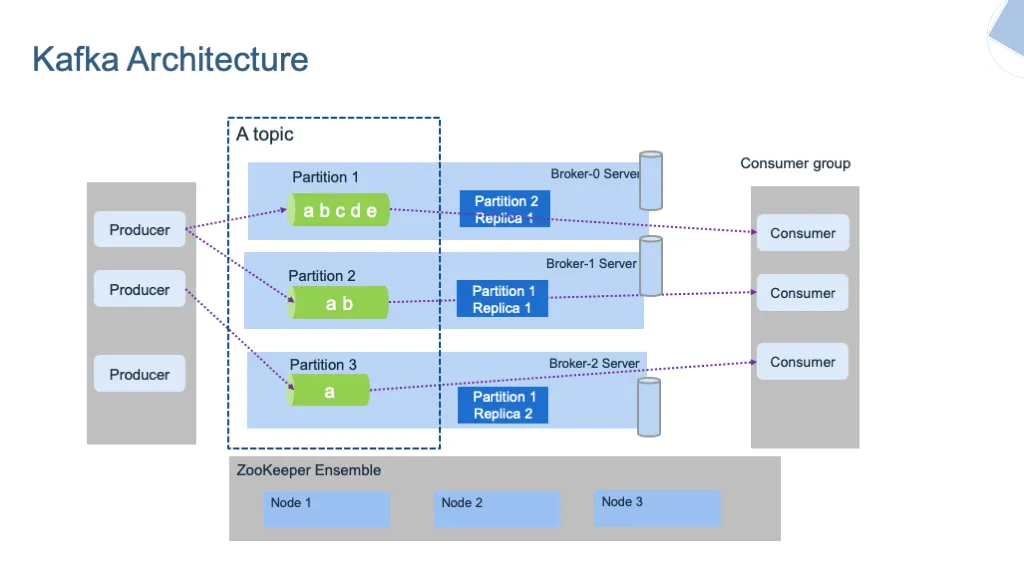
各个组件
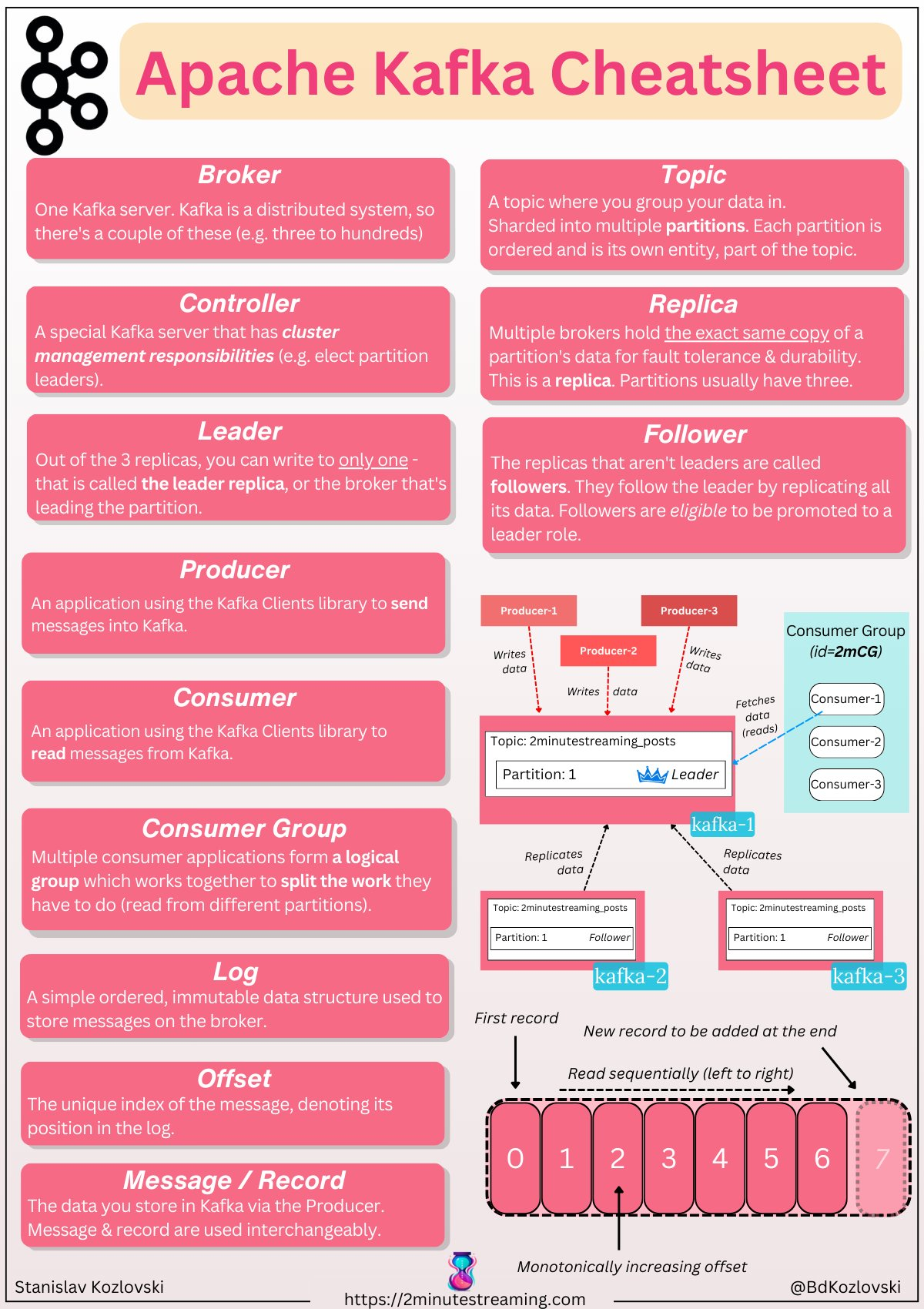
采用 append 追加方式,所以数据是顺序写入
读的话,是 head 读,或者 tail 读,所以读的速度也很快
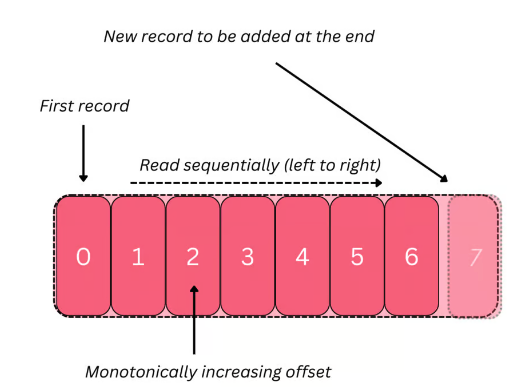
Log Segment
- 一个分区内,包含多个Log Segment
- 日志内的数据,是单调递增的
- 一个 segment 的数据会持续写入,当一个文件写满了(默认1G),就会变成不活跃的
- 默认只有一个活跃的,可以接受append写入,其他 不活跃的就变成只读的了
- 当然kafka 会保留一段时间的数据,直到超时后,会删除掉这些数据
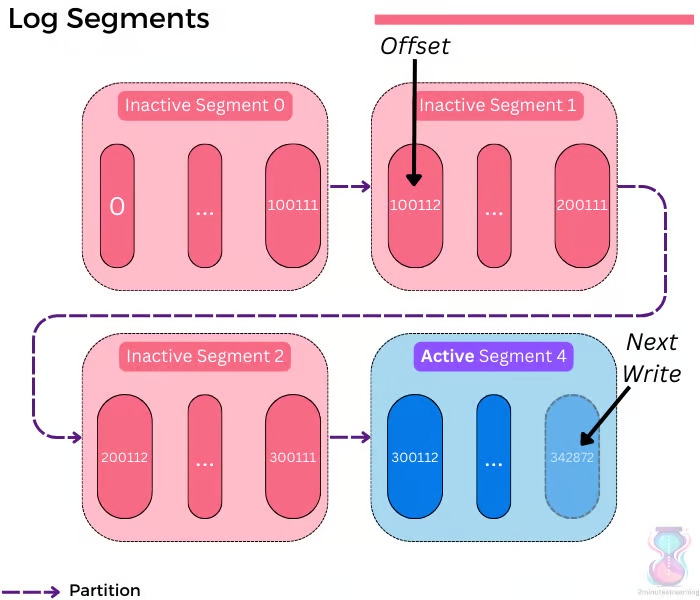
broker,partition,segment关系
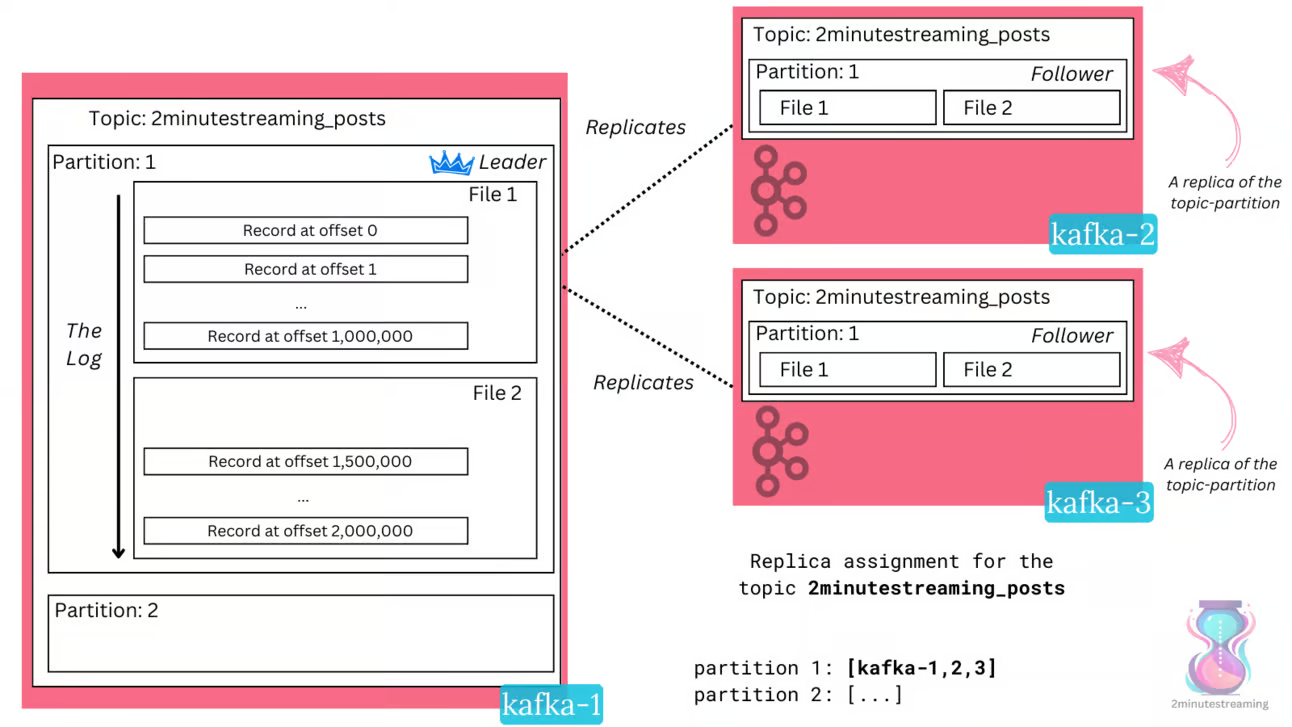
- 一个topic会跨多个 broker 存储
- 一个 topic 会拆分成多个分区,每个分区都有一个活跃的 segment
- 每个分区的数据存储到多个 segment 中,也就是存到磁盘上
- 这些磁盘上的数据就是 log segment,按append 方式写入的
分区的leader
- 分区分区包含多个文件,序号递增
- 有一个leader,从节点负责同步数据,但不负责接受请求
producer 写入到 brokder 的配置,根据 ack 来保证数据是否确定
- acks=0 - the producer won’t even wait for a response from the broker, it immediately considers the write successful
- acks=1 - a response is sent to the producer when the leader acknowledges the record (persists it to disk).
- acks=all (the default) - a response is sent to the producer only when all of the in-sync replicas persist the record.
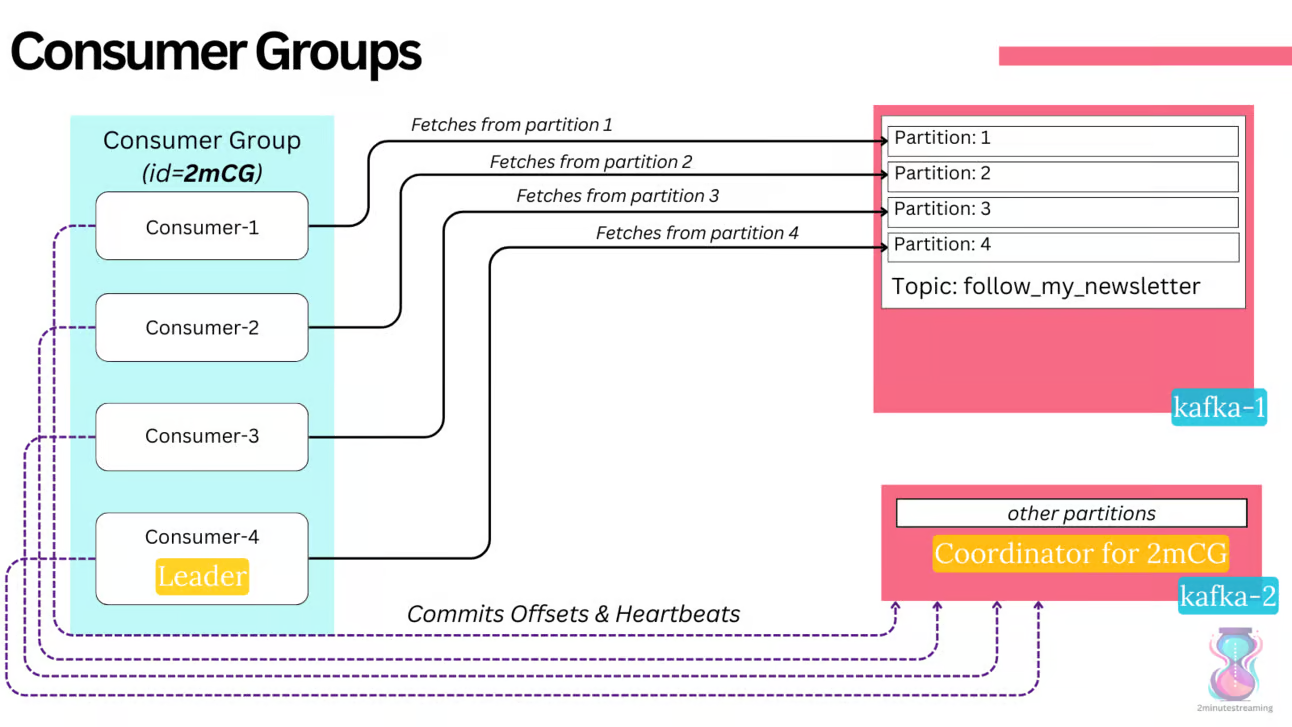
consumer
- 一堆consumer 放在一起,变成 consumer groups
- 这些消费者将自身的 offset 保存到内部的 topic:__consumer_offsets 中
- 消费者组协议确保同一消费者组中的两个消费者不能从同一分区中读取数据
- 可以有许多不同的消费者群体阅读同一主题
- 跟传统的 消息队列不同,kafka 不会因为consumer 消费了就删除数据,会一直保留
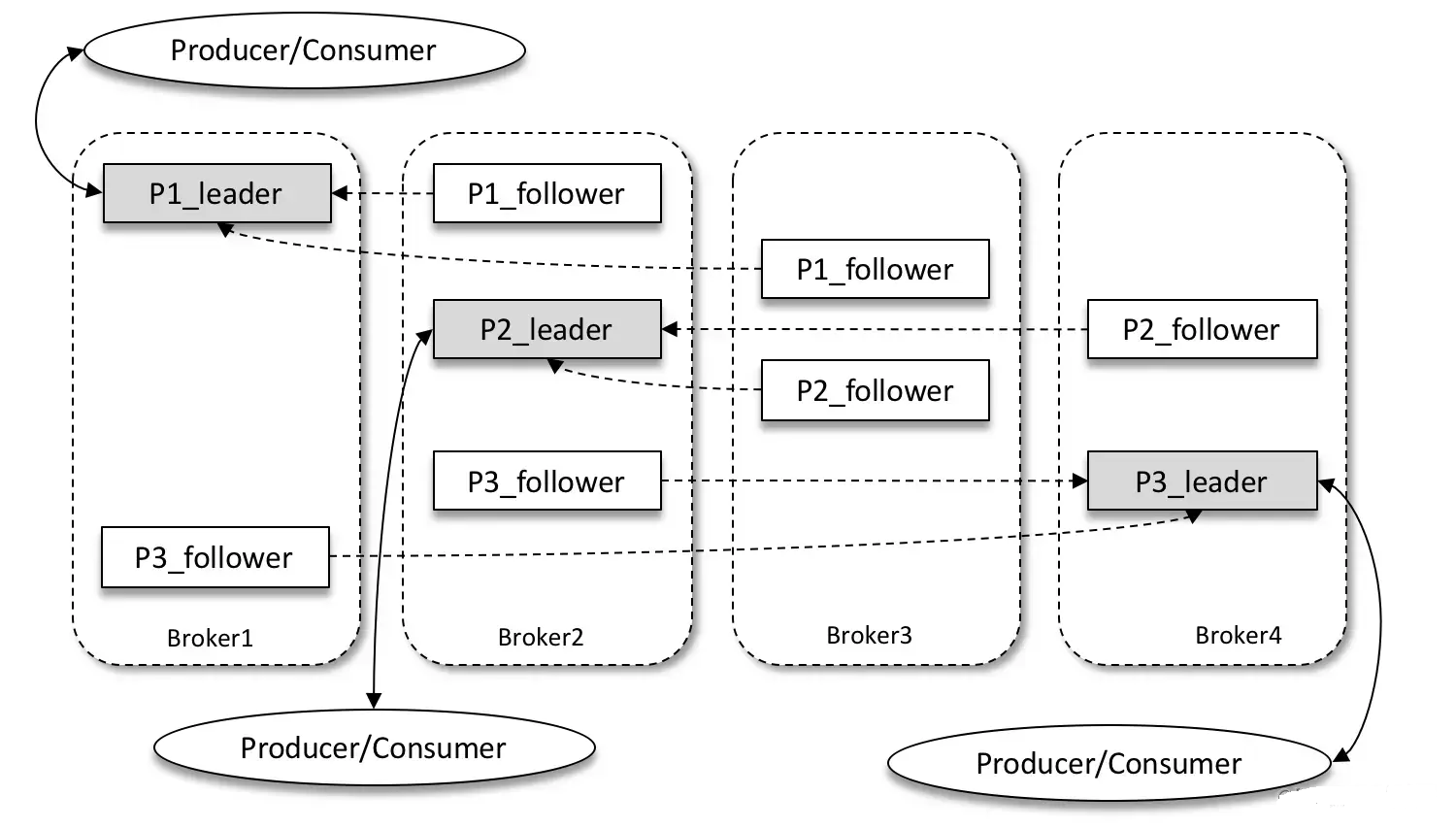
AR、ISR和OSR
- AR(Assigned Replicas):分区中的所有副本统称为AR。
- ISR(In-Sync Replicas):所有与 leader 副本保持一定程度同步的副本(包括 leader 副本在内)组成ISR,ISR 集合是 AR 集合中的一个子集。
- OSR(Out-of-Sync Replicas):与 leader 副本同步滞后过多的副本(不包括 leader 副本)组成 OSR。AR=ISR+OSR
- leader副本负责维护和跟踪 ISR 集合中所有follower副本的滞后状态
- 当 follower 副本落后太多或失效时,leader 副本会把它从 ISR 集合中剔除
- 如果 OSR 集合中有 follower 副本“追上”了 leader 副本,那么 leader 副本会把它从 OSR 集合转移至 ISR 集合
- 分区ISR 集合中的每个副本都会维护自身的LEO,而ISR集合中最小的LEO 即为分区的HW,对消费者而言只能消费 HW 之前的消息
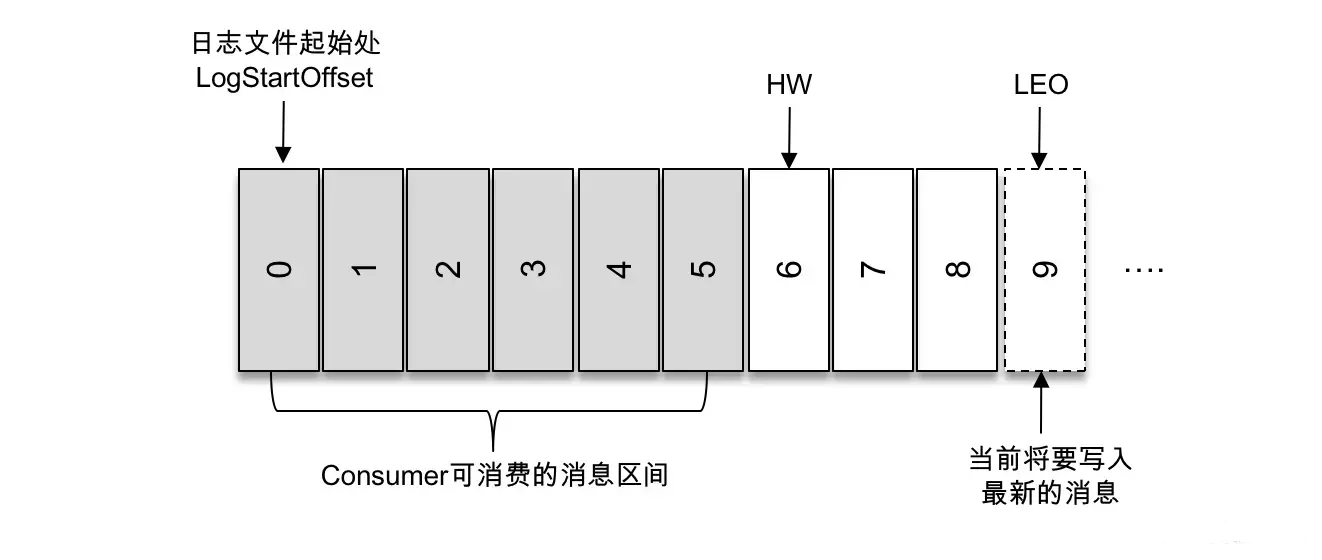
HW 和 LEO
- HW(High Watermark):高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个 offset 之前的消息
- LEO(Log End Offset):它标识当前日志文件中下一条待写入消息的 offset,上图中 offset 为9的位置即为当前日志文件的 LEO,LEO 的大小相当于当前日志分区中最后一条消息的 offset 值加1
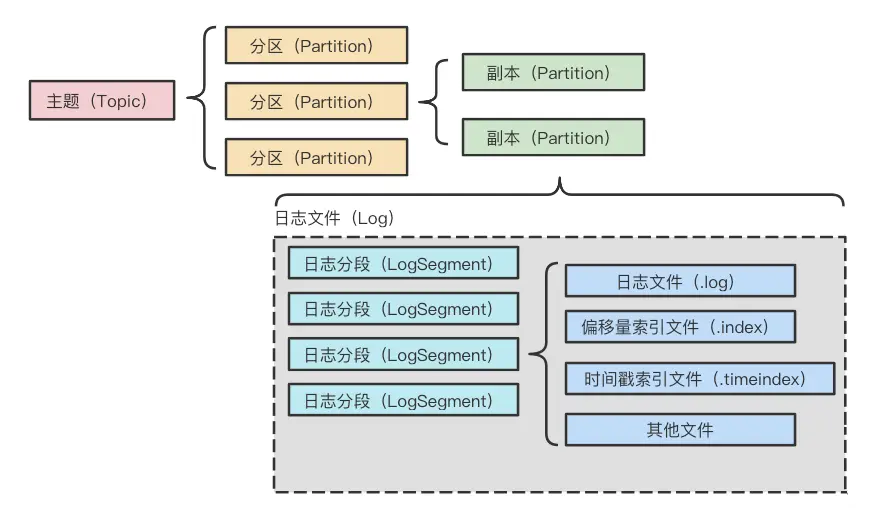
Log Segment
整个主题、分区、副本、日志关系如下
- 每个日志分段除了真实的数据日志文件(.log后缀)之外
- 还有对应的2个索引文件:偏移量索引文件(.index)和时间戳索引文件(.timeindex)
- 索引偏移量、时间戳索引 都是稀疏索引
- 采用二分查找的方式定位,再指向真实的 物理地址
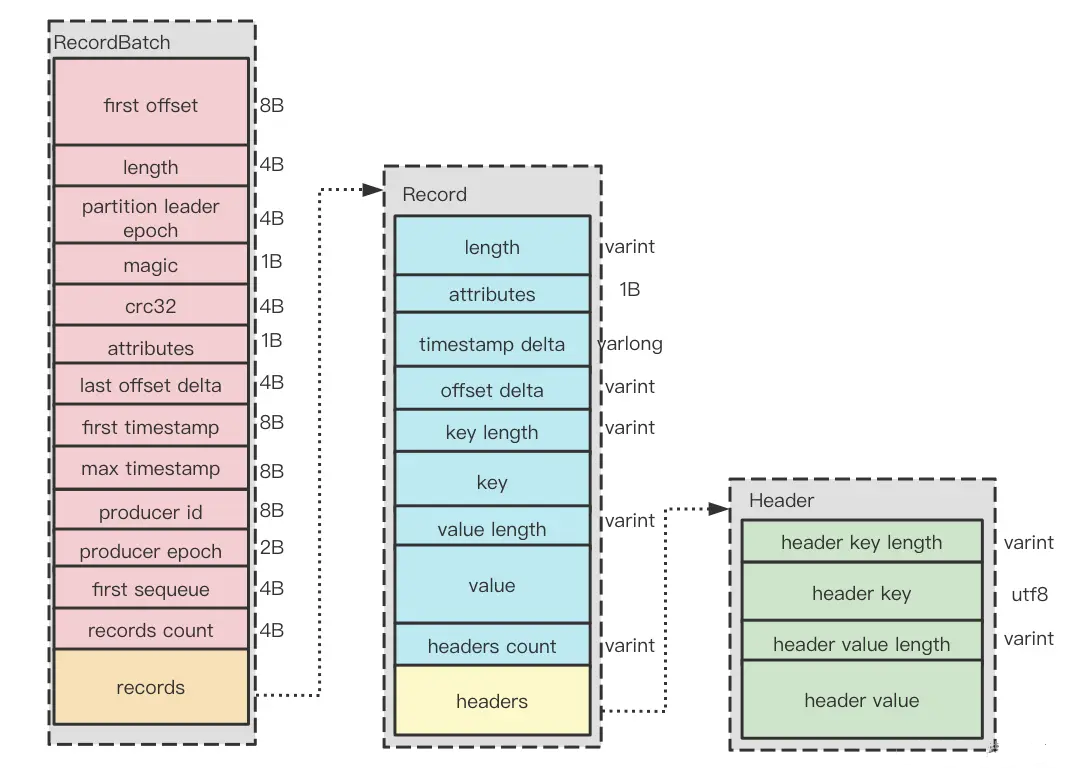
消息集格式
- Kafka从0.11.0版本开始使用v2版本消息格式
- 首先是引入了变长整形(varinits),做到了数值越小,占用的字节数就越少,从而大大节省了空间
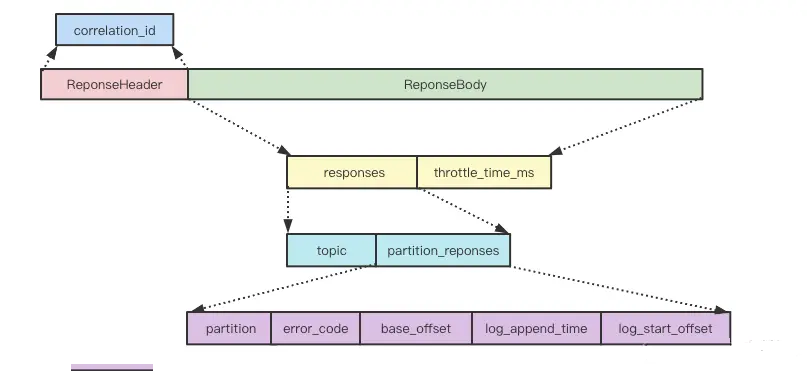
请求和响应格式
请求消息格式,基于 TCP 之上自定义的协议
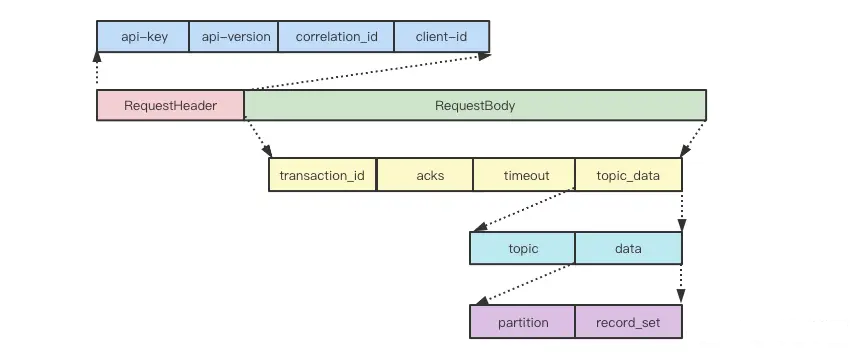
响应消息格式
一些优化
读写优化
- 预先读一批数据缓存到内存,这样下次读就直接从内存读
- 写也是直接写到内存,然后异步刷新到磁盘
- 读和写都是顺序的,相当于 机械盘的顺序读,或者 SSD的顺序读 和写
- 最大限度的利用了磁盘 I/O
系统级别优化
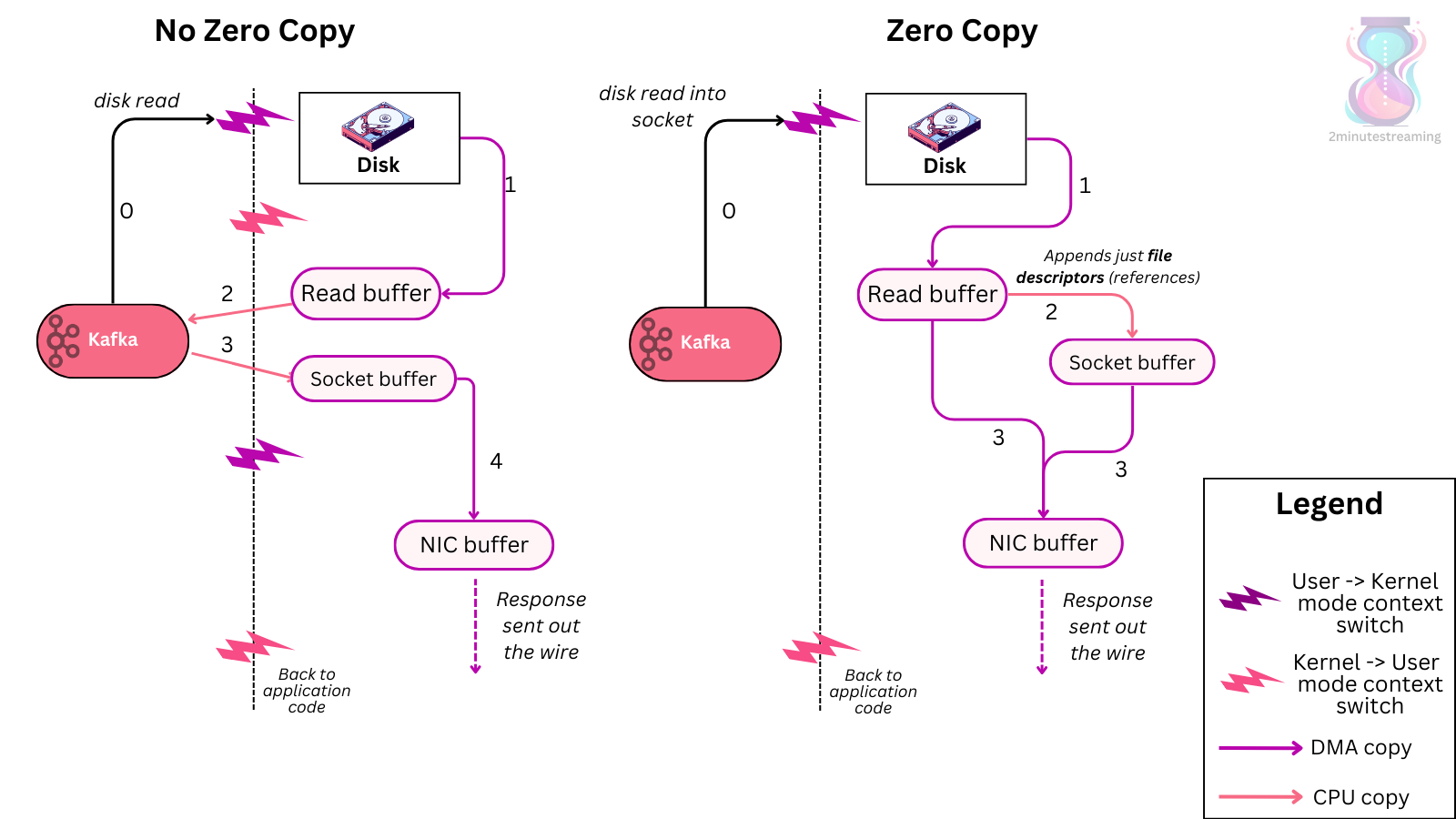
- 使用了 page-cache 优化
- zero-copy 优化
Consensus
- 之前用 ZK 做共识算法,brokder 等元数据存储在 ZK 上
- zk 上的 znode 叫:/controller
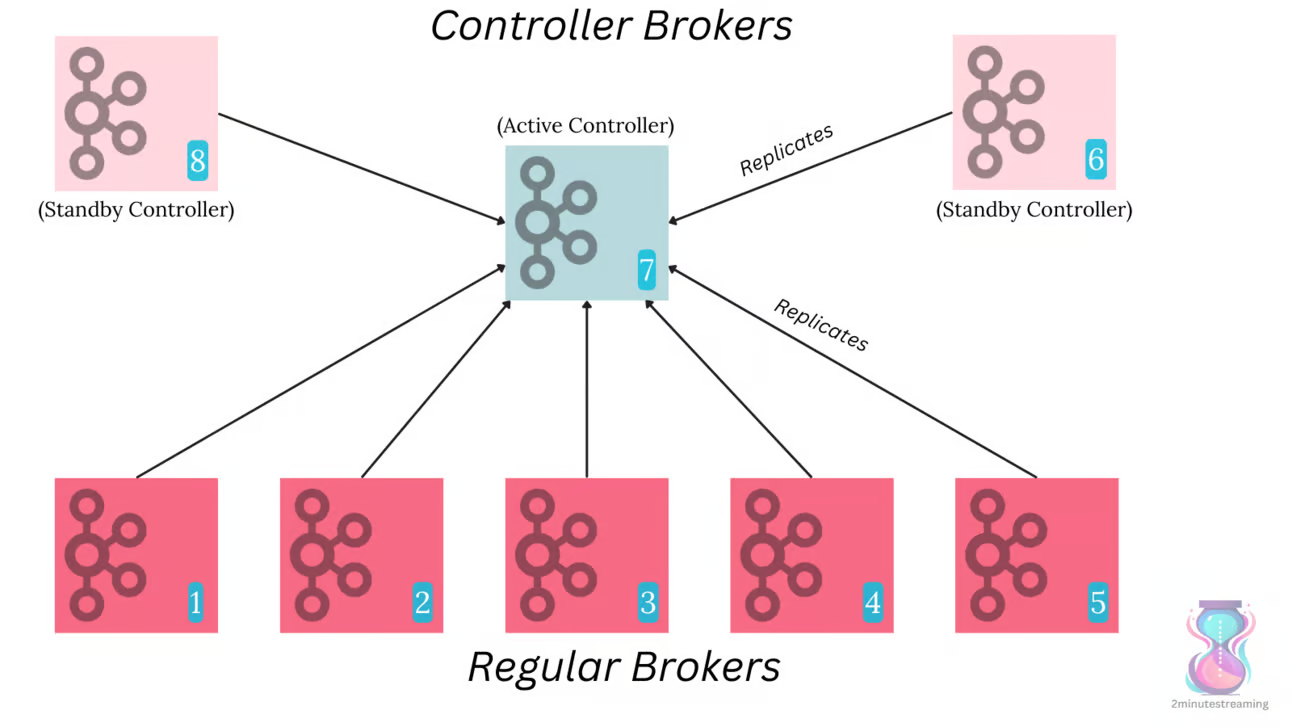
- 现在改用 raft 替代 ZK,使用的是 raft 的方言:Kafka Raft
- 新的方式也是要有 N controllers,然后选举一个主节点
- 存储到特定的 topic 的元数据主题:__cluster_metadata
- 这个主题有一个单独的分区,它的leader选举是由Raft管理的(而不是其他每个主题的Controller)
- 分区的leader将成为当前活动的Controller,其他控制器充当热备用,在内存中存储最新的元数据
- KRaft 支持两种模式部署,brokder本身又做为 controller,或者单独一个controller
分层存储,现有的问题
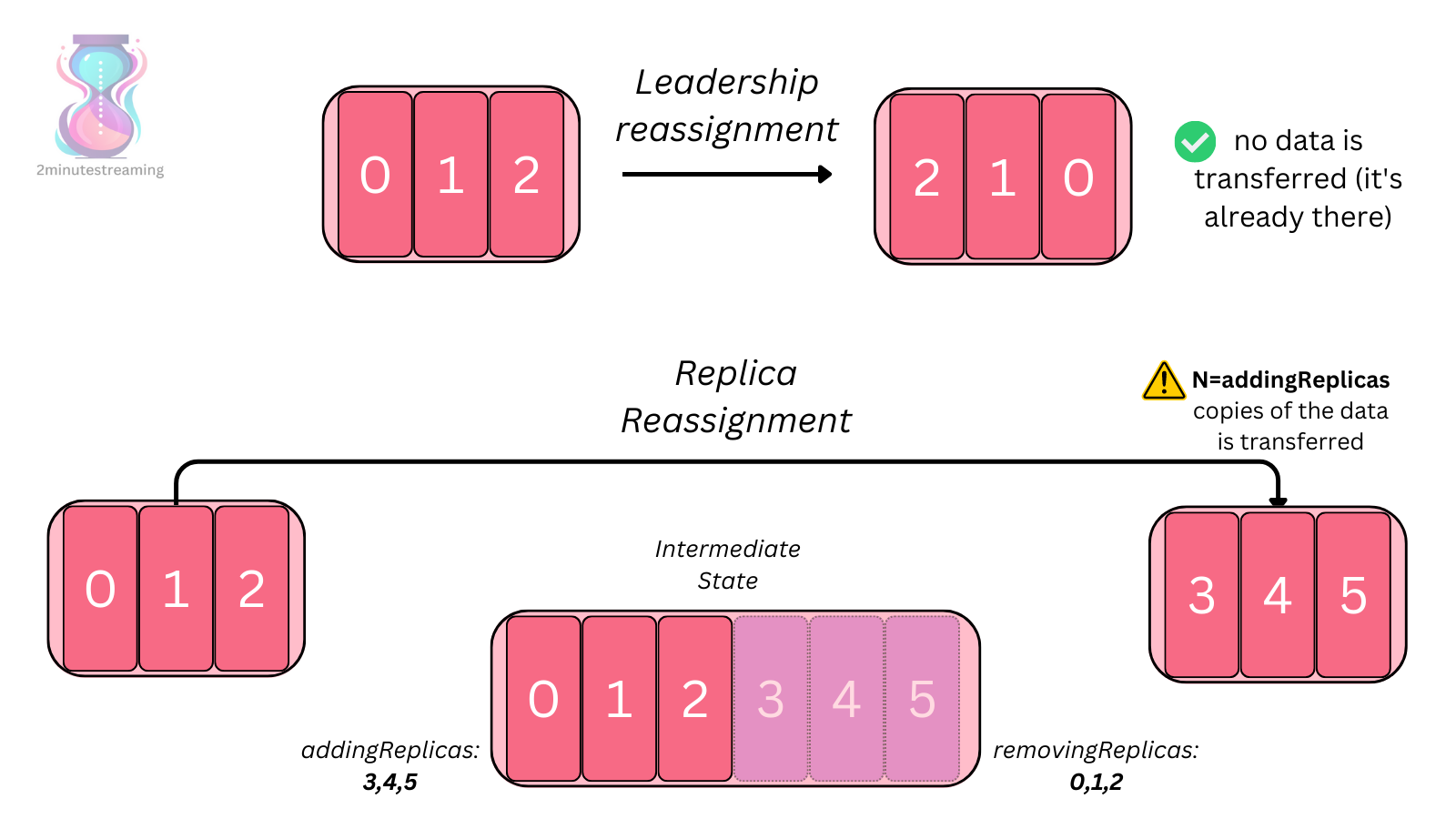
- kafka 是用本地磁盘的,但是有副本问题,比如 1T 数据会变成 3T 数据
- 当每个节点有 10T 的本地数据时,如果碰到某个 broker下线,那么同步数据需要非常多的时间
- 或者 rebalance,也需要非常多的时间,取决于网络带宽,和磁盘 I/O
- 或者一个新节点加入集群,也需要拷贝大量数据
分层存储架构
- 活跃的数据存储在本地磁盘
- 冷数据放到 S3 上
- 当 brokder 挂掉,或者新的broker 需要读历史数据,直接从 S3 上读取
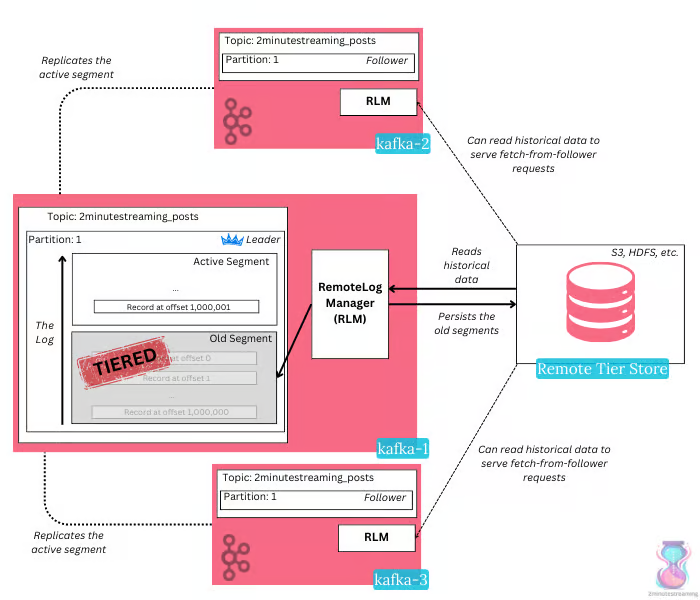
辅助系统
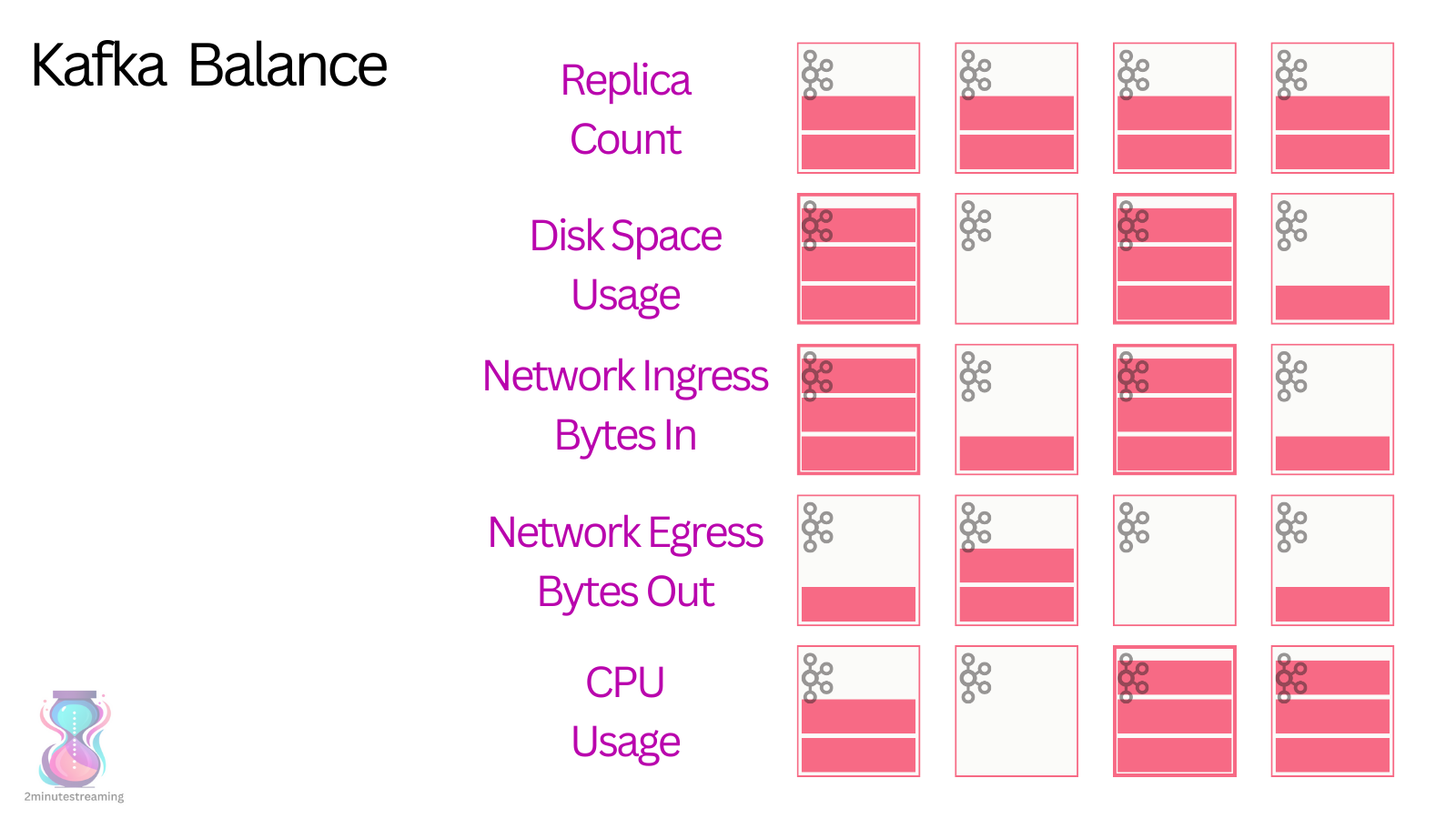
kafka balance
- 这实际是一个 NP 问题
- 需要考虑 副本数量,读流量,写流量,网络带宽,CPU使用率等等
- 开源项目 Cruise,会读取 kafka 的 metrics,然后统计最有效的方式
- 再通过 API 触发 rebalance
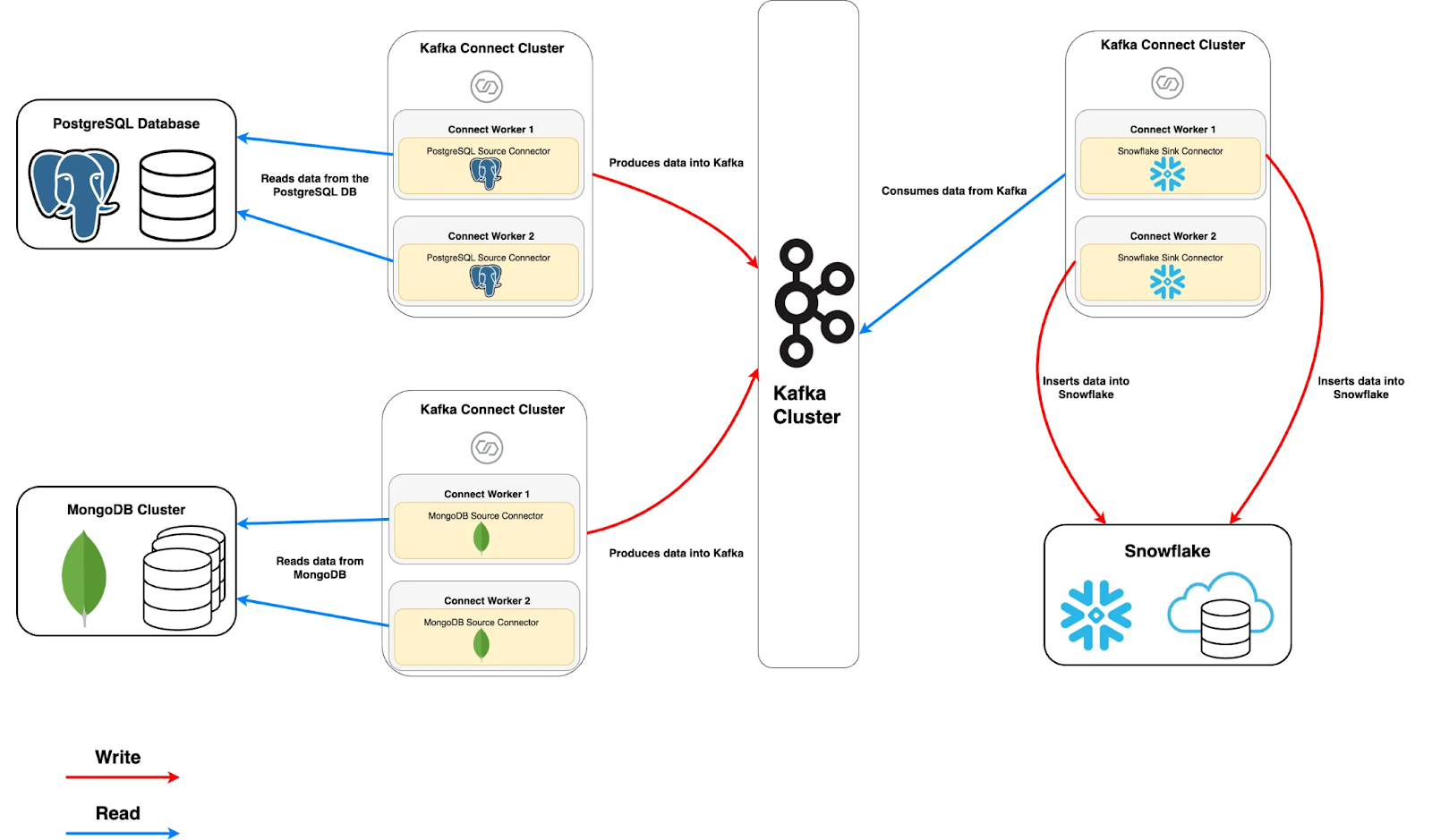
Kafka Connect
- Source Connector — used when sourcing data from another system (the source) and writing it to Kafka.
- Sink Connector — used when sourcing data from Kafka and writing it to another system (the sink).
Kafka Streams
- 有点类似于 Flink,提供一个处理复杂事件的 API
未来
- Kora: A Cloud-Native Event Streaming Platform For Kafka
- Keynote:用 C++ 重写的 kafka
- WarpStream:statefulness 架构,数据存储在 S3 上
参考
- 官方文档
- kafka之深入理解日志存储
- Kafka 101
- Behind AWS S3’s Massive Scale
- Kora: A Cloud-Native Event Streaming Platform For Kafka
- WarpStream
- the requirements of: Uber’s Exabyte-Scale Data Infrastructure (The Uber Series Part I)
- The Numbers Behind Uber’s Data Infrastructure (The Uber Series Part II)
- 图解Kafka:架构设计、消息可靠、数据持久、高性能背后的底层原理