概念
三个角色
| Component |
Data Stored |
Replication |
Replication Method |
| Ozone Manager (OM) |
Full namespace metadata |
Fully replicated on all OM nodes |
Raft (Apache Ratis) |
| Storage Container Manager (SCM) |
Full storage metadata |
Fully replicated on all SCM nodes |
Raft (Apache Ratis) |
| DataNode |
Actual data blocks |
Replicated as per replication factor (e.g., 3 replicas) |
Managed by SCM pipelines |
架构
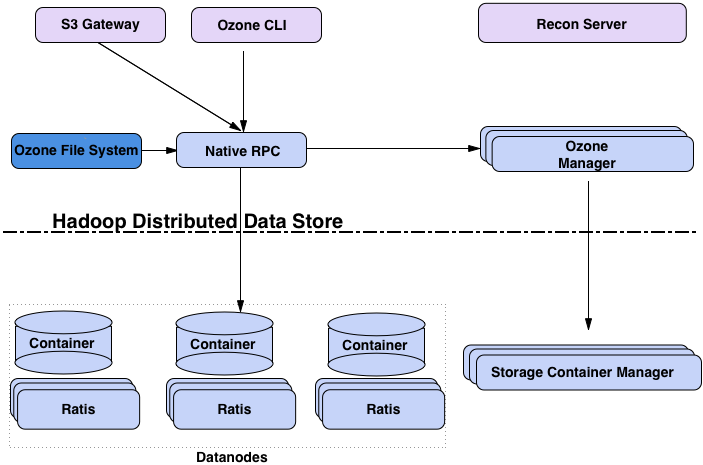
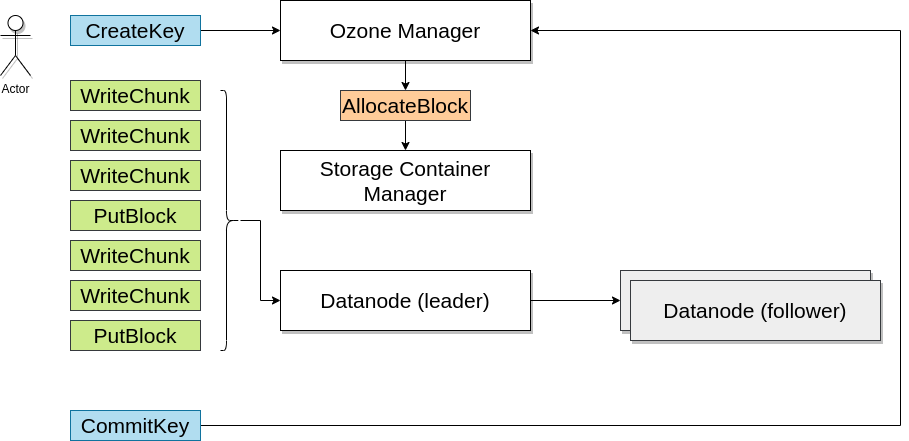
om 的 处理过程
om 存储的元数据大致内容
1
2
3
4
5
6
|
Container: c1
├── Block: b1 (DataNode1, DataNode2, DataNode3)
├── Block: b2 (DataNode1, DataNode2, DataNode3)
Container: c2
├── Block: b3 (DataNode4, DataNode5, DataNode6)
|
存储在 rocksdb 中的内容
1
2
3
4
5
6
7
8
|
{
"container_id": "c1",
"blocks": ["b1", "b2"],
"replication_factor": 3,
"pipeline": "pipeline_1",
"datanodes": ["datanode1", "datanode2", "datanode3"]
}
|
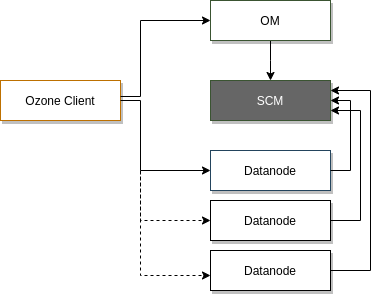
scm 的处理过程
存储的内容
1
2
3
4
5
6
|
Container: c1
├── Block: b1 (DataNode1, DataNode2, DataNode3)
├── Block: b2 (DataNode1, DataNode2, DataNode3)
Container: c2
├── Block: b3 (DataNode4, DataNode5, DataNode6)
|
存储在 rocksdb 中的内容
1
2
3
4
5
6
7
8
9
10
11
|
{
"block_id": "b1",
"container_id": "c1",
"size": "4MB",
"checksum": "abc123",
"replicas": [
{"datanode": "datanode1", "location": "/path/to/block1"},
{"datanode": "datanode2", "location": "/path/to/block1"},
{"datanode": "datanode3", "location": "/path/to/block1"}
]
}
|
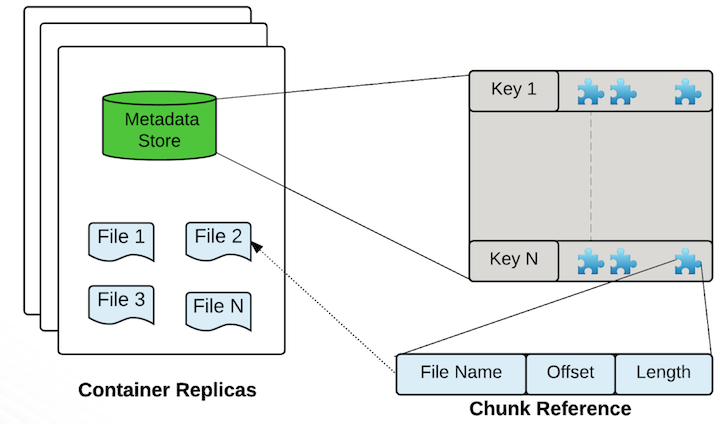
datanode 类似 HDFS 的datanode,是真正存储数据的地方
- 会先分配一个 container,默认 5G
- 多个文件都是放到一个 container中,按照offset区分
recon 提供管理界面
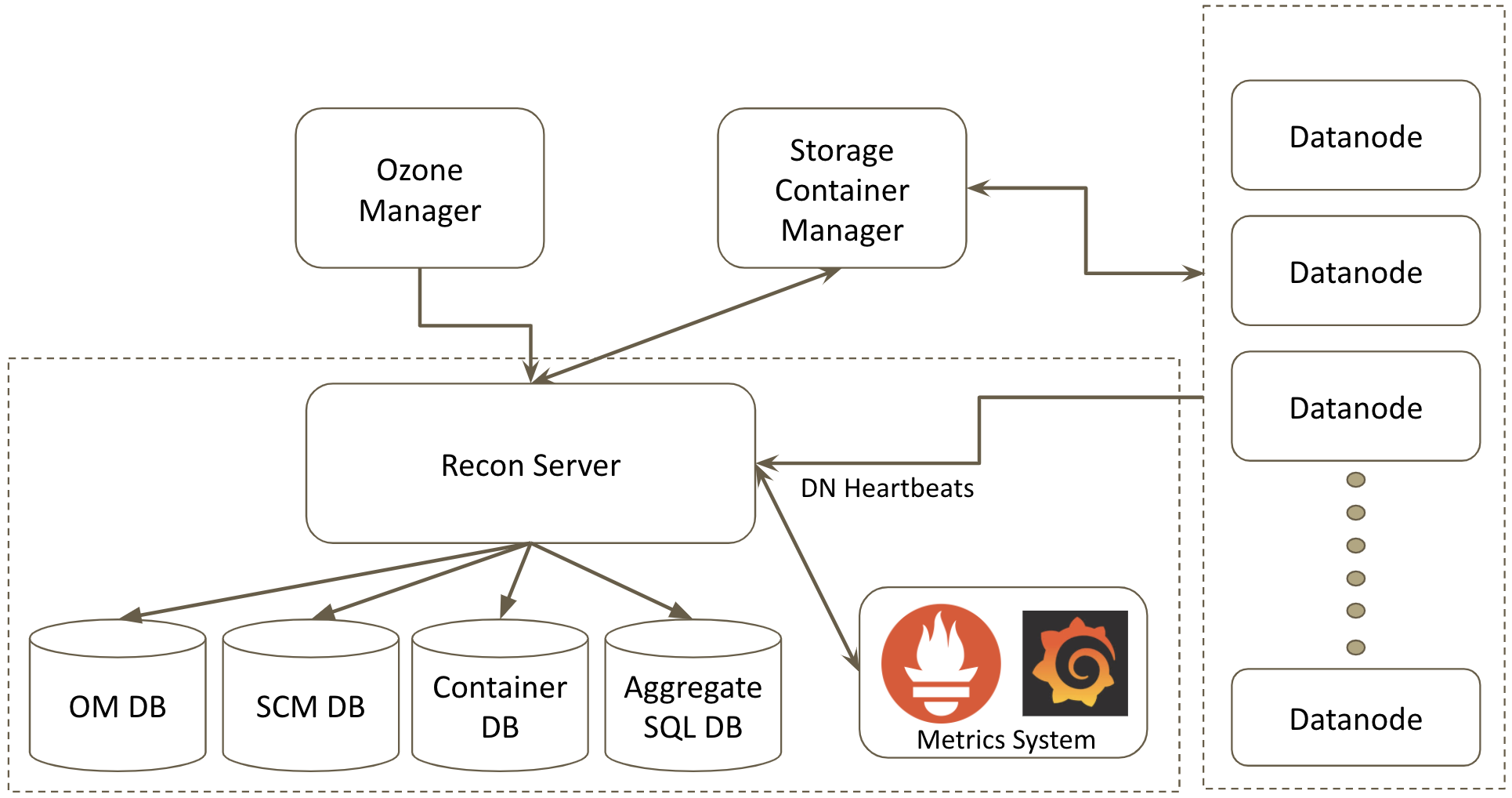
高可用,使用 rocksdb + raft 实现的
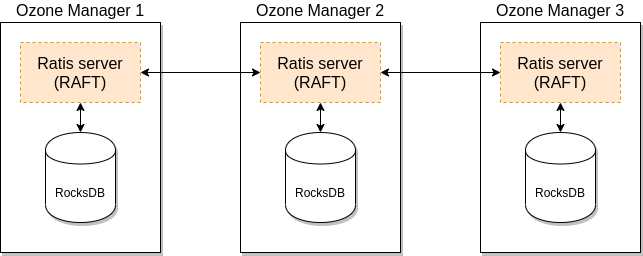
其中 raft 使用的是 apache 开源的 raft 实现库
https://github.com/apache/ratis
安全,可以整合 ranger 和 kberos
自带了一些 ACL
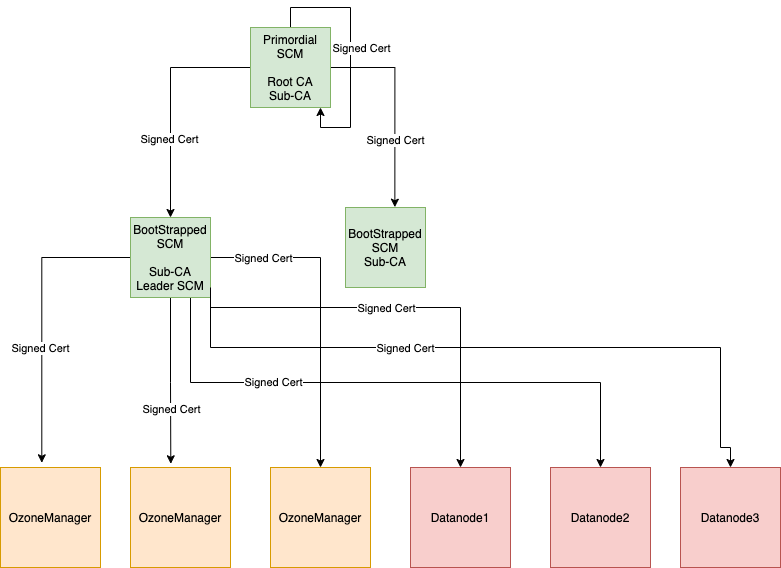
文件的元数据布局

存储方案
HDFS 替代存储的性能对比
| Feature |
Apache Ozone |
Ceph |
Cluster Storage (General) |
MinIO |
| Storage Type |
Object Storage (HDFS Compatible) |
Object, Block, File Storage |
Varies (File, Block, etc.) |
Object Storage (S3 Compatible) |
| Hadoop Integration |
Full Integration |
Limited (via S3 Gateway) |
Varies |
None (direct S3 interface) |
| Ease of Deployment |
Moderate |
Complex |
Varies |
Easy |
| Performance |
Optimized for small/large files |
High performance with scalability |
Depends on system |
High throughput, low latency |
| Use Case |
Big Data Analytics |
Multi-purpose storage |
HPC, scalable general storage |
Cloud-native object storage |
整合
ozone整合
整合 spark
1
2
3
4
5
|
spark-submit \
--master local \
--conf spark.hadoop.fs.defaultFS=ofs://ozone1 \
--conf spark.hadoop.ozone.om.address=localhost:9862 \
--class your.package.YourApp your-spark-app.jar
|
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("Spark with Ozone")
.config("spark.hadoop.fs.defaultFS", "ofs://ozone1")
.config("spark.hadoop.ozone.om.address", "localhost:9862")
.getOrCreate()
val data = Seq(("Alice", 25), ("Bob", 30))
val df = spark.createDataFrame(data).toDF("name", "age")
df.write.format("parquet").save("ofs://ozone1/mybucket/spark_data")
val readDF = spark.read.format("parquet").load("ofs://ozone1/mybucket/spark_data")
readDF.show()
|
整合 flink
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object FlinkOzoneExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val data = env.fromElements(("Alice", 25), ("Bob", 30))
data.writeAsCsv("ofs://ozone1/mybucket/flink_data")
env.execute("Flink Ozone Integration")
}
}
|
presto、trino
hive.metastore.uri=thrift://localhost:9083
hive.s3.warehouse.dir=ofs://ozone1/mybucket/
fs.defaultFS=ofs://ozone1
ozone.om.address=localhost:9862
然后直接查询就可以了
1
|
SELECT * FROM mybucket.my_table WHERE age > 25;
|
impala,因为是兼容 hdfs,所以整合也很简单
1
2
|
SET fs.defaultFS=ofs://ozone1;
SELECT * FROM mybucket.my_table;
|
doris
1
2
3
4
5
6
7
8
9
10
|
CREATE EXTERNAL TABLE my_external_table (
id INT,
name STRING
)
PROPERTIES (
"fs.defaultFS"="ofs://ozone1",
"path"="ofs://ozone1/mybucket/doris_data/"
);
SELECT * FROM my_external_table;
|
minio整合
整合spark
spark.hadoop.fs.s3a.endpoint=http://<minio-host>:9000
spark.hadoop.fs.s3a.access.key=<your-access-key>
spark.hadoop.fs.s3a.secret.key=<your-secret-key>
spark.hadoop.fs.s3a.path.style.access=true
spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("Spark with MinIO")
.config("spark.hadoop.fs.s3a.endpoint", "http://localhost:9000")
.config("spark.hadoop.fs.s3a.access.key", "minioadmin")
.config("spark.hadoop.fs.s3a.secret.key", "minioadmin")
.config("spark.hadoop.fs.s3a.path.style.access", "true")
.getOrCreate()
val data = Seq(("Alice", 28), ("Bob", 35))
val df = spark.createDataFrame(data).toDF("name", "age")
// Write to MinIO
df.write.parquet("s3a://mybucket/spark/data")
// Read from MinIO
val readDF = spark.read.parquet("s3a://mybucket/spark/data")
readDF.show()
|
flink 整合
1
2
3
4
5
|
s3.endpoint: http://<minio-host>:9000
s3.access-key: <your-access-key>
s3.secret-key: <your-secret-key>
s3.path-style-access: true
s3.filesystem.impl: org.apache.hadoop.fs.s3a.S3AFileSystem
|
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import org.apache.flink.api.scala._
object FlinkMinIOExample {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val data = env.fromElements(("Alice", 28), ("Bob", 35))
// Write to MinIO
data.writeAsCsv("s3a://mybucket/flink/data")
env.execute("Flink with MinIO")
}
}
|
presto/trino
hive.s3.aws-access-key=<your-access-key>
hive.s3.aws-secret-key=<your-secret-key>
hive.s3.endpoint=http://<minio-host>:9000
hive.s3.path-style-access=true
hive.s3.file-system-type=EMRFS
查询
1
|
SELECT * FROM mybucket.my_table WHERE age > 30;
|
doris 整合
1
2
3
4
5
6
7
8
9
10
11
12
|
CREATE EXTERNAL TABLE my_external_table (
id INT,
name STRING
)
PROPERTIES (
"s3.endpoint" = "http://<minio-host>:9000",
"s3.access_key" = "<your-access-key>",
"s3.secret_key" = "<your-secret-key>",
"s3.path" = "s3a://mybucket/doris/data/"
);
SELECT * FROM my_external_table;
|
参考