k8s 网络
K8S网络
覆盖网络
原理
- Container 1 Creates a TCP Packet
- Container 1 initiates a connection to Container 3.
- It creates a TCP packet, encapsulated within an IP packet:
- Source IP: Container 1’s IP (e.g.,
10.244.1.2) - Destination IP: Container 3’s IP (e.g.,
10.244.2.2)
- Source IP: Container 1’s IP (e.g.,
- Virtual Ethernet and Host’s Bridge
- The TCP packet is sent out via Container 1’s
eth0. - The packet travels through the virtual network interface (veth) to the host’s virtual bridge (managed by Flannel or a similar CNI plugin).
- At this point, the packet is treated as a Layer 2 Ethernet frame.
- Flannel VXLAN Processing on Host 1
- Flannel running in kernel space intercepts the packet and determines that the destination IP (
10.244.2.2) is on a different host (Host 2).
VXLAN Encapsulation:
-
Flannel creates a new outer UDP packet that encapsulates the original TCP packet.
-
The outer packet includes:
- Outer Ethernet Header: MAC address of Host 2.
- Outer IP Header:
- Source: Host 1’s physical IP.
- Destination: Host 2’s physical IP.
- Outer UDP Header: Used for VXLAN tunneling.
- VXLAN Header: Contains the VXLAN network identifier (VNI) to map the packet to the correct virtual network.
- Inner Ethernet and IP Headers: The original Layer 2 and Layer 3 information for Container 3.
-
All of this encapsulation happens in kernel space, avoiding costly user space operations.
- Packet Transmission Across the Physical Network
- The encapsulated packet is sent through the physical network interface (
eth0) on Host 1. - It travels over the physical network, appearing as a standard IP packet between Host 1 and Host 2.
- Flannel VXLAN Processing on Host 2
- When the encapsulated packet arrives at Host 2, it is intercepted by Flannel in kernel space.
- Flannel decapsulates the packet:
- Strips off the outer Ethernet, IP, UDP, and VXLAN headers.
- Retrieves the original inner packet with Container 3’s destination IP (
10.244.2.2).
- Packet Delivery to Container 3
- The decapsulated packet is passed to the veth interface of Container 3.
- Container 3 processes the packet as if it had been sent directly from Container 1, unaware of the underlying encapsulation and routing.
Flannel
Flannel 早期的方案,基于 UDP,仅发送就需要三次内核态、用户态切换
- pod 通过 veth 发到 docker0 网桥
- 网桥进入到 桥接内核态,内核态转到 flannel 用户态进程
- 用户态进程检查网络发送的路由信息,找到目标转发信息
- 交给内核态做数据包转发

新的方案,基于 vxlan,全部是内核态
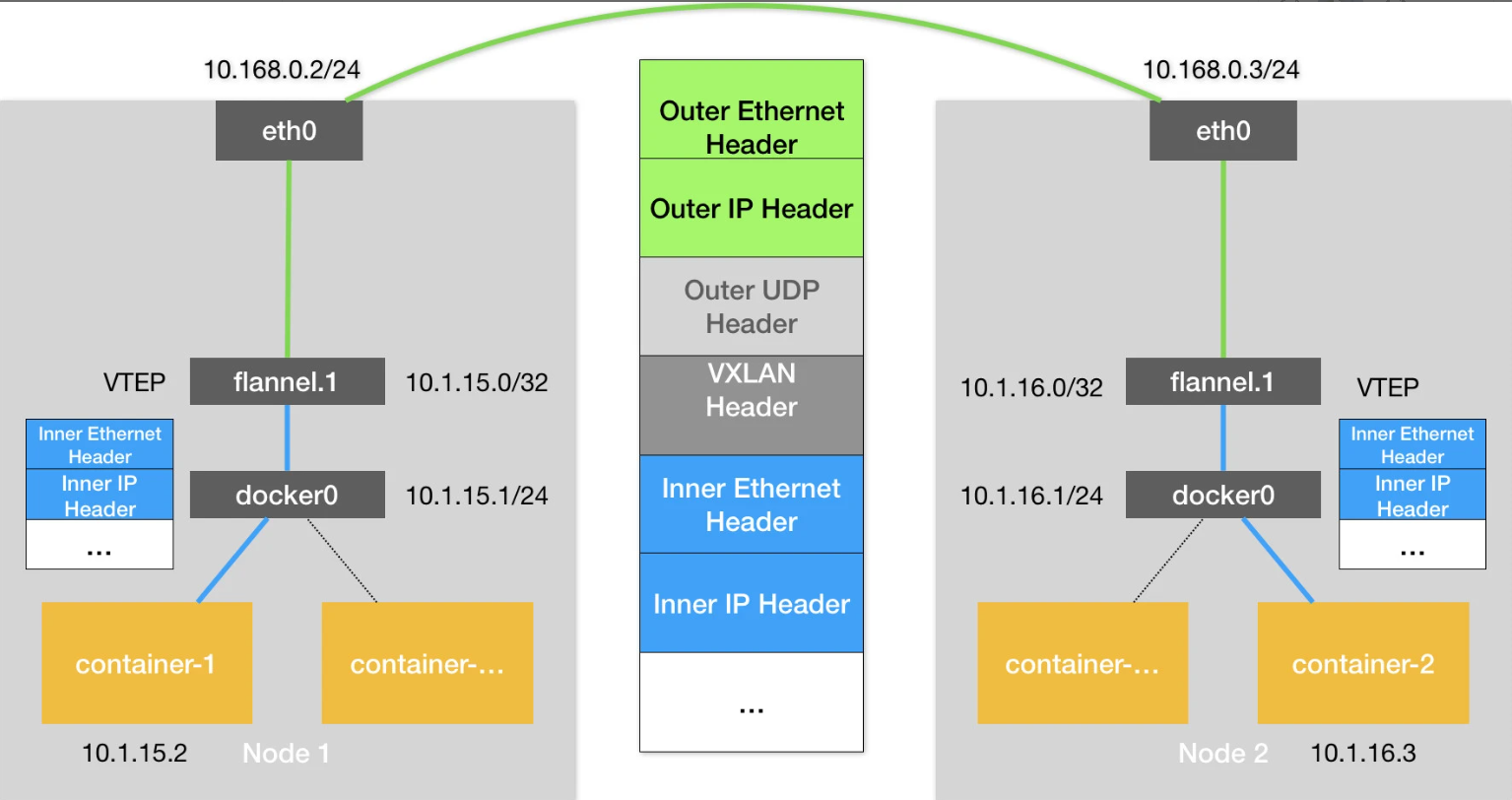
封装的外层数据包

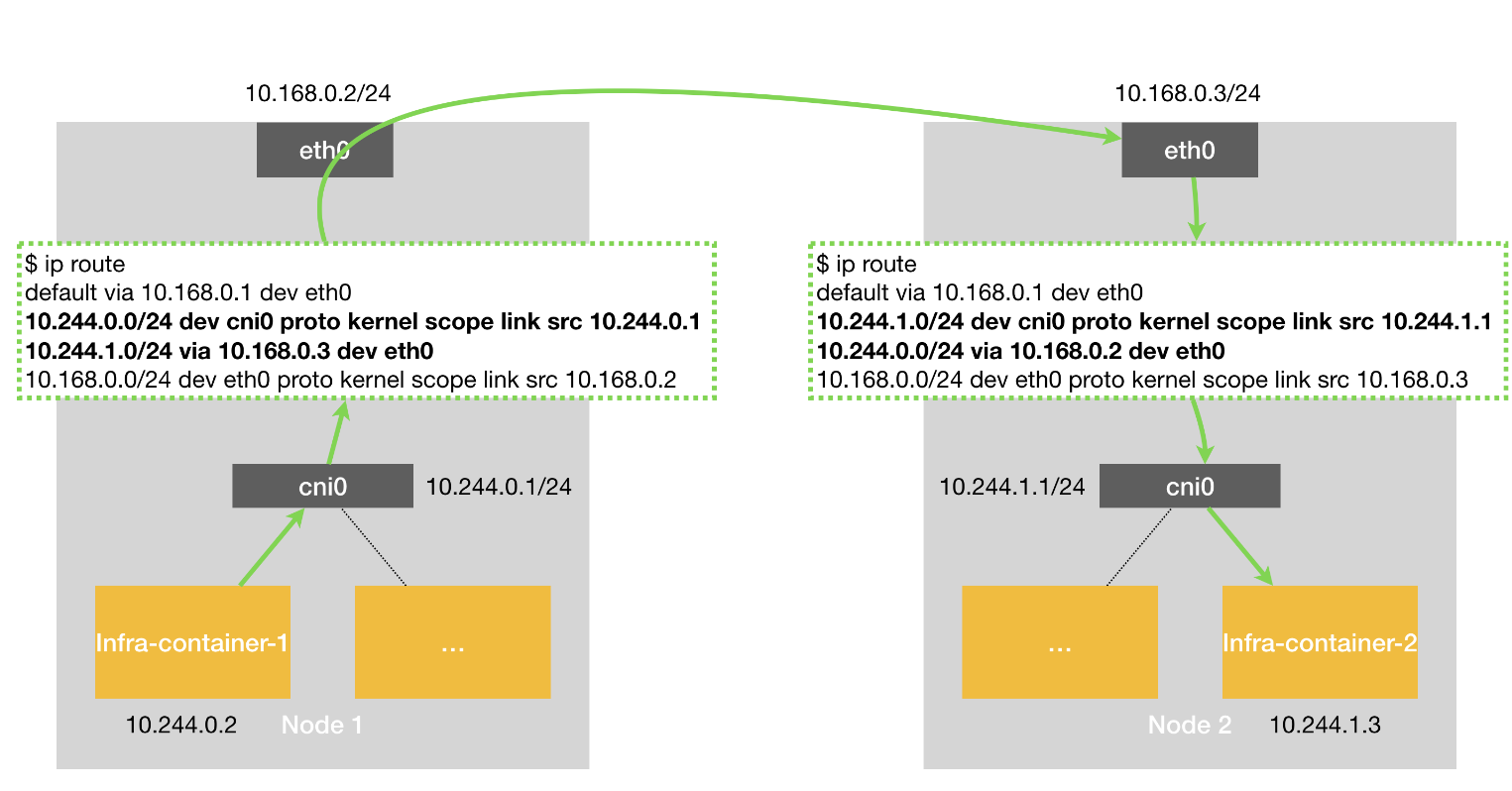
host-gw 方案,走的是三层网络,需要保证 所有 pod 二层是可通的
- pod 通过veth 到docker0 网桥
- node1 宿主机上会有一个路由规则,目标pod的下一条地址,是 node2
- 于是这个数据包直接转给 node2,node2 接收到后做一些拆封,交给 node2 上的容器
- host-gw 模式的工作原理,其实就是将每个 Flannel 子网(Flannel Subnet,比如:10.244.1.0/24)的“下一跳”,设置成了该子网对应的宿主机的 IP 地址
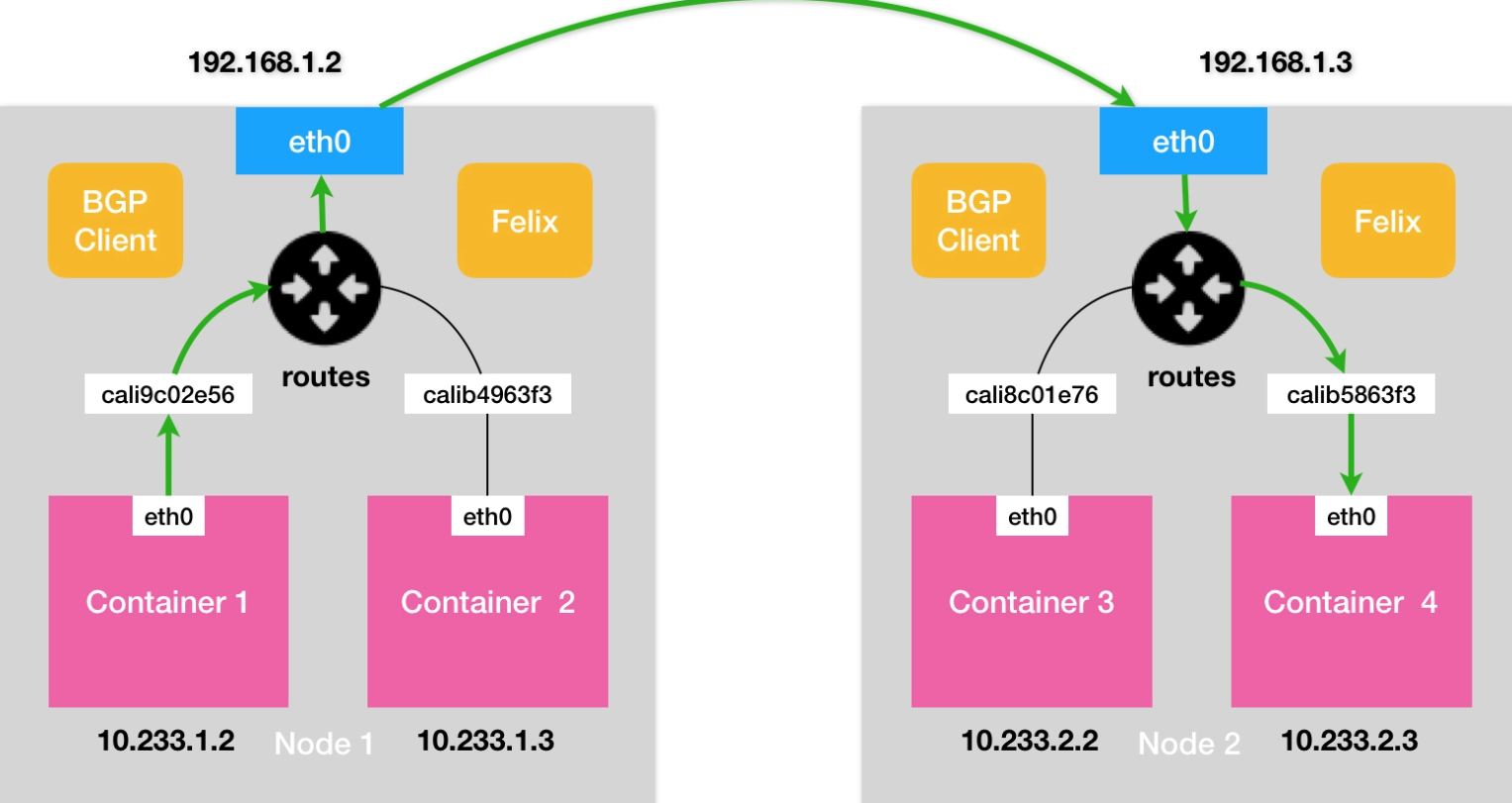
Calico
实现
- 不同于 Flannel 通过 Etcd 和宿主机上的 flanneld 来维护路由信息的做法,
- Calico 项目使用了 BGP 自动地在整个集群中分发路由信息
- BGP 的全称是 Border Gateway Protocol,即:边界网关协议
- Calico 用了 BGP 客户端,每个节点都安装这个客户端,将下一跳指向对端
- 这种是全网络连接的,一般 N 为100个,太大的就需要专门的节点收集集群节点信息了
- 一般采用 Route Reflector 来收集所有节点信息
IPIP
- 如果下一跳跟当前不是一个网段,需要将数据包发给 IP 隧道
- linux 内核封装 真实的 目标 ip地址,然后发给路由器,到下一跳
- 下一跳再将原先的数据包解开,后面过程就是类似的
- 这种方式有性能损失
- Calico 默认都是 一跳的方式实现,如果碰到 IPIP,可以采用 两跳的方式
- 仍然用 Route Reflector 收集所有节点信息,配置 两跳的路由信息
- 这样避免 IPIP 模式,增加性能
网络隔离
Kubernetes 网络插件对 Pod 进行隔离
- 其实是靠在宿主机上生成 Network Policy 对应的 iptable 规则来实现的
- 这跟传统 IaaS 里面的安全组(Security Group)其实是非常类似的
- Kubernetes 从底层的设计和实现上,更倾向于假设你已经有了一套完整的物理基础设施。然后,Kubernetes 负责在此基础上提供一种“弱多租户”(soft multi-tenancy)的能力
- Kubernetes 项目在云计算生态里的定位,其实是基础设施与 PaaS 之间的中间层。这是非常符合“容器”这个本质上就是进程的抽象粒度的
CNI 插件
k8s 的方案跟 flannel 类似,只不过 docker0 网桥换乘了 cni0 网桥了
CNI 插件
| CNI Plugin | Description |
|---|---|
| Flannel | Simple overlay network using VXLAN or host-gw. Suitable for basic use cases. |
| Calico | Provides both overlay and BGP-based routed networking. Includes network policy enforcement. |
| Weave | Creates a mesh overlay network with encryption and automatic peer discovery. |
| Cilium | Focuses on advanced networking, including eBPF for high performance and security policies. |
| Kube-Router | Combines networking and network policy capabilities, focusing on performance. |
Service
实现
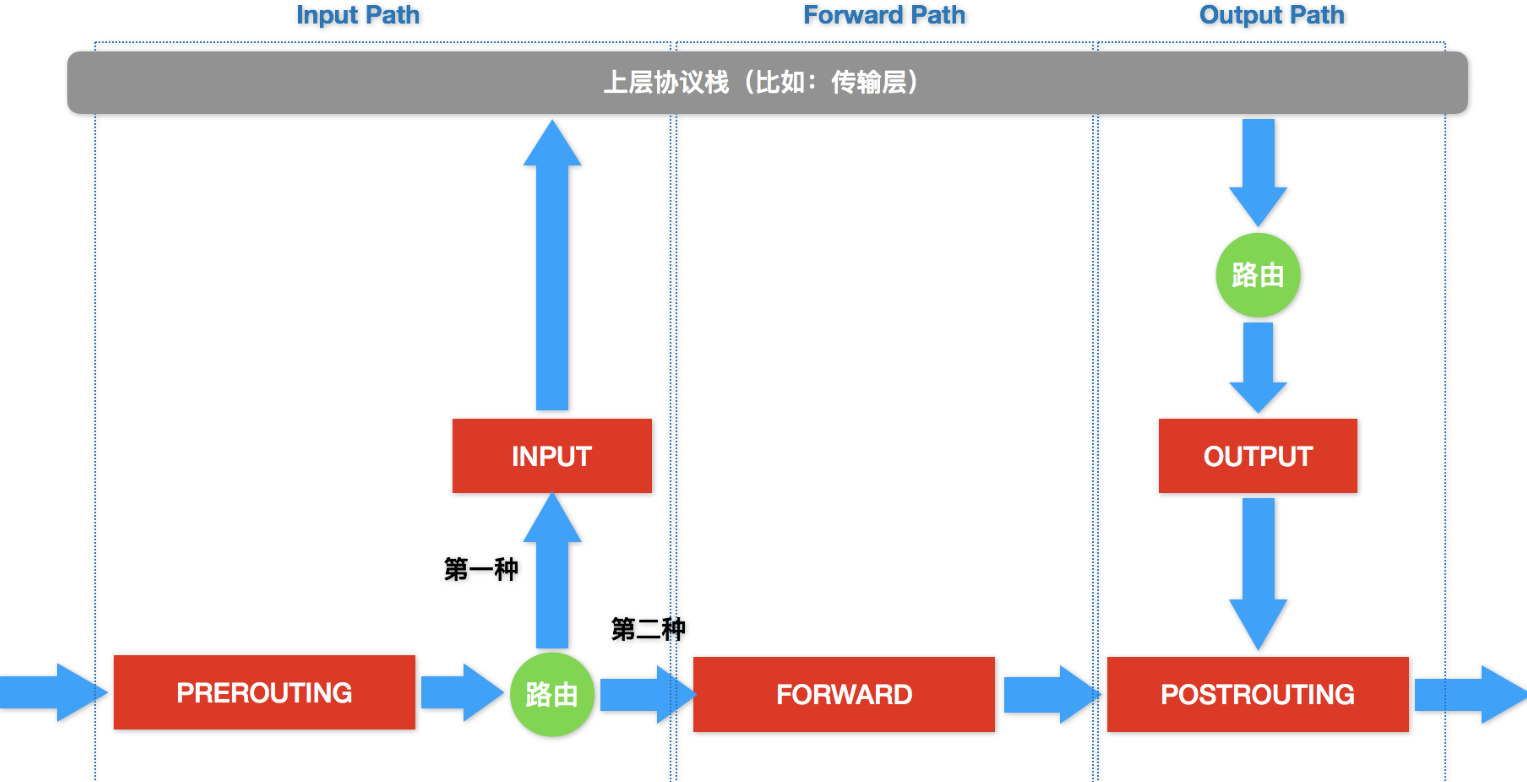
- Service 是由 kube-proxy 组件,加上 iptables 来共同实现的
创建一个 service,等于在 iptables 上创建一个规则
|
|
解释
- 这条 iptables 规则的含义是
- 凡是目的地址是 10.0.1.175、目的端口是 80 的 IP 包
- 都应该跳转到另外一条名叫 KUBE-SVC-NWV5X2332I4OT4T3 的 iptables 链进行处理
即将跳转的 KUBE-SVC-NWV5X2332I4OT4T3 规则
|
|
这一组规则,实际上是一组随机模式(–mode random)的 iptables 链
而这三条链指向的最终目的地,其实就是这个 Service 代理的三个 Pod
serivce 等价的转发原理
|
|
解释
- 这三条链,其实是三条 DNAT 规则
- DNAT 规则的作用,就是在 PREROUTING 检查点之前,也就是在路由之前,将流入 IP 包的目的地址和端口,改成–to-destination 所指定的新的目的地址和端口
- 访问 Service VIP 的 IP 包经过上述 iptables 处理之后,就已经变成了访问具体某一个后端 Pod 的 IP 包了
Kubernetes 的 kube-proxy 还支持一种叫作 IPVS 的模式
- 一直以来,基于 iptables 的 Service 实现,都是制约 Kubernetes 项目承载更多量级的 Pod 的主要障碍
- IPVS 模式的工作原理,其实跟 iptables 模式类似
- IPVS 在内核中的实现其实也是基于 Netfilter 的 NAT 模式
- 只是把对这些“规则”的处理放到了内核态,从而极大地降低了维护这些规则的代价
两种服务发现
- ClusterIP 模式的 Service 是一个 Pod 的稳定的 IP 地址,即 VIP,这里 Pod 和 Service 的关系是可以通过 Label 确定的
- Headless Service 是一个 Pod 的稳定的 DNS 名字,这个名字是可以通过 Pod 名字和 Service 名字拼接出来的
从外部访问 Service 的三种方式
- NodePort
- LoadBalancer
- External Name
Kubernetes 里面的 Service 和 DNS 机制,也都不具备强多租户能力
Ingress 服务
- 全局的、为了代理不同后端 Service 而设置的负载均衡服务
- 所谓 Ingress,就是 Service 的“Service”。
Ingress Controller
- 如 example.com 统一入口,根据 /aa, /bb 分发到不同的 service
- 常用的实现如: Nginx、HAProxy、Envoy、Traefik
日志
日志收集
- 第一种,在 Node 上部署 logging agent,将日志文件转发到后端存储里保存起来
- 第二种,就是对这种特殊情况的一个处理,即:当容器的日志只能输出到某些文件里的时候,我们可以通过一个 sidecar 容器把这些日志文件重新输出到 sidecar 的 stdout 和 stderr 上,这样就能够继续使用第一种方案了
- 第三种方案,就是通过一个 sidecar 容器,直接把应用的日志文件发送到远程存储里面去
调度
架构
- 第一个控制循环,我们可以称之为 Informer Path,用来监听 etcd 的变化
- 第二个控制循环,是调度器负责 Pod 调度的主循环,我们可以称之为 Scheduling Path
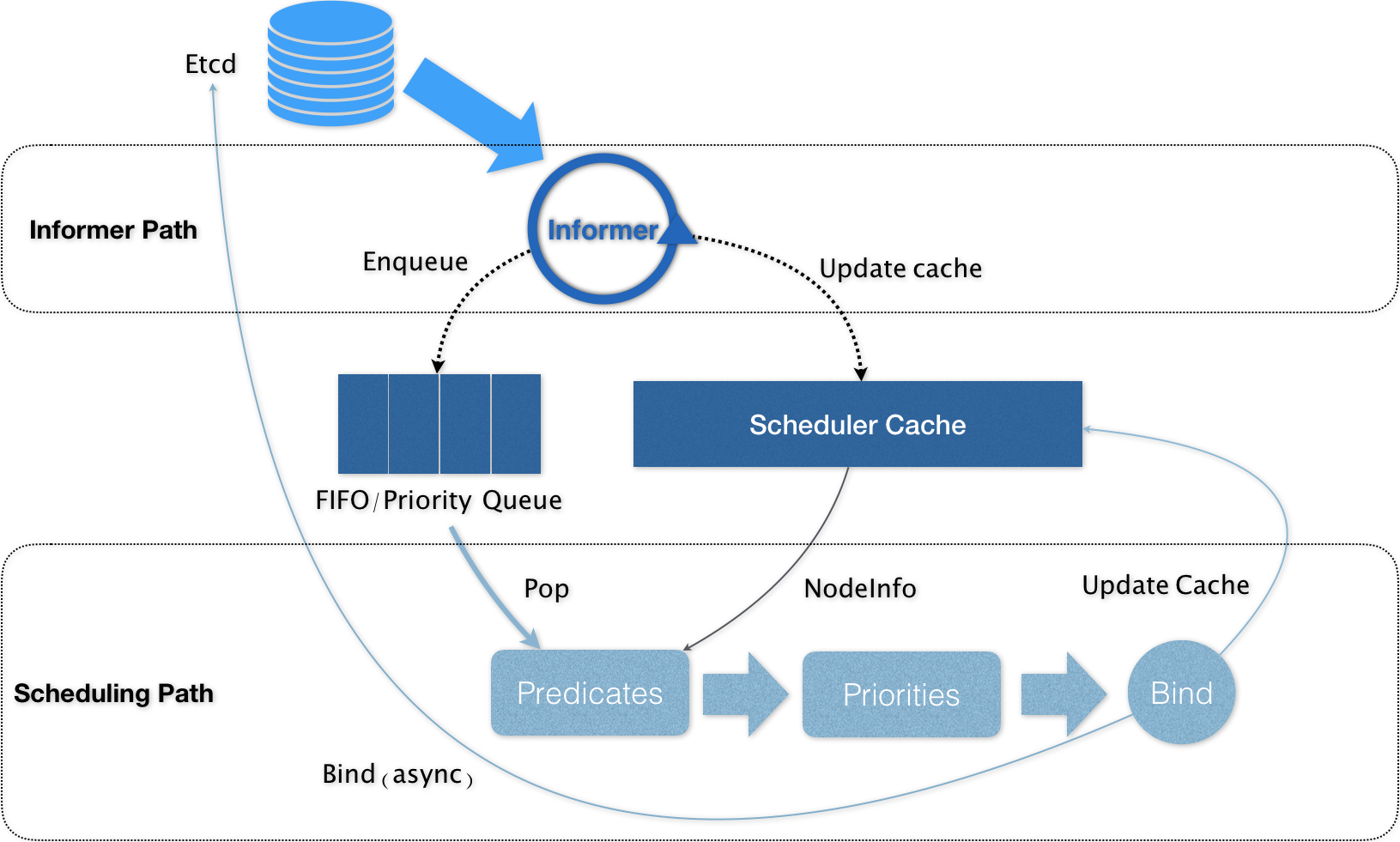
调度过程中 Predicates 和 Priorities 这两个调度策略
Predicates 在调度过程中的作用,可以理解为 Filter
- 第一种类型,叫作 GeneralPredicates,如CPU是否足够
- 第二种类型,是与 Volume 相关的过滤规则
- 第三种类型,是宿主机相关的过滤规则
- 第四种类型,是 Pod 相关的过滤规则
Priorities
- 工作就是为这些节点打分
- 这里打分的范围是 0-10 分,得分最高的节点就是最后被 Pod 绑定的最佳节点
- 这个算法实际上就是在选择空闲资源(CPU 和 Memory)最多的宿主机
Pod 调度失败的情况
- 优先级(Priority )
- 抢占(Preemption)
特殊硬件的调度
- kubelet 关联 Device Plugin,通过gRPC通讯
- 通过ListAndWatch获取资源列表
- 通过 Allocate() 分配 GPU
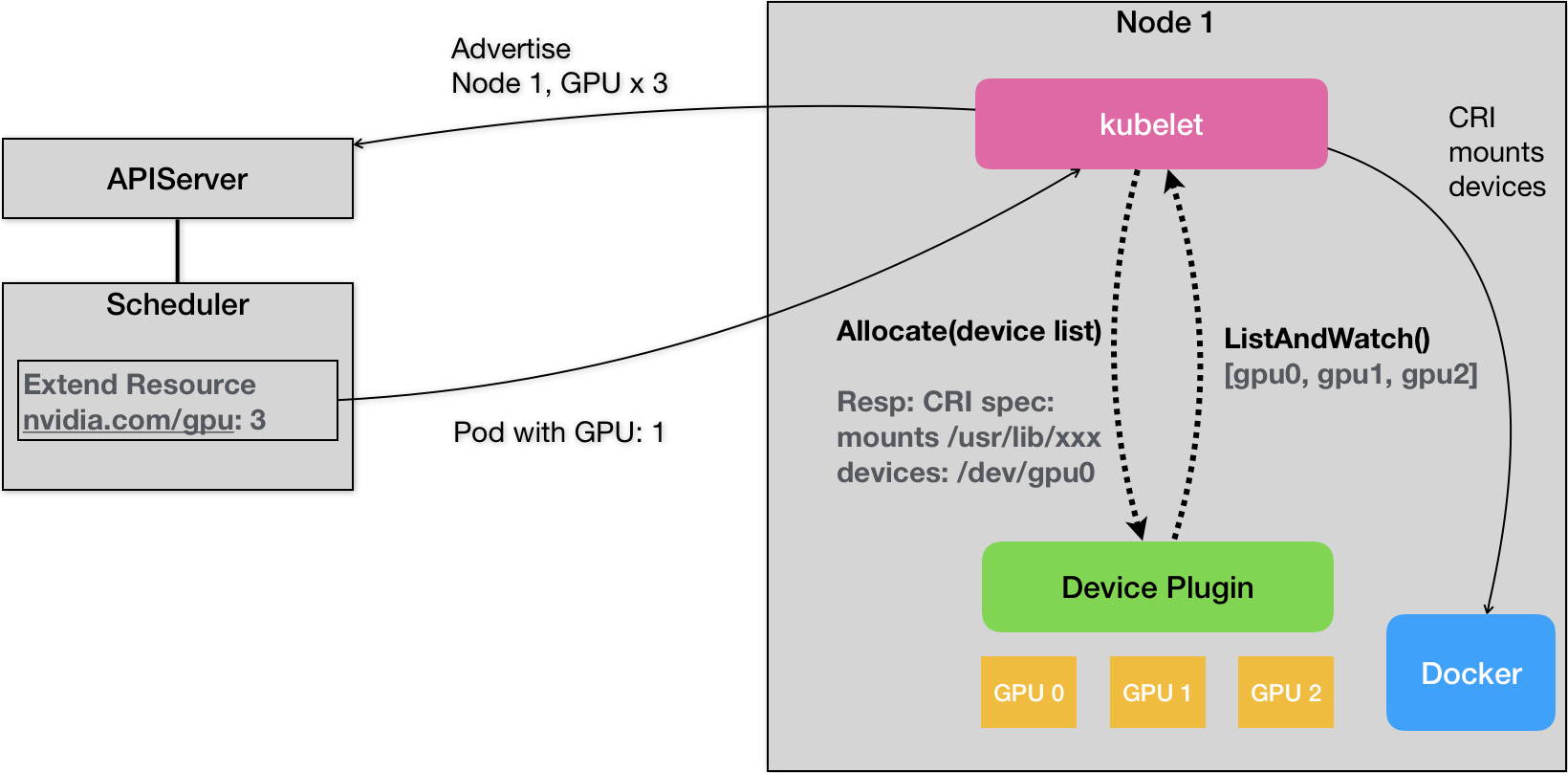
K8S社区的硬件插件
运行时
K8S 中两个不可替代的组件
- kube-apiserver
- kubelet
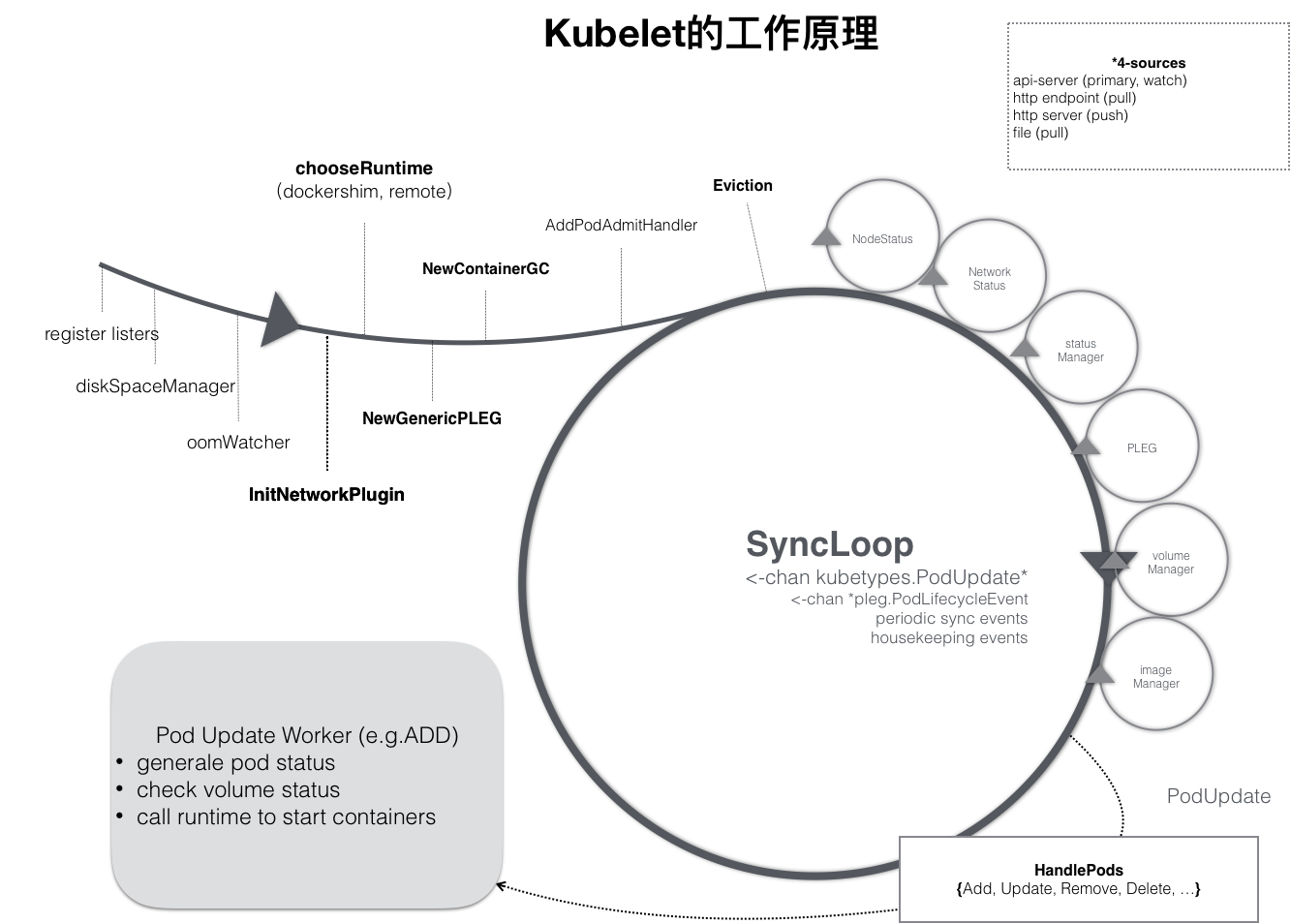
kubelet 的工作核心
- 一个控制循环,即:SyncLoop(图中的大圆圈)
- Pod 更新事件、Pod 生命周期变化、kubelet 本身设置的执行周期、定时的清理事件
- 还有各种小事件:Volume Manager、Image Manager、Node Status Manager
- 而当一个 Pod 完成调度、与一个 Node 绑定起来之后, 这个 Pod 的变化就会触发 kubelet 在控制循环里注册的 Handler
- kubelet 调用下层容器运行时的执行过程,并不会直接调用 Docker 的 API
- 而是通过一组叫作 CRI(Container Runtime Interface,容器运行时接口)的 gRPC 接口来间接执行的
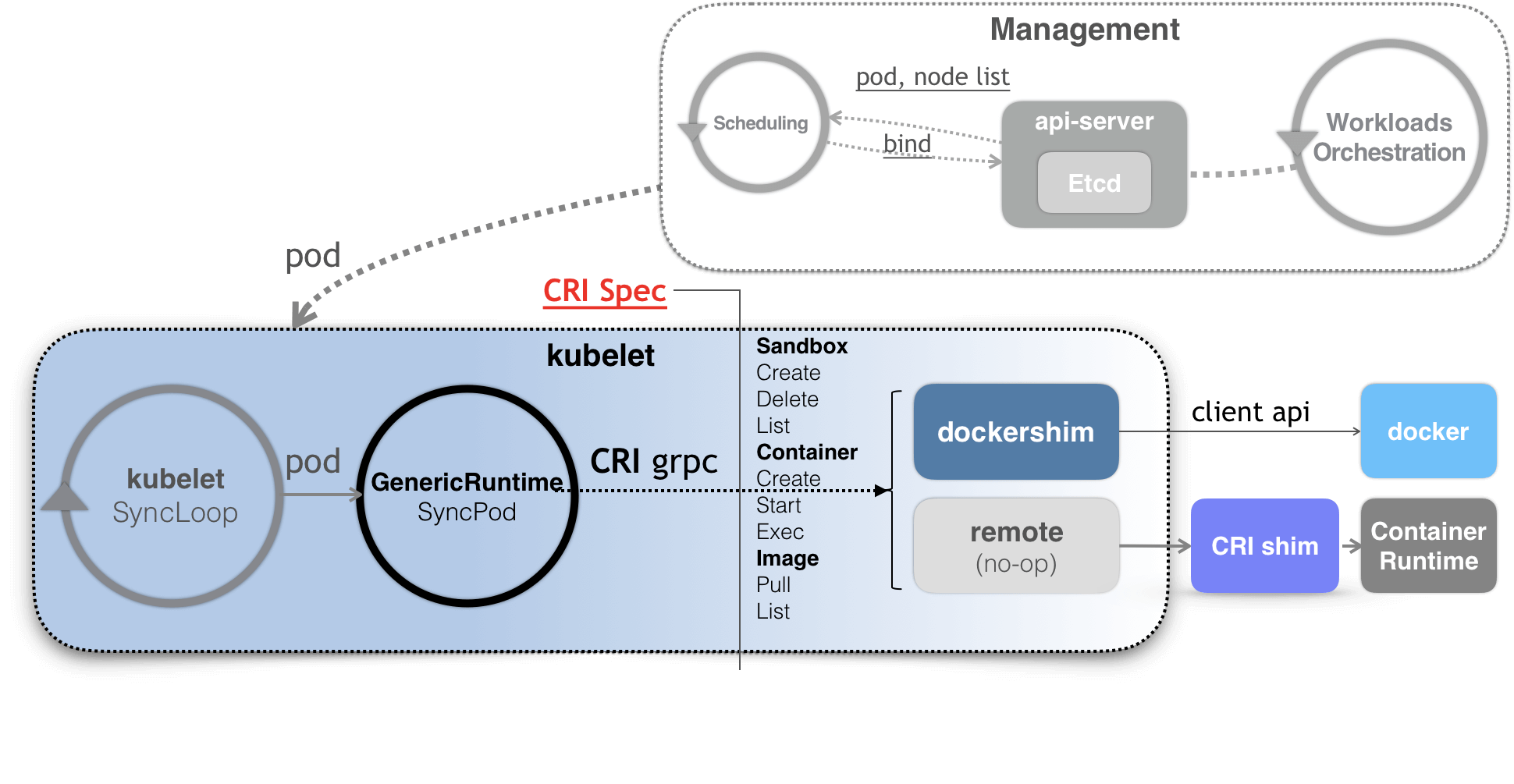
CRI 之后的架构
- kubelet 当然会通过 SyncLoop 来判断需要执行的具体操作
- kubelet 实际上就会调用一个叫作 GenericRuntime 的通用组件来发起创建 Pod 的 CRI 请求
- CRI shim,实现 CRI 规定的每个接口,然后把具体的 CRI 请求“翻译”成对后端容器项目的请求或者操作
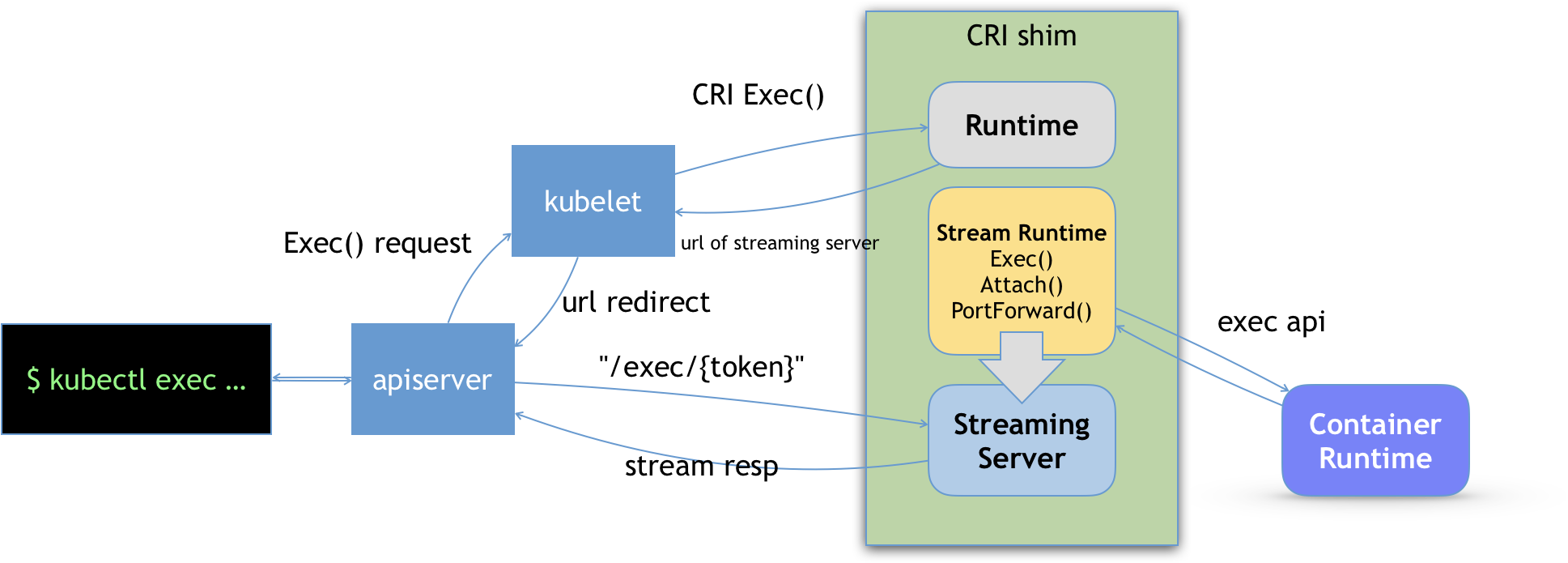
CRI 分为两组
- RuntimeService。它提供的接口,主要是跟容器相关的操作。比如,创建和启动容器、删除容器、执行 exec 命令等等
- ImageService。它提供的接口,主要是容器镜像相关的操作,比如拉取镜像、删除镜像等等
长连接
- 为了维护 logs,exec 等接口,需要长连接,也就是:Streaming API
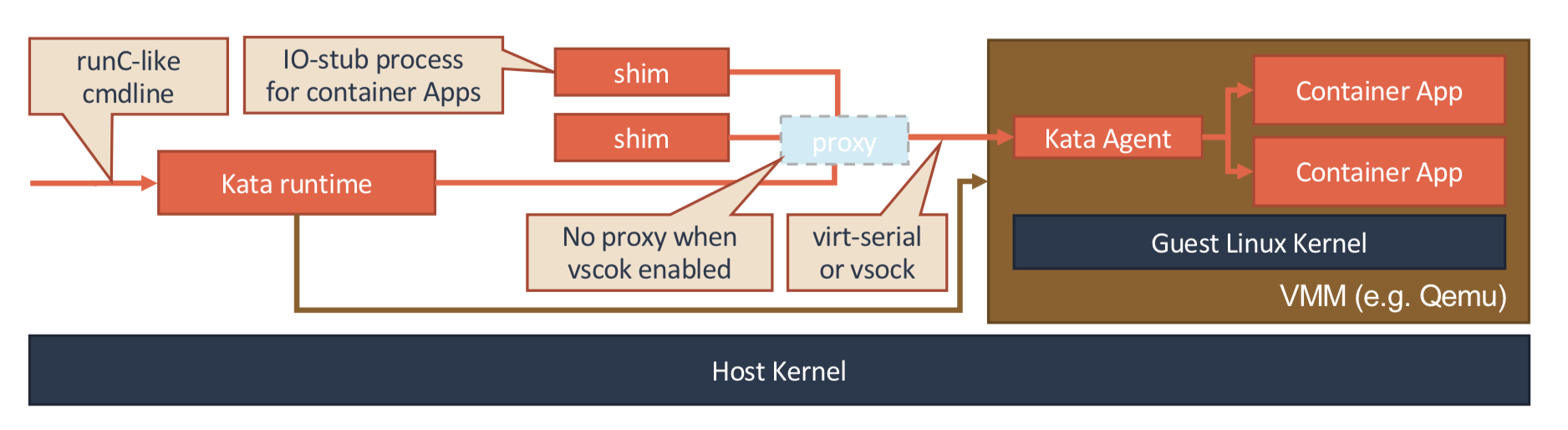
基于虚拟化的容器
- Kata Containers,本质就是一个精简后的轻量级虚拟机
- gVisor 项目给容器进程配置一个用 Go 语言实现的、运行在用户态的、极小的“独立内核”
- 这两种容器实现的本质,都是给进程分配了一个独立的操作系统内核,从而避免了让容器共享宿主机的内核
Kata Containers 的本质
- 一个标准的虚拟机管理程序(Virtual Machine Manager, VMM)是运行 Kata Containers 必备的一个组件
- 原生就带有了 Pod 的概念。即:这个 Kata Containers 启动的虚拟机,就是一个 Pod
- 一个特殊的 Init 进程负责管理虚拟机里面的用户容器,并且只为这些容器开启 Mount Namespace
- 容器启动后只能看到,被裁减过的 Guest Kernel,以及通过 Hypervisor 虚拟出来的硬件设备
- 通过 vhost 技术(比如:vhost-user)来实现 Guest 与 Host 之间的高效的网络通信
- 使用 PCI Passthrough (PCI 穿透)技术来让 Guest 里的进程直接访问到宿主机上的物理设备
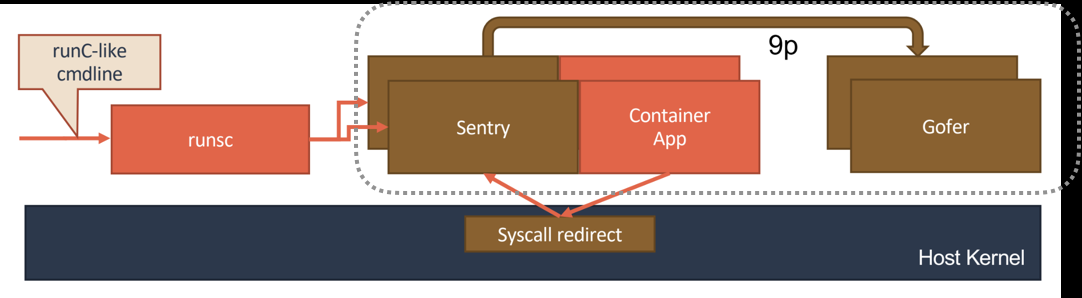
gVisor 的设计
- 核心是:Sentry 的进程,Go语言重写的,一个对应用进程“冒充”内核的系统组件
- 提供一个传统的操作系统内核的能力,即:运行用户程序,执行系统调用
- Sentry 对于 Volume 的操作,则需要通过 9p 协议交给一个叫做 Gofer 的代理进程来完成
- Sentry 并不会真的像虚拟机那样去虚拟出硬件设备、安装 Guest 操作系统。它只是借助 KVM 进行系统调用的拦截,以及处理地址空间切换等细节