ES的简单学习
基本概念
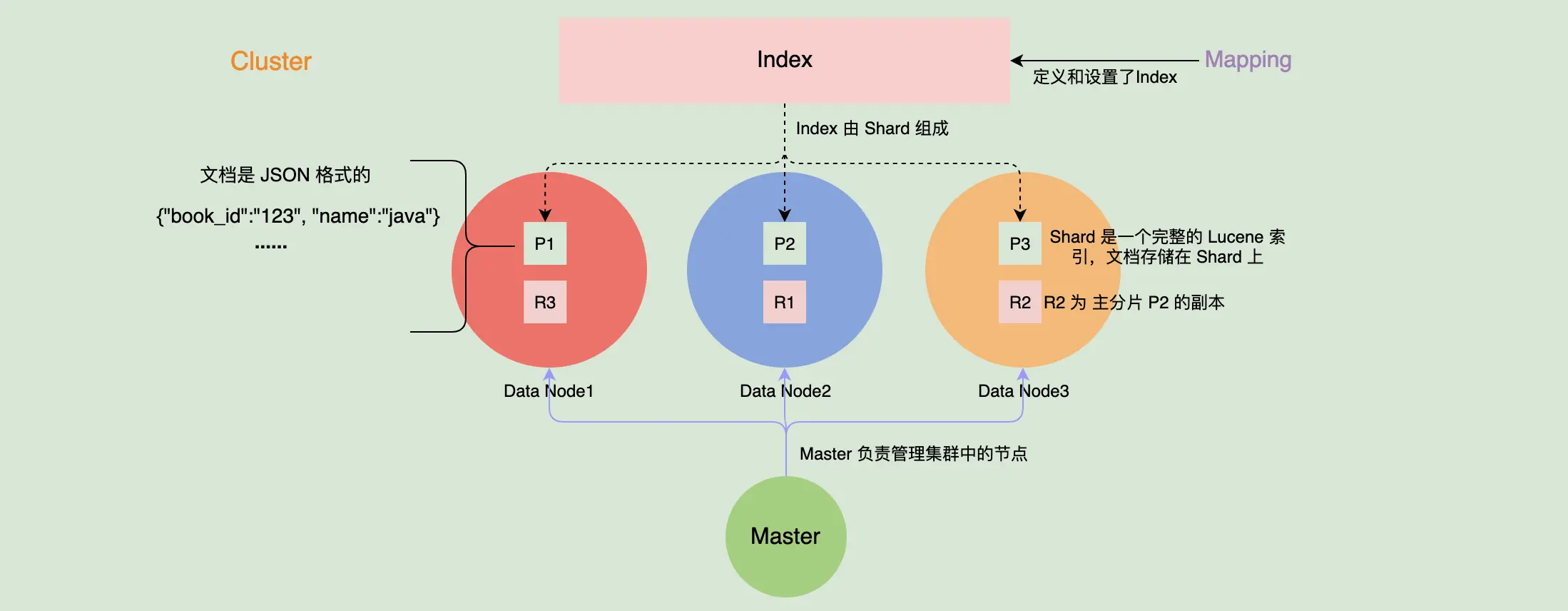
节点
- 主节点(Master),负责管理集群变更、元数据的更改
- 数据节点(Data Node),搜索、聚合、CURD 等
- 协调节点(Coordinating Node),负责接受客户端的请求,将请求路由到对应的节点进行处理
- 预处理节点(Ingest Node)
分片
- 主分片(primary shard)和副分片(replica shard)
- 分片数量是固定的
索引(Index)
- 一个索引由多个分片组成
- 一个分片由多个 segment 组成
- Mapping 定义了索引里的文档到底有哪些字段及这些字段的类型
- 向 ES 中写入的每一条数据都是一个文档(类似数据库中的一条记录)
- 搜索也是以文档为单位的
- 字段
- 词项(Term)
- 倒排索引与正排索引
查询
Term 是文本经过分词处理后得出来的词项,是 ES 中表达语义的最小单位
- Term Query,返回在指定字段中准确包含了检索内容的文档。
- Terms Query,跟 Term Query 类似,不过可以同时检索多个词项的功能。
- Range Query,范围查询。
- Exist Query,返回在指定字段上有值的文档,一般用于过滤没有值的文档。
- Prefix Query,返回在指定字段中包含指定前缀的文档。
- Wildcard Query,通配符查询。
组合查询
- Bool Query,布尔查询,可以组合多个过滤语句来过滤文档。
- must,查询的内容必须在匹配的文档中出现,并且会进行相关性算分。简单来说就是与 AND 等价。
- filter,查询的内容必须在匹配的文档中出现,但不像 must,filter 的相关性算分是会被忽略的。因为其子句会在 filter context 中执行,所以其相关性算分会被忽略,并且子句将被考虑用于缓存。简单来说就是与 AND 等价。
- should,查询的内容应该在匹配的文档中出现,可以指定最小匹配的数量。简单来说就是与 OR 等价。
- must_not,查询的内容不能在匹配的文档中出现。与 filter 一样其相关性算分也会被忽略。简单来说就是与 NOT 等价。
- Boosting Query,在 positive 块中指定匹配文档的语句,同时降低在 negative 块中也匹配的文档的得分,提供调整相关性算分的能力。
- constant_score Query,包装了一个过滤器查询,不进行算分。
- dis_max Query,返回匹配了一个或者多个查询语句的文档,但只将最佳匹配的评分作为相关性算分返回。
- function_score Query,支持使用函数来修改查询返回的分数。
- script_score:利用自定义脚本完全控制算分逻辑。
- weight:为每一个文档设置一个简单且不会被规范化的权重。
- random_score:为每个用户提供一个不同的随机算分,对结果进行排序。
- field_value_factor:使用文档字段的值来影响算分,例如将好评数量这个字段作为考虑因数。
- decay functions:衰减函数,以某个字段的值为标准,距离指定值越近,算分就越高。例如我想让书本价格越接近 10 元,算分越高排序越靠前。
Suggesters API
- Term Suggester:基于单词的纠错补全。
- Phrase Suggester:基于短语的纠错补全。
- Completion Suggester:自动补全单词,输入词语的前半部分,自动补全单词。
- Context Suggester:基于上下文的补全提示,可以实现上下文感知推荐。
ES 中聚合的类型主要有以下 3 种
- Metric Aggregations: 提供求 sum(求总和)、average(求平均数) 等数学运算,可以对字段进行统计分析。
- Bucket Aggregations:对满足特定条件的文档进行分组,例如将 A 出版社的书本分为一组,将 B 出版社的书本分为一组,类似于 SQL 里的 Group By 功能。
- Pipeline Aggregations:对其他聚合输出的结果进行再次聚合
字段类型
原理
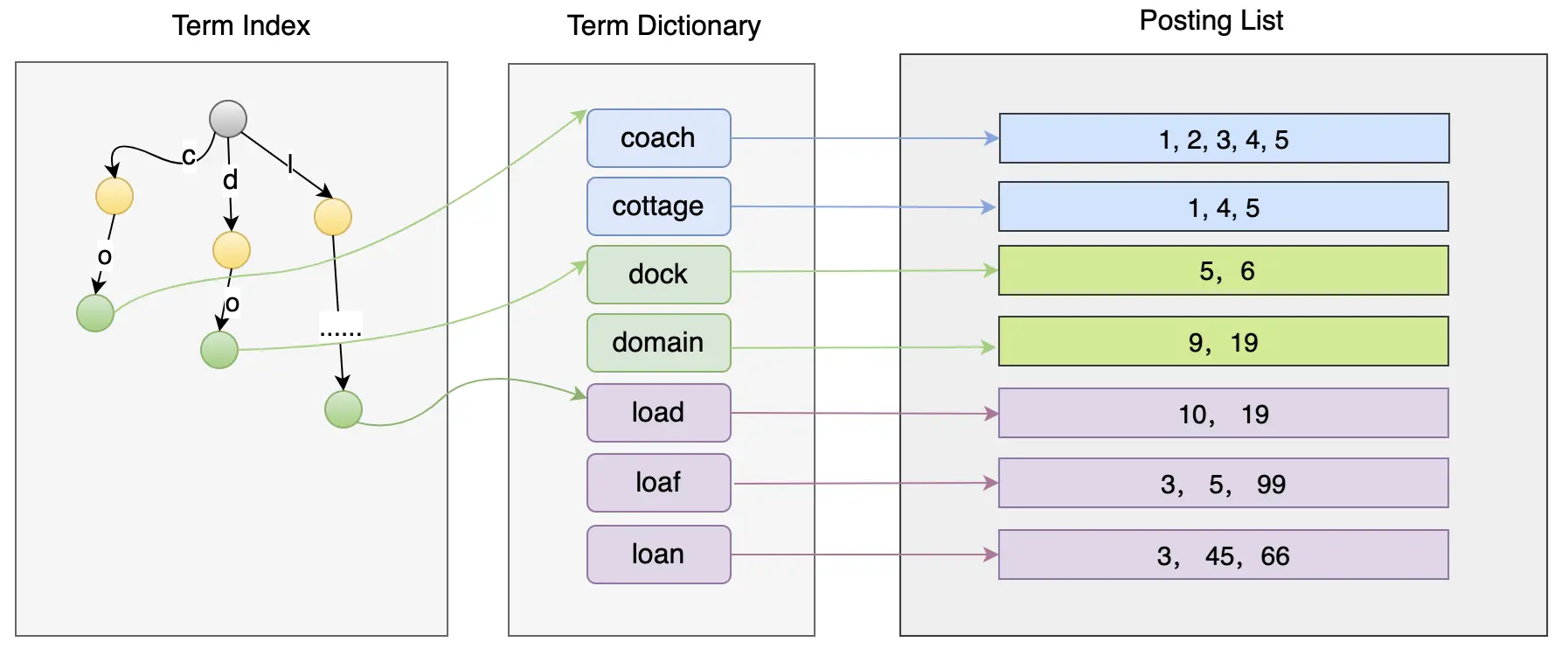
倒排索引
- term dictionary存储分词后的关键词
- posting list 是文档的 id
- 当 term dictionary 变得很大后,还需要索引,也就是 term index
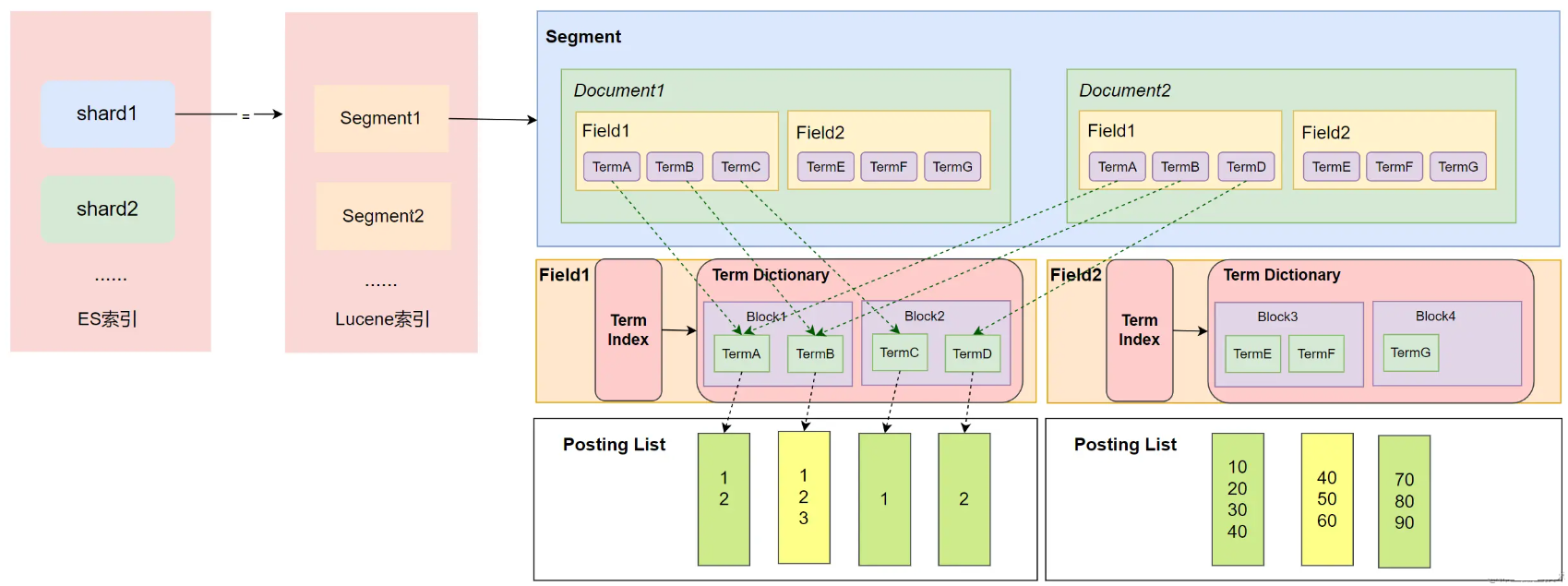
Lucene的结构
- 一个shared 包含多个 segment,而一个segment中包含了多个 document
- document中包含了多个filed,field 类似数据库表中的字段,filed有name 和类型
- 每个filed都有独立的索引,这个索引就是上面的倒排索引结构
term index
- 这里使用的是前缀的方式,压缩了空间
- 类似与前缀树,但用是 FST 算法来解决
- FST(Finite State Transducers)是一种 FSM(Finite State Machines,有限状态机)

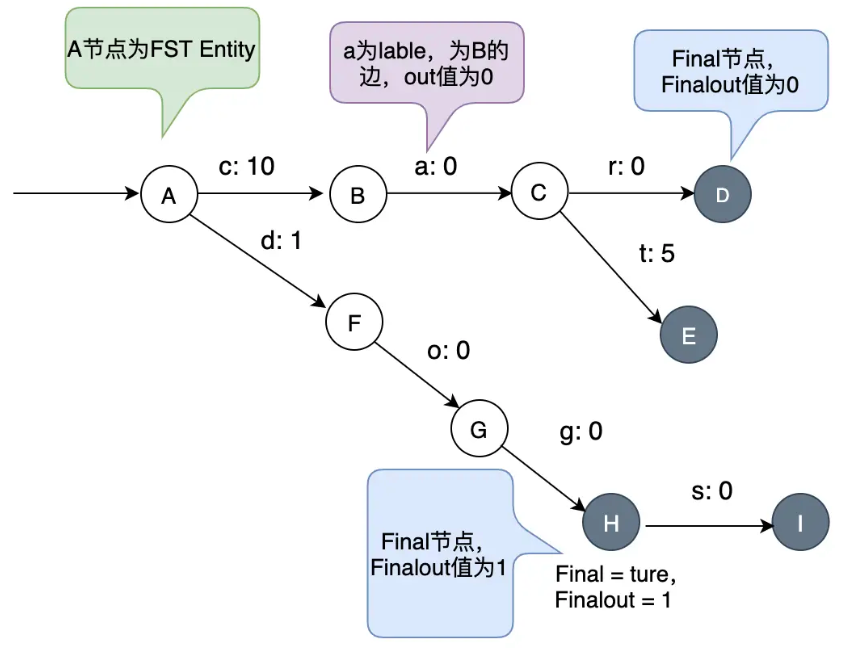
FST
- 通过对 Term Dictionary 数据的前缀复用,压缩了存储空间
- 高效的查询性能,O(len(prefix))的复杂度
- 构建后不可变
- 如下:访问cat为 10 + 0 + 5 + 0 = 15
- 访问 dog:需要加上 g 的 Finalout:1 + 0 + 0 + 1 = 2
- 相当于:占用空间小且高效的 Key-Value 数据结构
- 快速试错,如果在 FST 上不存在,不需要再遍历整个 Term Dictionary;
- 快速定位到 Block 的位置,经过 FST 的输出,可以算出 Block 在文件中的位置
Posting List 的实现
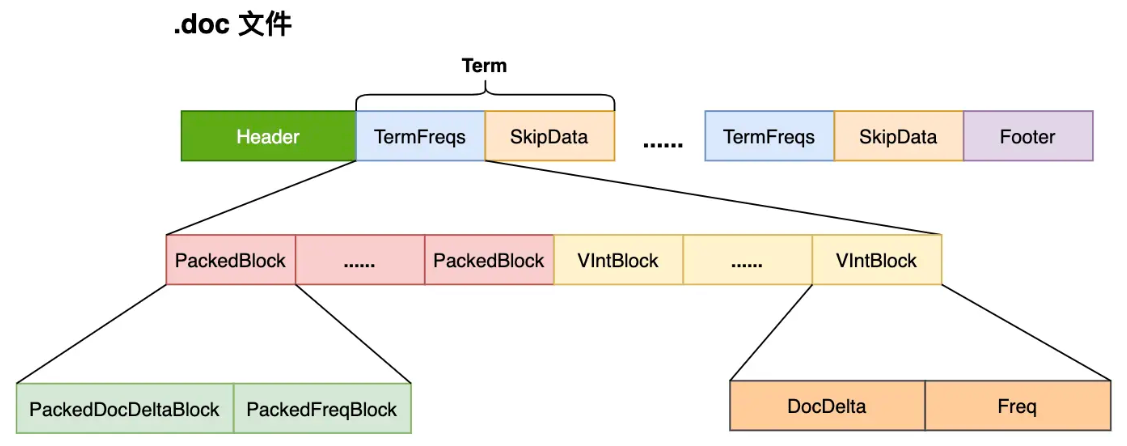
Lucene 把这些数据分成 3 个文件进行存储
- .doc 文件,记录了文档 ID 信息和 Term 的词频,还额外记录了跳跃表的信息,用来加速文档 ID 的查询;并且还记录了 Term 在 pos 和 pay 文件中的位置,有助于进行快速读取
- .pay 文件,记录了 Payload 信息和 Term 在 doc 中的偏移信息
- .pos文件,记录了 Term 在 doc 中的位置信息
Posting List 主要面临着两个问题:
- 如何节省存储?
- 如何快速做交集?
编码格式
- PackedBlock,小于128bit固定长度
- VIntBlock
- 差值编码,delta方式存储
使用 PackedBlock 与 VIntBlock 来解析 .doc 文件
- Lucene 在处理文档的时候,每处理 128 篇文档就会将其对应的文档 ID 数组(docDeltaBuffer)和词频(TermFreq)数组(freqBuffer)
- 处理为两个 Block:PackedDocDeltaBlock 和 PackedFreqBlock
- 使用 PackedInts 类对数据进行压缩存储,生成一个 PackedBlock
- 不足 128 篇文档的数据采用 VIntBlock 来存储
- 在生成 PackedBlock 的时候,会生成跳表(SkipData),使得在读取数据时可以快速跳到指定的 PackedBlock
Roaring Bitmaps
- 用来求两个元素是否都匹配,求交集
- 高 16 位作为一个数值存储到有序数组里
- 低 16 位则存储到 2^16 的位图中去,将对应的位置设置为 1
- 高位使用二分查找,低为使用传统 bitmap 查询
- 如果某个块的 bit很少,直接换成普通数组
还是用了 跳表来 求交集
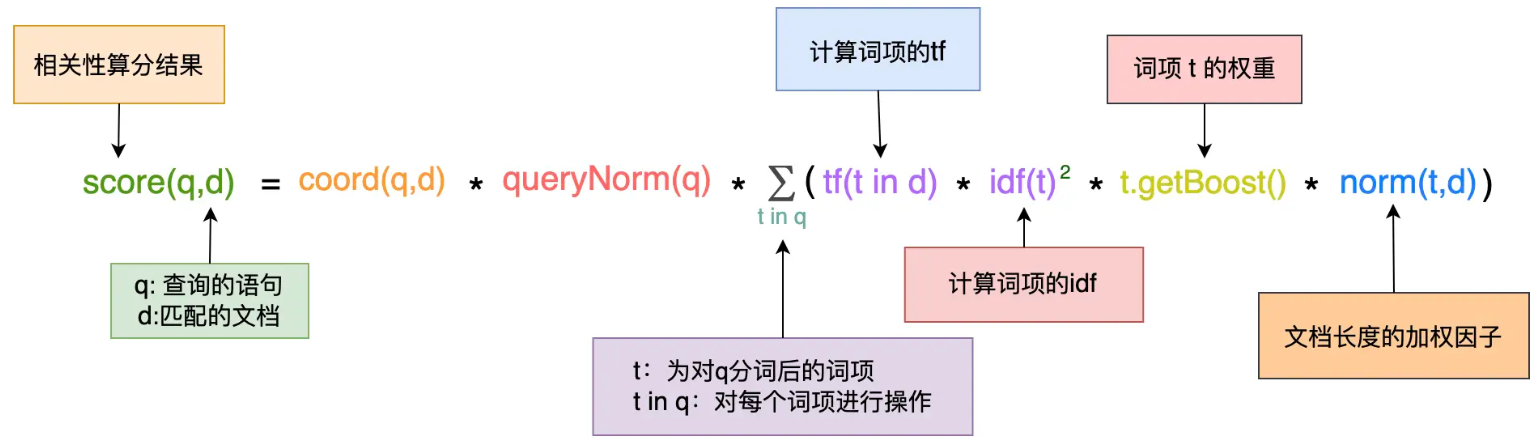
相关性评分
- TF-IDF (Term Frequency-inverse Document Frequency)
TF-IDF
- 一个词的重要程度跟它在一篇文章中出现的频率成正比
- 跟它在语料库中出现的频率成反比
- TF (Term Frequency On Per Document)表示一个词在一篇文档中出现的频率,值越大越重要
- DF(Document Frequency)表示词项在语料库中出现的频率,值越大就不重要
- IDF(Inverse Document Frequency)表示逆文档频率,值越高越稀有
- tf-idf 本质上是对 TF 进行了加权计算,而这个权重就是 IDF
java in linux” 这个查询,我们可以这样来计算每个匹配文档的得分
|
|
Lucene 的 TF-IDF 算分公式
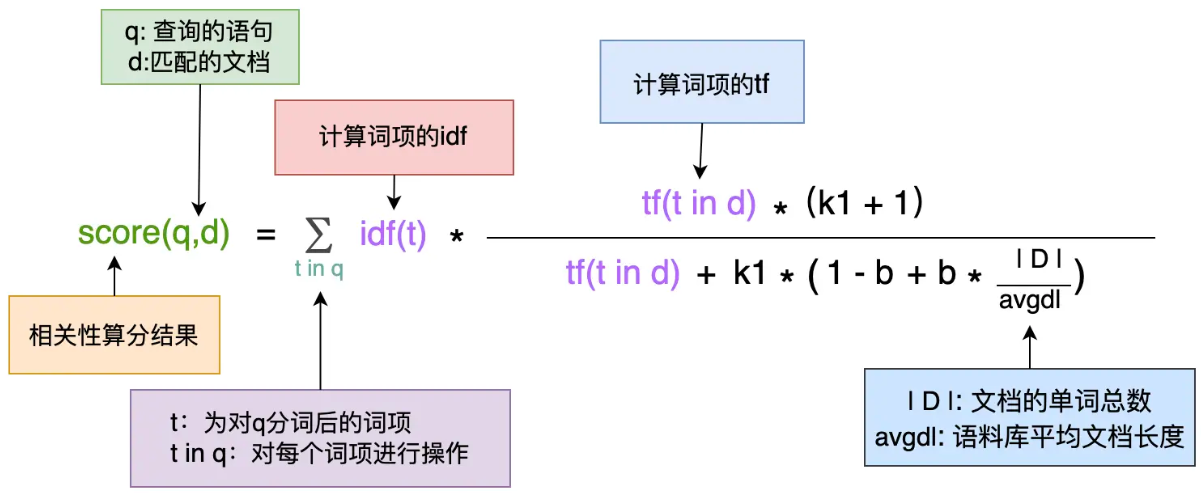
BM25 算分模型
- BM25 是基于词频的,它不会考虑多个搜索词项在文档里靠不靠近
- 只会考虑它们各自在文档中出现的次数
分词器
- Character Filter:主要对原文本进行格式处理,如去除 html 标签等
- Tokenizer:按照指定的规则对文本进行切分,比如按空格来切分单词,同时也负责标记出每个单词的顺序、位置以及单词在原文本中开始和结束的偏移量
- Token Filter:对切分后的单词进行处理,如转换为小写、删除停用词、增加同义词、词干化等
ES 为用户提供了多个内置的分词器
- Standard Analyzer : 这个是默认的分词器,使用 Unicode 文本分割算法,将文本按单词切分并且转为小写
- Simple Analyzer : 按照非字母切分并且进行小写处理
- Stop Analyzer : 与 Simple Analyzer 类似,但增加了停用词过滤
- Whitespace Analyzer : 使用空格对文本进行切分,并不进行小写转换
- Patter n Analyzer : 使用正则表达式切分
- Keyword Analyzer : 不进行分词
- Language Analyzer : 提供了多种常见语言的分词器
- Customer Analyzer:自定义分词器
ES 中的数据大致可以分为两种
- 全文本,例如短信的内容、文章内容等;
- 精确值,如实体 ID、日期等
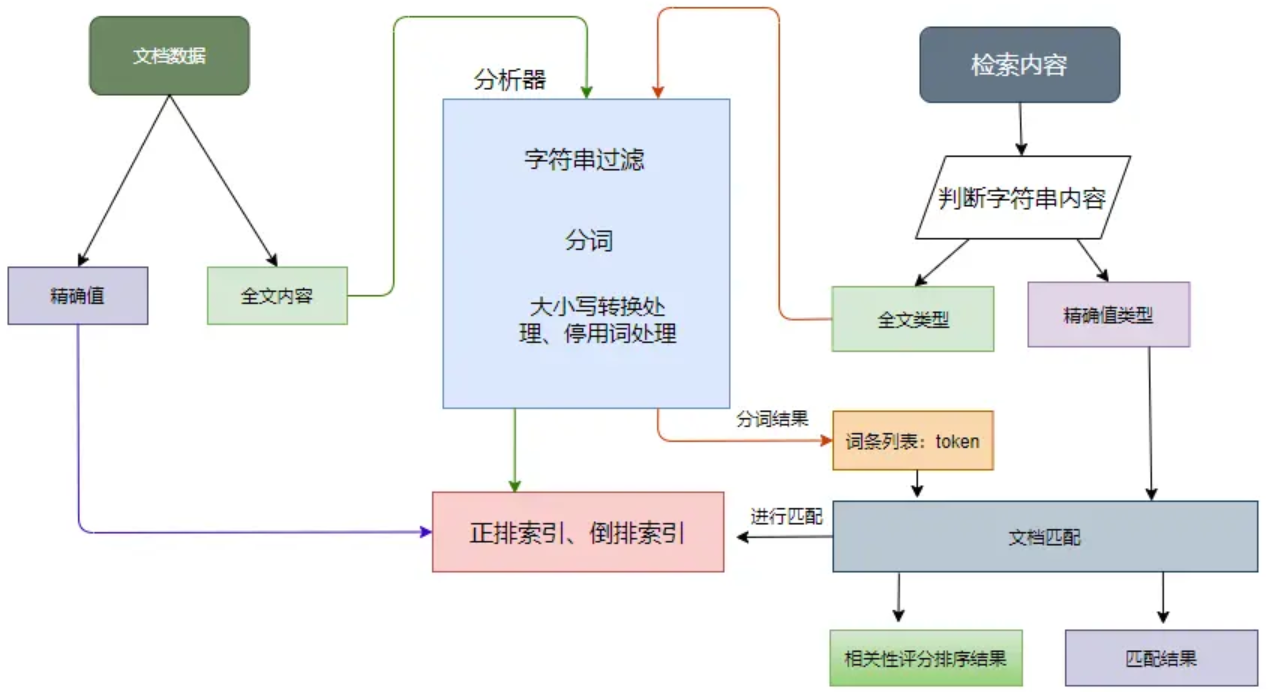
分析器的处理流程如下
- 先对字符串进行过滤,把一些 HTML、& 等字符处理掉;
- 分词器会将字符串按某些规律(空格、句号等)切分成单词,输出的这些单词为词条(token);
- 词条过滤器对切分后的词条进行过滤,例如过滤停用词(and、is 等),或者同义词转换等;
- 对过滤后的词条作进一步的处理,如小写转换、词根转换。
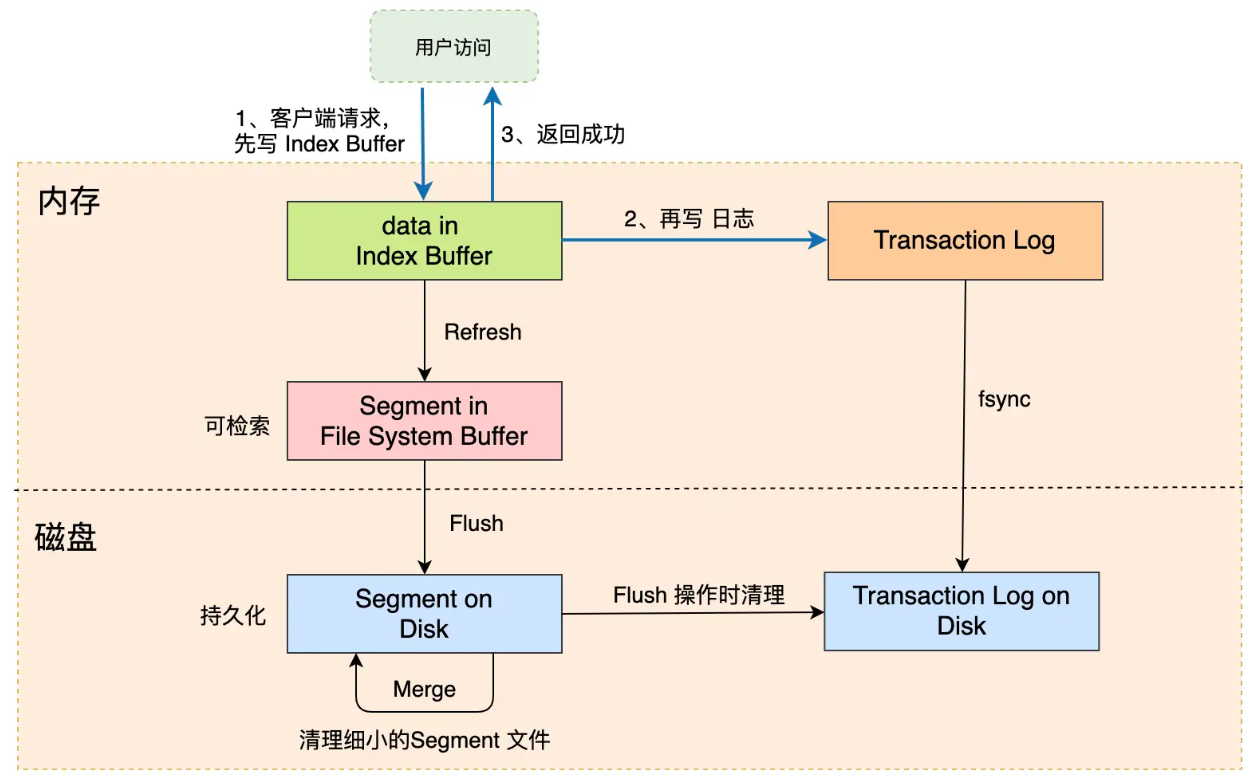
近实时搜索的原因:Refresh
- 数据先写到 buffer中,等到了阈值或者满了才刷盘
- 避免每次写入创建一个 segment
- 查询的时候最新写入的可能还没落盘,所以找不到
- Transaction Log 用来防止丢失,跟 WAL 类似
ES 提供了 3 种分页方式:
- from + size:最普通、简单的分页方式,但是会产生深分页的问题。
- search after:解决了深分页的问题,但只能一页一页地往下翻,不支持跳转到指定页数。
- scroll API:会创建数据快照,无法检索新写入的数据,适合对结果集进行遍历的时候使用
- Point In Time:PIT 是一个轻量级的数据状态视图,用户可以利用这个视图反复查询某个索引
Terms 聚合的结果不准的问题
- 数据进行了分片存储
- 每个分片的 top n 并不一定是全量数据的 top n
- 每个分片返回足够多的分组
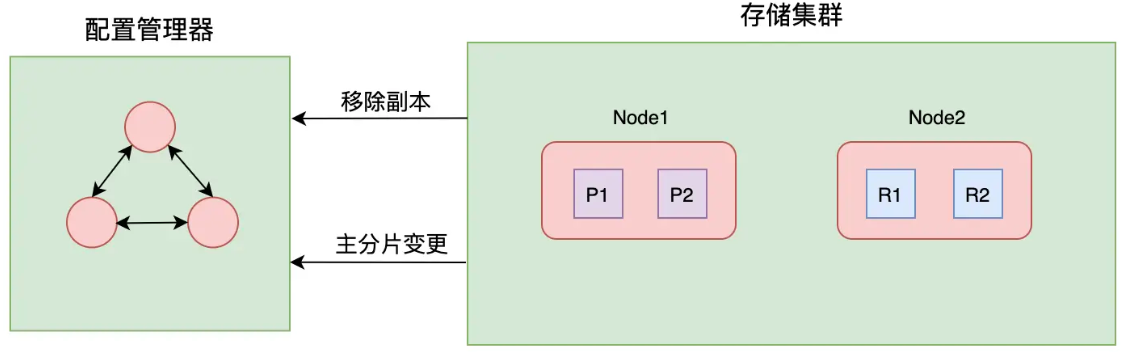
PacificA
- 微软提出的,ES 使用它来做主和从副本之间的同步
- 系统框架主要分为两个部分
- 配置管理器使用单独一个集群来管理,其维护了副本组(Replica Group)信息
- 数据存储集群主要负责数据的读写、复制等操作
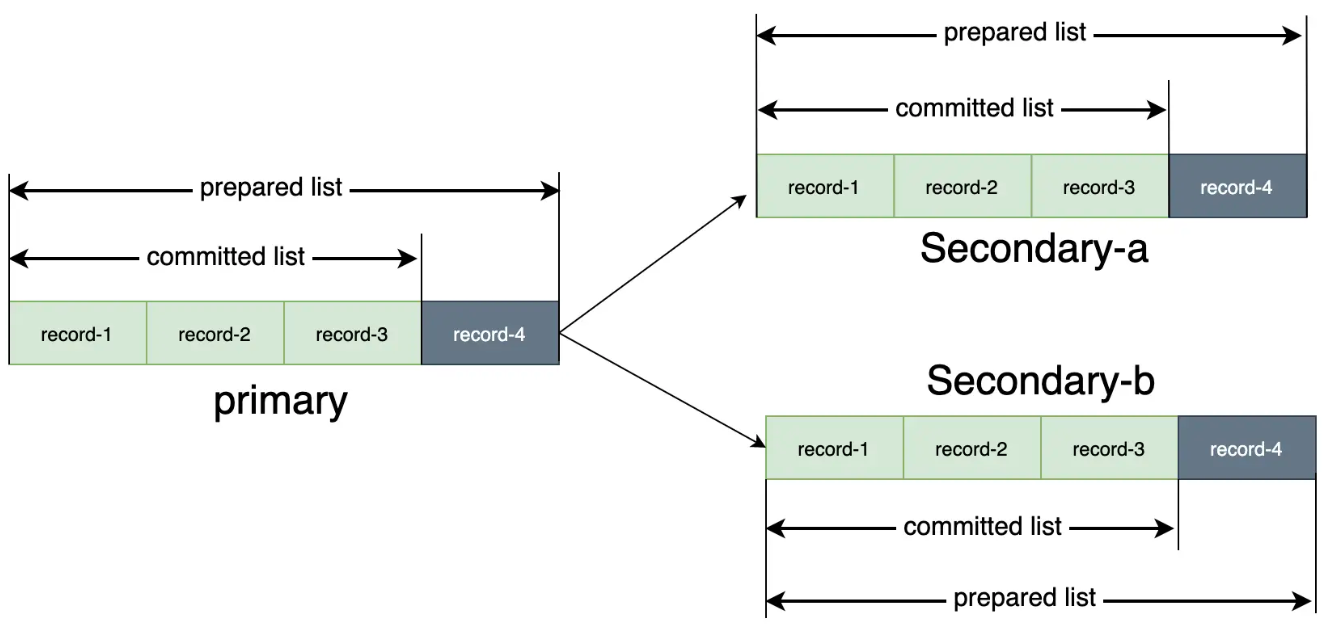
PacificA 的数据复制策略
- 主副本写入后,会将 SN 记录到 prepared list 中
- 发送写请求和 SN 给所有 从副本
- 从副本记录并返回给主副本
- 主副本返回给客户端
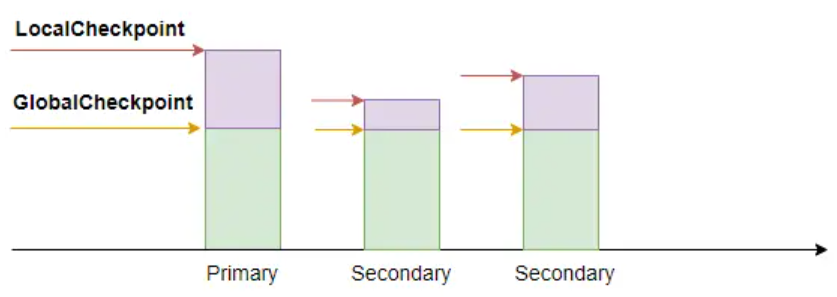
ES 使用本地检查点和全局检查点来标记从副本与主副本的差异
- 两个检查点的值就是上述提到的 Sequence ID
- 全局检查点(GlobalCheckpoint),是所有活跃分片历史都已经对齐、持久化成功的序列号
- 小于全局检查点的操作都已经在所有副本上处理完了
- 本地检查点(LocalCheckpoint),代表着本副本中所有小于这个值的操作都已经处理完毕了
- 有了全局检查点后,系统就可以实现增量数据复制了
更改集群配置(Reconfiguration)
- Primary 故障
- Secondary 故障
- 加入新节点
监控优化
集群管理
- Cluster REST API
- CAT,简化显示的 REST API
集群规划
- 基本架构,在协调节点前加一个 LB 实现请求的负载均衡。
- 读写分离架构,基于基本架构衍生出来的架构,将读写请求分别负载到读写 LB 处理。
- 跨机房部署机构,GTM 分发流量,使客户端实现就近读取数据。多个数据中心的集群互备
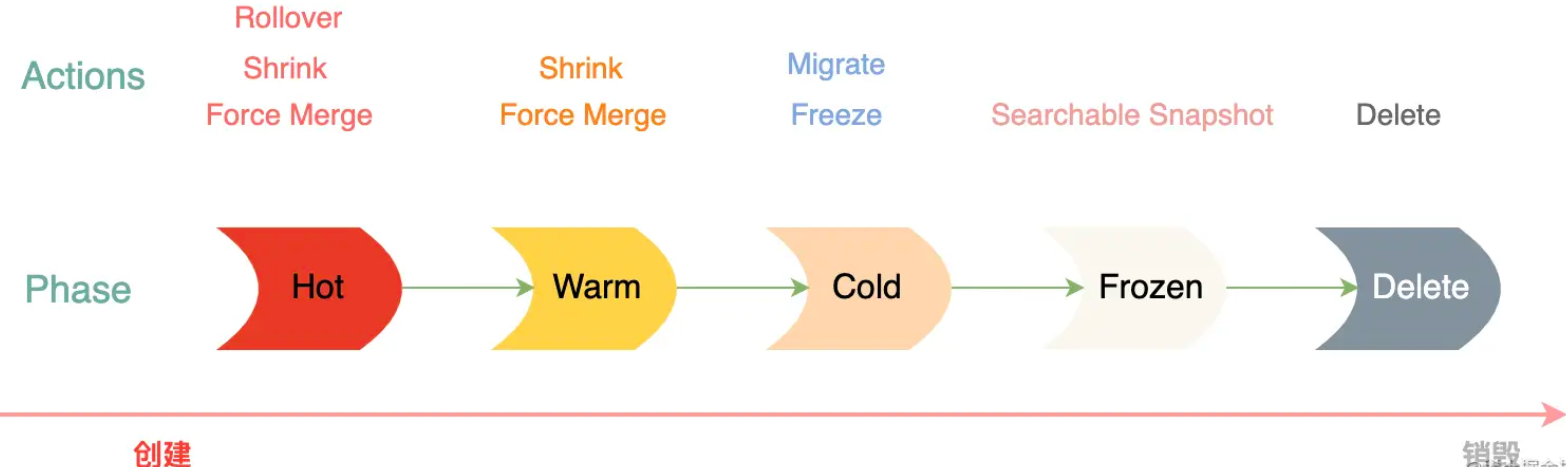
索引生命周期管理
索引管理
- 单个索引的创建、删除等
- 别名管理
- 索引设置
- mapping
- reindex
- 索引模版
- 收缩 index
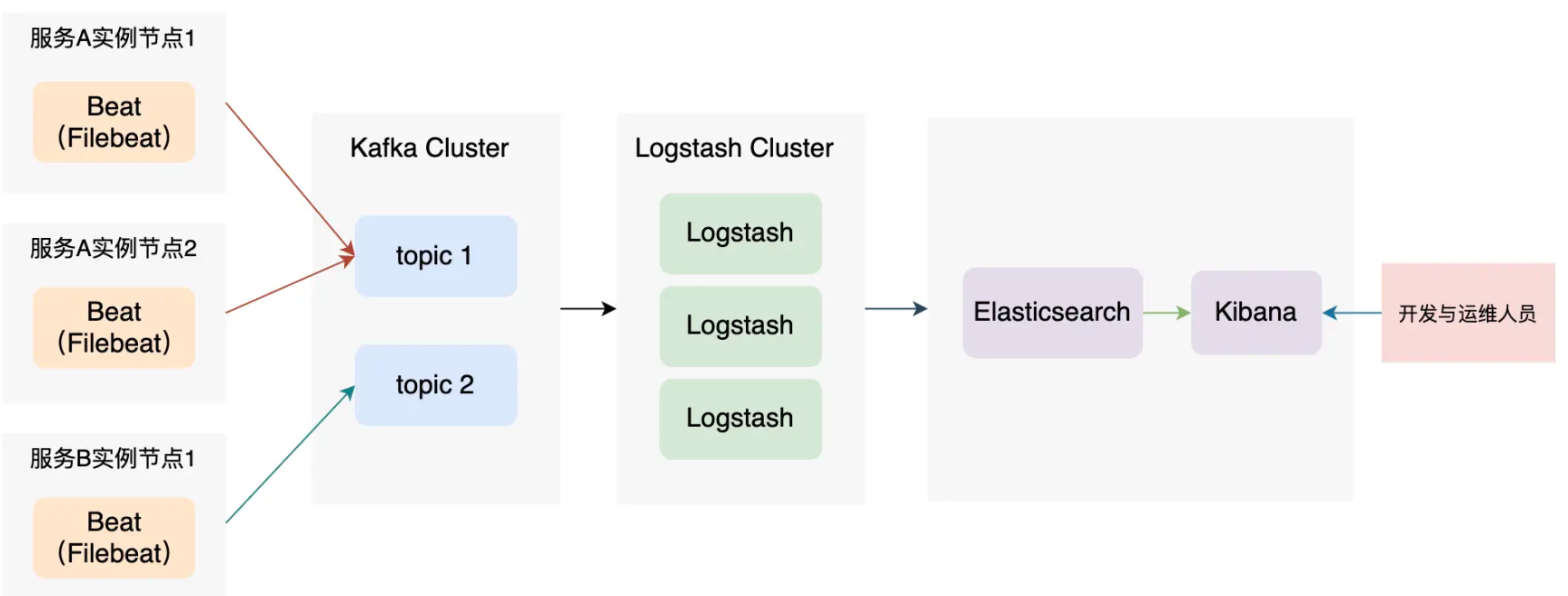
ELK 架构
ES 优化
- snaphost,备份,跨集群使用REST API来备份
- 索引生命周期管理,批量写入/更新,批量读取
- shared 分配和rebalance
- 慢查询日志,cpu/内存/磁盘/网络/负载/QPS,JVM 和 GC
- 使用 filter,_search_after而不是from+size
- 存储限流、调整刷新间隔,segment merge策略
- 监控指标:Indexing Rate、Latency、Refresh Rate和Time、Merge Time
- shared数量,大小,segment数量和大小,每个shared的文档count
相关算法和数据结构
算法
- 编辑距离(edit distance),用来做单词纠错、补全的
- 数据编码压缩算法
- TF-IDF、BM25评分模型
- 分词器
- PacificA 主副本同步策略
- raft 选主
数据结构
- 倒排索引
- Roaring Bitmaps
- skip list
- FST 前缀索引,前缀树
- transaction log