sea tunnel
背景
数据同步的演化
- N 个源、M 个目标,所以要做 解耦合
- 基本都是 source + channel + sink 这种模式
- 单线程读取太弱,改为多线程并行读取
- 基于多线程的 task,需要有调度机制,也就是 engine
- 还有表结构的同步,schema(如kafka的topic自动发现机制)
- 数据湖格式,MPP大表同步,需要多引擎支持
源的拆分机制
- min,max 计算数据区间,如果不均衡才需要采样
- string 类型,datax 是转换为 long,再根据步长拆分长 10片
需要
- 搬运源 -> 目标,单表,多表,整个库
- 实时,离线,CDC,一致性,一些转换
- 对接 MPP,数据湖格式
- 各种监控、报警,自动化,方便使用
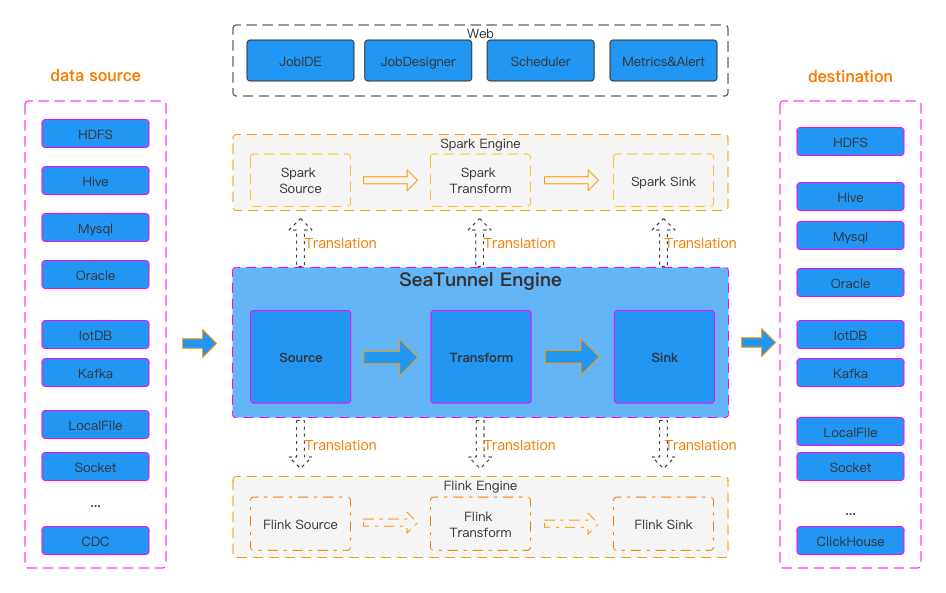
SaeTunnel
SeaTunnel的设计目标:
- 简单易用:通过简单的配置和命令即可创建同步任务和运行同步任务;
- 同步过程可监控、指标可量化:同步过程中自动统计任务读取写入的数据量,性能指标,数据延时等信息
- 丰富的数据源生态:支持国内外数据库、消息队列、云存储、云组件、数据湖、仓、SaaS服务、支持用户自定义数据源
- 全场景支持:支持所有数据集成场景,包括离线、实时、全量、增量、CDC、CDC整库同步、DDL变更、动态加表
- 数据一致性保障:数据不丢失、不重复、精确处理一次、支持断点续传
- 资源使用少:包括内存优化、CPU线程优化、多表同步数据库连接共享
SeaTunnel的源连接器
- 支持离线和实时操作模式,通过环境配置中的作业模式轻松切换
- Source可以实现并行读取、动态分片发现、字段投影、多表读取
- 精确一次语义支持,以及适配Zeta、Spark和Flink的Checkpoint机制
- 比如源表很大,有几万个 jdbc 链接,这时候需要做连接池控制并发
SeaTunnel的Sink连接器支持以下功能:
- 支持SaveMode,灵活选择目标性能和数据处理方式
- 自动创建表,支持模板修改表创建,在多表同步场景下解放双手
- 精确一次语义支持,数据不会丢失或复制,Checkpoint机制适配 Zeta、Spark、Flink引擎
CDC
- 离线和实时的
- 离线CDC 一般需要源表有 timestampe 支持,但是处理不了 delete情况
- 需要将 先记录一个中间表,再根据源表和中间表比对做delete
- 离线CDC,基于binlog 的offset位点,同步一批,再启动后读取上一次的 offset
SeaTunnel的CDC(Change Data Capture)
- 主要用来做CDC的同步
- 连接器支持无锁快照读取,动态发现表,多表同步和多表写入
- Schema evolution,checkpoint
- CDC批量数据同步,适应了离线数据同步的需求
- SeaTunnel支持多表数据读取和写入,通过简单配置,即可实现多表数据的快速读取和写入
- 通过 SQL 创建 cdc 任务
|
|
精确一致
- 两阶段提交
- 目标端冥等写入
Zeta 引擎
- 不依赖任何第三方组件,不需要 ZK
- 内置了一套分布式网格系统,可以内存持久化,持久任务状态
- 无主的架构,当有节点挂掉后,通过分布式存储做自动恢复
AI 支持
- sea tunnel row 增加 向量的 long,float支持
- 支持向量数据库的 读、写
- 以及未来包含 transform 的支持