Spark的一些优化
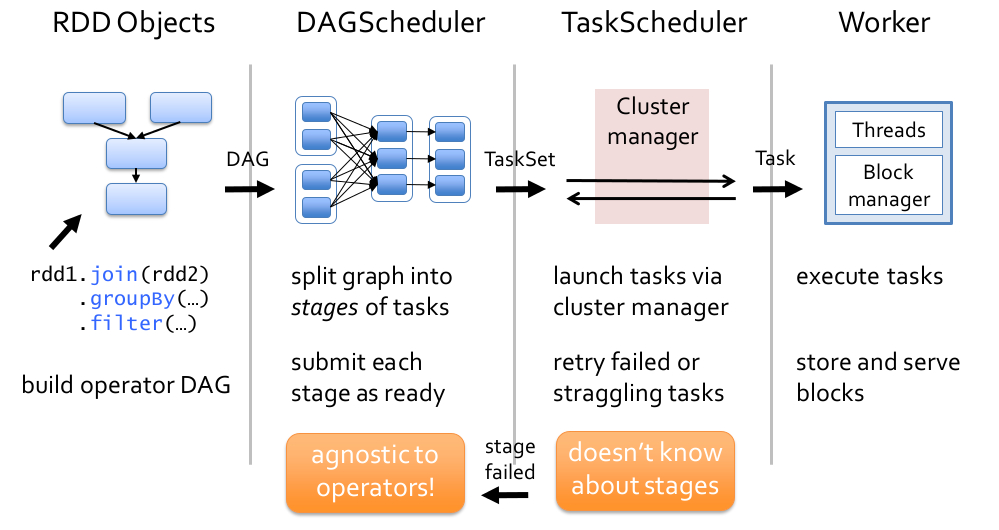
调度过程
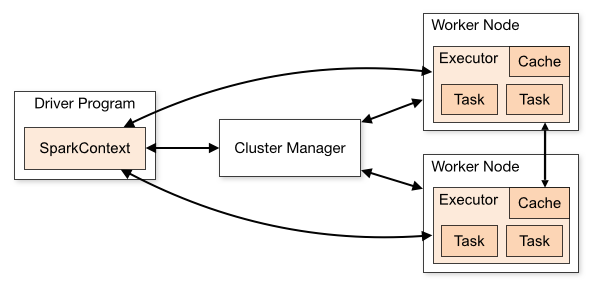
架构
调度过程
WEB-UI
Web-UI 需要关注的指标
- Executor 中
- 失败的数据,读数据,shuffle,cache
- CPU,内存使用,RDD 数量,GC时间
- SQL 节点关注执行执行计划
- 整个执行计划的大体看下,关注 shuffle 部分
- shuffle 读、写的数量,时间
- shuffle 本地读,跨网络传输的数量,时间
- Sort 的排序时间,spill 溢出数量
- Aggregate 聚合的时间,spill 数量
- Stage 分析
- 看 DAG,看下大体情况
- 看 Event Timeline,就是这个 stage中每个步骤大概花了多少时间
- schedule、deserialization、shuffle读写、executor计算时间
- 理想情况应该 executor计算时间最多
- shuffle时间过大,考虑是否用 broadcast 优化
- schedule时间多,优化并行度,减少调度开销
- Task Metrics
- 以一个更细的粒度,看 task 的执行细节
- 最小,25%分为,50%分为,75%,Locality level
- shuffle读写,spill,持续时间,序列化,内存,schedule,GC time
- 其他
- Storage 信息
- environment 信息
shuffle优化
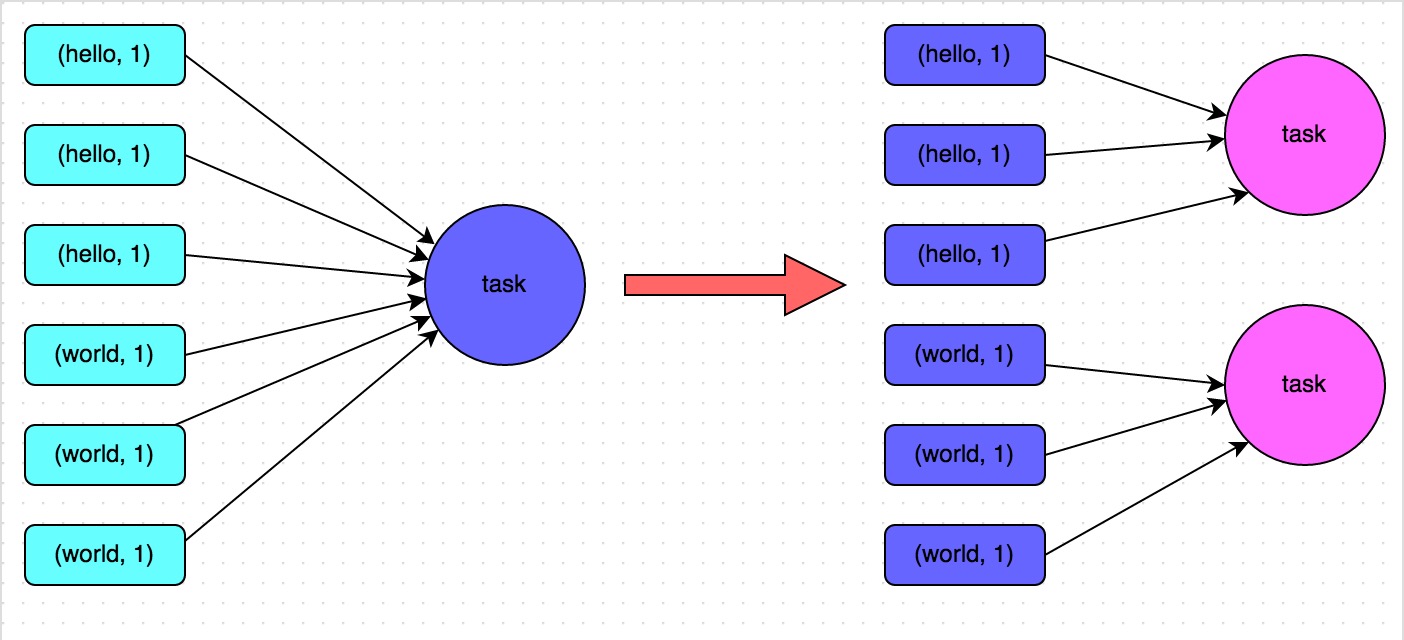
提高shuffle操作的并行度
- 最简单的一种方式
- 增加了 task 数量,每个task 出来的任务少了
- 某个key对应100W数据,增加并行度后,这个 task 还是会处理这么多
两阶段聚合(局部聚合+全局聚合)
- 适合group by 这种操作
- 给每个key 增加随机前缀(executor数量),对这些打散的随机key做聚合
- 对局部聚合的数据去掉 随机前缀,再次聚合,就是最终结果
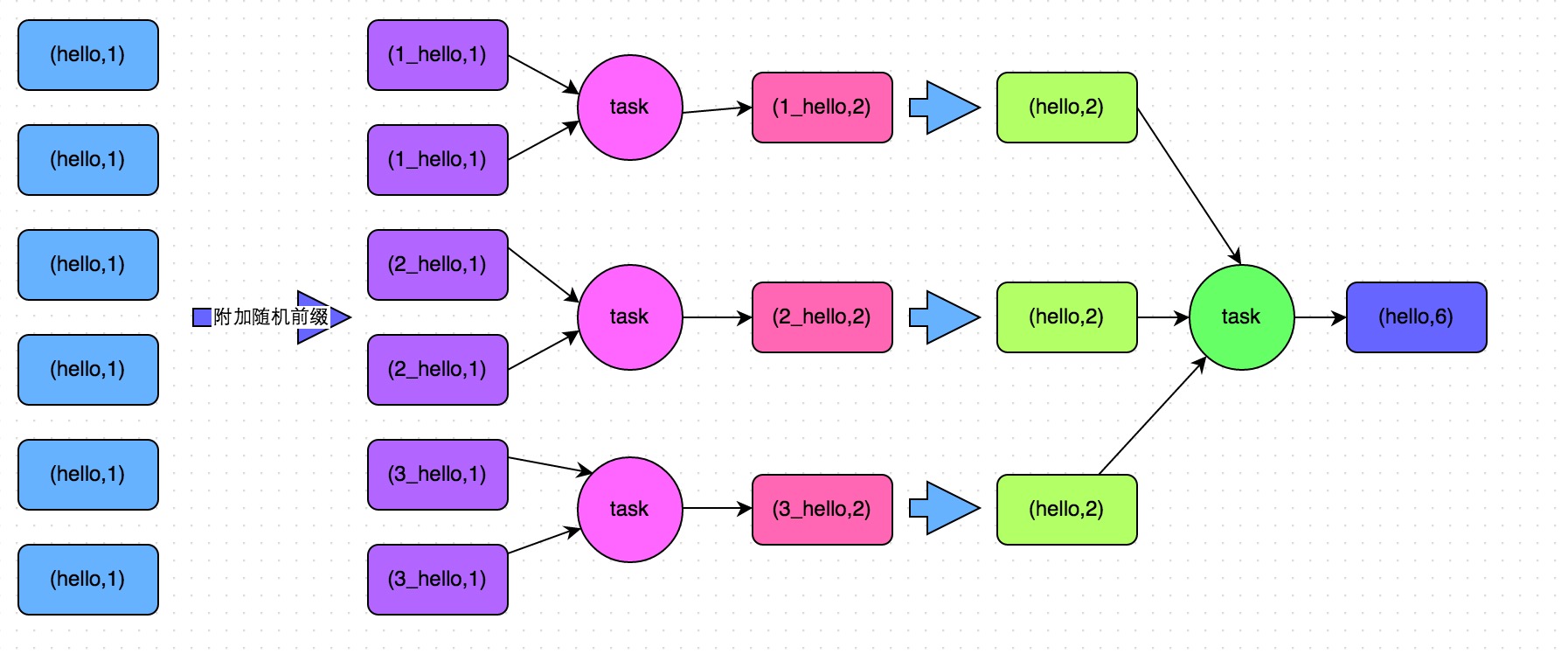
实现
- 第一步,给RDD中的每个key都打上一个随机前缀。
- 第二步,对打上随机前缀的key进行局部聚合。
- 第三步,去除RDD中每个key的随机前缀。
- 第四步,对去除了随机前缀的RDD进行全局聚合。
|
|
将reduce join转为map join
- 也就是 BHJ 方式,用广播来优化
- 只是适合 大表 join 小表的场景
|
|
采样倾斜key并分拆join操作
|
|
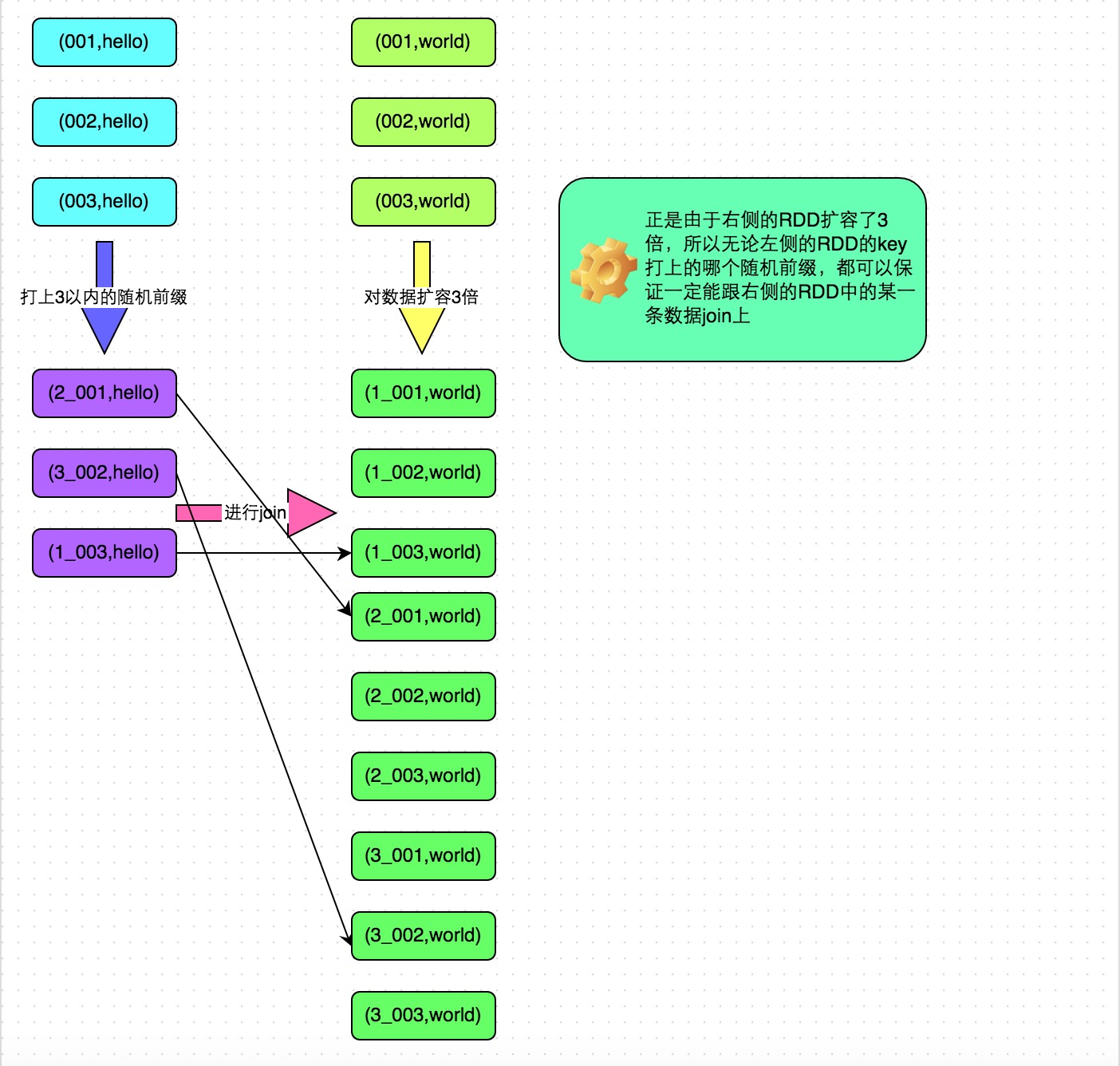
使用随机前缀和扩容RDD进行join
如果表中包含了很多倾斜 key,处理方式 跟 加盐 join 的类似
- 首先将其中一个key分布相对较为均匀的RDD膨胀100倍。
- 其次,将另一个有数据倾斜key的RDD,每条数据都打上100以内的随机前缀。
- 将两个处理后的RDD进行join即可
|
|
另一个例子
代码
|
|
shuffle原理
HashShuffleManager,现在已经没有了
未优化的方式,task 生成的磁盘文件会很多
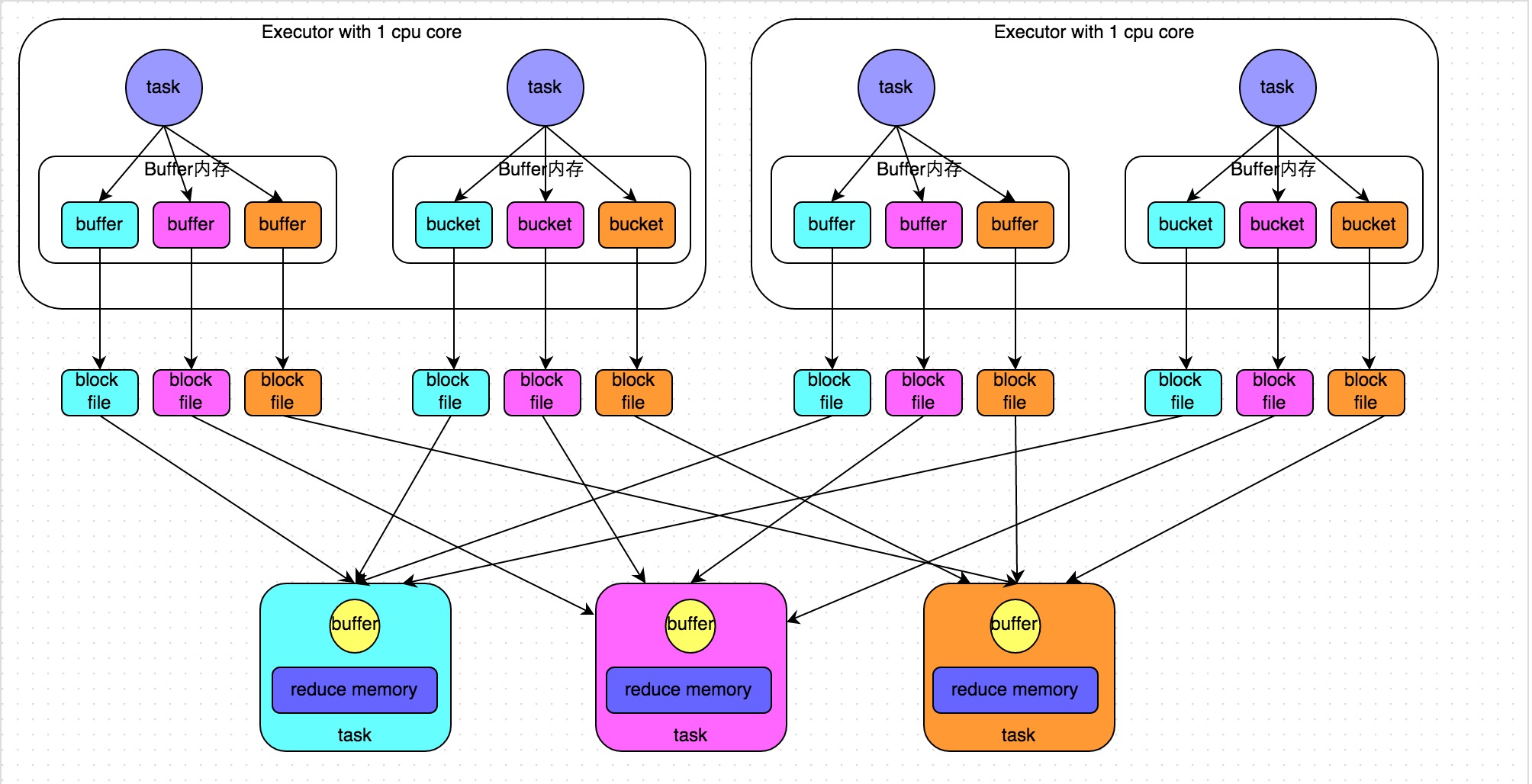
优化后的
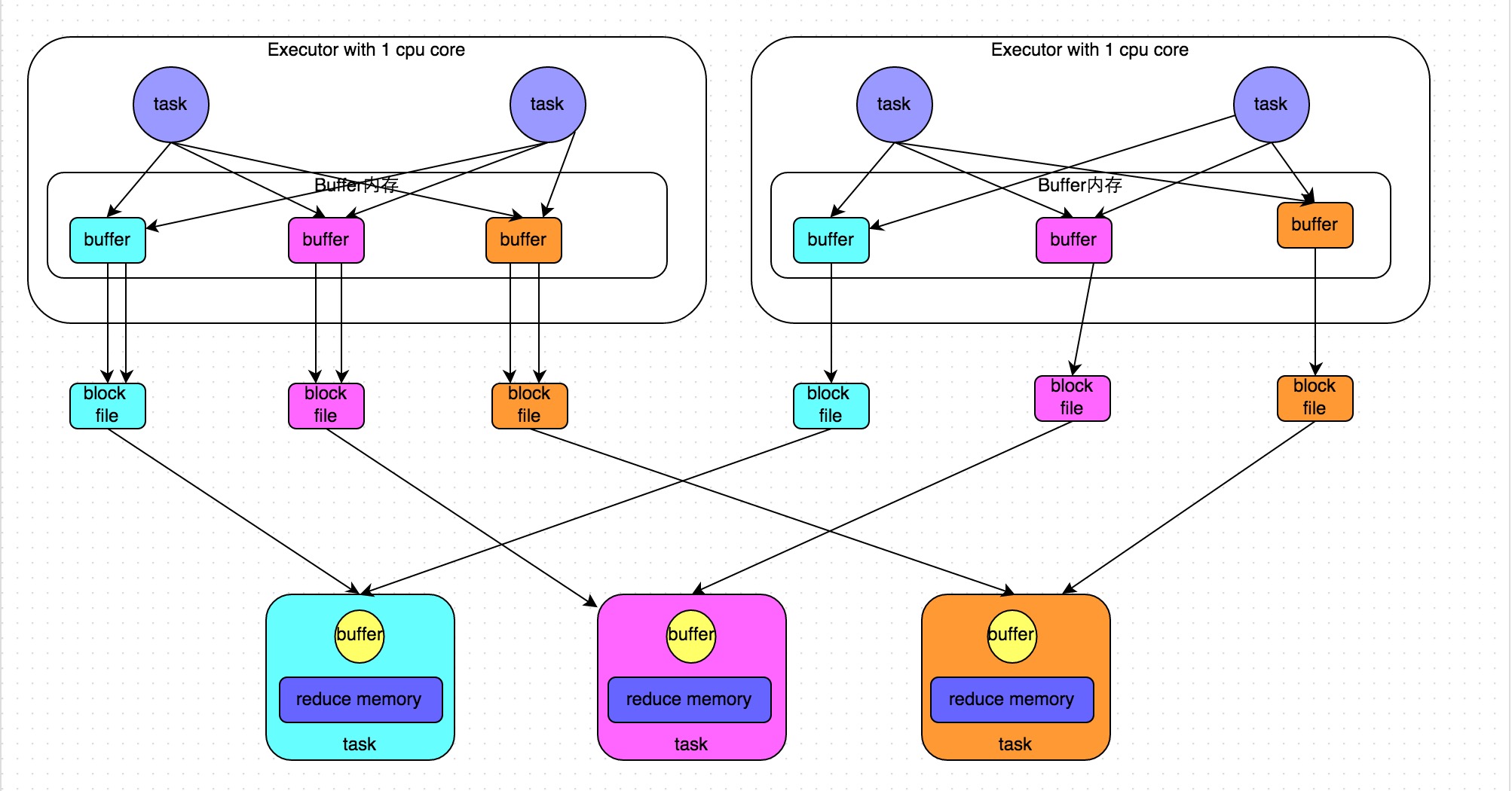
现在 ShuffleManager接口只有一个实现类
- SortShuffleManager
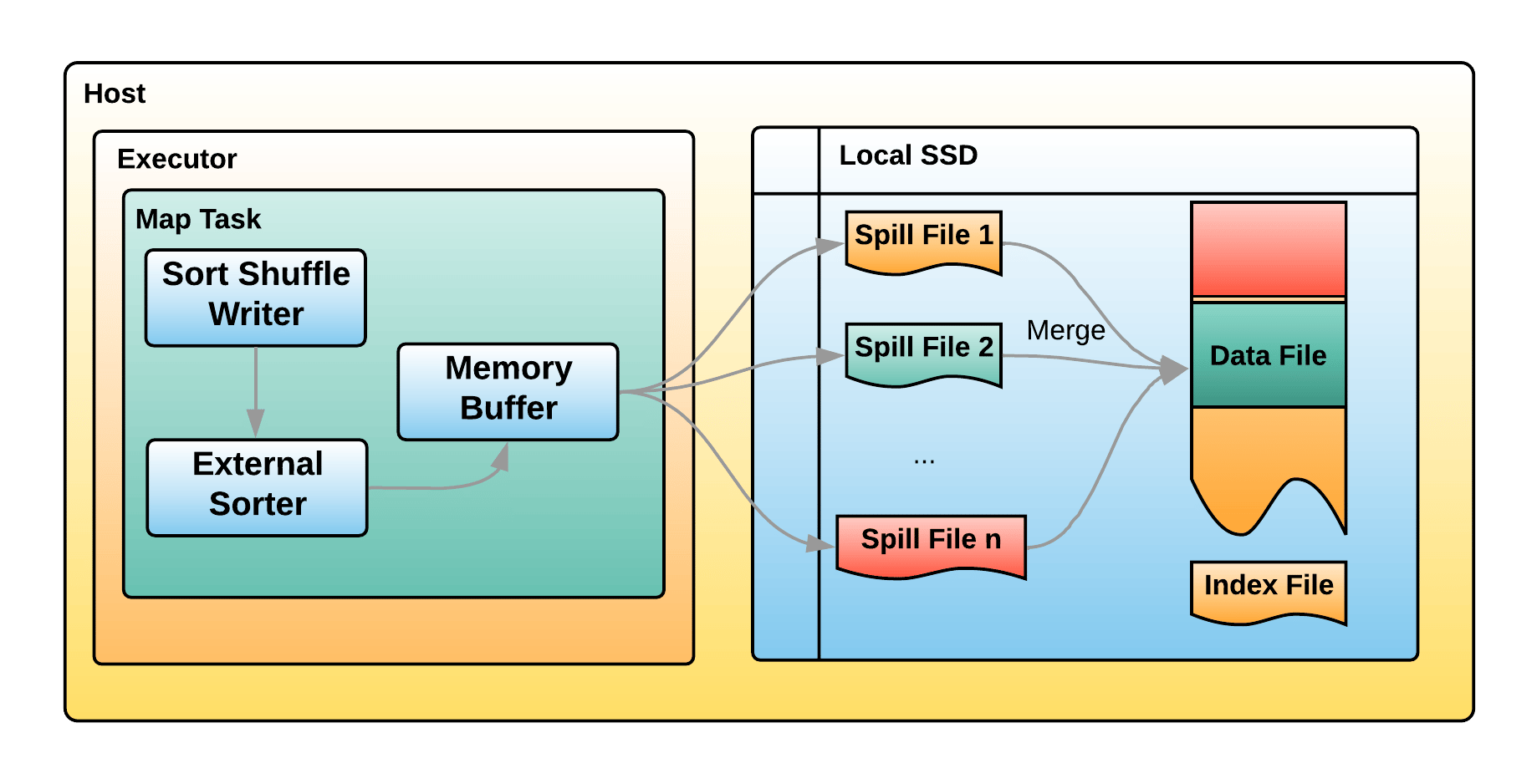
普通情况下,会先排序,再写文件,最后 merge,这样文件就很少了
为了方便下游 task read shuffle 的数据,还有一个 index 文件,记录了 key 对应文件的 offset
总的文件数量,就是每个 executor 上的 task 数量
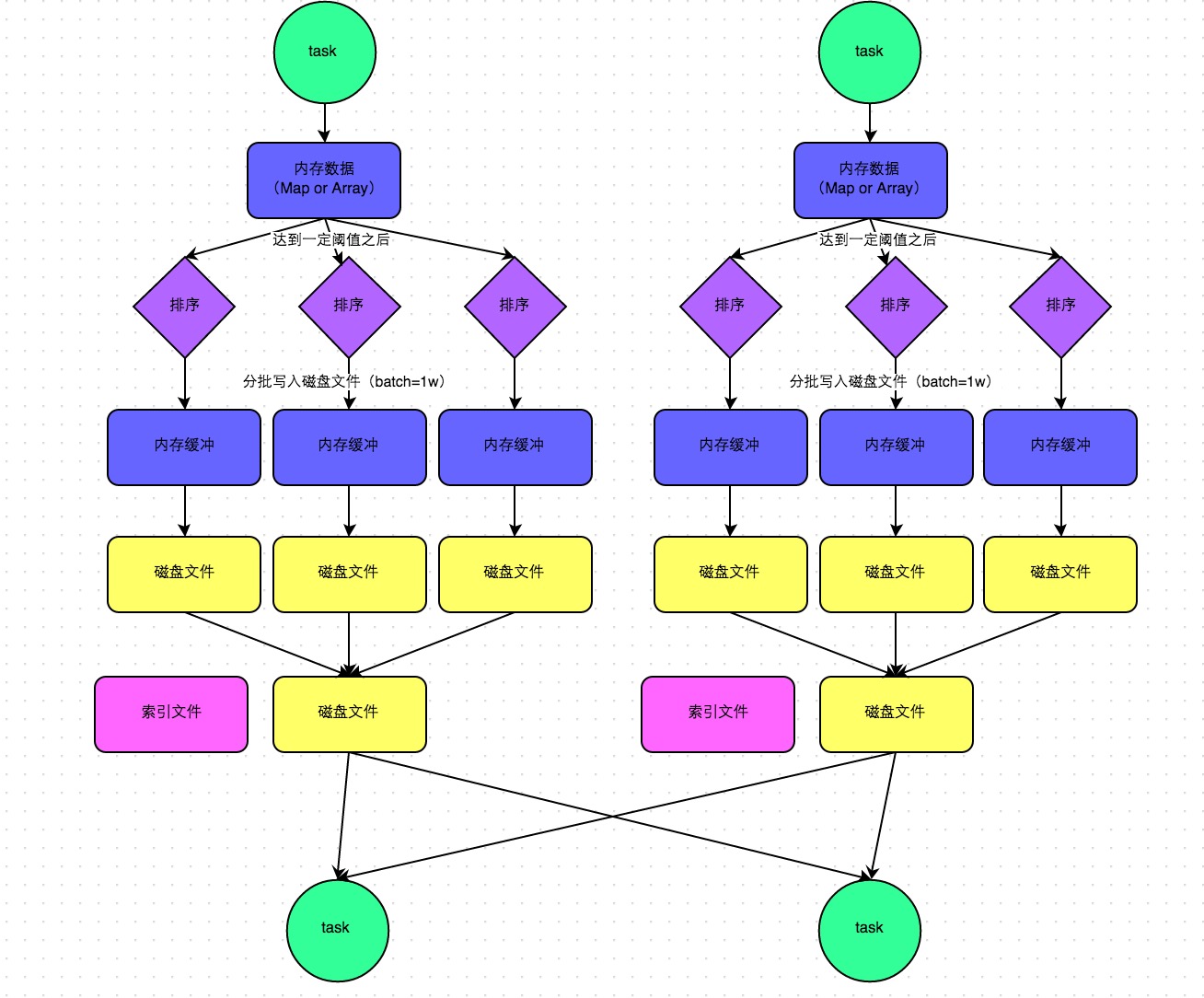
bypass 机制,最后也会merge 成一个文件,只是不做 sort 了,省了一些时间
源码层面优化
join优化
- bucked join
- colocate join
with 的优化
- 创建 自己的 with 逻辑计划
- 逻辑计划中的 查询做优化
- 转换成自定义的 物理计划
- 物理计划缓存
|
|
查询下推
- mysql_table_a JOIN mysql_table_b JOIN pg_table_c
- 可以将 mysql a,b 合并为一个 sql,下推到数据源
- 将spark的逻辑计划,转为 calcite 逻辑计划,再转换为数据源的 sql
自动倾斜 join 优化
- 需要一套元数据中心,通过元数据中心,获取数据源的信息
- 扩展 CBO,通过表数据量,可以做 join 的order 调整
- 扩展 优化规则,可能还需要一些物理计划
|
|
Limit大数量
Limit 一次性取 1亿条,limit 1亿非常慢
包括的Limit类型
- CollectLimitExec
- CollectTailExec
- BaseLimitExec
- LocalLimitExec
- GlobalLimitExec
执行过程
- 对于子RDD(上游RDD), 使用mapPartitionsInternal, 对每个partitions执行取前1亿行的操作
- 将第一步输出RDD进行shuffle, 混洗成一个单分区RDD(SinglePartition)
- 对单分区RDD再做一次取前1亿行的操作
- 建设分区 100个,每个分区都要取 1亿,再shuffle 到一个分区,再对这个分区取 1亿
优化
- 不要一次那么多
- sample 采样获取
- 每个分区 take少量一些,最后再汇总,limit
JOIN优化
bucked join
|
|
最后生成的物理计划,没有了exchange操作
|
|
4个大表 join问题
sql 执行过程,是前面两个 SMJ,然后跟 第三个 SMJ,再跟第四个 SMJ
整体的 DAG 是串行的
|
|
优化,数据量不变,但是并行度提高了
|
|
打印的物理计划看,不再是串行了,而是 1 join 2, 3 join 4,是并行的
最后 1,2 的结果 join 3,4 的结果
|
|
RSS
Uber 的 原始 shuffle 问题
- Hardware Reliability: Due to the large volumes of shuffle data being written to the SSD daily, Uber disks were worn out faster than the initial design. Instead of being sustained for three years, the disk at Uber wears out in 6 months.
- Shuffle failure: when the reducer fetches the data from all mapper tasks on the same machine, the service becomes unavailable, which causes a lot of shuffle failures.
- Noisy Neighbor Issue: An application that writes more significant shuffle data will potentially take all the disk space volume in the machine, which causes other applications on this machine to fail due to disk full exceptions.
- Shuffle Service Unreliability: Uber user external shuffle service in YARN and Mesos for Spark. They often experienced the shuffle service being unavailable in a set of nodes.
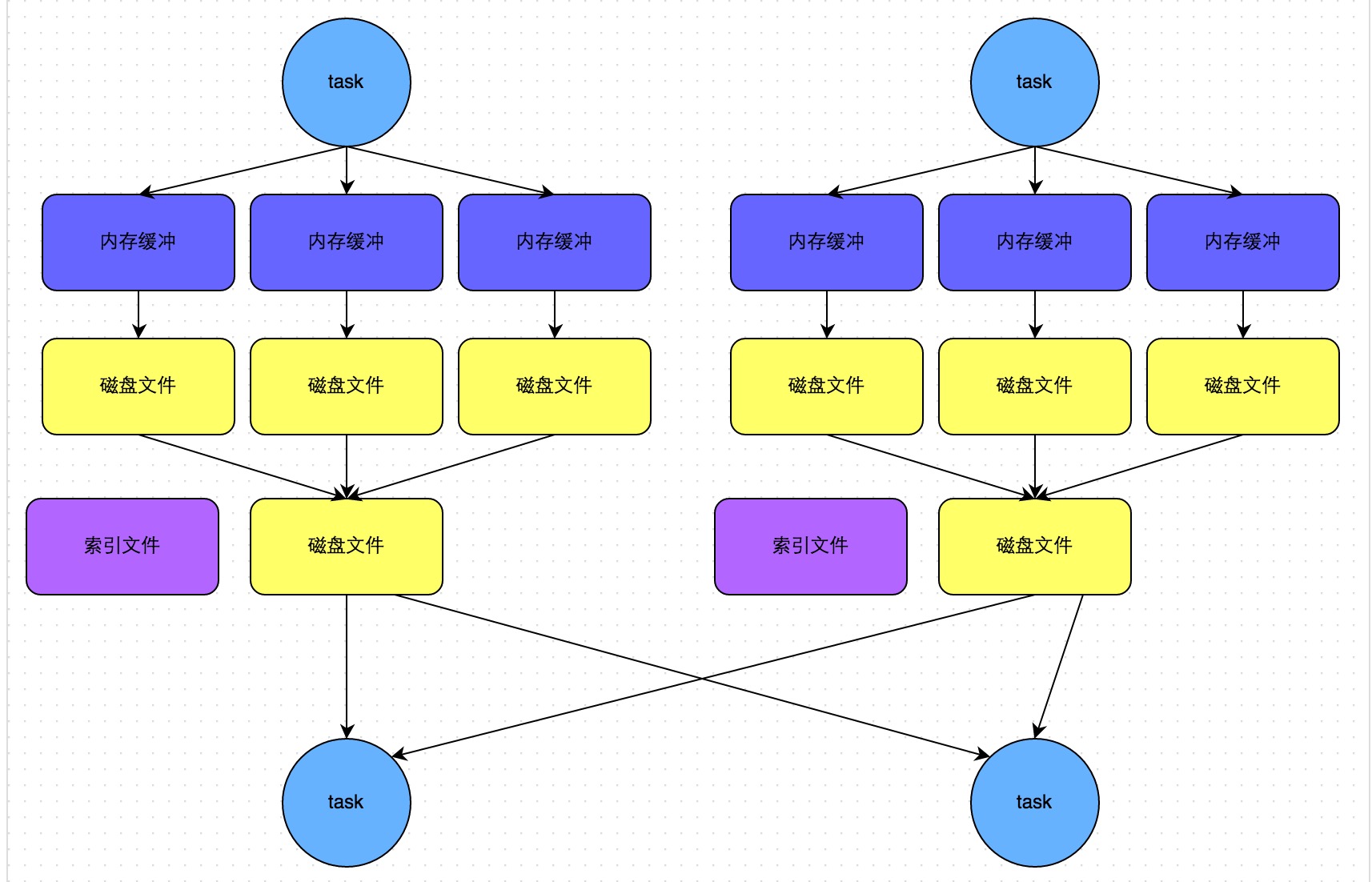
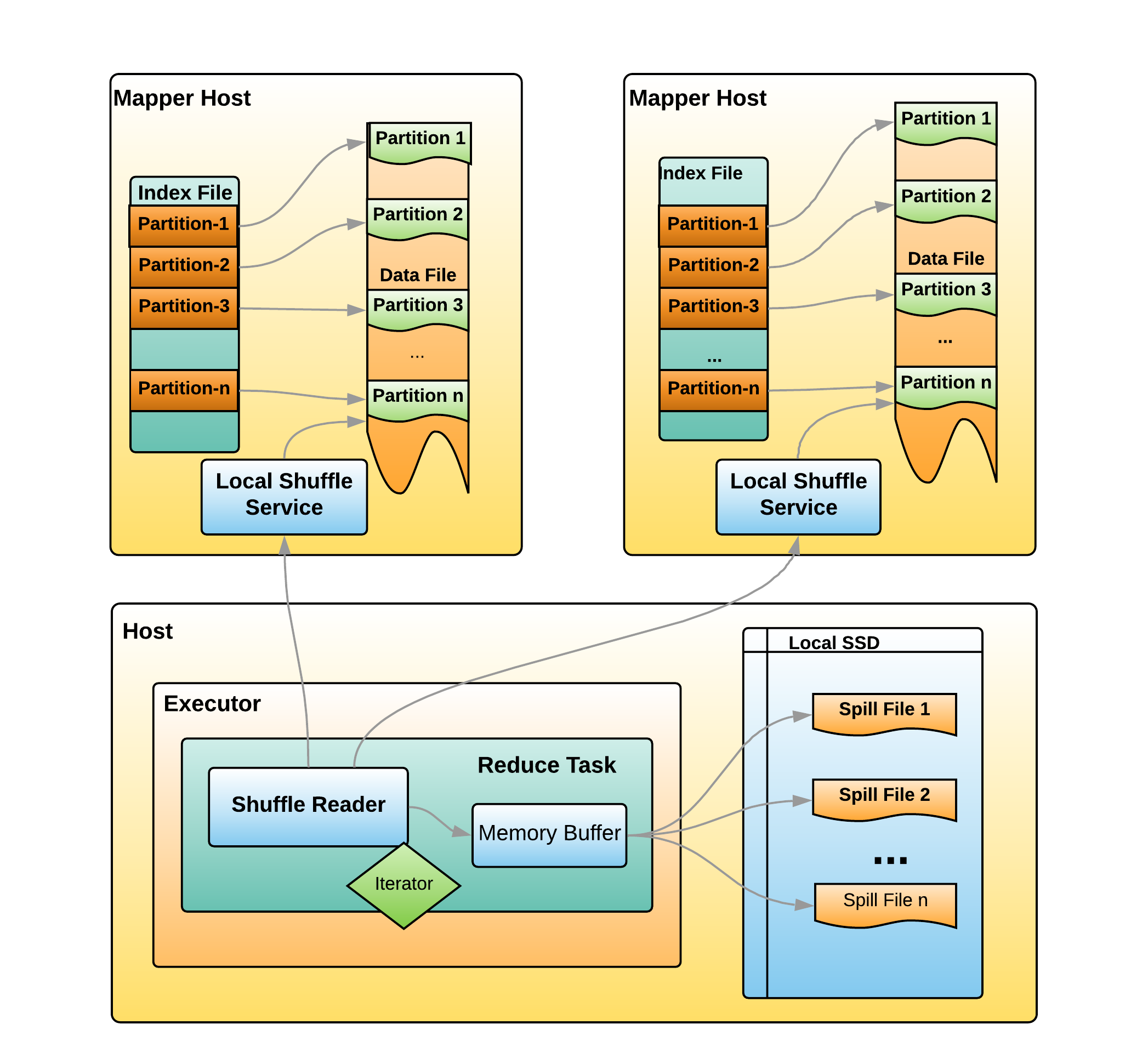
普通的 shuffle 调用过程
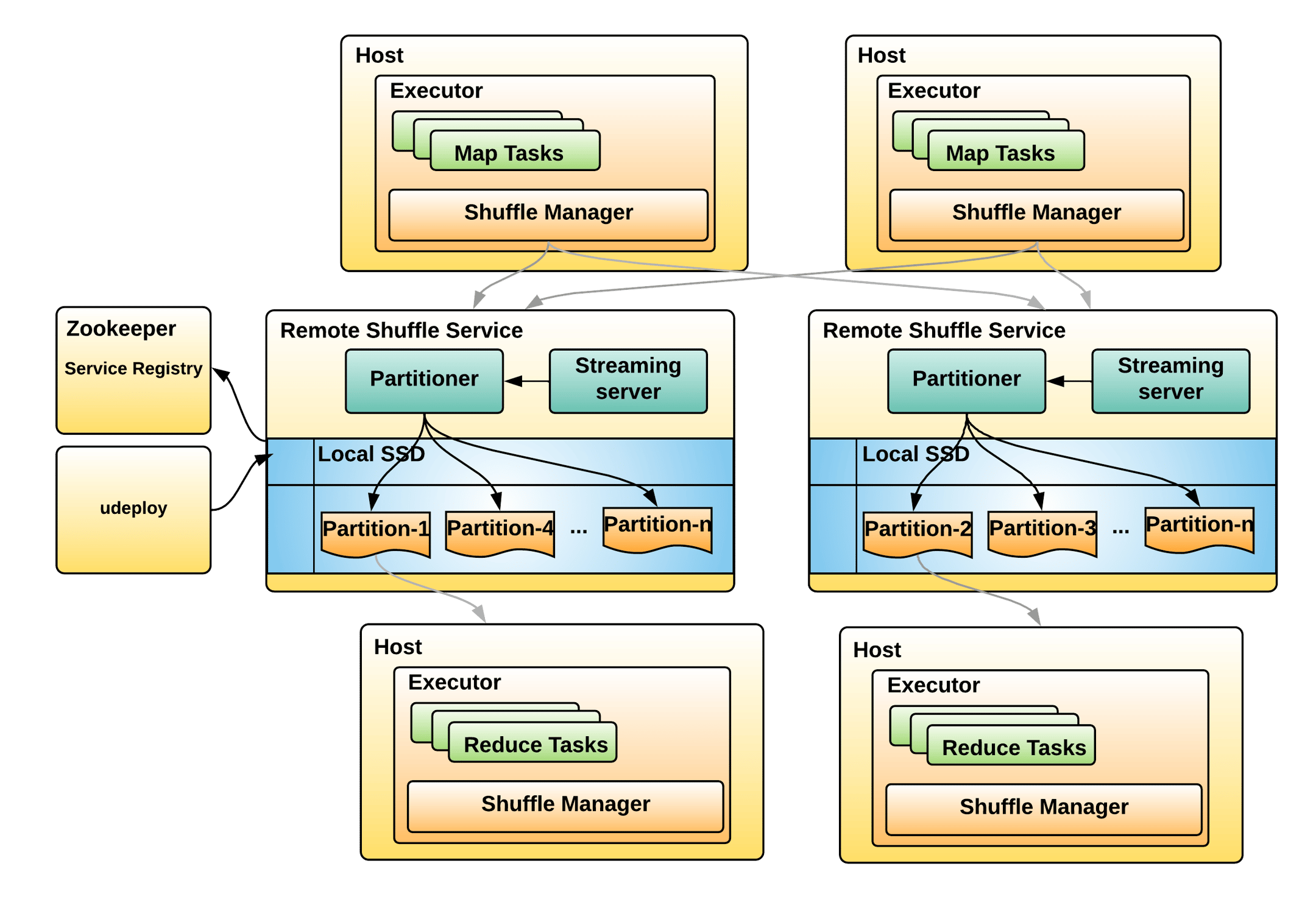
Uber 的 RSS 架构
- 先将 RSS服务注册到 ZK 上,driver根据负载情况选择 RSS 服务
- mapper 将相同的分区直接写到固定的 RSS 上,reducer 也去指定的 RSS 上获取
- 这样 reducer 就只需要跟一个 RSS通讯
- 为保持高可用,mapper可以写多个 RSS机器
参考
- Tuning Spark
- Spark性能调优实战
- Spark性能优化指南——基础篇
- Spark性能优化指南——高级篇
- Spark向量化计算在美团生产环境的实践
- 美团大规模KV存储挑战与架构实践
- 大数据 SQL 性能调优
- 国产化大数据,Hadoop该如何应对
- spark硬核优化1 布隆过滤器大join优化
- Spark 优化 | 京东 Spark 基于 Bloom Filter 算法的 Runtime Filter Join 优化机制
- [WIP][SPARK-32268][SQL] Bloom Filter Join
- 第四范式 OpenMLDB: 拓展 Spark 源码实现高性能 Join
- Optimize Join operation using Bucketing in Apache Spark
- pyspark.sql.DataFrameWriter.bucketBy
- Quickstart: Spark Connect
- Parquet Files
- What: All About Bucketing and Partitioning in Spark
- How does Uber handle petabytes of Spark shuffle data every day?
- Apache Celebron
- Apache Gluten
- facebook volex
- Uber RemoteShuffleService
- I spent 6 hours learning how Apache Spark plans the execution for us
- Uber’s Highly Scalable and Distributed Shuffle as a Service
- Peloton: Uber’s Unified Resource Scheduler for Diverse Cluster Workloads